
Nacos 上的负载均衡
服务多级存储模型
在之前我们讲解 Nacos 的数据模型可以了解,Nacos 实例 Key 由如下三元组唯一确定,命名空间,分组,服务名
1 | Namespace(命名空间) |
在之前,我们的服务模型都是按照两层划分的,一个服务就是一个业务的微服务,一个服务下可以有多个实例
不过随着我们的业务规模越来越大,为了增加稳定性和容灾性,我们会将一个实例部署在多个机房,所以
Nacos 引入了地域 (Zone)
的概念,把同一个服务的多个实例部署到不同地域的机房中
(鸡蛋分开不同的篮子放) ;又把在同一个地域的机房的多个服务实例称为集群
(Cluster) 。比如,杭州机房的 2 个用户服务 user-service
称为杭州 user-service 集群。
这样,把一在同一个机房的多个实例称为一个集群,三层的服务多级模型就出现了
一个服务可以分多个集群部署,一个服务器可以部署多个服务(但是一般不会这么做,一般一台服务器就只部署一个服务实例),一个集群可以有多个实例;
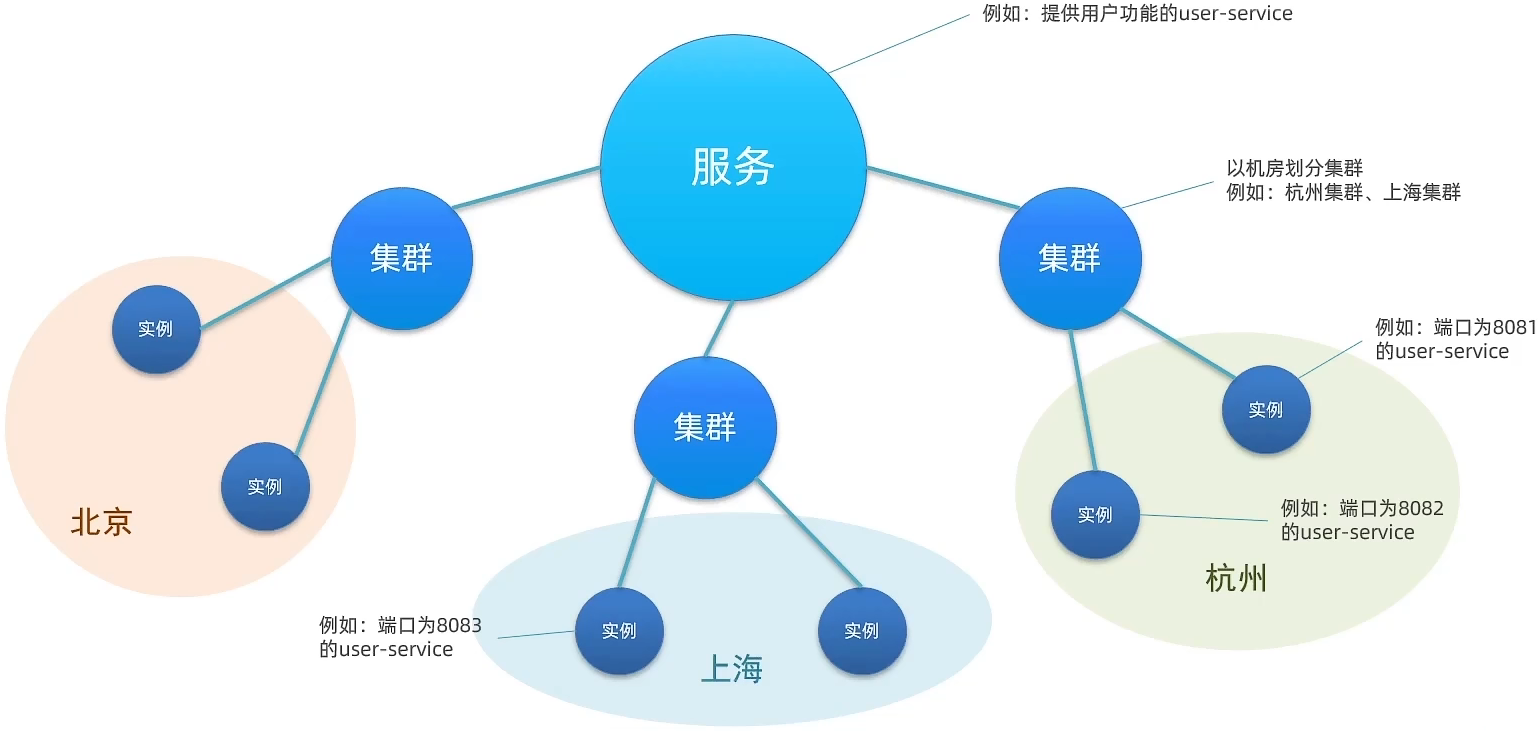
因此,在 Nacos 的服务分级模型中,
- 第一级是微服务 (如订单服务) ;
- 第二级是集群 (如北京订单服务集群、上海订单服务集群等) ;
- 第三集是实例 (如杭州服务集群的 8081 端口实例、8082 端口实例等) 。
所以就会产生服务跨集群调用的问题
微服务之间的远程调用要优先调用同一个地域的集群中的实例,因为访问同一个集群中的服务距离较短、速度比较快、延迟比较低 (例如北京集群的订单服务调用北京集群的用户服务) 。而跨地域集群地域距离远、速度慢、延迟高 (例如北京集群的订单服务调用上海集群的用户服务) 。
那为什么 Nacos 还要增加一层 集群 的概念呢?
首先就是为了避免跨地域集群的远程调用发生,让微服务之间的远程调用尽可能地发生在同一个地域集群中,保证访问的高速低延迟。其次就是为了当同地域的集群服务不可用时,可以跨地域集群访问,保证服务的高可用,提升系统的容灾能力。
服务多级存储模型的实例演示
首先,我们要进行这样的一个配置,这些配置中,都可以修改 Nacos 的服务存储模型中的内容,我感觉还不止这些,但是我就知道这些了
1 | # 命名空间配置 - 创建自定义命名空间(需要先在Nacos控制台创建) |
然后在控制台就可以看到集群的变化,可以再Nacos中看到部署的服务实例
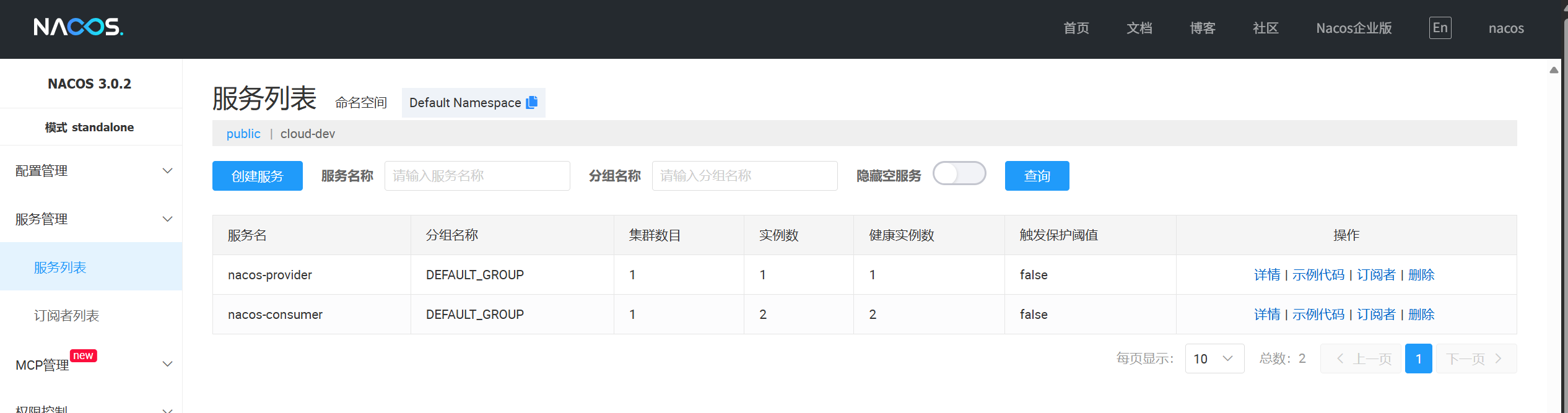
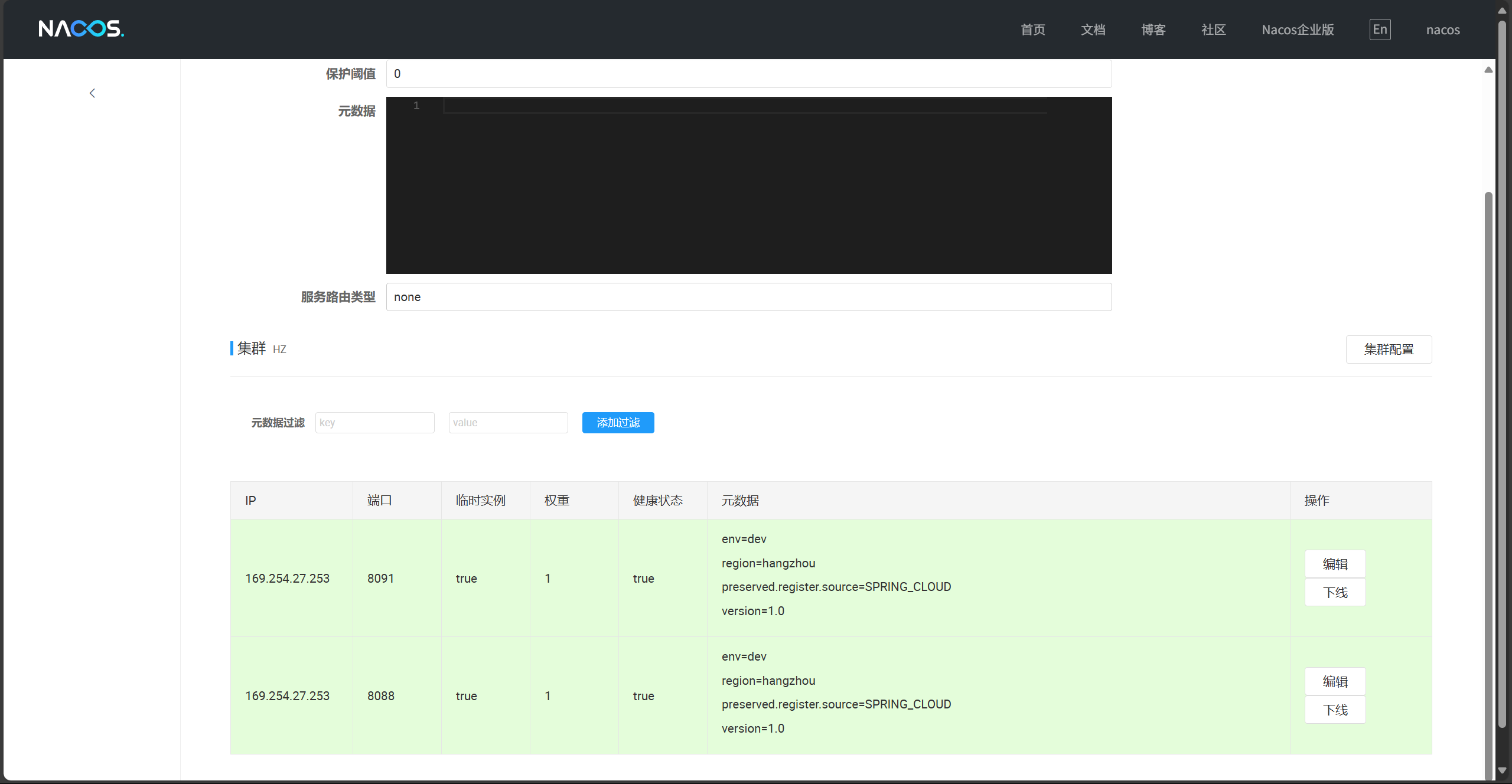
点击“详情”:可以看到集群和部署的实例
Nacos 负载均衡的原理详解
首先,Nacos 增加集群这一层是为了确保微服务间远程调用尽可能地在同一地域的集群中发生,避免跨集群的远程调用。这种调用情况必然涉及到一些全新的负载均衡的内容,我们来写一些东西测试 Nacos 默认的负载均衡策略
为每个端口的实例都写一个配置文件,实现两个实例在杭州,一个实例在沈阳的这种情况,方便验证,然后像这样修改
验证一下配置成功
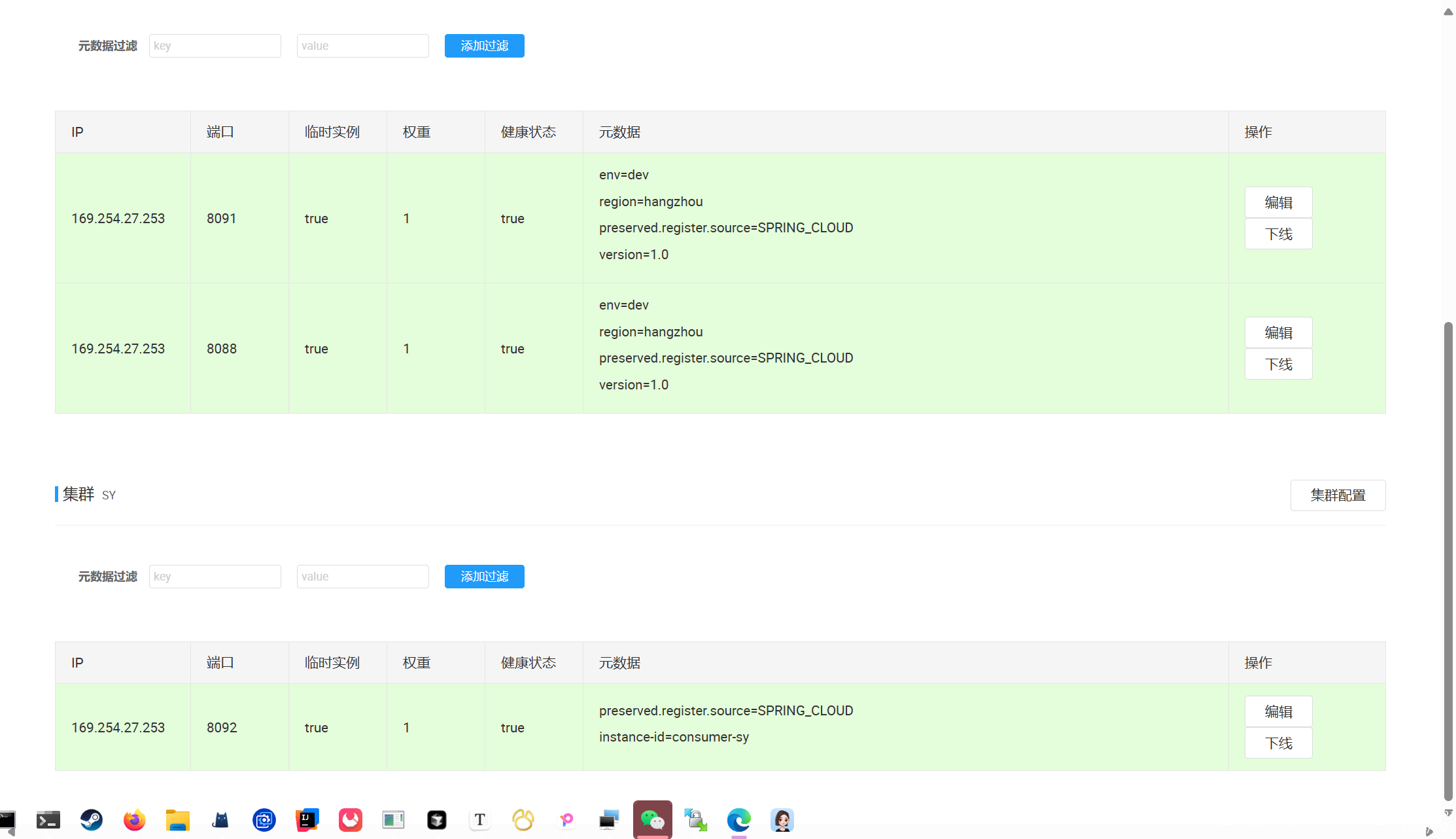
- 提供者实例:端口8087
- 消费者实例:
- 杭州集群:端口8088(权重1)和8089(权重2)
- 沈阳集群:端口8090(权重1)
我们修改了控制器,然后进行了服务提供端向消费端进行了十次调用
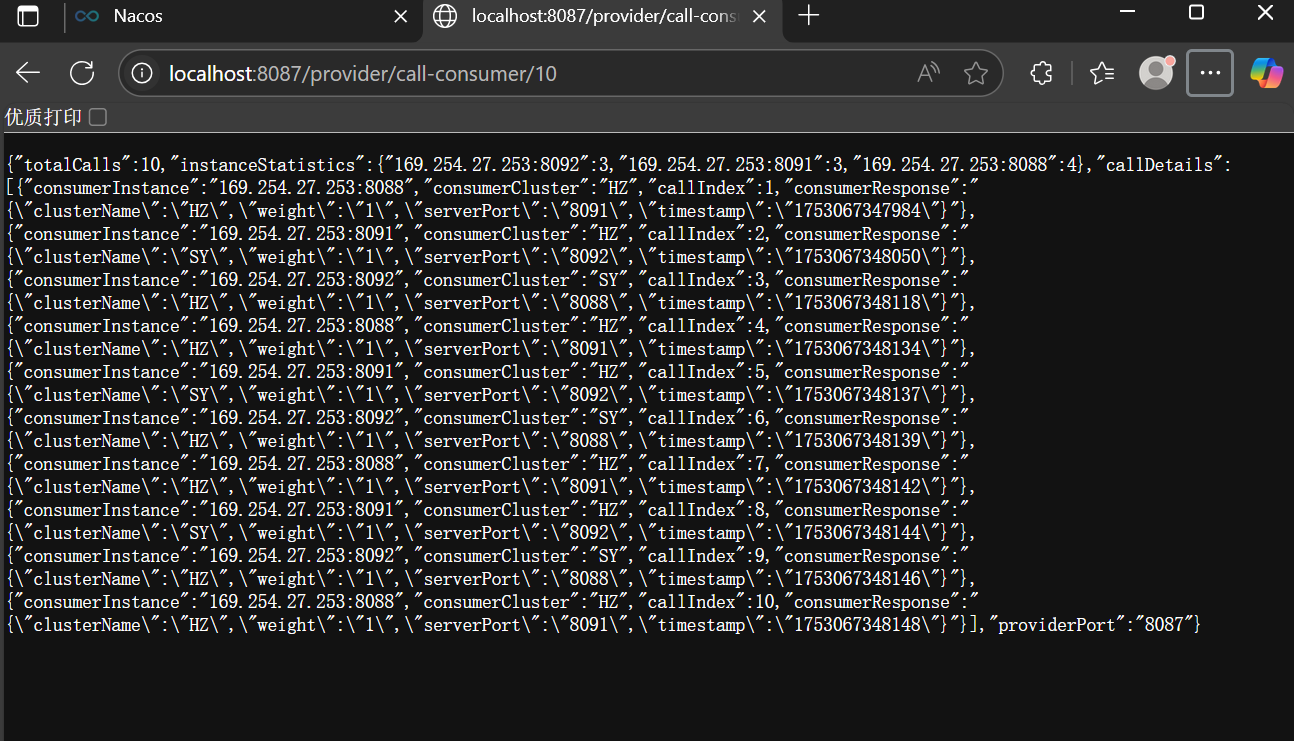
发现 Nacos 会以集群下先作为轮询,然后集群内采取轮询,有人说 Nacos 默认的不是权重随机策略吗,怎么会这样,其实在Spring Cloud Alibaba早期版本中,Nacos确实默认使用的是基于权重的随机负载均衡,但在Spring Cloud 2020版本后,默认使用的是Spring Cloud LoadBalancer,它的默认策略是RoundRobinLoadBalancer(轮询)
而我们常用的策略是权重随机策略,比 Ribbon 的要复杂一些,简单讲一下
- 权重设置:每个服务实例可以设置一个权重值(weight),这个权重值表示该实例在负载均衡中被选中的概率。权重值越大,被选中的概率就越高。在 Nacos 中,服务实例的权重可以通过 Nacos 控制台或者相关配置进行设置 。例如,有三个服务消费者端口实例 A、B、C,分别设置权重为 5、3、2,权重总和为 5 + 3 + 2 = 10。
- 随机选择:在进行负载均衡决策时,Nacos 首先会根据各个服务实例的权重,计算出每个实例被选中的概率范围。以上述例子为例,实例 A 的概率范围是 [0, 5),实例 B 的概率范围是 [5, 8),实例 C 的概率范围是 [8, 10) 。然后,Nacos 会生成一个 0 到权重总和之间的随机数,根据随机数落在哪个概率范围,来决定选择哪个服务实例。比如生成的随机数是 3,落在了实例 A 的概率范围内,那么这次调用就会选择实例 A 。
假设存在以下服务消费者实例及其权重配置:
| 服务消费者实例 IP | 端口 | 权重 |
|---|---|---|
| 169.254.27.53 | 8088 | 3 |
| 169.254.27.53 | 8091 | 2 |
| 169.254.27.53 | 8092 | 5 |
- 计算权重总和:3 + 2 + 5 = 10。
- 确定每个实例的概率范围:
- 实例(169.254.27.53:8088):[0, 3)
- 实例(169.254.27.53:8091):[3, 5)
- 实例(169.254.27.53:8092):[5, 10)
- 生成一个 0 到 10 之间的随机数,比如随机数是 7,落在了实例(169.254.27.53:8092)的概率范围内,那么此次请求就会被路由到该实例上。
要启用Nacos的权重随机负载均衡和集群亲和性,需要进行以下配置
1 | /** |
修改application.properties,添加配置
1 | # 添加以下配置 |
我们把其中一个实例的权重降低,来测试一下
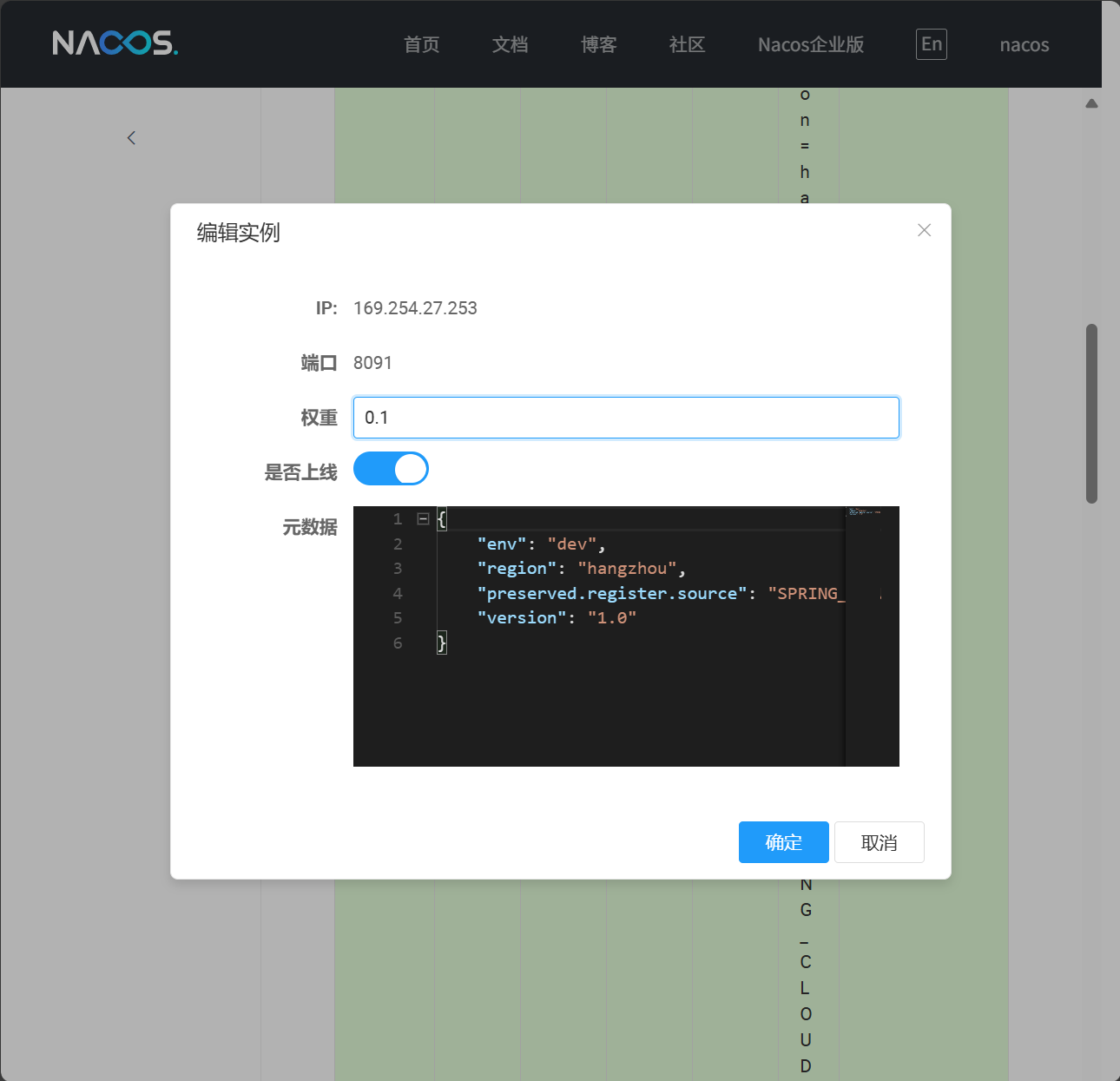
修改配置后,再次访问 http://localhost:8087/provider/call-consumer/25,观察结果:调整的太低了,没访问出来))
实际上,Nacos 作为服务注册中心时,本身并不直接提供负载均衡的核心实现,而是通过集成 Spring Cloud LoadBalancer 或 Ribbon 等组件来实现负载均衡功能。不过,Nacos 提供了服务发现能力,为负载均衡提供了服务列表数据支持。
Nacos 的负载均衡—NacosIRule 源码讲解
讲了如上内容,都是为了 Nacos 的负载均衡做准备,现在就开始讲解 Nacos 的负载均衡和它和 Ribbon 的联系与区别
Nacos 其实同样的使用的是 Ribbon 的规则,不过 Nacos
实现了自己的类。继承自 AbstractLoadBalancerRule
1 | import com.netflix.client.IClientConfigAware; |
这个类封装了对ILoadBalancer的管理(设置和获取),实现了两个接口:IRule和IClientConfigAware,表明它具备负载均衡规则和客户端配置感知的能力,这两个接口的内容之前在
Ribbon 时候详细讲过,没看的的可以去看,在这里只是简单说一下
1 | package com.netflix.loadbalancer; |
其中,`choose
方法就是负载均衡策略进行实例选择的方法接口,七种实现对应七种负载均衡的策略
还记得之前,我们从LoadBalancerInterceptor这个拦截器类,进入到其核心的
execute 方法,然后最后遭到
ReactorLoadBalancer这个负载均衡的控制器吗
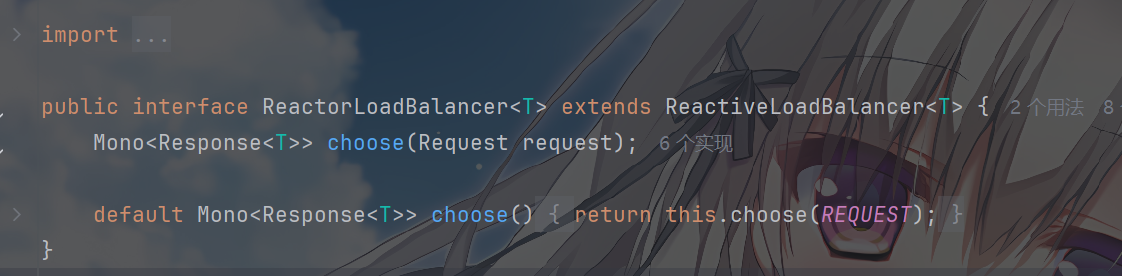
然后发现他有一个类
ReactorServiceInstanceLoadBalancer,会继承ReactorLoadBalancer,这就是负载均衡的实现组件的接口,规定从服务注册中心(如
Nacos、Eureka 等)获取可用的服务实例列表然后按照策略选择
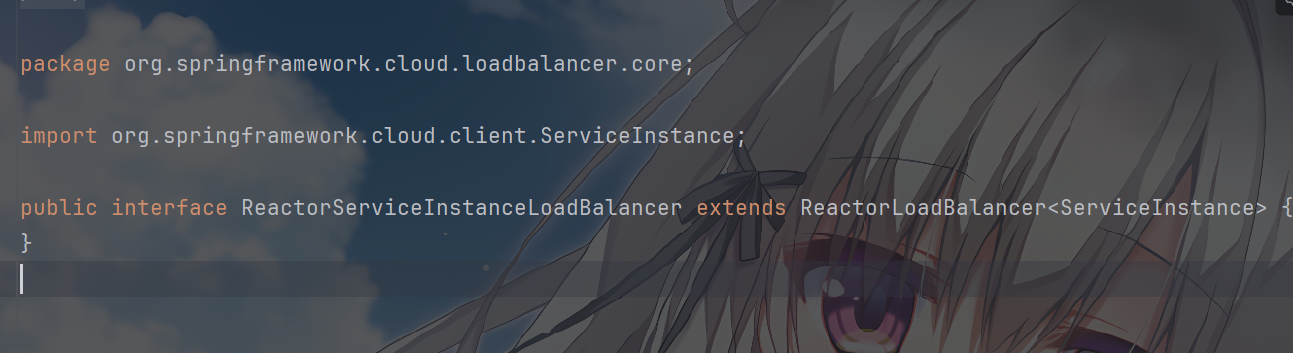
你再进入你就会发现,NacosLoadBalancer——Nacos
的负载均衡核心类,继承了这个,至此,一套从 Ribbon 和 Spring Cloud
LoadBalance 完美过渡实现到 Nacos 的继承和类体系大概就是差不多了,它基于
Nacos 服务发现的负载均衡器实现,集成了 Spring Cloud LoadBalancer 的
ReactorServiceInstanceLoadBalancer 接口
管这个类叫 Nacos 负载均衡器 吧,这个类挺长的,只说其中核心的原理
一些属性,说一下省的我和大伙总忘了什么是什么,其中的Nacos发现配置属性前面已经说过这个自动配置类了
1 | // 服务ID,标识当前负载均衡器对应的服务 |
其中有个挺好的东西,就是这个 IPV4 的正则,我自从发现了这个之后一直用的是这个))狠狠地偷
1 | // IPv4地址正则表达式,用于验证IP地址是否为IPv4格式 |
初始化方法就是构造 IPv6
的地址,然后根据IP类型过滤服务实例private List<ServiceInstance> filterInstanceByIpType(List<ServiceInstance> instances),支持IPv4/IPv6双栈,根据当前服务IP类型选择合适的实例,这种
Nacos 的特性不多说,知道就行
核心类在这里,这也就是为什么上面的测试会产生这样的情况
1 | /** |
- Nacos
的
getHostByRandomWeight3方法实现了基于权重的随机选择,权重可以在 Nacos 控制台配置,权重越高的实例被选中的概率越大,这种算法既保证了负载分散,又能根据实例性能差异进行流量调控 - 实现了 Spring Cloud LoadBalancer
的
ReactorServiceInstanceLoadBalancer接口,通过ServiceInstanceListSupplier获取服务实例列表,与 Spring Cloud 生态无缝衔接,使用响应式编程(Mono)提高异步处理能力,适合高并发场景
其中有个 NacosLoadBalancerClientConfiguration
自动配置类,是 Spring Cloud Alibaba Nacos
负载均衡组件的核心配置类,主要用于配置 Nacos 集成 Spring Cloud
LoadBalancer 所需的
Bean。`NacosDiscoveryProperties它被该配置以来。
它配置 Nacos
负载均衡器(NacosLoadBalancer),根据不同的服务发现模式(响应式
/
阻塞式)配置服务实例列表供应商,提供基于区域偏好的服务实例选择能力,其中,有个ReactiveSupportConfiguration是响应式服务发现配置,有个BlockingSupportConfiguration是阻塞式服务发现配置
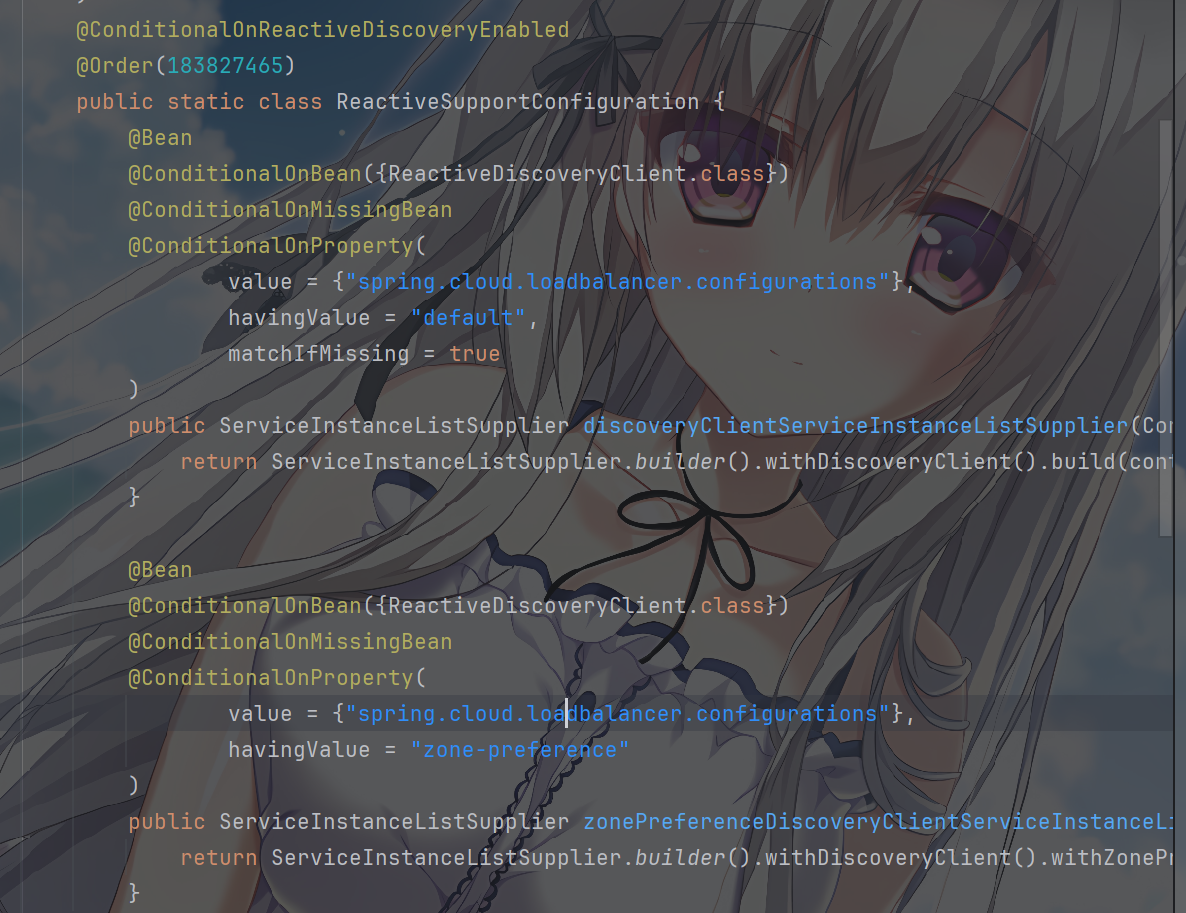
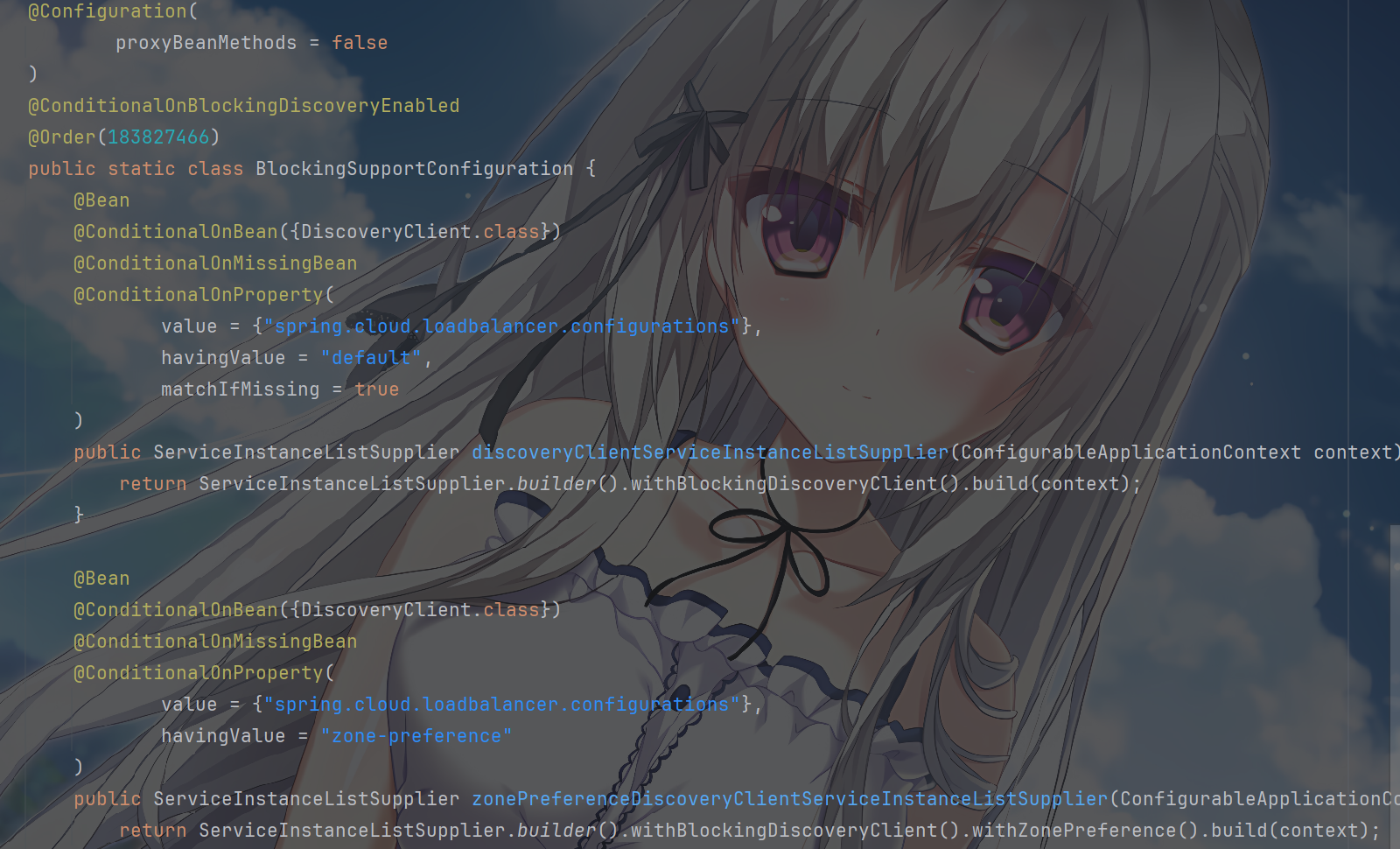
而 Nacos
在服务发现和服务调用等位置需要使用负载均衡的地方,都是通过如下,间接引入到NacosLoadBalancerClientConfiguration
并且进行自动配置,引入负载均衡的配置和相关实现
1 | this.nacosDiscoveryProperties = nacosDiscoveryProperties; |





