
Python的数据类型
- 数值(Numbers)
- 字符串(String)
- 元组(Tuple)
- 列表(List)
- 集合(Set)
- 字典(Dictionary)
- ……
- 其他数据类型
- 字节类型(Bytes):b’Hello’
- 字节数组(Byte Arrays): bytearray(b’Hello’)
- 空类型(None):没有返回的函数值
- 未执行的(NotImplemented):在运算时,对象不支持,返回该值
- 省略号(Ellipsis):用于Numpy的切片或者表示无限循环
Python数据类型-数值型
Python数值型介绍
- 整型(int):123
- 布尔型(bool):False(0)、True(1)
- 浮点型(float):123.04
- 复数型(complex):3 + 7j、real + imagj
复数的一些常见应用场景包括:
- 工程学:在电气工程中,复数用于分析交流电路,其中电压和电流随时间变化。复数使得可以轻松地处理电路中的电阻、电感、电容和它们的相位关系。
- 物理学:在量子力学中,波函数通常是复数。复数用于描述粒子的位置和动量等物理量。
- 数学:在纯数学中,复数用于解决不能在实数域内解决的问题,如在复平面上分析多项式方程的根。
- 信号处理:在数字信号处理中,复数用于表示频率和相位信息,以及进行傅里叶变换等操作。
- 计算机图形学:复数可以用于计算二维图形的旋转和平移。
其中的虚部j表示乘以根号下-1(即虚数单位),这意味着这个复数在复平面上距离原点3个单位向右(实部),4个单位向上(虚部)。
对象由identity、type和value标识
1 | a = |
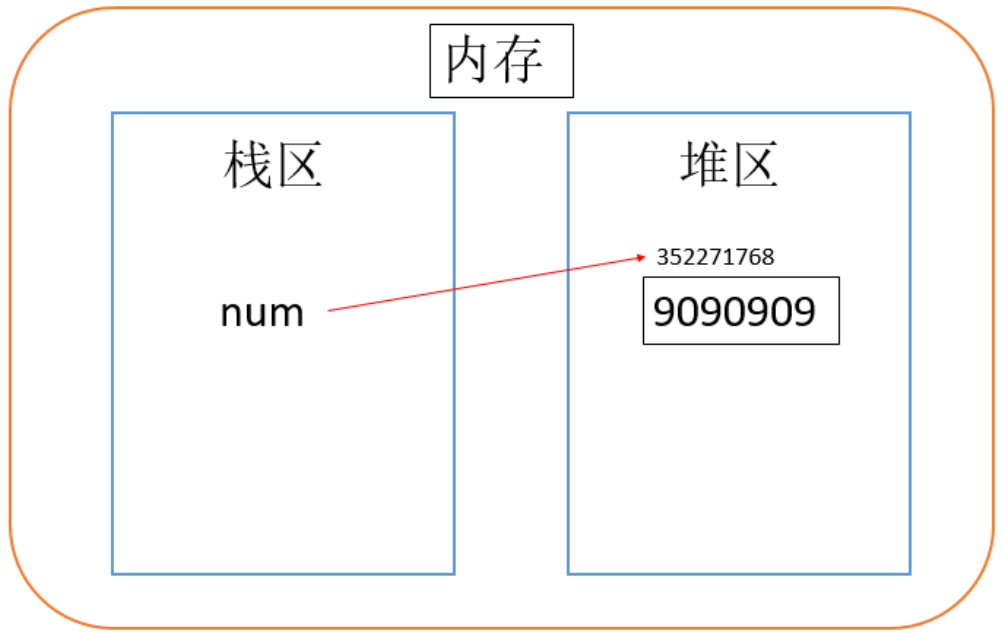
Python整数的存储
在内存中,变量存放到栈区,相对应的数据存放到常量区或堆区。
整型有一个“小整数池”(small integer pool)
- 这个区域是为了快速访问和存储小整数而设计的,它是一个固定的范围,用于缓存频繁使用的小整数。
- 整型的缓存区范围通常为[-5,256]
不同版本的python范围可能稍有不同
如果变量值是整数且不在“小整数池”的范围呢?如果是浮点型、布尔型或复数型呢?
新创建的变量和原来的id还会一样吗?
1 | x = 10 + 9j |
1 | def ppoi(): |
1 | def ppoi(): |
Python的交互模式下,一行一行执行代码
- 不会检查内存中是否存在相同的变量值,所以相同的变量值也可能会出现id值不同。
若在同一个代码块中
- 首先检查内存中是否存在当前变量值,若存在则直接指向;若不存在会重新分配空间。
总结:
- 常量区的数据范围为[-5,256],此区域内的数据有驻留机制
- 堆区的数据:在一个代码块中,数据的地址会暂时存储不被垃圾回收;不同代码块则会重新分配
类型转换函数 (类似构造函数)
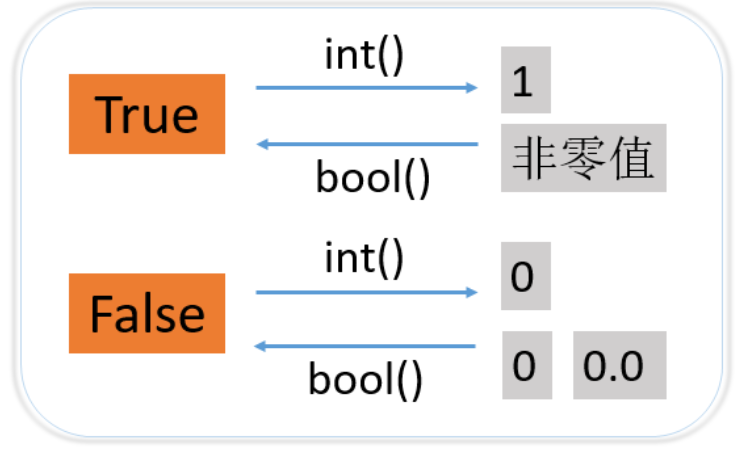
int() int()函数主要用于将一个值转换为整数
浮点数转换时,向下取整。
布尔值转换时,True对应1,False对应0。
复数只有当虚数部分为0时才能转换,例如3+0j。
参数为字符串时,字符串内容必须为整数值。
1
2
3
4
5
6
7
8
9
10f1 = float(120)
print(f1)
f2 = float(True)
print(f2)
f3 = float('120')
print(f3)
f4 = float('Infinity')#无穷大
print(f4)
f5 = float('NaN')
print(f5)
bool()
float()
complex()
1
2
3
4
5
6
7
8
9#布尔类型
b1 = bool(0) # 0和1
print(b1)
b2 = bool(98)# 'xyz123'
print(b2)
#复数类型
c1 = complex(3, 5)
print(c1)
一些问题
1.整型之间进行(加,减,乘,除,取余,幂次)运算,最后得到的是整型吗?
2.浮点型之间进行(加,减,乘,除,取余,幂次)运算,最后得到的是浮点型吗?
3.布尔型变量之间可以进行布尔运算,整型和浮点型变量之间可以吗?
4.复数型的实部和虚部具体是什么数据类型?
Python数据类型-字符串
Python字符串介绍
字符串是什么?
- 字符串是一种以Unicode编码的序列,是一种 有顺序 的 不可变 的序列。 Unicode 规范https://www.unicode.org/ 旨在罗列人类语言所用到的所有字符,并赋予每个字符唯一的编码。该规范一直在进行修订和更新,不断加入新的语种和符号。
字符串的创建
用单引号、双引号或三引号包围起来创建字符串。
- 单引号受限制的情况下,需要用双引号或三引号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#单引号受限制的情况,字符串中包含单引号
# str1 = 'He's a good boy.'
#改成双引号:
message = "He's a good boy."
print(message)
#改成三引号:三引号(''' 或 """)可以用来定义多行字符串,
# 也可以用来避免单引号和双引号的冲突
message = """He's a "good" boy."""
print(message)
#长字符串中间有换行的可以用三引号
word = '''Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.'''字符串中包含双引号则可以用单引号包围
如下情况必须使用三引号
- 字符串中既包含单引号又包含双引号时
- 作为文档字符串时
- 定义多行字符串时
1 | #1. 例如"It's my book."、 "hello'p'ython"、 "o'" |
用类型构造函数str()创建字符串
1
2
3
4
5
6#数值型转化为字符串
a = 123
print(a, type(a))
str6 = str(a)
print(str6, type(str6))
转义字符
- 以
\开头的字符叫转义字符,通过转义字符可以正确表示具有二义性的字符或无法显示的控制字符。 例如:It's my book.中的'既是普通字符又是标识字符串的符号。 - 在
'前加上\,可以使字符仅作为普通字符出现,避免二义性。
1 | #打印字符串"Let's go!" |
常用的转义字符:
\n(换行符)\t(Tab制表符)\r(回车)\'(单引号)\"(双引号)\\(反斜线)
PEP8规范建议:
为了增加代码的可读性,对于字符串内部的引号,尽量使用与内部不同的引号标识字符串,而不是使用转义字符。
如果不想让转义字符生效,怎么办?
1 | #在字符串前面加r或R |
字符串的索引和切片
1.通过索引获取字符串中的元素
- 正索引:元素位置(下标)从左往右从0开始,依次递增。
- 负索引:元素位置(下标)从右往左从-1开始,依次递减。

2.切片是一种高级索引
切片可以灵活获取字符串的多个元素
1 | #切片操作尝试 |
切片的定义:
切片是用于截取索引片段获得序列中元素的方法。
切片的表示形式:
sequence[start : end : step]
start→起始索引值,省略时代表索引值为0;
end→结束索引值(不包含在内),省略时代表索引值为end+1;
step→步长,两个相邻元素间的步长为1,步长为1时可省略。步长为负数时,反转序列。 step的两个重要功能:
- 跳过某些元素
- 反转序列
注意: 字符串是不可变的,不能用索引和切片给字符串重新赋值。
索引和切片总结:
- 索引只能获取单个元素,切片可以获取多个元素。
- 切片适用于所有序列,不仅仅是字符串。
- 字符串不可变,不能用索引或切片给字符串重新赋值。
字符串的拼接
- 用 + 拼接
- 用 * 拼接
- 格式化拼接 %
- 格式化拼接 format()
- 格式化拼接 f-string(Python 3.6及更高版本)
- join()方法
1 | #用+拼接两个字符串 |
format()更多用法:
print("My name is {1} and I am {0} years old.".format(age, name))#位置索引占位符print("My name is {name} and I am {age} years old.".format(name=name, age=age))#指定变量名print("The value of pi is approximately {:.2f}.".format(num))#格式化数字: {:,}千位符
join()的语法格式:
1 | str.join(iterable) |
其中str是分隔符,用于连接iterable中的元素。
1 | str.join(iterable) |
总结:
- +拼接方法,常用于字符串变量之间的相加。
- 格式化拼接方法,代码具有可读性和可维护性。
- join()方法,适用于拼接的字符串较多时。
成员关系操作符(in、not in)
- 成员关系运算符用来判断一个字符串是否包含在另一个字符串中。
1 | v_str = 'water.tif, app.jpg, wechat.png, google.gif, football.jfif' |
字符串对象的常用方法
- 字符串类型判断
1 | s.isnumeric() #是否只包含数字字符 |
- 字符串大小写转换
1 | s.lower() #转为小写 |
- 字符串拆分、组合及去空格
1 | split(sep=None, maxsplit=-1) #按sep(默认为空格)分割字符串,maxsplit是分割的最大次数,返回列表。 |
1 | # 函数接收一个任意字符串s,要求删除两侧的空白字符,把字符串中连续多个空格替换为1个空格,返回处理后的新字符串。例如,s为'a bb c '时返回'a bb c'。 |
- 字符串的查找和替换
1 | s.find() #查找指定字符串n,返回n的起始下标,没有则返回-1 |
1 | # 函数接收一个表示日期时间的字符串s,格式为'2020-02-18 22:02:22',要求删除每一部分的前导0,返回格式为'2020-2-18 22:2:22'的字符串。不能导入任何模块,注意年月日和时分秒之间有且只有一个空格。 |
Python的数据类型之元组
- 元组是一种有序的、不可变的序列。
- 元组的创建方法:
- 显式的直接创建
- 使用类型构造函数创建
1. 显式的直接创建元组
- 使用
()包围数据创建元组,各元素之间用逗号隔开。
1 | # 使用 () 创建一个空元组 |
元组的两种特殊表示情况:
- 元组只有一个元素的时候,不能省略逗号
- 元组也可以没有圆括号包围
1 | # 元组元素只有一个时 |
没有原括号包围也可以创建元组(PEP8不推荐此方法,代码可读性较低)
1 | # 没有圆括号包围 |
2. 使用类型构造函数创建
- 使用类型构造函数
tuple()将其他可迭代对象转换成元组类型。
1 | tuple(可迭代对象) |
可迭代对象
- 实现了__iter__()方法
- 是指可以在循环中逐一返回其元素的对象
目前学到的可迭代对象:字符串、元组。
判断一个对象是不是可迭代对象,可以用isinstance()函数,此函数的作用是类型检查。
1 | isinstance(判断对象, collections.abc.Iterable) |
Iterable类型存在于collections.abc模块中
1 | # 定义一些测试对象 |
元组的序列操作
元组的序列操作
- 索引访问
1 | tp1 = (1, 3, 5, 7, 9, 11, 13) |
- 切片操作
1 | tp1[2:5] #5,7,9 |
- 连接
1 | tp2 = ('a', 'b', 'c', 'd') |
- 重复操作
1 | tp2 * 2 |
- 成员关系操作
1 | 2 in tp1 |
- 比较运算操作(==、!=、>、>=、<、<=)
1 | tp1 == tp2 |
元组解包
- 将元组赋值给多个变量,这个过程被称作元组解包
1 | a, b, c = ('1s', '2s', '3s') |
python数据类型之列表
- 列表是一种有序的、可变的序列。
- 创建方法:
- 显式的直接创建
- 使用类型构造函数
显式的直接创建
使用方括号(
[])创建列表,各元素之间用逗号隔开。1
2
3
4
5
6
7
8
9
10# 创建一个空列表
empty_list = []
#非空列表,元素可以是任意类型
# 创建一个包含整数的列表
list_of_integers = [1, 2, 3, 4, 5]
# 创建一个包含字符串的列表
list_of_strings = ["apple", "banana", "cherry"]
# 创建一个包含不同数据类型的列表
mixed_list = [1, "hello", 3.14, True]
列表的元素:
- 列表的元素可以是不同类型(包括列表)
- 列表中具有相同值的元素允许出现多次
使用类型构造函数创建
- 使用类型构造函数
list()将其他可迭代对象转换成列表类型。
list(可迭代对象)
1 | # 从字符串创建字符列表 |
用切片和索引修改列表的值
1 | ls0 = [1, 2, 3, 4, 5, 6] |
- 字符串和元组不能改变切片的值,因为字符串和元组都是不可变的。列表是可变数据,所以可以通过更新切片,改变列表元素的值。
index 方法会返回元素第一次出现的下标
1 | # 查找列表中某元素的下标 |
列表的添加和拼接
- ls.append()
- ls.extend(iterable)
- ls.insert(index, object)
+和+=
1 | #append() |
1 | # 函数main(lst)接收包含若干正整数的列表lst,要求返回所有奇数下标元素之和与所有偶数下标元素之和组成的元组,例如lst为[1234,5,13,65]时返回(70,1247)。 |
列表的移除和删除
- ls.pop()
- ls.remove()
- ls.clear()
- 关键字del
1 | #pop:按照下标进行移除 |
列表的排序
- 使用列表对象方法
sort()对原列表进行排序,改变原列表 - 使用内置的排序函数
sorted()返回排好序的列表副本,原列表不变(也可用于元组和字典) - 这两种方式默认的排序都是升序的
1 | #降序的参数 |
1 | # 现有一个列表 |
到目前为止,我们学到的可变的数据类型只有列表,接下来我们从列表内存角度来理解列表的可变性。
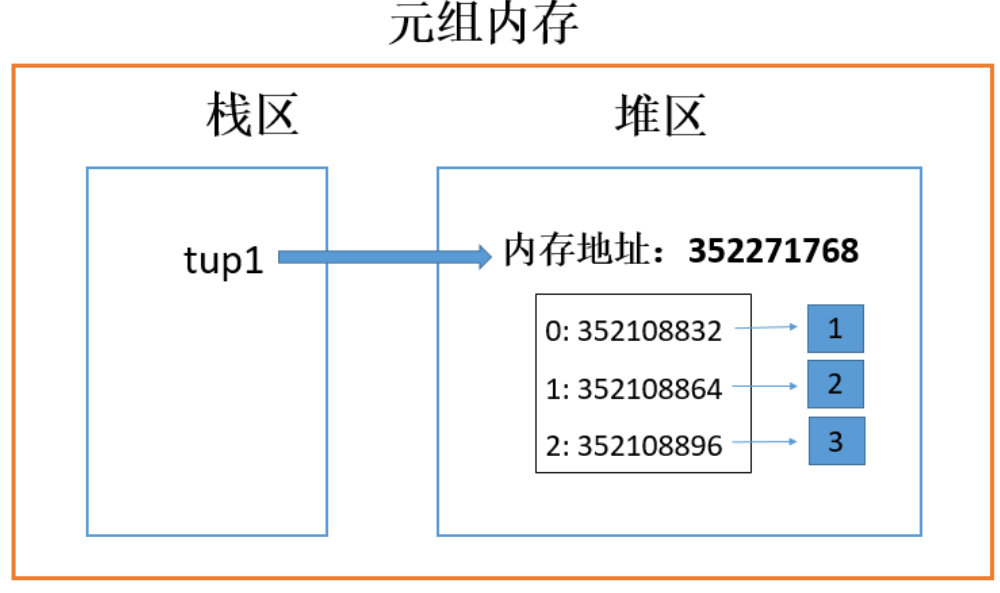
1 | list1 = [1, 2, 3, 4, 5, 6] |

总结:
- 列表是可变序列,修改原列表的数据时,整个列表的id值不发生改变。
- 一旦有新的列表产生,就会开辟新的内存地址,即使和原列表一模一样也会开辟新空间。
Python数据类型之集合
- 集合是一个无序的、不重复的元素集。
- 创建方法:1.显式的直接创建 2.使用类型构造函数
显式的直接创建
- 使用大括号
{}创建,各元素之间用逗号隔开。
1 | #创建空集合 |
用{}不能创建空集合,{} 是Python中字典的语法,用于定义键值对。如果{}是空的,Python会默认它是一个空字典,而不是空集合。
1 | #错误创建非空集合 |
用花括号创建的集合,其元素只能是可哈希的元素。
可哈希对象(bool、int、float、complex、str、tuple、frozenset等)
不可哈希的对象(list、set、dict)
注意:也不能含有不可哈希对象
使用类型构造函数创建
- 使用类型构造函数
set()或frozenset()将其他类型转换成列表类型。 set()和frozenset()的参数需要满足:是可迭代对象,并且该可迭代对象中都是可哈希对象。
目前学到的可迭代对象:字符串、元组、列表、集合。
- 创建空集合只能使用
set()或frozenset() - set() 是可变的,你可以对它进行添加、删除等操作。
- frozenset() 是不可变的,一旦创建,不能修改。
1 | # 用set()创建空集合 |
总结:
- 集合的创建方法有两种,一种是用
{}创建,另一种是set()或frozenset()函数创建,其中frozenset()是不可变的集合。 set()和frozenset()的参数必须是可迭代对象,且该对象中元素必须为可哈希对象。
集合添加元素
- set.add() ——添加单个元素
- set.update() ——可添加多个元素
1 | a = {1, 2, 3} |
集合删除元素
- set.remove() ——一次只能删除一个元素,若删除的元素不存在则会报错
- set.discard() ——一次只能删除一个元素,若删除的元素不存在不报错
- set.pop() ——默认删除第一个元素
- set.clear() ——清空集合元素
1 | #1.remove一次只能删除一个元素,删除的元素不存在则会报错 |
集合类型操作符(用于可变集合和不可变集合)
- 集合等价/不等价:
==、!=(只要它们包含相同的元素,比较就会返回 True) - 子集/超集判定:
<、<=、>、>=
- #1.集合的等价、不等价
1 | set('book') == frozenset('book') |
集合的数学操作
- 交集 “&” “set1.intersection(set2)”
- 并集 “|” “set1.union(set2)”
- 差集 “-” “set1.difference(set2)”
- 对称差集 “^” “set1.symmetric_difference(set2)”
1 | s = set('abcde') |
其他的集合常用方法:
- s.issubset(t) # 如果s是t的子集,返回True
- s.issuperset(t) # 如果s是t的超集,返回True
1 | #如果集合 A 中的所有元素都在集合 B 中,那么集合 A 被称为集合 B 的子集。 |
Python数据类型之字典
- 是一种以键值对为元素的无序组合,键和值之间用冒号隔开,字典元素之间以逗号隔开。
- 创建方法:
- 显式的直接创建
- 使用类型构造函数
字典是Python中一种映射数据结构,映射是根据键(key)查找其映射值(value)的过程。
- 字典中的键(key)必须是可哈希对象
- 可哈希对象:bool、int、float、complex、str、tuple、frozenset
显式的直接创建
- 使用花括号
{}创建字典,各元素之间用逗号隔开。
1 | #1. 创建一个空字典,使用 dict() 函数创建空字典 |
字典中键的规则
- 不允许一个键对应多个值
- 键必须是可哈希的(列表、字典这样的可变类型是不可哈希的,所以不能作为键)
- 所有不可变类型都是可哈希的(不可包含可变元素),都可以作为字典的键,但字典中的键通常是字符串
- dict(元组)、dict(列表)里面的元素必须为序列,且子序列中元素顺序要满足键值对的顺序。
Python中的不可变数据类型默认是可哈希的,包括:
整数(int)
浮点数(float)
布尔值(bool)
字符串(str)
元组(tuple)(注意,元组中的所有元素也必须是可哈希的)
冰冻集合(frozenset)(冰冻集合本身是可哈希的,但它是不可变的集合类型)
相反,以下数据类型是不可哈希的,因此不能用作字典的键或添加到字典中:
- 列表(list)
- 集合(set)
- 字典(dict)
类型构造函数dict()创建字典
- dict(键=值)
- dict(元组)
- dict(列表)
1 | dict_0 = {'one': 1, 'two': 2, 'three': 3} |
使用fromkeys() 创建字典
1 | dict.fromkeys(iterable, value) |
- 用一个可迭代对象作为字典的键
- 第二个参数用来设置字典每个键值对的值,如果忽略的话值默认为
None
1 | dict7 = {}.fromkeys(('x', 'y'), 1) # 给所有key一个默认值 |
1 | # 现有一个列表list_1,要求把list_1的重复元素去掉,返回一个新列表list_2,新列表中的元素保持在原列表中首次出现的相对顺序。不要使用循环和推导式。 |
字典元素的增加和修改
- 字典变量名[key] = value
如果key不存在则为字典增加一项,如果key存在则修改对应的value值。
1 | #元素增加 |
删除指定key对应的value
- del 字典变量名[key]
1 | del dic["name"] |
字典的查询
- 根据键名查询
- 查询所有的键名
- 查询所有键的值
- 查询所有键值对
1 | # 1.根据键名查询 |
函数接收一个任意字符串s,要求返回其中只出现了1次的字符组成的新字符串,每个字符保持原来的相对顺序。例如,s为’Beautiful is better than ugly.’时返回’Bfsbrhngy.’
1 | def unique_chars(s): |




