
结构化查询语言SQL
关系数据模型
关系模型三要素:
- 关系数据结构
- 完整性约束
- 关系操作
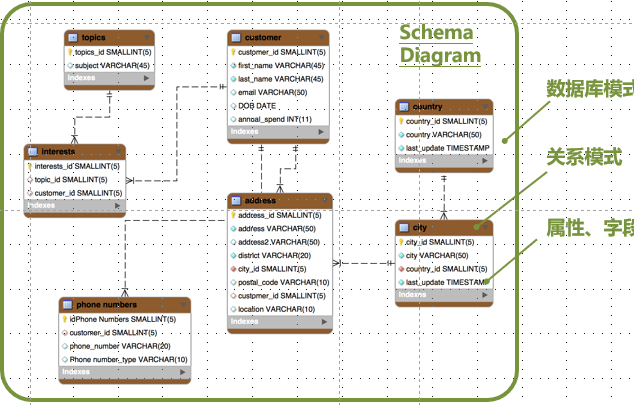
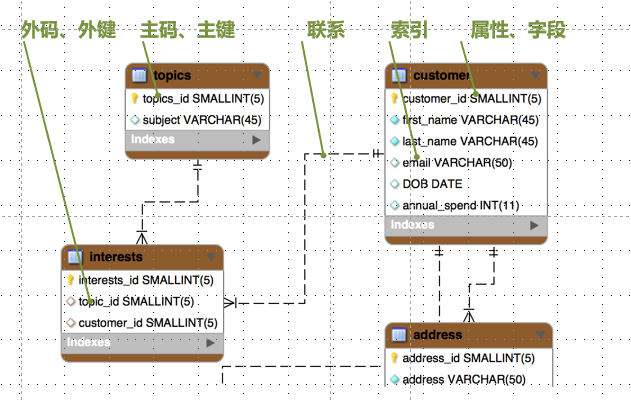
码:关系中某些属性集合具有区分不同元组的作用,称为码
- 超码:如果关系的某一组属性的值能唯一标识每个元组,则称该组属性为超码(super key)。
- 候选码:如果一个超码的任意真子集都不是超码,则称该超码为候选码。候选码是极小的超码。
- 主键:每个关系都有至少一个候选码,人为指定其中一个作为主键
- 外码:设 F 是关系 R 的属性子集。若 F 与关系 S 的主键 K 相对应,则称 F 是 R 的外键(foreign key)。
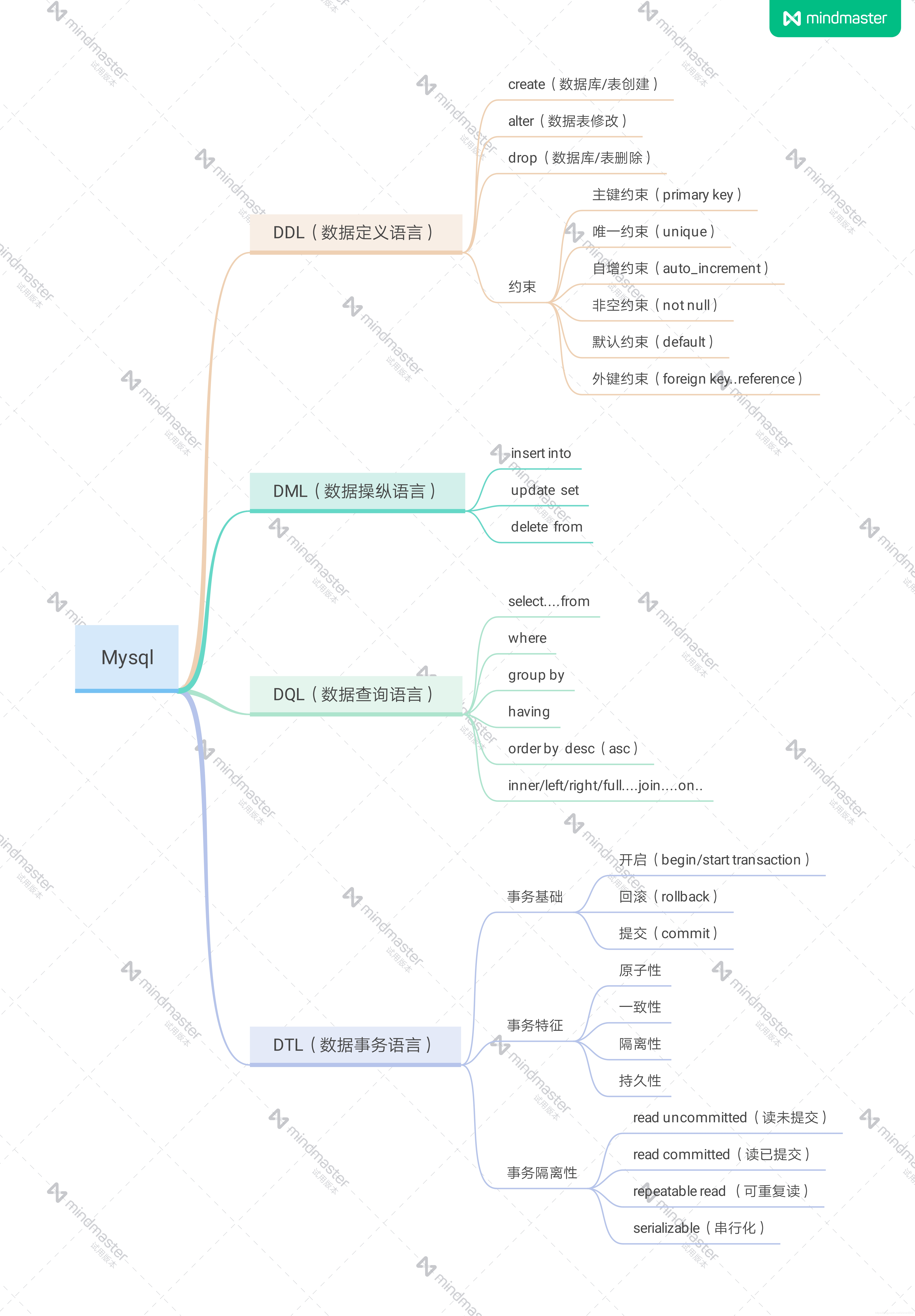
SQL分类
DDL:数据定义语言 定义了不同的数据库,表,视图,索引等数据库对象 还可以创建修改删除等操作数据库表的结构 CREATE ALTER DROP RENAME TRUMCATE
DML:数据操作语言 增删改查数据库记录 INSERT DELETE UPDATE SELECT
DCL:数据控制语言 定义数据库,表,字段,用户访问权限和安全级别的 COMMIT ROLLBACK SAVEPOINT
DQL:数据库查询语言 查询数据库中表的记录
DTL:数据库事务语言
SQL基本语法
SQL以分号结尾,可以用空格和缩进,windows不区分大小写,linux下大小写敏感,建议关键字大写
注释 –单行注释– # 单行注释
/* 多行注释*/
字符串类型和日期类型的数据可以用 ’’ 表示
列的别名,使用双引号 ”“ 不建议省略as
书写规范:
数据库名,表名,表别名,字段名,字段别名等小写
SQL关键字,函数名,绑定变量等大写
不能以SQL关键字来命名,如果要用,需要加上‘’着重号标记
DDL-数据定义语言
数据定义语言 定义了不同的数据库,表,视图,索引等数据库对象 还可以创建修改删除等操作数据库表的结构
DDL-数据库操作
查询
1
SHOW DATABASES;
查询当前数据库
1
SELECT DATABASE{};
创建
1
CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 指定使用的字符集] [COLLATE 指定排序规则];
删除
1
DROP DATABASE [IF EXISTS] 数据库名;
使用
1
USE 数据库名;
修改数据库
1
ALTER DATABASE 数据库名 修改部分;
表操作
DDL-表操作-查询
查询当前数据库所有表
1
SHOW TABLES
查询表结构
DESCRIBE 表名;简写如下1
DESC 表名;
SHOW CREATE TABLE语句会返回创建表时所用的 SQL 语句查询指定表的建表语句
1
SHOW CREATE TABLE 表名;
DDL-表操作-创建
1 | CREATE TABLE 表名{ |
快速复制表结构
1 | -- 只复制结构不复制数据 |
DDL-表操作-修改
1 | ALTER TABLE 表名 ADD|DROP|MODIFY|CHANGE 字段名 类型 (长度) [COMMENT 注释] [约束]; |
添加字段
1
ALTER TABLE 表名 ADD 字段名 类型 (长度) [COMMENT 注释] [约束];
案例:
emp表添加一个新的字段 昵称为 nickname 类型 varchar(20)
1
ALTER TABLE emp ADD nickname VARCHAR(20) COMMENT "昵称";
修改数据类型
1
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
修改字段名和字段类型
1
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
删除字段
1
ALTER TABLE 表名 DROP 字段名;
修改表名
1
ALTER TABLE 表名 RENAME TO 新表名;
DDL-表操作-删除
删除表
1
DROP TABLE [IF EXIST] 表名;
删除指定表,并重新创建
1
TRUNCATE TABLE 表名;
DML-数据操作语言
数据操作语言 增删改查数据库记录
- 添加数据 INSERT
- 修改数据 UPDATE
- 删除数据 DELETE
DML-插入
给指定的字段添加数据
1
INSERT INTO (字段名1,字段名2) VALUES (值1,值2。。)
给全部字段添加数据
1
INSERT INTO 表名 VALUES (值1,值2。。)
批量添加数据
1
2
3INSERT INTO 表名 (字段名1,字段名2。。。) VALUES (值1,值2...) (值1,值2...) (值1,值2...);
INSERT INTO 表名 VALUES (值1,值2...) (值1,值2...) (值1,值2...);
注意:
- 插入数据时,指定的字段顺序需要与值的顺序一一对应
- 字符串和日期的数据类型都应该包含在引号中
- 插入的数据大小,应该在这个字段的范围内
DML-修改
修改数据表中的字段值:
1 | UPDATE 表名 SET 字段名1=值1,字段名2=值2..... [WHERE 条件]; |
- 修改语句的条件可以有,如果没有就是针对整张表
DML-删除
删除数据表中的数据
1 | DELETE FROM 表名 [WHERE 条件]; |
DELETE的条件可以有,如果没有,就是删除整张表的数据
DELETE不能删除某一个字段的值,可以用UPDATE
DQL-数据查询语言
数据查询语言,查询数据库中表的记录
- 关键字 SELECT
DQL 语法
1 | SELECT |
DQL-基础查询
1 | SELECT |
查询多个字段
1 | SELECT 字段1,子段2。。。 FROM 表名; |
整表查询
1 | SELECT * FROM 表名; |
设置别名
1 | SELECT 字段1 [AS 别名1],字段2 [AS 别名2] ... FROM 表名; |
- as 列的别名可以用一对“”引起来
去除重复记录
1 | SELECT DISTINCT 字段列表 FROM 表名; |
查询常数
查询常数指的是在查询结果里返回固定值,而非从表字段获取数据
1 | SELECT '这是一个常数' AS constant_value; |
假定有一个 employees 表,包含 id 和
name 字段,你能够在查询结果里既显示表数据,又显示常数。
1 | SELECT id, name, '固定部门' AS department FROM employeses; |
此查询会返回 employees 表中的 id 和
name 字段,同时为每一行添加一个名为 department
的列,其值均为 固定部门。
DQL-条件查询
基本语句
1 | SELECT 字段列表 FROM 表名 WHERE 条件列表; |
比较运算符
等于(=)
不等于(<> 或!=)
大于(>)
小于(<)
大于等于(>=)
小于等于(<=)
BETWEEN…AND某个范围内 (BETWEEN之后跟最小值 AND之后跟着最大值)
IN 在IN之后的列表中的值,多选一
LIKE 模糊匹配(_匹配单个字符,%匹配多个字符)
1 | -- 查询名字包含"张"的员工 |
IS NULL (NULL)
1 | -- 查询奖金为NULL的员工 |
逻辑运算符
AND 或 && 与
OR 或 || 或
NOT 或 ! 非
1 | -- 查询年龄 |
DQL-聚合函数
聚合函数:一列数据作为一个整体,纵向计算
常见聚合函数:
count 统计数量
max 最大值
min 最小值
avg 平均值
sum 求和
聚合函数都是作用与表的某一列
1 | SELECT 聚合函数(字段列表) FROM 表名; |
null不参与聚合函数的计算
空值参与运算,结果一定为空
1 | -- 查询总数据 |
DQL-分组查询
关键字:GROUP BY
语句:
1 | SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件]; |
where与having区别
执行实际不同:where是分组前进行过滤,不满足where条件不参与分组;HAVING是分组后对结果过滤
判断条件不同:WHERE不能对聚合函数判断,HAVING可以
执行顺序 where > 聚合函数 > having
分组之后,查询的字段一般为聚合函数和分组字段,其他字段无意义
1 | SELECT name,gender,COUNT(*) FROM employee GROUP BY gender; |
1 | -- 根据性别分组统计男女员工数量 |
DQL-排序查询
1 | SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2...; |
支持多字段排序
如果是多字段排序,当第一个字段值相同时候会按照第二个这样依次
排序方式
- ASC 升序 默认
- DESC 降序
1 | -- 排序查询 |
DQL-分页查询
1 | SELECT 字段列表 FROM 表名 LIMIT 起始索引, 每页记录数; |
注意:
起始索引从0开始,起始索引 = (查询页码-1)*每页显示记录数
分页查询是数据库的方言,不同的数据库之间不同,
mysql中是LIMIT如果查询的第一页数据,起始索引可以省略,直接简写
DQL-执行顺序
编写顺序
1 | SELECT |
执行顺序
- FROM 决定我要查询那一张表
- WHERE 指定查询的条件
- GROUP BY 和 HAVING 指定分组
- SELECT 字段列表
- ORDER BY 指定排序
- LIMIT 指定分页
DCL-数据控制语言
主要用来管理数据库的用户,控制数据库的访问权限
DCL–管理用户
本质上是对user表的修改
主机名可以用%通配
查询用户
1 | USE mysql; |
- 主机地址和用户名才能定位一个用户,本质上是查询user表
创建用户
1 | CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY '密码'; |
CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
修改用户密码
1 | ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码'; |
删除用户
1 | DROP USER ‘用户名’@‘主机名’; |
DCL-权限控制
MySQL中定义了多种权限,常用的就这些
ALL, ALL PRIVILEGES 所有权限
SELECT 查询数据
INSERT 插入数据
UPDATE 修改数据
DELETE 删除数据
ALTER 修改表
DROP 删除数据库/表/视图
CREATE 创建数据库/表
查询权限
1 | SHOW GRANTS FOR '用户名'@'主机名'; |
授予权限
1 | GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; |
撤销权限
1 | REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'; |
注意:
- 多个权限之间,使用逗号分隔
- 授权时,数据库名和表名可以使用*进行通配,代表所有
多表查询
多表关系
一对多(多对一) 多的一方建立外键,指向一的一方的主键
多对多 建立第三张表,中间表至少包含两个外键,分别关联两方主键
一对一 拆分表
在任意一方加入外键,管理另外一方的主键,并且设置为UNIQUE
内连接
查询表1,表2 交集部分数据
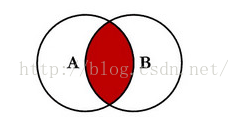
这种场景下得到的是满足某一条件的A,B内部的数据;正因为得到的是内部共有数据,所以连接方式称为内连接。
隐式内连接
1 | SELECT 字段列表 FROM 表1,表2 WHERE 筛选条件; |
显式内连接
1 | SELECT 字段列表 FROM 表1 INNER JOIN 表2 ON 连接条件; |
示例:
1 | -- 题目 1:查询每个用户的角色ID列表 |
外连接

左右外连接
左外连接
左外连接查询左表所有数据,以及两张表交集部分数据
左外连接相当于查询表A(左表)的所有数据和中间绿色的交集部分的数据。
表1的位置为左表,表2的位置为右表
1 | SELECT 字段列表 |
右外连接
右外连接查询左表所有数据,以及两张表交集部分数据
右外连接相当于查询表B(右表)的所有数据和中间绿色的交集部分的数据。
表1的位置为左表,表2的位置为右表
1 | SELECT 字段列表 |
自连接
自连接是指将一张表与自身进行连接操作。通常用于处理表中存在层级关系或递归关系的数据。
在自连接中,我们需要为同一张表创建两个别名(如 p1 和
p2),然后通过某种条件将这两个别名关联起来。
自连接表一定要起别名
对于自连接查询,可以是内连接查询,也可以是外连接查询。
连接条件通常是父子关系字段
1 | SELECT 字段列表 |
示例:
1 | -- permission_id:权限的唯一标识。 parent_permission_id:当前权限的父权限 ID。 |
连接条件:对于 p1 中的每个权限(父权限),查找
p2 中所有 parent_permission_id 等于该权限 ID
的记录(子权限)
- 使用
INNER JOIN时,只会返回有子权限的父权限。 - 使用
LEFT JOIN时,会返回所有父权限,即使它们没有子权限。
1 | -- 查询员工及其直接上级 |
联合查询
union查询,就是把多次查询的结果合并,形成一个新的查询结果
1 | SELECT 字段列表 FROM 表A |
联合查询的多张表列数必须保持一致,字段类型也需要保持一致
union all会将全部的数据合并,union会对合并后的数据去重
子查询
子查询是指嵌套在另一个 SQL 语句中的 SELECT 查询。
它可以出现在 WHERE、FROM、SELECT 等子句中,用于提供额外的数据过滤或计算条件。
子查询必须用括号 () 包裹
NULL 值处理:子查询返回 NULL 可能导致意外结果,需用
IS NULL 或 COALESCE 处理
1 | SELECT * FROM 表1 WHERE 字段列表1 = (SELECT 字段列表 FROM 表2) |
- 子查询外部的语句可以是INSERT UPDATE DELETE SELECT中的任意一个
- 标量子查询:子查询结果为单个值
- 列字查询:子查询结果为一列
- 行子查询:子查询结果为一行
- 表子查询:子查询结果为多行多列
根据子查询位置,分为WHRER之后,FROM之后,SELECT之后
标量子查询
- 特点:返回单个值(一行一列)
- 常见场景:作为条件判断、赋值或计算的一部分
示例:查询工资高于平均工资的员工
1 | SELECT emp_name, salary |
- 子查询
(SELECT AVG(salary) FROM employees)返回一个标量值(平均工资) - 主查询通过
>比较每个员工的工资与平均值
列子查询(Column Subquery)
- 特点:返回一列多行的数据
- 常用操作符:
IN,NOT IN,ANY,ALL
示例:查询所有部门经理的员工信息
1 | SELECT * |
行子查询(Row Subquery)
- 特点:返回一行多列的数据
- 常用操作符:
=,<>,ALL
示例:查询与某个员工(ID=1001)部门和职位都相同的其他员工
1 | SELECT * |
- 子查询返回
emp_id=1001的员工的部门和职位信息 - 主查询使用行比较
(col1, col2) = (val1, val2)匹配条件
表子查询(Table Subquery)
- 特点:返回多行多列的数据(类似临时表)
- 常用位置:FROM 子句中,需使用别名
示例:查询每个部门的平均工资,并按降序排列
1 | SELECT dept_name, avg_salary |
- 子查询计算每个部门的平均工资
- 主查询将子查询结果(临时表
t)与部门表连接,获取部门名称
子查询中 EXISTS
EXISTS:子查询是否返回任何行。如果子查询返回至少一行,则EXISTS条件为真,外层查询将根据这个结果进行相应的操作。
EXISTS只关心子查询是否有结果返回,而不关心返回的具体内容
1 | SELECT columns |
1 | -- 查询有下属的员工 |
子查询与连接(JOIN)的对比
子查询和连接都可以实现多表数据关联,但适用场景不同:
| 子查询 | 连接(JOIN) |
|---|---|
| 适合单值条件过滤 | 适合多表数据关联展示 |
| 逻辑上更直观(分步处理) | 性能通常更高(优化器优化) |
| 可能导致多次执行子查询 | 通常一次性扫描所有表 |
示例对比:查询每个部门的经理姓名(子查询 vs JOIN)
1 | -- 子查询 |




