
JUC 并发工具包介绍
JUC 并发工具包介绍
JUC 是 java.util.concurrent 包的简称,从 Java 5 开始引入,专门用于解决并发编程中的线程同步、线程池、锁机制、并发集合等问题,是 Java 处理高并发场景的核心工具包。
它弥补了传统 synchronized 关键字、Thread 类的局限性,提供了更高效、更灵活的并发编程方案。
JUC 的设计:
- 分离锁与同步机制:将锁(Lock)、条件(Condition)、原子操作(Atomic)、并发容器等组件解耦,按需使用;
- CAS 无锁优化:基于 CPU 原语的 CAS(Compare-And-Swap)实现无锁并发,减少线程阻塞开销;
- 线程池化:通过线程池管理线程生命周期,避免频繁创建 / 销毁线程的性能损耗;
- 并发容器:针对多线程场景优化的集合类,替代线程不安全的 HashMap、ArrayList 等。
JUC 并发工具包都包括什么
原子操作类
基于 CAS 实现的无锁原子操作,避免 synchronized 的阻塞开销,核心类:
基本类型
AtomicInteger:原子 int 类型AtomicLong:原子 long 类型AtomicBoolean:原子 boolean 类型
数组类型
AtomicIntegerArray:原子地更新int[]数组中的元素AtomicLongArray:原子地更新long[]数组中的元素AtomicReferenceArray<E>:原子地更新对象引用数组中的元素。
带有字段更新器的原子类
AtomicIntegerFieldUpdater<T>:原子地更新对象T的volatile int字段。AtomicLongFieldUpdater<T>:原子地更新对象T的volatile long字段。AtomicReferenceFieldUpdater<T, V>:原子地更新对象T的volatile V引用字段。
引用类型
AtomicReference:原子更新对象引用AtomicStampedReference:对 CAS 的 ABA 问题的一个优化AtomicMarkableReference<V>:与AtomicStampedReference类似,也是为了解决 ABA 问题。但它使用一个boolean标记位
累加器
LongAdder:高并发下的long类型累加器LongAccumulator:比LongAdder更通用的累加器,可以自定义累加函数DoubleAdder:高并发下的double类型累加器。DoubleAccumulator:DoubleAdder的通用版本。
锁机制
替代 synchronized 的灵活锁实现,核心接口:
Lock:锁的顶级接口,提供比 synchronized 更细粒度的控制,定义了所有可重入锁获取和释放锁的基本行为,是
synchronized的现代、灵活替代品。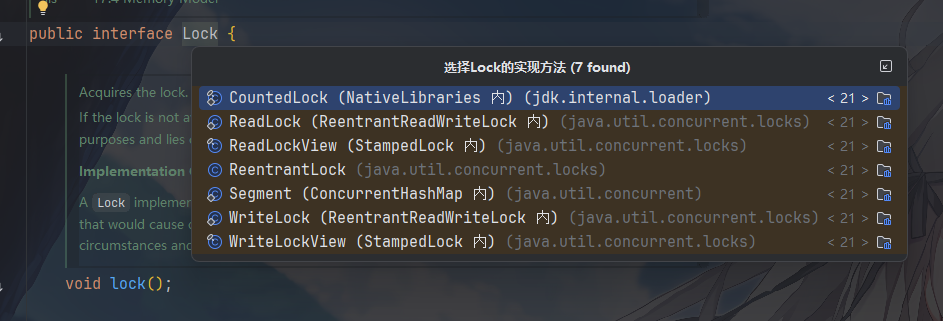
ReadWriteLock:读写锁,分离读 / 写操作,读共享、写独占,适合读多写少场景。
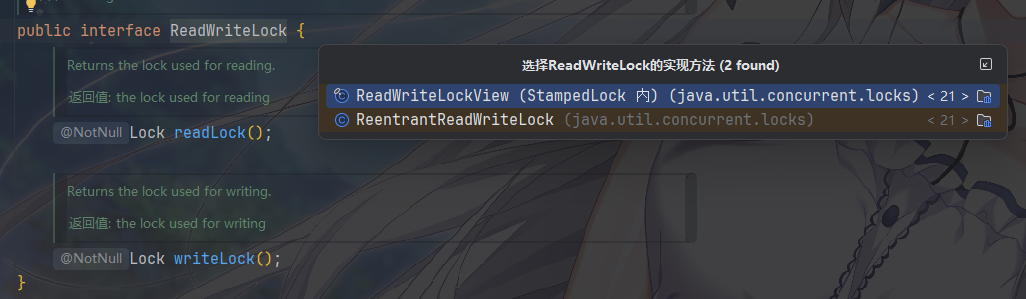
单独的类还有一个
StampedLock,它是 Java 8 新增,支持乐观读,性能优于读写锁
| 特性 | synchronized |
Lock |
|---|---|---|
| 获取方式 | 隐式(代码块/方法) | 显式(调用 lock()) |
| 释放方式 | 自动(finally 或异常) | 必须手动调用 unlock() |
| 中断支持 | 不支持(一旦等待,无法被中断) | 支持(lockInterruptibly()) |
| 超时控制 | 不支持 | 支持(tryLock(time)) |
| 公平性 | 默认非公平 | 可选择公平或非公平(实现类决定) |
| 条件变量 | wait()/notify() |
Condition 对象(更强大) |
线程池
线程池是 JUC 最核心的组件之一,用于管理线程生命周期,核心接口如下:
Executor:最顶层的接口,这是整个线程池框架的基石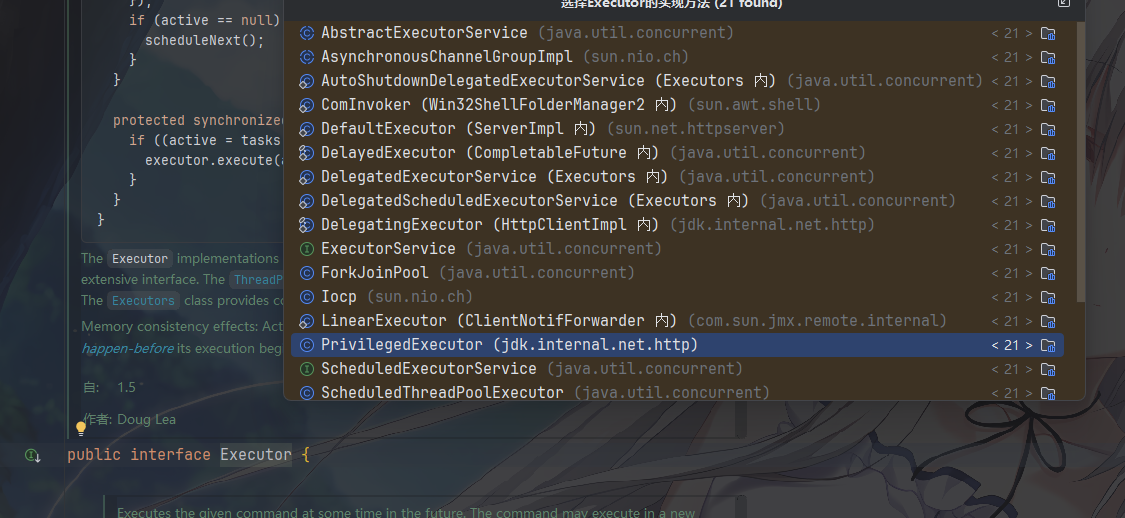
ExecutorService:核心服务接口,继承自Executor,极大地扩展了功能,是我们在日常开发中最常打交道的接口。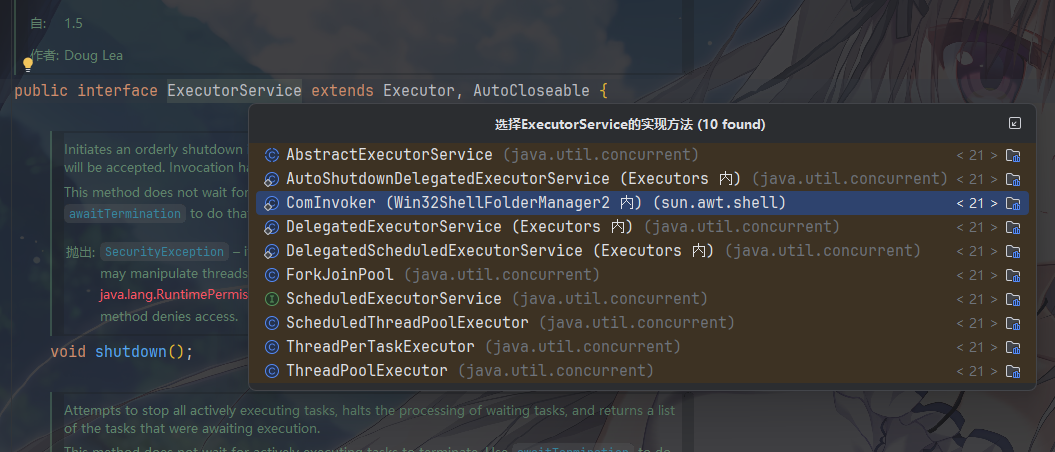
ScheduledExecutorService:定时任务接口,继承自ExecutorService,专门用于处理延迟执行或周期性执行的任务。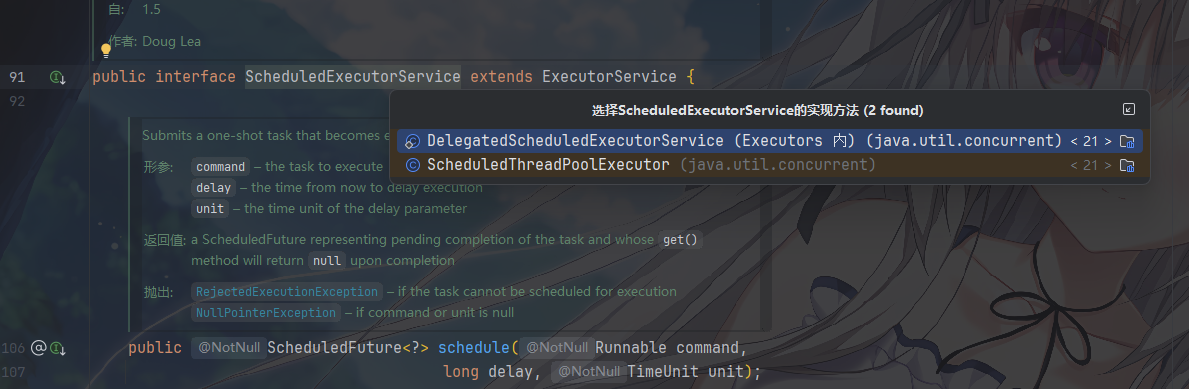
核心类如下:
ThreadPoolExecutor:标准的线程池实现,这是 JUC 线程池体系中最重要、最核心的实现类,也是我们推荐在生产环境中直接使用的类。ScheduledThreadPoolExecutor:定时线程池实现类,内部使用一个特殊的延迟队列DelayedWorkQueue来管理定时任务,确保任务能按预定的时间点被触发。
工具类:
Executors:提供了一系列静态工厂方法,用于快速创建几种预定义的线程池。这些方法内部都是调用ThreadPoolExecutor的构造函数,阿里《Java开发手册》明确禁止在生产环境中直接使用Executors创建线程池。强烈建议直接使用ThreadPoolExecutor并手动指定所有参数,以明确线程池的行为并规避风险。
并发容器
替代线程不安全的容器,不在这细说,我放到容器框架那边去了,这里只做介绍
List 接口下的
CopyOnWriteArrayList<E>:写时复制的线程安全ArrayList。所有读操作无锁,写操作会加锁并复制整个底层数组。适用于读多写少的场景(如监听器列表、配置白名单)。写操作开销大,不适合频繁修改或大数据量场景。
Vector 和 synchronizedList
是旧式同步容器,不推荐使用
Set接口下的
CopyOnWriteArraySet<E>:基于CopyOnWriteArrayList实现的线程安全Set。同样采用写时复制策略,适用于读多写少的无序集合场景。ConcurrentSkipListSet<E>:基于跳表(Skip List)实现的线程安全、有序(SortedSet)的Set。支持高并发的插入、删除和查找操作,性能优于synchronizedSortedSet。
Queue/Deque下的
阻塞队列
ArrayBlockingQueue<E>:有界阻塞队列,基于数组实现。创建时需指定容量,FIFO。可选公平/非公平策略。LinkedBlockingQueue<E>:可选有界/无界(默认无界)阻塞队列,基于链表实现。FIFO。吞吐量通常高于ArrayBlockingQueue。PriorityBlockingQueue<E>:无界阻塞队列,基于堆(Heap)实现。元素按优先级(Comparable/Comparator)排序,非 FIFO。DelayQueue<E extends Delayed>:无界阻塞队列,只有当元素的延迟时间到期后才能被取出。常用于定时调度任务。SynchronousQueue<E>:无缓冲的阻塞队列。每个put必须等待一个take,反之亦然。吞吐量极高,常用于线程池(如Executors.newCachedThreadPool)。
非阻塞队列
ConcurrentLinkedQueue<E>:无界、非阻塞(Lock-Free)的线程安全队列,基于链表和 CAS 实现。FIFO。高并发下性能极佳ConcurrentLinkedDeque<E>:无界、非阻塞的线程安全双端队列(Deque),支持从头尾两端高效插入/删除。
Map接口下的
ConcurrentHashMap<K,V>:最常用的高并发Map。JDK 8+ 采用 CAS + synchronized(分段锁思想),读操作几乎无锁,写操作锁粒度极细(只锁桶头节点)。支持高并发读写,是Hashtable和synchronizedMap的首选替代品。ConcurrentSkipListMap<K,V>:基于跳表实现的线程安全、有序(SortedMap)的Map。支持高并发的范围查询(如subMap)、插入和删除。
其他并发容器
BlockingDeque<E>:阻塞双端队列接口。JDK 提供了LinkedBlockingDeque实现(基于链表的有界阻塞双端队列)。TransferQueue<E>:该接口扩展了BlockingQueue,增加了transfer(E e)方法,确保生产者必须等到消费者接收元素才返回。LinkedTransferQueue是其高性能无界实现。SequencedCollection<E>/SequencedSet<E>/SequencedMap<K,V>:新接口,统一了有序集合(如List,LinkedHashSet,LinkedHashMap)的操作,它们的并发实现(如ConcurrentSkipListSet,ConcurrentSkipListMap)也实现了这些接口,但并非所有并发容器都适用(如ConcurrentHashMap无序)。
JUC原子操作类
再提CAS
介绍CAS
在 Java 中,实现 CAS
操作的一个关键类是Unsafe,它依赖现代多核 CPU
提供的一种硬件级别的原子指令。
只有当内存中的值 V 等于我预期的旧值 A 时,我才将它更新为新值 B;否则,什么也不做。”
Unsafe类位于sun.misc包下,是一个提供低级别、不安全操作的类。由于其强大的功能和潜在的危险性,它通常用于
JVM
内部或一些需要极高性能和底层访问的库中,而不推荐普通开发者在应用程序中使用
sun.misc包下的Unsafe类提供了compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法来实现的对Object、int、long类型的
CAS 操作
1 | // 原子地比较并交换对象引用 |
Object o: 要修改的对象。long offset: 对象中字段的内存偏移量。这是通过objectFieldOffset(Field f)方法获取的,它告诉 JVM 要修改的是对象中的哪个具体字段。expected: 预期的当前值(A)。x: 要设置的新值(B)。
类如其名,直接使用 Unsafe
非常危险且不被官方推荐,因此,JUC
包提供了一系列原子类,它们内部正是基于 Unsafe 的
CAS 操作来实现线程安全的。
我们的 Atomic 类,也就是原子操作类依赖于 CAS
乐观锁来保证其方法的原子性,而不需要使用传统的锁机制(如
synchronized 块或 ReentrantLock)。以
AtomicInteger 为例,其核心方法 compareAndSet
的实现如下
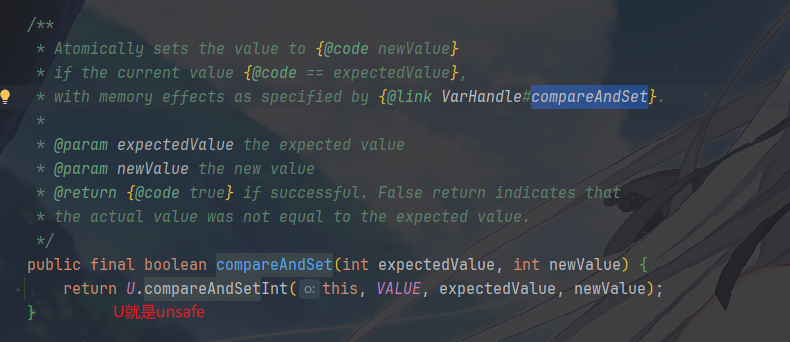
之前总说的自旋重试就是在一个循环里不断重试,直到成功为止。
CAS的问题
ABA
尽管 CAS 强大,但它并非万能,存在一个著名的缺陷:ABA 问题。
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 “ABA”问题。
JUC 提供了 AtomicStampedReference<V> 和
AtomicMarkableReference<V> 来解决 ABA 问题。
AtomicStampedReference:除了维护对象引用外,还维护一个整数版本号(stamp)。CAS 操作会同时比较引用和版本号。即使值变回A,版本号也已递增,从而可以检测到中间的变化。AtomicMarkableReference:使用一个boolean标记位代替版本号,适用于只需要区分“是否被修改过”的简单场景。
自旋开销大
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
只能保证一个共享变量的原子操作
CAS 操作仅能对单个共享变量有效。当需要操作多个共享变量时,CAS
就显得无能为力。不过,从 JDK 1.5 开始,Java
提供了AtomicReference类,这使得我们能够保证引用对象之间的原子性。通过将多个变量封装在一个对象中,我们可以使用AtomicReference来执行
CAS 操作。
除了 AtomicReference
这种方式之外,还可以利用加锁来保证
Atomic 原子类介绍
原子类简单来说就是具有原子性操作特征的类。
Atomic
翻译成中文是“原子”的意思。在化学上,原子是构成物质的最小单位,在化学反应中不可分割。在编程中,Atomic
指的是一个操作具有原子性,即该操作不可分割、不可中断。即使在多个线程同时执行时,该操作要么全部执行完成,要么不执行,不会被其他线程看到部分完成的状态。
java.util.concurrent.atomic 包中的 Atomic
原子类提供了一种线程安全的方式来操作单个变量。
它们所有读写操作(如 get, set)都带有
volatile 语义,所有复合操作都基于
CAS + 自旋 实现,避免了使用 synchronized
锁。
Atomic 类依赖于 CAS
乐观锁来保证其方法的原子性,而不需要使用传统的锁机制(如
synchronized 块或 ReentrantLock)。
基本类型原子类
使用原子的方式更新基本类型
AtomicInteger:整型原子类AtomicLong:长整型原子类AtomicBoolean:布尔型原子类
上面三个类提供的方法几乎相同,所以我们这里以
AtomicInteger 为例子来介绍。
AtomicInteger
的核心目标是:在多线程环境下,对一个 int
值进行原子性的读写、更新和计算操作,而无需使用 synchronized
这样的重量级锁。
它通过以下两大支柱实现这一目标:
- 硬件支持:利用 CPU 提供的 CAS(Compare-And-Swap)。
- 内存可见性:使用
volatile关键字保证变量的修改对所有线程立即可见。
对于 AtomicInteger的核心字段,如下
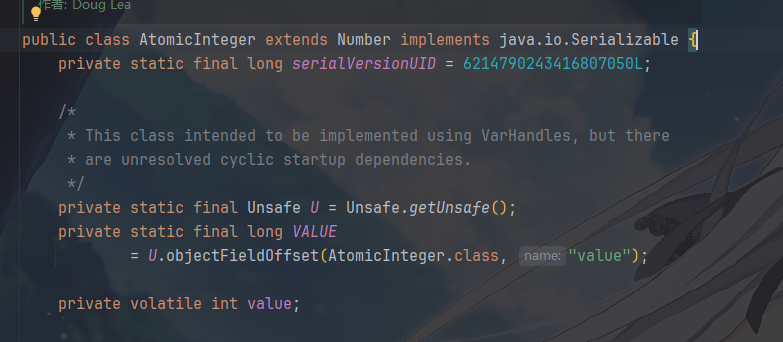
Unsafe: JVM 提供的后门,允许直接操作内存。AtomicInteger所有原子操作最终都委托给Unsafe的 native 方法。VALUE: 这是一个常量,代表了value字段在AtomicInteger对象实例中的内存偏移地址。有了它,Unsafe就能精准地定位并修改这个字段。volatile int value:volatile是关键,它确保了可见性,禁止重排序
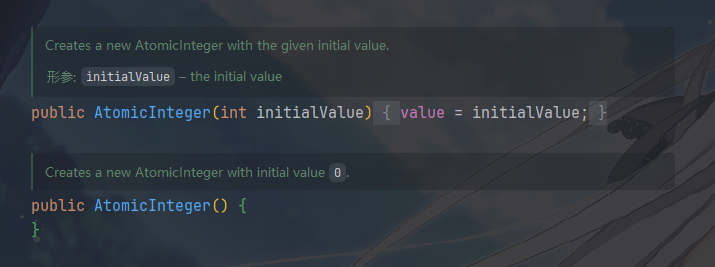
构造方法倒是没啥好说的
基础操作:get() 和
set()
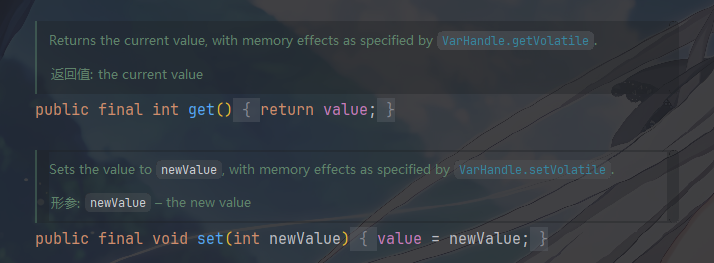
- 这两个方法看起来很简单,但因为
value是volatile的,所以它们本身就具备了内存可见性。调用get()总是能拿到最新的值。
核心原子操作:CAS 与自旋
自旋下,线程不会被挂起,而是在用户态不断重试,直到 CAS 成功,在低竞争场景下,性能远优于阻塞。
compareAndSet(expectedValue, newValue)如果当前
value的值等于expectedValue,则将其原子地设置为newValue,并返回true;否则,不做任何事,返回false。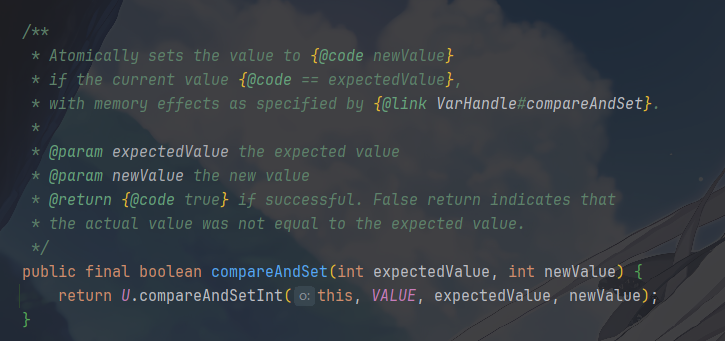
- 它直接调用
Unsafe的compareAndSetInt方法,该方法会编译成一条 CPU 的 CAS 指令。
- 它直接调用
getAndSet(newValue)先获取旧值,再设置新值的原子操作
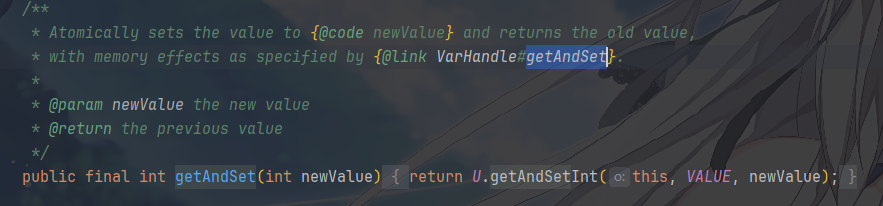
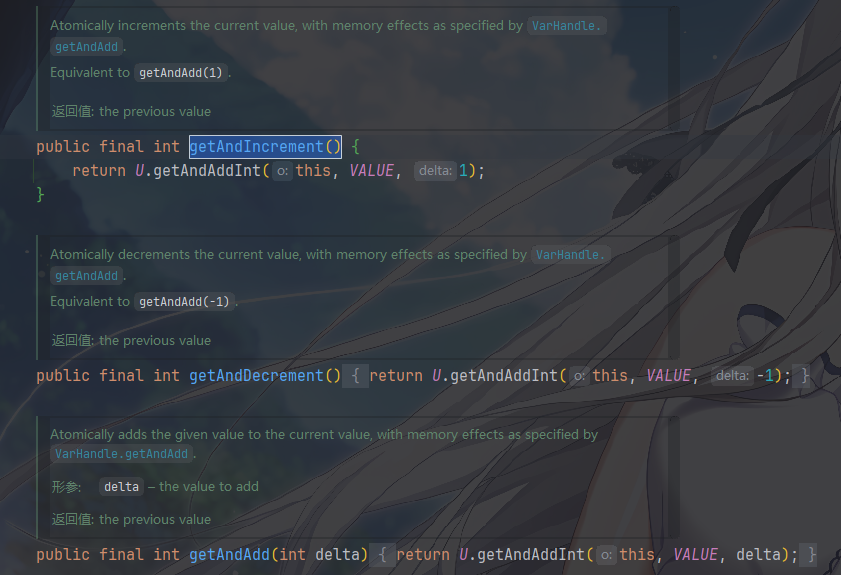
getAndAdd(delta)/getAndIncrement()/getAndDecrement()分别是,获取当前的值,然后加上预期的值/自增/自减,可以发现这些都是重载方法
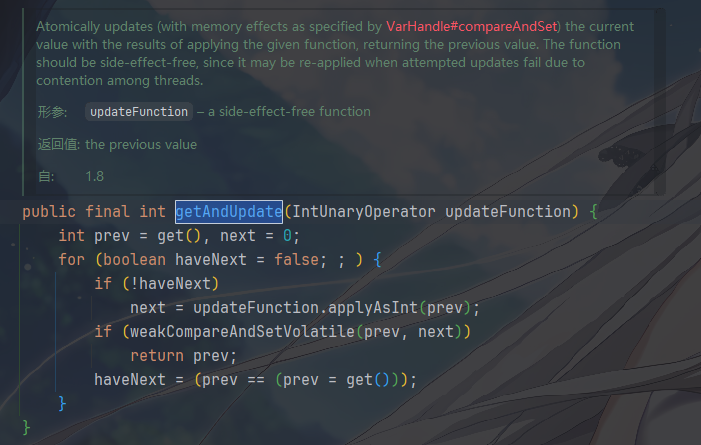
高级操作,函数式更新
- 这些方法(如
getAndUpdate,updateAndGet)允许你传入一个函数来定义复杂的更新逻辑。核心依然是 CAS 自旋,先获取当前值prev,用函数计算出新值next,然后尝试 CAS。失败就重试。 - 它要求函数是无副作用的(side-effect-free),因为可能会被多次调用。
在高度竞争的情况下,还可以使用Java
8提供的LongAdder和LongAccumulator,下面说
数组类型原子类
使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类AtomicLongArray:长整形数组原子类AtomicReferenceArray:引用类型数组原子类
上面三个类提供的方法几乎相同,所以我们这里以
AtomicIntegerArray 为例子来介绍。
常用方法如下
1 | // 获取 index=i 位置元素的值 |
二编:注意,JDK 9+ 后,
AtomicIntegerArray等数组类型的原子类不再直接依赖sun.misc.Unsafe,而是通过java.lang.invoke.VarHandle来实现。VarHandle是一个更安全、更通用的变量句柄,它封装了对变量(包括数组元素)的各种访问模式,不细说了
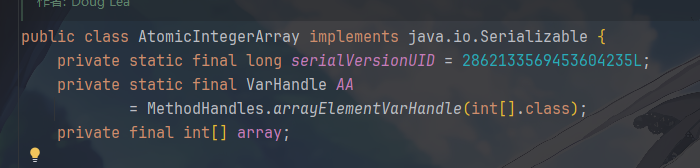
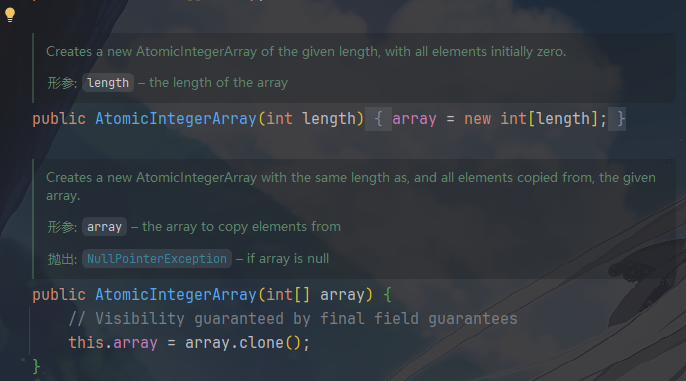
AtomicIntegerArray的核心字段及其构造函数
基础操作:get() 和
set()
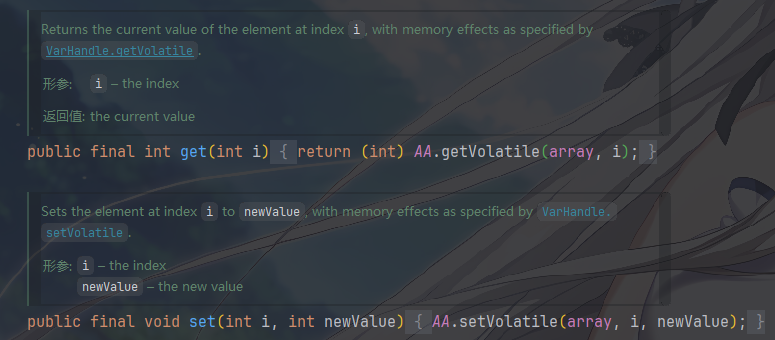
AA.getVolatile(...): 这不是普通的数组访问array[i],而是通过VarHandle执行一次带有volatile读语义的操作。这保证了每次读取都能拿到主内存中的最新值。AA.setVolatile(...)同理
核心原子操作:CAS 与自旋
compareAndSet(i, expected, update)原子地比较
array[i]和expectedValue,如果相等,则将其设置为newValue。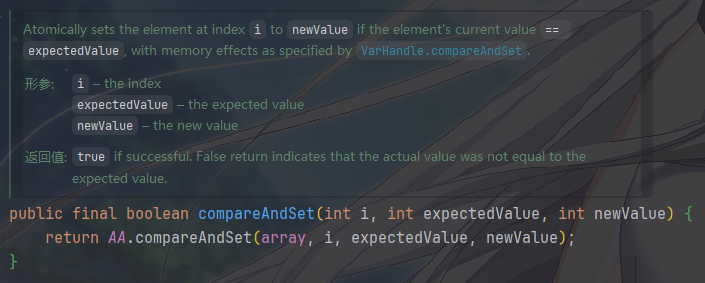
- 它委托给
VarHandle的compareAndSet方法,该方法最终会编译成一条 CPU 的 CAS 指令,作用于array[i]这个内存位置。
- 它委托给
`
getAndAdd(i, delta)/getAndIncrement(i)/getAndDecrement(i)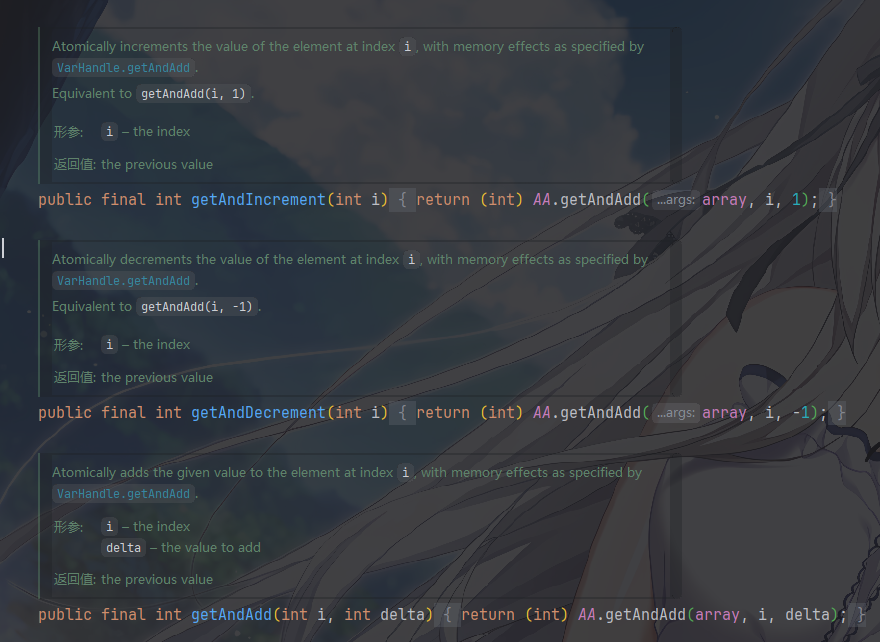
几乎和
AtomicInteger一样
高级操作:函数式更新
它们的内容和逻辑与 AtomicInteger
完全一致,只是操作对象变成了 array[i]。
核心依然是 CAS 自旋,先获取 array[i] 的当前值
prev,用函数计算出新值 next,然后尝试
CAS。失败就重试。
也要求函数是无副作用的
带有字段更新器的原子类
AtomicIntegerFieldUpdater<T>:原子地更新对象T的volatile int字段。AtomicLongFieldUpdater<T>:原子地更新对象T的volatile long字段。AtomicReferenceFieldUpdater<T, V>:原子地更新对象T的volatile V引用字段。
以AtomicIntegerFieldUpdater<T>为例子,就是讲一下实际上和AtomicInteger区别不是很大
AtomicIntegerFieldUpdater<T>
是一个“反射工具”,它用于对任意类中某个 volatile int
字段进行原子操作,其主要目的是对已有类中的 volatile int
字段提供原子更新能力
它不持有数据,只操作外部对象的字段,就例如
1 | class Counter { |
而 AtomicInteger 则是:
1 | AtomicInteger ai = new AtomicInteger(0); |
而AtomicIntegerFieldUpdater<T>是一个抽象类,具体实现在内部类
AtomicIntegerFieldUpdaterImpl,构造时通过反射获取目标类
T 的指定字段
fieldName,只不过,验证该字段必须是
volatile int,因为它是操作 int 的
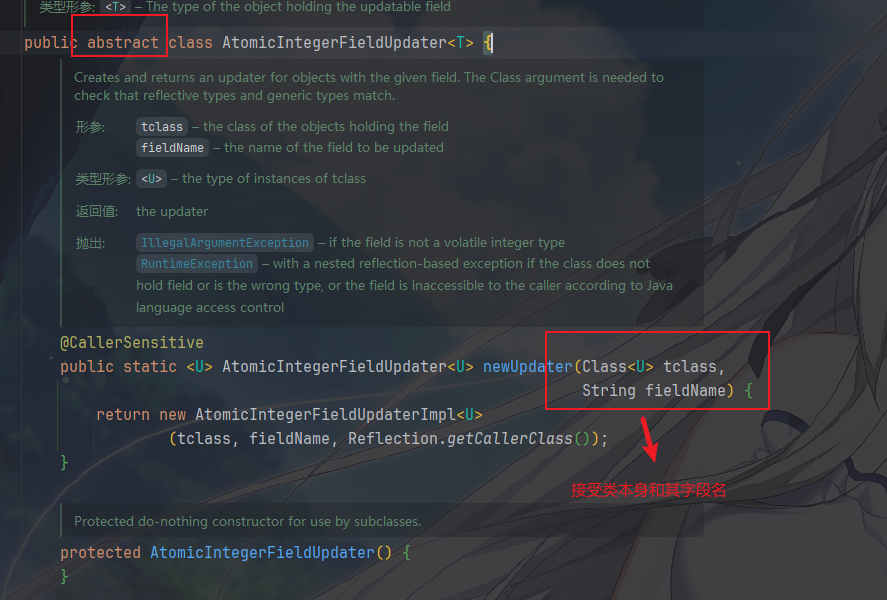
而两者提供的 API 几乎完全一致,也是通过 Unsafe 进行原子更新,接口行为一致,但作用对象不同,但是有人乐意用,我就乐意用,有人觉得用这个乱套,例如我朋友,所以,因人而异
emmm,不能用于 static
字段,因为objectFieldOffset 不支持
引用类型原子类
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。它是构建更复杂无锁数据结构(如无锁队列、栈、链表等)的基石。
AtomicReference:引用类型原子类AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来
上面三个类提供的方法几乎相同,所以我们这里以
AtomicReference 为例子来介绍。
二编:一样,JDK 9+ 后,
AtomicReference通过java.lang.invoke.VarHandle来实现。这比直接使用Unsafe更安全、更标准
核心字段和初始化
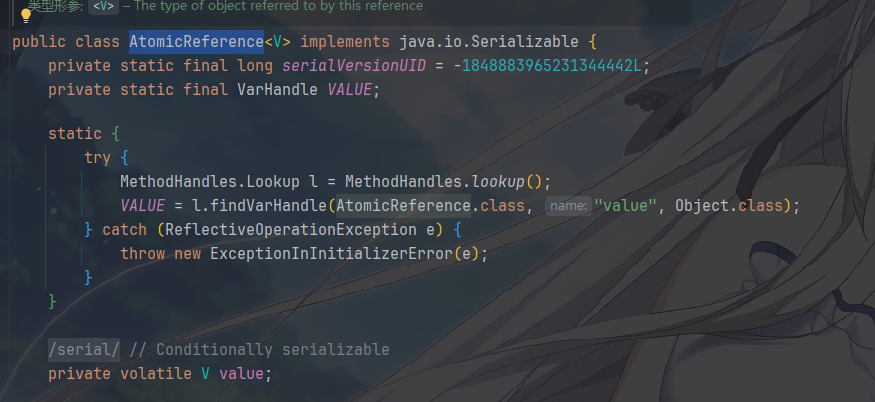
VarHandle VALUE: 这个句柄知道如何以原子的方式访问AtomicReference类实例中的value字段。这是所有原子操作的入口。
基础操作

value 字段本身就是 volatile
的。直接操作就行
核心原子操作:CAS 与自旋
compareAndSet(expected, update)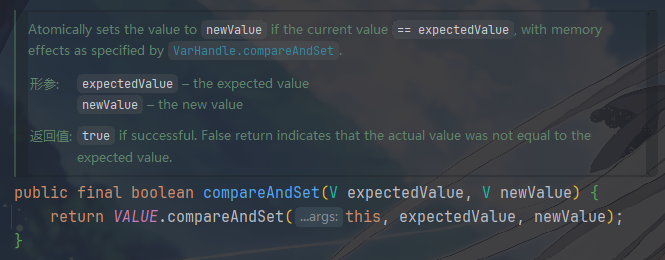
没啥太大差别,只不过CAS最终作用于
this.value这个内存位置。原子地比较this.value和expectedValue,这里是引用相等==,不是equalsgetAndSet(newValue)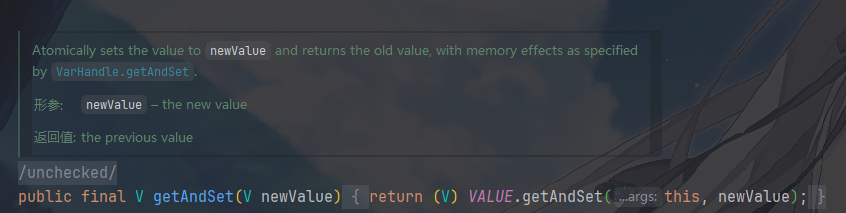
依旧自旋,依旧无锁等待
对于高级特性的函数式更新部分,几乎一致,只不过,它会尝试用
weakCompareAndSetVolatile,也就是一种弱化的
CAS(最终一致性)将 prev 替换为 next。
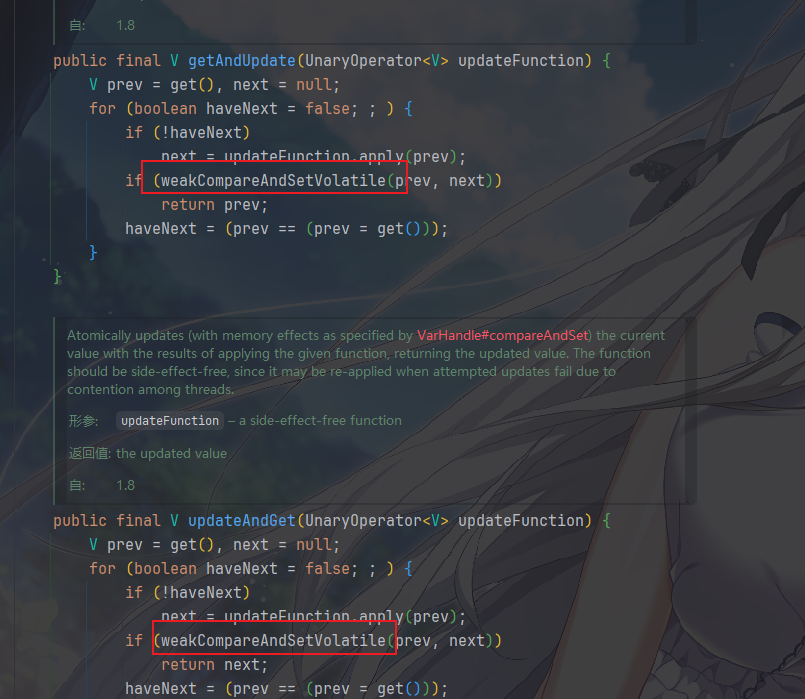
AtomicReference vs
synchronized
1 | private String value; |
每次访问都需要获取锁,性能开销大,且在高并发下会导致线程阻塞。
1 | private AtomicReference<String> valueRef = new AtomicReference<>(); |
读写操作无锁,性能极高。对于简单的赋值和读取场景,AtomicReference
是更好的选择。
所以说,AtomicReference我用的最多的就是作为状态机的状态持有者,当你的状态是一个复杂的对象时,可以用
AtomicReference<State> 来安全地切换状态。例如
1 | import java.util.concurrent.atomic.AtomicReference; |
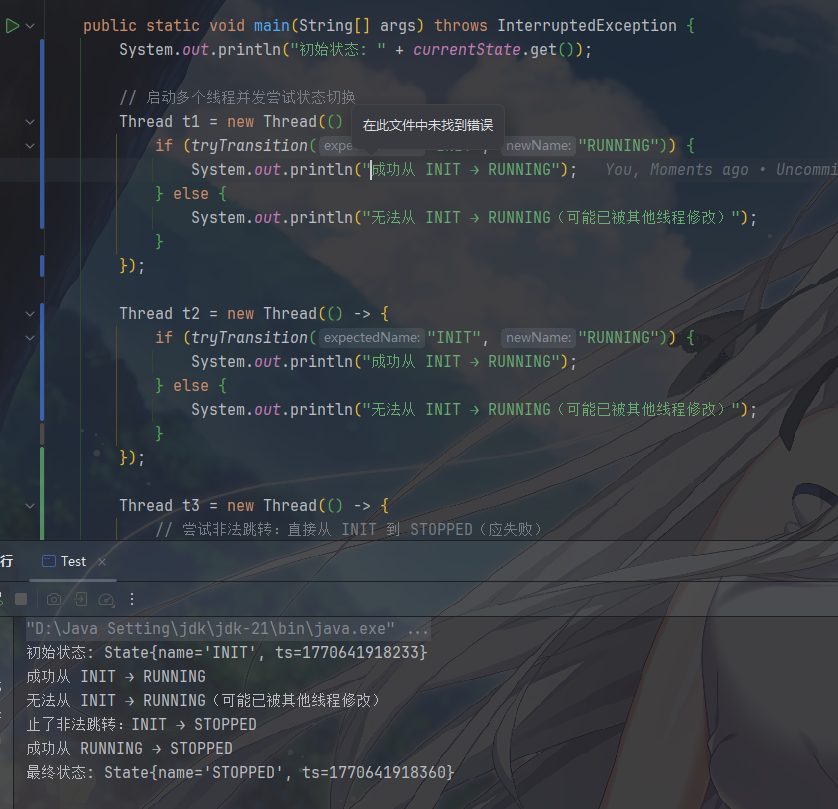
效果一目了然
累加器
以 LongAdder为例子,作为代表讲解整个 JUC 累加器
AtomicLong 主要依赖 CAS
操作保证原子性。当多线程同时更新同一个计数器时,会出现的各种激烈竞争和CAS重试等各种问题大家也都清楚,所以说,我们可以使用
LongAdder
LongAdder是JDK 1.8 新增的原子类,基于 Striped64
实现,LongAdder基类是Number。
从官方文档看,LongAdder在高并发的场景下会比
AtomicLong 具有更好的性能,代价是消耗更多的内存空间:

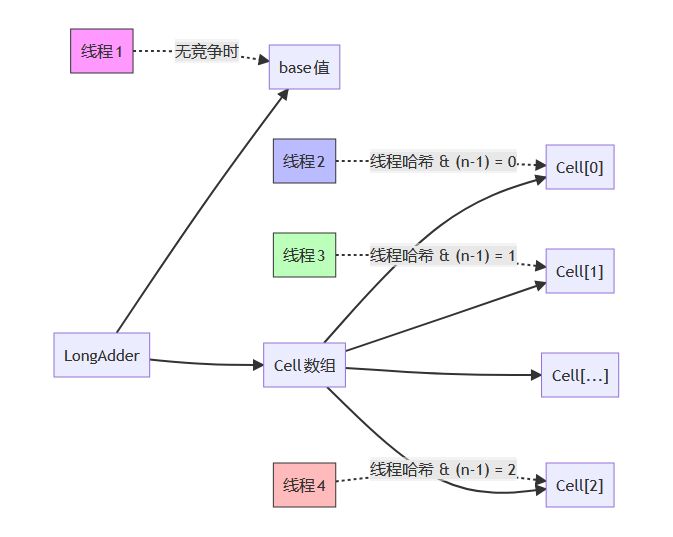
对于 Striped64 就是典型的用空间换时间,将高并发下的大量竞争分散,减少线程间的直接冲突。
Striped64 内部维护了一个基础值 base 和一个 Cell 数组,它将一个 LongAdder 对象分成多个 Cell,每个 Cell 维护一个独立的计数器。在多线程并发量很高的时候进行累加操作时,每个线程会根据自己的 hash 值选择对应的 Cell 进行累加操作,最后再汇总到一块作为其值,大家都管这个操作叫分段相加。
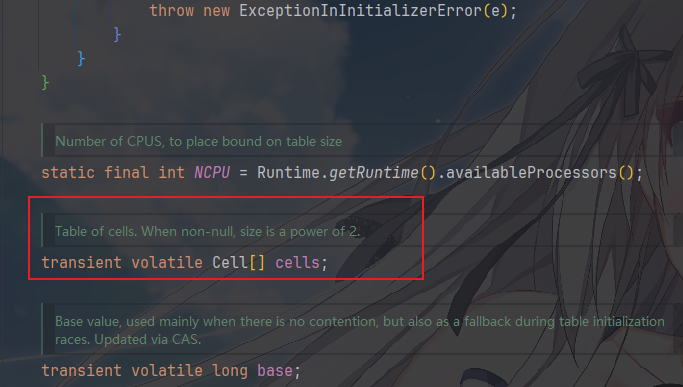
其中 Cell 是一个内部静态类
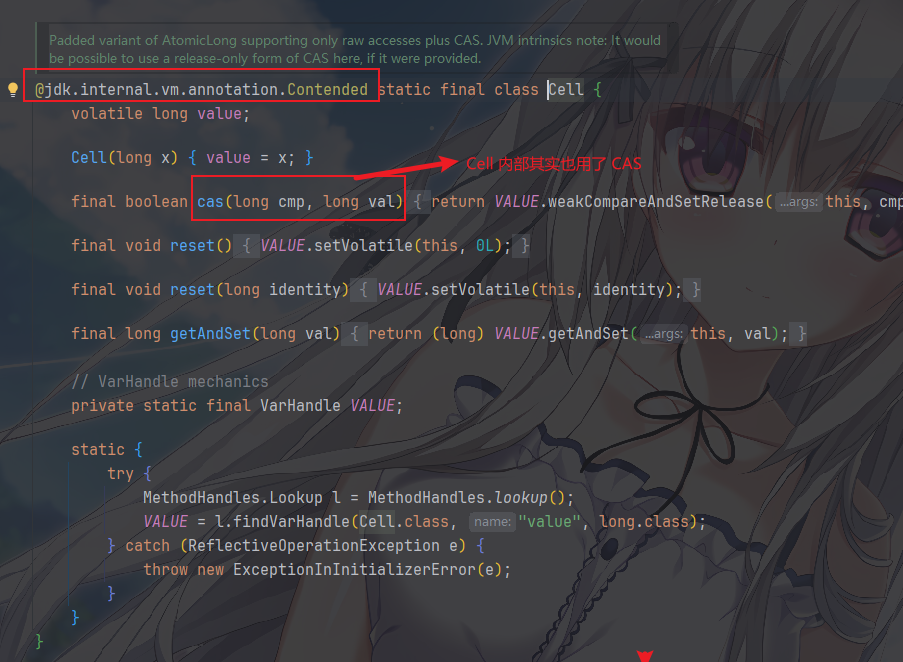
@Contended 注解防止不同 Cell
被加载到同一缓存行,避免伪共享,值得注意的是@Contended注解默认仅对
JDK
内部类生效,外部应用需通过-XX:-RestrictContended参数启用,反正我是没用到过。。。
以 LongAdder 中的 add 方法为例子
1 | public void add(long x) { |
好像银行柜台,人少时一个窗口就够了(base);人多时开放多个窗口(Cells),每个客户去不同窗口办理,互不影响,效率大大提高。
LongAdder 不会一开始就创建很多
Cell,它是会扩容的,首先,初始状态一个 base 值,所有线程操作这个变量操作
LongAdder,当发现 base 更新冲突,才初始化 Cell
数组,线程通过ThreadLocalRandom.getProbe()生成哈希值映射到对应
Cell,不同线程操作不同 Cell,极大降低冲突。当 Cell
更新失败时,longAccumulate方法会根据情况进行重试或者扩容,当然其中也有可能进行自旋,能扩多大跟你
CPU 内核数有关系
方法代码太长,就不放了
对于对所有 Cells 进行求和,也就是汇总这个方法
1 | public long sum() { |
很明显,它不是原子操作,虽然sum()方法本身是线程安全的,因为它在读取时不会阻塞写操作,可能读到部分更新的中间状态。这与
AtomicLong 的get()方法提供的强一致性形成对比
但当所有写操作完成后,多次调用sum()结果最终一致,而这对统计类场景已经足够。






