体验在实际项目中使用 Neo4j
搭建项目
关于如何把 Neo4j
引入到项目中并且使用是本文的重点,以前的那种思想,图数据库相关的理解什么的,就不说了
那么,如何把 Neo4j 引入到 Spring
的项目中,首先,要有对应的有必要使用的业务
而且将 Neo4j 引入 Spring Boot 项目,最标准且高效的方式是使用
Spring Data Neo4j
那么,就以我们之前经常提到的社交网络搭建这个作为基本的业务,来去实现这么一个项目,这个例子也方便我们后续去引入
AI 来学习 Neo4j 在 AI 上的应用
Spring 中操作 Neo4j,核心是:
1 2 3 4 5 6 7 Spring Boot ↓ Spring Data Neo4j(SDN) ↓ Neo4j Java Driver ↓ Neo4j Database
那么,基本就需要引入如下依赖就足够了
1 2 3 4 5 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-neo4j</artifactId > </dependency >
然后进行一些最简单的配置
1 2 3 4 5 6 spring: neo4j: uri: bolt://localhost:7687 authentication: username: neo4j password:
这是我们的 Neo4j 数据库 URI
和凭据。在此处输入的用户名和密码应与您的个人数据库匹配。这是连接到 Neo4j
实例所需的最低配置。
无需为驱动程序添加任何其他配置,这得益于 SDN 6 开箱即提供的 Spring
Boot 驱动程序自动配置。
但是上述配置连接的是 Neo4j
默认的数据库,大多数情况下我们不希望这样,所以我们通常会指定一个数据库
1 2 3 4 5 6 spring: neo4j: uri: bolt://localhost:7687/你的数据库名 authentication: username: neo4j password: 你的密码
呃呃但是会出现这种情况,也就是说,Neo4j
社区版不支持直接创建新数据库的命令。你需要使用 Neo4j
企业版来执行这些命令。
image-20260422142637233
除了换企业版,另一种方法是运行多个 Neo4j
实例,每个实例使用不同的端口和数据库路径。
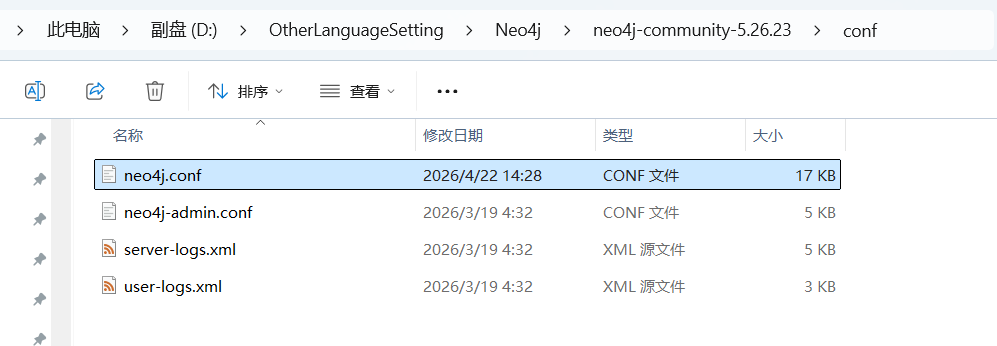
还有一种方法只能更换默认数据库名称,现在这种方法不会创建新的数据库
image-20260422143350770
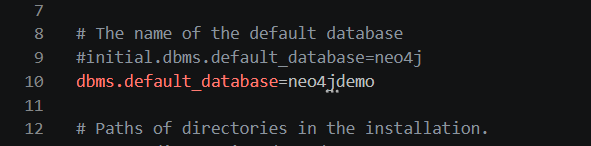
找到neo4j的配置文件,打开然后修改默认数据库,,只需要按照这个格式在下面插入一行就行,保存文件后退出,然后关闭neo4j后重启即可让neo4j自动创建这个数据库:
image-20260422143420578
编写实体类
注意千万不要用@Data,因为 User
实体类中存在循环引用 ,且 Lombok 的 @Data
注解自动生成的 hashCode()
方法会触发无限递归,这样,当计算一个 User 的
hashCode() 时,会递归计算其 following 里每个
User 的 hashCode(),而这些 User
又会反向引用原 User最终导致无限递归,栈被撑爆。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package hbnu.project.neo4jdemo.entity;import lombok.Data;import org.springframework.data.neo4j.core.schema.GeneratedValue;import org.springframework.data.neo4j.core.schema.Id;import org.springframework.data.neo4j.core.schema.Node;import org.springframework.data.neo4j.core.schema.Relationship;import java.util.HashSet;import java.util.Set;@Node("User") @Data public class User { @Id @GeneratedValue private Long id; private String name; private Integer age; private String email; @Relationship(type = "FOLLOWS", direction = Relationship.Direction.OUTGOING) private Set<User> following = new HashSet <>(); @Relationship(type = "FOLLOWS", direction = Relationship.Direction.INCOMING) private Set<User> followers = new HashSet <>(); public void follow (User user) { this .following.add(user); user.getFollowers().add(this ); } public void unfollow (User user) { this .following.remove(user); user.getFollowers().remove(this ); } }
编写持久层
和 Spring Data JPA 开发大部分数据库一样,只需要继承对应数据库的
Repository
基础接口,即可拥有大部分常用的数据库方法,所以说,在比较简单的场景下,挂个空接口是比较常见的
1 2 3 4 5 6 7 import hbnu.project.neo4jdemo.entity.User;import org.springframework.data.neo4j.repository.Neo4jRepository;public interface UserRepository extends Neo4jRepository <User, Long> {}
但是,为了接下来的演示和之后的扩展,我们扩展一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import hbnu.project.neo4jdemo.entity.User;import org.springframework.data.neo4j.repository.Neo4jRepository;import org.springframework.data.neo4j.repository.query.Query;import org.springframework.data.repository.query.Param;import org.springframework.data.domain.Page;import org.springframework.data.domain.Pageable;import java.util.List;import java.util.Optional;public interface UserRepository extends Neo4jRepository <User, Long> { Optional<User> findByName (String name) ; List<User> findByAgeBetween (Integer minAge, Integer maxAge) ; Page<User> findByAgeGreaterThan (Integer age, Pageable pageable) ; @Query("MATCH (u:User)-[:FOLLOWS]->(f:User) WHERE u.id = $userId RETURN f.name") List<String> findFollowingNamesByUserId (@Param("userId") Long userId) ; @Query("MATCH (u1:User)-[:FOLLOWS]->(u2:User), (u2)-[:FOLLOWS]->(u1) WHERE u1.id = $u1Id AND u2.id = $u2Id RETURN count(*) > 0") boolean isMutualFollow (@Param("u1Id") Long u1Id, @Param("u2Id") Long u2Id) ; @Query("MATCH (u1:User)-[r:FOLLOWS]->(u2:User) WHERE u1.id = $u1Id AND u2.id = $u2Id DELETE r") void deleteFollowRelationship (@Param("u1Id") Long u1Id, @Param("u2Id") Long u2Id) ; }
服务层
服务层和控制器层就是很简单的一些 Spring Boot
内容,在这里就不展示控制器层了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 package hbnu.project.neo4jdemo.service;import hbnu.project.neo4jdemo.entity.User;import hbnu.project.neo4jdemo.repository.UserRepository;import lombok.RequiredArgsConstructor;import org.springframework.data.domain.Page;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Pageable;import org.springframework.data.domain.Sort;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;import java.util.List;import java.util.Optional;@Service @RequiredArgsConstructor public class UserService { private final UserRepository userRepository; @Transactional(readOnly = true) public Optional<User> getUserById (Long id) { return userRepository.findById(id); } @Transactional public User createUser (User user) { return userRepository.save(user); } @Transactional public User updateUser (Long id, User updateUser) { return userRepository.findById(id) .map(user -> { user.setName(updateUser.getName()); user.setAge(updateUser.getAge()); user.setEmail(updateUser.getEmail()); return userRepository.save(user); }) .orElseThrow(() -> new RuntimeException ("用户不存在" )); } @Transactional public void deleteUser (Long id) { userRepository.deleteById(id); } @Transactional public User followUser (Long userId, Long followUserId) { User user = userRepository.findById(userId) .orElseThrow(() -> new RuntimeException ("用户不存在" )); User followUser = userRepository.findById(followUserId) .orElseThrow(() -> new RuntimeException ("被关注用户不存在" )); user.follow(followUser); return userRepository.save(user); } @Transactional public void unfollowUser (Long userId, Long followUserId) { User user = userRepository.findById(userId).orElseThrow(() -> new RuntimeException ("用户不存在" )); User followUser = userRepository.findById(followUserId).orElseThrow(() -> new RuntimeException ("被关注用户不存在" )); user.unfollow(followUser); userRepository.deleteFollowRelationship(userId, followUserId); userRepository.save(user); } @Transactional(readOnly = true) public Page<User> getUsersByAgeGreaterThan (Integer age, Integer pageNum, Integer pageSize) { Pageable pageable = PageRequest.of(pageNum - 1 , pageSize, Sort.by(Sort.Direction.DESC, "age" )); return userRepository.findByAgeGreaterThan(age, pageable); } @Transactional(readOnly = true) public List<String> getFollowingNames (Long userId) { return userRepository.findFollowingNamesByUserId(userId); } @Transactional(readOnly = true) public boolean checkMutualFollow (Long u1Id, Long u2Id) { return userRepository.isMutualFollow(u1Id, u2Id); } }
进行体验
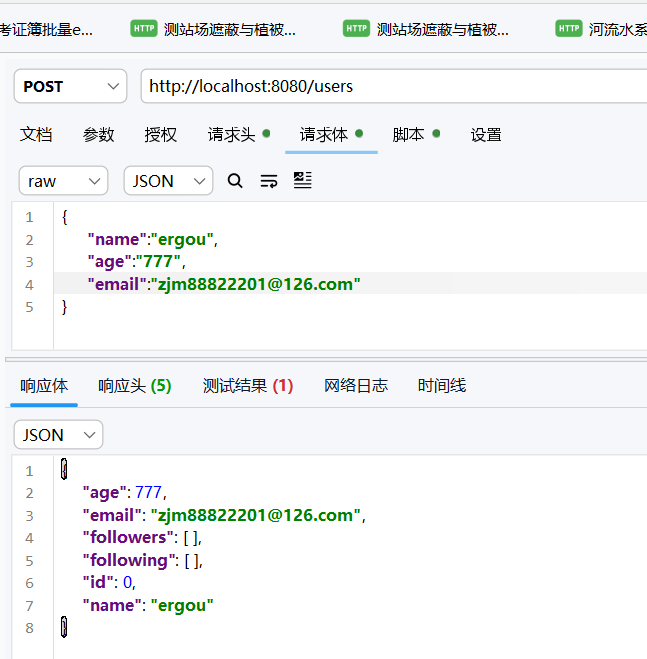
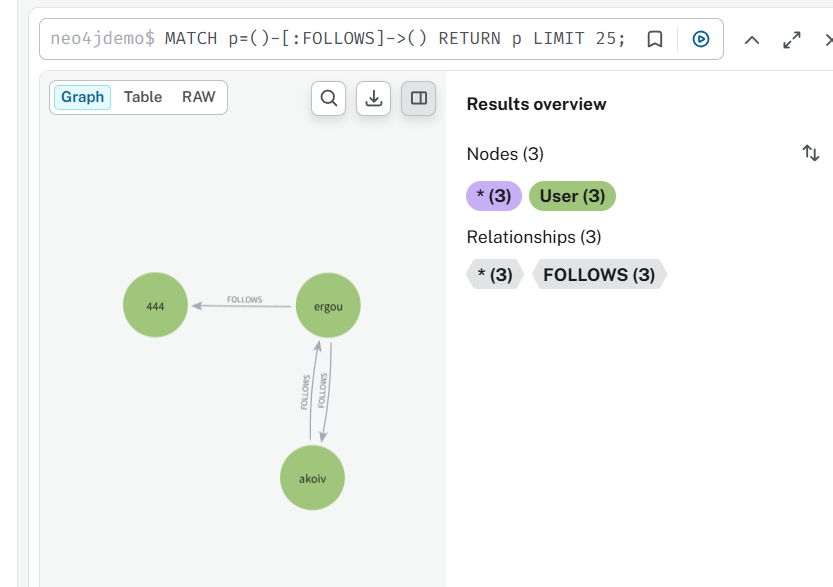
创建一些用户看看
image-20260422143915126
image-20260422144739892
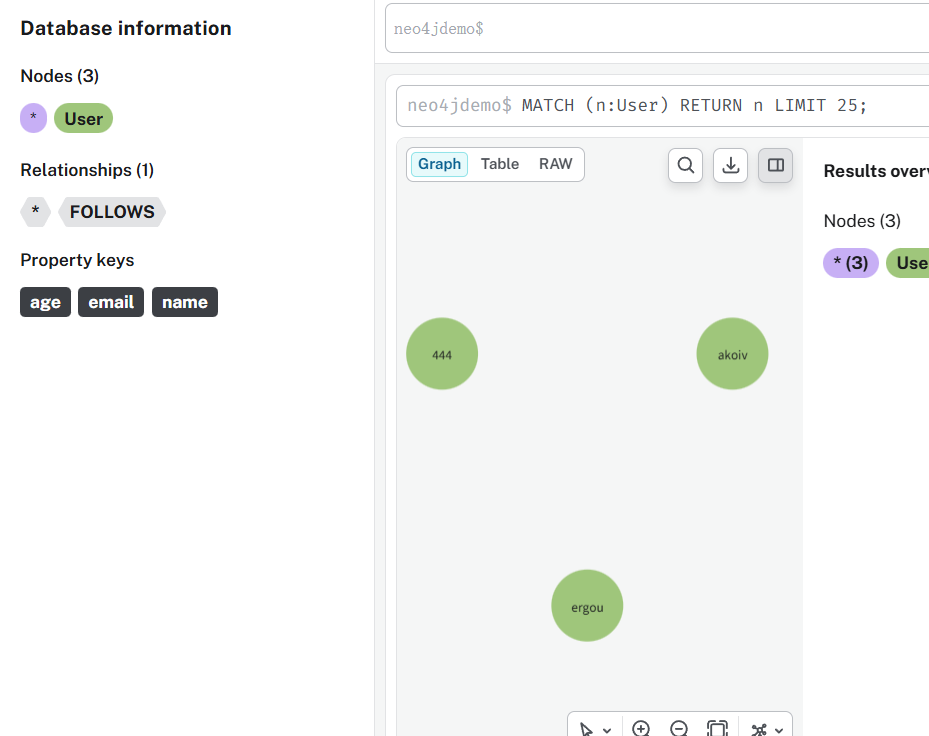
然后让他们有一些关注关系
image-20260422145223230
然后查询一下 ergou 的用户的关注列表
在 Spring 项目中使用 Neo4j
实体类编写方面
对于一个节点实体,核心的注解有这些
注解
作用
@Node标记节点
@Id主键
@GeneratedValue自动生成ID
@Property字段映射
@Relationship图关系
@Node
指定标签:@Node("Person"),等价于(:Person)
1 2 3 4 5 @Node("Person") public class User { }
若不写值:@Node →
标签默认是类名,首字母大写。一个类只能有一个
@Node,但节点可拥有多个标签
对于 ID 的几种模式
字段映射 @Property
就跟 MyBatis
那个@TableName一样,做字段和属性名映射的,字段名与库字段名一致 时可省略。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import org.springframework.data.neo4j.core.schema.Property;@Node("Person") public class User { @Id private String userId; @Property("user_name") private String name; @Property private Integer age; @Property(readOnly = true) private LocalDateTime createTime; }
动态标签@DynamicLabels
Neo4j 节点允许多标签,静态标签用
@Node,动态标签 用
@DynamicLabels
1 2 3 4 5 6 7 8 9 10 11 import org.springframework.data.neo4j.core.schema.DynamicLabels;import java.util.Set;@Node("User") public class User { @Id private String userId; @DynamicLabels private Set<String> labels; }
这个是什么意思,普通关系型数据库一行数据只能属于一张表,但是 Neo4j
一个节点可以同时属于 N 个标签,静态标签 @Node
是写死的,代表这个节点永远带着这个标签,动态标签
@DynamicLabels 就是除了固定的 User
标签外,我还可以给这个节点额外贴任意多个标签,随时加、随时删。
关系映射 @Relationship
关系实体
Neo4j
中关系本身可以携带属性,此时必须使用:@RelationshipProperties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @RelationshipProperties public class FriendRelation { @RelationshipId private Long id; @TargetNode private User friend; private LocalDate since; private Integer strength; }
在节点中引用关系实体
1 2 3 4 5 6 7 8 9 @Node("Person") public class User { @Id private String userId; @Relationship(type = "FRIEND") private List<FriendRel> friends; }
还有一些其他的内容,对于 Neo4j 这边也支持,例如
@Version乐观锁,@ReadOnlyProperty设置只读字段,JPA
审计的一些内容,审计注解(@CreatedBy、@CreatedDate、@LastModifiedBy、@LastModifiedDate)这都是支持的
持久层方面
持久层方面就 Neo4jRepository 比较关键,它也是一种 JPA
的写法,这是其数据库持久层的基础接口
1 2 public interface UserRepository extends Neo4jRepository <User, String> {}
方法名查询也不需要写 Cypher,和 JPA 一样,支持关键字推导
1 2 3 4 5 List<User> findByAgeLessThan (Integer age) ; List<User> findByNameContainingAndAgeBetween (String name, int min, int max, Sort sort) ;
自定义 Cypher 查询我们使用 MySQL 时候的一样,都是
@Query
1 2 3 4 5 6 @Query(""" MATCH (u:User) WHERE u.age > $age RETURN u """) List<User> findAdultUsers (Integer age) ;
这里的 $age类似 MyBatis 那样,这是参数
返回路径是Neo4j
最大特点,可以返回图路径是非常重要的,有时候结果不一定有过程重要
1 2 3 4 @Query(""" MATCH p=(u:User)-[:FRIEND]->(f:User) RETURN p """)
这里p 是路径对象,包含:起始节点、关系、结束节点
Spring Data Neo4j
对复杂路径映射支持有限,这是为了递归的考虑,所以说在返回路径的时候,我们通常都封装一个DTO,然后用@QueryResult
映射:
1 2 3 4 5 6 7 8 9 10 11 12 13 import org.springframework.data.neo4j.core.schema.QueryResult;import org.springframework.data.neo4j.core.schema.Property;@QueryResult public class UserFriendDTO { private User user; private String relationType; private User friend; private LocalDate since; }
Neo4jClient 在很多复杂查询的时候,基础的 Repository 不够用,此时
Neo4jClient 就需要大量使用
注入
1 2 @Resource private Neo4jClient neo4jClient;
执行 Cypher,绑定参数,映射 DTO
最后,Neo4j 事务和 Spring 一致,就是加个
@Transactional,对于隔离级别,Neo4j 仅支持
READ_COMMITTED
响应式开发
Neo4j 4.0
以后,支持了响应式流,能做到非阻塞、按需取数据、自动防过载,特别适合高并发、大数据量的图数据库场景。Neo4j(4.0+
版本)结合了 响应式宣言
(Reactive Manifesto)
的原则,用于通过驱动程序在数据库和客户端之间传递数据。开发人员可以利用响应式方法来处理查询并返回结果。这意味着驱动程序与数据库之间的通信可以根据客户端的数据需求进行动态管理和调整。
Neo4j
支持的响应式宣言,主要内容是如下,而且基本也对应了现代高并发系统的 4
个标准:
即时响应(快)
弹性(压力大也不崩)
弹性伸缩(资源自动调节)
消息驱动(异步、非阻塞)
响应式编程原则允许消费方(应用程序和其他系统)指定在特定时间窗口内接收的数据量。Neo4j
数据库驱动程序还将维护从服务器请求数据的速率限制,从而在整个 Neo4j
堆栈中提供流控。
什么意思,数据库是有可能一股脑地把所有数据推给你,不管你扛不扛得住。现在的话你要多少,数据库给多少;你能处理多快,数据库发多快。而且消费方能指定接收数据量,也就是背压
无论数据多大、并发多高,因为响应式对于数据一条一条流式读取 ,不占满内存,会自动控制速率,所以说就不会因为数据量太大而崩
而 Neo4j 的响应式的底层引擎也是 Project Reactor
Spring Data Neo4j 6 内置了 OGM(对象图映射),不再需要单独库,能把把
Java 对象与 Neo4j 节点 / 关系 自动互相转换,而且支持不可变实体
使用响应式开发改写项目
首先 Neo4j 响应式的依赖跟以前的非响应式的不太一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-webflux</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-neo4j-reactive</artifactId > </dependency > <dependency > <groupId > org.neo4j.driver</groupId > <artifactId > neo4j-java-driver-reactive</artifactId > </dependency >
那么使用响应式,相关的持久层就要这么写了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public interface ReactiveUserRepository extends ReactiveNeo4jRepository <User, String> { Mono<User> findByName (String name) ; Flux<User> findByAgeBetween (Integer minAge, Integer maxAge) ; @Query("MATCH (u:User)-[:FOLLOWS]->(f:User) WHERE elementId(u) = $userId RETURN f.name") Flux<String> findFollowingNamesByUserId (@Param("userId") String userId) ; @Query("MATCH (u1:User)-[:FOLLOWS]->(u2:User), (u2)-[:FOLLOWS]->(u1) " + "WHERE elementId(u1) = $u1Id AND elementId(u2) = $u2Id RETURN count(*) > 0") Mono<Boolean> isMutualFollow (@Param("u1Id") String u1Id, @Param("u2Id") String u2Id) ; @Query("MATCH (u1:User)-[r:FOLLOWS]->(u2:User) WHERE elementId(u1) = $u1Id AND elementId(u2) = $u2Id DELETE r") Mono<Void> deleteFollowRelationship (@Param("u1Id") String u1Id, @Param("u2Id") String u2Id) ; @Query("MATCH (me:User)-[:FOLLOWS]->(:User)-[:FOLLOWS]->(rec:User) " + "WHERE elementId(me) = $userId AND elementId(rec) <> $userId " + "AND NOT (me)-[:FOLLOWS]->(rec) " + "RETURN DISTINCT rec") Flux<User> findRecommendedUsers (@Param("userId") String userId) ; }
可以很明显的看到,继承的是 ReactiveNeo4jRepository,而非
Neo4jRepository,但,其余写法完全一样,本质 Spring Data
自动处理不变,只不过调用的逗是 Neo4j 的响应式 API
然后所有返回值换成 Mono<T>(单个结果)或
Flux<T>(多个结果)
对于响应式的异步数据流的内容,这里简单提一下,需要注意的是,响应式代码中绝对不能调用非响应式的API
概念
说明
Mono<T>0或1个结果的异步流,类比 Optional 但非阻塞
Flux<T>0到N个结果的异步流,类比 List 但非阻塞
flatMap把一个流中的元素变换成新流(有IO操作时用)
map把一个流中的元素同步变换(无IO操作时用)
Mono.zip并发等待多个Mono,全部完成后合并
switchIfEmpty流为空时执行备用逻辑(如抛出异常)
take(n)只取Flux的前n个元素
两者的区别大概如下,在持久层这个层面
1 2 3 4 5 6 7 8 阻塞式 响应式 ───────────────────────────────────────────────────── Neo4jRepository ReactiveNeo4jRepository Optional<User> Mono<User> List<User> Flux<User> findById(id) findById(id) ← 签名相同,返回类型不同 userRepo.save(user) userRepo.save(user).flatMap(...) @Transactional @Transactional ← 响应式事务同样支持
服务层并无太大区别,只不过是接受数据的时候使用 Mono 和 Flux
接收异步数据流罢了,就说白了,之前是这样的
单个对象 → User /
Optional<User>
多个对象 → List<User>
没有返回值 → void
这次变成这样的了
单个对象 → Mono<User>
多个对象 → Flux<User>
没有返回值 → Mono<Void>
因为响应式不直接返回数据,返回的是待执行的异步任务,框架会在真正需要时执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 @Service @RequiredArgsConstructor public class ReactiveUserService { private final ReactiveUserRepository userRepository; public Mono<UserDTO> getUserById (String id) { return userRepository.findById(id) .map(UserDTO::from); } @Transactional public Mono<UserDTO> createUser (User user) { return userRepository.save(user) .map(UserDTO::from); } @Transactional public Mono<UserDTO> updateUser (String id, User updateData) { return userRepository.findById(id) .map(user -> { user.setName(updateData.getName()); user.setAge(updateData.getAge()); user.setEmail(updateData.getEmail()); return user; }) .flatMap(userRepository::save) .map(UserDTO::from) .switchIfEmpty(Mono.error(new RuntimeException ("用户不存在: " + id))); } @Transactional public Mono<Void> deleteUser (String id) { return userRepository.deleteById(id); } @Transactional public Mono<UserDTO> followUser (String userId, String targetId) { Mono<User> userMono = userRepository.findById(userId) .switchIfEmpty(Mono.error(new RuntimeException ("用户不存在: " + userId))); Mono<User> targetMono = userRepository.findById(targetId) .switchIfEmpty(Mono.error(new RuntimeException ("目标用户不存在: " + targetId))); return Mono.zip(userMono, targetMono) .flatMap(tuple -> { User user = tuple.getT1(); User target = tuple.getT2(); user.follow(target); return userRepository.save(user); }) .map(UserDTO::from); } @Transactional public Mono<Void> unfollowUser (String userId, String targetId) { Mono<User> userMono = userRepository.findById(userId) .switchIfEmpty(Mono.error(new RuntimeException ("用户不存在: " + userId))); Mono<User> targetMono = userRepository.findById(targetId) .switchIfEmpty(Mono.error(new RuntimeException ("目标用户不存在: " + targetId))); return Mono.zip(userMono, targetMono) .flatMap(tuple -> { User user = tuple.getT1(); User target = tuple.getT2(); user.unfollow(target); return userRepository.save(user) .then(userRepository.deleteFollowRelationship(userId, targetId)); }); } public Flux<UserDTO> getUsersByAgeBetween (Integer minAge, Integer maxAge) { return userRepository.findByAgeBetween(minAge, maxAge) .map(UserDTO::from); } public Flux<String> getFollowingNames (String userId) { return userRepository.findFollowingNamesByUserId(userId); } public Flux<String> getFollowingNamesByUserName (String name) { return userRepository.findByName(name) .switchIfEmpty(Mono.error(new RuntimeException ("用户不存在: " + name))) .flatMapMany(user -> userRepository.findFollowingNamesByUserId(user.getId())); } public Mono<Boolean> checkMutualFollow (String u1Id, String u2Id) { return userRepository.isMutualFollow(u1Id, u2Id); } public Flux<UserDTO> getRecommendedUsers (String userId, int limit) { return userRepository.findRecommendedUsers(userId) .map(UserDTO::from) .distinct() .take(limit); } }
其他的一些响应式的 API 我就简单说说了
操作符
作用
非响应式
map()同步修改数据,不查库
user.setXXX()
flatMap()执行新异步操作(查库 / 保存)
方法调用
zip()并行执行多个查询
串行查询(响应式更快)
switchIfEmpty()空值时返回默认 / 错误
if == null
then()前一个执行完再执行下一个
两行代码顺序执行
然后是控制器层,这一层变化也不大,你注入响应式
Service,那么就需要写响应式的 Controller
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 @RestController @RequestMapping("/reactive/users") @RequiredArgsConstructor public class ReactiveUserController { private final ReactiveUserService userService; @GetMapping("/{id}") public Mono<UserDTO> getUserById (@PathVariable String id) { return userService.getUserById(id); } @PostMapping @ResponseStatus(HttpStatus.CREATED) public Mono<UserDTO> createUser (@RequestBody User user) { return userService.createUser(user); } @PutMapping("/{id}") public Mono<UserDTO> updateUser (@PathVariable String id, @RequestBody User user) { return userService.updateUser(id, user); } @DeleteMapping("/{id}") @ResponseStatus(HttpStatus.NO_CONTENT) public Mono<Void> deleteUser (@PathVariable String id) { return userService.deleteUser(id); } @PostMapping("/{userId}/follow/{targetId}") public Mono<UserDTO> followUser (@PathVariable String userId, @PathVariable String targetId) { return userService.followUser(userId, targetId); } @DeleteMapping("/{userId}/unfollow/{targetId}") @ResponseStatus(HttpStatus.NO_CONTENT) public Mono<Void> unfollowUser (@PathVariable String userId, @PathVariable String targetId) { return userService.unfollowUser(userId, targetId); } @GetMapping("/age-range") public Flux<UserDTO> getUsersByAgeBetween ( @RequestParam Integer minAge, @RequestParam Integer maxAge) { return userService.getUsersByAgeBetween(minAge, maxAge); } @GetMapping(value = "/age-range/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux<UserDTO> getUsersByAgeBetweenStream ( @RequestParam Integer minAge, @RequestParam Integer maxAge) { return userService.getUsersByAgeBetween(minAge, maxAge); } @GetMapping("/following-names") public Flux<String> getFollowingNames (@RequestParam String userName) { return userService.getFollowingNamesByUserName(userName); } @GetMapping("/check-mutual") public Mono<Boolean> checkMutualFollow ( @RequestParam String u1Id, @RequestParam String u2Id) { return userService.checkMutualFollow(u1Id, u2Id); } @GetMapping("/{userId}/recommendations") public Flux<UserDTO> getRecommendations ( @PathVariable String userId, @RequestParam(defaultValue = "5") int limit) { return userService.getRecommendedUsers(userId, limit); } }
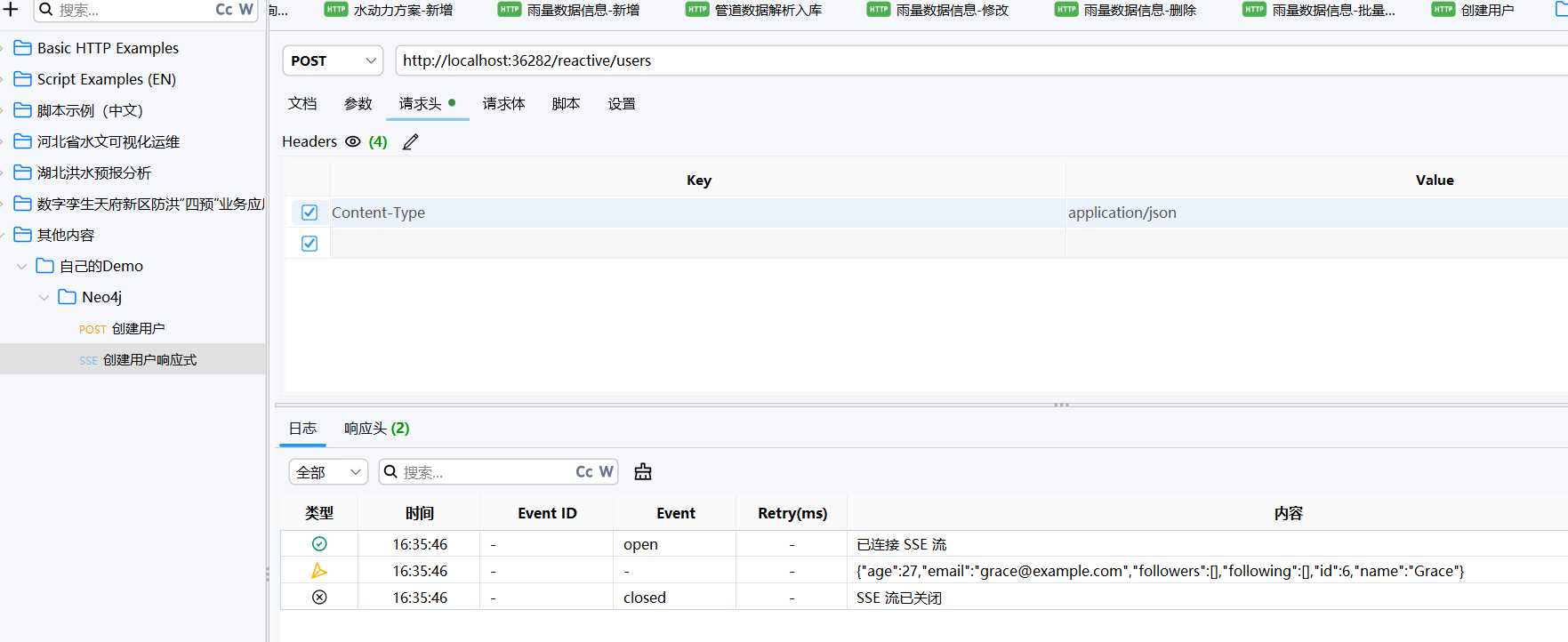
提一下流式查询 SSE 的相关内容,普通 Flux 查询所有数据,SSE 流式 Flux
加了 produces,查到一条数据立刻推送
1 2 3 4 5 6 7 8 9 10 11 @GetMapping("/age-range") public Flux<User> getUsersByAgeBetween (...) { return userService.getUsersByAgeBetween(...); } @GetMapping(value = "/age-range/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux<User> getUsersByAgeBetweenStream (...) { return userService.getUsersByAgeBetween(...); }
其他的很明显,注解完全不变
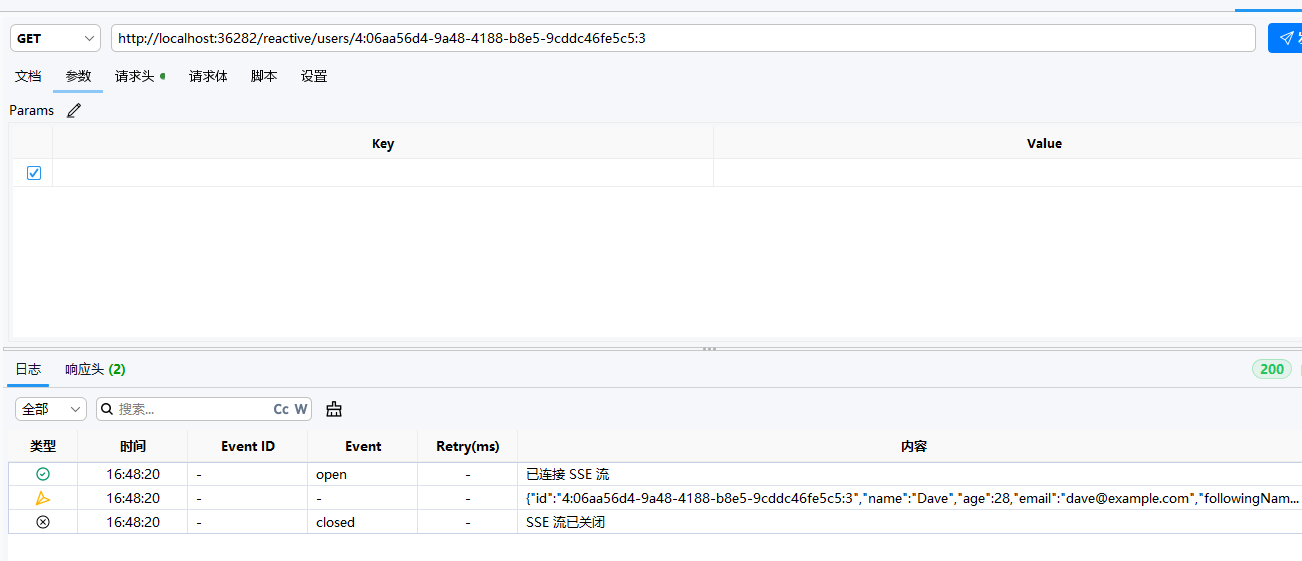
我们来体验一下
image-20260514163559338
可以看到流式查询非常迅速,而且服务压力很小
image-20260514164851259
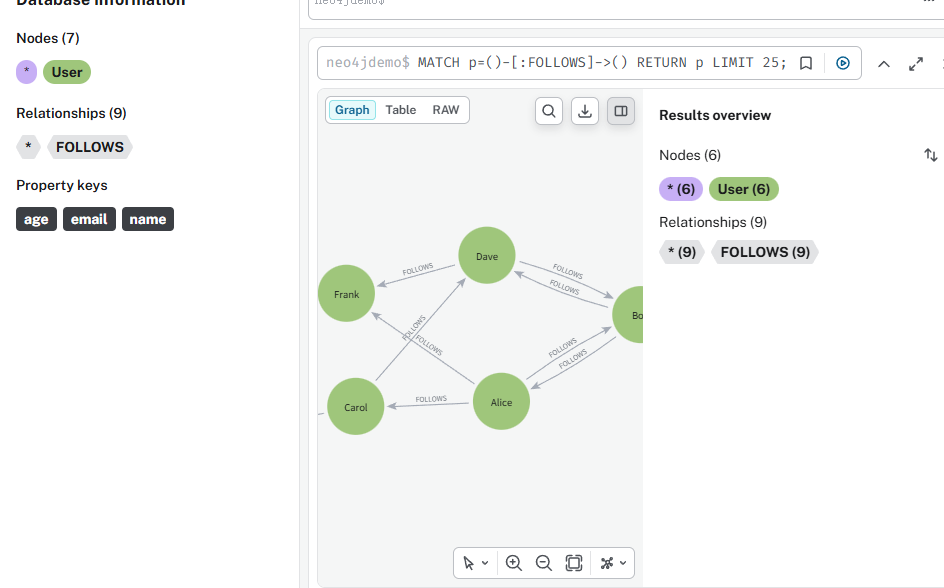
查询关注信息,调整关注情况,使用 Neo4j
这种图数据库,操作方便,性能不错,直观性高
image-20260514165305285