
什么是负载均衡
在前面其实已经进行了比较详尽的说明了,但是在这里我还是再说两句。
大型网站都要面对庞大的用户量,高并发,海量数据等挑战。为了提升系统整体的性能,可以采用垂直扩展和水平扩展两种方式。
- 垂直扩展:在网站发展早期,可以从单机的角度通过增加硬件处理能力,比如 CPU 处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升。但是,单机是有性能瓶颈的,一旦触及瓶颈,再想提升,付出的成本和代价会极高。这显然不能满足大型分布式系统(网站)所有应对的大流量,高并发,海量数据等挑战。
- 水平扩展:通过集群来分担大型网站的流量。集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点,这些节点共同分担访问压力。水平扩展有两个要点:
- 应用集群:将同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。
- 负载均衡:将用户访问请求,通过某种算法,分发到集群中的节点。
当有多个服务提供者实例(比如多台服务器部署了同一用户服务)时,负载均衡能帮服务消费者合理挑选一个实例发请求,避免单个实例被请求 “压垮”,让流量更均匀地分配,提升系统整体稳定性和效率。是高并发、高可用系统必不可少的关键组件,目标是 尽力将网络流量平均分发到多个服务器上,以提高系统整体的响应速度和可用性。
负载均衡有两方面的含义:
- 首先,大量的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间;将大量的并发处理转发给后端多个节点处理,减少工作响应时间;
- 其次,单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后,将结果汇总,返回给用户,系统处理能力得到大幅度提高。将单个繁重的工作转发给后端多个节点处理,处理完再返回给负载均衡中心,再返回给用户。
负载均衡的主要作用如下:
高并发:负载均衡通过算法调整负载,尽力均匀的分配应用集群中各节点的工作量,以此提高应用集群的并发处理能力(吞吐量)。
伸缩性:添加或减少服务器数量,然后由负载均衡进行分发控制。这使得应用集群具备伸缩性。
高可用:负载均衡器可以监控候选服务器,当服务器不可用时,自动跳过,将请求分发给可用的服务器。这使得应用集群具备高可用的特性。
安全防护:有些负载均衡软件或硬件提供了安全性功能,如:黑白名单处理、防火墙,防 DDos 攻击等。
负载均衡的分类
支持负载均衡的技术很多,我们可以通过不同维度去进行分类。
软硬件负债均衡
从支持负载均衡的载体来看,可以将负载均衡分为两类:硬件负载均衡、软件负载均衡
硬件负载均衡,一般是在定制处理器上运行的独立负载均衡服务器,价格昂贵,土豪专属。硬件负载均衡的主流产品有:F5 和 A10。
软件负载均衡,应用最广泛,无论大公司还是小公司都会使用。
软件负载均衡从软件层面实现负载均衡,一般可以在任何标准物理设备上运行。
软件负载均衡的 主流产品 有:Nginx、HAProxy、LVS。
LVS 可以作为四层负载均衡器。其负载均衡的性能要优于 Nginx。
HAProxy 可以作为 HTTP 和 TCP 负载均衡器。
Nginx、HAProxy 可以作为四层或七层负载均衡器。
四七层负债均衡
软件负载均衡从通信层面来看,又可以分为四层和七层负载均衡。
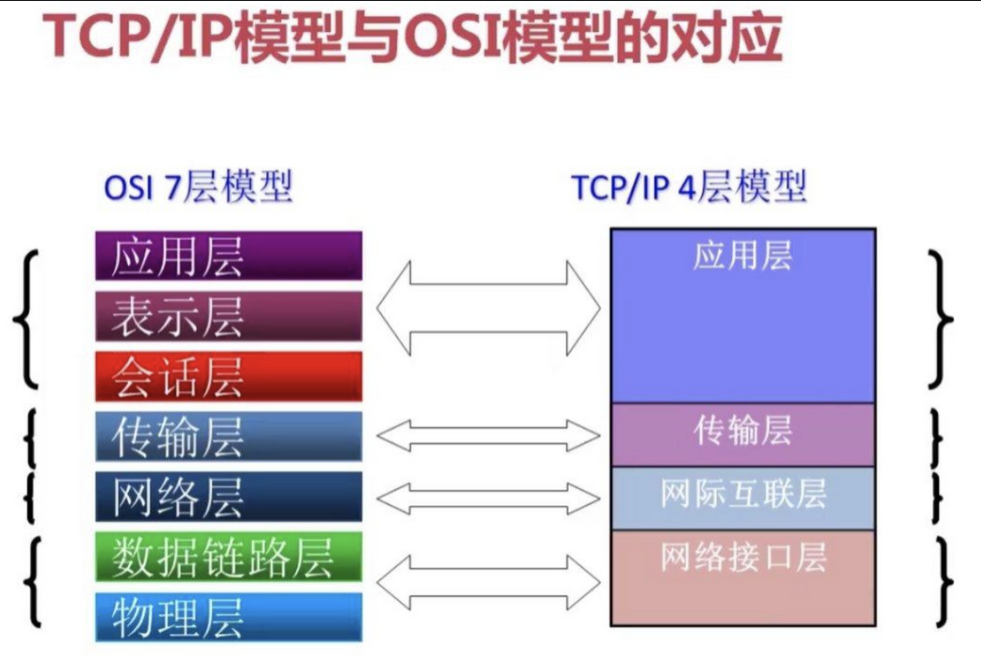
服务端负载均衡器和客户端负载均衡器的区别如下图所示:
七层负载均衡:就是可以根据访问用户的 HTTP 请求头、URL 信息将请求转发到特定的主机。七层负载均衡七层负载均衡工作在OSI模型的应用层,应用层协议较多,常用http、radius、dns等。七层负载就可以基于这些协议来负载。
- DNS 重定向
- HTTP 重定向
- 反向代理- 四层负载均衡:基于 IP
地址和端口进行请求的转发。工作在OSI模型的传输层。四层负载均衡服务器在接受到客户端请求后,以后通过修改数据包的地址信息(IP+端口号)将流量转发到应用服务器。
- 修改 IP 地址
- 修改 MAC 地址
DNS 负债均衡
DNS 负载均衡一般用于互联网公司,复杂的业务系统不适合使用。大型网站一般使用 DNS 负载均衡作为 第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。DNS 负载均衡属于七层负载均衡。
DNS(域名解析服务 ),遵循 OSI 第七层网络协议,是树形结构的分布式应用。架构包含根域名服务器、各级域名服务器(一级、二级等 )、本地域名服务器 。为避免根服务器负载过大,DNS 查询采用逆向递归流程:客户端先请求本地 DNS 服务器,若未命中,依次向上级(上一级、根服务器 )查询,一旦命中就返回结果,且各级服务器会缓存查询结果减少重复查询。
DNS 负载均衡的工作原理就是:基于 DNS 查询缓存,依据服务器负载情况,返回不同服务器的 IP 地址,以此实现负载分配。
- 优点
- 使用简单:无需自行维护负载均衡服务器,把负载均衡逻辑交给 DNS 服务器处理。
- 提升性能:支持基于地址的域名解析,能将域名解析为距离用户最近的服务器 IP(类似 CDN 原理 ),加快用户访问速度。
- 缺点
- 可用性欠佳:DNS 是多级解析,新增或修改 DNS 记录后,解析生效时间长(受 TTL 等影响 );解析过程中若 DNS 异常,用户访问易失败。
- 扩展性有限:负载均衡控制权在域名服务商,难以自主扩展、优化策略。
- 维护性差:无法实时反映服务器运行状态(如服务器故障不能及时感知 );支持的负载均衡算法少,也不能依据服务器差异(如性能、服务状态 )智能分配负载。
HTTP 负债均衡
HTTP 负载均衡是基于 HTTP 重定向实现的。HTTP 负载均衡属于七层负载均衡。负载均衡器接收用户 HTTP 请求后,计算出真实应访问的服务器地址,将该地址写入 HTTP 重定向响应(如 302 跳转 ),返回给浏览器,由浏览器重新发起对真实服务器的访问。
HTTP 重定向的优点:方案简单。
HTTP 重定向的 缺点:由于其缺点比较明显,所以这种负载均衡策略实际应用较少
- 性能较差:每次访问需要两次请求服务器,增加了访问的延迟。
- 降低搜索排名:使用重定向后,搜索引擎会视为 SEO 作弊。
- 如果负载均衡器宕机,就无法访问该站点。
反向代理负债均衡
反向代理(Reverse Proxy)方式是指以 代理服务器 来接受网络请求,然后 将请求转发给内网中的服务器,并将从内网中的服务器上得到的结果返回给网络请求的客户端。反向代理负载均衡属于七层负载均衡。
反向代理属于七层负载均衡,以代理服务器(如 Nginx、Apache )为中间层,接收客户端网络请求,转发给内网中的真实服务器,再把真实服务器的响应结果返回给客户端 。整个过程客户端无感知,代理服务器隐藏了真实服务器架构。
反向代理服务的主流产品:Nginx、Apache。
正向代理与反向代理有什么区别?
- 正向代理:发生在客户端侧,由用户主动发起。比如翻墙软件,客户端明确通过代理服务器访问外网,代理服务器代替客户端获取数据后回传。
- 反向代理:发生在服务端侧,用户完全不知道代理存在。用户直接访问代理服务器(以为是真实服务 ),实际请求由代理转发给内网服务器处理。。
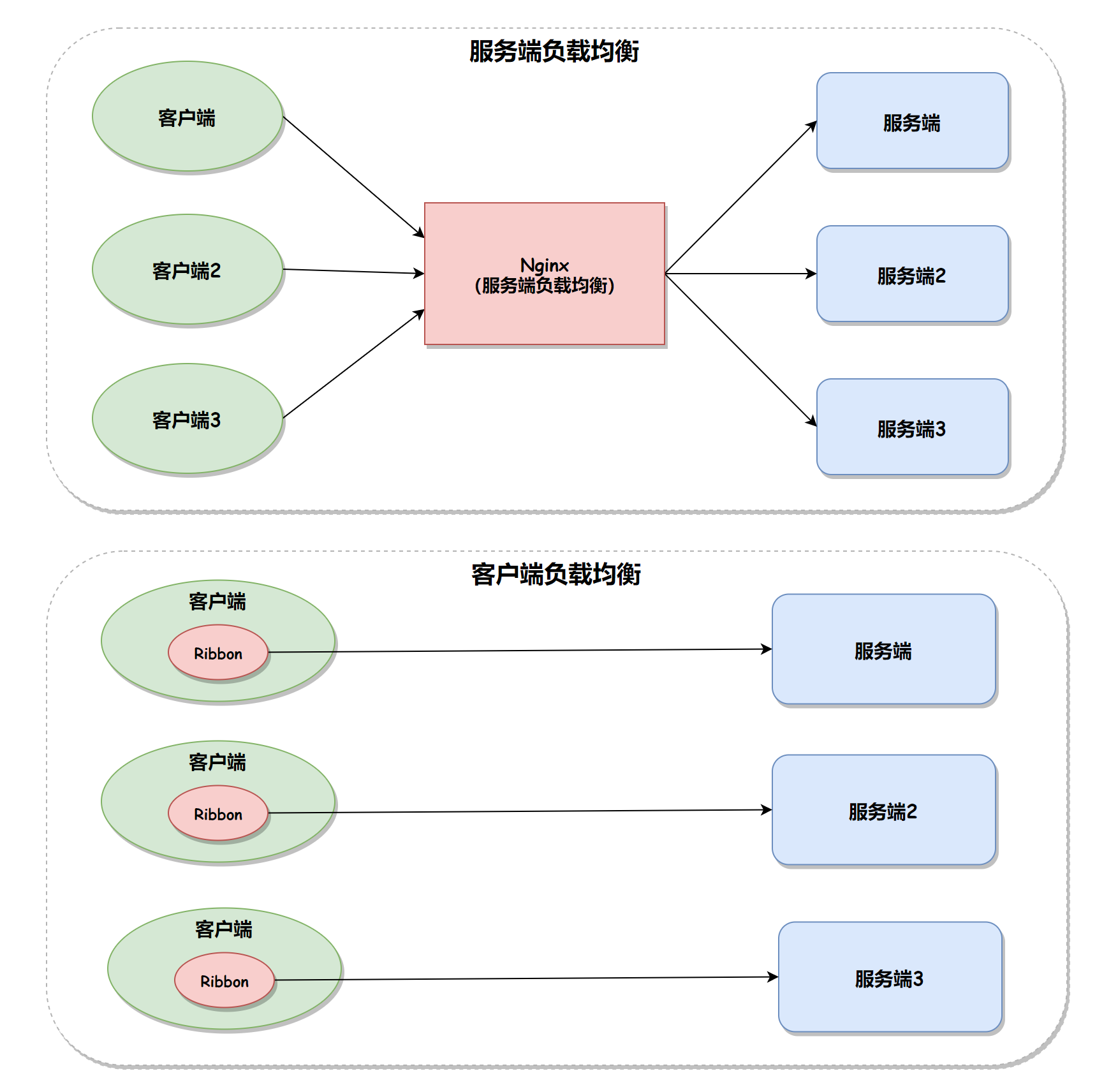
Ribbon 负载均衡的原理
工作机制
在前面,我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理、什么策略呢?
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。
那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?为什么我们只输入了service名称就可以访问了呢?它的请求发出之前肯定还是要做一些处理,找到真实的 ip 和端口,ribbon拦截后肯定是找真实地址,然后找对应的地址是什么服务,这里服务的拉取就是从注册中心 Erueka 拉取。而这个端口怎么挑选,选择的策略,就是负载均衡的体现。
这其实就是涉及到 Ribbon 实现的 负载均衡
的实例选择,Ribbon是拦截了这个请求,然后使用LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从
Eureka 根据服务 id
获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务
id。
Ribbon 是 Spring Cloud 中一个基于 HTTP 和 TCP 的客户端负载均衡工具,它主要负责从服务注册中心获取服务实例列表,并在这些实例中选择一个来发起请求,从而实现负载均衡。
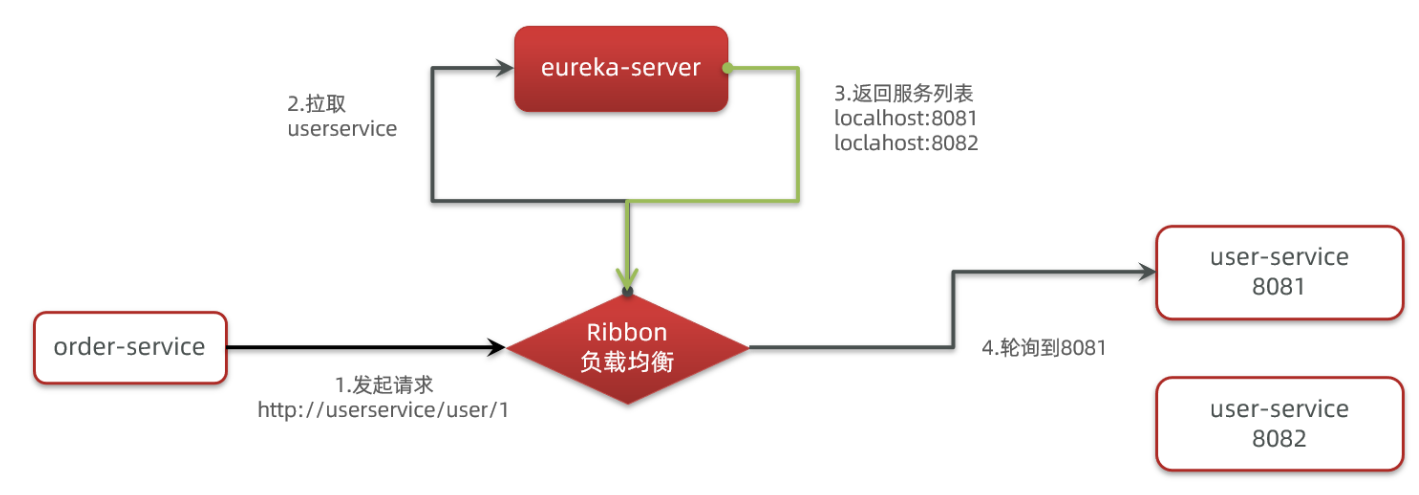
客户端负载均衡器的流程如下
客户端负载均衡器的实现原理是通过注册中心,将可用的服务列表拉取到本地(客户端),再通过客户端负载均衡器(设置的负载均衡策略)获取到某个服务器的具体 ip 和端口,然后再通过 Http 框架请求服务并得到结果,其执行流程如下图所示:
源码分析
目前为止,直接使用旧版本 Ribbon 是很少的一个策略了,如果使用Spring Cloud LoadBalancer,基本没有直接使用旧版 Ribbon的,都是直接用这个 LoadBalancer
LoadBalancerInterceptor 是 Spring Cloud
中实现客户端负载均衡的核心拦截器类,它与 @LoadBalanced
注解配合,让 RestTemplate
具备了通过服务名调用服务并自动负载均衡的能力。
1 | public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor { |
当 RestTemplate 被 @LoadBalanced
注解标记时,Spring 会自动为其添加 LoadBalancerInterceptor
拦截器。因此,RestTemplate 发起的请求会被该拦截器处理,实现
“服务名 → 实际地址” 的转换和负载均衡。
@LoadBalanced这个注解没什么特殊好讲的,实际上,它只是一个标记注解
LoadBalancerInterceptor 的核心逻辑可概括为:
拦截请求 → 提取服务名 → 委托 LoadBalancerClient
执行负载均衡 → 替换地址并发起请求。
而这个 ClientHttpRequestInterceptor 接口是 Spring
框架中主要用于拦截 RestTemplate 发送的 HTTP
请求,主要用于在发送 HTTP 请求前后执行自定义逻辑,这和我们之前自定义
Spring MVC 配置又串联起来了
1 | import java.io.IOException; |
从源码分析实际工作流程
我们来调试一下代码,在这里打上断点
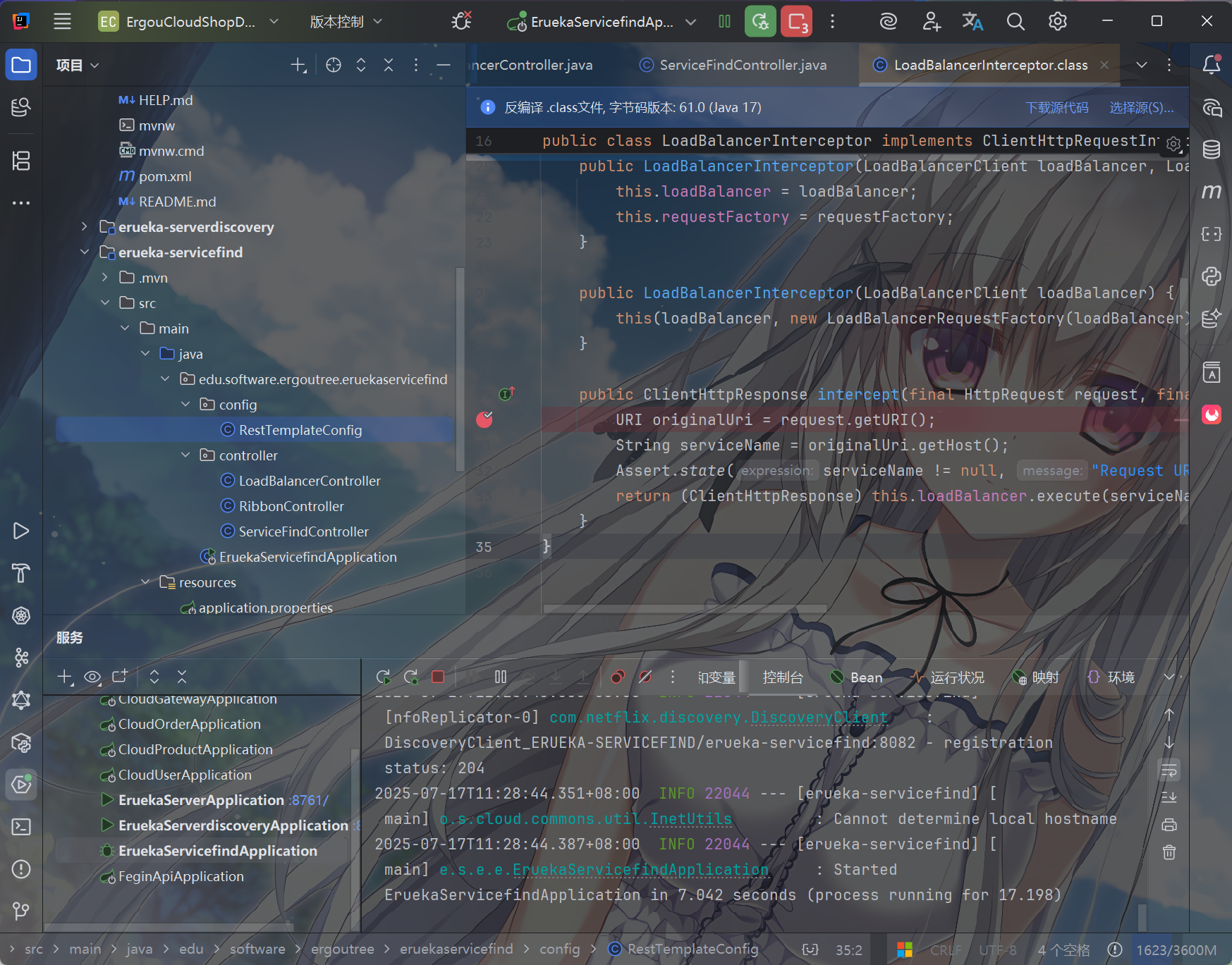
用我们之前的带@LoadBalanced注解的RestTemplate,并且通过服务名发起了请求(如 http://erueka-serverdiscovery/api/instance-info)。
1 | /** |
输入我们的调用指定服务的实例信息API的接口,http://localhost:8082/ribbon/instance-info/erueka-serverdiscovery,进入断点
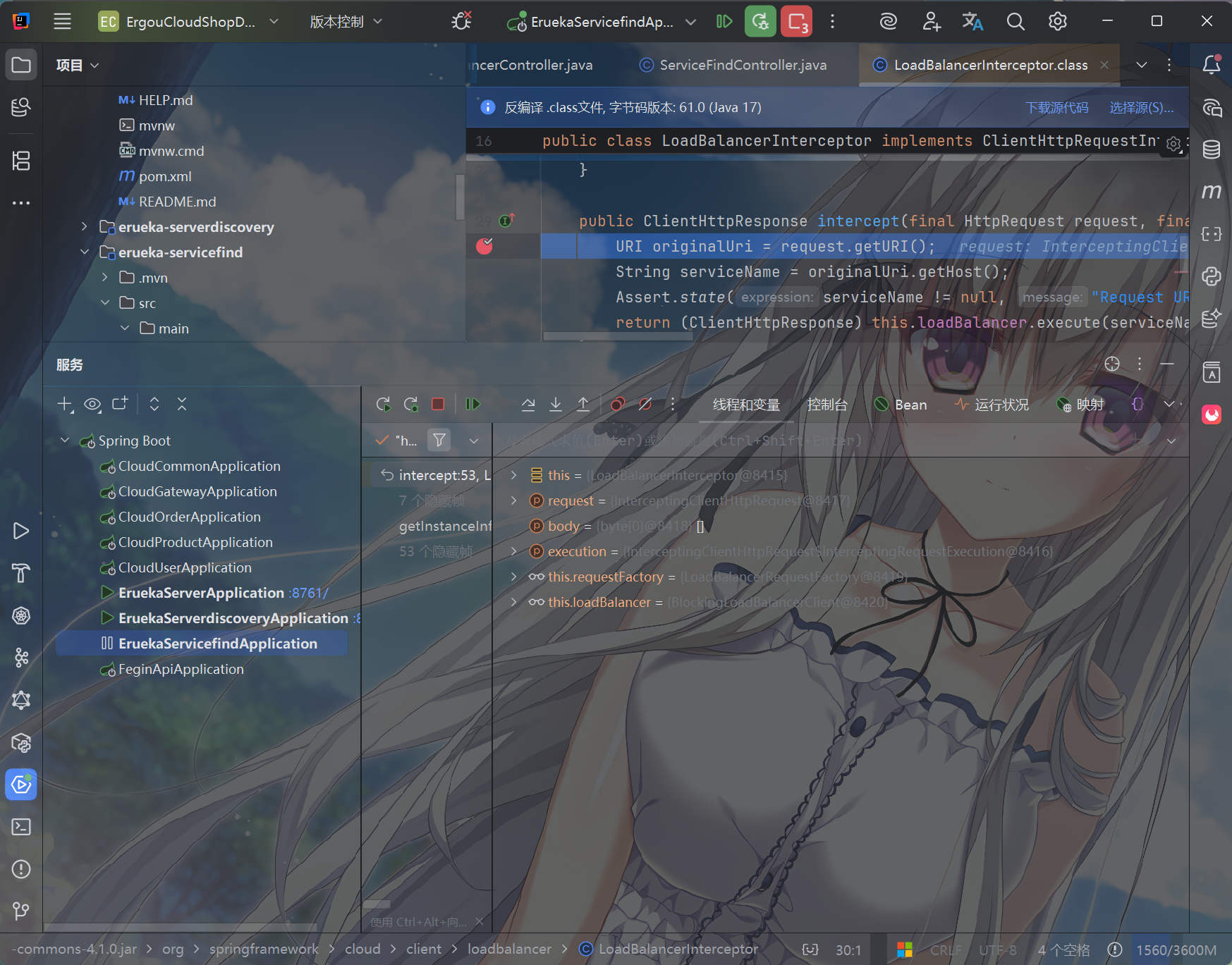
跳两步可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
- request.getURI():获取请求uri,
- originalUri.getHost():获取uri路径的主机名,其实就是服务id名称
- this.loadBalancer.execute():处理服务id名称,和用户请求。
经过这些处理,我们才能看到如下内容
这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入。
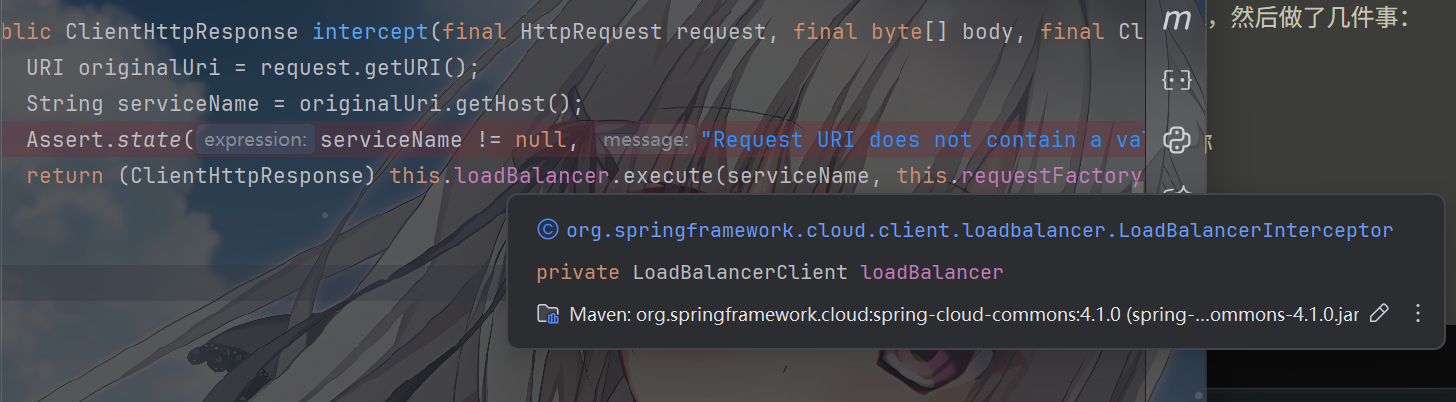
进入其中的 execute 方法
1 | public interface LoadBalancerClient extends ServiceInstanceChooser { |
其中,第一个execute方法(无ServiceInstance参数)是选择合适的服务实例并执行请求,通过this.choose(serviceId, lbRequest)从服务注册中心选择一个可用服务实例,第二个
execute
方法,使用指定的服务实例执行实际请求,触发负载均衡生命周期处理器的onStartRequest事件,通过request.apply(serviceInstance)执行请求
第一个execute方法通过this.choose(...)获取服务实例,先根据serviceId获取对应的负载均衡器(ILoadBalancer)
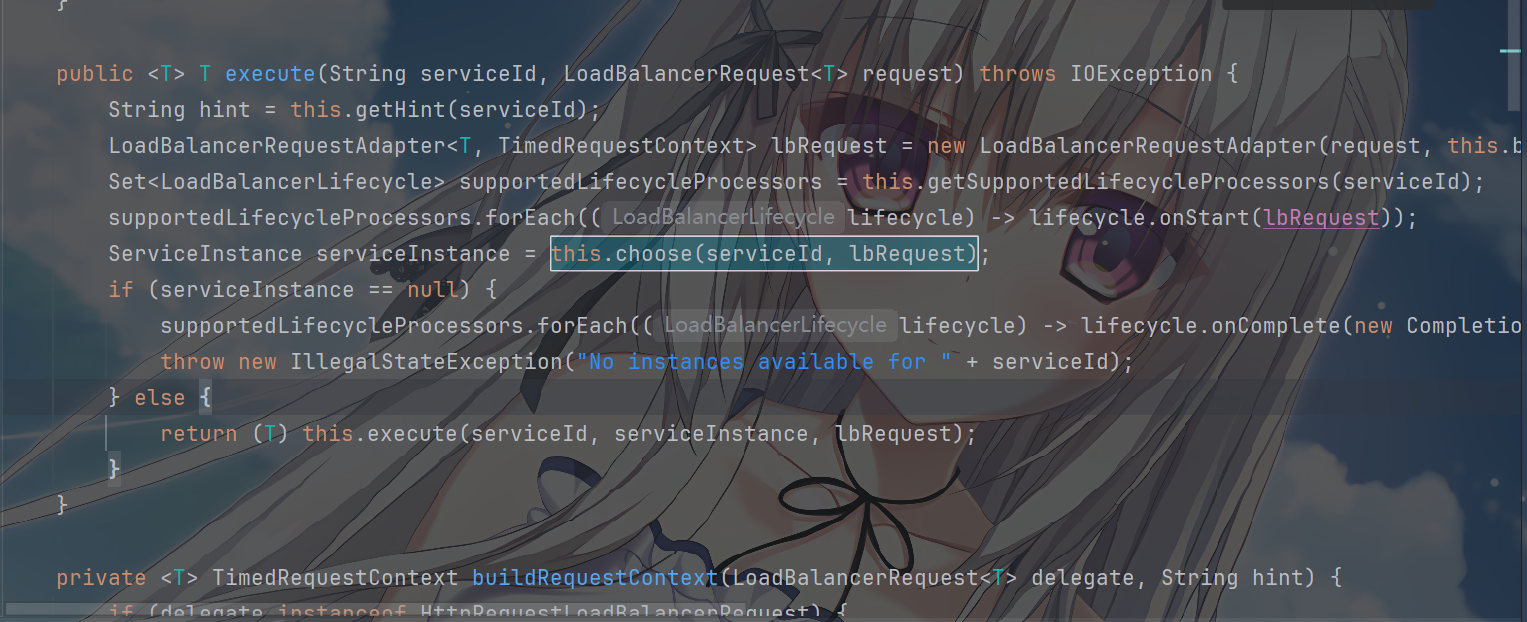
可以看到 choose
方法先根据serviceId获取对应的负载均衡器ILoadBalancer,再通过负载均衡器从注册中心
Erueka 拉取并维护服务列表
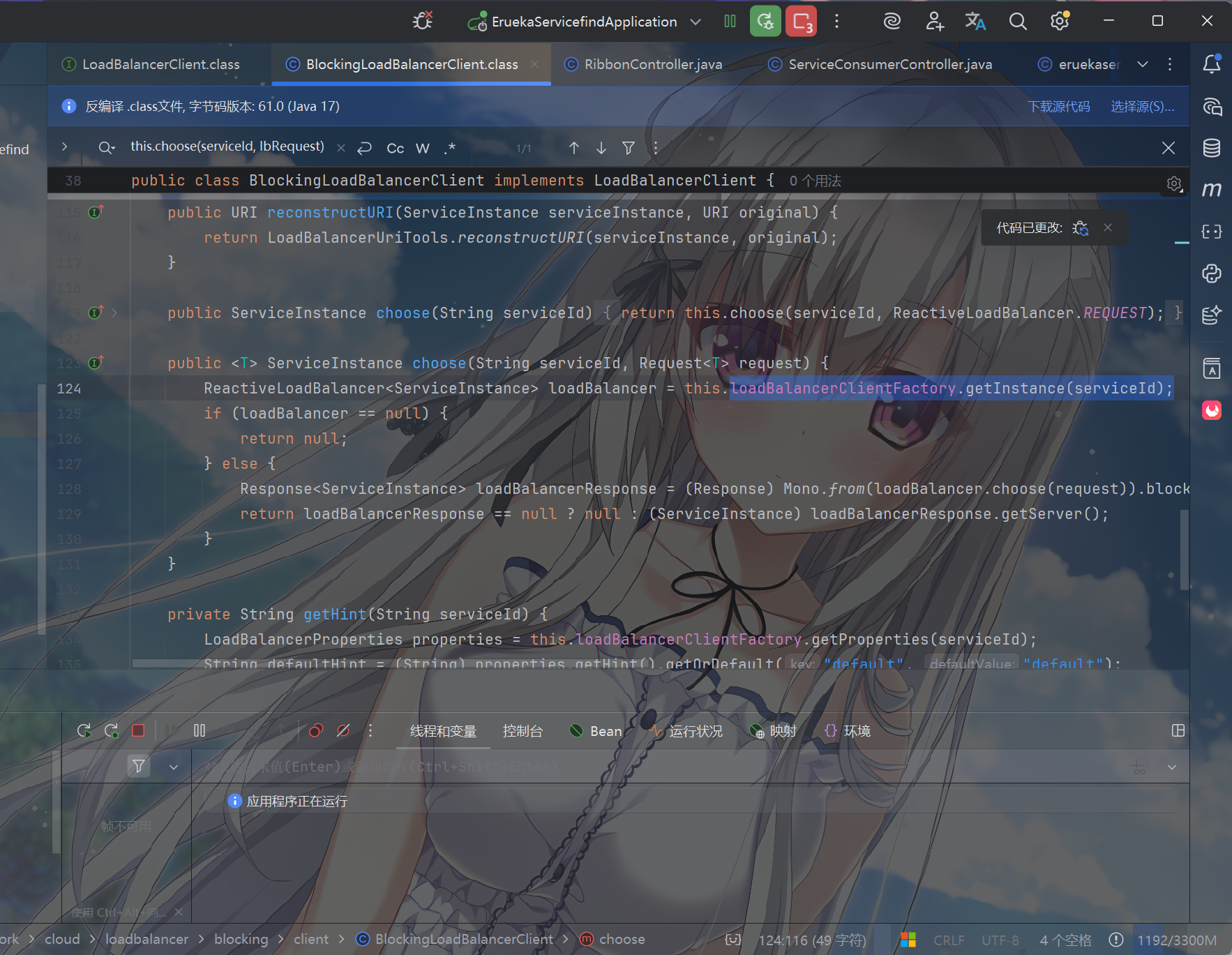
而且,在第一个execute方法中:
1 | ServiceInstance serviceInstance = this.choose(serviceId, lbRequest); |
这行代码的作用就是:通过负载均衡器(ILoadBalancer)中维护的服务列表,应用内置的负载均衡算法(如轮询、随机等),最终选择一个可用的服务实例
放行后,继续跟进步骤,再次访问并跟踪,发现获取的是…..
呃呃我铸币了忘记了部署多个服务,所以只有一个8081,在这里部署多个服务你多访问几次结果肯定是不一样的
到这里,我们就清楚负载均衡的实现和工作流程了,Spring Cloud Ribbon(LoadBalance) 的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。
世界线发生了变动,我装了nextify的ribbon后回来了,这样,再上面选择
excute 方法的实现类中,进入到RibbonLoadBalancerClient
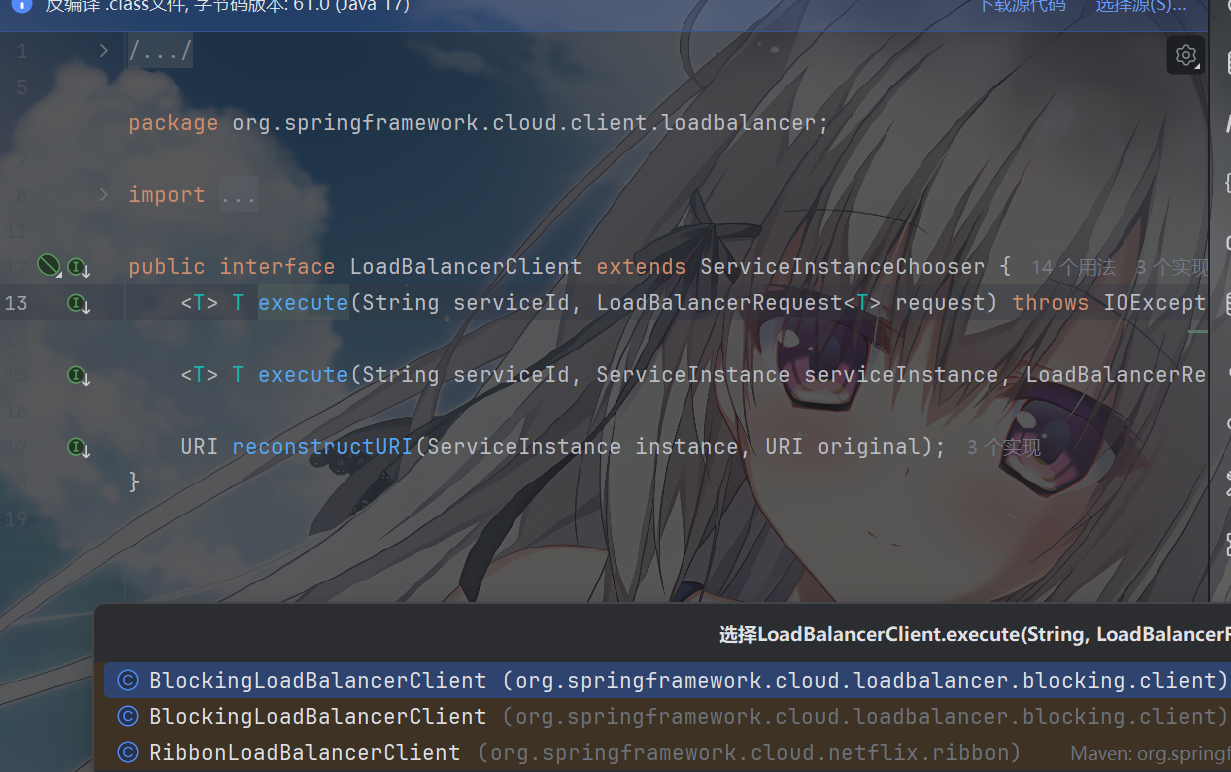
可以看到这里,execute 方法调用了
getServer方法,而在getServer方法中,它调用了内置的负载均衡算法,选择并且返回一个服务,如果这里你开调试,会看到自己的内网
ip
其中
getLoadBalancer(serviceId):根据服务id获取ILoadBalancer,而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。getServer(loadBalancer):利用内置的负载均衡算法,从服务列表中选择一个。
负载均衡策略选择逻辑
在上面的 BlockingLoadBalancerClient 中,第一个 execute
方法中,有这么一段代码
负载均衡器通过loadBalancerClientFactory.getInstance(serviceId)获取,这里的loadBalancer实例默认就是RoundRobinLoadBalancer(Spring
Cloud LoadBalancer 的默认实现)。
1 | ReactiveLoadBalancer<ServiceInstance> loadBalancer = this.loadBalancerClientFactory.getInstance(serviceId); |
我们需要查看其中ReactiveLoadBalancer这个接口,转到其实现

ReactorLoadBalancer(org.springframework.cloud.loadbalancer.core
接口)是Spring Cloud LoadBalancer
中定义负载均衡核心行为的接口,不是具体算法实现。Mono<Response<T>> choose(Request request),要求实现类返回一个包含选中实例的响应式结果。RoundRobinLoadBalancer、RandomLoadBalancer
等都是它的实现类,规范了负载均衡逻辑的基本结构。
1 | public interface ReactorLoadBalancer<T> extends ReactiveLoadBalancer<T> { |
可以看到 Mono 是一个响应式的抽象类,很大很大
可以发现有如下负载均衡的策略,其中
RandomLoadBalancer(org.springframework.cloud.loadbalancer.core)- 随机策略,从可用服务实例列表里,完全随机挑选一个实例。实现简单,通过
ThreadLocalRandom或类似工具生成随机索引,再从实例列表取对应元素。适合实例性能、负载能力相近的场景,能让请求均匀分散,但无法针对实例差异做智能调度。
- 随机策略,从可用服务实例列表里,完全随机挑选一个实例。实现简单,通过
RoundRobinLoadBalancer(org.springframework.cloud.loadbalancer.core)- 轮询策略,维护一个计数器,按顺序循环从服务实例列表中选实例,比如实例列表是
[A, B, C],第 1 次选 A,第 2 次选 B,第 3 次选 C,第 4 次又回到 A…… 保证所有实例被 “轮流” 调用,能在实例性能相近时,让请求绝对均匀分配,是最基础、常用的策略之一
- 轮询策略,维护一个计数器,按顺序循环从服务实例列表中选实例,比如实例列表是
如果你是从 RibbonLoadBalancerClient通过 getServer
进来的话,
1 | protected Server getServer(ILoadBalancer loadBalancer, Object hint) { |
ILoadBalancer就是进行负载均衡策略选择的接口,最后能进入到IRule,可见IRule接口有很多的实现
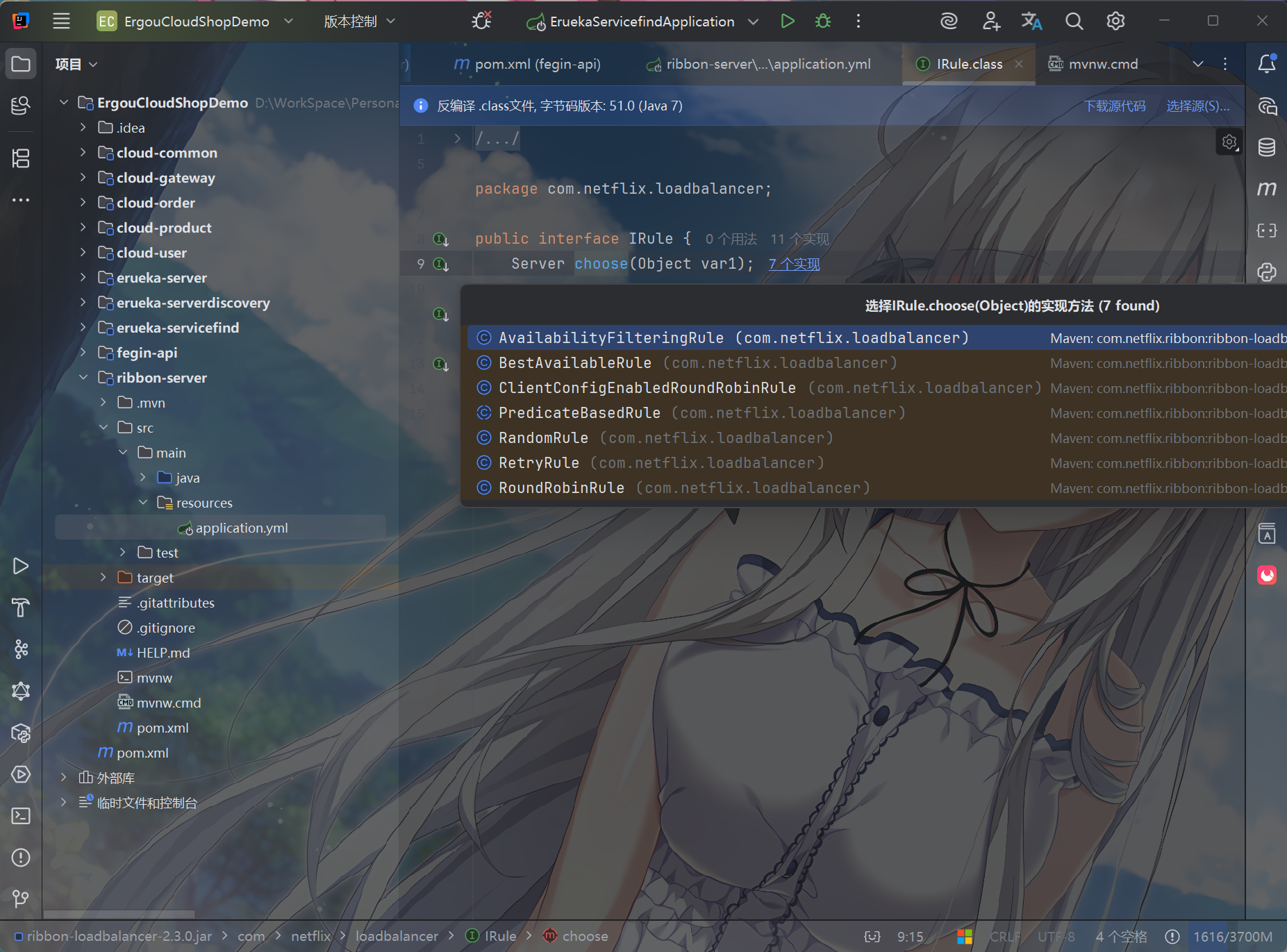
默认的实现就是ZoneAvoidanceRule,是一种轮询方案,默认情况下,浏览器依次按照端口访问实例
Ribbon 的饥饿加载机制
浏览器第一访问用例的时候,通常会比较慢
这是因为:
- Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
- 当客户端第一次向某个服务发起请求时,Ribbon
才会创建对应的
LoadBalanceClient - 在
LoadBalanceClient创建并初始化完成后,Ribbon 会将其缓存起来。后续对同一服务的请求将直接使用这个已经缓存好的LoadBalanceClient,而无需再次进行加载操作。- 当然,如果是别的服务的LoadBalanceClient,还需要加载
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
1 | ribbon: |
负载均衡策略详解
在 Spring Cloud
较新的版本中,spring-cloud-loadbalancer逐渐替代了 Netflix
Ribbon,但是底层机制是一样的,所以我会根据这个讲解,所以才没有 IRule
那七种负载均衡的策略,而spring-cloud-loadbalancer,负载均衡的策略,只有在ReactiveLoadBalancer接口中定义根据choose方法选择的两种实现
但是,我还是会根据 Ribbon 的七种负载均衡的策略讲解,因为你的配置文件中
1 | # Ribbon配置 |
负载均衡的策略选择都是在这里选的,那我不讲这个你不炸了
首先,我们之前在负载均衡的策略选择部分来回进入的地方,会进入到这个接口
IRule,定义了 Ribbon
的负债均衡策略在里面,而IRule有很多不同的实现类:
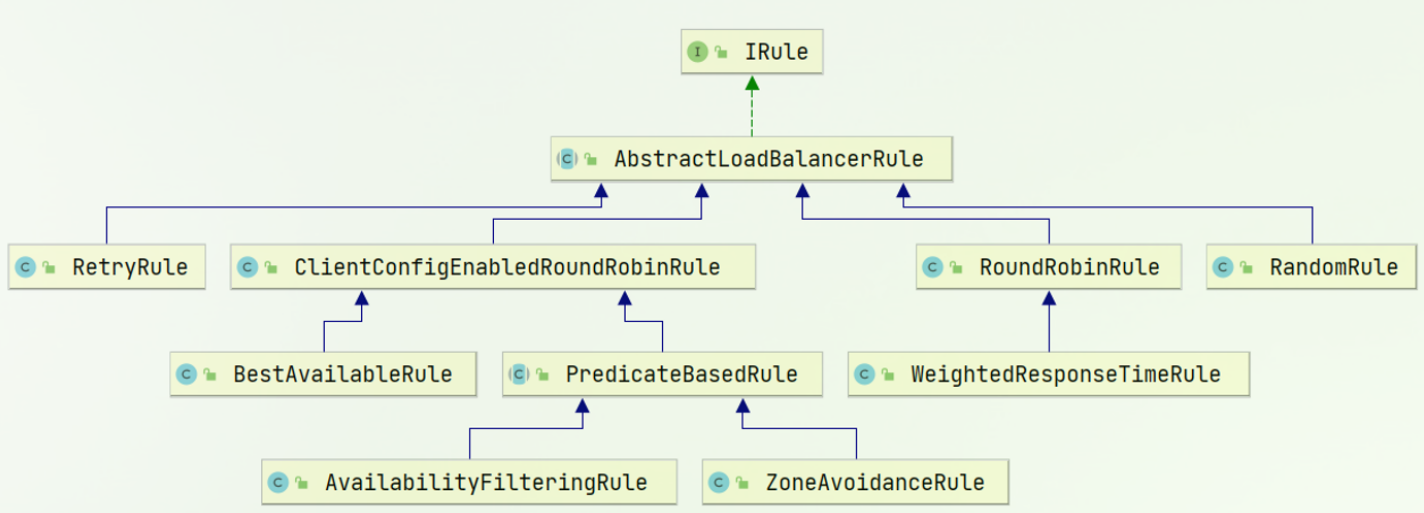
以下是各个实现类的详细解释:
- RoundRobinRule(轮询策略)
- 这是 Ribbon 默认的负载均衡策略。
- 它会按照顺序依次将请求分发到每个服务实例上,实现简单且公平,适用于各个服务实例性能相近的场景。
- RandomRule(随机策略)
- 该策略会在可用的服务实例中随机选择一个来处理请求。
- 它的优点是实现简单,能够避免请求集中在某些实例上,但可能无法充分利用性能较好的实例。
- RetryRule(重试策略)
- 它在一个配置的时间段内,当选择某个实例失败时,会不断尝试选择其他实例。
- 这有助于提高系统的容错性,当某个实例出现短暂故障时,能够通过重试其他实例来保证请求的成功处理。
- WeightedResponseTimeRule(加权响应时间策略)
- 它会根据每个服务实例的平均响应时间来分配权重,响应时间越短的实例权重越高,被选中的概率越大。
- 这种策略能够更合理地分配请求,优先将请求发送到响应速度快的实例上,从而提高整体系统的性能。
- BestAvailableRule(最佳可用策略)
- 它会选择当前并发请求数最少的服务实例。
- 这样可以避免将过多的请求集中到负载较高的实例上,平衡各个实例的负载。
- AvailabilityFilteringRule(可用性过滤策略)
- 它会先过滤掉那些因为多次访问故障而处于断路器跳闸状态的实例,以及并发连接数超过阈值的实例。
- 然后从剩余的实例中选择一个进行请求分发,提高了系统的可用性和稳定性。
- ZoneAvoidanceRule(区域回避策略)
- 它会综合考虑区域的性能和实例的可用性来选择服务实例。
- 它会先判断区域的运行状况,如果区域不可用,则不会在该区域内选择实例;如果区域可用,则再根据实例的可用性等因素进行选择。
总结一下
| 实现类 | 策略名称 | 策略描述 |
|---|---|---|
| RoundRobinRule | 轮询策略 | 简单轮询服务列表来选择服务器,按顺序依次选择服务实例,默认策略 |
| RandomRule | 随机策略 | 在可用实例中随机选择 |
| RetryRule | 重试策略 | 在配置时间段内尝试选择可用实例 |
| WeightedResponseTimeRule | 加权响应时间策略 | 根据响应时间分配权重,响应快的实例权重高,这个权重规则会影响随机选择服务器 |
| BestAvailableRule | 最佳可用策略 | 选择并发请求数最少的实例 |
| AvailabilityFilteringRule | 可用性过滤策略 | 过滤掉故障和高并发实例,选择剩余实例 |
| ZoneAvoidanceRule | 区域回避策略 | 以区域可用的服务器为为基础进行服务器的选择,综合考虑区域性能和实例可用性进行选择 |
源码这个自己看吧,也不难,我全列出来一个个讲,我估计多到网站都加载费劲
Ribbon 负载均衡实践
项目搭建
pom文件引入如下依赖
1 | <!-- Eureka Client --> |
主启动类,在启动类上添加注解
1 |
|
编写一个 Ribbon 的服务层,完成Ribbon负载均衡测试模块的实现
1 |
|
编写控制器层
1 |
|
编写配置文件,Ribbon 提供多种内置策略,可在
application.yml 中配置:
1 | server: |
1 | # 对 某服务 服务配置负载均衡策略 |
演示负载均衡效果
为了测试负载均衡效果,需要启动多个相同服务的实例。
如何在同一个服务使用不同端口启动多个实例,另外开一篇文章说吧,要不然这篇文章东西太多了
反正这里是启动成功了
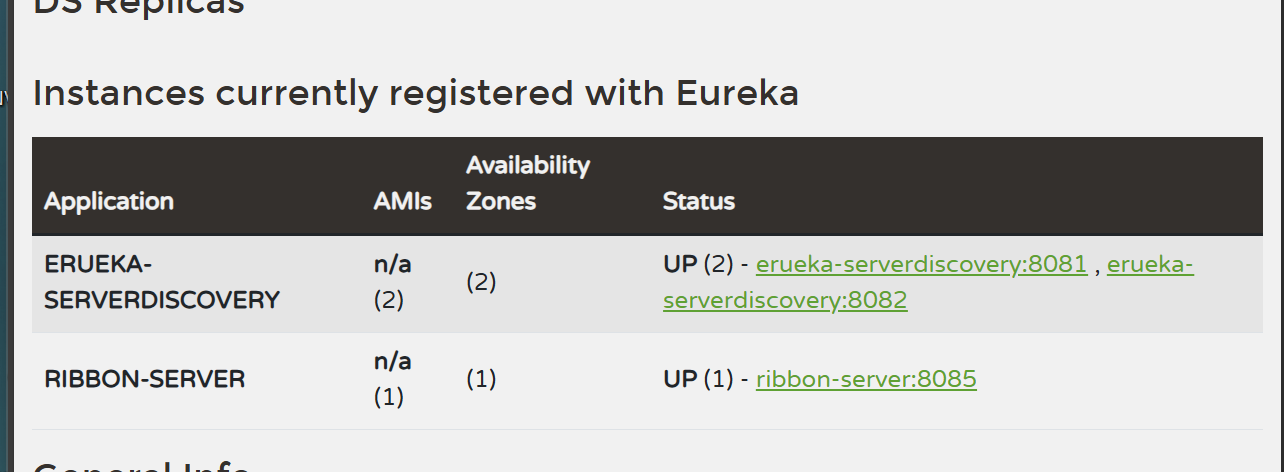
我们查看所有已注册的服务,根据我们的服务层和控制器层,访问http://localhost:8085/ribbon/services,这将返回所有已注册到Eureka的服务名列表。
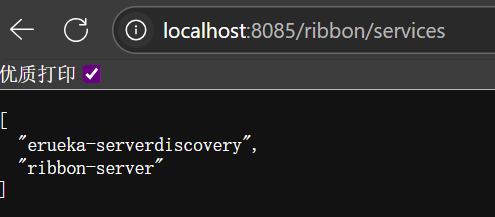
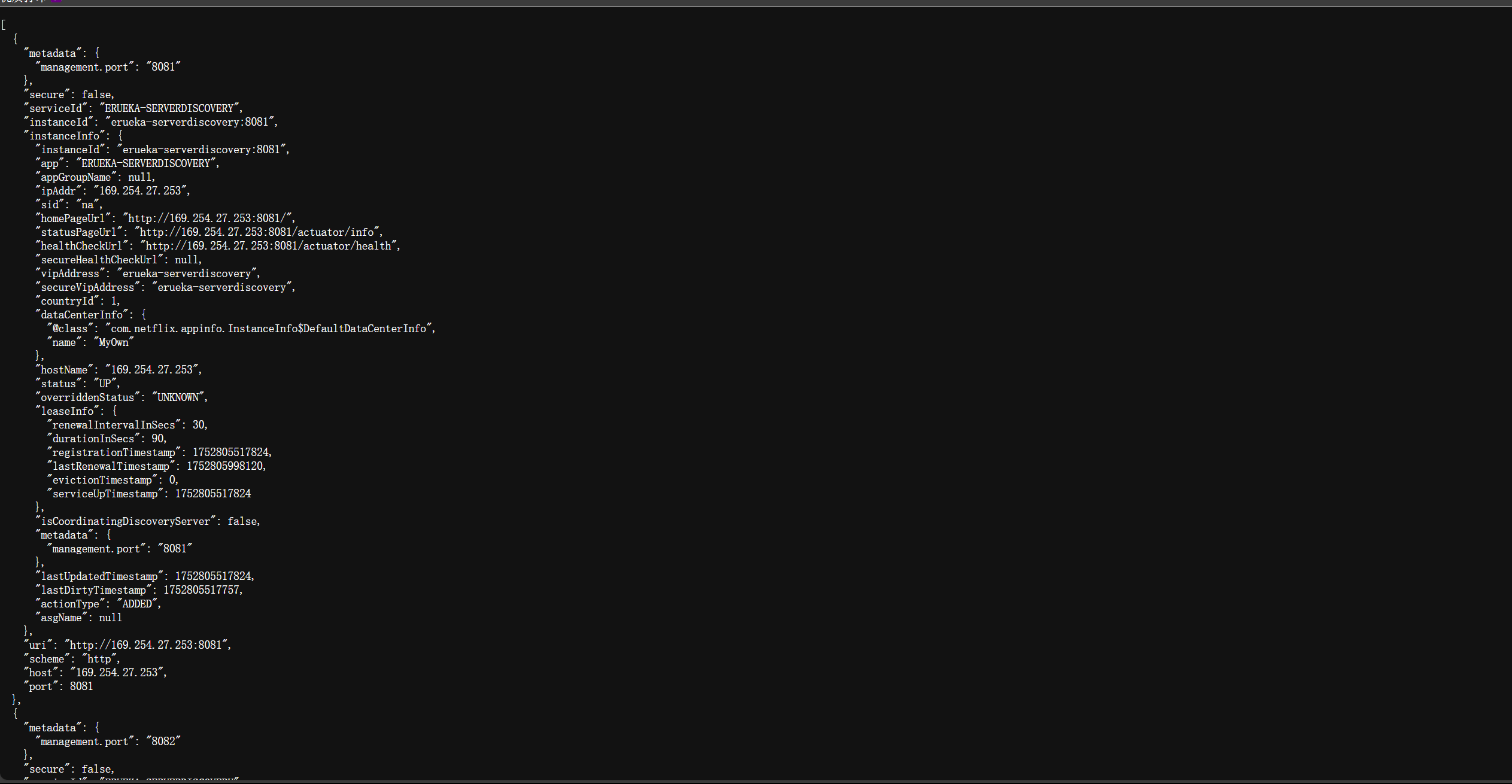
查看指定服务的所有实例,访问http://localhost:8085/ribbon/instances/erueka-serverdiscovery,这将返回EruekaServicediscovery服务的所有实例信息,包括主机、端口等。
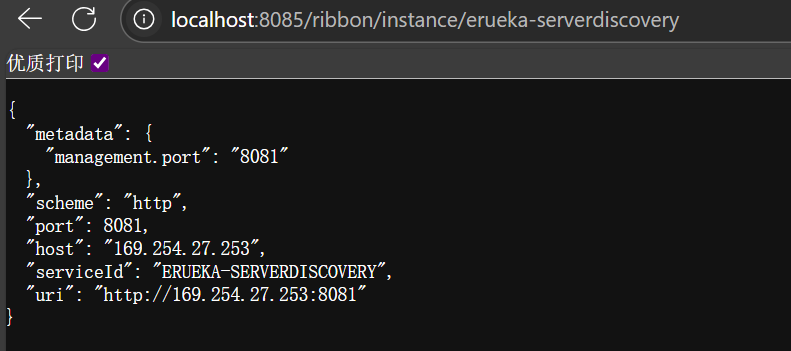
测试负载均衡器选择的实例,访问:http://localhost:8085/ribbon/instance/erueka-serverdiscovery,多次刷新页面,观察每次返回的实例是否不同,这表明负载均衡器在工作。

测试负载均衡效果,访问http://localhost:8085/ribbon/test-balance/erueka-serverdiscovery?count=20,这将模拟20次服务调用,并统计每个实例被调用的次数,从而直观地展示负载均衡的效果。

为什么调用次数都是一样的,用的轮询策略可不一样吗那)
自定义负载均衡策略
上面我们提到,在配置文件中,可以修改你想要的负载均衡策略
1 | # 给某个微服务配置负载均衡规则 |
而且通过配置类方式肯定也能搞,配置文件能搞的,肯定能写个配置类搞,但是这种写法就是全局,你用@LoadBalancerClient然后指定服务名就可以实现针对服务设置负载均衡的策略
1 |
|
但是,这只是选择已有的负载均衡策略,想要真正实现自定义,还差临门一脚
这是 RibbonConfig 类,可以在这里添加自定义的负载均衡配置
1 | import org.springframework.cloud.client.loadbalancer.LoadBalanced; |
你自己随便写一个负载均衡的策略,这是我自己重新写的权重
1 | public class WeightedLoadBalancer implements ReactorLoadBalancer<ServiceInstance> { |
接下来,创建一个配置类来注册我们的自定义负载均衡器
1 | public class CustomLoadBalancerConfiguration { |
修改现有的RibbonConfig类,添加@LoadBalanced注解和RestTemplate配置
1 |
|
然后,在配置文件中,就可以指定自己的自定义策略
这次就是真正的自定义了





