
Spring Cloud Alibaba
什么是Spring Cloud Alibaba
Spring Cloud Alibaba 是阿里巴巴基于 Spring Cloud 规范开发的微服务生态体系,旨在为开发者提供一套完整的微服务解决方案,Spring Cloud Alibaba 生态以 Nacos、Sentinel、Seata 为核心,整合了网关、消息队列等组件,形成了一套适合国内企业的微服务解决方案。其优势在于组件一体化、高性能、本土化适配,尤其适合对稳定性和并发能力要求高的业务场景。
Spring Cloud Alibaba 核心组件及功能
Spring Cloud Alibaba 与 Spring 官方提供的 Spring Cloud 生态的不同,就基本都是体现在组件的不同上,基本Spring Cloud 生态的该有的各种组件类型,Spring Cloud Alibaba 也基本都有
Spring Cloud Alibaba 的生态组件围绕微服务全生命周期展开,以下是他们的核心组件
服务注册与发现组件,分布式配置:Nacos
- Nacos 是 Spring Cloud Alibaba
的核心组件,集服务注册发现与配置管理于一体,替代了传统的
Eureka + Config 组合。
- 服务注册发现:支持基于 DNS 和 RPC 的服务发现,兼容 Dubbo、Spring Cloud 等框架,提供实时健康检查(TCP/HTTP/MySQL 等协议),自动剔除不健康服务。
- 动态配置管理:支持配置的集中管理、动态推送(无需重启服务),并可按环境、集群、命名空间隔离配置,满足多环境部署需求。
- 高可用设计:采用集群部署(至少 3 节点),通过 Raft 协议保证数据一致性,支持数据持久化(MySQL 存储),避免单点故障
- 优势:相比 Eureka,Nacos 支持配置管理与服务发现一体化,减少组件依赖;相比 Consul,Nacos 提供更丰富的配置管理功能和本土化适配
- Nacos Config 作为配置中心,解决了微服务中配置分散、更新繁琐的问题,与 Nacos 服务发现共享同一集群,减少部署成本。
- Nacos 是 Spring Cloud Alibaba
的核心组件,集服务注册发现与配置管理于一体,替代了传统的
Eureka + Config 组合。
服务熔断与服务降级:Sentinel
- Sentinel 是面向分布式系统的流量控制工具,替代了
Hystrix,提供流量控制、熔断降级、系统负载保护等功能,以
“熔断降级” 为核心,保障服务稳定性。
- Sentinel 采用滑动窗口计数(更精准),支持更细粒度的规则配置,且控制台更易用,性能优于 Hystrix(单机 QPS 可达百万级)
- Sentinel 是面向分布式系统的流量控制工具,替代了
Hystrix,提供流量控制、熔断降级、系统负载保护等功能,以
“熔断降级” 为核心,保障服务稳定性。
分布式事务:Seata
Seata 是阿里巴巴开源的分布式事务解决方案,解决微服务中跨服务数据一致性问题,替代了传统的 2PC(两阶段提交)方案,支持AT、TCC、SAGA、XA 四种模式。
AT 模式(默认):基于本地事务 + 全局锁实现,无需业务代码侵入。流程为:
- 第一阶段:本地事务提交,记录 undo_log(回滚日志);
- 第二阶段:若所有分支事务成功,删除 undo_log;若失败,根据 undo_log 回滚。
TCC 模式:需要业务代码实现 Try(资源检查 / 预留)、Confirm(确认提交)、Cancel(取消释放)三个接口,灵活性高但开发成本高,适合复杂业务场景。
SAGA 模式:基于状态机的长事务解决方案,通过补偿操作实现最终一致性,适合长流程业务(如订单履约)。
优势:相比传统 2PC,Seata 减少了锁竞争,性能更高;AT 模式无需侵入业务代码,降低开发成本。
网关路由:Spring Cloud Gateway + Alibaba Cloud Gateway
- 网关是微服务的入口,负责路由转发、负载均衡、认证授权、限流等功能,Spring
Cloud Alibaba 推荐使用 Spring Cloud Gateway(基于 Netty
的非阻塞网关),并提供 Alibaba Cloud Gateway 作为增强方案。
动态路由:基于配置中心(如 Nacos)动态更新路由规则,无需重启网关。
负载均衡:集成 Ribbon/Nacos 负载均衡策略,将请求分发到后端服务实例。
与 Sentinel 集成:通过 Sentinel 网关规则,对网关层进行流量控制(如限制某路由的 QPS)。
- 网关是微服务的入口,负责路由转发、负载均衡、认证授权、限流等功能,Spring
Cloud Alibaba 推荐使用 Spring Cloud Gateway(基于 Netty
的非阻塞网关),并提供 Alibaba Cloud Gateway 作为增强方案。
消息驱动:Spring Cloud Stream + RocketMQ
- Spring Cloud Stream 是消息驱动开发的标准化框架,而 RocketMQ 是阿里巴巴的分布式消息队列,两者结合实现服务间异步通信,解耦服务依赖,避免同步调用导致的服务阻塞。
服务间调用:Dubbo Spring Cloud
- Dubbo 是阿里巴巴的 RPC 框架,Spring Cloud Alibaba 提供 Dubbo Spring
Cloud 组件,支持基于 Dubbo 的 RPC 调用,与 Spring Cloud
的 REST 调用形成互补。
Dubbo 基于二进制协议(如 Hessian2),性能优于 REST(HTTP/JSON),适合高频、低延迟的服务调用。
REST 基于 HTTP 协议,更适合跨语言、跨平台通信(如前端与后端)。
两者可共存:核心服务间用 Dubbo 提升性能,对外接口用 REST 保持兼容性。
- Dubbo 是阿里巴巴的 RPC 框架,Spring Cloud Alibaba 提供 Dubbo Spring
Cloud 组件,支持基于 Dubbo 的 RPC 调用,与 Spring Cloud
的 REST 调用形成互补。
| 功能场景 | Spring Cloud 原生组件 | Spring Cloud Alibaba 组件 | 优势对比 |
|---|---|---|---|
| 服务注册发现 | Eureka/Consul | Nacos | Nacos 集成配置管理,高可用更优 |
| 熔断降级 | Hystrix | Sentinel | Sentinel 性能更高,规则配置更灵活 |
| 配置管理 | Config + Bus | Nacos Config | 一体化部署,动态推送更高效 |
| 分布式事务 | 无原生支持(需集成 Seata) | Seata | 深度集成,AT 模式降低开发成本 |
| 网关 | Zuul | Spring Cloud Gateway | 非阻塞 IO,性能提升 10 倍以上 |
| 消息队列 | RabbitMQ/Kafka | RocketMQ | 事务消息支持更完善,本土化适配更好 |
Nacos 与 Erueka 有什么区别
其实这个问题应该这么问,大家其实就差不多知道区别了——为什么使用Nacos而不是Eureka
工作方式的区别:
- Erueka:Eureka包含两个组件:Eureka Server和Eureka Client,这俩的作用前面已经说过了
- Nacos:Nacos提供了namespace来实现环境隔离功能。
- nacos中可以有多个namespace
- namespace下可以有group
- 不同namespace之间相互隔离,例如不同namespace的服务互相不可见
支持CAP的情况:
- Consistency(一致性) :数据一致更新,所有数据的变化都是同步的
- Availability(可用性) :在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求
- Partition tolerance(分区容忍性) :某个节点的故障,并不影响整个系统的运行
| 注册中心 | AP | CP |
|---|---|---|
| Eureka | 支持 | 不支持 |
| Nacos | 支持 | 支持 |
连接方式:
- Nacos使用的是netty和服务直接进行连接,属于长连接
- Eureka是使用定时发送和服务进行联系,属于短连接
服务异常的检测和剔除:
- Erueka:Eureka client在默认情况每隔30s想Eureka Server发送一次心跳,当Eureka Server在默认连续90s秒的情况下没有收到心跳,会把Eureka client 从注册表中剔除,在由Eureka-Server 60秒的清除间隔,把Eureka client 给下线,也就是在极端情况下Eureka 服务从异常到剔除在到完全不接受请求可能需要 30s+90s+60s=3分钟左右
- Nacos client 通过心跳上报方式告诉 nacos注册中心健康状态,默认心跳间隔5秒,nacos会在超过15秒未收到心跳后将实例设置为不健康状态,可以正常接收到请求超过30秒nacos将实例删除,不会再接收请求
操作方式:
- Erueka:仅提供了实例列表,实例的状态,错误信息,相比于nacos过于简单
- Nacos:提供了nacos console可视化控制话界面,可以对实例列表进行监听,对实例进行上下线,权重的配置,并且config server提供了对服务实例提供配置中心,且可以对配置进行CRUD,版本管理
Nacos 的原理
Nacos 介绍
在服务注册和发现中,服务消费者要去调用多个服务提供者组成的集群,需要做到以下几点:
- 服务消费者需要在本地配置文件中维护服务提供者集群的每个节点的请求地址。
- 服务提供者集群中如果某个节点宕机,服务消费者的本地配置中需要同步删除这个节点的请求地址,防止请求发送到已经宕机的节点上造成请求失败。
因此需要引入服务注册中心,它具有以下几个功能:
- 服务地址的管理。
- 服务注册。
- 服务动态感知。
而Nacos致力于解决微服务中的统一配置,服务注册和发现等问题。Nacos集成了注册中心和配置中心。其相关特性包括:
- Nacos支持基于DNS和RPC的服务发现,即服务消费者可以使用DNS或者HTTP的方式来查找和发现服务。
- Nacos支持传输层(Ping/TCP)、应用层(HTTP、Mysql)的健康检查。
- Nacos支持动态配置服务,可以以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。
- Nacos支持动态 DNS 服务,支持权重路由,让开发者更容易的实现中间层的负载均衡、更灵活的路由策略、流量控制以及DNS解析服务。
- Nacos允许开发者从微服务平台建设的视角来管理数据中心的所有服务和元数据。如:服务的生命周期、静态依赖分析、服务的健康状态、服务的流量管理、路由和安全策略等。
Nacos 架构
如下为 Nacos 的架构图
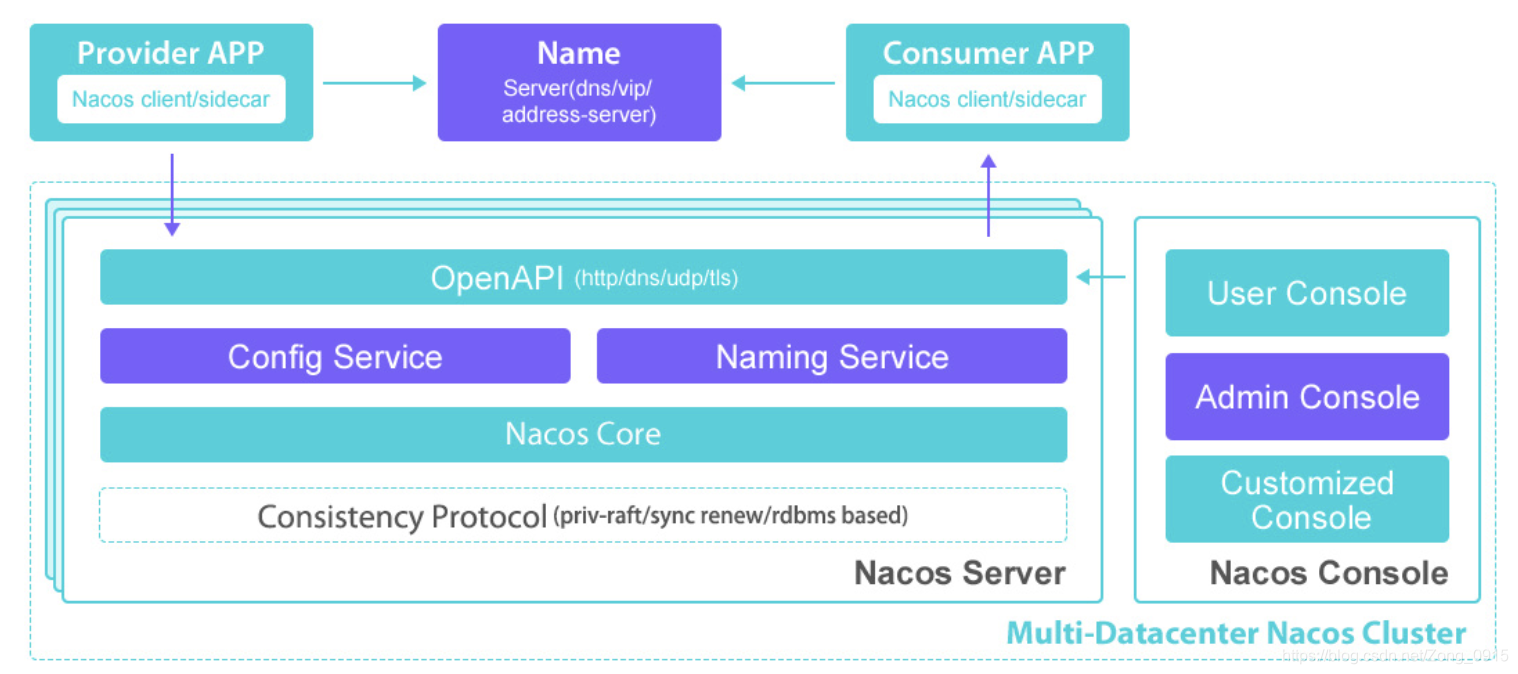
flowchart TB
subgraph 多数据中心Nacos集群
subgraph Nacos服务器
OpenAPI[OpenAPI(http/dns/udp/tls)]
subgraph 服务层
ConfigService[配置服务]
NamingService[命名服务]
end
NacosCore[Nacos核心]
ConsistencyProtocol[一致性协议(priv-raft/sync renew/rdbms based)]
OpenAPI --> ConfigService
OpenAPI --> NamingService
ConfigService --> NacosCore
NamingService --> NacosCore
NacosCore --> ConsistencyProtocol
end
subgraph Nacos控制台
UserConsole[用户控制台]
AdminConsole[管理控制台]
CustomizedConsole[自定义控制台]
end
end
ProviderAPP[提供者应用\nNacos客户端/边车] --> NameServer[名称服务器\n(dns/vip/地址服务器)]
ConsumerAPP[消费者应用\nNacos客户端/边车] --> NameServer
NameServer --> OpenAPI其中分为这么几个模块:
Multi-Datacenter Nacos Cluster:多数据中心 Nacos 集群
这是整个 Nacos 的部署环境,表示 Nacos 可以支持在多个数据中心进行部署,以实现高可用性和容灾能力。
Nacos Server:Nacos 服务器
Nacos Server的底层则通过数据一致性算法(Raft)来完成节点的数据同步。
OpenAPI(http/dns/udp/tls):提供了多种协议的开放 API 接口,供外部应用(如提供者应用和消费者应用)进行服务注册、发现、配置获取等操作。支持 HTTP、DNS、UDP、TLS 等多种通信协议,增强了 Nacos 的兼容性和灵活性。
服务层(Service Layer)
- 配置服务(Config Service):负责配置的管理,包括配置的存储、读取、更新、删除等操作。应用可以通过该服务获取和更新配置信息。
- 命名服务(Naming Service):主要处理服务的注册与发现。服务提供者将自己的服务信息注册到命名服务,服务消费者通过命名服务获取可用的服务实例信息。
Nacos Core:Nacos 核心模块
是 Nacos 的核心模块,整合了配置服务和命名服务的功能,处理各种业务逻辑和请求分发。
Consistency Protocol - priv-raft/sync renew/rdbms based:一致性协议
保证 Nacos 集群中数据的一致性。这里提到了几种可能的一致性协议实现方式,如私有的 Raft 协议、同步更新协议以及基于关系型数据库(RDBMS)的方式。这些协议确保在分布式环境下,各个节点之间的数据能够保持同步和一致。
Nacos Console:Nacos控制台
- 用户控制台(User Console):为普通用户提供的操作界面,用户可以在这里进行服务和配置的相关操作,如查看服务列表、配置信息等。
- 管理控制台(Admin Console):主要供管理员使用,用于对 Nacos 集群进行管理和监控,如查看集群状态、进行节点管理、配置管理等高级操作。
- 自定义控制台(Customized Console):允许用户根据自己的需求进行定制开发的控制台界面,以满足特定的业务需求。
提供者应用(Provider APP)和消费者应用(Consumer APP)
- 都包含 Nacos 客户端 / 边车(Nacos client/sidecar),用于与 Nacos 服务器进行交互。提供者应用将服务注册到 Nacos 服务器,消费者应用从 Nacos 服务器获取服务信息。
- 它们通过名称服务器(Name Server - dns/vip/ 地址服务器)与 Nacos 服务器的 OpenAPI 进行通信。名称服务器起到了路由和寻址的作用,帮助应用找到正确的 Nacos 服务器节点。
Nacos 的数据模型
Nacos 数据模型 Key 由三元组唯一确定。通过以下三者就可以确定同一个服务了
在服务注册和订阅的时候,必须要指定上述三部分信息,如果不指定,Nacos就会提供默认的信息
命名空间(Namespace):多租户隔离用的,默认是
publicNamespace 的常用场景之一是不同环境的配置的区分隔离,例如开发测试环境和生产环境的资源(如配置、服务)隔离等。
分组(Group):这个其实可以用来做环境隔离,服务注册时可以指定服务的分组,比如是测试环境或者是开发环境,默认是
DEFAULT_GROUPNacos 中的一组配置集,一个有意义的字符串(如 Buy 或 Trade )对配置集进行分组,从而区分 Data ID 相同的配置集,默认采用 DEFAULT_GROUP 。
配置分组的常见场景:不同的应用或组件使用了相同的配置类型。
服务名(ServiceName):这个就不用多说了
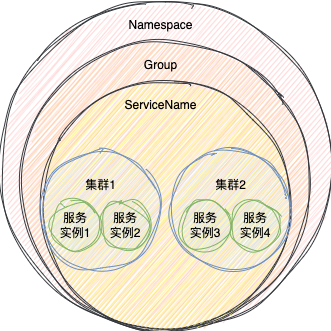
其中,在服务里面其实还是有一个集群的概念,在服务注册的时候,可以指定这个服务实例在哪个集体的集群中,默认是在DEFAULT集群下,在服务订阅的时候,可以指定订阅哪些集群下的服务实例,当然,如果不指定的话,默认就是订阅这个服务下的所有集群的服务实例
临时实例和永久实例
临时实例和永久实例在Nacos中是一个非常非常重要的概念,因为临时实例和永久实例在源码层次的许多实现机制是完全不同的
临时实例在注册到注册中心之后仅仅只保存在服务端内部一个缓存中,不会持久化到磁盘,这个服务端内部的缓存在注册中心届一般被称为服务注册表,当服务实例出现异常或者下线之后,就会把这个服务实例从服务注册表中剔除
永久服务实例不仅仅会存在服务注册表中,同时也会被持久化到磁盘文件中,当服务实例出现异常或者下线,Nacos只会将服务实例的健康状态设置为不健康,并不会对将其从服务注册表中剔除
临时实例就比较适合于业务服务,服务下线之后可以不需要在注册中心中查看到
永久实例就比较适合需要运维的服务,这种服务几乎是永久存在的,比如说MySQL、Redis等等,对于这些服务,我们需要一直看到服务实例的状态,即使出现异常,也需要能够查看实时的状态
1 | spring |
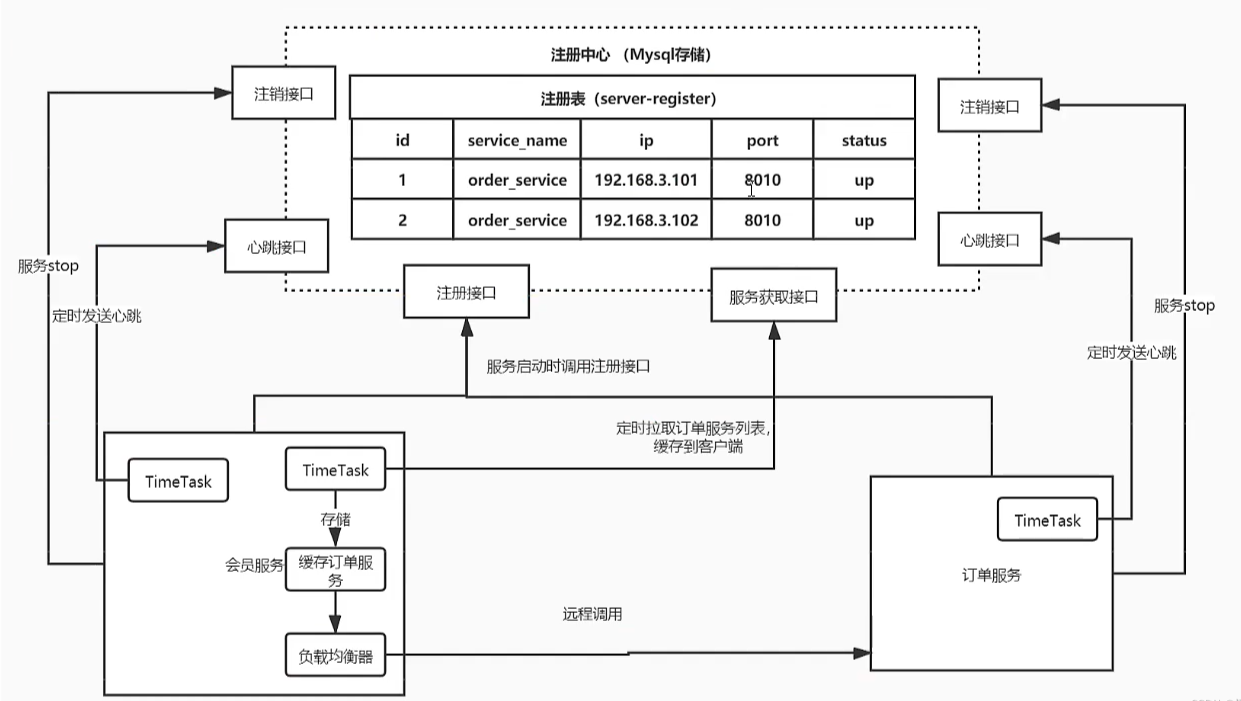
注册中心的原理
作为一个服务注册中心,服务注册肯定是一个非常重要的功能,首先,服务注册的功能体现在:
- 服务实例启动时注册到服务注册表、关闭时则注销(服务注册)。
- 服务消费者可以通过查询服务注册表来获得可用的实例(服务发现)。
- 服务注册中心需要调用服务实例的健康检查API来验证其是否可以正确的处理请求(健康检查)。
Nacos服务注册和发现的实现原理的图如下:
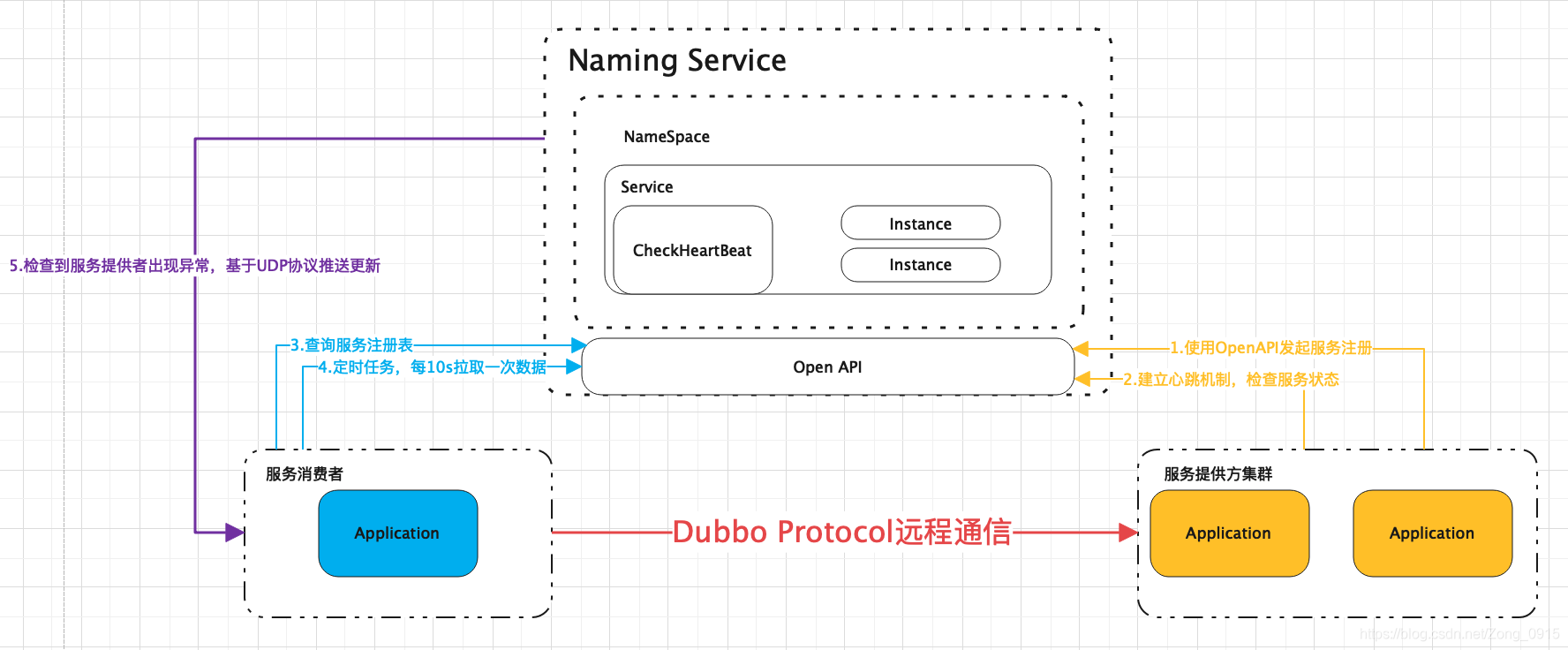
在 2.x 的版本中,Nacos 的服务注册就比较复杂,因为2.x版本相比于1.x版本最主要的升级就是客户端和服务端通信协议的改变,Nacos 2.x 最核心的升级是通信协议从 HTTP 改为 gRPC。
之所以改成了gRPC,主要是因为HTTP 是短连接模式,每次通信都需要建立 TCP 连接→发送请求→断开连接,频繁的连接创建 / 销毁会消耗大量资源,这样,HTTP 的开销会成为系统瓶颈,而且最重要的一点是实时性很差,HTTP 基于请求 - 响应模式,服务端无法主动向客户端推送信息
在具体的实现中,Nacos客户端在启动的时候,会通过gRPC跟服务端建立长连接,这个连接会一直存在,之后客户端与服务端所有的通信都是基于这个长连接来的,客户端的所有操作(注册、心跳、查询服务、订阅配置等)都通过这个长连接完成,不再频繁创建新连接

剩下的就差不多了,服务端拿到服务实例存到服务注册表,对于临时实例(默认类型),客户端会将注册信息缓存到本地,方便 Redo 操作
而 Redo 操作本质是 “操作重做” 的补偿策略,本质是个定时任务,默认每3s执行一次:
- 触发场景:当网络异常导致 gRPC 长连接断开后,重新建立连接时
- 核心作用:确保客户端之前的关键操作(注册、订阅等)在重连后能恢复
- 实现方式
- 客户端本地维护一个 “操作日志缓存”,记录所有需要持久化的操作(如临时实例注册、服务订阅)
- 内置定时任务(默认 3 秒执行一次)检查连接状态
- 当连接恢复时,自动重新执行缓存中的操作(如重新注册服务实例、重新订阅服务)
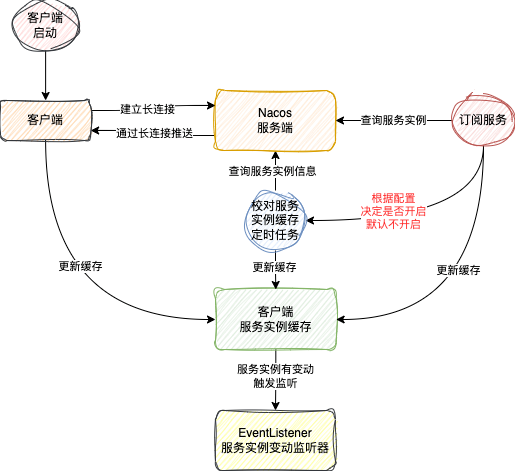
Nacos 服务发现的原理
所谓的服务发现就是指当有服务实例注册成功之后,其它服务可以发现这些服务实例
Nacos提供了两种发现方式:
- 主动查询:客户端主动向服务端发起查询请求,获取服务实例列表,也就是拉(pull)的模式,一般在服务启动时获取初始服务列表
- 服务订阅:客户端向服务端发送一个订阅服务的请求,当被订阅的服务有信息变动就会主动将服务实例的信息推送给订阅的客户端,本质就是推(push)模式
在我们平时使用时,一般来说都是选择使用订阅的方式,这样一旦有服务实例数据的变动,客户端能够第一时间感知,并且Nacos在整合 Spring Cloud 的时候,默认就是使用订阅的方式
服务查询
服务查询其实实现都很简单,1.x整体就是发送Http请求去查询服务实例,2.x只不过是将Http请求换成了gRPC的请求。服务端对于查询的处理过程都是一样的,从服务注册表中查出符合查询条件的服务实例进行返回
服务订阅
在Nacos客户端,不论是1.x还是2.x都是通过SDK中的NamingService中的subscribe方法来发起订阅的,只支持订阅临时服务,对于永久服务,已经不支持订阅了
gRPC 长连接推送:
- 基于 gRPC 的双向流特性,服务端可以主动向客户端推送服务变更
- 当有服务实例变动的时候,服务端直接通过这个长连接将服务信息发送给客户端
本地缓存机制:
- 保留了与 1.x 相同的本地缓存策略
- 服务变更时更新本地缓存
定时拉取机制 (默认关闭):
- 保留了定时拉取补偿机制,但默认不启用,因为长连接比较稳定
- 可以通过配置手动开启,作为极端情况下的兜底策略
Redo 机制保障:
当客户端出现异常,接收不到请求,那么服务端会直接跟客户端断开连接
连接断开重连后,通过 Redo 机制自动重新订阅服务,所以还是能拿到最新的实例信息的
这个机制确保服务端和客户端状态最终一致
Nacos 中的心跳机制
Nacos 心跳机制的保活
Erueka 有的,我们 Nacos 也有,而且做得更好
在前面我们学习过,心跳机制的作用就是服务实例告诉注册中心我这个服务实例还活着,而且通过心跳机制,Nacos 服务端可以实时了解每个服务实例的运行状态,如果服务端在一定时间内没有收到某个服务实例的心跳,就会认为该服务实例出现故障,将其从服务注册表中剔除,从而避免消费者调用到不可用的服务
在Nacos中,心跳机制仅仅是针对临时实例来说的,临时实例需要靠心跳机制来保活
在上面我提过,由于版本更新使用 gRPC 协议,客户端与服务端保持长连接,所以它是利用这个 gRPC 长连接本身的心跳来保活
除了连接本身的心跳之外,Nacos还有服务端的一个主动检测机制,Nacos服务端也会启动一个定时任务,默认每隔3s执行一次,这个任务会去检查超过20s没有发送请求数据的连接,一旦发现有连接已经超过20s没发送请求,那么就会向这个连接对应的客户端发送一个请求,如果请求不通或者响应失败,此时服务端也会认为与客户端的这个连接异常,从而将这个客户端注册的服务实例从服务注册表中剔除
在 Http 协议的版本中,心跳机制本质就是两个定时任务
在服务注册时,如果发现是临时实例,客户端会开启一个5s执行一次的定时任务,这个定时任务会构建一个Http请求,携带这个服务实例的信息,然后发送到服务端
Nacos 服务端接收到心跳请求后,会根据请求中的信息,在服务注册表中找到对应的服务实例记录,并更新该实例的最后心跳时间。通过记录最后心跳时间,服务端可以判断服务实例的活跃状态。
而在Nacos服务端也会开启一个定时任务,默认也是5s执行一次,去检查这些服务实例最后一次心跳的时间,也就是客户端最后一次发送Http请求的时间
- 当最后一次心跳时间超过15s,但没有超过30s,会把这服务实例标记成不健康
- 当最后一次心跳超过30s,直接把服务从服务注册表中剔除
Nacos 的健康检查机制
那么,心跳机制仅仅是临时实例用来保护的机制,而对于永久实例来说,一般来说无法主动上报心跳,这怎么办
所以针对永久实例的情况,Nacos通过一种叫健康检查的机制去判断服务实例是否活着
健康检查跟心跳机制刚好相反,心跳机制是服务实例向服务端发送请求
而所谓的健康检查就是服务端主动向服务实例发送请求,去探测服务实例是否活着
Nacos服务端在会去创建一个健康检查任务,这个任务每次执行时间间隔会在2000~7000毫秒之间,当任务触发的时候,会根据设置的健康检查的方式执行不同的逻辑,目前主要有以下三种方式
TCP:根据服务实例的ip和端口去判断是否能连接成功,如果连接成功,就认为健康,反之就任务不健康,默认情况下,都是通过TCP的方式来探测服务实例是否还活着
HTTP:向服务实例的ip和端口发送一个Http请求,请求路径是需要设置的,如果能正常请求,说明实例健康,反之就不健康
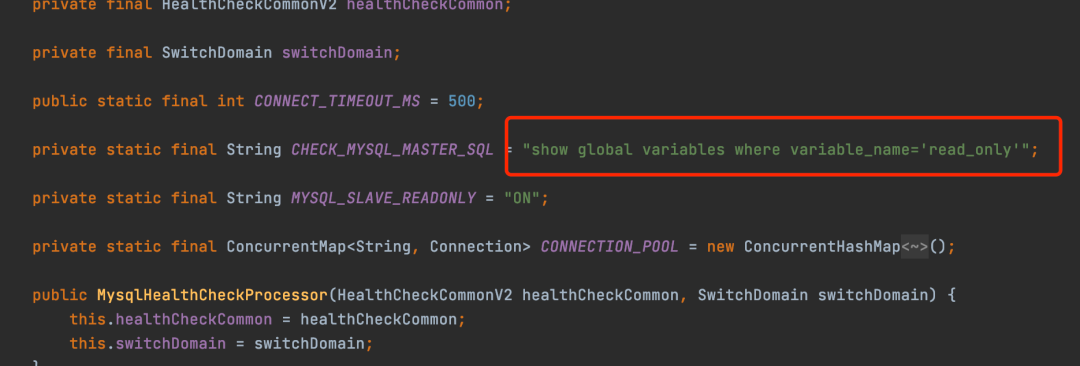
MySQL:他可以执行下面这条Sql来判断数据库是不是主库
数据一致性
由于Nacos是支持集群模式的,所以一定会涉及到分布式系统中不可避免的数据一致性问题
服务实例的责任机制
Nacos 集群中的每个节点都会维护完整的服务注册表,但为了平衡负载,每个节点只负责部分服务实例的健康检查,当然每个Nacos服务的注册表还是全部的服务实例数据:
- 责任分配算法:基于服务实例的 IP 或哈希值进行分片,确保每个服务实例只被一个节点负责
- 数据同步:所有节点通过一致性协议保持服务注册表的最终一致
- 故障转移:当某个节点宕机时,其负责的服务实例会被重新分配给其他节点

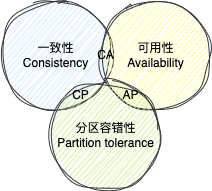
CAP 定理
CAP 定理是分布式系统设计的基础理论,包含三个核心要素:
- 一致性 (Consistency):所有节点在同一时间看到相同的数据
- 可用性 (Availability):系统在合理时间内返回结果,不出现错误
- 分区容错性 (Partition tolerance):系统在网络分区情况下仍能继续运行
三者不可兼得的原因:
网络分区是分布式系统必然存在的情况
当网络分区发生时,系统必须在一致性和可用性之间做出选择
经典场景分析:
假设系统分为 A、B 两个区域,网络分区导致 A 和 B 无法通信:
- 保证可用性:A 区域可以处理写请求 (i=1),但 B 区域无法同步更新,导致数据不一致
- 保证一致性:A 区域必须拒绝写请求,系统失去写可用性
BASE理论
继续上面的例子,首先我们可以先保证系统的可用性,也就是先让系统能够写数据,将A区域服务中的i修改成1,之后当AB区域之间网络恢复之后,将A区域的i值复制给B区域,这样就能够保证AB区域间的数据最终是一致的了
BASE 理论是对 CAP 定理的妥协,强调可用性优先:
- 基本可用 (Basically Available):系统出现故障时仍能提供核心功能
- 软状态 (Soft State):允许系统在一段时间内存在数据不一致
- 最终一致性 (Eventually Consistent):系统恢复后,数据会自动同步达到一致
BASE 理论在 Nacos 中的应用:
- 临时实例处理
- 注册时先保证可用性,立即返回成功
- 通过心跳机制最终保证实例状态一致
- 配置同步
- 配置修改后立即返回成功
- 通过长轮询或推送机制最终同步到所有节点
- 服务发现
- 允许短时间内的服务列表不一致
- 通过定时拉取保证最终一致性
Nacos 的 AP 实现(可用性优先)
Nacos其实目前是同时支持AP和CP的,具体使用AP还是CP得取决于Nacos内部的具体功能
就以服务注册举例来说,对于临时实例来说,Nacos会优先保证可用性,也就是AP,对于永久实例,Nacos会优先保证数据的一致性,也就是CP
对于AP来说,Nacos使用的是阿里自研的 Distro 协议,专为高可用场景设计。
在这个协议中,每个服务端节点是一个平等的状态,每个服务端节点正常情况下数据是一样的,每个服务端节点都可以接收来自客户端的读写请求
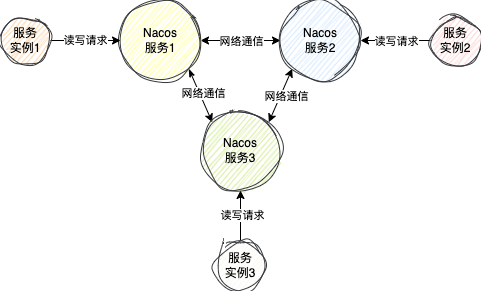
当某个节点刚启动时,他会向集群中的某个节点发送请求,拉取所有的服务实例数据到自己的服务注册表中,这样其它客户端就可以从这个服务节点中获取到服务实例数据了

当某个服务端节点接收到注册临时服务实例的请求,不仅仅会将这个服务实例存到自身的服务注册表,同时也会向其它所有服务节点发送请求,将这个服务数据同步到其它所有节点,所以此时从任意一个节点都是可以获取到所有的服务实例数据的。
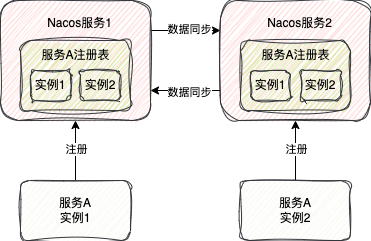
即使数据同步的过程发生异常,服务实例也成功注册到一个Nacos服务中,对外部而言,整个Nacos集群是可用的,也就达到了AP的效果,而且Nacos也有下面两种机制保证最终节点间数据最终是一致的:
失败重试机制:当数据同步给其它节点失败时,会每隔3s重试一次,直到成功
定时对比机制:
每个Nacos服务节点会定时向所有的其它服务节点发送一些认证的请求
这个请求会告诉每个服务节点自己负责的服务实例的对应的版本号,这个版本号随着服务实例的变动就会变动
如果其它服务节点的数据的版本号跟自己的对不上,那就说明其它服务节点的数据不是最新的
此时这个Nacos服务节点就会将自己负责的服务实例数据发给不是最新数据的节点,这样就保证了每个节点的数据是一样的了。
Nacos 的 CP 实现
Nacos 的 CP(一致性优先)模式基于 Raft 共识算法,提供强一致性保证。
在Raft算法,每个节点主要有三个状态
- Leader,负责所有的读写请求,一个集群只有一个
- Follower,从节点,主要是负责复制Leader的数据,保证数据的一致性
- Candidate,候选节点,最终会变成Leader或者Follower
集群启动时都是节点 Follower,超时未收到心跳会转换成 Candidate 状态参与选举,再经过一系列复杂的选择算法,选出一个Leader
当有写请求时,如果请求的节点不是Leader节点时,会将请求转给Leader节点,由Leader节点处理写请求,然后Leader 向 Follower 同步日志,而且写入操作需要超过半数节点确认,这样确保数据强一致性





