
从源码部分详细分析 Gateway 的各部分实现原理
我这篇内容会比较多,因为我看到什么东西都想说说,怕讲不明白))))))
Gateway在项目启动过程如何实现自动配置的
项目启动肯定是离不开 run 方法了,我们也是直接进入,分析一下它的启动流程,看他会进行什么样的初始化配置
首先,在 SpringApplication
的构造函数中,它会进行一些早期的初始化
会推断应用类型(在 Spring Cloud Gateway 的场景下,由于依赖了
spring-boot-starter-webflux,应用类型会被推断为
REACTIVE)。
还会从 META-INF/spring.factories 文件中加载
ApplicationContextInitializer 和
ApplicationListener
的实现类。先看这个,因为这是旧一些版本的基础,因为这个依旧有实际意义
1 | public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) { |
上述代码通过
getSpringFactoriesInstances(Class<T> type) 方法从
META-INF/spring.factories
加载指定类型的实现类,具体流程没啥好说的,就是用SpringFactoriesLoader进行了一个加载。
而SpringFactoriesLoader 是 Spring 框架用于加载类路径下
META-INF/spring.factories
文件中配置的类的工具类。该文件的格式为键值对,键为接口 /
抽象类的全限定名,值为实现类的全限定名列表(用逗号分隔)。我不展示了,有兴趣自己去看看。
加载的ApplicationListener会集成服务发现,GatewayDiscoveryClientAutoConfiguration中就有一个内部类监听器,它会被加载到初始化的配置中通过this.setListeners。
而恰恰就是在这里,进行了是 Spring Cloud Gateway 作为“插件”无缝集成到
Spring Boot “主程序”中的生命周期钩子,SpringFactoriesLoader
扫描所有 JAR 包的 META-INF/spring.factories 文件
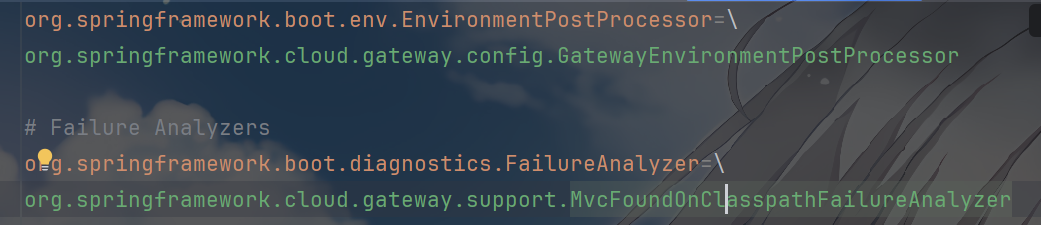
可以看到其中有GatewayEnvironmentPostProcessor,它实现了EnvironmentPostProcessor
接口,这和下面会说到的一个上下文 Environment
的配置有关系,实现了负责调整管理Gateway
应用的PropertySource。
而另一个MvcFoundOnClasspathFailureAnalyzer就是在应用程序启动失败时提供更友好、更详细的错误分析和提示信息,这里体现了一个很重要的事情,就是Spring Cloud Gateway
既可以基于 WebFlux 实现响应式编程,也可以基于传统的
Spring MVC 。当项目中同时引入了与 Spring MVC
相关的依赖,并且这种依赖与 Gateway
的响应式特性产生冲突时,MvcFoundOnClasspathFailureAnalyzer
会对这种情况进行检测和分析。
而接下来,SpringApplication
实例化这些类的对象,并将它们分别存放在initializers 和
listeners 这两个集合中。在这个阶段,这些
Initializer 和 Listener
对象仅仅是被创建并存储起来了,它们自身的业务逻辑(如
initialize() 方法或 onApplicationEvent()
方法)还没有被执行。
初始环境准备完成,接下来就是加载上下文调用
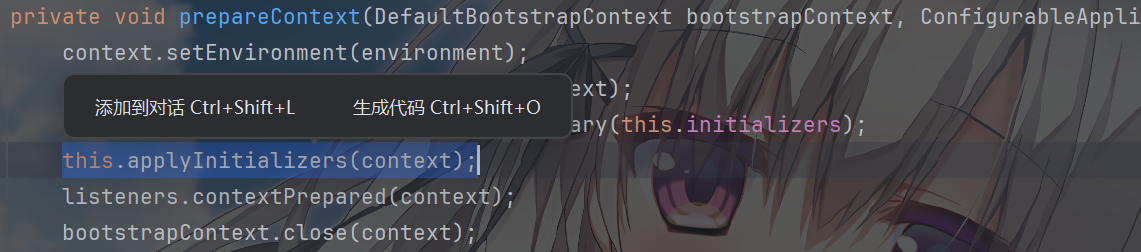
prepareContext() 时。遍历上面创建的
initializers 列表。然后对每一个
ApplicationContextInitializer 对象,调用其
initialize(context) 方法。Spring Cloud
体系(包括
Gateway)就是利用这个时机来准备配置环境。
它会扫描到这么一个 factories
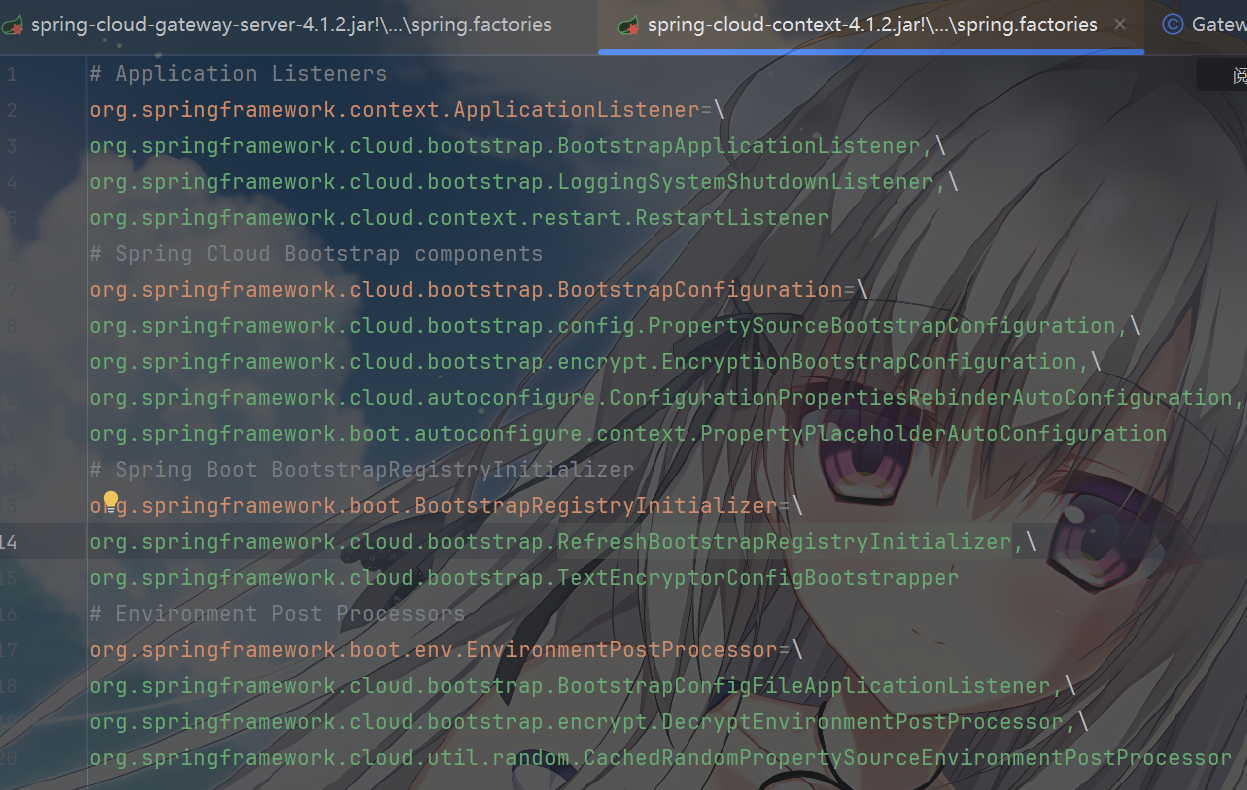
其中BootstrapConfigFileApplicationListener这个源码你们可以自己去看看,它的任务非常专一,就是去寻找并加载项目类路径下的
bootstrap.yml (或.properties)
文件,这就完成与配置中心的联系。而BootstrapApplicationListener
会监听一个早期的应用事件
(ApplicationEnvironmentPreparedEvent)。当监听到这个事件后(此时
bootstrap.yml 里的配置已经被加载到
Environment中了),它就会创建并启动一个独立的、临时的
Spring 引导上下文(Bootstrap Context)。
这只是其中的一个方法,新版本的实现主要依赖
spring-cloud-context 包提供的
ConfigDataApplicationContextInitializer应用上下文初始化器。从BootstrapApplicationListener
演变为
ConfigDataApplicationContextInitializer。(二编,第一次写时候没想到)
它直接利用 Spring Boot 自身的 ConfigData
处理机制。当它被执行时,它会触发 Spring Boot 的
ConfigDataEnvironmentPostProcessor。
这个后处理器会解析 spring.config.import 属性(例如
spring.config.import=nacos:)。根据 nacos:
这个前缀,找到对应的 ConfigDataResolver(Nacos 客户端会提供
NacosConfigDataResolver)。直接调用这个
Resolver 去 Nacos 拉取配置。将拉取到的配置作为
ConfigData 返回,并由 Spring Boot 统一整合进
Environment 中。
1 | public class ConfigDataApplicationContextInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> { |
而引导上下文中涉及到 Gateway 处理加载 Nacos 的机制如下
1 | # Spring Cloud Bootstrap components |
这个配置项中的PropertySourceBootstrapConfiguration类会把这个
key 下的所有类作为自己的 @Configuration
配置类。如果我们引入了 Nacos,它会自动提供一个名为
NacosPropertySourceLocator
的实现。PropertySourceBootstrapConfiguration 找到
NacosPropertySourceLocator
后,就会调用它,就会拿到上面提到的从 bootstrap.yml 中加载的
Nacos 地址,连接到 Nacos 服务器,拉取与当前应用名
(spring.application.name)
匹配的所有配置。这些配置就包括了我们定义的
spring.cloud.gateway.routes。
1 | // 引导上下文的收尾工作,可以在 BootstrapApplicationListener 中找到关键代码。 |
到这里,引导上下文完成它的使命,随着这个 PropertySource
被添加到主应用程序的 Environment
中,引导上下文这一步也就完成。
如上是旧版本的内容,在新版本中,这个机制已经被彻底替换了。(二编,第一次写时候没想到)
spring.factories 中 BootstrapConfiguration
这一项已经不再被使用。取而代之的,是前面提到的
ConfigDataResolver 体系。从
BootstrapConfiguration + PropertySourceLocator
体系,演变为更原生的 ConfigDataResolver 体系。
也就不再需要一个“引导配置类”—PropertySourceBootstrapConfiguration。就像我上面说的那样,当
Spring Boot 看到
spring.config.import=nacos:your-group
这样的配置时,它会自动在类路径上寻找能处理 nacos: 协议的
ConfigDataResolver。
spring-cloud-starter-alibaba-nacos-config 会提供一个
NacosConfigDataLocationResolver 并通过 Spring Boot
的自动配置机制注册它,来处理配置引导载入到 Environment 这件事
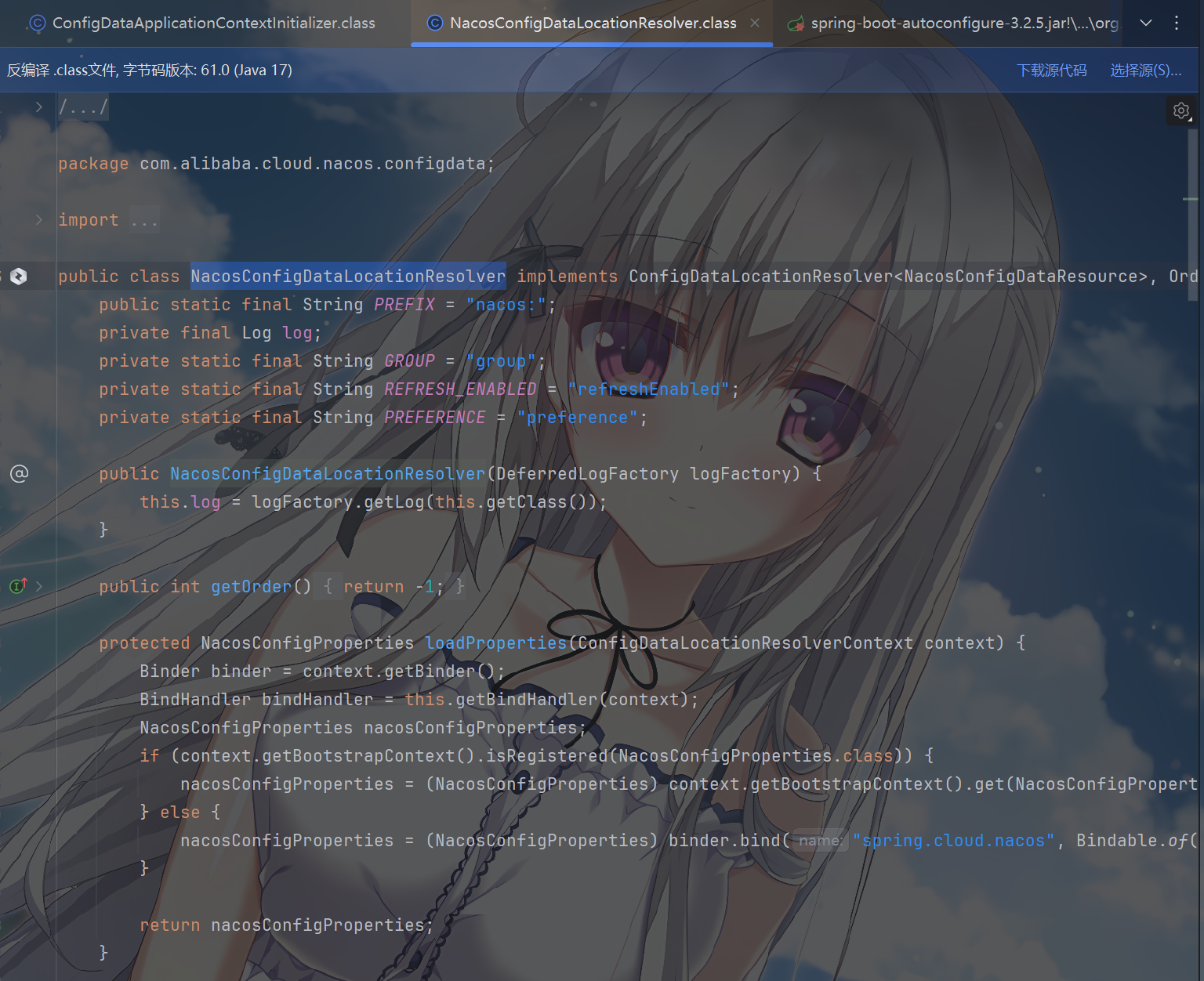
终于,随着刷新上下文
(refreshContext)在启动流程中的必然执行,这是整个启动过程中最核心的部分,refreshContext(context)方法会调用
context.refresh()。
在核心的 refresh() 阶段,由
@EnableAutoConfiguration 机制触发,加载了
spring.factories 中配置的
GatewayAutoConfiguration,详细的加载流程如下
1 | // 触发器@EnableAutoConfiguration 注解通过 @Import 导入了一个关键的选择器。 |
1 | // AutoConfigurationImportSelector 的核心任务就是去加载 spring.factories 文件。 |
完了,找不到,org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ org.springframework.cloud.gateway.config.GatewayAutoConfiguration这项配置,这难道不是个死局吗
其实是这样从 Spring Boot 2.7 版本开始,为了提升启动性能,Spring
官方推荐了一种全新的、更高性能的自动配置注册方式,并逐步废弃了在
spring.factories 中使用 EnableAutoConfiguration
的做法。但是我为什么要讲,毕竟不少人用老版本,而且这个配置原理是基础。
新版本中,使用的是META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
是 Spring Boot 2.6
版本引入的自动配置导入文件,这种新方式有更好的性能,它让 Spring Boot
能更高效地识别和加载自动配置类。
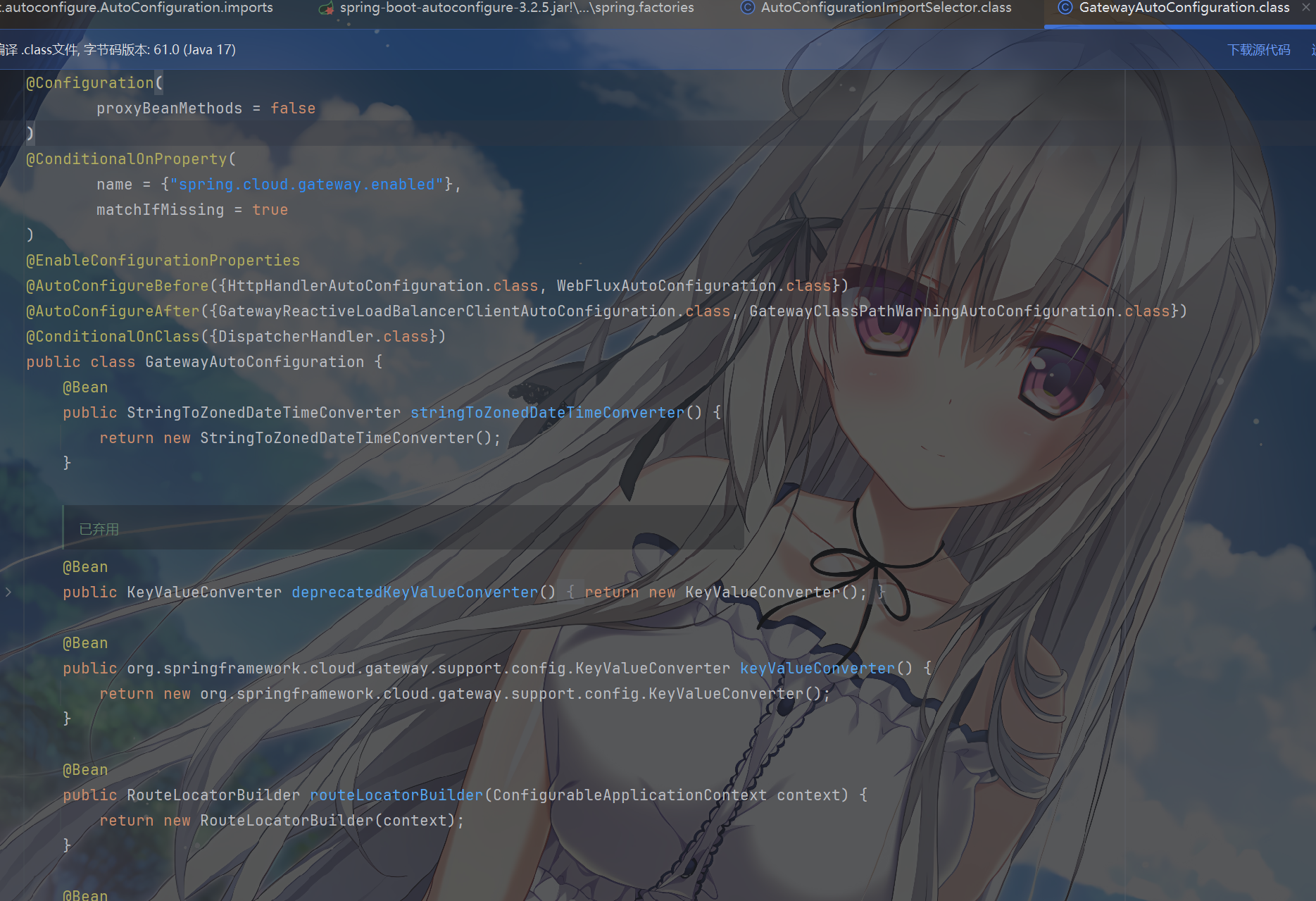
细说几个重要的
GatewayAutoConfiguration:Spring Cloud Gateway 的核心自动配置类。GatewayResilience4JCircuitBreakerAutoConfiguration:与 Resilience4J 集成,实现熔断器(Circuit Breaker)功能的自动配置。我们下面讲Gateway集合其他组件的时候会说GatewayDiscoveryClientAutoConfiguration:当 Gateway 与服务发现组件(如 Eureka、Consul 等)集成时,该配置类会自动配置相关逻辑。也就是说,新版本自动配置导入的相关逻辑在这里SimpleUrlHandlerMappingGlobalCorsAutoConfiguration:用于自动配置全局的跨域资源共享(CORS)规则。GatewayReactiveLoadBalancerClientAutoConfiguration:针对响应式编程模型,自动配置负载均衡客户端。会自动配置 Spring Cloud LoadBalancer 等负载均衡组件
而且它支持向后兼容: Spring Boot 的
AutoConfigurationImportSelector,在新的版本中,它会同时检查新的
.imports 文件和旧的 spring.factories
文件。这样既能享受到新方式带来的性能提升,又能兼容那些尚未迁移的旧版第三方库。
而整个启动流程的逻辑和原理完全没有变:
@EnableAutoConfiguration依然是触发器。AutoConfigurationImportSelector依然是“发现者”。GatewayAutoConfiguration依然是那个被找到并加载的“配置类”。
在 Spring Cloud Gateway
启动时,根据约定大于配置原则,会自动初始化在
GatewayAutoConfiguration 配置的对象实例,其中包括
- 初始化核心组件:路由(
RouteLocator)、断言(RoutePredicateFactory)、过滤器(GatewayFilterFactory)。 - 集成周边生态:服务发现(Eureka、Nacos)、监控(Actuator)、安全(OAuth2)、Netty 通信。
- 条件化加载:确保组件按需启用,避免冗余。
他喵的这个类,900多行,我挑点重要的列举出来,因为我不可能全部讲完所有内容,但是我会给大家一个自己去看的我没讲的东西的思路
1 |
|
- 用于以编程方式构建路由规则(替代 YAML/Properties 配置),支持通过 Java 代码形式动态定义路由。
1 |
|
- 聚合所有路由定义源(如
PropertiesRouteDefinitionLocator、DiscoveryClientRouteDefinitionLocator)。 - 支持从配置文件(
application.yml)、服务发现(Eureka、Nacos)等多源加载路由。CompositeRouteDefinitionLocator确保所有路由规则被合并处理。 - 这也就是为什么,Gateway 支持多配置中心的原理
1 |
|
- 想看路由的缓存规则就在里面,我不单独拿出来说了,我记得是30秒刷新,可以改
1 |
|
- 一切断言工厂的基础,一切支持配置文件实现网关断言的基础
1 |
|
- 一切过滤器的基础,只不过这个是局部的,上面的还有个全局的,实现了支持配置文件配置过滤器的基础
1 |
|
- 监听服务发现事件,为什么 Gateway 能做到实现动态路由并且自动刷新路由规则的基础
1 |
|
- 集成 OAuth2 实现令牌中继(Token Relay),将客户端令牌传递到下游服务。
- 实现跨域配置和 OAuth2 认证的基础
说了这么多终于把自动配置的流程说完了,他喵的这么我说了这么多??????
其实也正常,自动配置这个东西本来就是一个很复杂的东西,而且 Gateway 结合这个结合那个,版本更新实现原理还变,只能多说了
Gateway 是如何通过 Netty 启动的
AbstractApplicationContext:refresh()
方法的核心定义
refresh() 方法触发了 Spring 容器的整个初始化和 Bean
的生命周期管理。这会启动内嵌服务器,在
refreshContext 内部,作为
onRefresh()的一部分
AbstractApplicationContext 是 Spring
容器的抽象基类,定义了 refresh() 方法的整体流程
所谓的刷新 12 大步
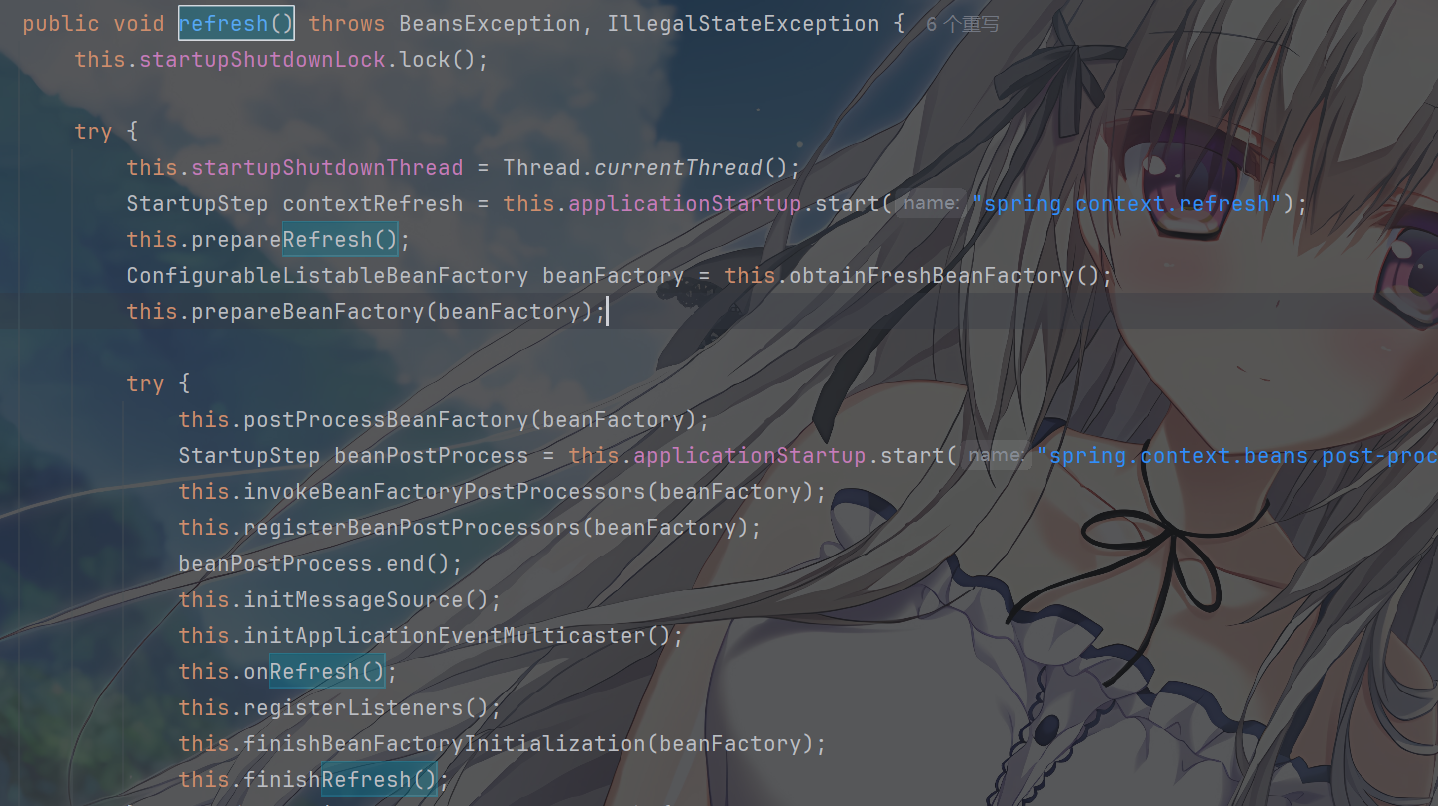
其中 onRefresh() 是留给子类(如响应式 Web
上下文)实现特定逻辑的扩展点,内嵌服务器的启动逻辑就封装在这里。
可以看到这个方法是完全交给子类实现的
我们来到这个抽象类其中的一个实现,ReactiveWebServerApplicationContext,这才是我们要看的内容
ReactiveWebServerApplicationContext:响应式
Web 上下文的服务器启动
ReactiveWebServerApplicationContext 是 Spring 响应式 Web
应用(如 Spring Cloud Gateway,基于 WebFlux 这种)的上下文实现,继承自
AbstractApplicationContext,并重写了
onRefresh() 方法
所以说ReactiveWebServerApplicationContext
会创建并启动内嵌的 Web 服务器(默认为 Netty)。
1 | public class ReactiveWebServerApplicationContext extends GenericReactiveWebApplicationContext { |
- 重写
onRefresh()方法,通过createWebServer()触发服务器创建和启动。 - 依赖
WebServerFactory(如 Netty 工厂)创建具体的服务器实例,并调用start()方法启动。
ReactiveWebServerFactory
与 NettyReactiveWebServerFactory:服务器工厂
接下来我们看 ReactiveWebServerFactory 与
NettyReactiveWebServerFactory,ReactiveWebServerFactory
是响应式 Web
服务器工厂的接口,定义了创建服务器的方法。NettyReactiveWebServerFactory
是其默认实现(因 Spring Cloud Gateway 基于 Netty),负责创建 Netty
服务器。
这是这个接口的定义
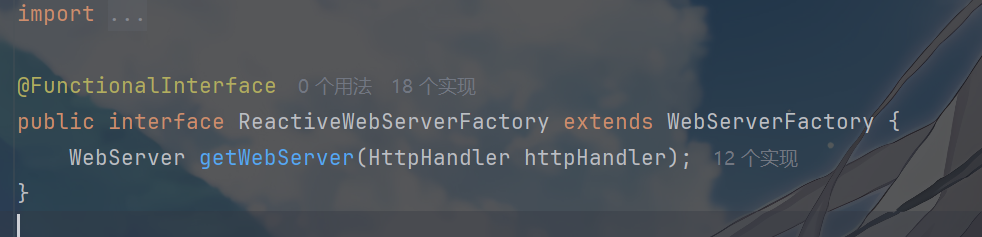
其中可以看到关于 Netty 的实现
我们进入NettyReactiveWebServerFactory()来看一下是如何创建
Netty 服务器的
这个类很长,但是我会详细的说 Netty 的创建流程,方便不太了解 Netty 的读者来方便理解
我先说明,该类的核心职责是:根据配置(端口、SSL、协议等)和自定义规则,创建并配置
Netty 的 HttpServer 实例,最终封装为
NettyWebServer(实现 Spring 的 WebServer
接口),对外提供服务器的启动、停止等生命周期管理能力。
入口:getWebServer(HttpHandler)
方法
getWebServer 是创建服务器的入口方法,接收 Spring 的
HttpHandler(处理 HTTP
请求的核心逻辑处理器)作为参数,返回可启动的 WebServer
实例。
1 | public WebServer getWebServer(HttpHandler httpHandler) { |
- 第一步
createHttpServer()是核心,负责构建并配置 Netty 的HttpServer。 - 第二步通过
ReactorHttpHandlerAdapter实现 Spring 与 Netty 的适配(将 Spring 的请求处理逻辑转换为 Netty 的ChannelHandler)。
然后创建并配置
HttpServer:createHttpServer()
方法
createHttpServer() 是配置 Netty
服务器的核心方法,包含地址绑定、SSL、压缩、协议支持等关键配置。
1 | private HttpServer createHttpServer() { |
- 其中,绑定地址:
getListenAddress()
1 | private InetSocketAddress getListenAddress() { |
- 如果配置了 SSL(如
server.ssl.enabled=true),则通过SslServerCustomizer配置 Netty 的 SSL 上下文,它会配置 HTTPS 所需的 SSL 证书、加密套件、客户端认证等,使服务器支持 HTTPS。
1 | private HttpServer customizeSslConfiguration(HttpServer httpServer) { |
- 压缩配置:
CompressionCustomizer,如果启用了请求压缩(server.compression.enabled=true),则通过CompressionCustomizer配置 Netty 的压缩策略:
1 | // 内部类:处理压缩配置 |
- 这里也就是涉及到了我们上述说的 Gateway 会通过 Netty 的一个 GZIP 压缩特性减少网络的传输量,这部分就是具体实现
协议配置:
listProtocols(),配置服务器支持的 HTTP 协议(默认 HTTP/1.1,可选 HTTP/2):1
2
3
4
5
6
7
8
9
10
11
12
13private HttpProtocol[] listProtocols() {
List<HttpProtocol> protocols = new ArrayList<>();
protocols.add(HttpProtocol.HTTP11); // 默认支持 HTTP/1.1
// 如果启用 HTTP/2
if (this.getHttp2() != null && this.getHttp2().isEnabled()) {
if (this.getSsl() != null && this.getSsl().isEnabled()) {
protocols.add(HttpProtocol.H2); // HTTPS 环境下用 H2(HTTP/2 over TLS)
} else {
protocols.add(HttpProtocol.H2C); // 明文环境下用 H2C(HTTP/2 over 明文)
}
}
return protocols.toArray(new HttpProtocol[0]);
}应用自定义的配置:
applyCustomizers()通过
NettyServerCustomizer接口允许开发者对HttpServer进行自定义扩展:1
2
3
4
5
6private HttpServer applyCustomizers(HttpServer server) {
for (NettyServerCustomizer customizer : this.serverCustomizers) {
server = customizer.apply(server); // 逐个应用自定义器
}
return server;
}
然后进行了一大堆的配置实现之后,我们就真正来到了创建
NettyWebServer,也就是createNettyWebServer()
方法
NettyWebServer 是 Spring 对 Netty 服务器的封装,实现了
WebServer
接口,负责服务器的启动、停止等生命周期管理,下面细嗦

WebServer与NettyWebServer:服务器实例与启动逻辑
接下来继续 Netty 的创建流程,来到创建
NettyWebServer:createNettyWebServer()
方法
NettyWebServer 是 Spring 对 Netty 服务器的封装,实现了
WebServer 接口,负责服务器的启动、停止等生命周期管理
其中 WebServer 的接口定义如下,可以看到其中就三个方法,而且一读就知道这几个方法都是做什么的,实现了基本的服务器所需要的方法
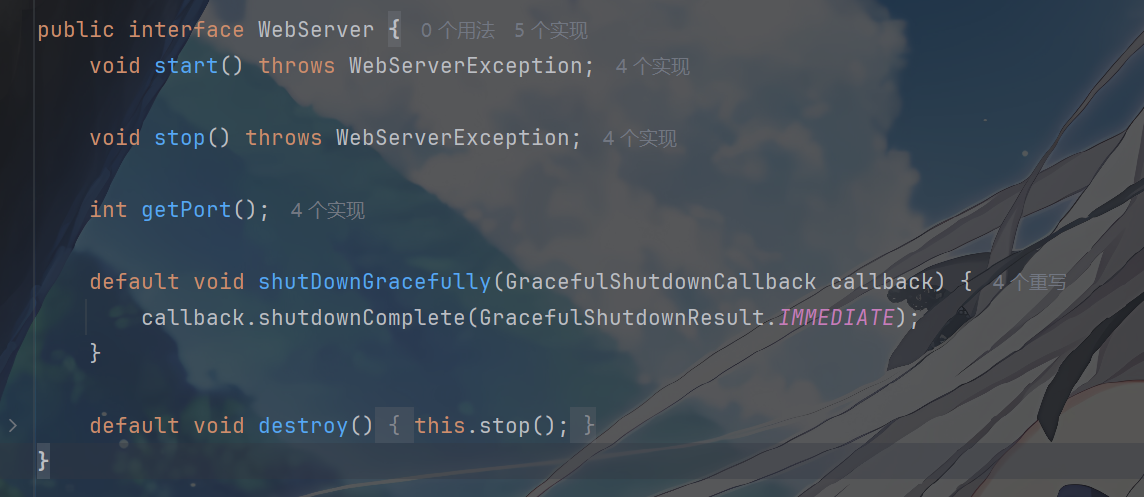
NettyWebServer 作为其实现,封装了启动 Netty
的所需方法

然后,createNettyWebServer被调用,NettyWebServer对象被创建
1 | NettyWebServer createNettyWebServer( |
resourceFactory:ReactorResourceFactory实例,管理 Netty 的事件循环组(EventLoopGroup)等资源,实现资源复用。lifecycleTimeout:服务器启动 / 停止的超时时间。shutdown:服务器关闭策略(如IMMEDIATE立即关闭,GRACEFUL优雅关闭)。
最后,NettyWebServer 是最终对外提供服务的实例,其
start() 方法会启动 Netty 服务器:
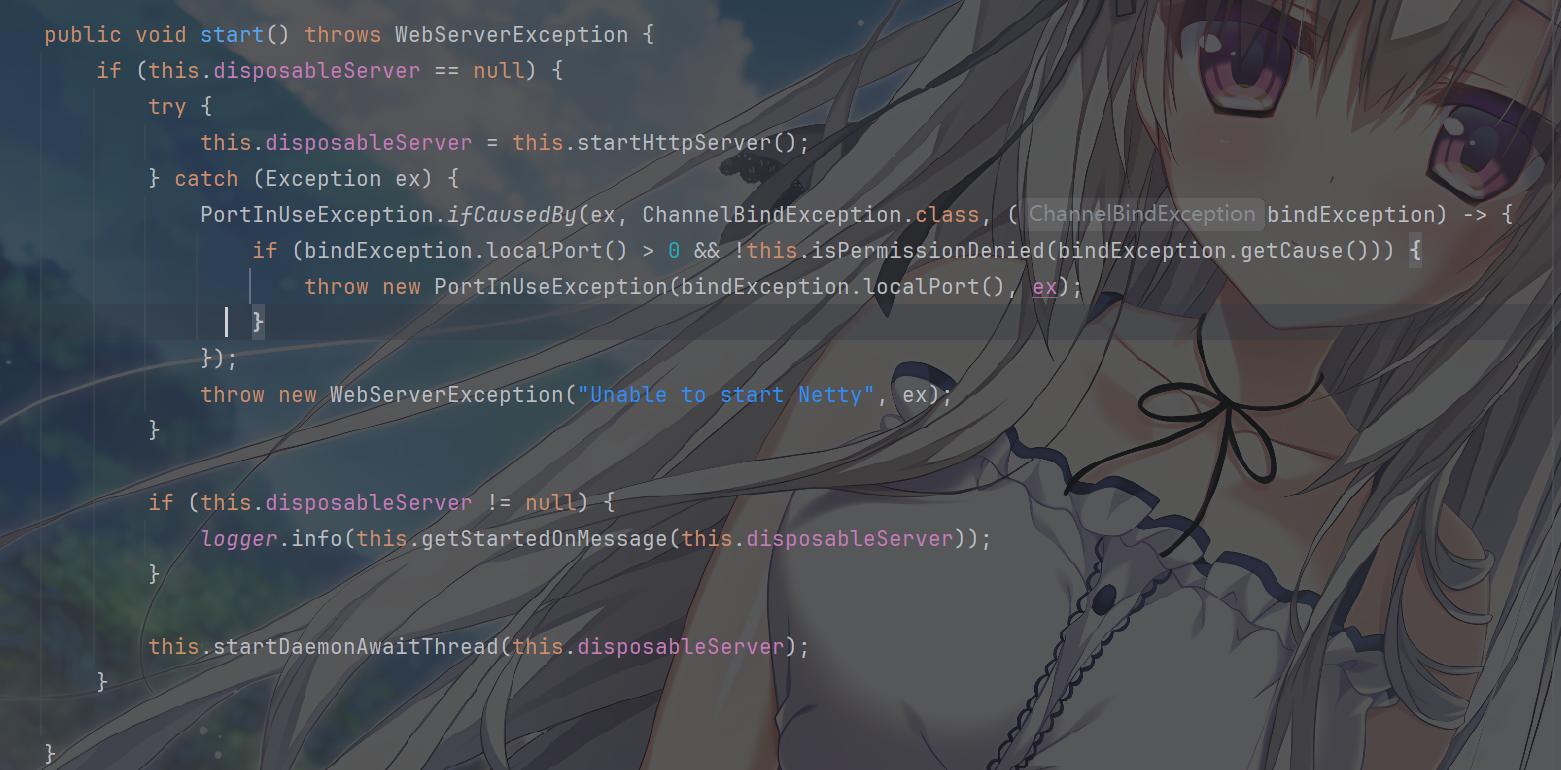
1 | // NettyWebServer 类的 start() 方法核心逻辑 |
bindNow():Netty 服务器绑定端口并启动,开始监听请求。DisposableServer:Netty 提供的服务器句柄,用于停止服务器(dispose()方法)。
上面提到的这些内容,都会有部分配置可以在配置文件中实现自定义配置
因为在我们创建NettyWebServer对象的时候,调用了createNettyWebServer,创建了ReactorResourceFactory
实例,NettyReactiveWebServerFactory 支持多种配置,可以通过
setter 方法或外部配置生效
ReactiveWebServerFactoryAutoConfiguration:自动配置服务器工厂
最后,
来看一下ReactiveWebServerFactoryAutoConfiguration自动配置服务器工厂
可以看到这个是 Netty
服务器的配置类,因此它的启动顺序是最高的,这里挺反直觉的,Integer.MIN_VALUE
表示最高优先级,确保该配置在其他 Web 相关配置之前执行。仅当类路径中存在
ReactiveHttpInputMessage
类时生效和那个条件注解,都没啥好说的,毕竟是给人家响应式用的
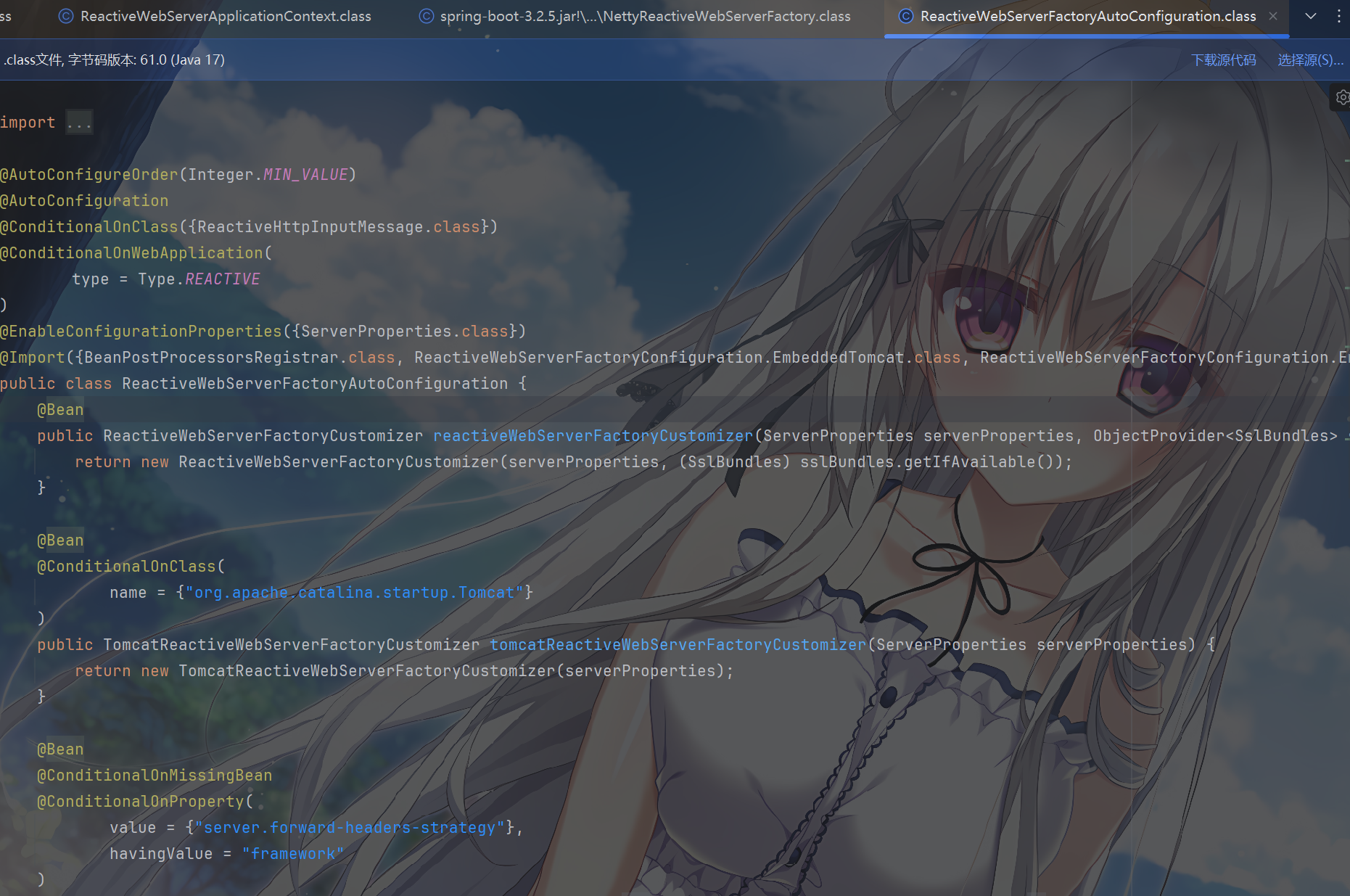
Spring Boot 会通过自动配置类
ReactiveWebServerFactoryAutoConfiguration 注册
ReactiveWebServerFactory 实例(默认
NettyReactiveWebServerFactory)。
注意这里导入 BeanPostProcessorsRegistrar,它是用于注册
Web
服务器相关的后置处理器,也就是网关自己也是和其他服务一样都是嵌入式服务的基础。
里面的几个bean挑几个讲一讲
1 |
|
- 作用:创建响应式服务器工厂的通用定制器。
- 功能:根据
ServerProperties中的配置(如端口server.port、上下文路径server.servlet.context-path等)和 SSL 配置,定制响应式服务器的行为,是外部配置可用的基础
1 |
|
- 处理反向代理(如 Nginx)转发的请求头(如
X-Forwarded-For、X-Forwarded-Proto等),确保服务器能正确识别客户端的真实信息。基于反向代理实现各种内容例如 Netty 软件负载均衡的基础
这里的内部类BeanPostProcessorsRegistrar 实现了
ImportBeanDefinitionRegistrar 和
BeanFactoryAware,注册关键后置处理器,用于向容器中注册必要的
Bean 定义:
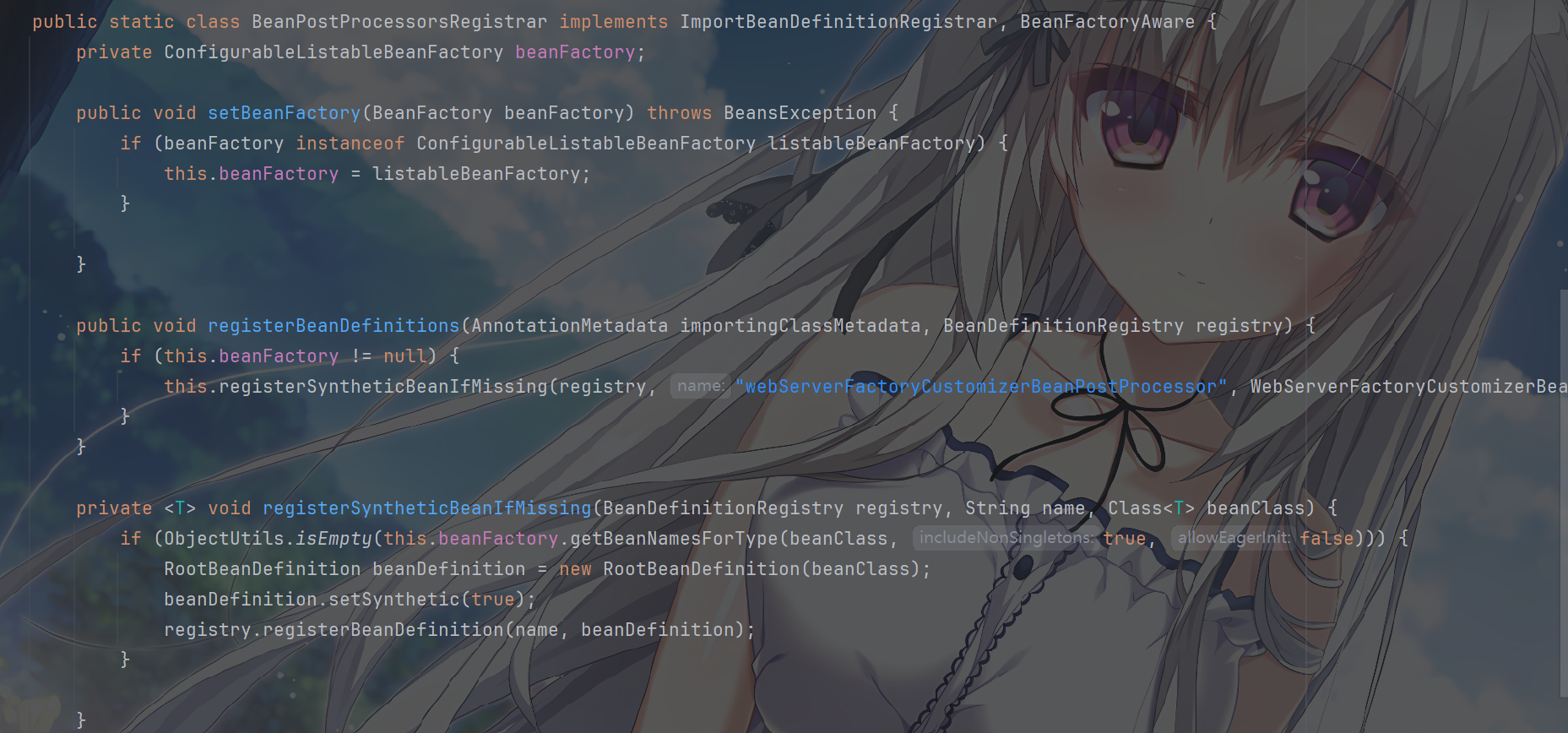
其中WebServerFactoryCustomizerBeanPostProcessor的是一个
Bean 后置处理器,用于收集所有 WebServerFactoryCustomizer
类型的定制器,并在 Web 服务器工厂(如
NettyReactiveWebServerFactory)初始化时,将定制器的配置应用到工厂中,最终实现对服务器的定制。
说一下,以后大家看到这种WebServerXXXXXPostProcessor都是类似内容
总结一下,Spring Cloud Gateway 内嵌 Netty 服务器的启动,使其能够接收和处理 HTTP 请求的流程链如下
AbstractApplicationContext.refresh()触发容器初始化,调用onRefresh()。ReactiveWebServerApplicationContext.onRefresh()调用createWebServer()。createWebServer()从容器获取NettyReactiveWebServerFactory(由ReactiveWebServerFactoryAutoConfiguration自动配置)。NettyReactiveWebServerFactory.getWebServer()创建NettyWebServer实例。NettyWebServer.start()启动 Netty 服务器,绑定端口并开始监听请求。
Gateway 是如何基于 webflux 进行扩展
这里主要是为下面打一个基础
这里简要说,因为知道一下就行,你自己学了 Webflux 自然会知道 Gateway 是如何扩展的,其核心主要还是利用了 Spring WebFlux 提供的非阻塞、响应式编程模型。
首先,WebFlux 的核心请求处理器是 WebHandler 接口(定义
Mono<Void> handle(ServerWebExchange exchange)
方法),Gateway 通过 FilteringWebHandler
实现这个接口,作为
WebHandler 这个接口只包含的一个方法就是处理请求
ServerWebExchange:此对象封装了 HTTP 请求和响应的所有上下文信息。Mono<Void>:作为响应式编程的返回类型,它表示一个异步操作,当操作完成时,不会返回任何实际内容,因为所有对响应的修改都已通过ServerWebExchange对象完成。
在标准的 WebFlux 应用中,DispatcherHandler 是
WebHandler 最重要的实现。它负责将请求分发到由
@Controller和 @RequestMapping
注解定义的相应处理方法。
继续看 FilteringWebHandler, Gateway
的精髓在于它并没有完全重新发明一套网络处理框架,而是巧妙地切入了 WebFlux
的核心处理流程。它通过提供一个自定义的 WebHandler
实现FilteringWebHandler来接管请求处理。
这意味着,当一个 HTTP 请求到达底层(如 Netty)服务器时,它将被移交给
FilteringWebHandler 进行处理,而非 WebFlux 默认的
DispatcherHandler
FilteringWebHandler
的核心职责是管理和执行一个过滤器链。[][]
简单来说,这个类的核心作用是:整合全局过滤器和路由特定过滤器,按顺序组成过滤器链,并执行过滤逻辑。相关内容下面过滤器链部分细说
通过实现 WebHandler 接口并注入自定义的
FilteringWebHandler,Gateway
成功地“拦截”了所有进入的请求。它将 WebFlux
的请求分发模型就这样转变为一个强大而灵活的过滤器链模型。
“不是我喜欢的请求,直接拒绝”
”哈哈“
”好主意“
”那就厉害了“
))))继续,请求处理的核心流程主要围绕两大组件展开:RoutePredicateHandlerMapping
和 FilteringWebHandler
这个RoutePredicateHandlerMapping就是路由匹配入口,与之前不同,现在处理请求的第一站不再是直接的
WebHandler,而是 AbstractHandlerMapping
的一个特定实现,是专门负责路由匹配的组件。
啊呀,骇死我哩
记住这个 AbstractHandlerMapping类是 Spring WebFlux
框架中处理请求映射的核心抽象基类,它为所有具体的处理器映射(HandlerMapping)实现提供了基础骨架和通用逻辑。其主要作用是
将 HTTP
请求映射到对应的处理器(Handler),是 WebFlux
中请求分发的关键组件。
1 | /** |
它定义了 getHandler(ServerWebExchange exchange)
方法(最终调用
getHandlerInternal(ServerWebExchange exchange)),负责根据当前ServerWebExchange找到匹配的Handler,通常是
WebHandler 实现类
getHandler(ServerWebExchange exchange)是对外暴露的核心方法,用于获取当前请求的处理器。
而getHandlerInternal(ServerWebExchange exchange)这个抽象方法,由子类实现具体的请求
- 处理器映射逻辑(如Gateway的基于路径、路由规则等),返回
Mono<?> 响应式编程模型类型
CorsConfiguration 这个玩意能支持跨域配置,Gateway
是直接拿这个用的,被子类重写以定制跨域逻辑,没绷住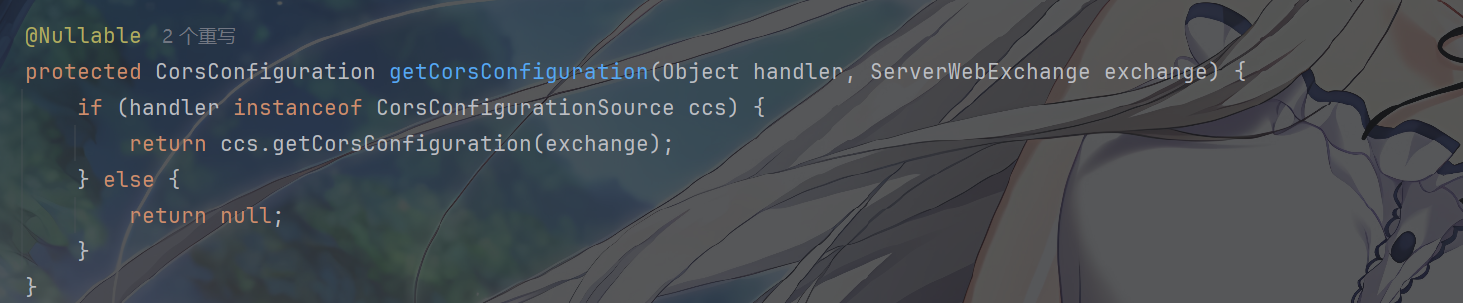
说实话这个类写的有点那个
这回我们就深刻理解,父类(AbstractHandlerMapping)定义流程骨架,子类(如网关的
RoutePredicateHandlerMapping)实现具体的处理器查找逻辑。来看RoutePredicateHandlerMapping吧
1 | protected Mono<Route> lookupRoute(ServerWebExchange exchange) { |
该类作为 Spring WebFlux 的
HandlerMapping,是专门负责路由匹配的组件。当一个请求到达时,WebFlux
的 DispatcherHandler 会首先询问各个
HandlerMapping 是否能处理该请求。
RoutePredicateHandlerMapping
的职责就是根据请求的各种属性(如路径、Host、Header
等)与您配置的所有路由规则(RouteDefinition)的断言(Predicate)进行匹配。
1 | protected Mono<?> getHandlerInternal(ServerWebExchange exchange) { |
一旦找到匹配的,它并不会立即执行,而是将这个 Route
对象存入 ServerWebExchange 的属性中
然后,它向 DispatcherHandler
返回一个统一的处理器——FilteringWebHandler 的实例。
这里Gateway 也通过基于 WebFlux 的 ServerWebExchange
增加了网关特有的属性(如 GATEWAY_ROUTE_ATTR
存储路由、GATEWAY_REQUEST_URL_ATTR 存储目标 URL 等),通过
ServerWebExchangeUtils 工具类操作。
还有一点,Gateway 使用 WebClient(WebFlux 提供的响应式
HTTP 客户端)作为底层转发工具,在
org.springframework.cloud.gateway.filter.NettyRoutingFilter
中实现请求转发,完全遵循 WebFlux 的响应式编程模型(非阻塞、异步)。
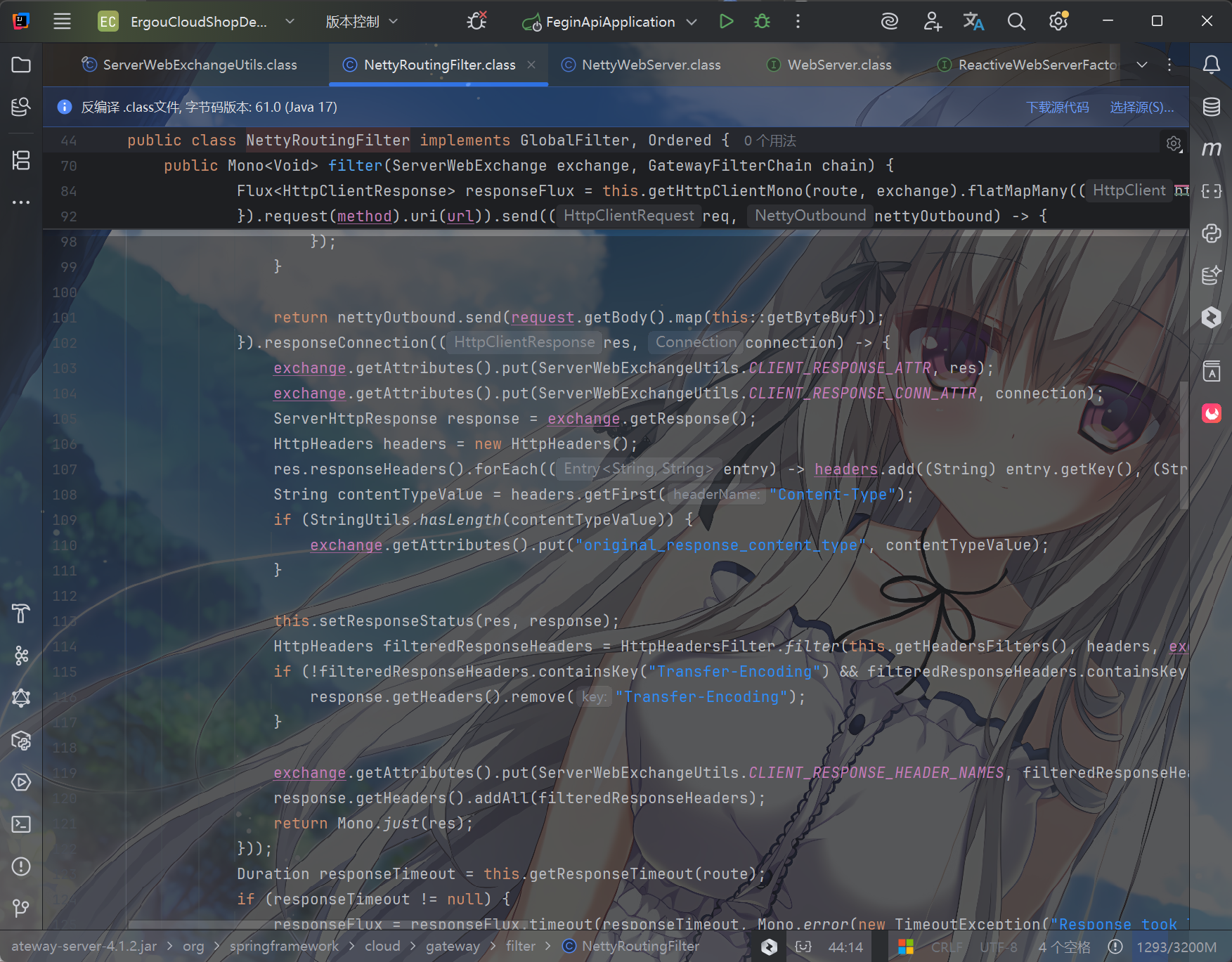
所以说
- WebFlux
提供基础骨架:
WebHandler(请求处理入口)、HandlerMapping(路由映射)、WebFilter(过滤链)、ServerWebExchange(上下文)、WebClient(响应式 HTTP 客户端)。 - Gateway 定制核心逻辑
- 用
FilteringWebHandler替代默认WebHandler,注入网关路由与过滤逻辑; - 用
RoutePredicateHandlerMapping替代默认HandlerMapping,实现基于谓词的路由匹配; - 基于
GatewayFilter/GlobalFilter扩展过滤机制,适配网关场景; - 全程使用
Mono/Flux响应式类型,保持与 WebFlux 编程模型一致。
- 用
什么你都要我细说?那我下面讲什么
Gateway 路由初始化
回旋镖打回来了,这里不得不提到包括GatewayAutoConfiguration的那一堆配置类文件,META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
在 Spring Cloud Gateway
启动时,根据约定大于配置原则,会自动初始化在
GatewayAutoConfiguration 配置的对象实例,其中包括
RouteDefinition 、RouteDefinitionLocator 、
RouteLocator,gatewayProperties
…..太多了,挑一些说吧。反正你要知道,这一个配置类包揽了 Gateway
核心功能的所有组件初始化。
在 GatewayAutoConfiguration
中,路由的初始化可以看作一个清晰的流水线过程:定义加载 ->
路由构建 -> 统一处理。这个过程由以下几个关键的 Bean
协作完成:
路由定义加载器 (RouteDefinitionLocator)
这是路由初始化的源头。它的职责是从各种数据源中发现和加载路由的原始定义(RouteDefinition)。RouteDefinition
可以看作是路由的静态描述,比如我们在 application.yml
中写的配置。下面讲为什么
有几个重要的组件实现了上述 RouteDefinitionLocator
接口
propertiesRouteDefinitionLocator(GatewayProperties properties)

点进去内部实现
1 | import org.springframework.cloud.gateway.route.RouteDefinition; |
- 作用:这个 Bean 负责从项目的配置文件(如
application.yml或application.properties)中读取以spring.cloud.gateway.routes为前缀的配置,并将它们解析成RouteDefinition对象。这是最常用的一种路由定义方式。 - 它是静态路由配置的直接入口。
routeDefinitionLocator(List<RouteDefinitionLocator> routeDefinitionLocators)

其中,CompositeRouteDefinitionLocator的核心能力是
“组合”,从@Bean定义可以看到,routeDefinitionLocator方法注入了List<RouteDefinitionLocator>——
这是 Spring 容器自动收集的所有实现了
RouteDefinitionLocator 接口的
Bean(包括PropertiesRouteDefinitionLocator,以及未来可能添加的
Nacos/Consul 路由定位器等)。
这些定位器被包装成Flux<RouteDefinitionLocator>传入CompositeRouteDefinitionLocator的构造函数,作为其内部的delegates(委托者)列表。
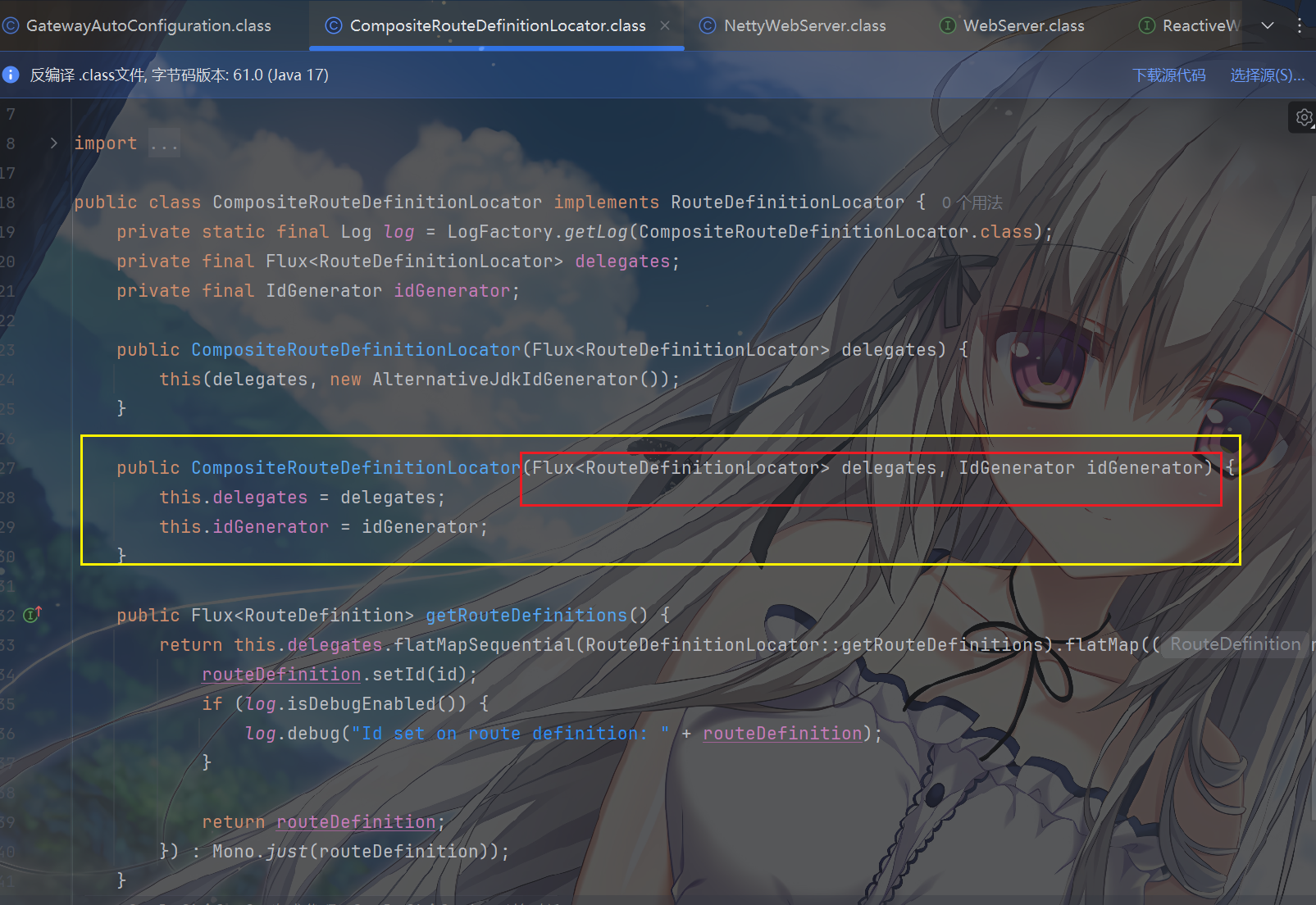
其中,CompositeRouteDefinitionLocator的getRouteDefinitions方法是实现聚合的关键:
1 | return this.delegates |
flatMapSequential:按顺序获取每个RouteDefinitionLocator的路由定义(Flux<RouteDefinition>),并将这些分散的流 “扁平” 合并成一个统一的Flux<RouteDefinition>。- 额外处理:如果某个路由定义没有 ID(可能来自自定义定位器),会自动生成唯一 ID,避免路由冲突。
而且,它提供了极高的扩展性。无论您从哪里加载路由定义,最终都会被它汇集起来进行统一处理。它被标记为
@Primary,是网关系统中首选的路由定义定位器。
可能大家还是对routeDefinitionLocator(List<RouteDefinitionLocator> routeDefinitionLocators)为什么能够支持任意的路由来源有些疑惑,而其中,CompositeRouteDefinitionLocator的扩展性来自于面向接口的设计
它依赖的是RouteDefinitionLocator接口,而非某个具体实现(如PropertiesRouteDefinitionLocator)。只要新的路由来源(如数据库、Redis、Nacos)实现了RouteDefinitionLocator接口并注册为
Spring
Bean,就会被自动纳入List<RouteDefinitionLocator>中,无需修改CompositeRouteDefinitionLocator的代码。
而Spring 容器会自动收集所有RouteDefinitionLocator类型的
Bean,无论何时添加新的实现(比如从注册中心加载路由的NacosRouteDefinitionLocator),CompositeRouteDefinitionLocator都会自动将其包含进来,实现
“即插即用” 的扩展。
这也就是为什么,定义了一大堆routeDefinitionLocator,就给它上了@Primary,馋死别人了
路由构建器 (RouteLocator)
RouteLocator 负责将加载到的 RouteDefinition
转换成网关在运行时真正使用的、可执行的 Route
对象。Route
对象内部包含了经过工厂(Factory)实例化的断言(Predicates)和过滤器(Filters)。

其中,routeDefinitionRouteLocator是流水线中最核心的“加工厂”。它订阅
RouteDefinitionLocator 提供的 RouteDefinition
流。是 Spring Cloud Gateway
中把路由定义转换为可执行路由的核心组件
RouteDefinitionRouteLocator是连接 “路由定义” 与
“实际路由” 的桥梁
构造函数注入了一堆依赖,光看依赖就知道他要干什么了
1 | public RouteDefinitionRouteLocator( |
RouteDefinitionLocator:提供源数据(RouteDefinition),是转换的 “输入”;RoutePredicateFactory/GatewayFilterFactory:是 “转换器”,负责将配置中的字符串定义(如Path=/users/**)转为可执行的代码逻辑(谓词 / 过滤器);GatewayProperties:提供全局默认配置(如defaultFilters,会应用到所有路由)。
所以说,对于每一个RouteDefinition,它会使用相应的
XXXXXFactory(如
GatewayFilterFactory、RoutePredicateFactory等,这些工厂也都在
GatewayAutoConfiguration中被初始化,上面说了)来创建组装成一个完整的、可执行的
Route 对象。
RouteDefinitionRouteLocator的核心逻辑是getRoutes()方法,整体流程为:获取路由定义
→ 转换为 Route 对象 →
返回可执行路由流,拆解如下,没事,下面我还要从另一个角度讲
获取路由定义
1
2
3public Flux<Route> getRoutes() {
return this.getRoutes(this.routeDefinitionLocator.getRouteDefinitions());
}- 从
RouteDefinitionLocator(如CompositeRouteDefinitionLocator)获取所有RouteDefinition(可能来自配置文件、Nacos 等); - 调用重载的
getRoutes(Flux<RouteDefinition>)方法,开始转换流程。
- 从
转换单个
RouteDefinition为Route(convertToRoute)每个
RouteDefinition通过convertToRoute方法转换为Route,核心是构建两个关键部分:路由谓词(匹配规则) 和网关过滤器(处理逻辑)。1
2
3
4
5
6
7
8
9
10
11private Route convertToRoute(RouteDefinition routeDefinition) {
// 1. 组合谓词:将多个谓词定义转为一个总的匹配规则
AsyncPredicate<ServerWebExchange> predicate = this.combinePredicates(routeDefinition);
// 2. 获取过滤器:加载默认过滤器和路由专属过滤器
List<GatewayFilter> gatewayFilters = this.getFilters(routeDefinition);
// 3. 构建Route对象
return Route.async(routeDefinition)
.asyncPredicate(predicate)
.replaceFilters(gatewayFilters)
.build();
}
所以说,RouteDefinitionRouteLocator这个转换器,上游依赖RouteDefinitionLocator(如CompositeRouteDefinitionLocator)提供路由定义,下游来生成的Flux<Route>被网关的路由匹配器(如SimpleRouteLocator)使用,用于处理请求时的路由匹配和过滤。
总结RouteDefinitionRouteLocator的核心作用就是
“将静态配置转为动态逻辑”
别忘了他也被CompositeRouteLocato组合路由定位器组合,所以说各种配置最后会合并的
请求处理器 (HandlerMapping & WebHandler)
当所有路由都构建并缓存好之后,就需要将它们应用到实际的请求处理中。
好像上面说了呢))所以在这里简单回顾一下算了
因为这两个分别对应
filteringWebHandler
创建 FilteringWebHandler 实例,它是 Gateway 中所有请求的最终执行者。它的核心职责是为一个请求构建并执行过滤器链

routePredicateHandlerMapping(FilteringWebHandler webHandler, RouteLocator routeLocator, ...)

这是 Gateway 请求处理的入口。它是一个 HandlerMapping(处理器映射器),在 WebFlux 体系中负责为请求找到对应的处理器(Handler)。它的工作流程是:
- 接收到一个请求 (ServerWebExchange)。
- 使用注入的
@Primary的RouteLocator(即带缓存的cachedCompositeRouteLocator)来查找与当前请求匹配的 Route。 - 如果找到,它就将匹配到的 Route 对象存入请求的上下文中。
- 然后,它并不直接处理,而是统一返回上面创建的
filteringWebHandler作为这个请求的处理器。
还有一些涉及到其他各种的 Handler ,再用到的时候我都会提到并且讲一下,别急
Gateway请求处理流程的源码分析
Spring Cloud Gateway的请求处理流程可以分为三个主要阶段:路由匹配、过滤器处理、请求转发。
Gateway 路由的查找,匹配与请求调度分发
一个 HTTP 请求到达后,其路由的查找和匹配过程可以分为三个主要层级:WebFlux 分发层、Gateway 路由映射层 和 Gateway 路由匹配层。
层级一:WebFlux 分发层 (请求的入口)
所有请求首先由 Spring WebFlux 的核心分发器接收,它负责将请求委派给正确的处理器。首先会落入 Spring WebFlux 框架的核心分发体系 中,这是请求处理的 “第一扇门”,决定着后续请求该往哪里走。
还记得上面我们提到的,找到匹配的Route之后,向
DispatcherHandler
返回一个统一的处理器——FilteringWebHandler
的实例,其中的DispatcherHandler 就是 Spring WebFlux 里
最核心的请求分发器
你可以理解为,当请求抵达底层服务器(比如基于 Netty 搭建的 HTTP
服务器)并被封装成
ServerWebExchange(包含请求、响应及各类上下文信息)后,DispatcherHandler
会被触发执行。它的核心工作是 遍历 Spring 容器中所有注册的
HandlerMapping 类型
Bean,依次询问它们:“你能不能处理当前这个请求呀?”,以此找到能真正处理该请求的后续处理器。
首先,DispatcherHandler 首先需要获取 Spring
容器中所有注册的 HandlerMapping 类型 Bean,这一过程在
initStrategies 方法中完成,也就是收集(遍历)
1 | protected void initStrategies(ApplicationContext context) { |
当请求抵达时,DispatcherHandler 的 handle
方法被触发,核心逻辑就在这里:
1 | public Mono<Void> handle(ServerWebExchange exchange) { |
- 通过循环调用各个
HandlerMapping的getHandler(ServerWebExchange exchange)方法,尝试获取可处理当前请求的Handler(通常是WebHandler实现类 )。一旦有某个HandlerMapping返回了有效的处理器,就停止遍历,把请求交接给这个处理器继续处理。
下面就是CORS跨域处理,本质上和上面普通请求一样
总结一下:
当一个请求进入应用时,
DispatcherHandler会被调用。它的核心职责是遍历 Spring 容器中所有注册的
HandlerMapping类型的 Bean。它会依次调用每个
HandlerMapping的getHandler(ServerWebExchange exchange)方法,询问:“你能处理这个请求吗?”一旦某个
HandlerMapping返回了一个处理器(WebHandler),DispatcherHandler就会停止遍历,并将请求交给这个返回的处理器去执行。
层级二:Gateway 路由映射层
在 Spring Cloud Gateway
的环境中,能够成功响应这个询问的,就是我们路由查找的主角:RoutePredicateHandlerMapping,其实本来想上面说的来着
1 |
|
当请求到达网关时,网关会从RouteDefinitionRouteLocator提供的Route中找到第一个匹配谓词的路由,然后执行该路由的所有过滤器,最终转发请求到目标服务。
那么,我们来拆解这个说法
其中,DispatcherHandler 会调用到
RoutePredicateHandlerMapping 的
getHandlerInternal(ServerWebExchange exchange) 方法(这是
getHandler 的内部实现)。
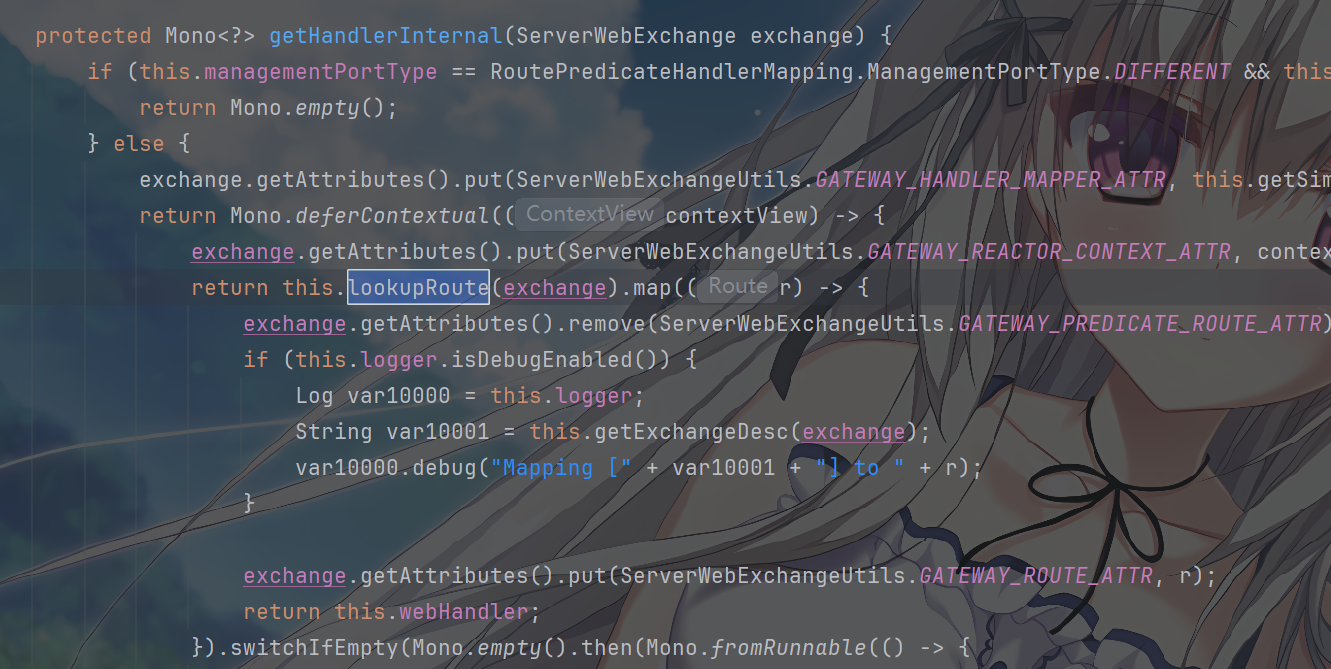
省去调用日志,此方法的核心逻辑就是调用
lookupRoute(ServerWebExchange exchange) 方法。
1 | /** |
lookupRoute 方法的职责非常纯粹:从 RouteLocator
中获取所有路由,然后逐一进行匹配,返回第一个匹配成功的
Route。
这个过程中的 this.routeLocator 就是下一层级的入口。一旦
lookupRoute 成功找到了一个
Route,RoutePredicateHandlerMapping 就会:
- 将这个 Route 对象存入
exchange的属性中 - 返回
this.webHandler,也就是FilteringWebHandler的实例,作为最终的请求处理器。
那么我们的断言工厂是如何实现自定义配置的?
联系一下我们上面的RouteDefinitionRouteLocator部分,在转换单个RouteDefinition为Route时候会装入我们自定义配置文件中路由断言工厂的内容
其中,路由定义中的predicates(如Path=/users/**、Method=GET)是就是我们之前讲的字符串配置的路由断言,combinePredicates负责将其转为可执行的AsyncPredicate(响应式谓词),并组合为一个整体匹配规则(多个谓词之间是
“逻辑与” 关系)。
1 | private AsyncPredicate<ServerWebExchange> combinePredicates(RouteDefinition routeDefinition) { |
lookup方法:根据谓词名称(如Path)找到对应的RoutePredicateFactory(如PathRoutePredicateFactory),将配置参数(如/users/**)绑定到工厂,生成AsyncPredicate实例。 例如:Path=/users/**会被PathRoutePredicateFactory转换为判断请求路径是否匹配/users/**的谓词。
Gateway 路由匹配层 (真正的匹配逻辑)
这一层由 RouteLocator 接口及其实现类构成,是查找和匹配逻辑最集中的地方
缓存层 (CachingRouteLocator)
它是缓存定位路由器,负责缓存 Route 配置,并包装代理
CompositeRouteLocator ,同时实现了
ApplicationListener
应用监听器接口、ApplicationEventPublisherAware
应用事件发布通知接口。
而且它也是一个CompositeRouteLocator组合式路由定位器,所以说,在开缓存的时候(条件注解),它也接收一个
Flux<RouteLocator>聚合系统中所有
RouteLocator
实现,并且缓存起来避免频繁去获取,当路由信息发生变化时(事件监听机制触发缓存刷新),它能更新缓存,保证路由信息的准确性。这个机制自己去看吧,不说了,也不难。
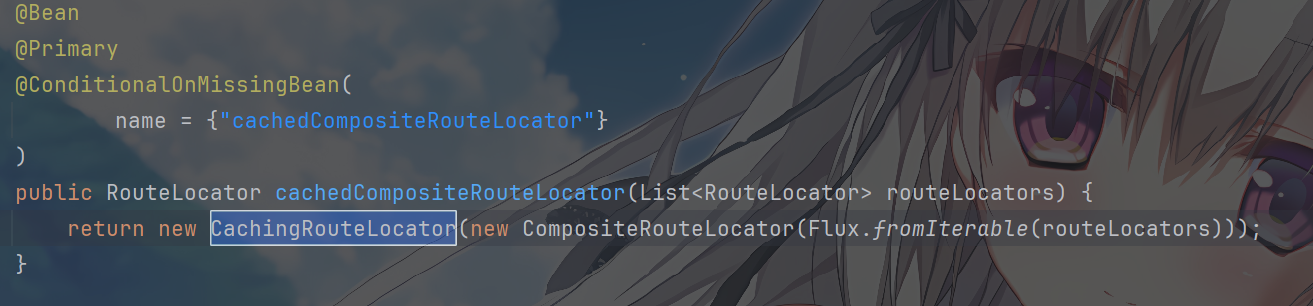
RoutePredicateHandlerMapping持有的是CachingRouteLocator的实例(因为它是@Primary Bean)。- 当调用
getRoutes()方法时,它首先会检查内部缓存。如果缓存中已有路由信息,则直接返回,避免了重复构建,这是性能优化的关键。 - 如果缓存未命中,它会委托给其内部包装的
RouteLocator去获取路由。
Spring Cloud Gateway
的作者使用了代理模式设计 RouteLocator
接口,代理关系链:CachingRouteLocator —>
CompositeRouteLocator —>
RouteDefinitionRouteLocator。
然后 RouteDefinitionRouteLocator获取到Route
路由信息的时候,又会进行如下调用链,RouteDefinitionRouteLocator
—> CompositeRouteDefinitionLocator —>
PropertiesRouteDefinitionLocator、InMemoryRouteDefinitionRepository
注意:在 GatewayAutoConfiguration
里会默认创建路由定义定位器 PropertiesRouteDefinitionLocator
实例,如果是基于内存保存的路由定义仓库为
InMemoryRouteDefinitionRepository 实例。
组合层 (CompositeRouteLocator):
CachingRouteLocator内部通常包装的是CompositeRouteLocator。这个我们熟悉,这个是搜集并且组合所有地方的路由定义的接口- 比如,一部分路由来自
RouteDefinitionRouteLocator(配置文件),另一部分可能来自你自定义的RouteLocator Bean。它将这些来源的路由流(Flux<Route>)合并成一个统一的流。
CompositeRouteLocator接口,
是路由定位器的组合模式实现,主要解决
“多个路由来源如何统一管理”
的问题,这个我上面忘记说了,在这里贴一下,如下,主要就是通过
delegates 存储多个 RouteLocator
实例(例如:从配置文件加载的路由、从数据库动态获取的路由、从服务注册中心发现的路由等),实现路由来源的聚合。
1 | import reactor.core.publisher.Flux; |
构建与匹配层 (RouteDefinitionRouteLocator & …PredicateFactory):
这里算是复习了,重述了不少上面的内容
原来CompositeRouteLocator
接口中,getRoutes() 这个方法通过
flatMapSequential 按顺序调用所有子定位器的
getRoutes(),将分散的路由合并为一个连续的流,保证路由的顺序性(与子定位器的定义顺序一致)。
而上述的CompositeRouteLocator 会调用到
RouteDefinitionRouteLocator 的 getRoutes()
方法。
欸我不是上面说了吗,算了,省略了一些日志代码,讲一下这个方法,
1 | private Flux<Route> getRoutes(Flux<RouteDefinition> routeDefinitions) { |
整个构建与匹配层获取配置的核心逻辑就是
- 它首先通过
RouteDefinitionLocator获取所有路由定义 (RouteDefinition),也就是你写在 YML 里的那些原始配置。 - 它遍历每一个
RouteDefinition,对每个定义调用convertToRoute()方法,将其从静态配置转换为可执行的运行时 Route 对象。 - 在
convertToRoute()方法内部,它会解析定义中的 predicates 列表(例如Path=/api, Method=GET)。 - 对于每一个断言配置(如
Path=/api/**),它会去org.springframework.cloud.gateway.handler.predicate包下查找同名的RoutePredicateFactory(例如PathRoutePredicateFactory)。 - 它使用找到的工厂,将配置(如
/api/**)转换为一个真正的Predicate<ServerWebExchange>函数式接口实例。 - 最后,它将一个
RouteDefinition中的所有断言函数通过and()方法组合成一个复合断言。这个复合断言就是Route对象中的核心匹配逻辑。
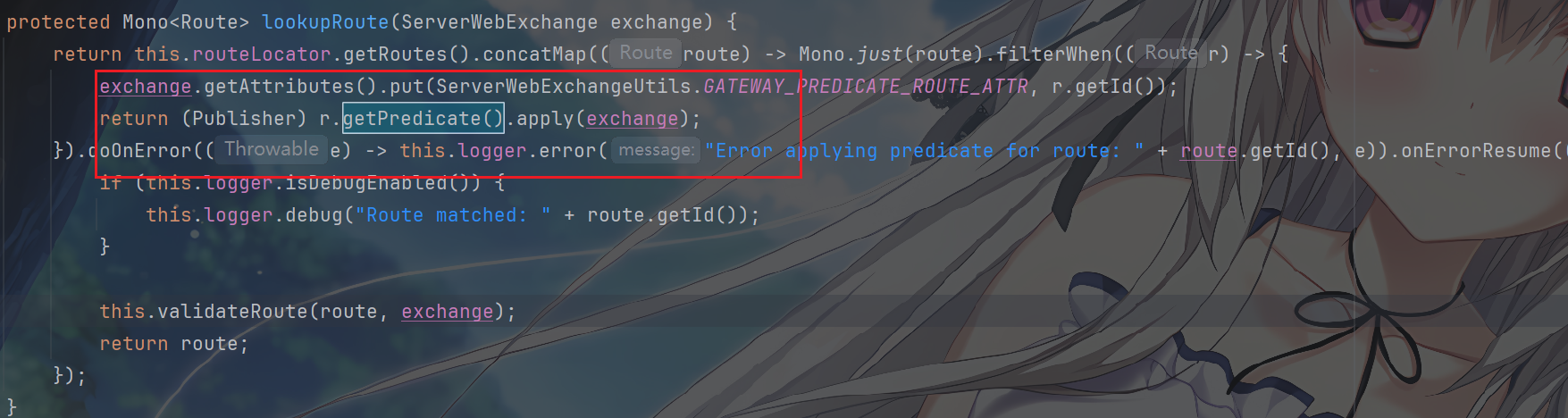
当 RoutePredicateHandlerMapping 在
lookupRoute 方法中执行
route.getPredicate().apply(exchange)时,就是在调用这个最终由所有断言工厂创建并组合起来的复合断言函数,从而判断当前请求是否与该路由的所有条件都匹配。
Gateway过滤器链的创建和处理
对于 Spring Cloud Gateway 的功能 ,基本
80%
功能是由过滤器实现的,这么说并不为过,因为负载均衡、实际请求转发、请求/响应重写等均是由过滤器完成的
前面程序完成查找 Route 后将委托
SimpleHandlerAdapter 适配器执行
FilteringWebHandler 的逻辑,包括获取
ServerWebExchange 上下文关联的 Route
路由、路由绑定的 GatewayFilter
过滤器、系统默认的全局过滤器等。
之后,就是分到FilteringWebHandler 进行处理了
我们之前看过Gateway过滤器链相关的内容,它就像一个
“请求加工厂”,先通过各种过滤器对请求进行过滤,最后用
WebClient
完成对外请求转发,把后端服务的响应再带回给客户端。
那么过滤器链(GatewayFilterChain)本身是如何驱动的?
回到我们的FilteringWebHandler类
而其中,首先,FilteringWebHandler的成员变量和构造方法这块都是接受并且存储所有全局过滤器List<GlobalFilter>,然后在下面转换成GatewayFilter
类型列表,注意一下,如果想看过滤器是怎么排序的,可以看这
loadFilters 方法

为啥要转一下?因为全局过滤器和路由过滤器接口不同,需要统一类型,索性都通过GatewayFilterAdapter将GlobalFilter包装为GatewayFilter,也顺便做了排序的准备
其中的核心就是handle 方法,作为 WebHandler
的实现方法,handle 是处理 HTTP
请求的入口,当请求到达网关时,handle方法是处理入口,负责构建完整的过滤器链:
1 | public Mono<Void> handle(ServerWebExchange exchange) { |
其中实现 GatewayFilterChain
接口,他就负责按顺序执行过滤器,别的不搞,不信你看

Gateway 过滤器至暗时刻来了,那我的那么多东西都哪去了,找吧
其中,我们看到,FilteringWebHandler有个内部类DefaultGatewayFilterChain,上面说了,new DefaultGatewayFilterChain(combined)创建过滤器链,并调用其filter(exchange)方法启动执行过滤器链,它实现了GatewayFilterChain
DefaultGatewayFilterChain是GatewayFilterChain接口的实现类,采用责任链模式,负责按顺序执行过滤器链中的每个过滤器。
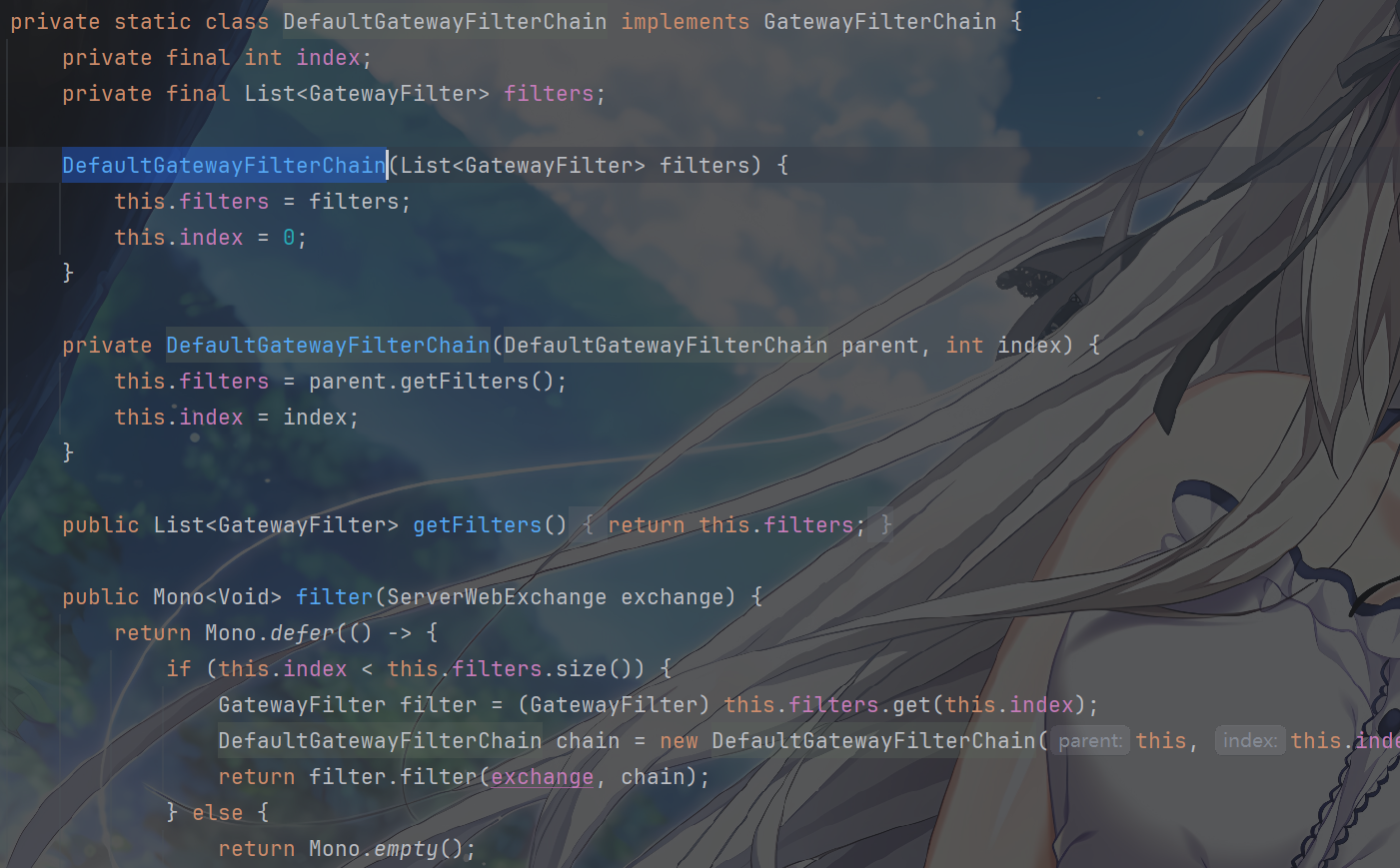
DefaultGatewayFilterChain 内部维护了两个关键成员
filters:已排序的GatewayFilter列表(全局过滤器 + 路由过滤器的合并结果)。index:当前要执行的过滤器索引(从 0 开始),用于追踪过滤器链的执行进度。
构造方法,就是链表,自己看一下吧,其中私有构造new DefaultGatewayFilterChain(parent, index + 1)用于创建下一个过滤器链节点,index递增
1,指向当前过滤器的下一个。
来到其核心方法,filter(ServerWebExchange exchange),该方法是过滤器链执行的核心逻辑,采用递归方式驱动过滤器依次执行:
1 | public Mono<Void> filter(ServerWebExchange exchange) { |
正是基于上述的链式调用模型,过滤器的“Pre”和“Post”逻辑才得以实现。在一个典型的过滤器中,抽象出的代码结构如下:
1 | public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { |
最后,在过滤器链执行过程中,除了常见的 “修改请求 / 响应”
逻辑,Gateway 还会在合适的时机(过滤器链末尾),通过
NettyRoutingFilter 等具体过滤器,使用
WebClient(WebFlux 提供的响应式 HTTP 客户端 )完成
请求的最终转发 。
着重说一下,NettyRoutingFilter这个是 Spring Cloud
Gateway 中的一个全局过滤器,主要用于将请求转发到后端服务。它基于 Netty
实现的 HttpClient 来处理 HTTP
请求和响应。NettyRoutingFilter
是最后一个执行的过滤器,确保所有前置过滤器都已处理完请求。
1 | public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { |
但它并不是孤立的。在它执行之前,有几个关键的全局过滤器为它铺平了道路。整个请求转发过程是一个精心编排的组合拳。
- 准备阶段 (RouteToRequestUrlFilter)
- 职责:
这是个全局过滤器,它的顺序比较靠前。它的任务是从 Route 的 URI(例如
lb://user-service)中解析出最终要请求的、具体的 URL。如果 URI 是负载均衡的(lb://),它会与LoadBalancerClient交互来选择一个服务实例。然后,它将解析出的最终 URL 放入ServerWebExchange的属性中(键为GATEWAY_REQUEST_URL_ATTR)。 - 这里实现了和负载均衡的组合
- 职责:
这是个全局过滤器,它的顺序比较靠前。它的任务是从 Route 的 URI(例如
- 执行阶段 (NettyRoutingFilter)
- 职责: 这个过滤器被设置为
Ordered.LOWEST_PRECEDENCE,确保它在过滤器链的几乎末尾执行。 - 它不直接使用
WebClient,而是使用更底层的Reactor Netty的HttpClient。 - 它的
filter方法会:- 从
exchange的属性中取出由RouteToRequestUrlFilter准备好的目标 URL。 - 将当前请求的头信息、方法、请求体等内容复制到
HttpClient的请求中。 - 在发送请求前,它还会应用一系列
HttpHeadersFilter(例如RemoveHopByHopHeadersFilter、XForwardedHeadersFilter)来清理和规范化请求头。 - 使用
HttpClient异步地将请求发送到目标服务。 - 收到响应后,它会把下游服务的响应码、响应头、响应体写回到
ServerWebExchange的response对象中。 - 设置一个特殊的
exchange属性GATEWAY_ROUTE_FILTERS_APPLIED_ATTR,标志着路由过滤器已经执行完毕,避免重复执行。
- 从
- 职责: 这个过滤器被设置为
- 收尾阶段 (NettyWriteResponseFilter)
- 职责: 它的顺序紧跟在
NettyRoutingFilter之后 (LOWEST_PRECEDENCE - 1)。它的任务是检查NettyRoutingFilter是否已经将响应写回。如果已经写回,它会拿到响应体(一个Flux<DataBuffer>),并将其真正地写入底层的 Netty 连接,发送给客户端。
- 职责: 它的顺序紧跟在
请求的最终转发不是由一个过滤器独立完成的,而是由
RouteToRequestUrlFilter(定址)、NettyRoutingFilter(发包和收包)、NettyWriteResponseFilter(回写响应)等一系列高度协同的全局过滤器共同完成的。
简单说一下,其中的过滤器排序的机制
排序的核心依据是上面
FilteringWebHandler中的order值决定:
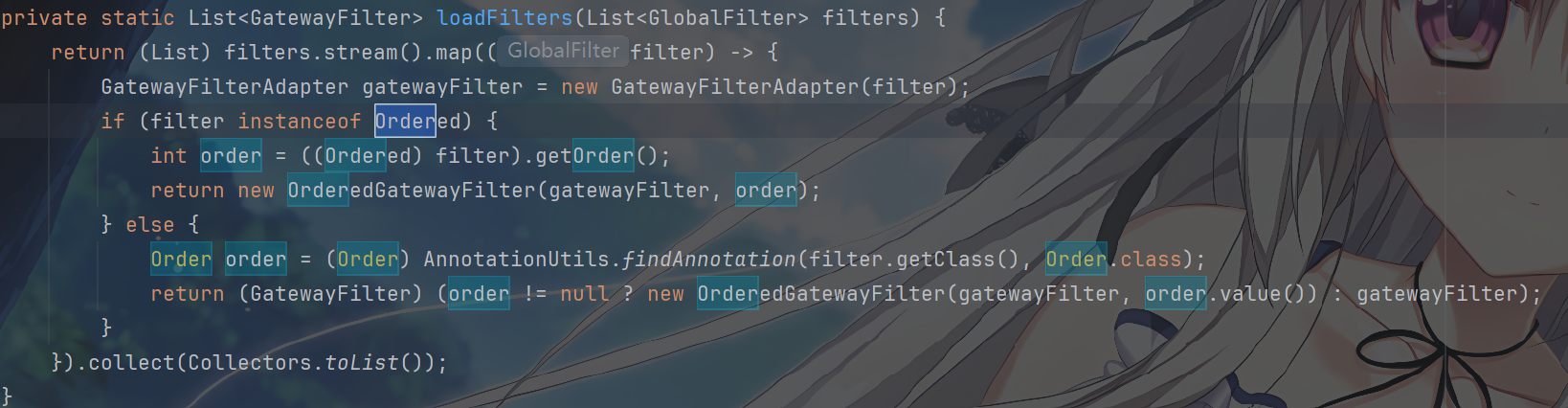
没错,这是 Spring
生态中统一的排序规则(如Ordered接口、@Order注解),Gateway
直接复用了这一机制。
在loadFilters方法中,系统会为每个过滤器(尤其是全局过滤器)确定order值
1 | // 伪代码简化逻辑 |
- 全局过滤器(GlobalFilter):通过上述逻辑确定
order后,会被包装为OrderedGatewayFilter(包含过滤器实例和order值)。 - 路由过滤器(Route-specific
Filter):在路由配置中定义时,通常已通过
order属性指定顺序(如spring.cloud.gateway.routes.filters.order),最终也会转换为OrderedGatewayFilter。
排序的核心就是在handle方法中的AnnotationAwareOrderComparator.sort(combined)
这是Spring
提供的排序工具类,专门处理实现Ordered接口或带有@Order注解的对象。其中
findOrder是提取排序依据的核心方法,逻辑如下:
1 |
|
- 第一步(
super.findOrder):调用父类OrderComparator的实现,检查对象是否直接实现了Ordered接口。若实现,则通过getOrder()方法获取order值。- 例如:路由过滤器常被包装为
OrderedGatewayFilter(明确实现Ordered接口),全局过滤器若实现Ordered也会在此处被提取。
- 例如:路由过滤器常被包装为
- 第二步(
findOrderFromAnnotation):若对象未实现Ordered接口,则从类的@Order注解中提取order值。- 例如:若某个全局过滤器未实现
Ordered,但类上标注了@Order(10),则会通过此逻辑提取order=10。
- 例如:若某个全局过滤器未实现
全局过滤器会被GatewayFilterAdapter包装(见FilteringWebHandler的loadFilters方法),但AnnotationAwareOrderComparator通过处理DecoratingProxy接口,能穿透包装类获取原始过滤器的注解:
1 | if (order == null && obj instanceof DecoratingProxy decoratingProxy) { |
GatewayFilterAdapter实现了DecoratingProxy接口,其getDecoratedClass()会返回原始GlobalFilter的类。- 因此,即使全局过滤器被包装,
@Order注解仍能被正确识别(从原始类中提取)。
全局过滤器和路由过滤器能在同一维度比较,本质是因为它们最终都被转换为可提取order值的对象,且AnnotationAwareOrderComparator对两者的order值提取逻辑完全一致:
| 过滤器类型 | 常见形式 | order值来源 |
提取逻辑 |
|---|---|---|---|
| 全局过滤器 | GatewayFilterAdapter包装类 |
1. 原始GlobalFilter实现Ordered接口 2.
原始GlobalFilter有@Order注解 |
若为DecoratingProxy,穿透获取原始类的order |
| 路由过滤器 | OrderedGatewayFilter |
实现Ordered接口(getOrder()返回配置的order) |
直接通过Ordered接口提取 |
通过上述逻辑,无论是全局过滤器还是路由过滤器,最终都会被转换为一个包含order值的
“可比较对象”。AnnotationAwareOrderComparator对所有对象一视同仁,仅根据order值大小排序(小值优先),因此能实现
“全局过滤器与路由过滤器的混合排序”。
那么配置文件中,是如何实现配置文件定义过滤器的
联系一下我们上面的RouteDefinitionRouteLocator部分,在转换单个RouteDefinition为Route时候会装入我们自定义配置文件中过滤器的内容,其中就是路由定义中的filters(如AddRequestHeader=X-Request-Source,gateway)也是配置文件中的那个熟悉的字符串配置,getFilters负责将其转为可执行的GatewayFilter实例,并合并全局默认过滤器。这里也就是实现我们能够在配置文件中自定义过滤器的基础
1 | private List<GatewayFilter> getFilters(RouteDefinition routeDefinition) { |
loadGatewayFilters方法:根据过滤器定义,通过对应的GatewayFilterFactory生成GatewayFilter实例。 例如:AddRequestHeader=X-Request-Source,gateway会被AddRequestHeaderGatewayFilterFactory转换为 “添加请求头” 的过滤器。- 排序逻辑:过滤器通过
Ordered接口或OrderedGatewayFilter指定顺序,最终按顺序执行(如先认证过滤,再日志过滤)。
过滤器执行中被其他组件拦截
也就是实现,Gateway 与其他组件进行结合
有空再说吧,累了





