
前言
首先,这篇文章你得会掌握 Spring Cloud Gateway 的基本使用和各种配置你能读懂,才能看懂
而且你也要知道网关是干什么的,在微服务中的作用是什么,这些内容要懂
- Gateway 处理请求的逻辑是根据 配置的路由 对请求进行 预处理 和 转发
- 单体应用拆分成多个服务后,对外需要一个统一入口,解耦客户端与内部服务
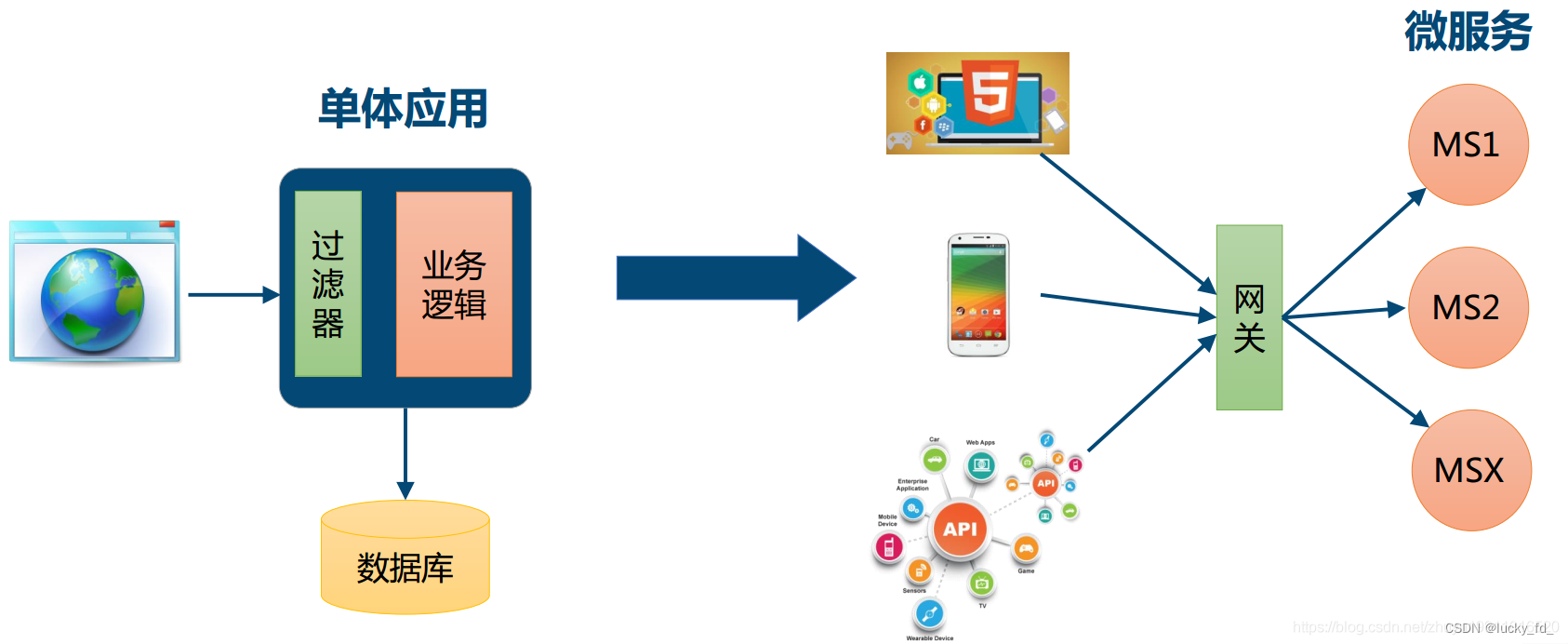
网关的作用你也要了解,在这里我不再说了,贴张图供大伙回顾一下
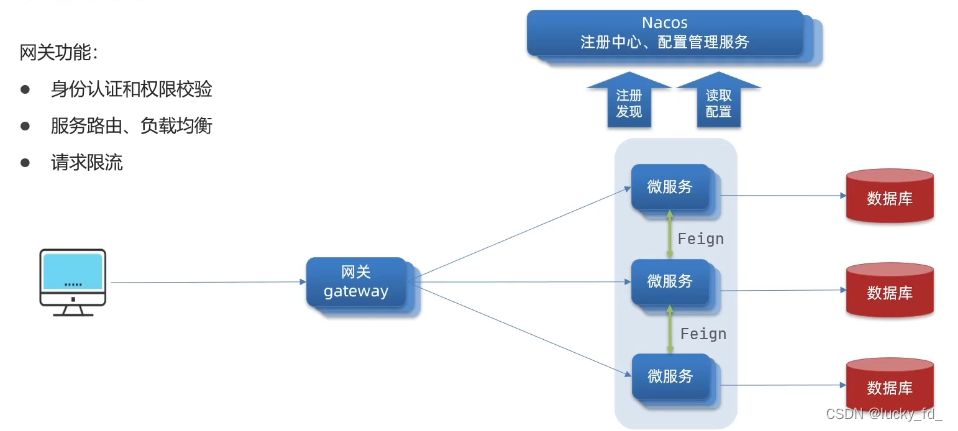
而且你要懂计算机网络的基本知识和一些实现原理,因为我在这里不会细说
因为这篇文章会基于我上篇使用篇继续讲解
Gateway 的工作机制
实现一个网关的几种方式
基于 Socket Api 实现
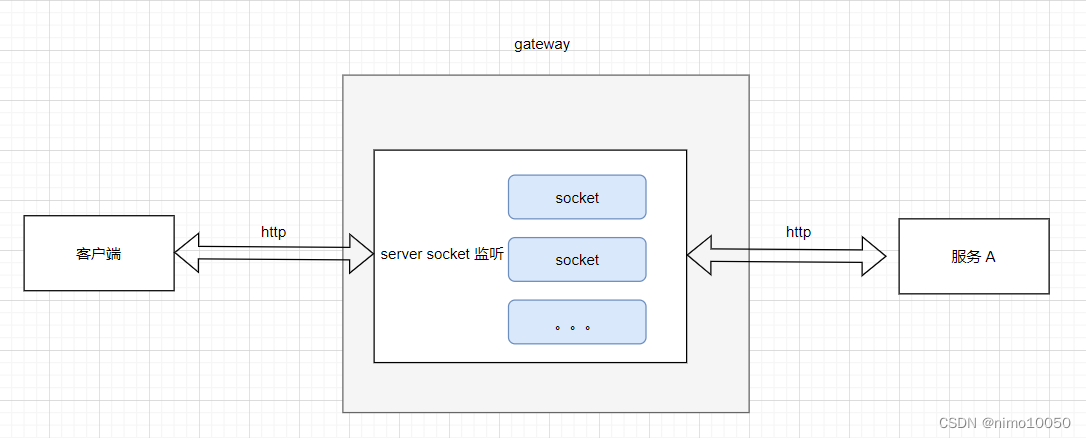
这是最基础、最底层的实现方式。它直接利用操作系统提供的 Socket API 来进行网络通信,从而构建网关。
实现的原理如下:
- 监听端口:网关服务器启动后,会创建一个 server socket(服务器套接字),并绑定到一个特定的端口(例如,HTTP 默认的 80 端口或 HTTPS 的 443 端口)进行监听。
- 接受连接:当客户端向网关发起一个 HTTP 请求时,操作系统底层会完成 TCP 的三次握手,然后 server socket 会接受这个连接,并为这个连接创建一个新的 socket。
- 读取与解析:网关通过这个新的 socket 读取客户端发送过来的原始数据流。因为是 HTTP 请求,所以这些数据流遵循 HTTP 协议的格式(请求行、请求头、请求体)。网关需要自己编写代码来解析这些数据。
- 转发请求:网关根据解析出的请求内容(比如请求的路径或头部信息),决定要将这个请求转发给后端的哪个微服务(例如图中的“服务 A”)。网关会作为“客户端”,创建一个新的 socket去连接后端服务。
- 返回响应:网关向后端服务发送请求后,会等待并接收后端服务的响应数据。接收到后再将这些数据通过之前与客户端建立的 socket 连接,回传给客户端。
基于 Netty 实现
Netty 是一个高性能、异步事件驱动的网络应用框架。它在 Java 的 NIO 基础上进行了更高层次的封装,极大地简化了网络编程的复杂性。
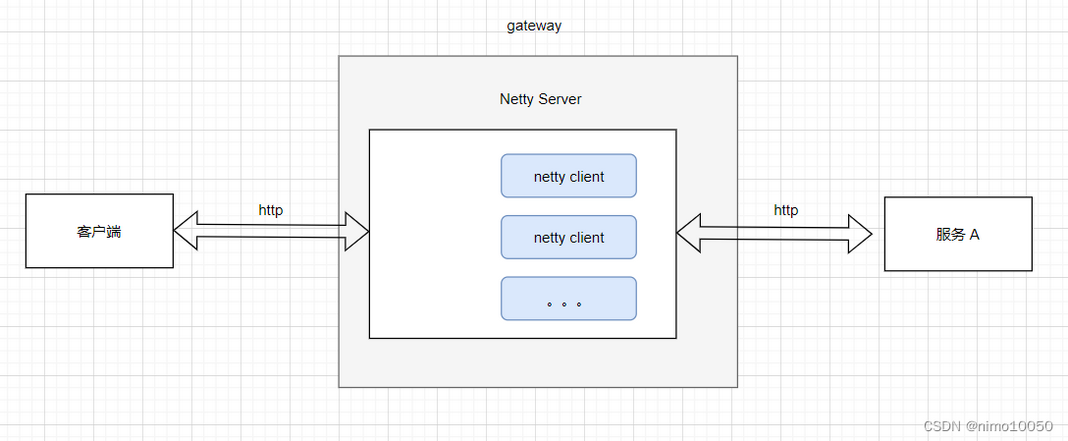
这个的实现原理就已经比较贴近 Spring Cloud 的网关实现了
- Netty Server:网关内部启动一个 Netty 服务器来接收客户端的连接请求。
- 事件驱动模型:Netty 使用了事件驱动和异步非阻塞 I/O 的模型。当有新的连接、数据可读等事件发生时,Netty 的事件循环(EventLoop)会调用相应的处理器(Handler)进行处理。
- 编解码器 (Codec):Netty 提供了丰富的编解码器。例如,它内置了 HttpRequestDecoder 和 HttpResponseEncoder,可以自动将原始的字节流数据转换成 HTTP 请求对象(如 HttpRequest),或者将 HTTP 响应对象编码成字节流,开发者无需手动解析 HTTP 协议。
- Netty Client:当需要将请求转发到后端服务时,网关会利用 Netty 内置的客户端功能(Netty Client)去连接后端服务(如“服务 A”)。
- 业务处理:开发者只需要编写自己的业务处理器(Handler),在其中获取到解码后的 HttpRequest 对象,根据业务逻辑(如路由规则)创建新的请求,通过 Netty Client 转发出去,并处理后端返回的响应。
基于 Web 框架实现
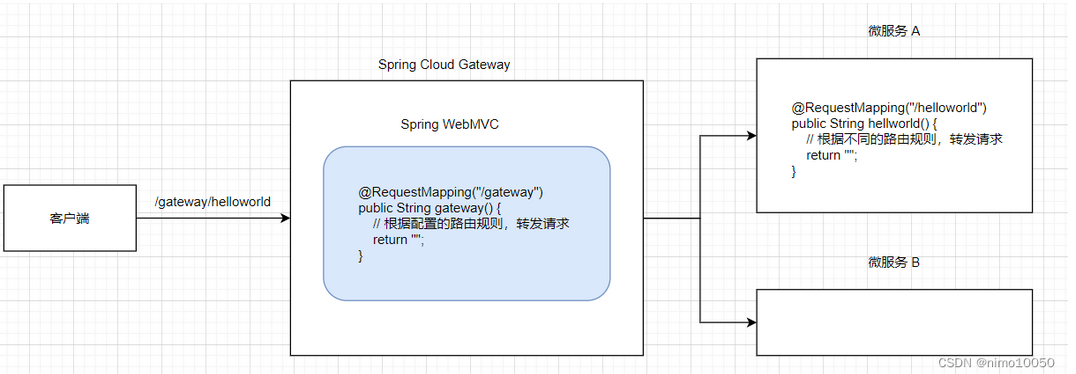
这是最高层次、最便捷的实现方式。它利用成熟的 Web 框架来构建网关,开发者完全不需要关心底层的网络通信细节,只需要进行配置和编写少量业务逻辑即可。
这个的原理就是我们今天要在这里细说的 Spring Cloud Gateway 的主要原理
- 高度抽象:Spring Cloud Gateway 是构建在 Spring WebFlux 之上的,而 Spring WebFlux 又是基于 Netty 的。所以它的底层依然是 Netty 和 NIO,但它为开发者提供了极高层次的抽象。
- 路由 (Route):这是网关的核心功能。开发者通过配置文件或代码来定义路由规则。一个路由通常由一个 ID、一个目标 URI、一组断言(Predicate)和一组过滤器(Filter)组成。
- 断言 (Predicate):当请求到达网关时,网关会用断言来判断这个请求是否匹配当前路由。例如,可以根据请求的路径(如 /gateway/helloworld)、请求方法(GET/POST)、Header 等进行匹配。
- 过滤器 (Filter):如果请求匹配了某个路由的断言,那么在将请求转发到目标 URI 之前(或之后),请求会被该路由关联的一系列过滤器处理。过滤器可以用来修改请求/响应、进行认证授权、限流、记录日志等。
- 请求转发:一旦请求通过了所有前置过滤器,Spring Cloud Gateway 内部的 DispatcherHandler 会将请求代理转发到路由指定的目标微服务(如“微服务 A”或“微服务 B”)。
而 Spring Cloud 中网关的实现包括两种
- Zuul
- Zuul
是基于
Servlet的实现,在1.x版本属于阻塞式编程,在2.x后是基于 netty,是非阻塞的。
- Zuul
是基于
- Spring Cloud Gateway
- SpringCloudGateway 则是基于 Spring5 中提供的 WebFlux,属于响应式编程的实现,具备更好的性能。
Spring Cloud Gateway 的架构分析
网关核心功能是路由转发,执行过滤器链等一些附加的路由功能,因此不要有耗时操作在网关上处理,让请求快速转发到后端服务上,网关如果出现性能阻塞会很严重,除非特意限流
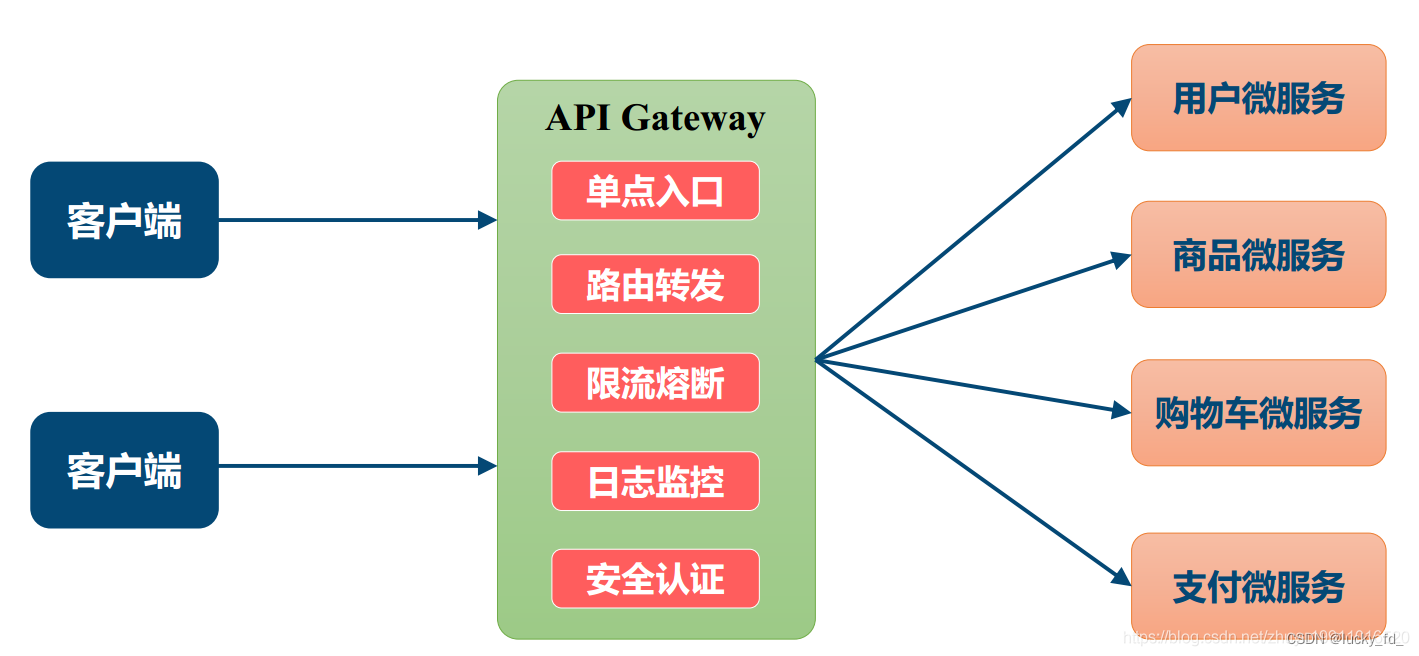
首先我先说一下,Spring Cloud 微服务生态中,有两个核心原则为 Gateway 的工作奠定了基础:
- 服务的注册与发现 (Service Registration &
Discovery)
- 当一个网关需要调用另一个服务时,它不会硬编码对方的 IP 地址。而是向注册中心询问:“请告诉我 xxx 现在有哪些可用的实例地址?” 注册中心会返回一个健康的实例列表。
- 客户端负载均衡 (Client-Side Load Balancing)
- 调用方网关需要决定到底调用哪一个。这个决策过程就在调用方客户端完成,因此称为客户端负载均衡。
Spring Cloud Gateway 的架构设计如下图
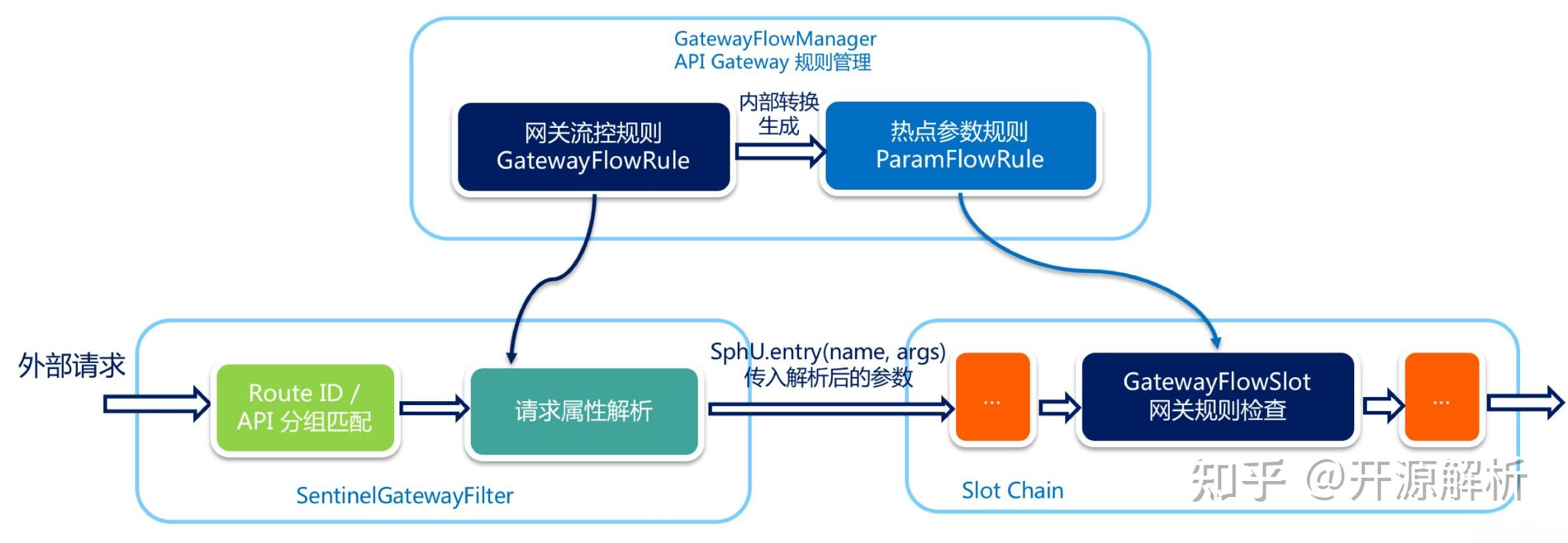
核心组件和我们在上篇文章讲的需要自定义的一样
- Route:代表网关中的一条路由,包含匹配条件和具体的转发目标。这是网关的基本构建块。它由一个 ID、一个目标 URI、一组断言(Predicates)和一组过滤器(Filters)组成。如果断言为真,则匹配该路由。
- Predicate:定义路由的匹配条件,如请求路径、HTTP方法等。
- Filter:对请求和响应进行处理,可以进行修改、增强或拦截。这是网关的核心功能所在。它允许你在请求被转发到下游服务之前(pre-filtering)或从下游服务收到响应之后(post-filtering)对请求或响应进行修改。
而图中的主要模块结合了结合 Sentinel 流控,我们来简单拆解一下 Spring Cloud Gateway
外部请求进入网关后,会经历 “匹配路由 → 解析规则 → 流控校验 → 转发 / 响应” 的完整流程,对应图中模块的串联逻辑:
- 路由匹配(Route ID / API 分组匹配)
- 组件:
SentinelGatewayFilter(也可理解为 Gateway 自身的路由匹配逻辑) - 根据请求的 路径、方法、Header
等信息,匹配到预先定义的
Route(路由)。- 比如请求路径是
/api/user,会匹配到配置中predicates: Path=/api/user的路由。
- 比如请求路径是
- 关键逻辑:Spring Cloud Gateway 通过
RouteLocator加载路由规则,用Predicate(断言)判断请求是否符合路由条件。
- 组件:
- 请求属性解析
- 作用:提取请求的 关键属性(如路径参数、Header、客户端 IP 等),为后续流控、过滤做准备。
- 典型场景:解析出
userId=123作为热点参数,或提取token做权限校验。
- 流控规则的校验
- 组件:
SphU.entry(...)、GatewayFlowSlot、Slot Chain - 用 Sentinel 流控规则 拦截异常流量,避免下游服务被压垮。不细说了
- 组件:
- 过滤器链
- 组件:
Filter(包含自定义过滤器、Gateway 内置过滤器) - 作用:对请求 / 响应 “预处理(pre,添加请求头)” 或 “后处理(post,修改响应头)”
- 按照过滤器的
Ordered优先级排序,形成责任链依次执行。前一篇说过了
- 组件:
那么, 如何理解 Spring WebFlux,我们暂且就把它当做 Spring
WebMVC。一个 web 框架。他们之间很重要的一个区别就在于 webmvc
我们一般会基于 tomcat 容器去完成底层的网络通信, 而 webflux
是基于 Netty。
Spring Cloud Gateway 的工作流程分析
Spring Cloud Gateway 的工作流程与请求的生命周期息息相关
网关的核心逻辑就是路由转发。在下面的处理过程中,Gateway Handler Mapping 将请求和路由进行匹配,这时候就需要用到 predicate,它是决定了一个请求是否走哪一个路由。
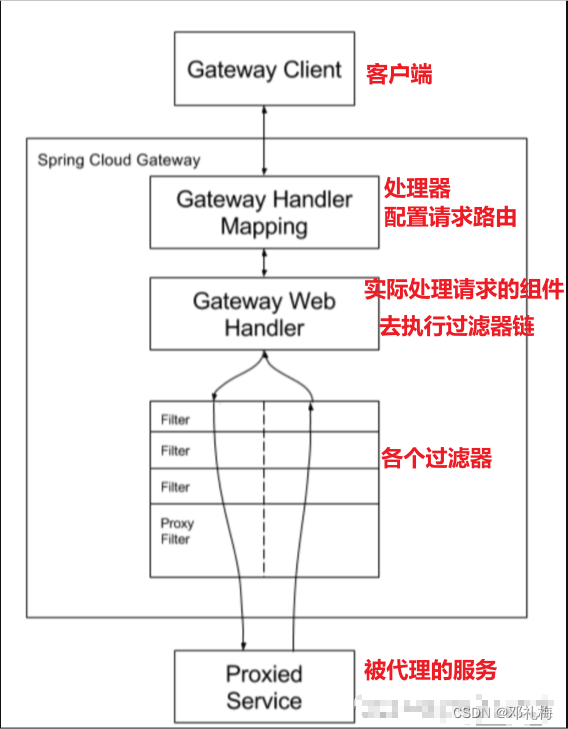
- 客户端向 Spring Cloud Gateway 发出请求。
- 如果 Gateway Handler Mapping 找到与请求相匹配的路由,将其发送到 Gateway Web Handler。
- Handler 再通过指定的 过滤器链 来将请求发送到我们实际的服务执行业务逻辑,然后返回。
- 过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑。
上面是省流版,下面是详细的网关各个工作步骤的详细流程的讲解
请求入口与路由匹配 (Gateway Client -> Gateway Handler Mapping):
- 请求到达:一切始于左上角的 Gateway Client(客户端),它向网关发起一个 HTTP 请求。
- 路由定位:请求进入 Spring Cloud Gateway 后,首先到达 Gateway Handler Mapping。这个组件的核心职责正如其名——“处理器映射”。它维护了所有的路由规则(即你在配置文件中定义的 routes),并根据请求的属性(如路径、请求头等)与每个路由的断言(Predicates)进行匹配。它的目标只有一个:为当前请求找到唯一匹配的路由规则。如果找不到,请求将被拒绝。
构建并执行过滤器链 (Gateway Web Handler -> Filters “Pre” 阶段)
- 移交处理:一旦
Gateway Handler Mapping成功匹配到路由,它会将请求连同匹配到的路由信息一起传递给 Gateway Web Handler。 - 组织过滤器:
Gateway Web Handler是真正的处理核心。它会获取所有需要对该请求生效的过滤器,这包括两种:- 全局过滤器 (Global Filters):对所有路由都生效。
- 路由特定过滤器 (GatewayFilter):仅在当前匹配的路由上配置的过滤器。 它将这些过滤器按照优先级排序,组成一个有序的过滤器链 (FilterChain)。
- “Pre”
过滤执行:如图中向下的箭头所示,请求开始依次穿过整个过滤器链。这个过程被称为
“Pre”
阶段。在这个阶段,每个过滤器都可以对请求进行检查或修改,例如:
- 执行身份认证和权限校验。
- 记录请求日志。
- 添加、删除或修改请求头。
- 对请求进行限流。
- 移交处理:一旦
代理请求到后端服务 (Proxy Filter -> Proxied Service)
- 请求转发:在请求成功通过所有 “Pre”
阶段的过滤器后,它会来到过滤器链的末端。图中特别标注了一个 Proxy
Filter,这代表了执行代理转发功能的特殊过滤器。在实际的实现中,这通常是由
NettyRoutingFilter或LoadBalancerClientFilter等过滤器完成的。 - 服务发现与负载均衡:这个代理过滤器会解析路由中配置的目标
URI。如果 URI 是
lb://user-service这样的形式,它会与服务发现组件(如 Nacos)交互,获取 user-service 的所有健康实例地址,并通过负载均衡策略选择一个最终的目标地址。 - 发出请求:最后,Gateway 会构建一个新的 HTTP 请求(包含了经过前面过滤器修改后的信息),并将其异步地发送给图中下方的 Proxied Service(被代理的后端微服务)。
- 请求转发:在请求成功通过所有 “Pre”
阶段的过滤器后,它会来到过滤器链的末端。图中特别标注了一个 Proxy
Filter,这代表了执行代理转发功能的特殊过滤器。在实际的实现中,这通常是由
响应的返回与处理 (“Post” 阶段)
接收响应:Proxied Service 处理完业务逻辑后,将响应数据返回给 Spring Cloud Gateway。
“Post” 过滤执行:如图中向上的箭头所示,响应会以相反的顺序再次穿过整个过滤器链。这个过程被称为 “Post” 阶段。在这个阶段,每个过滤器都有机会对返回的响应进行处理,例如:
添加统一的响应头。
对响应内容进行格式转换或修改。
记录响应日志和处理时长。
响应返回客户端
- 最终返回:当响应成功穿过所有 “Post” 阶段的过滤器后,Gateway Web Handler 将最终的、处理完毕的响应交还给 WebFlux 引擎,最终由 Netty 将其发送回最初的 Gateway Client。
Spring Cloud Gateway 的实现原理
SpringCloud Gateway 是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关。为了提升网关的性能,SpringCloud Gateway 是基于 WebFlux 框架实现的,而 WebFlux 框架底层则使用了高性能的 Reactor 模式通信框架 Netty。
结合我们上面讲的,可以重新剖析一下官网的描述,而这段官方描述非常精炼,它准确地指出了 Spring Cloud Gateway 高性能的根源。Netty、Project Reactor 和 WebFlux
我们可以将这三者的关系看作一个层层递进的技术栈,了解下 webflux 的工作原理, 然后延伸到 gateway 是如何基于 webflux 做扩展的
底层引擎:Netty 与 Reactor 设计模式
我们在文章开头已经提到过,实现网关可以基于 Netty。Spring Cloud Gateway 正是这样做的,它没有重新发明轮子,而是选择站在了巨人 Netty 的肩膀上。
- Netty 是什么? 它是一个高性能的、异步事件驱动的网络通信框架。你可以把它理解为一个经过极致优化的“网络服务器骨架”。当客户端的一个连接请求到达服务器时,是 Netty 负责接收这个连接,并读取上面的数据。
- 核心优势:Reactor 设计模式 Netty
的高性能秘诀在于它使用了 Reactor
设计模式。为了理解这个模式,我们可以对比传统的阻塞式 I/O
模型(如早期版本的 Tomcat):
- 传统阻塞模型:就像一个“一人服务一桌”的餐厅。来一个请求,就派一个线程专门为他服务。如果这时候出现了阻塞(比如数据库查询慢),这个线程就得在旁边干等着,出现忙等,不能去服务别的请求。如果请求太多,就需要开一堆线程,管理成本和开销(系统资源)巨大。
- Reactor
模式:就像一个“超级服务员”的餐厅。餐厅只有一个或少数几个“超级服务员”(Reactor
线程/EventLoop)。此线程永远不会被“等待做菜”这种 I/O
操作阻塞。他的工作流程是:
- A 客人来了,他迅速记下菜单(接收连接和请求事件),把菜单交给后厨(业务线程池处理),然后立刻去服务 B 客人。
- B 客人来了,同样的操作,把菜单交给后厨,再去服务 C 客人。
- 当后厨喊“A 的菜好了!”(I/O 操作完成事件),他会立刻放下手头的工作,把 A 的菜送过去,然后继续去处理其他事件。
- 也就是说,Netty 利用 Reactor 模式,可以用极少数的线程处理海量的并发连接,从根本上解决了传统模型因 I/O 阻塞导致的性能瓶颈和资源浪费问题。
编程范式:Project Reactor 响应式库
Netty 解决了底层 I/O 的效率问题,但它也带来了一个新的问题:异步编程的复杂性。传统的 if-else、for 循环、try-catch 写法在异步世界里会变得非常混乱(即所谓的“回调地狱”)。
为了优雅地处理异步事件流,Spring 引入了 Project Reactor。
Project Reactor 是什么? 它是一个实现了 Reactive Streams(响应式流)规范的 Java 库。它不是一个 Web 框架,而是一套用于编写异步和事件驱动代码的“工具集”或“编程范式”。
核心概念:Mono 和 Flux Reactor 提供了两种核心的“发布者”(Publisher)类型,用来处理数据流:
- Mono:代表一个最多包含 一个 元素的异步序列(0…1)。可以把它想象成一个“未来的结果”,这个结果可能是一个数据,也可能是一个完成信号,或者一个错误信号。非常适合封装一次性的异步操作,比如一次 HTTP 请求/响应。
- Flux:代表一个包含 零个或多个 元素的异步序列(0…N)。适合处理一连串的事件,比如从数据库中查询出的多条记录。
工作方式:声明式的“流水线” 使用 Reactor,你不是去写“先做什么,再做什么”的命令式代码,而是去声明一个数据处理的流水线。
1
2
3
4
5
6// 这是一个声明,它定义了当数据流来的时候该做什么
// 此时并没有真正执行
Flux.fromIterable(List.of("a", "b", "c")) // 1. 数据源
.map(String::toUpperCase) // 2. 转换成大写
.filter(s -> !s.equals("B")) // 3. 过滤掉"B"
.subscribe(System.out::println); // 4. 订阅并触发执行,打印结果这种链式调用,让复杂的异步逻辑变得像流水线一样清晰可控。
也就是说,Project Reactor 提供了一套优雅的 API(Mono/Flux),将复杂的异步非阻塞编程变成了声明式的数据流管道,极大地简化了开发。
上层框架:Spring WebFlux
现在,我们有了底层的非阻塞服务器 Netty,也有了上层的异步编程模型 Project Reactor。Spring WebFlux 的作用就是将这两者完美地粘合起来,应用在 Web 场景中。
- WebFlux 是什么? 它是 Spring 5 推出的一个全新的、完全非阻塞的、支持响应式编程的 Web 框架。它可以看作是传统 Spring MVC 的“响应式”版本。
- WebFlux 如何工作?
- 替换 Servlet API:它抛弃了传统的、阻塞的 Servlet API。它的整个请求处理生命周期都是异步的。
- 返回 Mono 和 Flux:在 WebFlux 中,Controller
的方法不再返回一个具体的对象(如 User),而是返回一个
Mono<User>或Flux<User>。这意味着你返回的不是“数据本身”,而是“一个未来会产生数据的承诺”。 - 全程非阻塞:当一个请求进入 WebFlux
应用后,它被封装成一个
Mono<ServerHttpRequest>。经过路由、过滤器、控制器处理,最终返回一个Mono<ServerHttpResponse>。在整个处理链条中,如果遇到 I/O 操作(比如调用下游微服务),处理线程不会等待,而是注册一个回调,然后立刻去处理其他请求。这保证了 Netty 的 EventLoop 线程永远不会被阻塞。
WebFlux 是一个构建在 Netty 和 Project Reactor 之上的响应式 Web 框架,它使得整个 HTTP 请求-响应的生命周期都运行在非阻塞的模式下。
最后,所以说,它的工作机制是:
- 启动时,它内部会启动一个嵌入式的 Netty 服务器,监听指定端口。
- 当一个客户端 HTTP 请求到达时,Netty 的 EventLoop 线程接收到这个网络事件,并将请求数据交给 WebFlux 框架处理。
- WebFlux 将请求封装成一个
ServerWebExchange对象,并将其放入一个基于 Project Reactor 构建的响应式处理链中。 - 这个请求会依次流经 Gateway 的各种过滤器 (Filter)。每一个过滤器都是响应式编程的实践者,它们对请求进行处理(如鉴权、修改请求头),然后将请求传递给下一个过滤器,整个过程返回的都是 Mono。
- 当需要将请求转发到下游微服务时,Gateway 使用的是非阻塞的 HTTP 客户端 WebClient。这个调用本身也是一个异步操作,不会阻塞当前线程。
- 最终,当下游服务返回响应后,这个响应会沿着过滤器链反向传播,经过一系列“post”过滤器的处理,最后由 WebFlux 和 Netty 将其写回给客户端。
因为整个流程——从接收请求到返回响应——的每一个环节都是异步和非阻塞的,所以 Gateway 可以用非常少的线程资源来支撑极高的并发量,这正是它高性能的根本所在。





