开始演示前的准备工作
搭建项目
其实设计三个子模块足矣
服务名
功能
数据库
order-service创建订单(主业务入口)
order_db
account-service扣减用户余额
account_db
storage-service扣减库存
storage_db
这是 Seata 官方示例的经典三服务模型,非常适合演练
集成 Seata Server
到你的项目中
下载 Seata Server(如
1.7.0),https://github.com/seata/seata/releases,然后把依赖添加到每个子项目中,这个就不说了,关于
Seata 如何安装配置,就不讲了
那么在项目开始编写之前,需要进入 seata-server/bin/
目录运行seata-server.bat然后启动seata,如果你配置了
Nacos 注册中心,注意注册中心也需要开启
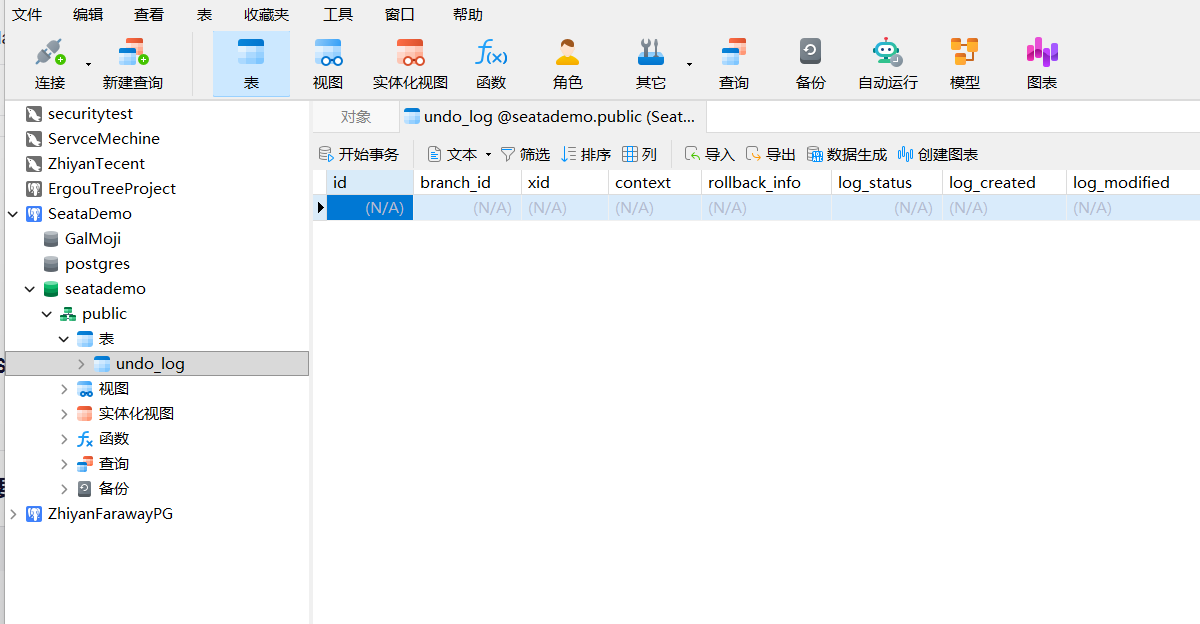
然后在项目开始编写前,需要做一些额外的处理,例如为每个数据库的配置文件和创建回滚日志表
image-20251228202110042
1 2 3 4 5 6 7 8 9 10 11 12 CREATE TABLE undo_log ( id SERIAL PRIMARY KEY , branch_id BIGINT NOT NULL , xid VARCHAR (128 ) NOT NULL , context VARCHAR (128 ) NOT NULL , rollback_info BYTEA NOT NULL , log_status INT NOT NULL , log_created TIMESTAMP DEFAULT CURRENT_TIMESTAMP , log_modified TIMESTAMP DEFAULT CURRENT_TIMESTAMP , CONSTRAINT ux_undo_log UNIQUE (xid, branch_id) );
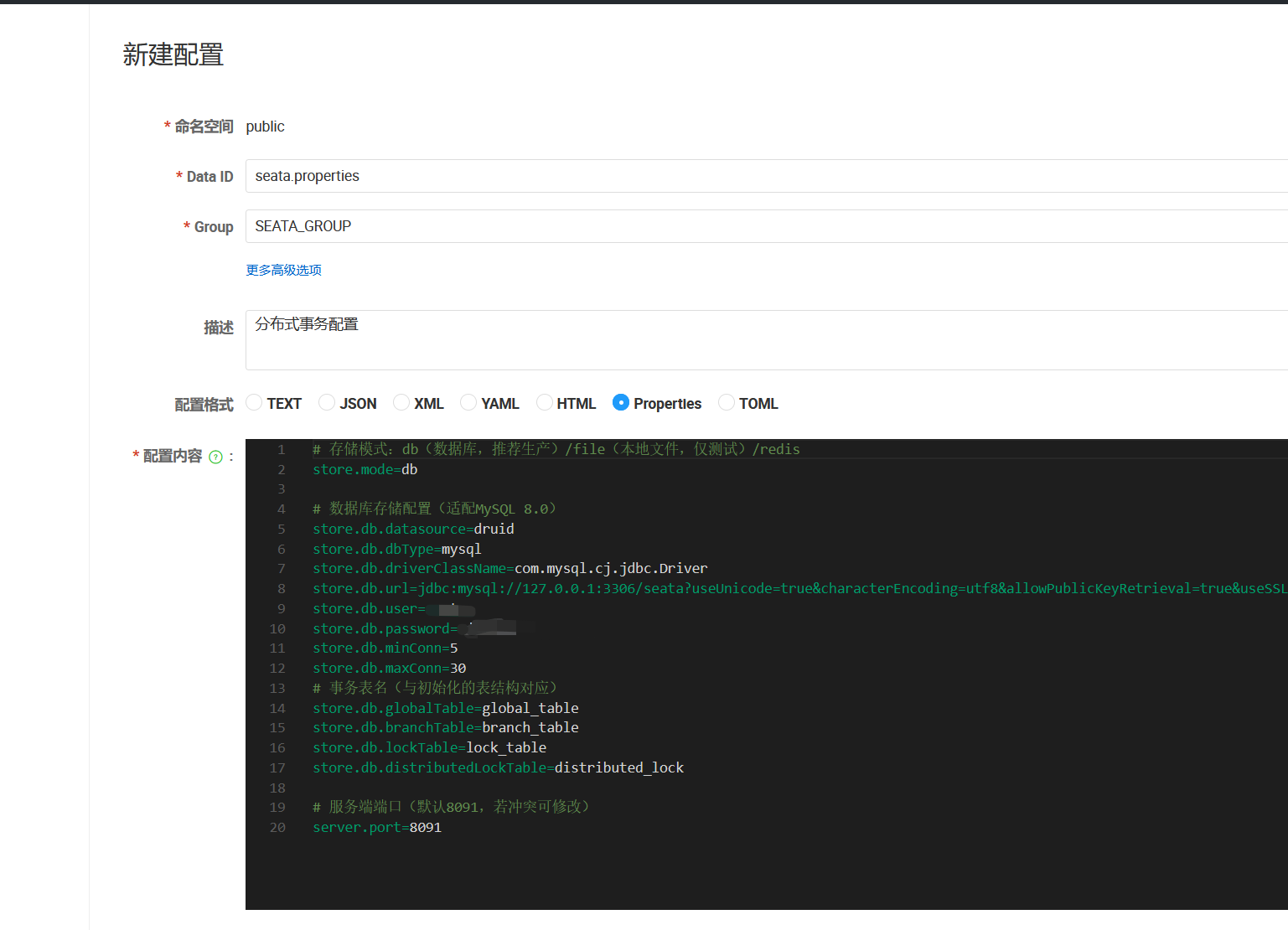
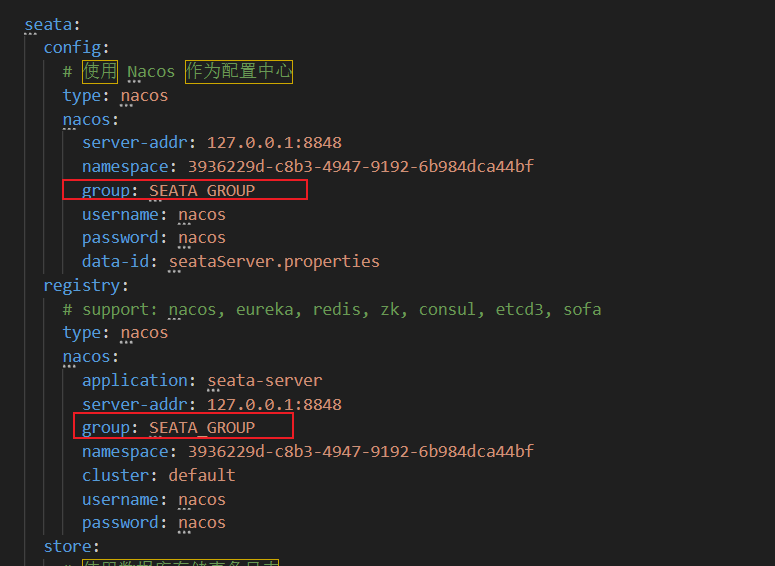
其中,关于 Seata 的配置文件可以这样编写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 seata: enabled: true application-id: ${spring.application.name} tx-service-group: my_tx_group service: vgroup-mapping: my_tx_group: default registry: type: nacos nacos: server-addr: 127.0 .0 .1 :8848 group: SEATA_GROUP namespace: ${spring.cloud.nacos.discovery.namespace} config: type: nacos nacos: server-addr: 127.0 .0 .1 :8848 group: SEATA_GROUP namespace: ${spring.cloud.nacos.discovery.namespace} enable-auto-data-source-proxy: true logging: level: io.seata: info com.zaxxer.hikari: warn
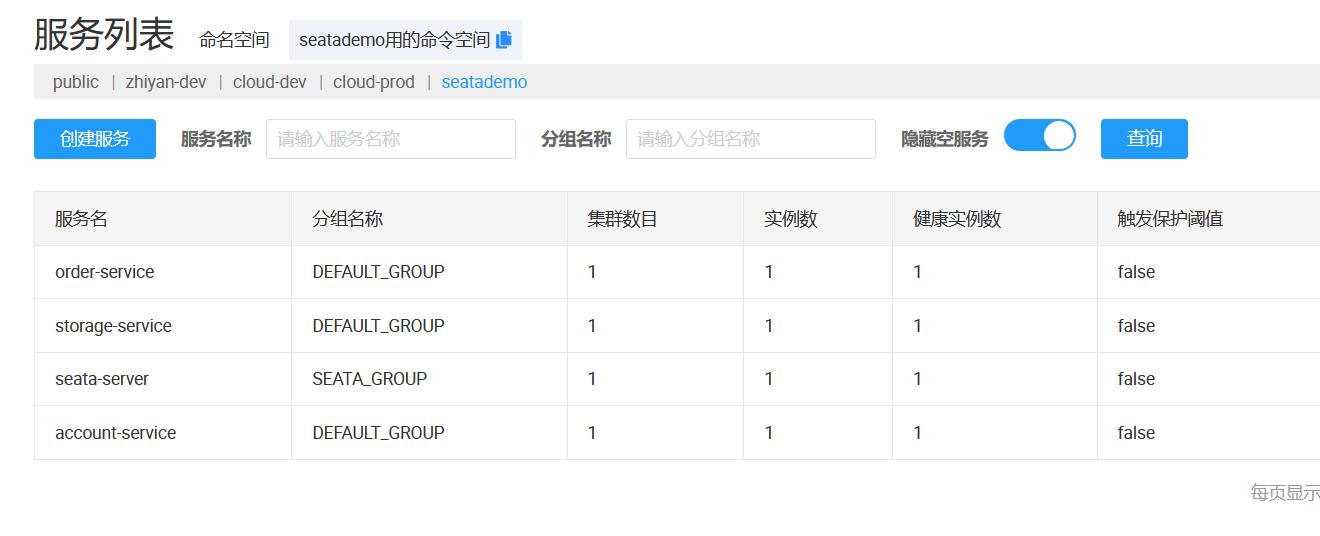
而且注意 Nacos 中的内容需要配置,因为我们需要使用服务发现
image-20251228203136342
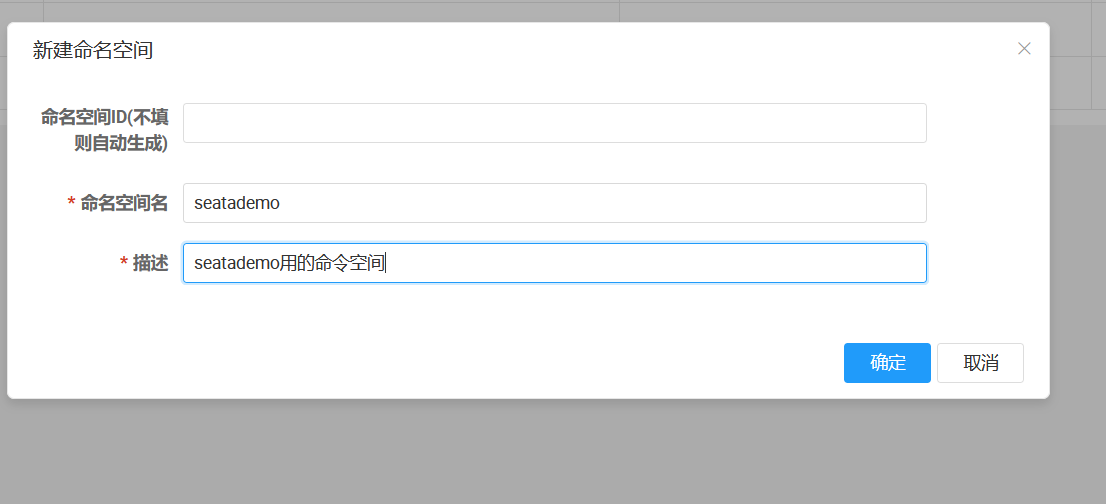
建议新开命名空间,而且主类别忘加上 Nacos 的那个注解
然后向 Nacos 添加 Seata 的配置项 ,即使你在
registry.conf 中用了
type = nacos,Seata Server 和客户端仍需从 Nacos
读取核心配置 ,否则会报错
can not get cluster name in registry config。
image-20251228204521271
image-20251228205545766
不建议在 public 空间创建,虽然 Seata 配置文件默认读的是 public 空间中
SEATA_GROUP 分组中的内容,但是 Seata 的配置必须和你的微服务使用相同的
Nacos 命名空间
image-20251228204722813
这样,准备任务就完成的差不多了
image-20251228205558284
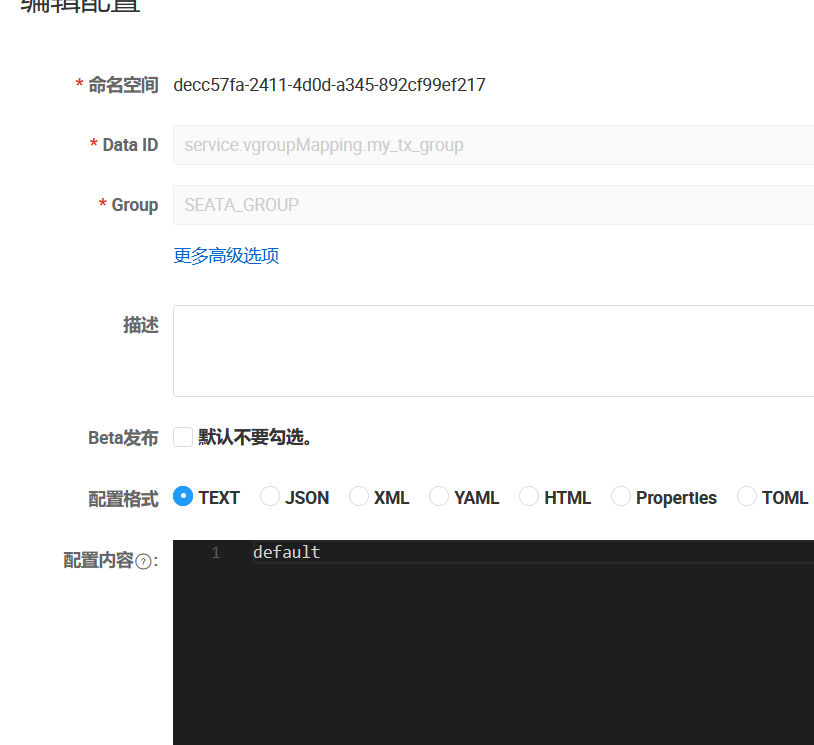
而且注意最后需要做一件事情,就是在 nacos 中进行一个这样的配置
image-20251230195341583
注意这里我使用的是默认组和默认集群,如果不是自己修改一下
image-20251230195200551
而且,如果你 seata 本身的配置如果是 mysql,注意启动
mysql,虽然它不会与项目中的 postgresql 冲突
然后,就可以开始编写实际的业务内容,来测试 Seata
支持的各种分布式事务了
基础业务模块的搭建就不演示了,直接开始,只说重要的部分
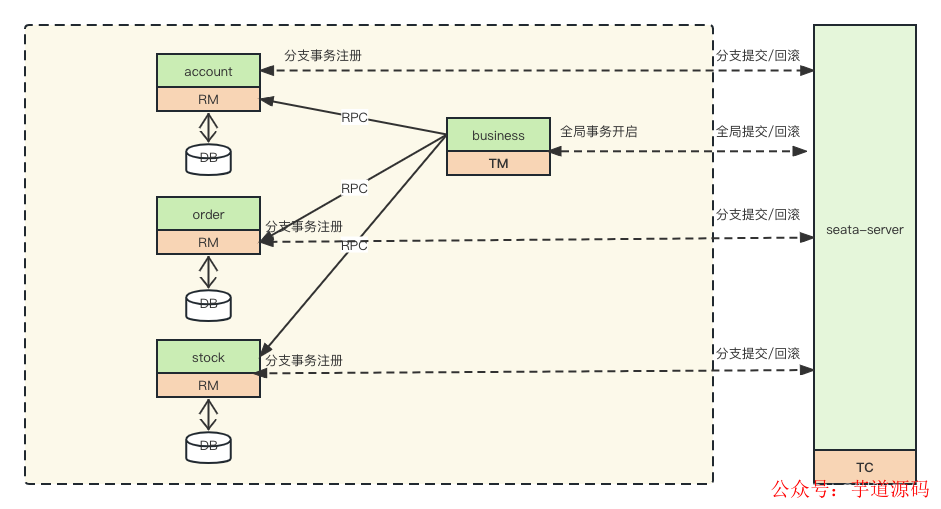
整体的业务可以参考这张图片
img
库存服务需要给指定的商品扣除仓储数量
订单服务需要根据采购的需求创建订单
账户服务需要下单和扣除对应的余额
AT模式的演示
AT 模式是 Seata 中使用最广泛的模式,它基于数据库的本地事务和 undo_log
日志实现分布式事务。默认隔离级别是读已提交
那么如何在 Seata 中开启 AT 模式呢?
分布式事务发起方开启AT模式
Seata 的 AT 事务是 TM 发起的,也就是说TM 所在服务中对应的方法需要被
@GlobalTransactional 注解标记,TM 才能向
TC 发起「创建全局事务」请求。其中,TC 是我们的 Seata
Server
例如,在上述我们的项目的架构中,事务的发起者就是
order-service,因为它需要创建订单,创建订单是一项涉及到分布式事务的业务,它会告诉库存服务扣除商品,告诉用户服务扣除金额,这涉及到了多个服务的跨库修改,所以,本次演示中认为它是分布式事务的入口,所以需要在其分布式事务的发生方法上添加@GlobalTransactional
它会开启一个全局事务(xid),并在后续 Feign 调用中自动传递该
xid,后续跨服务调用时通过拦截器传递
XID,确保所有分支事务关联到同一全局事务。这些都是 AT 的执行流程
rollbackFor = Exception.class 和
@Transactional的一样,确保任何异常都触发回滚。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 @Slf4j @Service @RequiredArgsConstructor public class OrderServiceAT { private final OrderRepository orderRepository; private final AccountServiceClient accountServiceClient; private final StorageServiceClient storageServiceClient; @GlobalTransactional( name = "createOrder", // 全局事务名称,用于监控 rollbackFor = Exception.class, // 任何异常都回滚 timeoutMills = 300000 // 全局事务超时时间 ) @Transactional(rollbackFor = Exception.class) public Order createOrder (CreateOrderDTO dto) { log.info("开始创建订单,用户ID: {}, 商品ID: {}, 数量: {}, 金额: {}" , dto.getUserId(), dto.getProductId(), dto.getCount(), dto.getMoney()); log.info("全局事务XID: {}" , io.seata.core.context.RootContext.getXID()); Order order = new Order (); order.setUserId(dto.getUserId()); order.setProductId(dto.getProductId()); order.setCount(dto.getCount()); order.setMoney(dto.getMoney()); order.setStatus(0 ); order = orderRepository.save(order); log.info("订单创建成功,订单ID: {}" , order.getId()); log.info("开始扣减库存,商品ID: {}, 数量: {}" , dto.getProductId(), dto.getCount()); storageServiceClient.deduct(dto.getProductId(), dto.getCount()); log.info("库存扣减成功" ); log.info("开始扣减账户余额,用户ID: {}, 金额: {}" , dto.getUserId(), dto.getMoney()); accountServiceClient.deduct(dto.getUserId(), dto.getMoney()); log.info("账户余额扣减成功" ); order.setStatus(1 ); order = orderRepository.save(order); log.info("订单创建完成,订单ID: {}" , order.getId()); return order; } public Order getById (Long id) { return orderRepository.findById(id) .orElseThrow(() -> new RuntimeException ("订单不存在,ID: " + id)); } }
然后,此时,被调用方,account 和
storage,这两个业务中的与上面下单涉及到的两个分支事务,使用普通的
@Transactional 确保普通的数据库回滚正确
AT 模式是自动生成 undo_log 回滚日志,发生意外据此进行数据回滚,AT
模式的演示比较简单,基于数据源代理,对业务代码侵入小,而且适合大多数业务场景,开发简单,所以我把
AT 放在了最开头
服务层添加了全局事务注解后,服务层和控制器层就不需要做太多额外的事情了,控制器该咋写咋写
展示一下上述分布式事务中用到的 feign
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @FeignClient(name = "storage-service", path = "/api/storage") public interface StorageServiceClient { @PostMapping("/deduct") void deduct (@RequestParam("productId") Long productId, @RequestParam("count") Integer count) ; } @FeignClient(name = "account-service", path = "/api/accounts") public interface AccountServiceClient { @PostMapping("/deduct") void deduct (@RequestParam("userId") Long userId, @RequestParam("money") BigDecimal money) ; }
分支事务需要做什么
以账户服务中,在上述创建订单中涉及到的其中的分支事务方法为例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Slf4j @Service @RequiredArgsConstructor public class AccountService { private final AccountRepository accountRepository; @Transactional(rollbackFor = Exception.class) public void deduct (Long userId, BigDecimal money) { log.info("开始扣减账户余额,用户ID: {}, 扣减金额: {}" , userId, money); Account account = accountRepository.findByUserId(userId) .orElseThrow(() -> new RuntimeException ("账户不存在,用户ID: " + userId)); BigDecimal newBalance = account.getBalance().subtract(money); if (newBalance.compareTo(BigDecimal.ZERO) < 0 ) { throw new RuntimeException ("账户余额不足,当前余额: " + account.getBalance() + ", 需要扣减: " + money); } account.setBalance(newBalance); accountRepository.save(account); log.info("账户余额扣减成功,用户ID: {}, 原余额: {}, 扣减后余额: {}" , userId, account.getBalance().add(money), newBalance); } public Account getByUserId (Long userId) { return accountRepository.findByUserId(userId) .orElseThrow(() -> new RuntimeException ("账户不存在,用户ID: " + userId)); } @Transactional(rollbackFor = Exception.class) public Account createAccount (Long userId, BigDecimal initialBalance) { Account account = new Account (); account.setUserId(userId); account.setBalance(initialBalance); return accountRepository.save(account); } }
实际上,在 AT 模式中,被调用方(分支事务)的需要但是只需要
@Transactional这种普通的业务注解就可以,此时XID 会通过
Feign 请求头自动传播,Seata 数据源代理会自动生成
undo_log,此时全局事务发生了回滚如果,就会自动使用 undo_log 恢复数据
上述方法 扣减账户余额,作为分支事务参与全局事务,XID 通过 Feign
请求头传播到这里,Seata
会自动将本次操作注册为分支事务,数据源代理会记录前镜像和后镜像到
undo_log 表,如果全局事务回滚,会自动恢复数据
这就是 AT
模式的工作原理在实际使用中的体现,而且注意,每个服务的数据库操作都会注册为分支事务,而且每个分支事务都会生成
undo_log,这就是为什么每个服务对应的数据库都需要 undo_log 表
只不过 AT 保证的是数据的最终一致性
测试
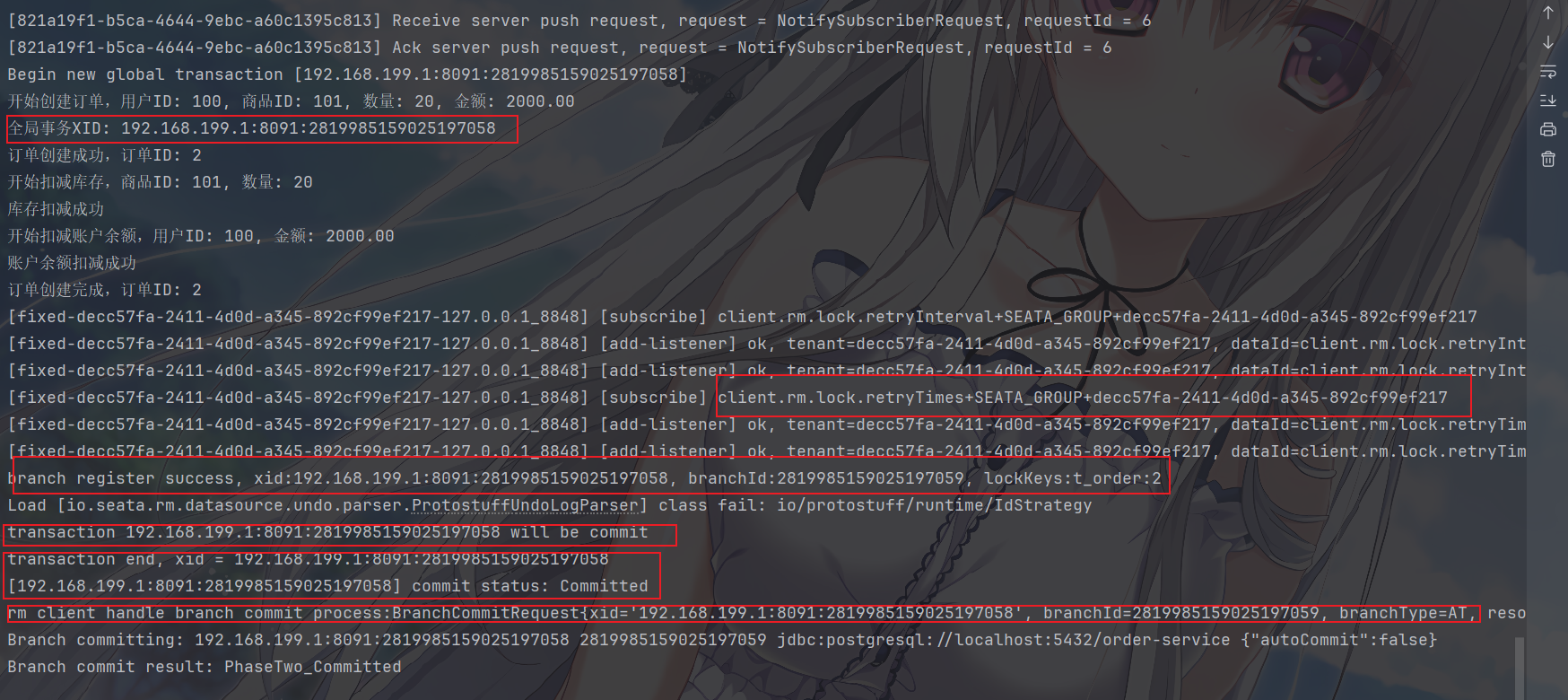
我们先测试一下正常下单,也就是走我们 AT模式的那个入口
image-20251230200309918
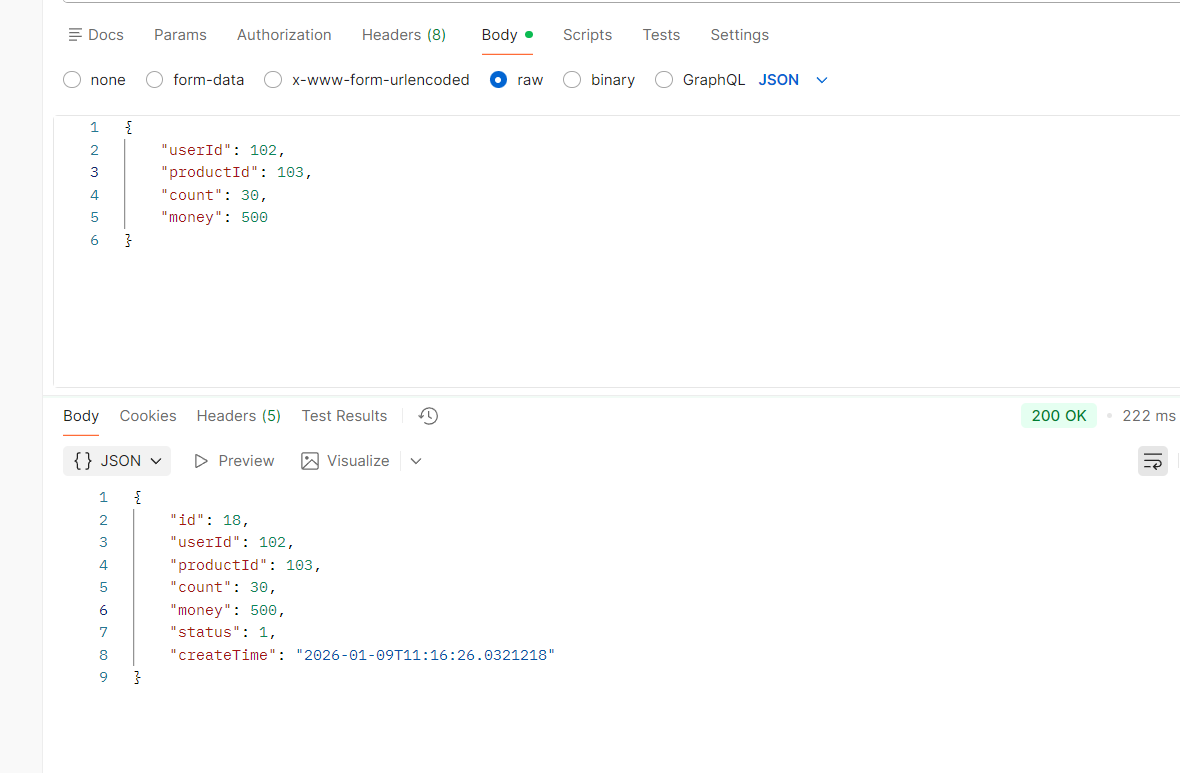
可以看到,接口的请求成功了
image-20251230200705363
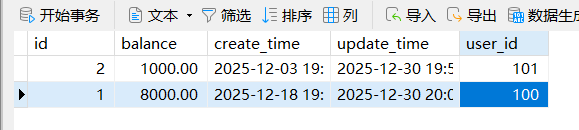
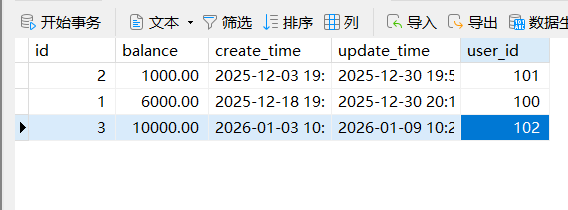
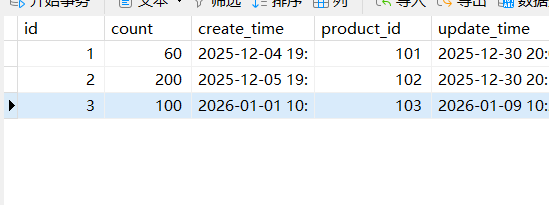
来看一下数据库的数据,其中的数据也是正确执行了分布式业务的两步业务
这是扣减用户余额
image-20251230200748984
产生账单
image-20251230200813157
这是扣减商品数量
image-20251230200856845
然后看一下 seata
的回滚日志表,因为是业务正确,所以暂时不会产生日志
可以看到,日志也是正确实现了整个 AT 分布式事务的业务流转
image-20251230201103797
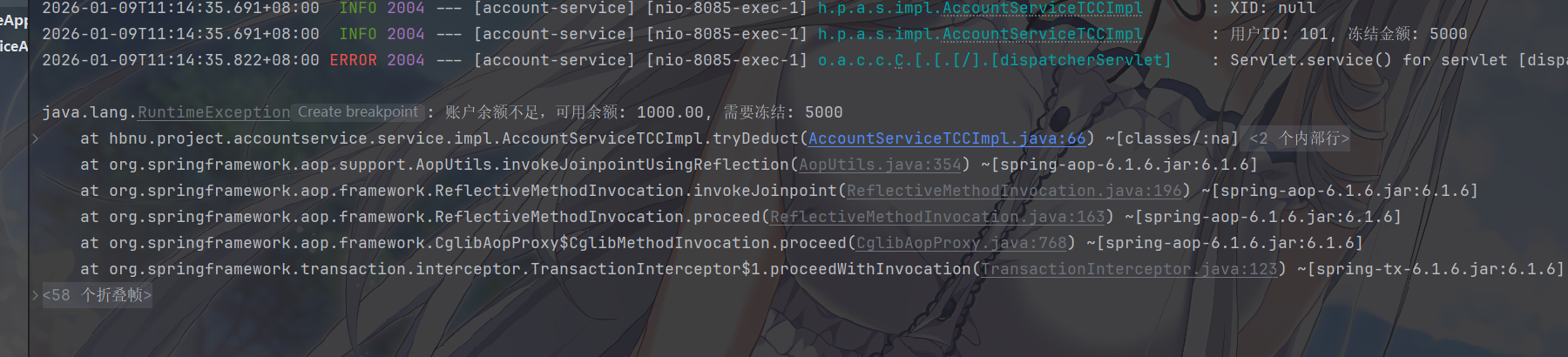
所以接下来我们测试一下其他情况,例如,用户下单了超过自己的余额的订单或者下单数量超过库存
其中,feign 调用被出现异常,数据库回滚,整个数据没有发生改变
TCC模式的演示
TCC 模式我们之前说过,TCC 不底层数据库,因为它是三阶段模型,第一阶段
Try 预留资源,第二阶段 Confirm 确认执行,第三阶段 Cancel
取消执行,而且TCC性能更好,不必对数据加全局锁,允许多事务
所以说,TCC 是一种强侵入式的分布式事务解决方案,需要我们自行实现
Try,Confirm,Cancel
三个操作,每个阶段的数据操作都要自己进行编码来实现,事务框架无法自动处理。
倒是 TCC 的涉及到的角色没太大变化
自定义实现 TCC
事务的三个步骤
我们的核心场景是下单,也就是同时检查库存和用户余额是否够,够就扣,那么三个服务的TCC三步是这样
库存服务(Storage)
Try:检查库存是否充足 → 冻结对应数量的库存(如订单要扣 10 件,就把
10 件库存标记为 “冻结”,剩余库存 = 总库存 - 冻结库存);
Confirm:将冻结的库存真正扣减(删除冻结记录,总库存 = 总库存 -
冻结数量);
Cancel:解冻冻结的库存(清空冻结记录,总库存恢复)。
账户服务(Account)
Try:检查账户余额是否充足 → 冻结对应金额(如订单要扣 200 元,就冻结
200 元,可用余额 = 总余额 - 冻结金额);
Confirm:真正扣减冻结的金额;
Cancel:解冻冻结的金额。
订单服务(Order)
Try:创建 “待确认” 状态的订单(仅预留订单 ID,不标记为
“已创建”);
Confirm:将订单状态改为 “已创建”;
Cancel:删除 “待确认” 的订单记录。
其中,Try
阶段必须保证幂等性 (重复调用结果一致)、可补偿 (Confirm/Cancel
能处理 Try
的结果)、资源隔离 (预留的资源只属于当前事务,不被其他事务占用)。
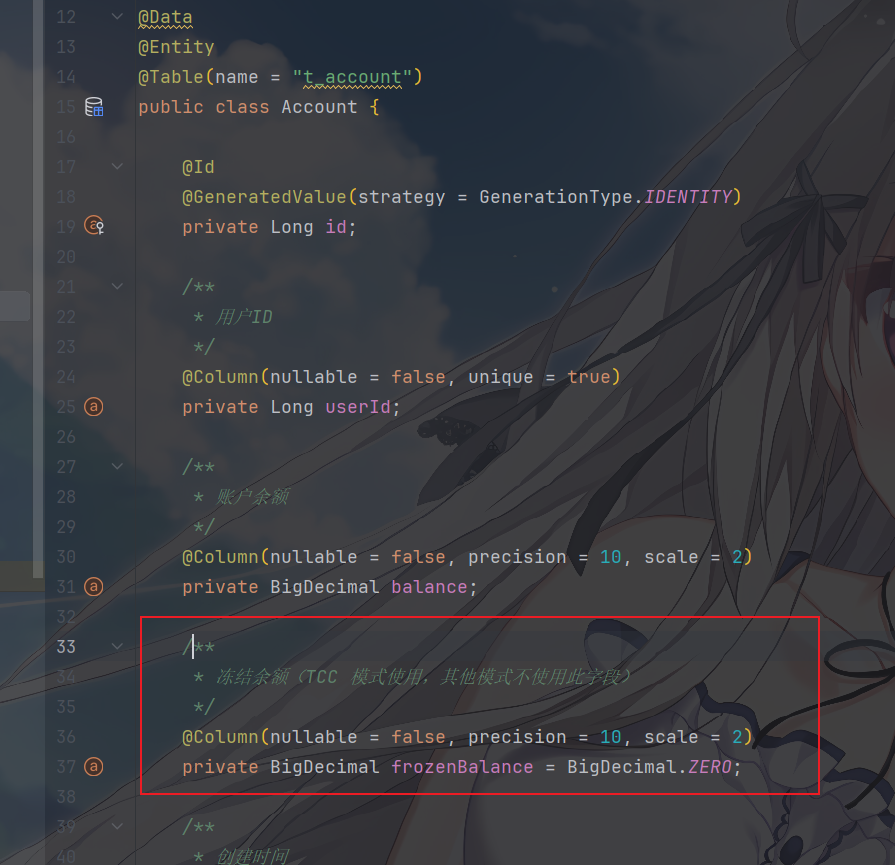
那么,首先,需要为实体类添加 TCC 模式需要的冻结字段,就像这样
image-20251230203421235
Try阶段
首先要明确,这部分要写什么,而且为什么要这样写,因为 TCC 的 Try
阶段是资源预留阶段 ,不是最终执行阶段。对账户服务来说,Try
阶段的核心目标是:
校验 :确认用户账户存在、可用余额足够扣减;预留 :把要扣减的金额 “冻结”
起来(标记为占用),避免被其他事务使用;触发 :若校验 / 预留失败,抛出异常,让 Seata
触发全局事务 Cancel 阶段;若成功,等待 Confirm 阶段最终确认。
然后来实现 Try 阶段,以 Account 账户服务为例子
首先,说下一个注解 @LocalTCC,本地 TCC bean
还需要在接口定义中添加 @LocalTCC 注解,表示该接口的实现类被 seata
来管理,但是我这边没写接口,所以就没用这个注解,也有人说这个注解写到实现类上是没问题的,我没试
我们再用 Seata 的 @TwoPhaseBusinessAction 注解标记 Try
方法,指定对应的 Confirm/Cancel 方法,然后方法参数中必须传递
BusinessActionContext(Seata 用于传递全局事务
ID、参数等)。
1 2 3 4 5 6 @TwoPhaseBusinessAction( name = "accountServiceTCC", // TCC bean 唯一标识,需和类名/bean名对应 commitMethod = "confirm", // 绑定 Confirm 阶段方法名(必须和类中方法名一致) rollbackMethod = "cancel" // 绑定 Cancel 阶段方法名(必须和类中方法名一致) ) @Transactional(rollbackFor = Exception.class)
name 必须唯一,若多个 TCC 服务,需区分(如
storageServiceTCC、orderServiceTCC);@Transactional 必须加,且
rollbackFor = Exception.class:确保 Try
阶段的冻结操作要么成功,要么本地回滚(比如冻结时数据库报错,本地先回滚,再抛异常给
Seata)。
方法参数设计就是注意,必须要传递
BusinessActionContext上下文
1 2 3 4 public boolean tryDeduct ( BusinessActionContext context, // 核心:Seata 全局事务上下文 @BusinessActionContextParameter(paramName = "userId") Long userId, // 标记需传递到Confirm/Cancel的参数 @BusinessActionContextParameter(paramName = "money") BigDecimal money) {
BusinessActionContext:Seata 自动注入,包含全局事务
XID、传递给 Confirm/Cancel 的参数、自定义上下文(如你的
failInTry 模拟失败标记),是 TCC 三阶段通信的核心;@BusinessActionContextParameter:必须给需要传递到
Confirm/Cancel 的业务参数加这个注解!Seata 会把这些参数存入
context,否则 Confirm/Cancel 阶段拿不到
userId/money,无法处理。
然后就是核心业务校验
查询并校验基础数据
1 2 Account account = accountRepository.findByUserId(userId) .orElseThrow(() -> new RuntimeException ("账户不存在,用户ID: " + userId));
校验资源是否充足
1 2 3 4 5 BigDecimal availableBalance = account.getBalance().subtract(account.getFrozenBalance());if (availableBalance.compareTo(money) < 0 ) { throw new RuntimeException ("账户余额不足,可用余额: " + availableBalance + ", 需要冻结: " + money); }
首先不能直接用 account.getBalance()
校验,必须减去已冻结余额,否则会出现 “超卖 /
超扣”,比如多个事务同时冻结同一笔余额,因为 TCC
是支持多个分布式事务同时执行的
执行资源预留
1 2 3 account.setFrozenBalance(account.getFrozenBalance().add(money)); accountRepository.save(account);
预留操作必须是可逆向 的:冻结金额的逆向操作就是
Cancel 阶段的 “减冻结金额”,所以 Try 阶段的操作必须能被 Cancel
回滚;
这里只做预留,不做最终操作
完整 Try 方法的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Override @TwoPhaseBusinessAction( name = "accountServiceTCC", // TCC bean name commitMethod = "confirm", // Confirm 阶段方法名 rollbackMethod = "cancel" // Cancel 阶段方法名 ) @Transactional(rollbackFor = Exception.class) public boolean tryDeduct ( BusinessActionContext context, @BusinessActionContextParameter(paramName = "userId") Long userId, @BusinessActionContextParameter(paramName = "money") BigDecimal money) { log.info("========== TCC Try 阶段:开始冻结账户余额 ==========" ); log.info("XID: {}" , context.getXid()); log.info("用户ID: {}, 冻结金额: {}" , userId, money); Account account = accountRepository.findByUserId(userId) .orElseThrow(() -> new RuntimeException ("账户不存在,用户ID: " + userId)); BigDecimal availableBalance = account.getBalance().subtract(account.getFrozenBalance()); if (availableBalance.compareTo(money) < 0 ) { throw new RuntimeException ("账户余额不足,可用余额: " + availableBalance + ", 需要冻结: " + money); } account.setFrozenBalance(account.getFrozenBalance().add(money)); accountRepository.save(account); log.info("账户余额冻结成功,用户ID: {}, 冻结金额: {}, 总冻结: {}, 可用余额: {}" , userId, money, account.getFrozenBalance(), account.getBalance().subtract(account.getFrozenBalance())); String failFlag = (String) context.getActionContext("failInTry" ); if ("true" .equals(failFlag)) { log.error("模拟 Try 阶段失败" ); throw new RuntimeException ("模拟 Try 阶段失败,测试回滚" ); } return true ; }
其实还可以做一些幂等性的优化,因为Seata
可能因网络超时、重试机制,多次调用同一个 Try
方法,但是我没写,实现其实也不难,在 Account 表中增加
xid 字段,Try 阶段先检查:若该 userId +
xid 已存在冻结记录,直接返回 true
1 2 3 4 5 6 7 8 if (account.getFrozenXid() != null && account.getFrozenXid().equals(context.getXid())) { log.info("该事务已冻结过余额,无需重复操作,XID: {}" , context.getXid()); return true ; } account.setFrozenXid(context.getXid()); account.setFrozenBalance(account.getFrozenBalance().add(money)); accountRepository.save(account);
Confirm 阶段
以库存服务为例子,来演示 Confirm 阶段如何编写
这个阶段是 TCC 三阶段中最终确认执行的阶段,,只有当 Try
阶段在所有参与方都执行成功后,事务协调器才会触发该阶段。将 Try
阶段的 预备操作(如冻结库存)真正落地为
最终状态(如实际扣减库存) 。
库存服务中,Try阶段我们肯定是冻结库存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Override @Transactional(rollbackFor = Exception.class) public boolean tryDeduct ( BusinessActionContext context, Long productId, Integer count) { log.info("========== TCC Try 阶段:开始冻结库存 ==========" ); log.info("XID: {}" , context.getXid()); log.info("商品ID: {}, 冻结数量: {}" , productId, count); Storage storage = storageRepository.findByProductId(productId) .orElseThrow(() -> new RuntimeException ("库存不存在,商品ID: " + productId)); int availableCount = storage.getCount() - storage.getFrozenCount(); if (availableCount < count) { throw new RuntimeException ("库存不足,可用库存: " + availableCount + ", 需要冻结: " + count); } storage.setFrozenCount(storage.getFrozenCount() + count); storageRepository.save(storage); log.info("库存冻结成功,商品ID: {}, 冻结数量: {}, 总冻结: {}, 可用库存: {}" , productId, count, storage.getFrozenCount(), storage.getCount() - storage.getFrozenCount()); String failFlag = (String) context.getActionContext("failInTry" ); if ("true" .equals(failFlag)) { log.error("模拟 Try 阶段失败" ); throw new RuntimeException ("模拟 Try 阶段失败,测试回滚" ); } return true ; }
那么Confirm 阶段则要完成 扣减总库存 + 释放冻结库存 的最终操作。
首先,和 Try
阶段一样,入参固定为BusinessActionContext ,这是
Seata TCC 的规范,所有 Confirm/Cancel
方法只能接收这个参数,不能自定义其他入参。然后注意添加@Transactional(rollbackFor = Exception.class)保证事务
1 2 3 @Override @Transactional(rollbackFor = Exception.class) public boolean confirm (BusinessActionContext context) {
然后,通过获取 TCC 事务上下文中的内容,来获取商品 ID
和扣减数量等需要的内容
1 2 3 Long productId = Long.valueOf(context.getActionContext("productId" ).toString());Integer count = Integer.valueOf(context.getActionContext("count" ).toString());
Confirm
阶段的逻辑必须满足幂等性、确定性、无业务检查 三大原则,我懒得做幂等了,整体方法如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Override @Transactional(rollbackFor = Exception.class) public boolean confirm (BusinessActionContext context) { String xid = context.getXid(); log.info("========== TCC Confirm 阶段:确认扣除库存 ==========" ); log.info("XID: {}" , xid); Long productId = Long.valueOf(context.getActionContext("productId" ).toString()); Integer count = Integer.valueOf(context.getActionContext("count" ).toString()); Storage storage = storageRepository.findByProductId(productId) .orElseThrow(() -> new RuntimeException ("库存不存在,商品ID: " + productId)); if (storage.getConfirmStatus() == 1 ) { log.info("该事务已执行过Confirm,无需重复处理,XID:{}" , xid); return true ; } storage.setCount(storage.getCount() - count); storage.setFrozenCount(storage.getFrozenCount() - count); storage.setConfirmStatus(1 ); storageRepository.save(storage); log.info("库存确认扣除成功,商品ID: {}, 扣除数量: {}, 剩余库存: {}, 剩余冻结: {}" , productId, count, storage.getCount(), storage.getFrozenCount()); return true ; }
注意,Confirm 阶段必须保证
“能成功就一定成功”,尽量避免抛出异常,我那是为了方便测试的模拟
Cancel 阶段
Cancel 阶段就继续使用库存服务吧
Cancel 阶段是 TCC 三阶段中回滚 Try
阶段操作 的阶段,当任意参与方的 Try
阶段执行失败,或事务发起方主动终止事务时,事务协调器会触发所有参与方的
Cancel 阶段。它会撤销 Try 阶段的预备操作,将数据恢复到 Try
之前的状态
一样,入参固定为BusinessActionContext ,Cancel
和 Confirm 方法只能接收该参数,所有业务参数都要从上下文获取。
而且添加
@Transactional(rollbackFor = Exception.class)
而且推荐为 Cancel
阶段有一定的可补偿型,也就是允许重试,不轻易抛异常,因为回滚代价大,虽然Cancel
阶段要保证 能回滚就一定回滚,但是,即使出现临时异常,也要允许 Seata
重试成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Override @Transactional(rollbackFor = Exception.class) public boolean cancel (BusinessActionContext context) { log.info("========== TCC Cancel 阶段:取消冻结库存 ==========" ); log.info("XID: {}" , context.getXid()); Long productId = Long.valueOf(context.getActionContext("productId" ).toString()); Integer count = Integer.valueOf(context.getActionContext("count" ).toString()); Storage storage = storageRepository.findByProductId(productId) .orElseThrow(() -> new RuntimeException ("库存不存在,商品ID: " + productId)); storage.setFrozenCount(storage.getFrozenCount() - count); storageRepository.save(storage); log.info("库存取消冻结成功,商品ID: {}, 释放数量: {}, 剩余库存: {}, 剩余冻结: {}" , productId, count, storage.getCount(), storage.getFrozenCount()); return true ; }
逻辑没啥好说的,Cancel 阶段核心是逆向撤销 Try
阶段的预备操作 ,仅恢复数据,不新增任何业务逻辑,而且 Cancel
阶段必须要做好幂等性,而且Cancel 阶段的幂等性难度较大,在这里不多说
事务发起方如何编写
那么,我们的下单服务还是整个业务的分布式事务发起方,它是分布式事务的入口,负责开启全局事务、调用各参与方的
Try 方法,并触发后续的 Confirm/Cancel 流程。
依旧
@GlobalTransactional,必须加在发起方的核心方法上
1 2 3 4 5 6 @GlobalTransactional( name = "createOrderTCC", // 事务名称,用于日志和监控 rollbackFor = Exception.class, // 所有异常都触发回滚 timeoutMills = 300000 // 事务超时时间,避免长时间卡住 ) @Transactional(rollbackFor = Exception.class)
TCC 模式的发起方只需要调用各参与方的 Try
方法 ,Confirm/Cancel 由 Seata 协调器自动触发
1 2 3 4 storageServiceTCCClient.tryDeduct(dto.getProductId(), dto.getCount(), failInTry); accountServiceTCCClient.tryDeduct(dto.getUserId(), dto.getMoney(), failInTry);
发起方仅调用 Try 阶段 ,不直接调用
Confirm/Cancel,这两个阶段交给 Seata 根据结果自己调用
所有 Try 方法调用必须在try块内,异常时抛出,触发 Cancel
流程
若所有 Try 方法执行成功,Seata 会自动调用所有参与方的 Confirm
方法;
若任意 Try 方法执行失败(抛异常),Seata 会自动调用所有已执行成功
Try 方法的参与方的 Cancel 方法。
而发起方需要捕获 Try 阶段的异常并重新抛出,让 Seata 感知到失败并触发
Cancel:
1 2 3 4 5 6 try { } catch (Exception e) { log.error("TCC Try 阶段失败,将触发 Cancel:{}" , e.getMessage()); throw e; }
捕获异常后不抛出,会导致 Seata 认为 Try 成功,触发 Confirm,Cancel
不会被触发,数据一致性会被破坏。
完整代码如下
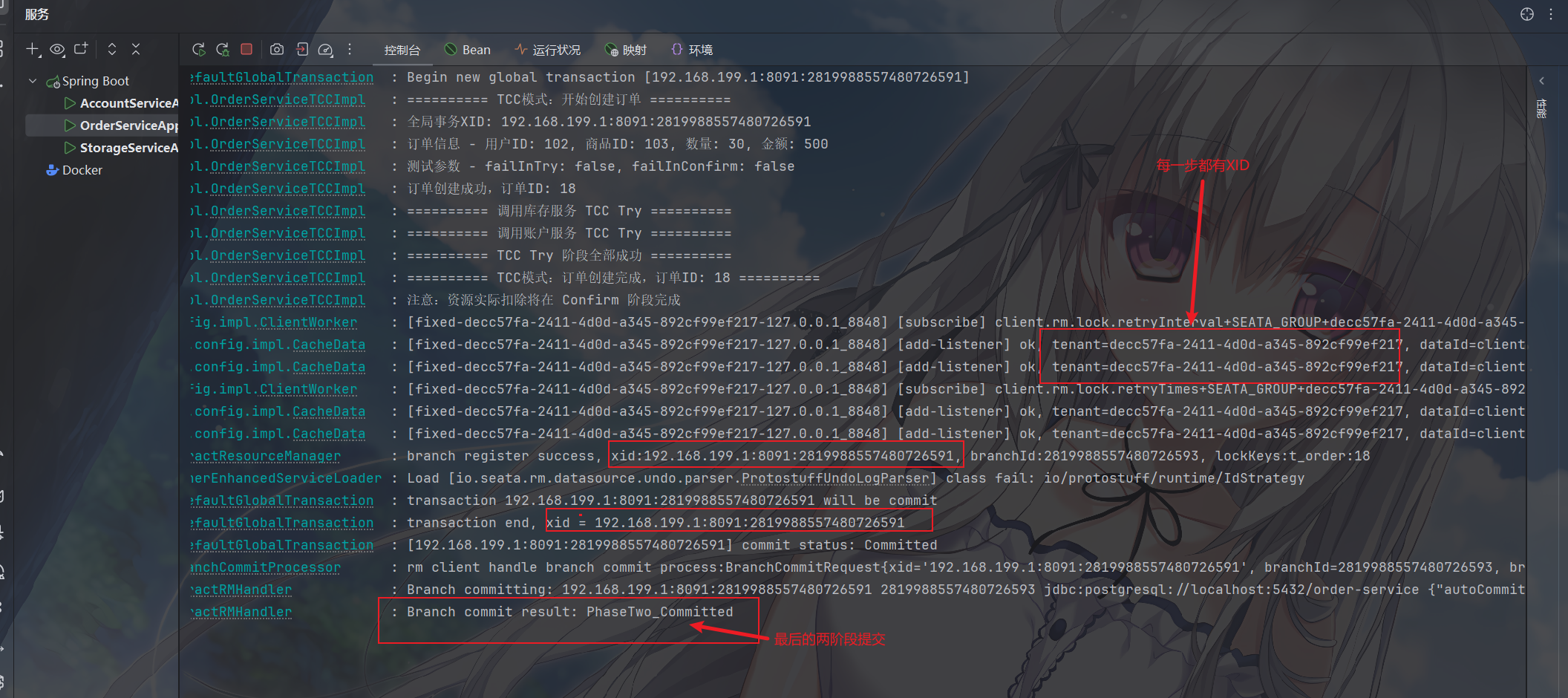
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 @Override @GlobalTransactional( name = "createOrderTCC", rollbackFor = Exception.class, timeoutMills = 300000 ) @Transactional(rollbackFor = Exception.class) public Order createOrder (CreateOrderDTO dto, Boolean failInTry, Boolean failInConfirm) { log.info("========== TCC模式:开始创建订单 ==========" ); log.info("全局事务XID: {}" , RootContext.getXID()); log.info("订单信息 - 用户ID: {}, 商品ID: {}, 数量: {}, 金额: {}" , dto.getUserId(), dto.getProductId(), dto.getCount(), dto.getMoney()); log.info("测试参数 - failInTry: {}, failInConfirm: {}" , failInTry, failInConfirm); Order order = new Order (); order.setUserId(dto.getUserId()); order.setProductId(dto.getProductId()); order.setCount(dto.getCount()); order.setMoney(dto.getMoney()); order.setStatus(0 ); order = orderRepository.save(order); log.info("订单创建成功,订单ID: {}" , order.getId()); try { log.info("========== 调用库存服务 TCC Try ==========" ); storageServiceTCCClient.tryDeduct(dto.getProductId(), dto.getCount(), failInTry); log.info("========== 调用账户服务 TCC Try ==========" ); accountServiceTCCClient.tryDeduct(dto.getUserId(), dto.getMoney(), failInTry); log.info("========== TCC Try 阶段全部成功 ==========" ); if (Boolean.TRUE.equals(failInConfirm)) { log.warn("将在 Confirm 阶段触发失败" ); } } catch (Exception e) { log.error("TCC Try 阶段失败,将触发 Cancel:{}" , e.getMessage()); throw e; } order.setStatus(1 ); order = orderRepository.save(order); log.info("========== TCC模式:订单创建完成,订单ID: {} ==========" , order.getId()); log.info("注意:资源实际扣除将在 Confirm 阶段完成" ); return order; }
测试
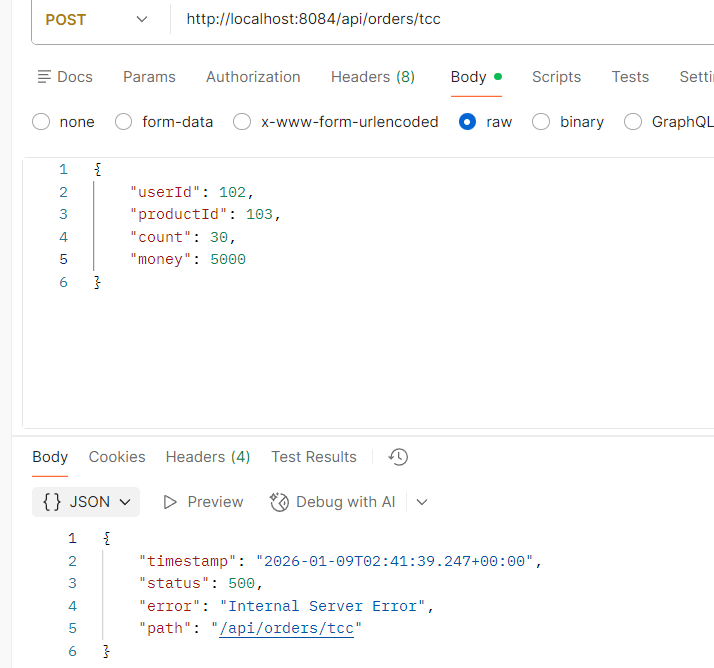
先来演示 TCC 事务失败,因为抛出了异常需要进行事务回滚的情况
image-20260109104638563
这里我内置了一个必定触发的异常,在我发起订单的时候,由库存的 Cancel
阶段触发
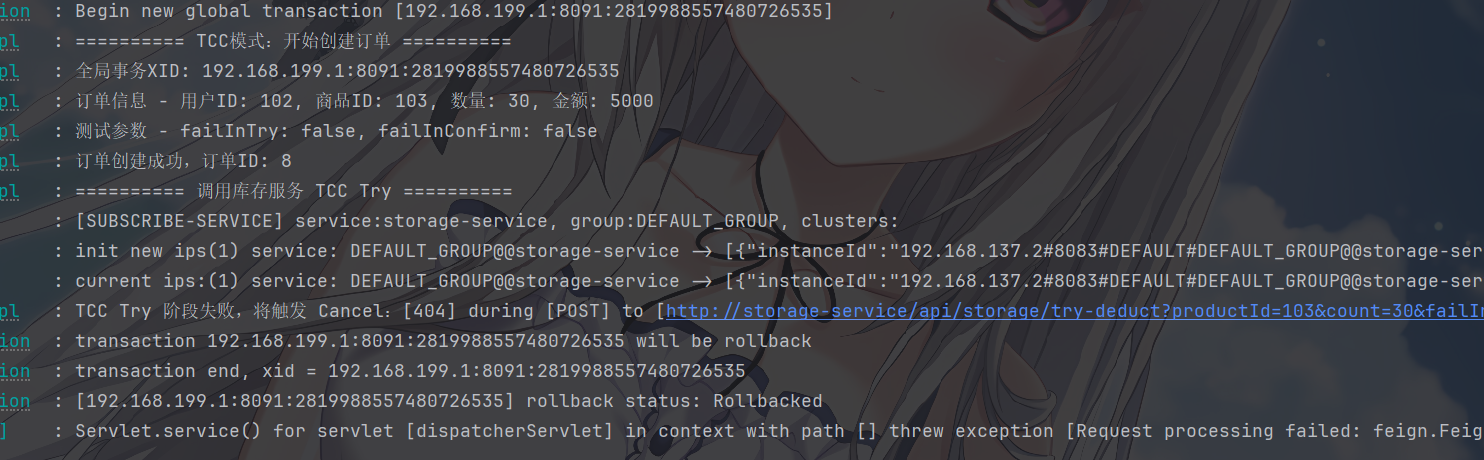
image-20260109104445238
来演示TCC在失败情况下,需要回滚的情况下的情况,此时会触发 Cancel
阶段,来保证数据的正确性
image-20260109104553153
image-20260109104524929
可以看到订单没有被创建,商品数量和用户余额也都是事务发起之前的情况
然后,我们可以在任意一个环节造成一个异常,可以发现 TCC
也是会在其异常的步骤会停止事务,停止这一步的操作,如果是 Try
步骤出现了异常,事务接下来都不会进行
image-20260109111556462
之后我们正确的来进行 TCC
的事务,可以发现是成功了,数据库也正确的进行了数据的扣减和订单的创建
image-20260109111704236
来看一下每个服务的 TCC 的事务的详细运行情况
image-20260109111743672
image-20260109111902425
image-20260109111851000
至此,TCC 模式的分布式事务就完成了
Saga模式的演示
Saga
模式适用于长事务场景,通过正向服务和补偿服务的组合来保证最终一致性。
核心是将一个分布式事务拆分为多个
本地事务步骤 ,每个步骤对应一个独立的业务服务操作。
当所有步骤正常执行时,事务成功完成;若某个步骤执行失败,则触发
补偿操作(Compensation
Step) ,按照与正向步骤相反的顺序回滚已执行的本地事务,最终使整个系统回到一致状态。
理解这些内容,就可以考虑我们下边如何编码的操作了,也就是说,我们需要编写对应分布式事务的步骤及其补偿操作
而且 Seata Saga
模式提供两种主流实现,编排式和注解式,编排式类似于需要使用JSON等编写流程定义,描述正向步骤和补偿步骤的执行顺序,但是注解式好像消失了,目前
Seata 的官网只写了编排式的方式实现 Saga 形式的分布式事务
关于 Seata 中使用 Saga 需要额外引入两个依赖
1 2 3 4 5 6 7 8 9 10 11 12 <dependency > <groupId > org.apache.seata</groupId > <artifactId > seata-saga-engine</artifactId > <version > 2.5.0</version > </dependency > <dependency > <groupId > org.apache.seata</groupId > <artifactId > seata-saga-statelang</artifactId > <version > 2.5.0</version > </dependency >
编写 Saga 服务类
以 订单服务为例子,来看一下 Saga 分布式事务下服务类如何编写
首先,编排式的分布式事务服务类需要引入
StateMachineEngine这个 bean 用于解析你在下面要定义的 JSON
状态机
然后,对于分布式事务的入口方法——创建订单,这个方法需要触发 Saga
事务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public Order createOrder (CreateOrderDTO dto) { Map<String, Object> startParams = new HashMap <>(); startParams.put("userId" , dto.getUserId()); startParams.put("productId" , dto.getProductId()); startParams.put("count" , dto.getCount()); startParams.put("money" , dto.getMoney()); startParams.put("businessKey" , "order_" + System.currentTimeMillis()); try { StateMachineInstance instance = stateMachineEngine.startWithBusinessKey( "orderSagaStateMachine" , null , (String) startParams.get("businessKey" ), startParams ); if (ExecutionStatus.SU.equals(instance.getStatus())) { Long orderId = (Long) instance.getEndParams().get("orderId" ); return orderRepository.findById(orderId) .orElseThrow(() -> new RuntimeException ("订单创建后查询失败" )); } else { throw new RuntimeException ("订单创建失败: " + instance.getException()); } } catch (Exception e) { throw new RuntimeException ("订单创建失败: " + e.getMessage(), e); } }
然后,Saga 模式要求为每个正向操作提供对应的补偿操作,代码中实现了 3
个方法,来对应每个正向操作的补偿操作:
方法名
类型
作用
核心逻辑
createOrderRecord正向
创建订单记录
保存订单到数据库,状态设为
创建中,返回订单 ID
completeOrder正向
完成订单
将订单状态改为
已完成(所有子事务成功后执行)
cancelOrder补偿
取消订单
将订单状态改为
已取消(子事务失败时执行)
其中,所有的正向和补偿操作都需要添加
@Transactional(rollbackFor = Exception.class)保证单库操作的原子性
一般情况下,Saga 事务的状态码设计是这样的,0 = 创建中、1 = 已完成、2
= 已取消
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 @Slf4j @Service @RequiredArgsConstructor public class OrderServiceSaga { private final OrderRepository orderRepository; private final StateMachineEngine stateMachineEngine; public Order createOrder (CreateOrderDTO dto) { log.info("[Saga模式] 开始创建订单: userId={}, productId={}, count={}, money={}" , dto.getUserId(), dto.getProductId(), dto.getCount(), dto.getMoney()); Map<String, Object> startParams = new HashMap <>(); startParams.put("userId" , dto.getUserId()); startParams.put("productId" , dto.getProductId()); startParams.put("count" , dto.getCount()); startParams.put("money" , dto.getMoney()); startParams.put("businessKey" , "order_" + System.currentTimeMillis()); try { StateMachineInstance instance = stateMachineEngine.startWithBusinessKey( "orderSagaStateMachine" , null , (String) startParams.get("businessKey" ), startParams ); if (ExecutionStatus.SU.equals(instance.getStatus())) { log.info("[Saga模式] 订单创建成功,状态机实例ID: {}" , instance.getId()); Long orderId = (Long) instance.getEndParams().get("orderId" ); return orderRepository.findById(orderId) .orElseThrow(() -> new RuntimeException ("订单创建后查询失败" )); } else { log.error("[Saga模式] 订单创建失败,状态: {}, 异常: {}" , instance.getStatus(), instance.getException()); throw new RuntimeException ("订单创建失败: " + instance.getException()); } } catch (Exception e) { log.error("[Saga模式] 订单创建异常" , e); throw new RuntimeException ("订单创建失败: " + e.getMessage(), e); } } @Transactional(rollbackFor = Exception.class) public Map<String, Object> createOrderRecord (Map<String, Object> params) { log.info("[Saga-正向] 创建订单记录: {}" , params); Order order = new Order (); order.setUserId(((Number) params.get("userId" )).longValue()); order.setProductId(((Number) params.get("productId" )).longValue()); order.setCount((Integer) params.get("count" )); order.setMoney((java.math.BigDecimal) params.get("money" )); order.setStatus(0 ); order = orderRepository.save(order); log.info("[Saga-正向] 订单记录创建成功,订单ID: {}" , order.getId()); Map<String, Object> result = new HashMap <>(); result.put("orderId" , order.getId()); return result; } @Transactional(rollbackFor = Exception.class) public void cancelOrder (Map<String, Object> params) { Long orderId = ((Number) params.get("orderId" )).longValue(); log.info("[Saga-补偿] 取消订单: orderId={}" , orderId); orderRepository.findById(orderId).ifPresent(order -> { order.setStatus(2 ); orderRepository.save(order); log.info("[Saga-补偿] 订单已取消: orderId={}" , orderId); }); } @Transactional(rollbackFor = Exception.class) public void completeOrder (Map<String, Object> params) { Long orderId = ((Number) params.get("orderId" )).longValue(); log.info("[Saga-正向] 完成订单: orderId={}" , orderId); orderRepository.findById(orderId).ifPresent(order -> { order.setStatus(1 ); orderRepository.save(order); log.info("[Saga-正向] 订单已完成: orderId={}" , orderId); }); } public Order getById (Long id) { return orderRepository.findById(id) .orElseThrow(() -> new RuntimeException ("订单不存在: " + id)); } }
然后,随便看一个分布式事务的分支事务的内容,每个分支事务的每个操作,也都需要有对应的正向和补偿操作
例如,你下了订单,订单能够被正确创建并且完成,库存服务就需要正确的扣减库存,这是分支事务需要的正向操作,但是如果订单没有被正确完成,库存服务就需要恢复被扣掉的库存,来回到事务开始前的状态,这是分支事务需要的补偿操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 @Transactional(rollbackFor = Exception.class) public Map<String, Object> deduct (Map<String, Object> params) { Long productId = ((Number) params.get("productId" )).longValue(); Integer count = (Integer) params.get("count" ); log.info("[Saga-编排式-正向] 扣减库存: productId={}, count={}" , productId, count); Storage storage = storageRepository.findByProductId(productId) .orElseThrow(() -> new RuntimeException ("库存不存在: productId=" + productId)); if (storage.getCount() < count) { log.error("[Saga-编排式-正向] 库存不足: productId={}, available={}, required={}" , productId, storage.getCount(), count); throw new RuntimeException ("库存不足" ); } Integer originalCount = storage.getCount(); storage.setCount(storage.getCount() - count); storageRepository.save(storage); log.info("[Saga-编排式-正向] 库存扣减成功: productId={}, 原库存={}, 扣减数量={}, 新库存={}" , productId, originalCount, count, storage.getCount()); Map<String, Object> result = new HashMap <>(); result.put("originalCount" , originalCount); result.put("deductedCount" , count); return result; } @Transactional(rollbackFor = Exception.class) public void compensateDeduct (Map<String, Object> params) { Long productId = ((Number) params.get("productId" )).longValue(); Integer count = (Integer) params.get("count" ); log.info("[Saga-编排式-补偿] 恢复库存: productId={}, count={}" , productId, count); Storage storage = storageRepository.findByProductId(productId) .orElseThrow(() -> new RuntimeException ("库存不存在: productId=" + productId)); Integer originalCount = storage.getCount(); storage.setCount(storage.getCount() + count); storageRepository.save(storage); log.info("[Saga-编排式-补偿] 库存恢复成功: productId={}, 原库存={}, 恢复数量={}, 新库存={}" , productId, originalCount, count, storage.getCount()); }
Saga 状态机
编排式 Saga 是通过一个中心化的状态机配置(JSON 或
YAML)定义整个事务的执行流程、正向操作、补偿操作、异常处理等逻辑,状态机引擎根据配置驱动各个微服务的方法调用,实现分布式事务的最终一致性。
首先,编排式 Saga
最重要的就是编排分布式业务的状态机,一般情况下,Saga 支持使用 JSON 和
YAML 描述事务流程,一般,我们放在 resources/statemachine/ 目录下
那么,状态机涉及到的 JSON
节点非常多,我写的相对简单一些,比较重要的节点有这些
State(状态) :每个状态对应一个具体操作(正向 /
补偿),如
CreateOrder(创建订单)、CancelOrder(取消订单
- 补偿);ServiceTask :最常用的状态类型,用于调用具体的业务服务方法;CompensateState :指定当前正向操作失败时的补偿状态;Input/Output :定义方法调用的入参、返回值映射;Catch/Retry :异常捕获、重试策略;CompensationTrigger :全局异常触发补偿的终结状态。
基础元信息部分
1 2 3 4 5 6 7 { "Name" : "orderSagaStateMachine" , "Comment" : "订单创建 Saga 状态机 - 编排式" , "Version" : "1.0.0" , "StartState" : "CreateOrder" , "States" : { ... } }
其中,Saga 中的所有状态,也就是整个 Saga
中的所有事务,都需要写到"States"块中,其中,States
块下一级字段都说对分布式事务的每个操作(状态)的名,例如CreateOrder
每个 Saga分布式事务中的状态(操作),或者说每个业务操作(正向 /
补偿)都定义为一个 ServiceTask 状态
每个业务操作(正向 / 补偿)中的字段差不多就这些
字段
作用
Type状态类型,ServiceTask
表示调用业务方法
ServiceName要调用的 Spring Bean
名称(对应服务类的实例名,Spring 自动生成)
ServiceMethod要调用的 Bean 中的具体方法名
CompensateState当前正向操作失败时,要执行的补偿状态名称
Input方法入参映射:从状态机上下文(params)中取值,传递给目标方法
Output方法返回值映射:将方法返回结果存入状态机上下文,供后续状态使用
Status方法执行结果的状态判断(SU = 成功,FA =
失败)
Next方法执行成功后,下一个要执行的状态名称
Catch异常捕获:指定异常类型及异常后跳转的状态(一般跳转到补偿触发)
Retry重试策略:方法执行失败时的重试配置(仅正向操作常用,补偿也可配置)
注意,状态机的 ServiceName 必须和 Spring Bean
名称一致(可通过 @Service("xxx")
手动指定),因为这是通过反射调用的
例如创建订单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 "CreateOrder" : { "Type" : "ServiceTask" , "ServiceName" : "orderServiceSaga" , "ServiceMethod" : "createOrderRecord" , "CompensateState" : "CancelOrder" , "Input" : [ "$.[userId]" , "$.[productId]" , "$.[count]" , "$.[money]" ] , "Output" : { "orderId" : "$.orderId" } , "Status" : { "#root == null" : "FA" , "#root != null" : "SU" } , "Retry" : [ ] , "Next" : "DeductStorage" , "Catch" : [ { "Exceptions" : [ "java.lang.Exception" ] , "Next" : "CompensationTrigger" } ] } ,
补偿状态也是 ServiceTask 类型,但无
Next/CompensateState ,例如
1 2 3 4 5 6 7 8 "CancelOrder" : { "Type" : "ServiceTask" , "ServiceName" : "orderServiceSaga" , "ServiceMethod" : "cancelOrder" , "Input" : [ "$.[orderId]" ] , "Status" : { "#root == null" : "FA" , "#root != null" : "SU" } , "Retry" : [ { "Exceptions" : [ "java.lang.Exception" ] , "IntervalMs" : 2000 , "MaxAttempts" : 5 } ] }
当任意正向操作抛出异常时,跳转到该异常终结状态,触发 Seata
引擎自动执行已完成操作的补偿,按反向顺序执行
1 2 3 4 5 "CompensationTrigger" : { "Type" : "Fail" , "ErrorCode" : "SAGA_TRANSACTION_FAILED" , "Message" : "Saga 事务执行失败,触发补偿" }
关于状态机的设计,Seata Saga
提供了一个可视化的状态机设计器方便用户使用,代码和运行指南请参考:
https://github.com/apache/incubator-seata/tree/refactor_designer/saga/seata-saga-statemachine-designer
那么,Saga 状态机是如何通过这个描述感极强的 JSON
流程文本,来调用服务类方法的?
Seata 状态机引擎通过 Spring Bean 容器 + 反射
实现服务类方法的调用
业务中涉及到的三个服务类(OrderServiceSagaArrangement、StorageServiceSagaArrangement、AccountServiceSagaArrangement)都加了
@Service 注解,Spring 会自动将其注册为 Bean,Bean
名称默认是类名首字母小写 ,这些都是很常规的内容
状态机引擎调用方法的核心步骤如下(以 CreateOrder
状态调用 orderServiceSaga.createOrderRecord 为例)
启动状态机,传入上下文参数
在 OrderServiceSagaArrangement.createOrder 方法中,通过
stateMachineEngine.startWithBusinessKey
启动状态机,并传入参数(userId、productId 等)
1 2 3 4 5 6 7 8 9 10 11 12 Map<String, Object> startParams = new HashMap <>(); startParams.put("userId" , dto.getUserId()); startParams.put("productId" , dto.getProductId()); startParams.put("count" , dto.getCount()); startParams.put("money" , dto.getMoney()); StateMachineInstance instance = stateMachineEngine.startWithBusinessKey( "orderSagaStateMachine" , null , (String) startParams.get("businessKey" ), startParams );
状态机引擎解析 Input,映射方法入参
状态机配置中 CreateOrder 的 Input 是
["$.[userId]", "$.[productId]", "$.[count]", "$.[money]"]
$ 代表状态机的上下文(即
startParams);$.[userId] 等价于
startParams.get("userId");
引擎会将这些参数按顺序封装为数组,作为 createOrderRecord
方法的入参,就像我上面写的方法入参是
Map<String, Object> params,Seata
会自动将上下文封装为 Map 传入。
之后就是反射调用 Bean 的方法,引擎通过 ServiceName
从 Spring 容器获取 Bean(orderServiceSaga),再通过
ServiceMethod(createOrderRecord)反射调用方法
然后解析 Output,将返回值存入上下文
createOrderRecord 方法返回
Map<String, Object>(包含
orderId),状态机配置的 Output 是
{"orderId": "$.orderId"}:
$.orderId 代表从方法返回的 Map 中取
orderId;引擎将 orderId 存入状态机上下文,供后续状态(如
DeductStorage、CompleteOrder)使用。
异常处理与补偿触发
如果 createOrderRecord 抛出异常,会触发
Catch 配置,跳转到对应配置的异常状态,我的状态机中使用的是
CompensationTrigger 状态
Saga 编排式后续需要做的事情
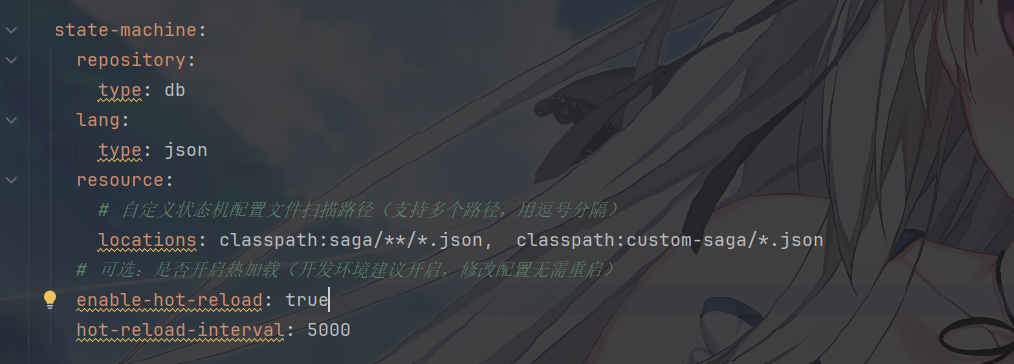
那么最后一个问题就是状态机文件要放到哪里,才能被正确读取
首先,Seata Saga
引擎默认会扫描 项目中以下路径的状态机配置文件,肯定要放到
Saga 分布式事务的入口对应的服务中
1 2 3 4 5 src └── main └── resources # 项目核心资源目录 └── saga # 必须创建名为 saga 的子目录(固定名称) └── orderSagaStateMachine.json # 你的状态机配置文件
当然,你也可以在配置文件中指定
image-20260110160051071
然后,还需要创建状态机相关的表在Saga
分布式事务的入口对应的服务中的数据库
因为 Seata Saga
模式依赖这些表来持久化状态机实例、执行日志等核心数据,保证事务的可追溯、可重试
Seata Saga 模式依赖以下 3 张核心表,表名和结构由 Seata
官方定义,不可自定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 CREATE TABLE IF NOT EXISTS seata_state_machine_inst( id VARCHAR (128 ) NOT NULL COMMENT 'id' , machine_id VARCHAR (32 ) NOT NULL COMMENT 'state machine definition id' , tenant_id VARCHAR (32 ) NOT NULL COMMENT 'tenant id' , parent_id VARCHAR (128 ) COMMENT 'parent id' , gmt_started TIMESTAMP (3 ) NOT NULL COMMENT 'start time' , business_key VARCHAR (48 ) COMMENT 'business key' , start_params TEXT COMMENT 'start parameters' , gmt_end TIMESTAMP (3 ) COMMENT 'end time' , excep BYTEA COMMENT 'exception' , end_params TEXT COMMENT 'end parameters' , status VARCHAR (2 ) COMMENT 'status(SU succeed|FA failed|UN unknown|SK skipped|RU running)' , compensation_status VARCHAR (2 ) COMMENT 'compensation status(SU succeed|FA failed|UN unknown|SK skipped|RU running)' , is_running SMALLINT COMMENT 'is running(0 no|1 yes)' , gmt_updated TIMESTAMP (3 ) NOT NULL COMMENT 'update time' , PRIMARY KEY (id), INDEX idx_business_key (business_key), INDEX idx_gmt_started (gmt_started), INDEX idx_status (status) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = 'state machine instance' ;CREATE TABLE IF NOT EXISTS seata_state_inst( id VARCHAR (128 ) NOT NULL COMMENT 'id' , machine_inst_id VARCHAR (128 ) NOT NULL COMMENT 'state machine instance id' , name VARCHAR (128 ) NOT NULL COMMENT 'state name' , type VARCHAR (20 ) COMMENT 'state type' , service_name VARCHAR (128 ) COMMENT 'service name' , service_method VARCHAR (128 ) COMMENT 'method name' , service_type VARCHAR (16 ) COMMENT 'service type' , business_key VARCHAR (48 ) COMMENT 'business key' , state_id_compensated_for VARCHAR (128 ) COMMENT 'state compensated for' , state_id_retried_for VARCHAR (128 ) COMMENT 'state retried for' , gmt_started TIMESTAMP (3 ) NOT NULL COMMENT 'start time' , is_for_update SMALLINT COMMENT 'is service for update' , input_params TEXT COMMENT 'input parameters' , output_params TEXT COMMENT 'output parameters' , status VARCHAR (2 ) NOT NULL COMMENT 'status(SU succeed|FA failed|UN unknown|SK skipped|RU running)' , excep BYTEA COMMENT 'exception' , gmt_updated TIMESTAMP (3 ) COMMENT 'update time' , gmt_end TIMESTAMP (3 ) COMMENT 'end time' , PRIMARY KEY (id, machine_inst_id), INDEX idx_machine_inst_id (machine_inst_id), INDEX idx_business_key (business_key), INDEX idx_gmt_started (gmt_started) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = 'state instance' ;CREATE TABLE IF NOT EXISTS seata_state_machine_def( id VARCHAR (32 ) NOT NULL COMMENT 'id' , name VARCHAR (128 ) NOT NULL COMMENT 'name' , tenant_id VARCHAR (32 ) NOT NULL COMMENT 'tenant id' , app_name VARCHAR (32 ) NOT NULL COMMENT 'application name' , type VARCHAR (20 ) COMMENT 'state language type' , comment_ VARCHAR (255 ) COMMENT 'comment' , ver VARCHAR (16 ) NOT NULL COMMENT 'version' , gmt_create TIMESTAMP (3 ) NOT NULL COMMENT 'create time' , status VARCHAR (2 ) NOT NULL COMMENT 'status(AC:active|IN:inactive)' , content TEXT COMMENT 'JSON content' , recover_strategy VARCHAR (16 ) COMMENT 'transaction recover strategy(compensate|retry)' , PRIMARY KEY (id) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = 'state machine definition' ;
最后,在 application.yml 中配置 Seata Saga 的数据源
1 2 3 4 5 6 7 8 9 10 11 saga: state-machine: repository: type: db db: datasource: druid url: jdbc:mysql://127.0.0.1:3306/order_db?useUnicode=true&characterEncoding=utf8&useSSL=false username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver
可见 Saga 实现 分布式事务 是比较复杂的,但是在长事务上,Saga
的稳定性很好
XA模式的演示
XA 我们之前也说过,Seata XA
模式是利用事务资源(数据库、消息服务等)对 XA
协议的支持,是两阶段提交协议,提供了强一致性的事务保障。
使用 Seata XA 模式是有前提的
但是 XA
协议被主流关系型数据库广泛支持,其实通常情况下不需要额外的适配即可使用。
和 AT 一样,XA
模式将是业务无侵入的,不给应用设计和开发带来额外负担。
所以说,XA模式和AT模式的实现差不多
XA模式下分布式事务入口的编写
XA模式和AT模式在分布式事务入口的编写没有太大差别,全局事务的开启也是使用
@GlobalTransactional 注解,在分布式事务开始的时候 Seata
会生成全局事务ID(XID),将 XID 绑定到当前线程,这和 AT 模式是一样的
XA事务是两阶段提交事务
第一阶段被称为 Prepare
阶段,此时各分支事务执行本地数据库操作,数据库记录事务日志,所有分支事务进入
Prepare 状态,等待提交指令
第二阶段就是(Commit 或 Rollback),如果所有分支事务 Prepare
成功,TC 发送 Commit 指令,各分支事务提交,而如果任何分支事务 Prepare
失败,TC 发送 Rollback 指令,所有分支事务回滚
这和 AT 事务也是差不多的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 @GlobalTransactional( name = "createOrderXA", // 全局事务名称,用于监控 rollbackFor = Exception.class, // 任何异常都回滚 timeoutMills = 300000 // 全局事务超时时间(毫秒) ) @Transactional(rollbackFor = Exception.class) public Order createOrder (CreateOrderDTO dto, Boolean failInDeduct) { log.info("========== XA模式:开始创建订单 ==========" ); log.info("全局事务XID: {}" , RootContext.getXID()); log.info("订单信息 - 用户ID: {}, 商品ID: {}, 数量: {}, 金额: {}" , dto.getUserId(), dto.getProductId(), dto.getCount(), dto.getMoney()); log.info("测试参数 - failInDeduct: {}" , failInDeduct); Order order = new Order (); order.setUserId(dto.getUserId()); order.setProductId(dto.getProductId()); order.setCount(dto.getCount()); order.setMoney(dto.getMoney()); order.setStatus(0 ); order = orderRepository.save(order); log.info("订单创建成功,订单ID: {}" , order.getId()); try { log.info("========== 调用库存服务扣减库存(XA事务)==========" ); storageServiceClient.deductXA(dto.getProductId(), dto.getCount()); log.info("库存扣减成功" ); if (Boolean.TRUE.equals(failInDeduct)) { log.error("========== 模拟扣减阶段失败,测试 XA 事务回滚 ==========" ); throw new RuntimeException ("模拟扣减阶段失败,测试 XA 事务回滚" ); } log.info("========== 调用账户服务扣减余额(XA事务)==========" ); accountServiceClient.deductXA(dto.getUserId(), dto.getMoney()); log.info("账户余额扣减成功" ); } catch (Exception e) { log.error("XA 事务执行失败,将触发全局回滚:{}" , e.getMessage()); throw e; } order.setStatus(1 ); order = orderRepository.save(order); log.info("========== XA模式:订单创建完成,订单ID: {} ==========" , order.getId()); log.info("所有分支事务将在全局事务提交时一起提交" ); return order; }
XA 模式不需要额外的数据库表(不需要 undo_log),但需要数据库支持 XA
事务,常用的数据库对 XA 的支持度如下:
PostgreSQL :完全支持 XA 事务MySQL 5.7+ :支持 XA 事务Oracle :支持 XA 事务
XA模式下分支事务的编写
我放出来大家就能看懂,和AT模式下基本一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Transactional(rollbackFor = Exception.class) public void deduct (Long userId, BigDecimal money) { String xid = RootContext.getXID(); log.info("========== XA分支事务:开始扣减账户余额 ==========" ); log.info("分支事务XID: {}" , xid); log.info("用户ID: {}, 扣减金额: {}" , userId, money); Account account = accountRepository.findByUserId(userId) .orElseThrow(() -> new RuntimeException ("账户不存在,用户ID: " + userId)); BigDecimal newBalance = account.getBalance().subtract(money); if (newBalance.compareTo(BigDecimal.ZERO) < 0 ) { throw new RuntimeException ("账户余额不足,当前余额: " + account.getBalance() + ", 需要扣减: " + money); } account.setBalance(newBalance); accountRepository.save(account); log.info("账户余额扣减成功,用户ID: {}, 原余额: {}, 扣减后余额: {}" , userId, account.getBalance().add(money), newBalance); log.info("注意:此事务处于 Prepare 状态,等待全局事务提交" ); }
但是有一个重要的配置需要处理
1 2 3 seata: enable-auto-data-source-proxy: true data-source-proxy-mode: XA
data-source-proxy-mode
配置必须在所有服务中保持一致 ,否则可能导致事务无法正确传播。
测试XA模式
首先测试正常的情况
image-20260110170521643
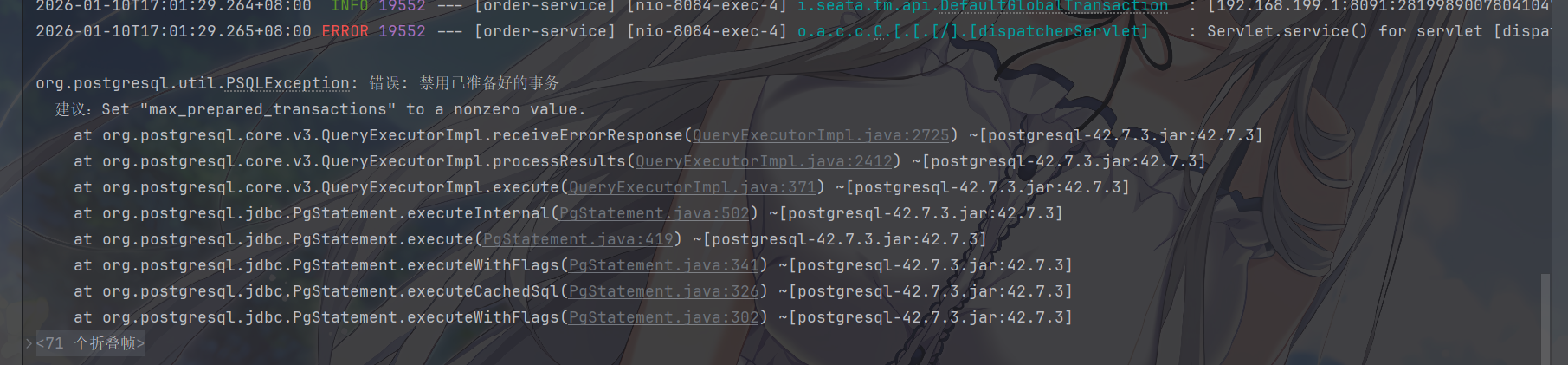
对了,如果使用 postgresql 的大伙,可能会出现这种情况
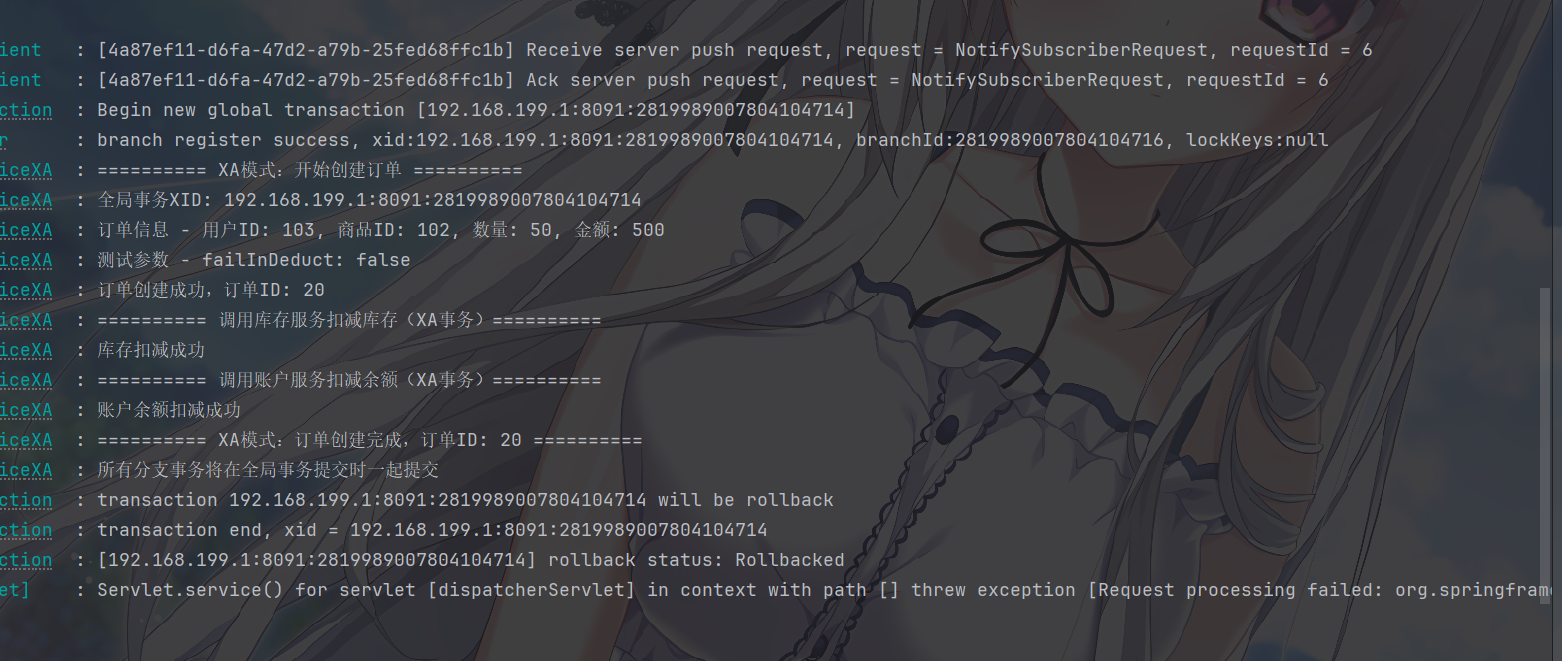
image-20260110170239543
pg在17的某个版本,PostgreSQL 禁用了已准备好的事务(Prepared
Transaction) ,而 Seata XA 模式依赖 PostgreSQL 的 XA
事务(即准备好的事务)来实现分布式事务的两阶段提交,因此触发了这个报错。
PostgreSQL 的 max_prepared_transactions 参数默认值是
0 ,表示完全禁用「准备好的事务」,这是 XA
事务的核心,所以说PostgreSQL 拒绝执行
PREPARE TRANSACTION,直接抛出上述错误。
修改比较简单,就是打开配置文件,找到以下参数并修改:
1 2 3 4 5 6 max_prepared_transactions = 100
然后重启服务,但是我的 pg
因为一些个人项目的原因,这个两阶段提交必须关闭,我就不改了
image-20260110170441424
所以可以把这次业务当成 XA
一次错误的回滚情况,可以看到数据库中的内容都是正确的,是事务开始之前的状态
按照正常的情况应该是能成功的,我就不测试了