
LLM基础
之前的 LLM 基础过于浅薄,我打算在这里再重述如下三个比较重要,示例的项目中广泛涉及到的内容,进行一个相对广泛的讲解
Embedding
为什么 Embedding 是 Neo4j + AI 的核心
因为现在基本的一些功能下:
- RAG
- GraphRAG
- AI 知识库
- Agent Memory
- Neo4j Vector Index
- Semantic Search
- 多模态检索
Embedding 依旧是它们的底层基础,在自然语言处理 (NLP) 任务中,LLM 本身不擅长知识检索,处理文本需要将每个单词转换成对应的数字表示。大多数 Embedding 方法都归结为将单词或标记转换为向量。各种嵌入技术之间的区别在于它们如何处理这种“单词→向量”的转换。
在 Neo4j 的实践下,Neo4j 负责知识的关系结构,Embedding 负责语义空间,两者结合,才形成现代 AI 检索系统。
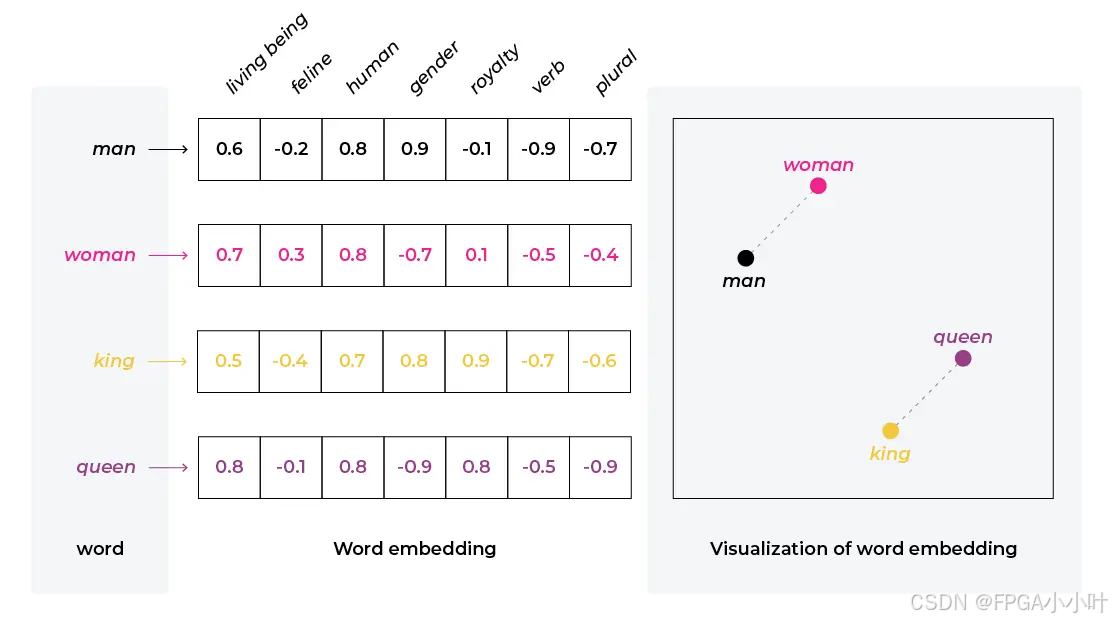
本质上,Embedding 是把文本转换成向量,但是我额外看到了一种很好的说法,就是,Embedding 是把人类语言映射到数学空间中的语义坐标。例如
1 | 猫 |
对于上述内容,在人类看来:猫和狗接近;Java 和 Spring Boot 接近;Neo4j 和 图数据库 接近。这是很清晰的
而 Embedding 模型会在高维空间中保留这种语义距离,这也就是为什么Embedding是 LLM 的语义支柱。因为它可以将原始文本转换为向量形式来方便模型理解。当你在使用 LLM 时,你的输入文本、代码等内容会被转换为高维向量,从而将其中的语义转化成数学关系。
假设,一句话:
1 | Spring Boot 是一个 Java 开发框架 |
经过 Embedding Model 会变成:
1 | [0.183, -0.284, 0.993, ...] |
可能,768维,1024维,1536维等等,这就是 高维浮点向量,核心是 Embedding 模型会让语义相近的文本,在向量空间中的距离也更接近
所以说,Embedding不仅适用于文本,还可以应用于图像、音频甚至图数据。广义上讲,Embedding是将(任何类型的)数据转换为向量的过程。但是肯定的,每种模态的Embedding方法都各不相同且独一无二。
那么向量是如何产生的,很明显,Embedding 层的本质是一个巨大的矩阵,输入一个 Token,模型直接通过索引取出对应的那一行向量。
而取出这个过程并非简单的查表,而是动态计算,这就涉及到 Transformer 的多层自注意力机制,初始的静态向量会根据上下文不断更新,最终形成包含完整语义信息的动态向量。
对于 LLM 来说,Embedding可以被视为其语言的词典。好的Embedding可以让模型能够更好的理解人类语言。但是,什么才是理想的嵌入技术呢?以下是嵌入技术的两个主要特性:
- 「语义表示」 某些类型的Embedding可以捕捉单词之间的语义关系。这意味着,含义更接近的单词在向量空间中更接近。例如,“猫”和“狗”的向量肯定比“狗”和“草莓”的向量更相似。
- 「维度」 嵌入向量的大小应该是多少?15、50 还是 300?找到合适的平衡点是关键。较小的向量(较低维度)在内存中保存或处理效率更高,而较大的向量(较高维度)可以捕捉复杂的关系,但容易出现过拟合。作为参考,GPT-2 模型系列的嵌入大小至少为 768。
Embedding 的工作流程一般如下
文本输入
例如,用户输入了:Neo4j 是图数据库
文本切分或者Tokenizer
- 对于分词Tokenizer:Embedding 不适合超长文本,对于上述输入,可以分词分成,Neo4j 图 数据库(此时,Token 不等于单词,LLM 使用的是Subword Tokenization)
Embedding Layer
每个词 token 会映射成 token -> 向量,Neo4j -> [0.13, 0.55, …],图数据库 -> [0.44, -0.12, …],这种形式
Transformer 编码
模型会结合上下文。在不同语境下,Embedding 不同。这叫 Contextual Embedding
输出 Sentence Embedding
最终整句话:
1
Neo4j 是图数据库
得到了
1
[0.123, -0.839, 0.228 ...]
很明显,向量距离是整个检索过程的核心,但是 Embedding 产生的高维向量的本身没太大意义,真正有意义的是向量之间的距离。
RAG
RAG 检索增强生成(Retrieval Augmented Generation),其核心思想是 先搜再答,让大模型在回答之前先去搜一遍相关资料,再基于搜到的知识来组织答案。这样就能给出可解释可溯源的准确答案。
虽然现在 AI 的上下文已经很大了,但是把所有文档塞进上下文窗口,既贵又不靠谱。上下文越长 token 费用越高,而且大模型普遍存在 “Lost in the Middle” 问题,顾名思义,就是对超长上下文中间部分的注意力会明显下降。这个也不难理解,就像听别人说话一样,我们对开头和结尾的印象会相对深刻一些,中间的总是容易忘记。
可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
对于主流的 RAG 方案,讲几个,其实基本步骤大差不大,主要是在查询优化上的不同优化
Naive RAG
一个文档可能非常大,几个G,但是一轮提问中需要到的内容可能也就是其中的几十兆,所以说,我们为了回答质量和成本,把文档切成小块(chunk),每块几百字,用 Embedding 模型把每个小块转成向量,把向量和对应原文都存进向量数据库,然后把用户问题也用 Embedding 模型转成向量
这样,去向量库里搜最相似的几个文档块,把这几个块和用户问题拼成 Prompt,交给大模型生成回答
Multi-Query RAG
用多角度提问打破单一视角,因为用户不可能照着文档来提问,如果用户的措辞和文档差距太大,向量检索就可能搜不到正确的内容。Multi-Query 的思路就是,既然一种问法搜不全,那就让大模型把原始问题改成多种不同的表述,分别去搜,最后把结果合并去重。这种方法的代价就是每次提问要多调用一次 LLM 做改写,再多跑 N 次向量检索,延迟和成本都会增加。而且如果 LLM 改写出的问题方向跑偏,会把无关文档也带进来,影响答案质量。
HyDE
它叫假设性文档嵌入,用户提问的时候,LLM 凭空编一个假设性答案,然后将假设答案向量化,不必完全准确,用这个向量去检索真实文档,LLM 再基于真实文档生成最终回答。因为用户的提问可能简单,可能模糊,但答案通常是详实、具体的,所以说,理想情况下假答案和真文档在向量空间中离得总应该更近。
在 GraphRAG 中,这三种策略通常用在入口定位阶段。例如,你可以用 HyDE 或 Multi-Query* 先在 Neo4j 的向量索引中,更精准地找到几个核心的实体节点,一旦定位到了这些实体,就可以发挥 Neo4j 的特长,沿着图关系去 Cypher 遍历向外挖掘更深层的知识,最后再交给 LLM 生成。
Memory
长任务一跑起来,很快就会撞到一些问题, 上下文窗口有上限,Token 昂贵,所以说,一套能挂载历史记录的记忆层很重要。
记忆(Memory)是AI智能体必备的能力之一。随着对话轮数与深度的增加,如何让AI智能体 记住 过去的上下文是关键,由于LLM存在上下文长度限制,如果不对记忆进行优化,长对话很容易遗忘早期信息,导致理解偏差并且带来高成本。
记忆系统通常分两层:短期记忆和长期记忆。两者在物理和逻辑上都应该分开,不要混成一锅。
短期记忆是 Session 级的,是 Agent 在当前单次会话中持有的暂存信息,服务当前任务,目的是关键事实(被强调的)内容不要丢失或者遗忘,短期记忆主要依托 LLM 自身的上下文窗口
窗口大,不等于可以无限塞上下文。推理成本会随 Token 数线性增长。在多文档检索型任务中,模型更容易利用上下文首尾的信息,中间段的信息利用率明显更低。窗口越长,这种位置偏差越明显。
长期记忆是跨 Session 的,负责把用户偏好、历史决策、过往经验沉淀下来,提升用户的使用体验。
虽然,长期记忆和 RAG 技术上很像,都会用向量库和语义检索。但它们服务的对象不一样。RAG 挂载的是共享知识源,长期记忆管理的是 Agent 与特定用户交互中动态沉淀的个性化经验
而且记忆还可以按存储位置和表征形式分成三类
| 存储形式 | 说明 | 典型实现 |
|---|---|---|
| Token 级记忆 | 以自然语言或离散符号形式存储在外部数据库 | 向量库中的文本块、结构化 JSON |
| 参数化记忆 | 将信息编码进模型参数中 | 预训练知识、LoRA 适配器、SFT 微调 |
| 潜在记忆 | 以隐式形式承载在模型内部表示中 | KV Cache、激活值、Hidden States |
- 但是上述内容中,这些记忆并不一定是完全按照这样可以完备的被描述的,记忆的流转很复杂,但是通常情况下,会把经常用的热记忆放到更近的位置,把稳定、长期的冷记忆用更重的方式固化下来
一条记忆从进入系统到最终被淘汰,一般会经历这些环节。不同论文里的名字会有差异,但语义基本能对上。
1 | 编码(Encode) → 存储(Storage) → 提取(Retrieval) → 巩固(Consolidation) → 反思(Reflection) → 遗忘(Forgetting) |
| 操作 | 说明 | 工程实现 |
|---|---|---|
| 编码 | 将原始交互转化为可存储的结构化信息 | LLM 提取事实三元组、生成摘要 |
| 存储 | 将编码后的信息持久化 | 写入向量库 / 图数据库 / 参数 |
| 提取 | 根据上下文检索相关记忆 | 向量检索 + BM25 + 图遍历 |
| 巩固 | 将短期记忆转化为长期记忆 | 异步任务:对话摘要 → 实体库 |
| 反思 | 主动回顾评估记忆内容,优化决策 | 任务完成后提取 Meta-Knowledge |
| 遗忘 | 淘汰低价值或过时记忆 | 权重衰减 + 冲突标记废弃 |
主流的记忆技术架构中,底层架构通常分三层。
- VectorStore 负责向量存储。它把提取出来的记忆文本转成 Embeddings,再存进向量数据库。
- GraphStore 负责图存储。我们使用 Neo4j,可以把记忆建模成知识图谱,这样 AI 就对需要多跳的推理更加擅长
- Reranker 负责重排序。向量检索只是初步召回,语义相关性并不总是精确有序。Reranker 通常基于交叉编码器(Cross-Encoder)对候选结果做二次精排,把更相关的记忆排到前面,减少无关内容进入上下文。
最后,用 markdown 存储 Agent 记忆非常常见,但是这个和叫做 skills 的 AGENTS.md 又是两回事。
引入AI到我们的项目
项目中如何进行的AI检索
AI 检索主要有如下三种形式,在本次项目中,我均尽量涉及到
| Vector Search | Graph Search | GraphRAG | |
|---|---|---|---|
| 输入 | 自然语言 | 实体名(人名/电影名/类型) | 自然语言 |
| 靠什么 | 向量 cosine 相似度 | Cypher 多跳遍历 | 向量粗筛 + 图扩展 + LLM 生成 |
| 优势 | 理解模糊语义 | 精准、可解释 | 准确度 + 自然交互 |
Vector Search 就是向量检索,它不依赖关键词的精准匹配,而是将文本转化为高维向量。通过计算向量之间相似程度(一般是余弦相似度),找到语义上最接近的内容。
Neo4j 提供了原生的向量索引,基于 HNSW 算法,可以将相关内容生成向量后存储在节点属性中,这样 AI 就拥有了语义理解能力,能处理模糊、同义改写的问题,但是缺乏精确的逻辑控制
Graph Search 就是图检索,利用图数据库中节点与关系的强连接特性,通过 Cypher 查询语言进行多跳遍历。这样就能够靠严密的逻辑路径查找事实
在 AI 项目中,通常结合 Text2Cypher 等技术,让大模型将用户的自然语言直接翻译成 Cypher 语句去查询数据库。
GraphRAG 图检索增强生成,它结合了向量检索和图检索的特性。
GraphRAG 通常包含三个关键步骤:向量粗筛(定位入口),图扩展,LLM生成
既保留了自然语言交互的流畅性,又通过知识图谱极大地降低了 AI 的幻觉
实体类的编排
这次我们打算做一个 AI 电影推荐系统,那么我们就需要编写下列的这三个实体类,他们的关系是这样的
| 实体类 | 对应节点 | 核心属性 | 关系说明 |
|---|---|---|---|
| Movie (电影) | :Movie |
标题、年份、简介、评分 | 被人导演、被人出演、属于类型 |
| Person (人物) | :Person |
姓名、出生年份 | 导演电影、出演电影 |
| Genre (类型) | :Genre |
名称 | 电影的分类 |
1 | /** |
- 使用了
@JsonIgnore注解是因为,在将对象序列化为 JSON(例如返回给前端)时,如果不忽略关系字段(如actedIn,directed),会因为对象之间的循环引用(Movie 引用 Person,Person 又引用 Movie)导致序列化失败或栈溢出。
为了简化设计,导演和演员共用同一个 Person 节点
1 | /** |
这是一个简单的字典类节点,用于分类电影
1 |
|
持久层
持久层接口依旧需要继承 Neo4jRepository来拥有了基本的
CRUD 能力。对于针对 AI
和图检索的特性,这里为MovieRepository
编写了特殊的查询方法。
1 | package hbnu.project.neo4jdemo.ai.repository; |
- 为了支持 AI 的语义搜索,需要根据 Neo4j 的
elementId批量查询电影。这是因为在向量索引中检索到相似内容后,需要通过 ID 回填完整的电影业务数据。利用Movie.plot的向量化,在MovieRepository中通过 ID 快速召回语义相似的电影。 - 那么,GraphRAG就是先用 Vector Search 找到入口节点,再用 Graph Search 沿着关系扩展上下文(如找出该电影的导演、演员),最后将这些结构化的图数据交给 LLM 生成更准确、有依据的回答,有效防止了 AI 的幻觉。
而GenreRepository 和 PersonRepository
因为本项目中这两个不在 AI
部分作为直接操作的对象,所以说非常简洁,只使用了 Spring Data
提供的派生查询,写一个findByName(String name):
根据名称查找唯一实体,应该就足够了
服务层
语义检索服务(Vector Search)
上面也提到了,它的作用是将用户自然语言的意图,转化为机器能理解的数学语言(向量),执行语义检索,从而在海量数据中找到最相关的信息。这是 LLM 生成高质量回答的基石。
VectorSearchService 作为知识检索器,它通过以下方式为 LLM
提供支持:
- 解决 幻觉 问题:LLM
本身是一个概率模型,容易产生幻觉。Vector Search
从数据库中找到的真实、相关的电影简介(
plot),为 LLM 提供了可靠的事实依据。 - 实现语义理解:它让系统能够理解用户模糊的、自然语言形式的查询(如“关于梦境的电影”),而不仅仅是依赖数据库中的精确关键字匹配。
- 提供上下文(Context):它检索到的电影信息(标题、年份、简介)会被拼接成一段Prompt,作为上下文输入给 LLM。LLM 基于这些上下文,生成最终的、个性化的推荐回复。
1 |
|
- 对于上面的
semanticSearch方法,它是 Vector Search 的核心,我们拆解一下它的实现- 接收自然语言:方法接收用户的查询字符串
query - 向量化:
embeddingModel.embed(query),这里使用 LangChain 自带的 Embedding 模型,将这段文本转换为一个384 维浮点数数组的数学向量,这样我们就捕捉到了文本的语义信息 - 相似度匹配:构建
EmbeddingSearchRequest并调用embeddingStore.search(request), Neo4j 的向量索引中,计算查询向量与所有存储的向量(电影简介plot的向量)之间的余弦相似度(Cosine Similarity)。根据minScore(最低相似度)和topK(返回数量)筛选出最匹配的结果。EmbeddingStore<TextSegment> embeddingStore就是向量的仓库,是配置好的 Neo4j 向量数据库连接。管理着向量的存储、索引和搜索
- 结果封装返回:将检索到的
EmbeddingMatch对象流转换为结构化的Map列表。
- 接收自然语言:方法接收用户的查询字符串
图检索服务(Graph Search)
我们现在进入了图数据库最核心、最具优势的领域,也是 Neo4j 结合 LLM 的核心,就是 Graph Search
如果说 Vector Search 负责理解“语义”,那么 Graph Search 就负责处理“关系”。它的核心职责是利用图数据库的多跳遍历(Multi-hop Traversal)能力,挖掘实体之间复杂的直接或间接联系。
1 |
|
- Vector Search
基于语义相似度,可能会因为向量空间的微小偏差导致推荐错误。Graph Search
基于明确的数学关系,就假如当用户问“诺兰导演的其他电影”时,Graph Search
能 100% 精确地顺着
DIRECTED关系箭头找到所有电影,这是可回溯的且精确的。
对于,需要注意一个问题,这个类专门解决了一个在混合检索系统中非常典型且棘手的问题,也就是 Spring Data Neo4j (SDN) 实体映射管线与自定义图结构查询之间的兼容性冲突。
1 |
|
- 在 Spring Data Neo4j (SDN) 框架中,如果你使用
@Query注解在 Repository 接口中编写自定义 Cypher 语句,SDN 会默认开启它的实体映射管线。- 对于 SDN,它通常期望查询结果是一个节点实体,或者一个简单的值
- 但是实际上,在 GraphRAG(图检索增强生成)场景下,我们需要查询的不仅仅是一个电影节点,而是电影节点关联的导演、演员、类型等复杂结构,并将其聚合成一个嵌套的 Map 结构
- 当 SDN 遇到
RETURN { ... } AS context这种返回嵌套 Map 的查询时,它会尝试将这个 Map 强行转换成它内部用于处理实体映射的特定对象 - 所以我们直接使用了 Neo4j Java Driver 原生的
Driver和Session来执行 Cypher 查询,不经过 Spring Data 的 Repository 层,获取到数据后手动包装
GraphRAG 服务
理解了 Vector Search(向量检索)和 Graph
Search(图检索)这两个独立模块后,我们现在要进入整个项目的灵魂所在GraphRagService。这是
Neo4j 结合 LLM 最具价值的体现。
GraphRagService 的核心职责是协调 Vector
Search和 Graph Search,为 LLM
提供最完美的上下文。
1 |
|
- 整个工作流可以清晰地划分为三个阶段
- 向量检索
- 调用
vectorSearchService.semanticSearch,这样就能用自然语言问题在向量索引中快速匹配出最相似的 Top-K 部电影。粗筛。不求精准,但求范围正确。
- 调用
- 图扩展
- 遍历上一步找到的电影 ID,调用
graphSearchService.findMovieContextByElementId。利用 Neo4j 的图遍历能力,沿着关系边抓取其周围的结构化信息。这样的上下文就更丰富
- 遍历上一步找到的电影 ID,调用
- LLM 生成
- 将图扩展得到的结构化数据拼接成 Prompt,发送给 LLM,LLM 阅读这些精准的上下文,结合其自身的语言能力,生成自然、流畅且基于事实的回答。
- 向量检索
LLM
的知识是静态的(截止到训练日期),且容易产生幻觉,一本正经地胡说八道,GraphRagService
通过一种混合检索的策略,通过向量检索,图扩展,完美地弥补了
LLM 的短板
- 向量检索确保了系统能理解用户的语义(“烧脑”、“梦境”)。
- 图扩展确保了回答的事实依据(“这部电影确实是诺兰导演的”)。
- LLM 只需专注于如何把事实说得更好
这样,Neo4j 的加成下,LLM如何获得的推理能力就一目了然了
测试
现在就是激情澎湃的测试环节了,先来创建初始数据
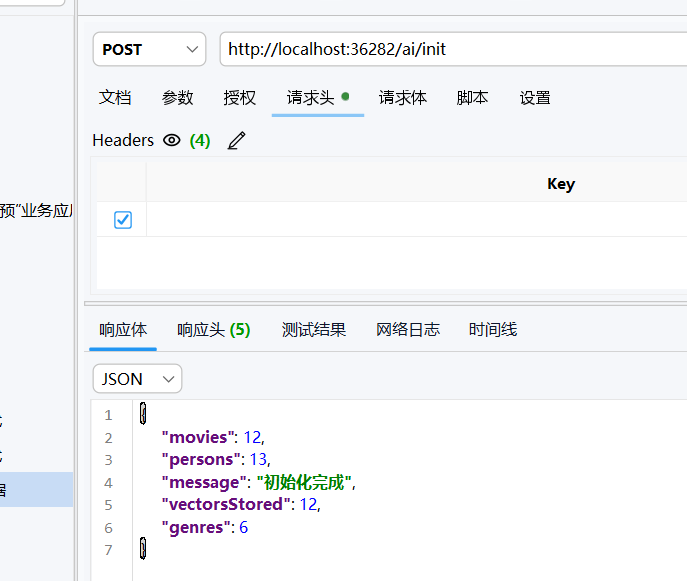
可以看到现在数据库中出现了我们需要的测试内容,示例数据,向量等内容
现在,测试纯向量检索,我们使用模糊的语义来测试,这个向量检索只会返回语义检索中最相近的内容,我们 top 设置为3,查询信息就描述The Matrix这部电影的基本特性,但是我们没有直接提到The Matrix这个词
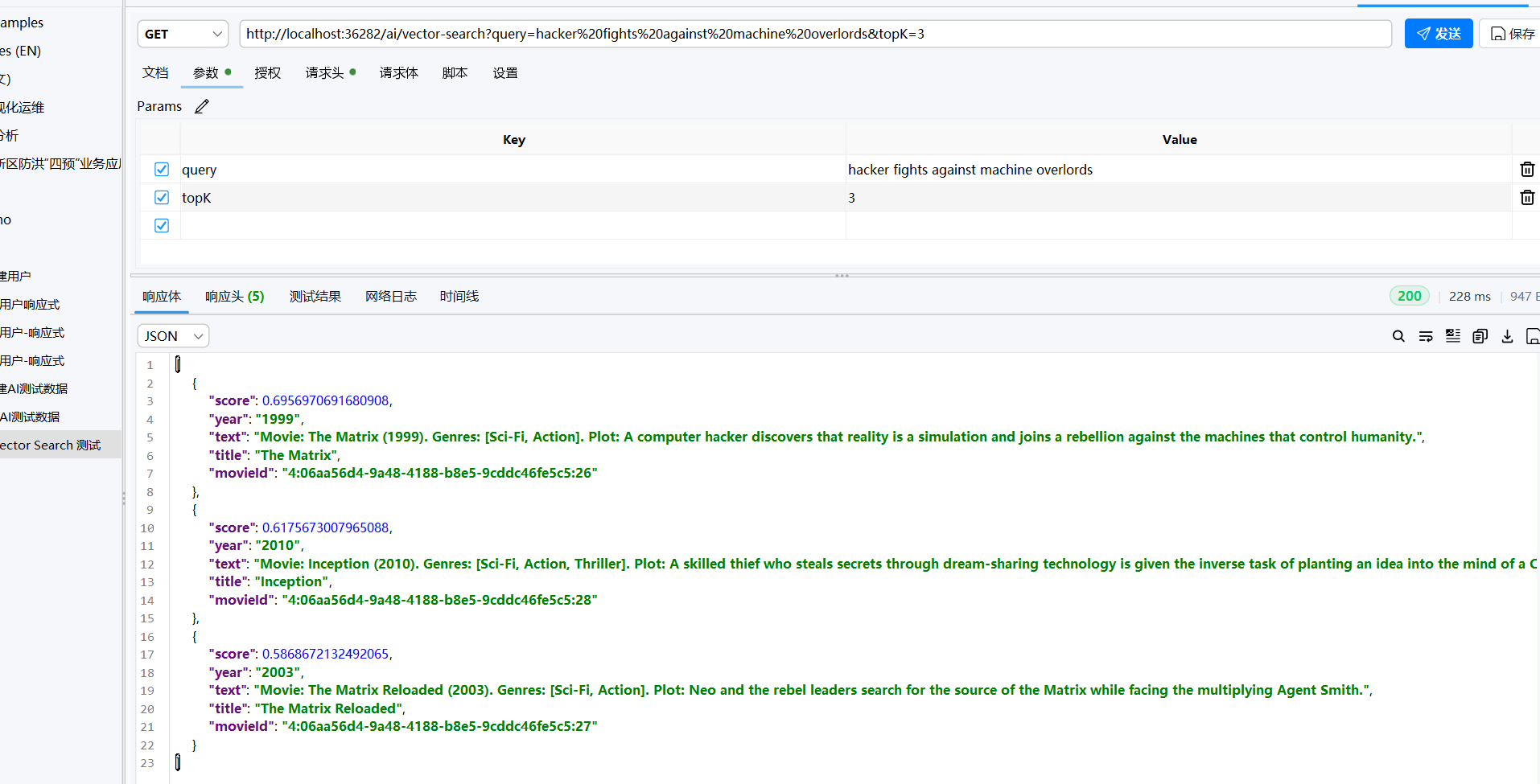
- 很明显,AI 通过了向量搜索,找到了我们最需要的内容
接下来使用纯 Vector Search 测试意境化查询的效果,
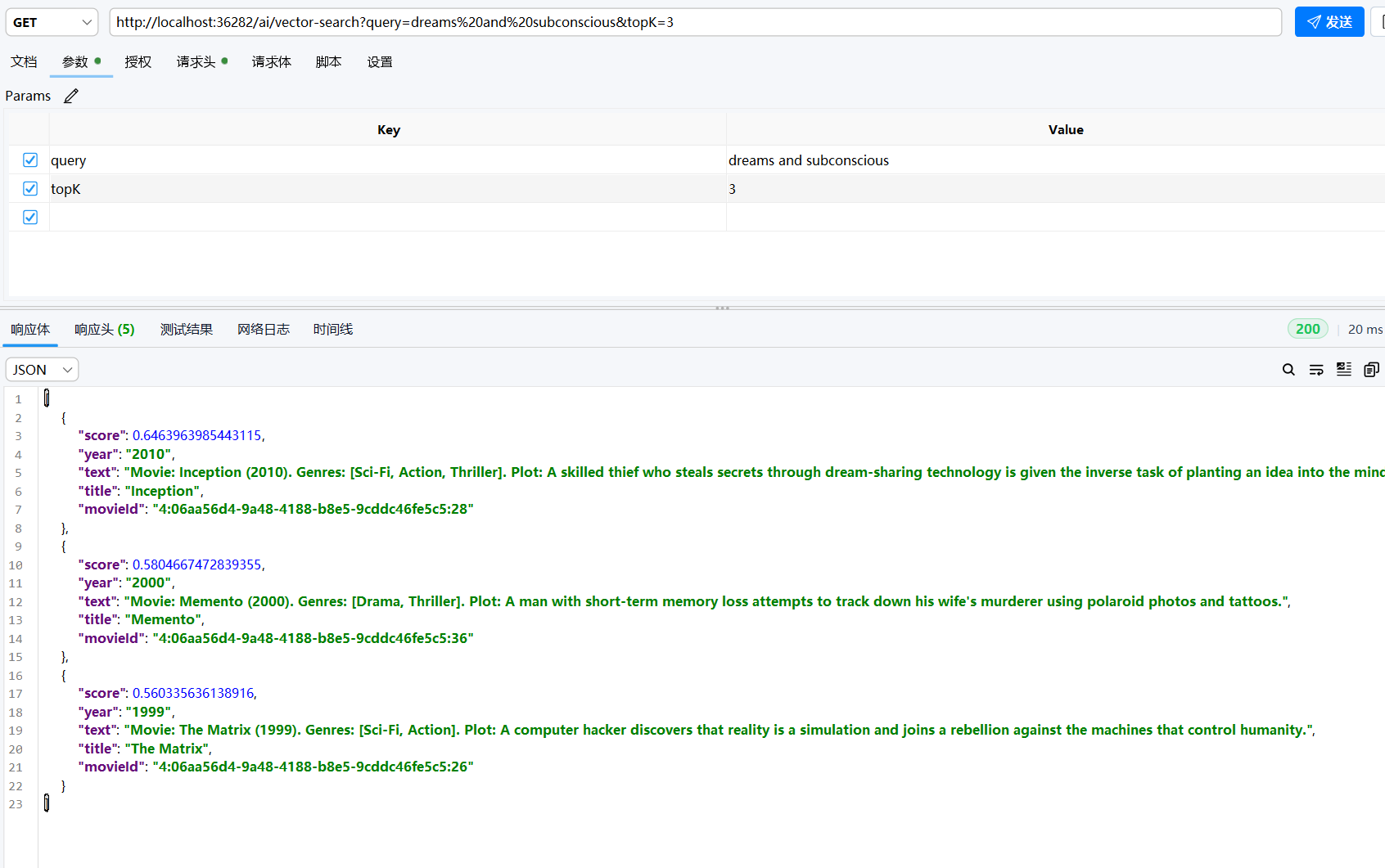
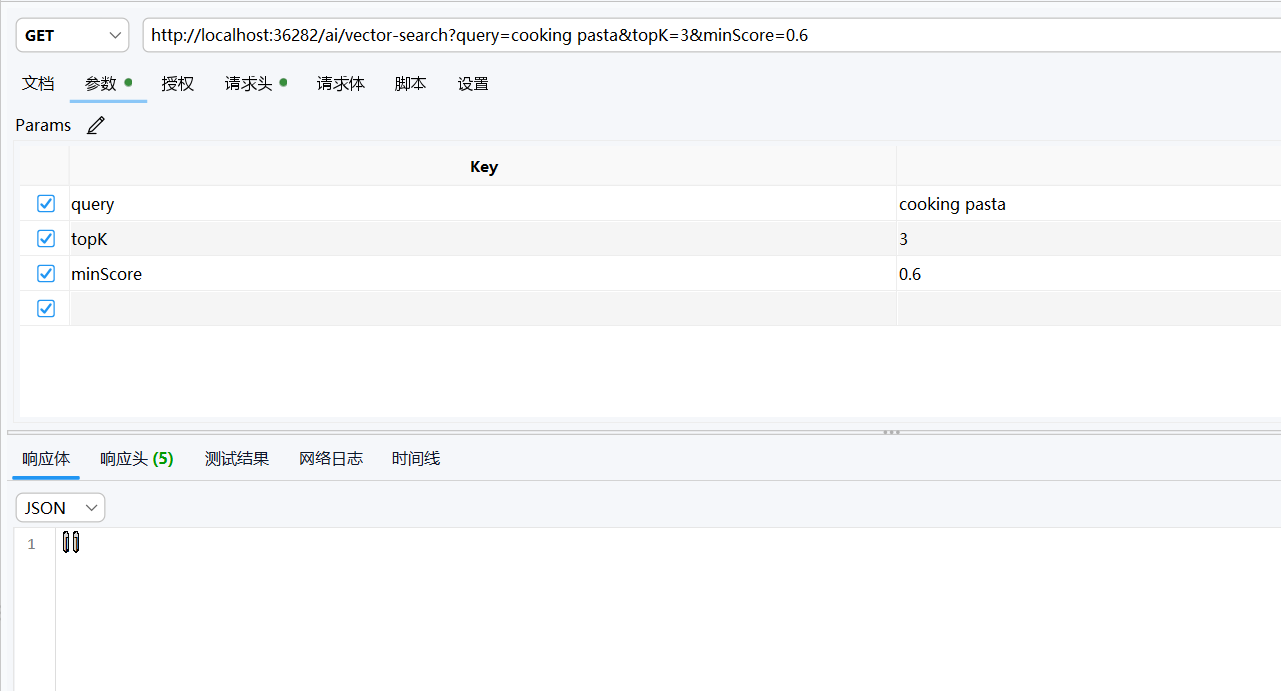
可以看到,在一个偏离描述的情况下,AI没有给出一个最低匹配得分为0.6的内容,这也说明了我们的AI在 Embeding 层没有产生幻觉,为了给出答案而强行给出一个答案
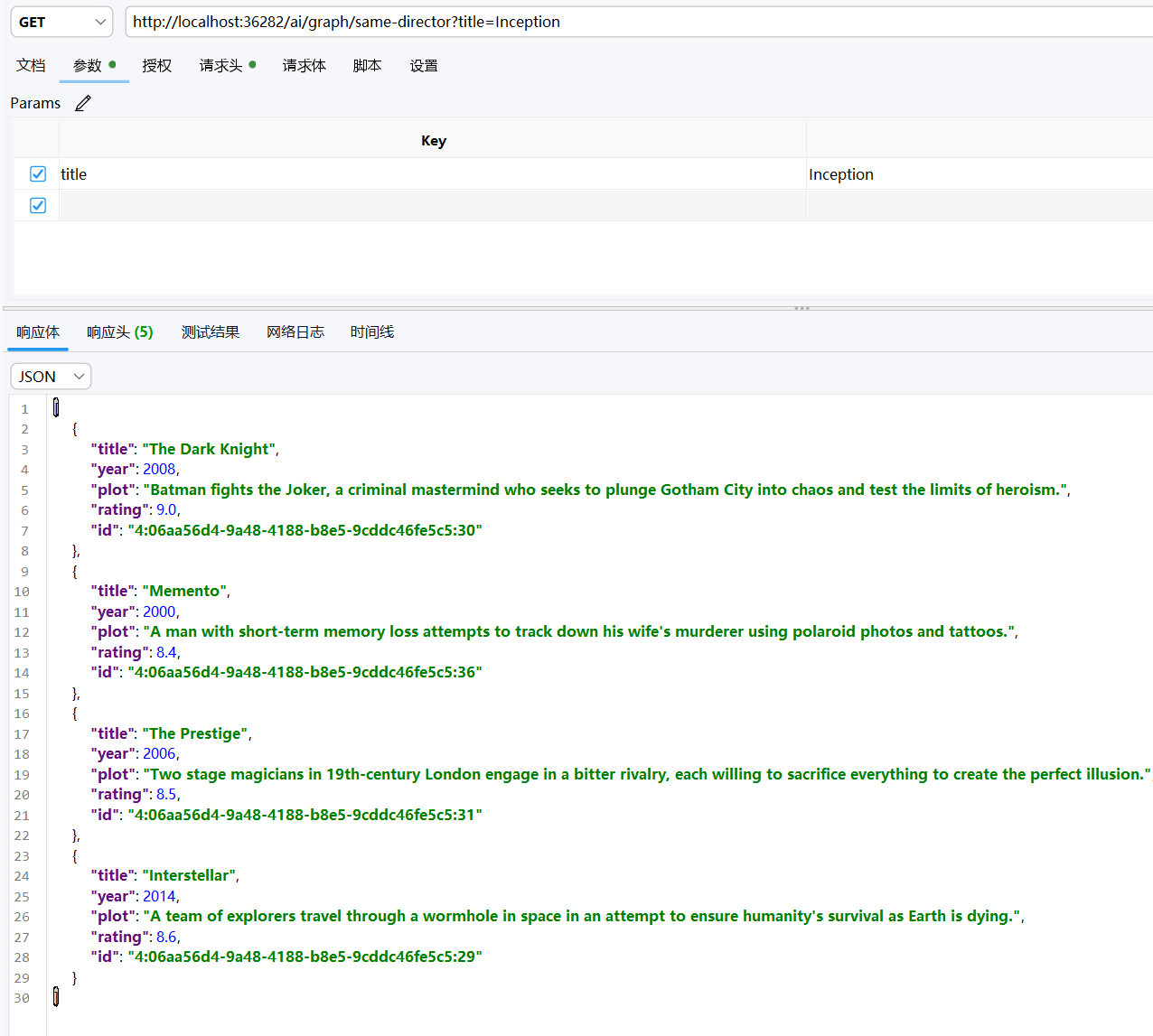
接着,测试一下纯 Graph Search 的情况,这个就和我们之前学习的 Neo4j 的基本查询比较相近,因为这个没有涉及到太多的AI内容,是对 Cypher 多跳遍历的测试,测试 Neo4j 的支撑合理性,我们尝试查询同导演电影,很明显发现,Neo4j 正确的精准的为 AI 提供了可追溯的数据支持
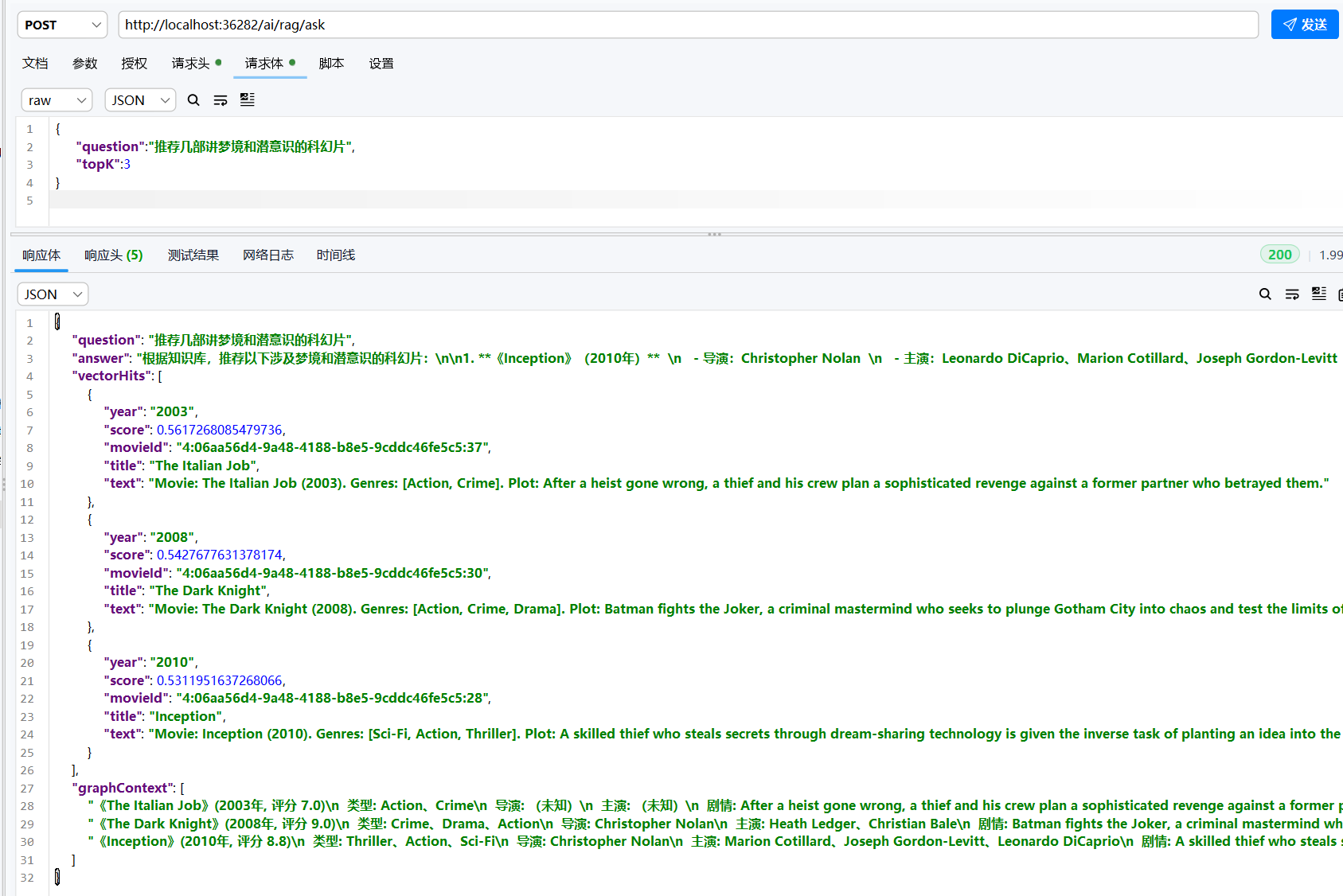
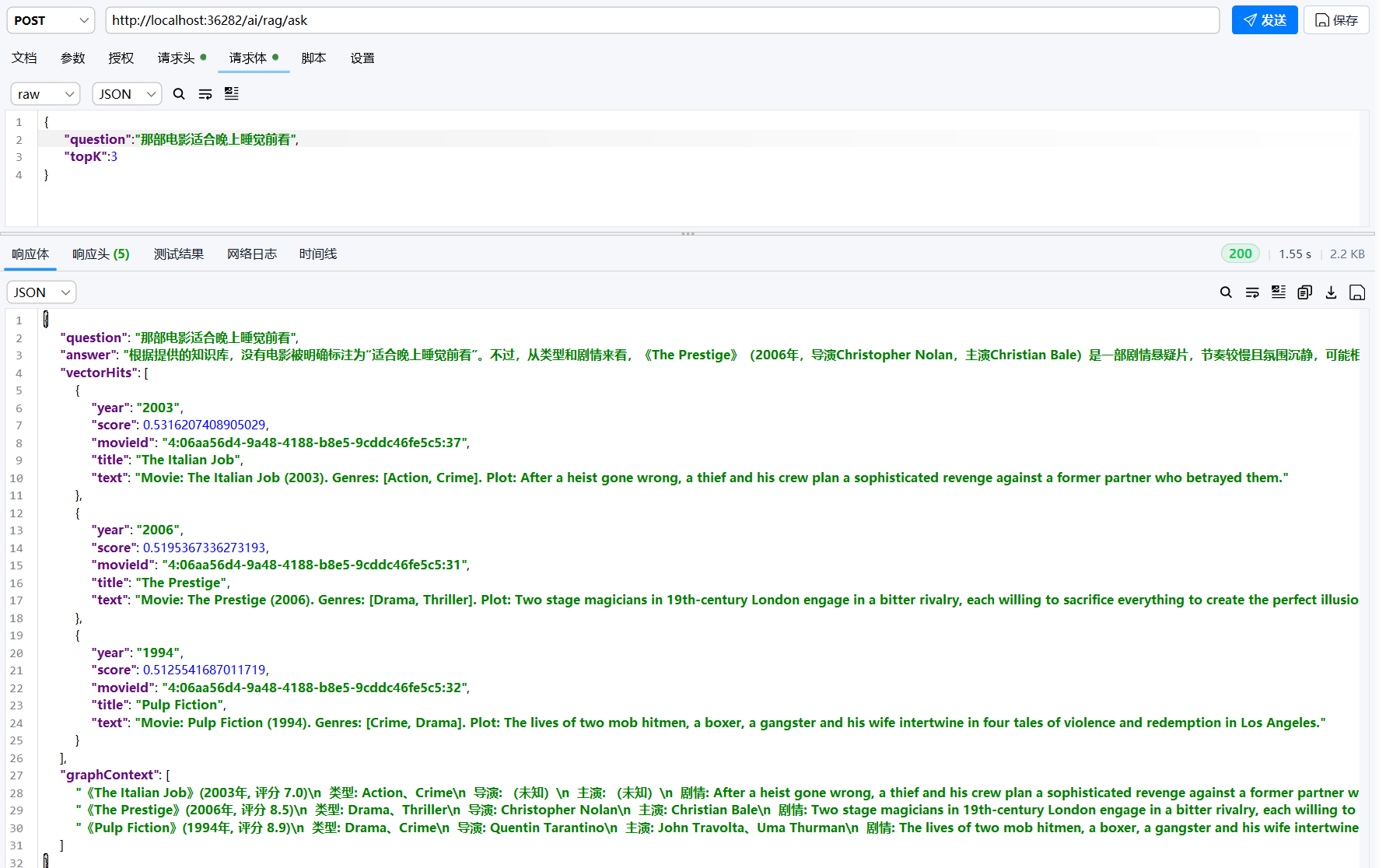
最后,我们测试一下项目最核心的功能,也是最复杂的一个,就是
GraphRAG,因为它演示了完整的 AI 工作流,提供了一个完整的 AI RAG
的基本内容,可以看到,graphContext
字段是从图里”扩展”出来的,包含了导演/演员,这些信息在原始电影简介里其实没有,是图扩展的功劳。
我们稍微调整一下问题,使得它具有更强的推理性,我们使用的是 deepseek v4,尽管在自建的 Neo4j 的简单 RAG 和 LangChain4j 本地的 Embeding 的情况下,但是效果还是非常好的
十分滴好用啊






