
了解 MyBatis
什么是 MyBatis
对于什么是 ORM,我就不说了
MyBatis 原来是 Apache 的一个开源项目,叫做 ibatis,2010年这个项目由 Apache 迁移到了 Google Code,并且改名为MyBatis,2013年11月官方代码迁移到GitHub
MyBatis 是一款半自动的 ORM 框架,核心定位是简化 JDBC 操作,同时兼顾 SQL 的灵活性。
如果你使用过 Hibernate,你就能理解什么是半自动 ORM 了,因为 Hibernate 是全自动 ORM,Hibernate 自动生成 SQL,开发者几乎无需写 SQL,映射方式是通过实体类注解全表映射,性能通过缓存调整,抓取策略,HQL优化等方式
MyBatis 作为一种半自动 ORM,它给了你对 SQL 的完全控制权,完全掌控 SQL 逻辑,而且是按需映射,支持字段与属性自定义映射,所以灵活性高一点,因为高程度的基于原生 SQL,学习成本也低一些,但代价是需要手动编写SQL语句
Hibernate 追求 完全屏蔽 SQL,用面向对象的方式操作数据库;这种是全自动 ORM
MyBatis 追求 简化 JDBC 繁琐操作,但开发者对 SQL 的控制权是完全的。而且比如分库分表、多表联查、存储过程调用这种很复杂的场景,MyBatis 比 Hibernate 更易实现一些。而且 MyBatis 核心包小,配置简单,无需像 Hibernate 那样配置复杂的缓存、级联关系。
所以说,MyBatis 避免的是几乎所有的 JDBC 代码和手动设置参数以及获取结果集的过程,减少了代码的冗余和程序员的配置操作。但是,开发者依旧需要自己使用 XML 或 注解 进行映射关系的配置,将接口和 Java 的 实体类映射成数据库中的记录,包括具体的 SQL 语句和逻辑的编写。
MyBatis 核心流程如下:
1 | 配置文件(数据源/SQL映射) → SqlSessionFactory → SqlSession → Mapper接口 → 执行SQL(自动封装结果) |
- MyBatis 帮你做了:连接池管理、SQL 参数拼接、结果集封装(自动转实体类)、资源关闭,开发的时候只需关注 写 SQL + 定义映射关系。
MyBatis中文文档:https://mybatis.net.cn/
仓库地址:https://github.com/mybatis/mybatis-3
认识 MyBatis 的性能
MyBatis 最核心的性能优势是开发者能自己掌控 SQL,这直接决定了数据库交互的性能上限,你牛逼它直接就牛逼:
- 可手动指定查询字段,可手写索引优化、分页)、联表、子查询等,Hibernate 自动生成的 SQL 往往有一些冗余,且复杂 SQL 需通过 HQL/Criteria 绕弯
- 而且 MyBatis 的半自动减少了很多多余的操作,比如批量插入,Hibernate
需配置
batch_size才能优化,而 MyBatis 可直接写INSERT INTO user (name, age) VALUES (?,?), (?,?), ...,减少网络交互次数。 - 比较关键的还有,MyBatis 核心 jar 包仅百 KB 级别,启动时无需加载复杂的元数据解析、缓存策略、级联关系等,启动速度远快于 Hibernate;
- 它没有别的其他内容的封装,MyBatis 本质是 JDBC 封装器,仅简化 JDBC 的繁琐操作,无额外的对象状态管理,开销低
- 缓存按需使用:MyBatis 一级缓存默认开启但轻量,二级缓存需手动配置,Hibernate 的缓存你搞不好就容易不一致
然后
MyBatis 会产生 Hibernate的那种 N+1 查询的问题吗?先说,会,但是不会自动产生
因为 MyBatis 是半自动的,所以说不会自动产生 N+1 查询问题,但如果使用不当,依然可能出现类似的性能问题
Hibernate 作为全自动 ORM,N+1 是其「自动关联查询」机制下的典型问题:
触发场景:查询主表(如
Order)时,默认采用「延迟加载」关联的子表(如OrderItem);执行过程:
- 1 次 SQL 查询所有
Order(1 次);- 遍历每个
Order时,触发延迟加载,为每个Order执行 1 次查询OrderItem的 SQL(N 次);- 最终产生
1 + N次查询。核心原因:Hibernate 替你自动管理关联关系,开发者容易忽略「延迟加载」的触发时机,导致无意识的 N+1。
MyBatis 是半自动 ORM,没有 自动关联加载 的机制,所有 SQL 都是你手动编写的,因此 N+1 只会在 开发者手动写了拆分的查询逻辑 时出现,常见场景有这样
业务代码中手动拆分查询
比如你要查询「所有订单 + 每个订单的订单项」,一定要注意,如果你自己代码逻辑写得不当,就会触发 N+1,例如典型的 for 循环中去做查询
1
2
3
4
5
6
7// 第一步:查询所有订单(1 次 SQL)
List<Order> orderList = orderMapper.selectAll();
// 第二步:遍历订单,逐个查询订单项(N 次 SQL)
for (Order order : orderList) {
List<OrderItem> itemList = orderItemMapper.selectByOrderId(order.getId());
order.setOrderItems(itemList);
}使用 MyBatis 的 关联查询标签 但配置不当
MyBatis 提供了
<association>(一对一)、<collection>(一对多)标签实现关联映射,若配置为「延迟加载」且使用不当,也会触发 N+1:1
2
3
4
5
6
7
8
9
10
11
12
13
14<!-- OrderMapper.xml 中配置:查询订单时,延迟加载订单项 -->
<resultMap id="OrderResultMap" type="Order">
<id column="id" property="id"/>
<result column="order_no" property="orderNo"/>
<!-- 配置延迟加载订单项 -->
<collection property="orderItems"
select="com.example.mapper.OrderItemMapper.selectByOrderId"
column="id" <!-- 将订单 id 传给 select 指定的方法 -->
fetchType="lazy"/> <!-- 延迟加载(默认) -->
</resultMap>
<select id="selectAll" resultMap="OrderResultMap">
SELECT id, order_no FROM `order`
</select>这本质上回到了 Hibernate 造成 N+1 查询的问题
MyBatis 解决 N+1 的思路很直接,用「一次联表查询」替代「1+N 次拆分查询」,因为你能完全掌控 SQL,所以方案更灵活
直接在 SQL 中通过
JOIN关联主表和子表,一次性查询所有数据,再通过resultMap封装成嵌套对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<!-- OrderMapper.xml -->
<resultMap id="OrderWithItemsResultMap" type="Order">
<id column="order_id" property="id"/>
<result column="order_no" property="orderNo"/>
<!-- 封装订单项列表 -->
<collection property="orderItems" ofType="OrderItem">
<id column="item_id" property="id"/>
<result column="product_name" property="productName"/>
<result column="quantity" property="quantity"/>
</collection>
</resultMap>
<select id="selectAllWithItems" resultMap="OrderWithItemsResultMap">
SELECT
o.id AS order_id, o.order_no,
oi.id AS item_id, oi.product_name, oi.quantity
FROM `order` o
LEFT JOIN order_item oi ON o.id = oi.order_id
</select>完全由你掌控 SQL,可按需调整
JOIN类型(INNER/LEFT)、筛选字段,比 Hibernate 的fetch = FetchType.EAGER更灵活,Hibernate 自动生成的联表 SQL 可能冗余。批量查询
如果联表 SQL 过于复杂,比如多表关联、大量筛选条件,可先批量查询主表 ID,再用
IN条件一次性查询子表数据,将 N+1 优化为1+1:1
2
3
4
5
6
7
8
9<!-- OrderItemMapper.xml -->
<select id="selectByOrderIds" resultType="OrderItem">
SELECT id, order_id, product_name, quantity
FROM order_item
WHERE order_id IN
<foreach collection="list" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</select>1
2
3
4
5
6
7
8
9
10
11// 第一步:查询所有订单(1 次)
List<Order> orderList = orderMapper.selectAll();
// 第二步:提取所有订单 ID,批量查询订单项(1 次)
List<Long> orderIds = orderList.stream().map(Order::getId).collect(Collectors.toList());
Map<Long, List<OrderItem>> itemMap = orderItemMapper.selectByOrderIds(orderIds)
.stream()
.collect(Collectors.groupingBy(OrderItem::getOrderId));
// 第三步:手动封装关联关系
for (Order order : orderList) {
order.setOrderItems(itemMap.getOrDefault(order.getId(), Collections.emptyList()));
}
为什么国内很多平台开发都使用的是 MyBatis
灵活性高
面对变化快、场景复杂、并发和性能要求高的业务,MyBatis 就相对适合一些
- 业务迭代快:如果需求频繁变更,如新增字段、调整查询条件,MyBatis 只需修改 XML 中的 SQL,无需改动实体类 / 逻辑代码,迭代效率远高于 Hibernate
- 复杂查询多:业务常涉及多表联查、动态条件、分库分表,MyBatis 的动态 SQL 可灵活拼接 SQL,Hibernate 的 Criteria API 绝对也不差,但是它确实不够灵活
- 性能敏感:MyBatis 这种半自动的 ORM,能够把 SQL 完全交给开发者来控制,MyBatis 能够更满足需求一些,Hibernate 自动生成的 SQL 可能低效,还容易自己就 N+1 了
- 排查问题简单:生产环境出现 SQL 性能问题时,可直接复制 MyBatis 中的 SQL 到数据库客户端执行、分析、优化,而 Hibernate 就没这么简单了
MyBatis 是对数据库的具体实现屏蔽吗?
MyBatis 并非像 Hibernate 那样 能够通过 Spring Data JPA 的帮助下,能够屏蔽数据库的具体实现,只用编写和简单的注解调整就能实现更换底层数据库的具体实现,但是它提供了适配多数据库的能力,只是实现方式和 Hibernate 截然不同
首先,Hibernate/JPA是完全屏蔽 SQL 和数据库方言,只操作对象,所以才能达到对下层实现屏蔽的能力
而 MyBatis 是不屏蔽 SQL,屏蔽的是 底层 JDBC 交互,SQL 依旧需要手动适配
Hibernate 的多库切换核心逻辑靠 方言配置 + 注解兼容,无需改 SQL,因为都是 HQL
配置文件指定
hibernate.dialect=org.hibernate.dialect.MySQLDialect或PostgreSQLDialect,这种就能实现更换底层数据库的具体实现,,框架自动将 对象操作 翻译成对应数据库的 SQL,比如 MySQL 的LIMIT→ PostgreSQL 的LIMIT、Oracle 的ROWNUM而 JPA 注解大部分都是跨数据库的,像主键生成策略这种可能需要进行调整,例如MySQL 用
IDENTITY,PostgreSQL 用SEQUENCE
而 MyBatis 中的 xml 映射配置,你写了很多的 SQL,所以一旦换库,需要根据具体的 DBMX 对 SQL 的实现做出相关的调整,所以说切换成本可能高一些
搭建第一个 MyBatis Demo 来上手体验
搭建项目
构建一个用户管理系统,来理解 MyBatis,使用 Spring Boot,大致的项目结构就这样
然后建库建表
1 | CREATE TABLE users ( |
导入依赖
要使用 MyBatis, 只需将mybatis-x.x.x.jar 文件置于类路径(classpath)中即可。
如果使用 Maven 来构建项目,则需将下面的依赖代码置于 pom.xml 文件中,这是单独的 Maven 工程下引入 MyBatis
1 | <dependencies> |
那么 Spring Boot 就是引入对应的 starter 就可以
1 | <!-- Spring Boot 数据源自动配置 --> |
编写配置文件
这个也是,需要数据库自己的连接配置,还要 MyBatis配置,常用的 MyBatis 配置基本就是这些
1 | spring: |
然后需要调整对应的启动类,添加@MapperScan,扫描Mapper接口包,替代每个接口加@Mapper
1 | /** |
实体类
随便填几个字段,跟数据库那边能对应上就可以
1 |
|
编写 Mapper 接口
如果启动类加了@MapperScan,Mapper
接口上的@Mapper注解可省略
1 | // @Mapper注解(如果启动类加了@MapperScan,此注解可省略) |
要注意,同样是编写持久层的接口,MyBatis 和 Hibernate 有很多不一样的地方
- 命名习惯:
- 一般情况下,使用 MyBatis 的持久层命名就是
xxxMapper - 使用 Hibernate
的持久层命名就是
xxxRepository,这是约定的
- 一般情况下,使用 MyBatis 的持久层命名就是
- 接口设计逻辑:
- MyBatis 的持久层 mapper,可以完全自定义方法签名,接口无需继承任何父接口。
- 而 Hibernate 为了遵循 JPA 规范,在必须继承
JpaRepository/CrudRepository等通用接口的情况下,需要靠 “方法名语义解析” 生成 SQL,所以方法名都是需要遵循约定的那种规则来命名
- SQL 控制权:
- MyBatis 中,因为你完全掌控 SQL,所以你的
xxxMapper只是空的接口,真正的数据库操作逻辑在xxxMapper.xml中 - 而 Hibernate 对开发者屏蔽
SQL,由框架自动生成,
xxxRepository中的接口只要正确编写,直接就能在需要的地方直接调用,不用写其他内容
- MyBatis 中,因为你完全掌控 SQL,所以你的
- 参数 和 结果处理:
- MyBatis 中参数或结果映射可手动控制,就好像单参数直接用
#{id}绑定,多参数必须加@Param注解。而MyBatis 的结过处理,通过<resultMap id="UserResultMap">显式映射数据库列到实体属性,返回值类型完全由你指定,框架严格按返回值类型封装结果。 - Hibernate
中全自动映射,无需手动干预,通用方法直接传对象或主键即可,自定义方法按方法参数顺序自动绑定,无需
@Param。而 Hibernate 结果处理靠实体类注解(@Entity/@Table/@Column)实现 列→属性 映射,框架自动把查询结果封装为对应对象,无需手动定义 结果映射。
- MyBatis 中参数或结果映射可手动控制,就好像单参数直接用
- 多条件动态查询的编写:
- MyBatis 在配置文件中通过 SQL+XML 的方式,就比较灵活
- 而 Hibernate
动态条件需用
Specification,也不能说灵活性差,就是比较难写而且很长,性能也差一些
编写 Mapper 的 xml 映射文件
重头戏,MyBatis 能够进行持久化的核心逻辑就是这个 XML,其中持久化的逻辑需要在其中有所体现,因为 Mapper 只是个空接口
其中
- XML 文件名建议和 Mapper 接口名一致,便于维护
id属性中,SQL 标签的id必须和接口方法名完全一致,而且大小写敏感namespace必须和接口全类名一致。
1 |
|
正是学习如何编写 Mapper 的 xml 映射文件前,讲解一下这个配置文件,有一定了解
首先,一个完整的 MyBatis Mapper XML 遵循固定结构
1 |
|
对于结果映射
<resultMap>,它负责数据库与实体的对应1
2
3
4
5
6<resultMap id="UserResultMap" type="hbnu.project.mybatisdemo.entity.User">
<id column="id" property="id"/> <!-- 主键映射 -->
<result column="name" property="name"/> <!-- 普通列映射 -->
<result column="email" property="email"/>
<result column="age" property="age"/>
</resultMap>定义数据库表的列名(
column)和 Java 实体类的属性名(property)的映射关系;其中属性:
id:当前 resultMap 的唯一标识,后续 SQL 标签用resultMap="UserResultMap"引用;type:映射的目标实体类,可写全类名,或利用type-aliases-package配置写别名User;<id>:主键列映射;<result>:普通列映射;
何时可以省略:如果数据库列名和实体属性名完全一致(或开启了
map-underscore-to-camel-case驼峰转换),可以直接用resultType="User"替代resultMap1
2
3<select id="findUserById" parameterType="int" resultType="User">
SELECT id, name, email, age FROM users WHERE id = #{id}
</select>SQL 操作标签
入库标签
<insert>1
2
3
4<insert id="insertUser" parameterType="hbnu.project.mybatisdemo.entity.User" useGeneratedKeys="true" keyProperty="id">
INSERT INTO users (name, email, age)
VALUES (#{name}, #{email}, #{age})
</insert>其中属性:
id:必须和 Mapper 接口中对应的方法名一致(insertUser),MyBatis 靠这个绑定 Mapper 接口中的方法;parameterType:入参类型(实体类全类名 / 别名,可省略,MyBatis 会自动推断);useGeneratedKeys="true":开启自增主键回填(针对 MySQL 的AUTO_INCREMENT);keyProperty="id":将数据库生成的主键值,回填到入参User对象的id属性中(执行后user.getId()能拿到自增 ID);
参数绑定:
#{name}对应User对象的getName()方法,MyBatis 会自动获取属性值,且预编译防 SQL 注入;所以说不要用${name},它是直接字符串拼接,有 SQL 注入风险,仅在动态表名 / 列名时使用。删除标签
<delete>没啥多说的,参数也一样
1
2
3<delete id="deleteUserById" parameterType="int">
DELETE FROM users WHERE id = #{id}
</delete>修改标签
<update>
1
2
3
4
5
6
7
8
9<update id="updateUser" parameterType="hbnu.project.mybatisdemo.entity.User">
UPDATE users
<set>
<if test="name != null">name = #{name},</if>
<if test="email != null">email = #{email},</if>
<if test="age != null">age = #{age},</if>
</set>
WHERE id = #{id}
</update><set>+<if>实现动态更新,是只更新非空字段,因为<set>:自动去掉最后一个字段后的逗号,比如只改name时,不会出现name = ?,这种语法错误;<if test="条件">:条件为 true 时才拼接该字段的更新语句
最后的
WHERE id = #{id}千万不能漏,剩下的参数也差不多查询标签
<select>单条查询和前面的差不多,只不过
resultMap是引用前面定义的UserResultMap它没有返回值属性,MyBatis 自动根据接口方法的返回值(
User)封装结果1
2
3
4
5<select id="findUserById" parameterType="int" resultMap="UserResultMap">
SELECT id, name, email, age
FROM users
WHERE id = #{id}
</select>动态查询后面讲
编写服务层
包括编写服务层接口和服务层的实现类
接口没啥好多说的,按照需要直接编写就可以
1 | public interface UserService { |
然后,按照 Spring Boot 框架那种编写服务层实现类的形式,编写实现类
1 |
|
编写控制器层
最后写个控制器用于测试
1 |
|
测试
增
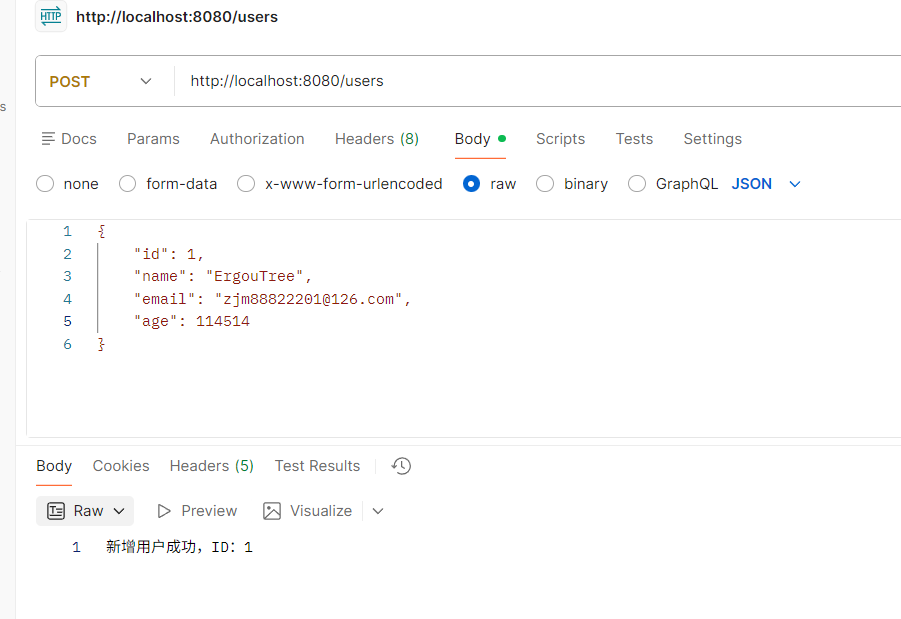
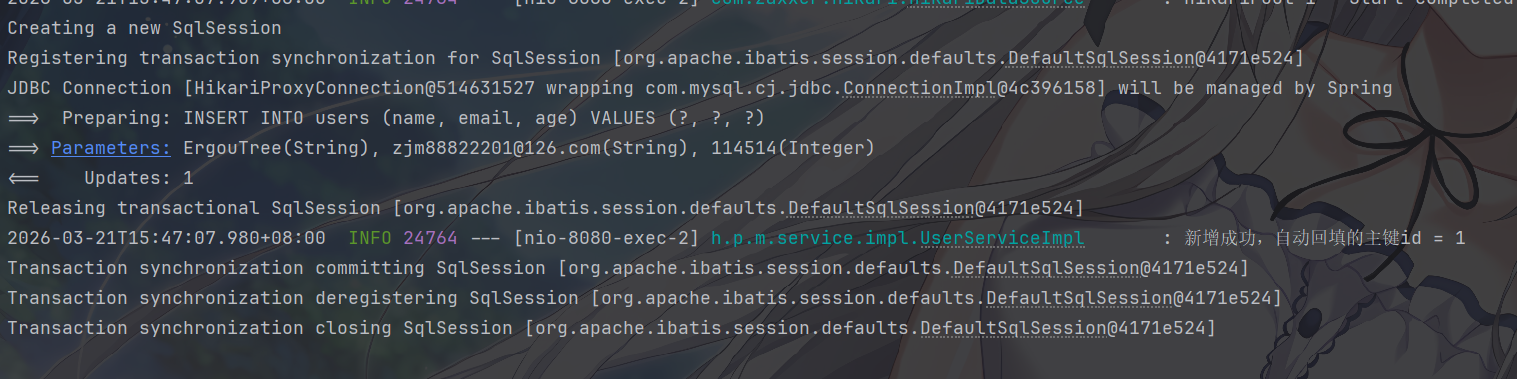
可以在控制台看到 MyBatis 与 MySQL 的数据交互
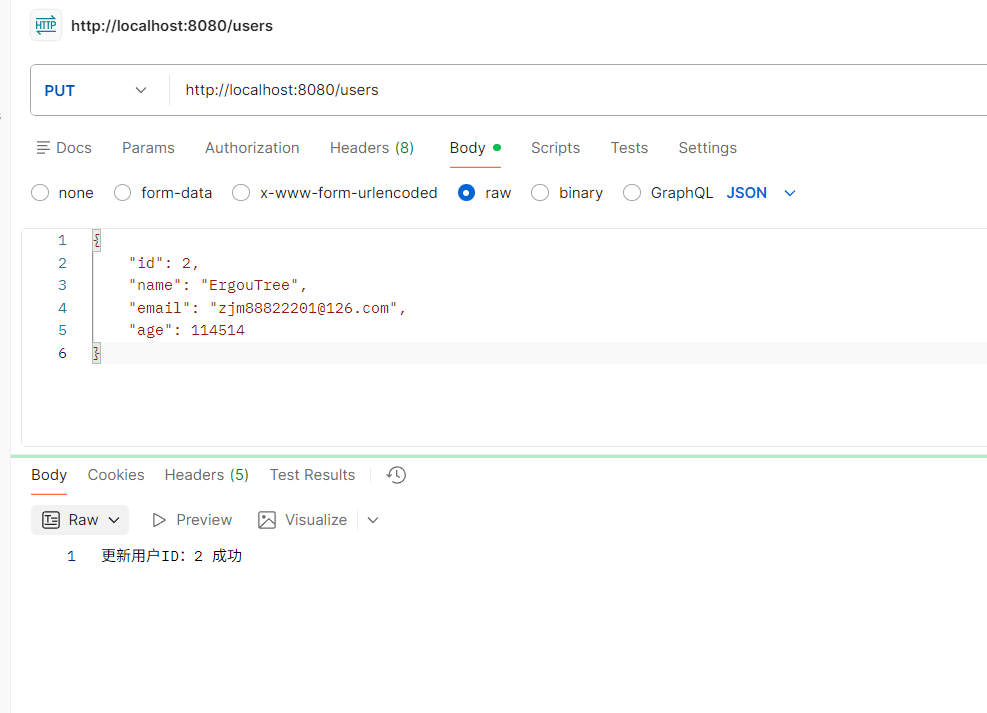
改
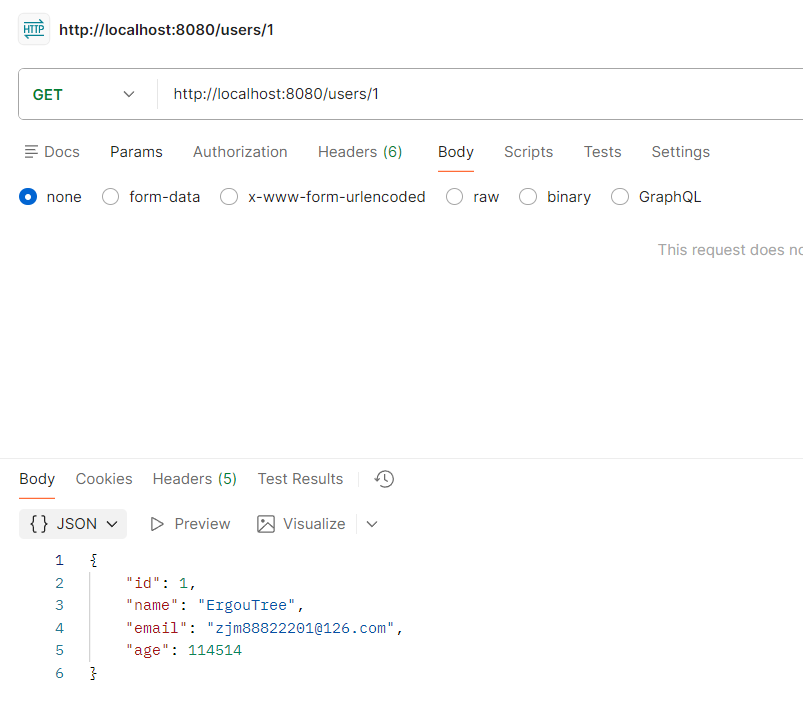
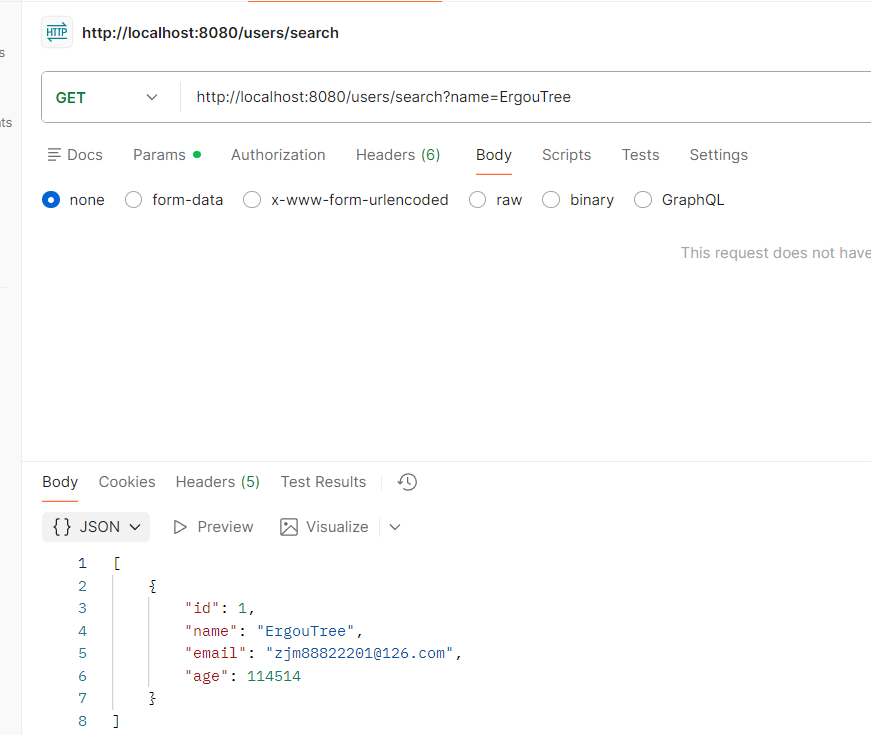
查
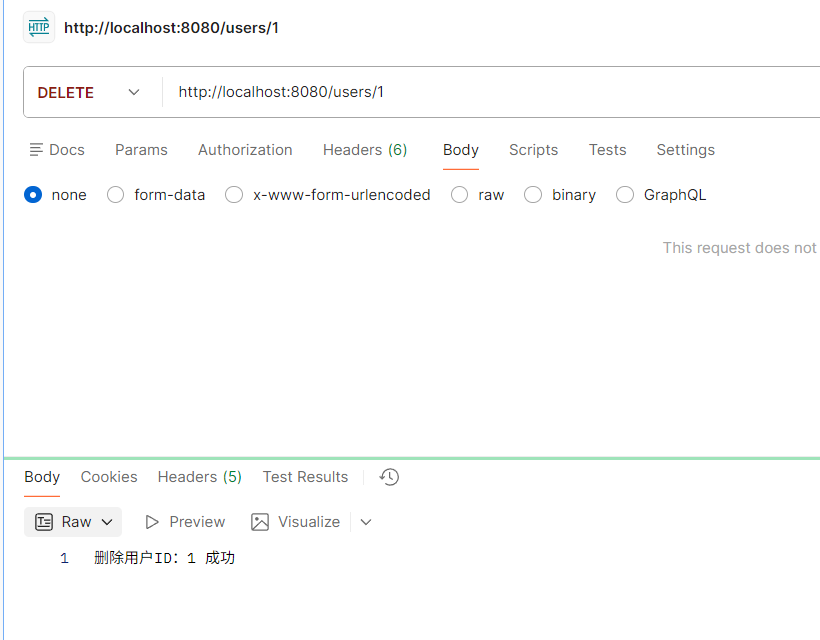
删
至此,一个可用的 Spring Boot 加 MyBatis 的工程就完成了





