
重新认识Dubbo
Dubbo 最初被定位为一个高性能的 RPC 框架,但这是过去,随着 Dubbo 3 的演进(尤其是与 Spring Cloud Alibaba 的整合),这个定义已远远不足以描述它的全貌。
因为,它已经具备了完整的 微服务治理能力,包括服务注册发现、配置中心、熔断限流、可观测性等,是一个面向云原生、支持多语言、具备完整微服务治理能力的一站式微服务解决方案。
什么意思,Dubbo 不是只有那几个注解来作为 RPC 框架的能力了,而是可以作为 Spring Cloud Alibaba 中的单独一个框架,自己实现服务注册发现、配置中心、熔断限流、可观测性等这些微服务框架需要的功能。
所以说,Dubbo 3 不再只是调用远程方法,而是构建和运维整个微服务体系的基础设施。
服务治理、服务通信。这是dubbo框架所提供的核心功能。实际上也是微服务框架所要提供的核心功能。
Dubbo 与 Spring Cloud 对比
而且Dubbo开发相较于 Spring Cloud 具有一些优势
- Dubbo 开箱即用,相对于 Spring Cloud 要易用一些
- Dubbo 功能丰富,基于原生库或轻量扩展即可实现绝大多数的微服务治理能力
- Dubbo 是面向超大规模微服务集群设计的,拥有高性能的 RPC 通信协议设计与实现,而且轻松支持百万规模集群实例的地址发现与流量治理
- Dubbo 对扩展支持性好
Dubbo 虽然可以独立使用,但在 Spring Cloud 生态中,推荐搭配 Spring Cloud Alibaba
一些需要认识的内容
云原生
首先,云原生没有确切的定义,云原生一直在发展变化之中,解释权不归某个人或组织所有。
首先,云原生借了云计算的东风,没有云计算,自然没有云原生,云计算是云原生的基础。
随着虚拟化技术的成熟和分布式框架的普及,在容器技术、可持续交付、编排系统等开源社区的推动下,以及微服务等开发理念的带动下,应用上云已经是不可逆转的趋势。
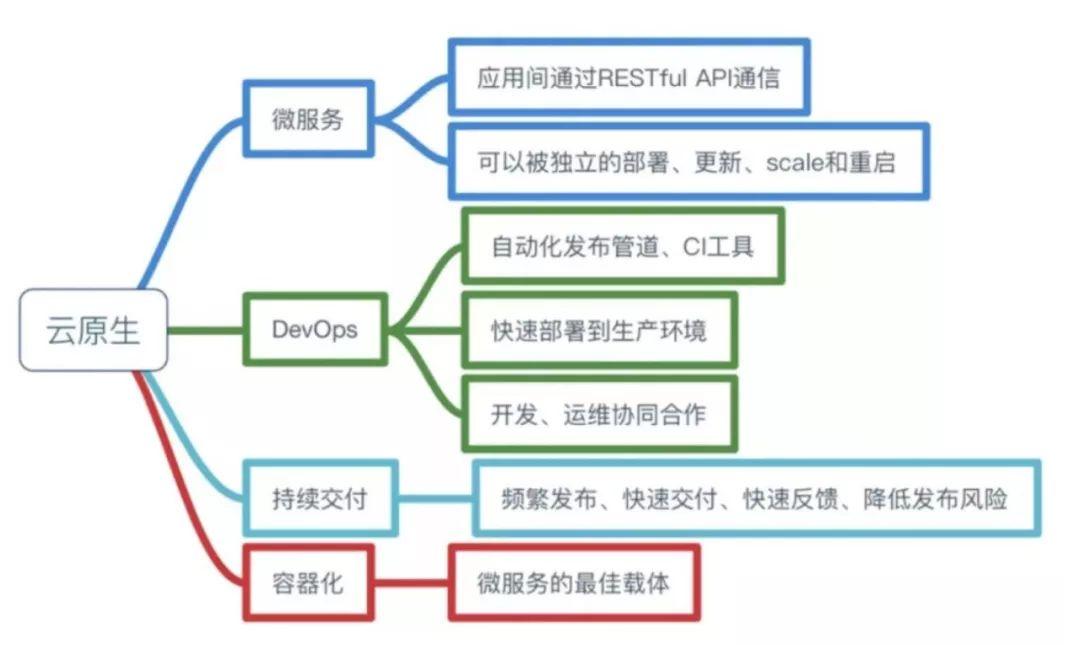
要转向云原生应用需要以新的云原生方法开展工作,云原生包括很多方面:基础架构服务、虚拟化、容器化、容器编排、微服务。
所以,云原生(CloudNative)是一个组合词,Cloud+Native。
- Cloud表示应用程序位于云中,而不是传统的数据中心;
- Native表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。
Pivotal 最新官网对云原生概括为4个要点:DevOps + 持续交付 + 微服务 + 容器
- DevOps:这是个组合词,Dev+Ops,就是开发和运维合体,实际上DevOps应该还包括测试,DevOps 是一个敏捷思维,是一个沟通文化,也是组织形式,为云原生提供持续交付能力。
- 持续交付:持续交付是不误时开发,不停机更新,小步快跑,反传统瀑布式开发模型,这要求开发版本和稳定版本并存,其实需要很多流程和工具支撑。
- 容器化:Docker是应用最为广泛的容器引擎,在思科谷歌等公司的基础设施中大量使用,是基于LXC技术搞的,容器化为微服务提供实施保障,起到应用隔离作用,K8S是容器编排系统,用于容器管理,容器间的负载均衡,谷歌搞的,Docker和K8S都采用Go编写,都是好东西。
- 微服务:看到这里的应该都懂微服务了吧
结果后来 云原生计算基金会成立又来搅和一把,现在已经很复杂了
总而言之,符合云原生架构的应用程序应该是:采用开源堆栈(K8S,Docker)进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。
如果说PC时代的基础设施是控件库,互联网时代的基础实施是云,那AI时代基础设施是什么?又会有什么高端玩法?只能说什么时候有什么时候的花样了。
Triple 协议
这是 Dubbo 嘴里一直在说的下一代协议
在以前 Dubbo 2.x 的时候,Dubbo 使用的是Dubbo 协议,这是一个私有二进制协议,但是现在 Dubbo 3.x 使用的是Triple 协议,它基于 HTTP/2 + gRPC,兼容原生 gRPC,支持流式通信,而且也增加了 Dubbo 特有的治理字段
从 Triple 协议开始,Dubbo 才支持基于 IDL 的服务定义。此外,Dubbo 还集成了业界主流的大部分协议
那么,它就有一些核心的优势了
- 网关友好:可直接被 Envoy、Spring Cloud Gateway 代理,传统 Dubbo 协议不行
- 多语言天然支持:使用
.proto定义服务,Java/Go/Python 共享同一份 IDL 来生成代码 - 流式通信:支持 Request Stream、Response Stream、Bidirectional Stream
emmm,之前在说 RPC 的时候就说过 Dubbo 是如何跨语言的,它通过 IDL(.proto)实现跨语言互通,通过 Protobuf 定义服务接口,然后去生成多语言客户端 / 服务端的代码
金丝雀发布
首先,Dubbo 3 将过去分散的路由、限流、降级等规则,抽象为一套流量和服务治理规则,无论你使用:
- 纯 SDK 模式
- Sidecar Mesh
- Proxyless Mesh
都能用同一套 YAML 规则进行管理 ,那么此时,我们就可以进行测试,这个在 Dubbo 那边叫了个词叫 金丝雀发布
那么 金丝雀发布 就是一种软件发布策略,旨在在将新版本全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证。这种策略的名称来源于矿工在矿井中使用金丝雀来检测有毒气体的做法。
新代码或更新逐渐部署到少量用户或服务器,以降低潜在风险
测试新版本的性能和表现,在保证系统整体稳定运行的前提下,尽早发现新版本在实际环境上的问题。
RPC vs REST
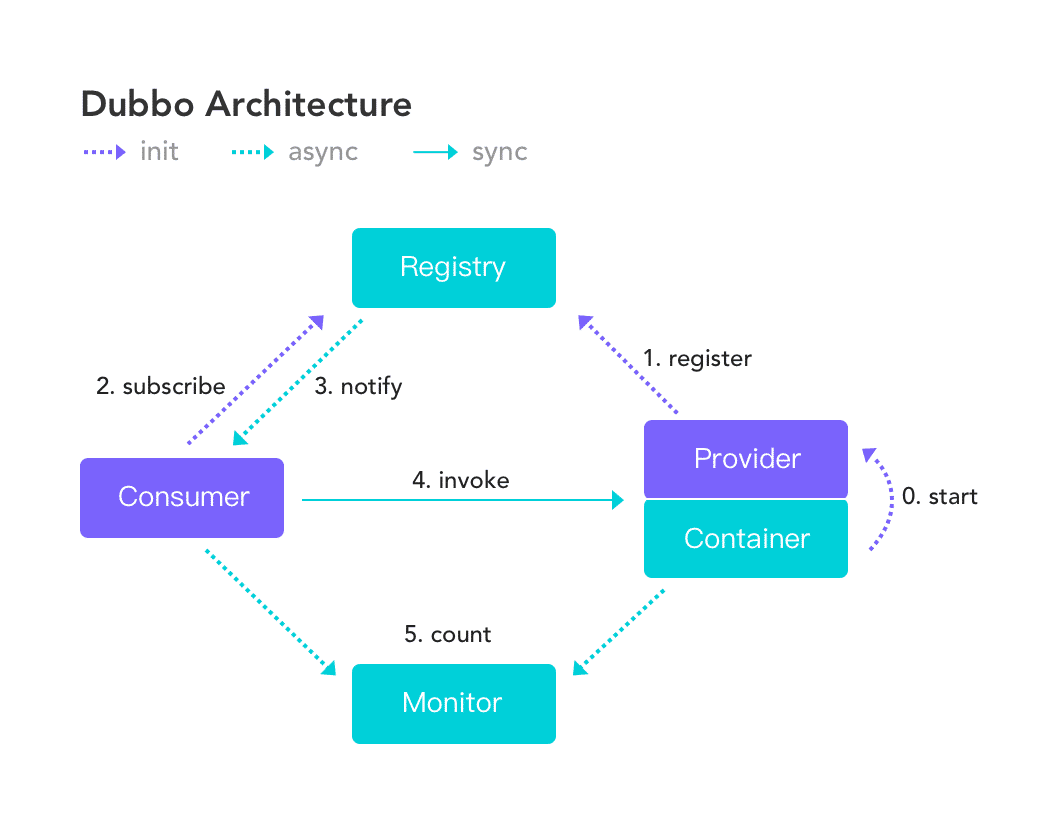
Dubbo 架构
首先,Dubbo 的架构如下
下面是它的源码架构
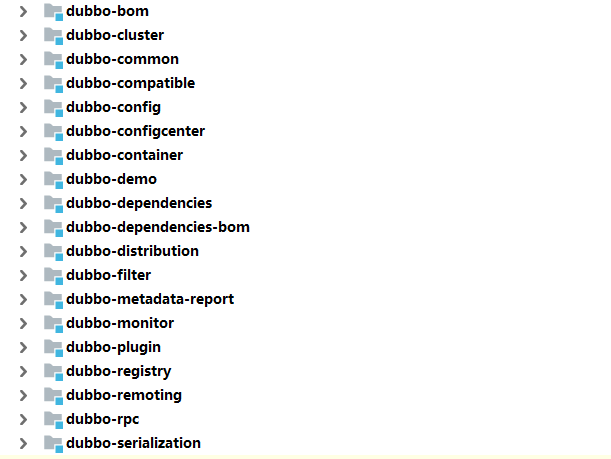
- dubbo-common:公共逻辑模块: 包括Util类和通用模型
- dubbo-remoting 远程通信模块: 相当于dubbo协议的实现,如果RPC使用RMI协议则不需要使用此包
- dubbo-rpc 远程调用模块: 抽象各种协议,以及动态代理,包含一对一的调用,不关心集群的原理。
- dubbo-cluster 集群模块: 将多个服务提供方伪装成一个提供方,包括负载均衡,容错,路由等,集群的地址列表可以是静态配置的,也可以是注册中心下发的.
- dubbo-registry 注册中心模块: 基于注册中心下发的集群方式,以及对各种注册中心的抽象
- dubbo-monitor 监控模块: 统计服务调用次数,调用时间,调用链跟踪的服务.
- dubbo-config 配置模块: 是dubbo对外的api,用户通过config使用dubbo,隐藏dubbo所有细节
- dubbo-container 容器模块: 是一个standlone的容器,以简单的main加载spring启动,因为服务通常不需要Tomcat/Jboss等web容器的特性,没必要用web容器去加载服务.
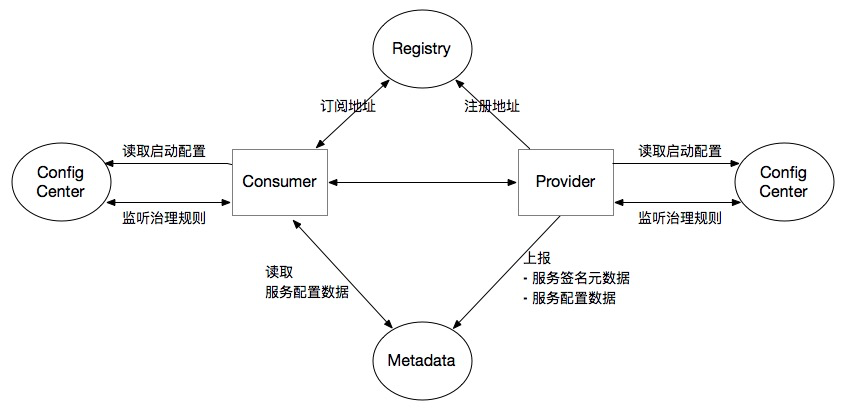
Dubbo微服务组件包含三个中心组件:
- 注册中心,协调Consumer与Provider之间的地址与发现
- 配置中心
- 存储Dubbo启动阶段的全局配置,保证配置的跨环境共享与全局一致性
- 负责服务治理规则(路由规则/动态配置等)的存储与推送
- 元数据中心
- 接收Provider上报的服务接口元数据,为Admin等控制台提供运维能力(如服务测试/接口文档等)
- 也作为注册中心的额外扩展,作为服务发现机制的补充,提供额外的接口/方法级别配置信息的同步能力
可以看到,整体上来看,Dubbo 首先是一款RPC框架,用户在使用 Dubbo 时首先需要定义好 Dubbo 服务,其次,是在将 Dubbo 服务部署上线之后,依赖 Dubbo 的应用层通信协议实现数据交换,再者,Dubbo 所传输的数据都要经过序列化,而这里的序列化协议是完全可扩展的。
然后,在分布式系统中,服务越来越多,应用之间的部署越来越繁杂,用户作为RPC的消费方,如何动态知道服务提供方地址,因此,Dubbo 引入了注册中心来协调提供方和消费方的地址,然后又引入了各种各样的微服务组件例如熔断限流,监控中心等。形成了一个完整的微服务框架。
其中
| 角色 | 职责 | 说明 |
|---|---|---|
| Provider | 暴露服务 | 实现业务接口,启动时向注册中心注册自己的地址 |
| Consumer | 调用服务 | 启动时从注册中心订阅服务,获得提供者列表,发起远程调用 |
| Registry | 服务注册与发现 | 协调 Provider 和 Consumer,推送地址变更(如 Nacos/ZK) |
| Monitor | 调用统计 | 收集 RPC 调用次数、耗时等指标,用于运维分析(可选) |
| Container | 运行容器 | 服务运行的宿主环境(Spring Boot、Tomcat、Main 函数等) |
那么,上述的流程可以概括为
- Provider 启动 → 注册到 Registry
- Consumer 启动 → 订阅 Registry → 获取 Provider 列表
- Consumer 调用本地代理 → Dubbo 选择一个 Provider 发起网络请求
- Provider 执行方法 → 返回结果 → Consumer 接收结果
那么,三大中心通过 RPC 协议,构建了完整的微服务治理体系,它们是这样协同工作的
sequenceDiagram
participant P as Provider
participant R as Registry (Nacos)
participant M as Metadata Center
participant C as Consumer
P->>R: 注册应用实例 (user-service@10.0.0.1)
P->>M: 上报元数据 (接口/方法/参数)
C->>R: 订阅 user-service
R-->>C: 返回实例列表 [10.0.0.1]
C->>M: 拉取 user-service 的元数据
M-->>C: 返回接口定义
C->>P: 通过 tri 协议调用 sayHello()
P-->>C: 返回结果Dubbo 的 RPC 架构
那么,Dubbo 的 RPC 流程的架构流转如下
- 使用 Dubbo 的第一步就是定义 Dubbo 服务,服务在 Dubbo 中的定义就是完成业务功能的一组方法的集合
- 然后定义好服务之后,服务端(Provider)需要提供服务的具体实现,并将其声明为 Dubbo 服务
- 站在服务消费方(Consumer)的视角,通过调用 Dubbo 框架提供的 API 可以获得一个服务代理(stub)对象,然后就可以像使用本地服务一样对服务方法发起调用了。
- 在消费端对服务方法发起调用后,Dubbo 框架负责将请求发送到部署在远端机器上的服务提供方,提供方收到请求后会调用服务的实现类,之后将处理结果返回给消费端,这样就完成了一次完整的服务调用。
但这背后,Dubbo 实际上完成了一整套高度抽象且可扩展的 RPC 调用流水线。
服务定义和服务契约:Java 接口方式 和 IDL 方式
服务暴露:当 Provider 应用启动时,Dubbo 会自动执行服务暴露(Service Export)流程,这个流程之后等说到 RPC 的时候再说
服务引用:Consumer 启动时,执行服务引用(Service Refer)流程
Dubbo 的注册中心架构
平常我们使用的注册中心还是配置中心,基本都是 Naocs,在 Dubbo 框架下,也是一样的,Dubbo 官方主推方案 就是 Naocs

但是,Dubbo 是一个框架,不是一个具体的中间件,它定义了注册中心、配置中心、元数据中心的 SPI 接口规范
实现了 Dubbo 的注册中心的是 dubbo-registry-*
模块,一般情况下,我们使用dubbo-registry-nacos,而下面要说的配置中心也是一样的
Dubbo 注册中心主要承载的作用是服务注册和服务发现的职责,Dubbo支持接口级别和应用级别的两种粒度的服务发现和服务注册。
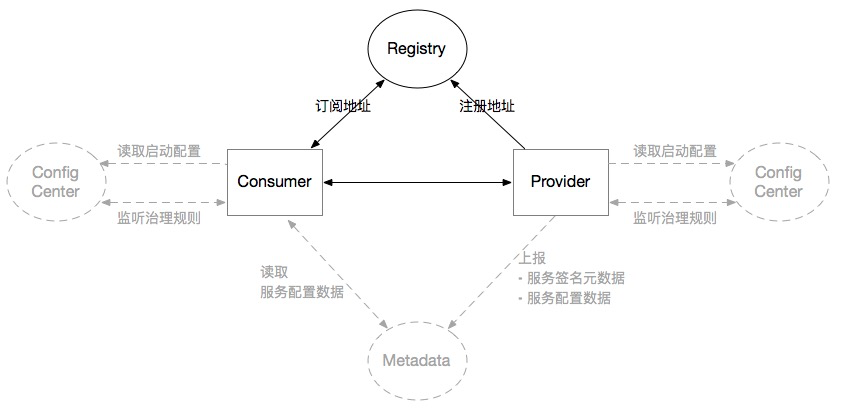
Dubbo的配置中心架构
整个部署架构中,整个集群内实例(无论是Provider还是Consumer)都会共享该配置中心集群中的配置。
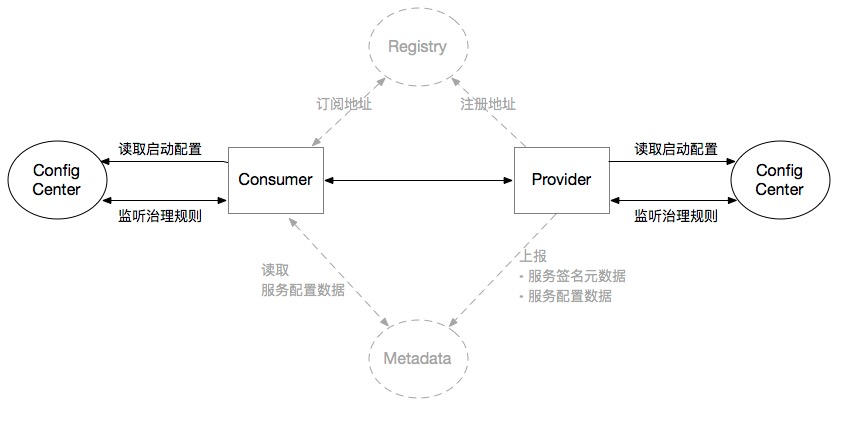
在 Dubbo 中,配置中心(Config Center)承担三个核心职责,具体实现我们还是使用 Nacos 为例子,因为我不熟悉 Zookeeper
| 职责 | 说明 | 传统方式对比 |
|---|---|---|
| 1. 外部化配置 | 集中存储 dubbo.properties 内容,替代本地配置文件 |
无需打包修改配置,支持跨环境共享 |
| 2. 动态配置 | 运行时动态修改超时、重试、线程池等参数 | 无需重启应用,秒级生效 |
| 3. 服务治理规则存储 | 存储路由规则(标签/条件)、降级规则、权重调整等 | 实现灰度发布、故障隔离、流量调度 |
具体实现就是 Dubbo 将配置中心视为一个 支持监听(Watch)的 Key-Value 存储系统:
- Key:由
{namespace}/{group}/{key}三元组唯一标识; - Value:配置内容
Dubbo 通过 SPI 机制 对接不同配置中心
Dubbo的元数据中心架构
Dubbo 的元数据中心是为整个微服务系统提供服务元信息的存储、查询与同步能力
Dubbo 3 会需要一个元数据中心来维护RPC服务与应用的映射关系,即接口与应用的映射关系
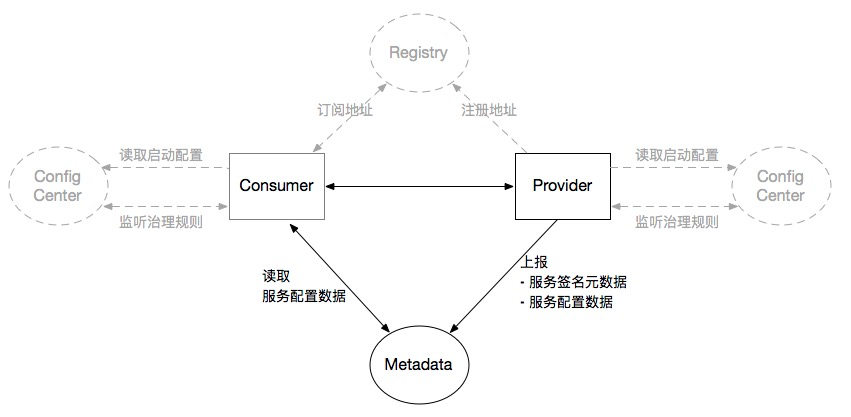
因为如果采用了应用级别的服务发现和服务注册,在注册中心中将采用“应用 —实例列表”结构的数据组织形式,不再是以往的“接口 —实例列表”结构的数据组织形式,这是什么意思,举个例子:
Dubbo 2.x 的时候,每个接口都需要独立注册,注册中心压力大
而 Dubbo 3.x 的时候,一个应用只注册一次:
这就产生一些额外的问题了,那么,例如 Consumer 要调
UserService.sayHello(),但注册中心只返回了user-service的 IP。如何知道user-service是否提供了UserService?其中是不是有.sayHello()这个方法?参数是什么?那么,Dubbo 3.x,引入 元数据中心,存储
接口 ↔︎ 应用的映射关系 + 接口详细元数据。
Dubbo 元数据中心包含 两类核心数据,分别解决不同问题
- 地址发现元数据:建立 接口名 → 应用名 的映射关系
- 服务运维元数据:描述 一个应用提供的所有接口详情
而且一般来说,未显式配置 metadata-report,Dubbo
自动将注册中心用作元数据中心
还是那句话,优先选择 Nacos,因为它与 Dubbo 生态深度集成
Dubbo的内部模块分层
虽然我不打算深入 Dubbo 的源码,不像我之前讲 Spring Cloud 那样,但了解分层有助于理解扩展点,因为 SPI 是其中重要的内容
| 层级 | 模块 | 职责 |
|---|---|---|
| Service | 业务接口 | 用户定义的 DemoService |
| Config | 配置层 | @DubboService, dubbo.properties |
| Proxy | 代理层 | 为 Consumer 生成本地代理对象 |
| Registry | 注册层 | 封装注册/发现逻辑 |
| Cluster | 集群层 | 负载均衡、容错、路由 |
| Protocol | 协议层 | dubbo://, tri:// 等协议实现 |
| Exchange | 交互层 | Request-Response 模式封装 |
| Transport | 传输层 | Netty / Grizzly 网络通信 |
| Serialize | 序列化层 | Hessian2 / JSON / Protobuf |
Dubbo的可扩展性
Dubbo 使用插件化的设计模式,这个设计模式具体的体现在其中叫做 SPI
为什么要在系统中强调可扩展性呢?一个很大的原因是,比如一个系统设计好之后,后期又需要加入一些功能代码或者插件,如何最小化改变原有代码加入功能代码或者插件,这个就是扩展性,Dubbo在架构时期也一直重视可扩展性。
开闭原则:对扩展开放,对修改关闭 —— 新功能应通过“新增代码”实现,而非“修改框架源码”。
所以说,Dubbo 很重视框架的扩展性,每个扩展点只封装一个变化因子,最大化复用
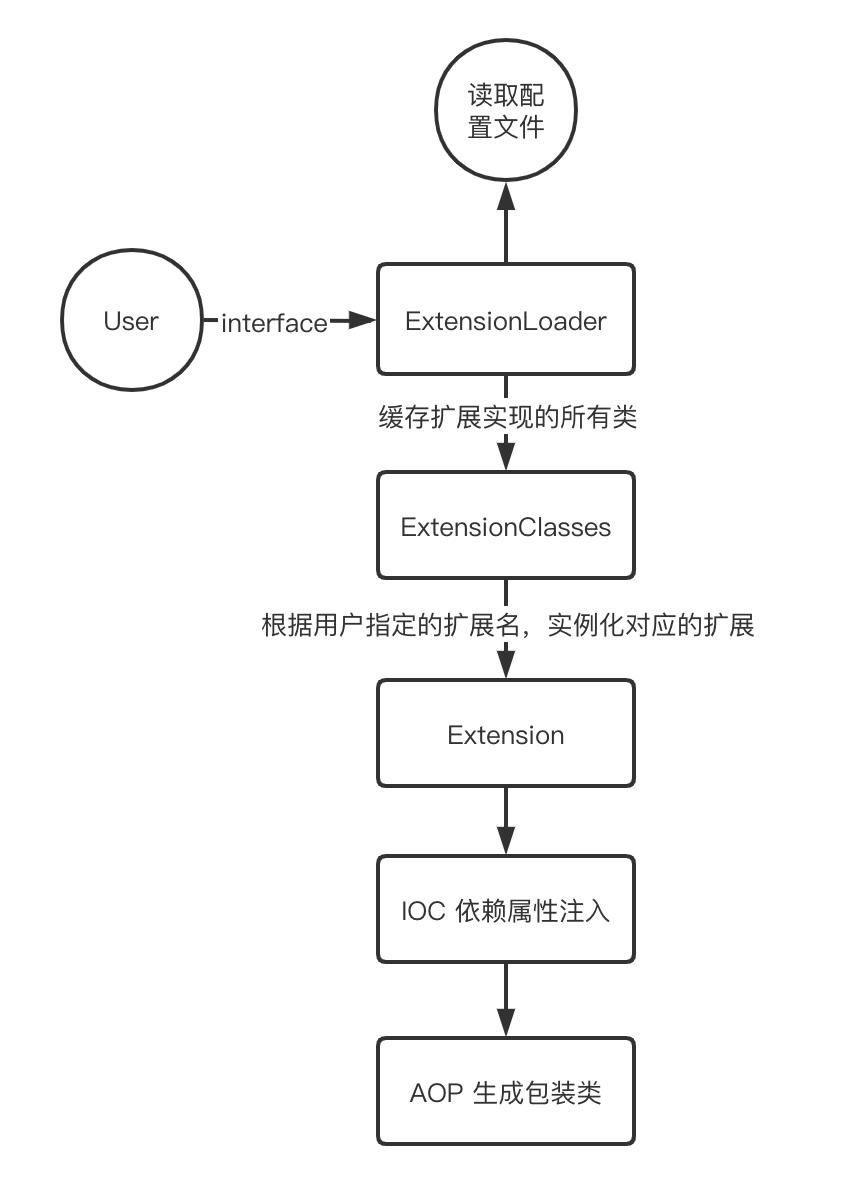
Dubbo 完全重写了 SPI 机制,命名为 ExtensionLoader
- 按需加载
- IOC
- AOP
- 自动激活和适配扩展,而且支持排序
使用 Dubbo + Spring Boot 构建微服务项目
这是我们接下来演示如何使用和实践 Dubbo 的核心内容
搭建项目
首先,从一个空的 Maven 项目开始搭建,使用 spring boot 组织为一个微服务项目
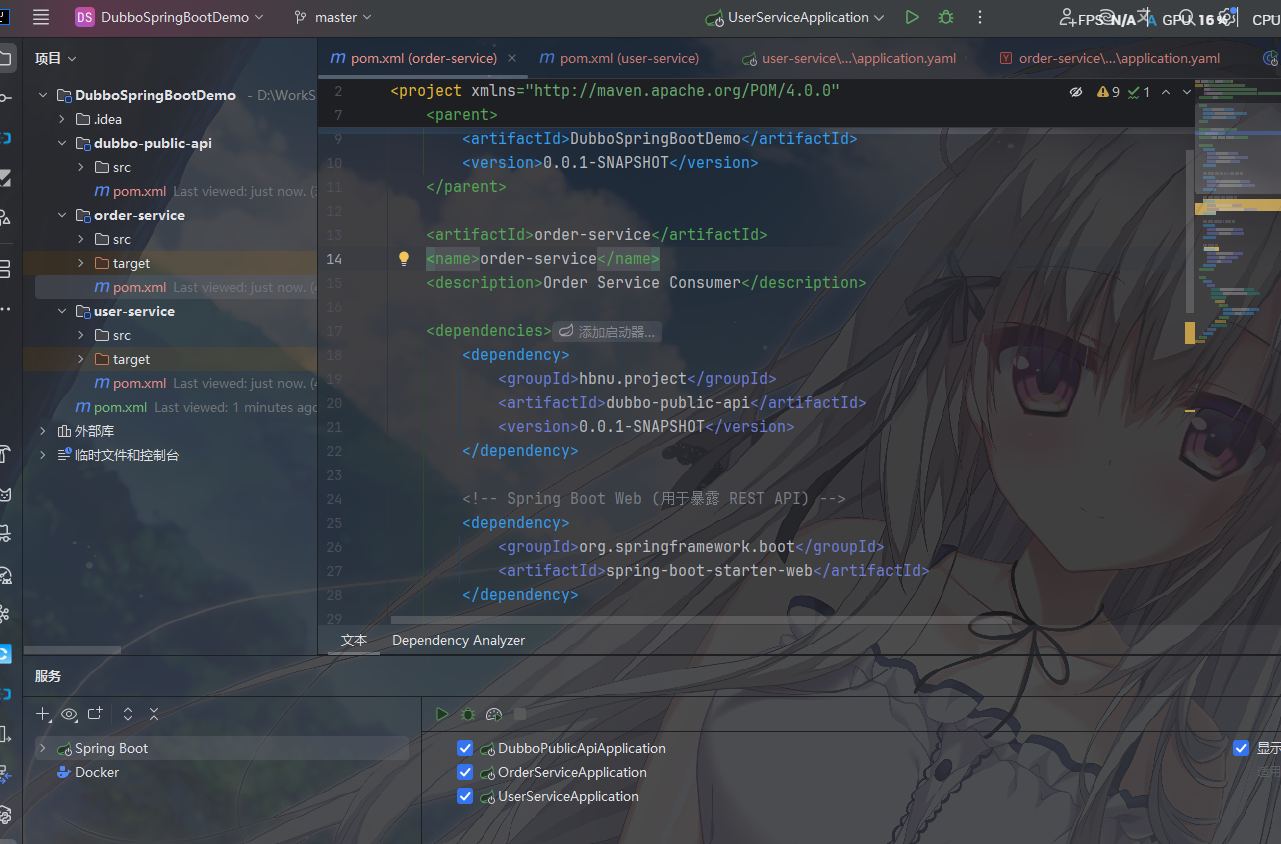
其中,服务 user-service 是生产者,order-service 是消费者,dubbo-public-api 是 公共api 模块,定义服务接口,供服务提供者和消费者共享
其中,涉及到的依赖如下
1 | <!-- Dubbo Spring Boot Starter --> |
一般来说,谁要调用远程服务的接口,就需要加上这个依赖,那么,也就是一般情况下,就是服务消费者需要加上
父模块的 pom 文件如下
1 |
|
子的也就是按需要去配置了,我就不放出来了
配置我放出来,服务提供者和服务消费者的配置大差不差,但是服务提供者不用配置 rpc
1 | server: |
搭建项目
dubbo-public-api 公共接口模块
首先,在 dubbo-public-api 这个公共接口暴露模块中,我们需要声明使用的接口
1 | package hbnu.project.dubbopublicapi.api; |
一般情况下,我习惯是把 DTO 放到公共接口模块中,看你们自己
user-service服务提供者
然后搭建服务提供者,首先,服务提供者需要实现上面我们暴露的接口
1 | package hbnu.project.userservice.service; |
order-service服务消费者
对于服务消费者,一样要创建服务类,这样能演示 RPC 远程调用和本地调用两种内容
1 | package hbnu.project.orderservice.service; |
对于控制器,需要使用 @DubboReference 注入远程服务,跟
Feign 不太一样
1 | // 使用 @DubboReference 注入远程服务 |
然后编写控制器中对应的接口就可以了,这里省略了
演示服务发现
当然,dubbo 默认在 public 的命名空间中,其中分组也是默认组
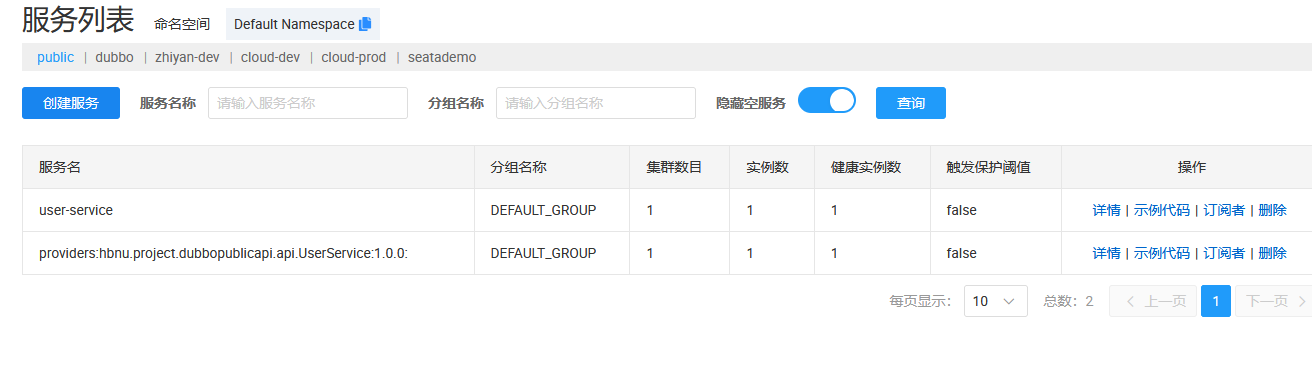
这样很明显是不够,本来 Nacos 中什么东西几乎都放到 public 中的默认组,所以,为了更好的服务隔离,我们需要针对其进行相关配置
首先,我们需要为两个服务进行命名空间的隔离
1 | registry: |
有人说这么写不太清晰,但是我习惯了,当然,有人说也可以这么写,对于服务发现,因为namespcae这个配置条在parameters中
1 | registry: |
我们重新启动一下项目,来看看服务发现的情况
可以看到服务发现正确的对应到对应的命名空间了
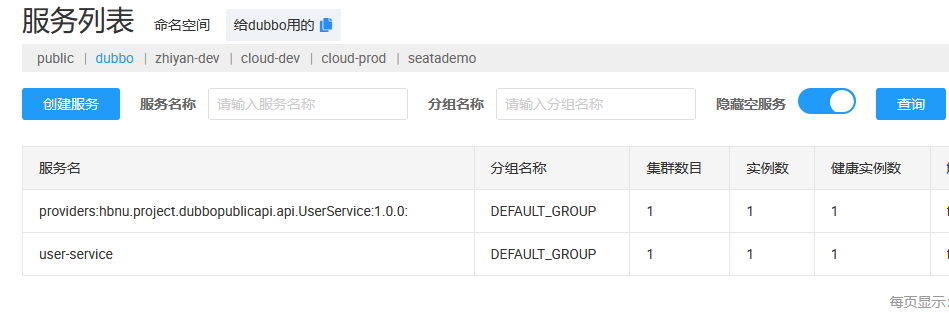
除了 namespace,还可以用 group 对服务进行逻辑分组。
那么,分组的配置也很清晰
1 | dubbo: |
我们曾经在 @DubboService 和 @DubboReference
中都指定了版本号
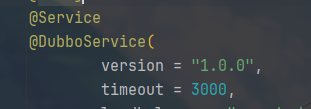
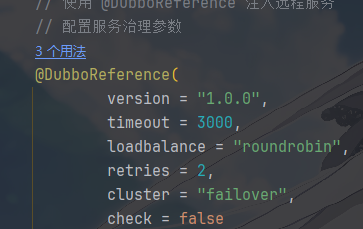
这个是接口灰度发布的基础,但是具体我好像没用过,不太清楚
最后测试一下 RPC 远程调用,因为服务发现和接口发现是 RPC 远程调用的基础

对于流量管理和服务治理:
对 Nacos
而言,所有流量治理规则和外部化配置都应该是全局可见的,因此相同逻辑集群内的应用都必须使用相同的
namespace 与 group。其中,namespace 的默认值是
public,group 默认值是 dubbo,应用不得擅自修改
namespace 与 group,除非能保持全局一致。
流量治理规则的增删改建议通过 dubbo-admin 完成,
演示配置中心
那么,服务都进行环境隔离了,那么配置中心肯定也要来一个环境隔离才对
那么,配置中心的环境隔离就可以这样写,别忘了 Dubbo 有元数据空间和配置空间
1 | config-center: |
当然你也可以继续进行 Group 的级别的设置
那么,我们当然可以进行进一步的实践,也就是外部化配置,不写死在
application.yml
上面的配置意味着什么,意味着 Dubbo 会从 Nacos 拉取配置,但我还没有在
Nacos 中创建任何 Dubbo 配置项,所以它只用了本地
application.yml 的默认值。
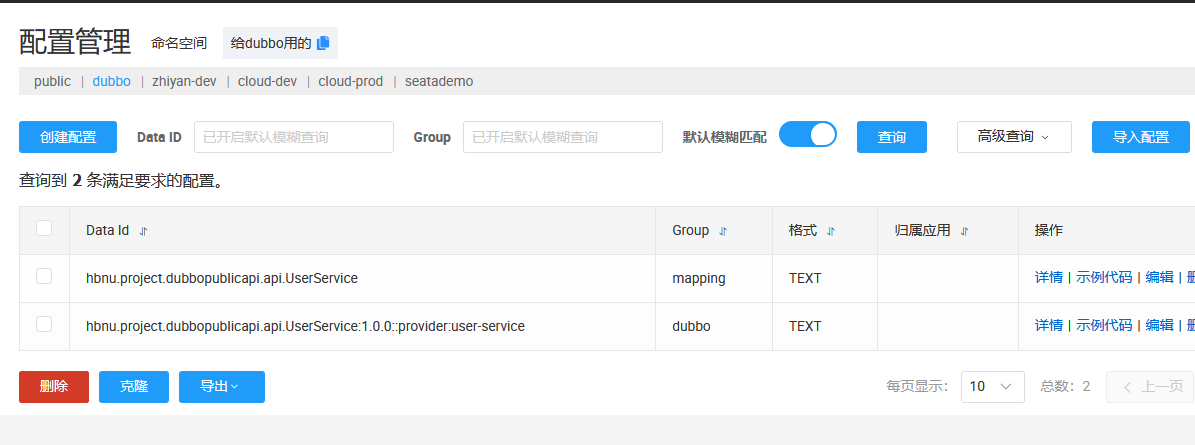
当然,dubbo 是有一个全局配置的
1 | dubbo: |
config-file - 全局外部化配置文件 key 值,默认
dubbo.properties。config-file 代表将 Dubbo
配置文件存储在远端注册中心时,文件在配置中心对应的 key
值,通常不建议修改此配置项。
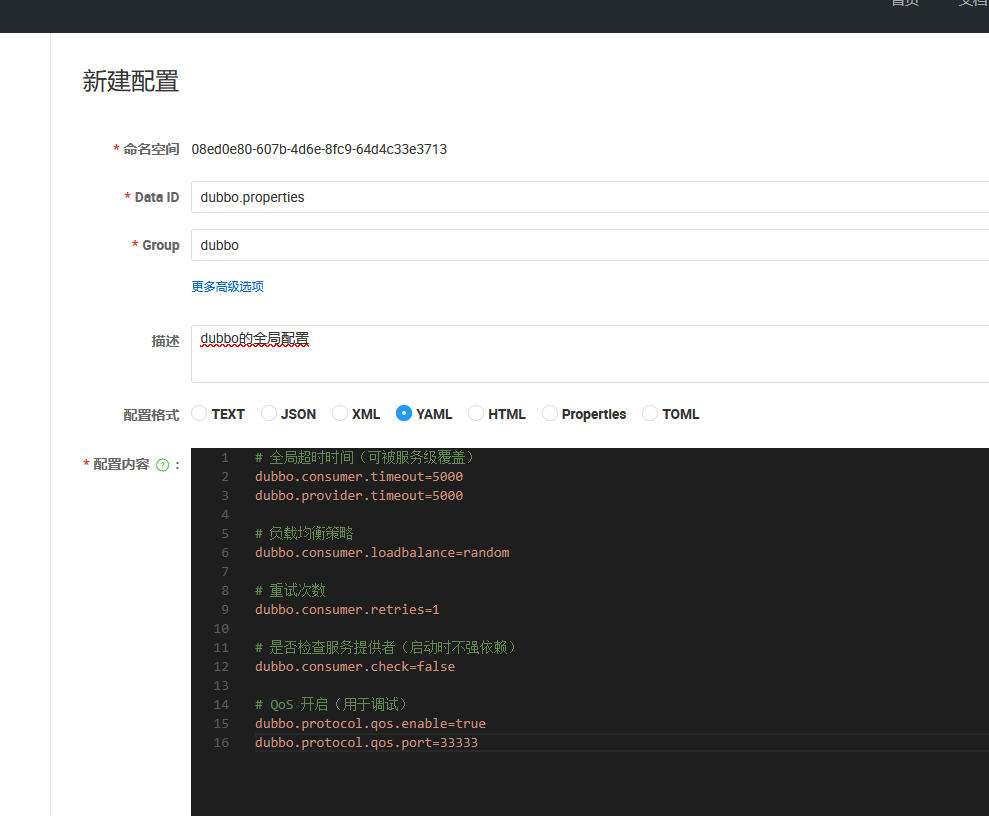
dataId 是 dubbo.properties,group 分组与 config-center
保持一致,如未设置则默认填 dubbo。
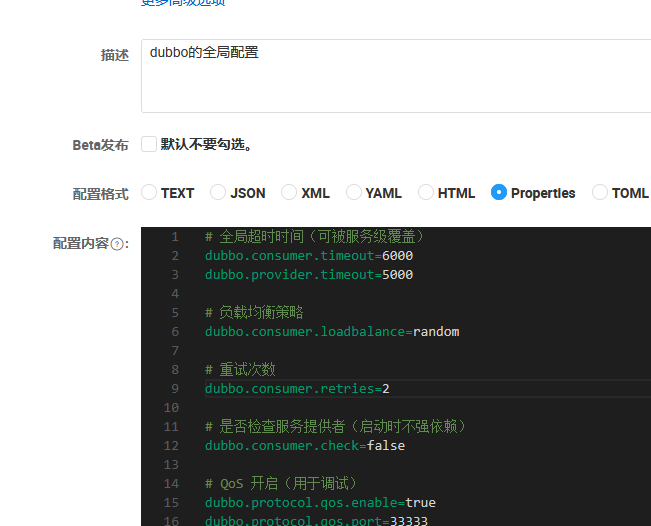
当然你也可以不停机修改服务配置
这些配置会自动覆盖代码中或
application.yml 中的同名配置!
对服务的配置也一样,也可以创建对应的配置文件,但是通常情况下
因为有元空间的存在,你可以深入到某个指定的接口进行配置,动态调整某个服务在的接口的权重以及其他内容,需开启
service-name-mapping=true
1 | # 权重路由规则(示例) |
然后启动我们观察一下配置的情况
首先看到全局配置被加载了
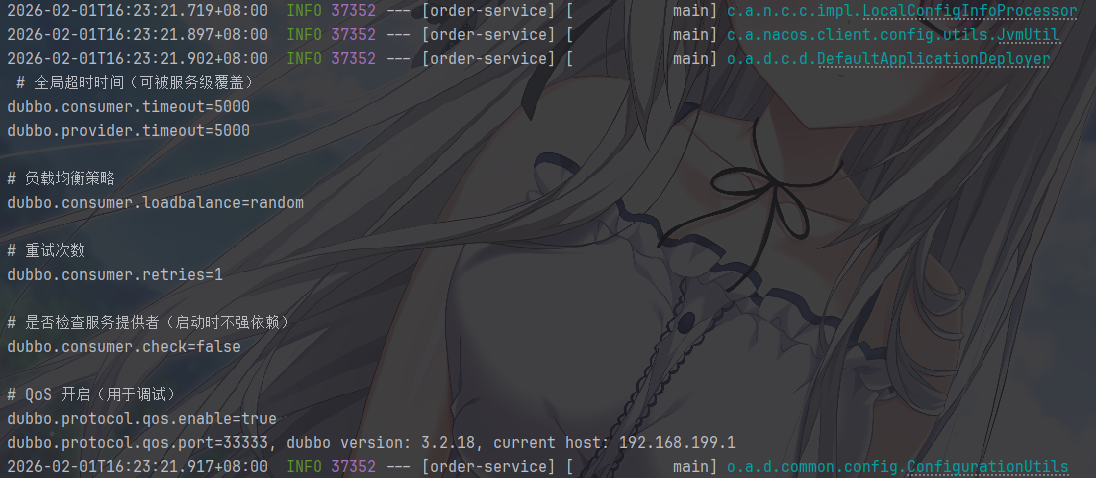
当然,也可以在Java代码中使用注解@NacosValue读取相应的配置参数,如果希望参数值动态刷新,必须设置autoRefreshed为true。
1 |
|
演示 RPC 调用
以此接口为案例吧
1 | /** |
然后,启动项目,可以看到服务都是启动成功了,其中 Dubbo 的 RPC 相关内容也起来了
就以上面提到的 Controller 接口来做示例了
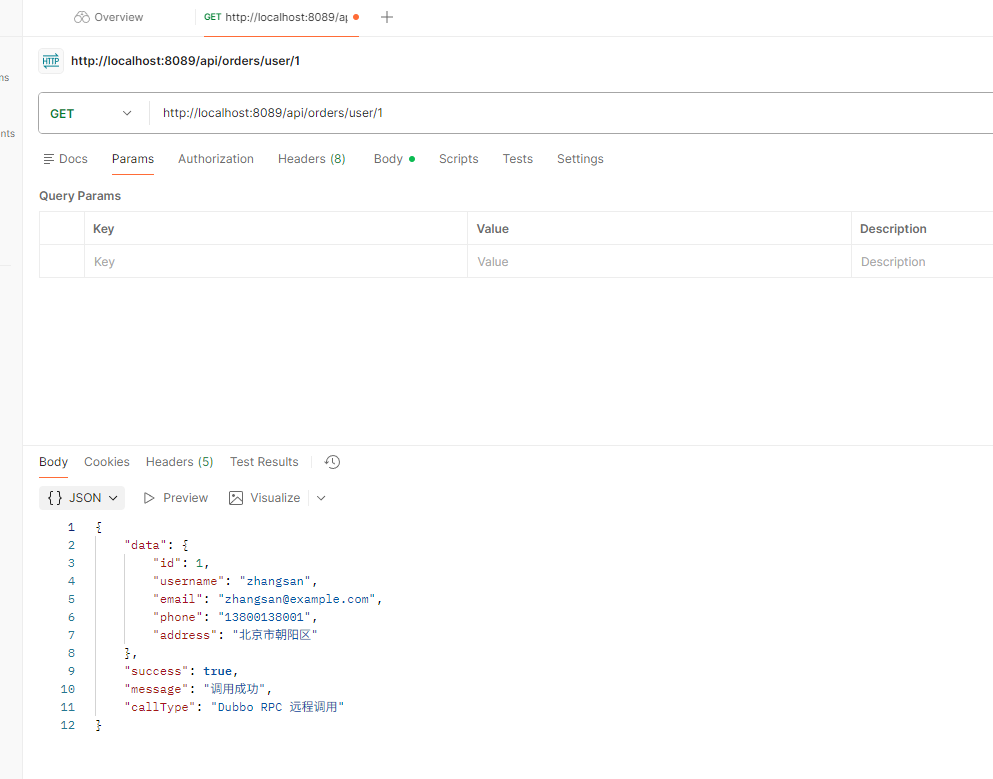
那么试一下混合调用,创建一个订单
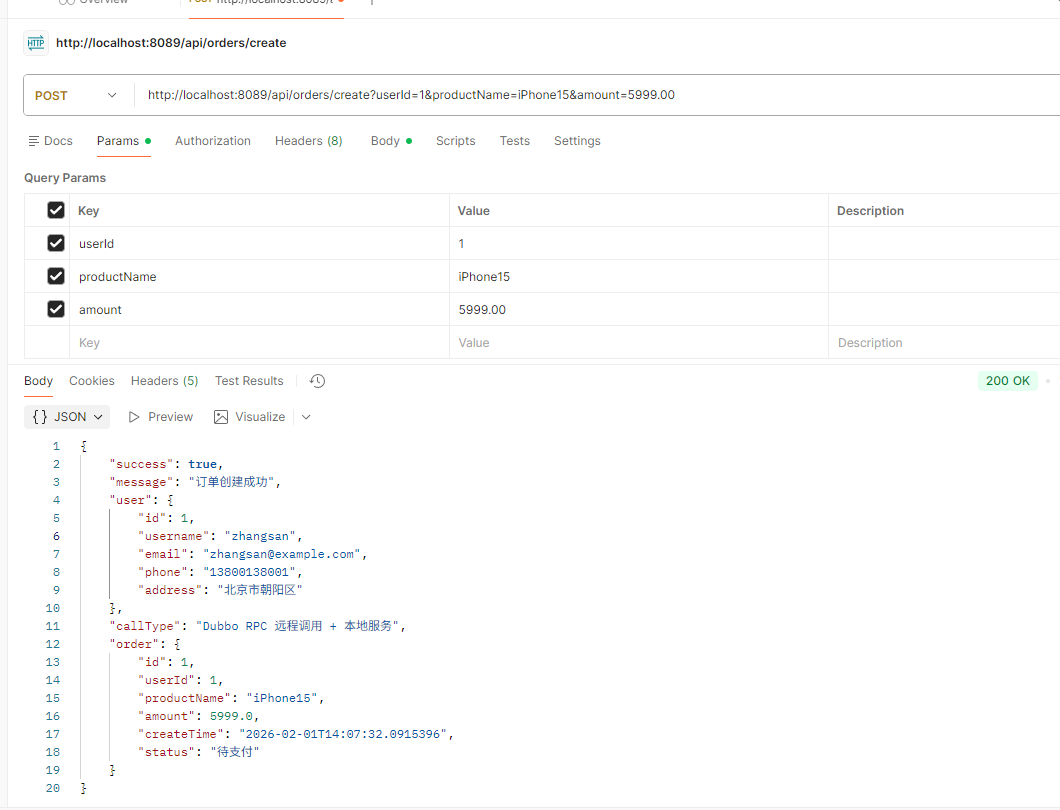
可以看到,RPC 远程服务接口就这样被启用了
就算不用 Dubbo 的各种服务治理什么的,光是一个服务调用我就感觉比 Feign 要好用






