微服务项目内如何集成 Kafka
和其他组件要考虑的事情一样,还是涉及到在哪用,用给谁,如何配置的这三个问题
在 Spring Cloud 微服务项目中集成
Kafka,主要涉及生产者(发送消息)和消费者(接收消息)的实现,以及与
Spring Cloud 生态的适配(如服务发现、配置中心等)
Spring创建了一个项目Spring-kafka,封装了Apache
的Kafka-client,用于在Spring项目里快速集成kafka。
依赖如下
1 2 3 4 5 6 7 8 9 10 11 <dependency > <groupId > org.springframework.kafka</groupId > <artifactId > spring-kafka</artifactId > </dependency > <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-stream-kafka</artifactId > </dependency >
然后这时候,不要忘记打开你的 Kafka,记录 Broker
地址(localhost:9092),然后在application.yml(或bootstrap.yml,结合配置中心)中配置
Kafka 连接信息,常用的配置是这样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 spring: kafka: bootstrap-servers: localhost:9092 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.springframework.kafka.support.serializer.JsonSerializer acks: 1 retries: 3 batch-size: 16384 buffer-memory: 33554432 consumer: group-id: service-order-consumer key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer auto-offset-reset: earliest enable-auto-commit: false listener: ack-mode: manual_immediate concurrency: 3
这里要注意,若使用 Spring Cloud Config/Nacos
配置中心,可将bootstrap-servers等配置抽离到配置中心,避免硬编码。因为消息队列的信息还是比较敏感的。
然后通过KafkaTemplate发送消息,支持同步 /
异步发送,发送了如何接受呢?通过@KafkaListener注解监听指定主题,处理消息。
这是最基本的使用,发送消息时注入一个KafkaTemplate,接收消息时添加一个@KafkaListener注解即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @SpringBootApplication @RestController public class Application { private final Logger logger = LoggerFactory.getLogger(Application.class); public static void main (String[] args) { SpringApplication.run(Application.class, args); } @Autowired private KafkaTemplate<Object, Object> template; @GetMapping("/send/{input}") public void sendFoo (@PathVariable String input) { this .template.send("topic_input" , input); } @KafkaListener(id = "webGroup", topics = "topic_input") public void listen (String input) { logger.info("input value: {}" , input); } }
如果出现处理消费失败的消息,想要进行处理,可以配置死信主题(如order-create-topic.DLT),通过@KafkaListener监听死信主题进行重试或人工处理。
之后我们就用实际项目中如何组合进这些内容来分析
Spring Cloud
微服务生态中集成 Kafka
添加依赖
1 2 3 4 5 <dependency > <groupId > org.springframework.kafka</groupId > <artifactId > spring-kafka</artifactId > </dependency >
编写配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 spring: application: name: kafka-message kafka: bootstrap-servers: localhost:9092 producer: retries: 3 batch-size: 16384 buffer-memory: 33554432 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.springframework.kafka.support.serializer.JsonSerializer acks: all compression-type: gzip consumer: group-id: kafka-message-group enable-auto-commit: true auto-commit-interval: 1000 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer auto-offset-reset: earliest properties: spring.json.trusted.packages: "*" max.poll.records: 500 listener: type: single ack-mode: batch concurrency: 3 server: port: 8085 logging: level: root: INFO org.springframework.kafka: INFO hbnu.project.kafkamessage: DEBUG
其中涉及到的很多重要的参数,在我们之前讲工作原理的时候就提到这些分别是什么了
定义配置类
在这里我定义了一个配置类用于创建主题并且配置参数,这里的核心组件是
KafkaAdmin
默认情况下,如果在使用KafkaTemplate发送消息时,Topic不存在,会创建一个新的Topic,默认的分区数和副本数为如下Broker参数来设定
如果Kafka
Broker支持(1.0.0或更高版本),则如果发现现有Topic的Partition
数少于设置的Partition 数,则会新增新的Partition分区。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 @Configuration public class KafkaTopicConfig { @Value("${spring.kafka.bootstrap-servers}") private String bootstrapServers; @Bean public KafkaAdmin kafkaAdmin () { Map<String, Object> configs = new HashMap <>(); configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); return new KafkaAdmin (configs); } @Bean public NewTopic simpleMessageTopic () { return TopicBuilder.name("simple-message-topic" ) .partitions(3 ) .replicas(1 ) .build(); } @Bean public NewTopic userMessageTopic () { return TopicBuilder.name("user-message-topic" ) .partitions(3 ) .replicas(1 ) .config("cleanup.policy" , "delete" ) .config("retention.ms" , "604800000" ) .build(); } @Bean public NewTopic orderMessageTopic () { return TopicBuilder.name("order-message-topic" ) .partitions(5 ) .replicas(1 ) .build(); } @Bean public NewTopic batchMessageTopic () { return TopicBuilder.name("batch-message-topic" ) .partitions(3 ) .replicas(1 ) .build(); } }
关于KafkaAdmin有几个常用的用法如下:
setFatalIfBrokerNotAvailable(true): 默认这个值是False的,在Broker不可用时,不影响Spring
上下文的初始化。如果你觉得Broker不可用影响正常业务需要显示的将这个值设置为TruesetAutoCreate(false) : 默认值为True,也就是 Kafka
实例化后会自动创建已经实例化的 NewTopic 对象initialize(): 当setAutoCreate为false时,需要我们程序显示的调用admin的initialize()方法来初始化NewTopic对象
定义实体类
先定义信息的实体,订单消息实体类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 package hbnu.project.kafkamessage.model;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.io.Serializable;import java.math.BigDecimal;import java.time.LocalDateTime;@Data @NoArgsConstructor @AllArgsConstructor public class OrderMessage implements Serializable { private Long orderId; private Long userId; private Long productId; private String productName; private BigDecimal amount; private Integer quantity; private String status; private LocalDateTime createTime; }
然后在实际项目中一般情况下我们还需要传递用户消息,定义其实体类,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @Data @NoArgsConstructor @AllArgsConstructor public class UserMessage implements Serializable { private Long userId; private String username; private String email; private String operation; private LocalDateTime timestamp; private String extraInfo; }
编写生产者
我们需要编写一个生产者服务的实现,它的目的是封装了多种消息发送方式,适配不同业务场景
先看代码,下面再讲
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 @Slf4j @Service public class KafkaProducerService { @Autowired private KafkaTemplate<String, Object> kafkaTemplate; public void sendSimpleMessage (String topic, String message) { log.info("发送简单消息到主题 [{}]: {}" , topic, message); kafkaTemplate.send(topic, message); } public void sendMessageWithKey (String topic, String key, String message) { log.info("发送消息到主题 [{}],Key: {}, 内容: {}" , topic, key, message); kafkaTemplate.send(topic, key, message); } public void sendUserMessage (UserMessage userMessage) { log.info("发送用户消息: {}" , userMessage); CompletableFuture<SendResult<String, Object>> future = kafkaTemplate.send("user-message-topic" , String.valueOf(userMessage.getUserId()), userMessage); future.whenComplete((result, ex) -> { if (ex == null ) { log.info("用户消息发送成功! Topic: {}, Partition: {}, Offset: {}" , result.getRecordMetadata().topic(), result.getRecordMetadata().partition(), result.getRecordMetadata().offset()); } else { log.error("用户消息发送失败: {}" , ex.getMessage()); } }); } public boolean sendOrderMessageSync (OrderMessage orderMessage) { log.info("同步发送订单消息: {}" , orderMessage); try { SendResult<String, Object> result = kafkaTemplate .send("order-message-topic" , String.valueOf(orderMessage.getOrderId()), orderMessage) .get(); log.info("订单消息发送成功! Offset: {}" , result.getRecordMetadata().offset()); return true ; } catch (Exception e) { log.error("订单消息发送失败: {}" , e.getMessage()); return false ; } } public void sendToPartition (String topic, Integer partition, String key, Object message) { log.info("发送消息到主题 [{}] 的分区 [{}]" , topic, partition); kafkaTemplate.send(topic, partition, key, message); } public void sendBatchMessages (String topic, List<String> messages) { log.info("批量发送 {} 条消息到主题 [{}]" , messages.size(), topic); messages.forEach(message -> { kafkaTemplate.send(topic, message); }); log.info("批量消息发送完成" ); } public void sendAndFlush (String topic, String message) { log.info("发送并刷新消息到主题 [{}]: {}" , topic, message); kafkaTemplate.send(topic, message); kafkaTemplate.flush(); log.info("消息已刷新发送" ); } }
首先,无论是发送消息还是接收消息,我们需要注入一个核心组件
KafkaTemplate,这是 Spring Kafka
提供的核心模板类,封装了 Kafka 生产者 API,简化了消息发送操作。Spring
Boot 会自动配置KafkaTemplate,底层关联 Kafka
原生的Producer实例。
其中,KafkaTemplate<String, Object>代表
泛型第一个参数String:消息的key类型(用于分区路由)
泛型第二个参数Object:消息体类型(支持字符串、自定义对象等)
简单字符串的消息就使用了
send方法,这是最基础的异步发送,只指定主题和消息体,不处理回调。当对消息可靠性要求不高,如日志采集、监控数据上报等,会使用这个方法
1 kafkaTemplate.send(topic, message);
注意的是,Kafka
默认异步发送,消息先存入本地缓冲区,满足批处理条件(如达到batch-size或linger.ms)后批量发送。这个
send 异步发送的方法拆解一下就是如下
1 2 3 4 5 6 7 8 9 10 11 template.send("" ,"" ).addCallback(new ListenableFutureCallback <SendResult<Object, Object>>() { @Override public void onFailure (Throwable throwable) { ...... } @Override public void onSuccess (SendResult<Object, Object> objectObjectSendResult) { .... } });
发送一个带 key 的消息就指定参数
key,通过key控制消息分区路由,需要保证需要保证消息顺序性等使用,一般情况下,默认通过key.hashCode() % 分区数计算分区索引
1 kafkaTemplate.send(topic, key, message);
Kafka
的每条消息由两部分组成:key和value(消息体)。
value:实际的业务数据(如字符串、UserMessage对象等),是消费端主要处理的内容。key:可选的元数据(默认null),通常是字符串或序列化后的对象,Kafka
内部会对其进行哈希计算,主要用于分区路由
上述不指定key(如sendSimpleMessage方法),key为null,Kafka
会采用轮询策略 将消息分发到不同分区(尽可能均匀分配)。指定
key
就根据key的哈希值计算分区,确保相同key的消息进入同一分区。
而key的核心作用是控制消息的分区路由 ,进而影响消息的顺序性、分组性和存储策略,相同key的消息会被路由到同一分区,相当于按key对消息进行
“分组”,便于消费端按组处理。而且,Kafka
的log.cleanup.policy=compact策略下,会保留相同key的最新一条消息 。
那么这个 key
,一般情况下,我们用业务主键作为key,确保同一主体的消息路由到同一分区。
还可以指定分区发送,指定参数
partition,会忽略路由规则,一般情况下自定义负载均衡用
1 kafkaTemplate.send(topic, partition, key, message);
发送带回调的对象消息,sendUserMessage,它通过CompletableFuture异步回调处理发送结果(成功
/ 失败)。
1 2 CompletableFuture<SendResult> future = kafkaTemplate.send(...); future.whenComplete((result, ex) -> { ... });
它能不阻塞主线程,同时能感知消息是否发送成功,成功时获取消息的分区、偏移量(offset)等元数据,失败会触发重试,当需要发送自定义对象(如UserMessage)且需要确认发送结果的场景,如用户登录通知、消息推送等,一般情况下我们使用这种消息
而且,代码中发送UserMessage、OrderMessage等自定义对象时,依赖配置中的value-serializer: JsonSerializer(默认使用
Jackson
序列化),要注意,消费者需配置对应的JsonDeserializer,并指定spring.json.trusted.packages(信任的包路径),避免反序列化失败。
那么还有一种同步发送消息(sendOrderMessageSync)
1 SendResult result = kafkaTemplate.send(...).get();
它通过get()方法阻塞当前线程,直到获取发送结果(成功 /
异常)。对消息可靠性要求极高,必须确认发送成功后再执行后续业务,如订单创建消息这种,需要用到这种的消息,注意,同步发送会降低吞吐量,性能不好
Kafka还能批量发送,循环调用单条发送,所以和单条的 send
一样,将多条消息缓存到缓冲区,满足batch-size(默认
16KB)或linger.ms(默认 0ms)时批量发送。
1 messages.forEach(message -> kafkaTemplate.send(topic, message));
发送并且立即刷新比较特殊,flush()方法会立即将缓冲区中的消息发送到
Kafka
broker,不等待批处理条件。在需要消息立即送达的特殊场景(如实时告警通知)相当有用。但是频繁调用flush()会破坏批处理优化,导致性能下降,谨慎使用。
1 2 kafkaTemplate.send(topic, message); kafkaTemplate.flush();
我这边没开事务,若需保证 “本地事务与消息发送”
的原子性(如订单创建成功后才发送消息),可开启事务:
配置transaction-id-prefix: tx-(指定事务 ID
前缀)。
在业务方法上添加@Transactional,并使用kafkaTemplate.executeInTransaction(...)发送消息。
创建消费者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 @Slf4j @Service public class KafkaConsumerService { @KafkaListener(topics = "simple-message-topic", groupId = "simple-group") public void consumeSimpleMessage (String message) { log.info("====================================" ); log.info("简单消息消费者接收到消息: {}" , message); log.info("====================================" ); processSimpleMessage(message); } @KafkaListener(topics = "user-message-topic", groupId = "user-group") public void consumeUserMessage (UserMessage userMessage) { log.info("====================================" ); log.info("用户消息消费者接收到消息:" ); log.info(" 用户ID: {}" , userMessage.getUserId()); log.info(" 用户名: {}" , userMessage.getUsername()); log.info(" 邮箱: {}" , userMessage.getEmail()); log.info(" 操作类型: {}" , userMessage.getOperation()); log.info(" 时间: {}" , userMessage.getTimestamp()); log.info("====================================" ); switch (userMessage.getOperation()) { case "CREATE" : log.info("处理用户创建事件" ); break ; case "UPDATE" : log.info("处理用户更新事件" ); break ; case "DELETE" : log.info("处理用户删除事件" ); break ; default : log.warn("未知的操作类型: {}" , userMessage.getOperation()); } } @KafkaListener(topics = "order-message-topic", groupId = "order-group") public void consumeOrderMessage (ConsumerRecord<String, OrderMessage> record) { log.info("====================================" ); log.info("订单消息消费者接收到消息:" ); log.info(" 主题: {}" , record.topic()); log.info(" 分区: {}" , record.partition()); log.info(" 偏移量: {}" , record.offset()); log.info(" Key: {}" , record.key()); OrderMessage order = record.value(); log.info(" 订单ID: {}" , order.getOrderId()); log.info(" 用户ID: {}" , order.getUserId()); log.info(" 产品: {}" , order.getProductName()); log.info(" 金额: {}" , order.getAmount()); log.info(" 状态: {}" , order.getStatus()); log.info("====================================" ); processOrder(order); } @KafkaListener(topics = "simple-message-topic", groupId = "detail-group") public void consumeWithHeaders ( @Payload String message, @Header(KafkaHeaders.RECEIVED_KEY) String key, @Header(KafkaHeaders.RECEIVED_PARTITION) int partition, @Header(KafkaHeaders.OFFSET) long offset, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) { log.info("详细信息消费:" ); log.info(" Topic: {}, Partition: {}, Offset: {}" , topic, partition, offset); log.info(" Key: {}, Message: {}" , key, message); } @KafkaListener(topics = "batch-message-topic", groupId = "batch-group") public void consumeBatchMessages (List<String> messages) { log.info("====================================" ); log.info("批量消息消费者接收到 {} 条消息" , messages.size()); for (int i = 0 ; i < messages.size(); i++) { log.info(" 消息 {}: {}" , i + 1 , messages.get(i)); } log.info("====================================" ); batchProcess(messages); } @KafkaListener( topics = "user-message-topic", groupId = "manual-ack-group", containerFactory = "kafkaListenerContainerFactory" ) public void consumeWithManualAck (UserMessage message, Acknowledgment acknowledgment) { try { log.info("手动ACK消费者处理消息: {}" , message); processUserMessage(message); acknowledgment.acknowledge(); log.info("消息处理成功,已提交offset" ); } catch (Exception e) { log.error("消息处理失败: {}" , e.getMessage()); } } @KafkaListener( groupId = "partition-group", topicPartitions = @TopicPartition( topic = "simple-message-topic", partitions = {"0", "1"} // 只监听分区0和1 ) ) public void consumeFromSpecificPartitions (String message) { log.info("特定分区消费者接收到消息: {}" , message); } @KafkaListener( groupId = "offset-group", topicPartitions = @TopicPartition( topic = "simple-message-topic", partitionOffsets = { @PartitionOffset(partition = "0", initialOffset = "0"), // 分区0从offset 0开始 @PartitionOffset(partition = "1", initialOffset = "10") // 分区1从offset 10开始 } ) ) public void consumeFromSpecificOffset (String message) { log.info("从指定offset消费: {}" , message); } private void processSimpleMessage (String message) { try { Thread.sleep(100 ); log.debug("简单消息处理完成" ); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } private void processUserMessage (UserMessage userMessage) { log.debug("处理用户消息: {}" , userMessage.getUserId()); } private void processOrder (OrderMessage order) { log.debug("处理订单: {}" , order.getOrderId()); if ("CREATED" .equals(order.getStatus())) { log.info("新订单创建,发送通知" ); } else if ("PAID" .equals(order.getStatus())) { log.info("订单已支付,准备发货" ); } } private void batchProcess (List<String> messages) { log.debug("批量处理 {} 条消息" , messages.size()); } }
编写消费者的时候,我们都通过@KafkaListener注解实现不同场景的消费逻辑,差异只不过是体现在
“消息格式”“元数据获取”“确认机制”“消费范围” 四个维度
@KafkaListener是 Spring Kafka
提供的核心注解,用于将方法标记为 Kafka 消息的消费者,实现
“监听指定主题并自动消费消息” 的功能
@KafkaListener包含多个参数
参数名
类型
作用
示例
topicsString[]指定要监听的主题(支持多个),最基础的配置
topics = {"order-topic", "user-topic"}
groupIdString指定消费者组 ID,同一组内消息仅被一个消费者消费
groupId = "order-service-consumer"
topicPartitionsTopicPartition[]精确配置监听的 “主题 + 分区”,支持指定 offset
见下文 “精确控制分区与 offset” 示例
containerFactoryString指定消费者容器工厂,用于自定义消费配置(如批量消费、重试)
containerFactory = "batchKafkaListenerContainerFactory"
idString消费者实例的唯一 ID,用于标识和管理消费者(默认自动生成)
id = "order-consumer-01"
concurrencyString该消费者的并发线程数(局部配置,优先级高于全局listener.concurrency)
concurrency = "3"(3 个线程同时消费)
errorHandlerString指定异常处理器,处理消费过程中的异常(如转发死信队列)
errorHandler = "kafkaErrorHandler"
它可以显示的指定消费哪些Topic和分区的消息,设置每个Topic以及分区初始化的偏移量,设置消费线程并发度,设置消息异常处理器
基础字符串的消费consumeSimpleMessage
直接接收字符串类型消息,自动反序列化(依赖StringDeserializer)。消费简单文本消息(如日志、通知文案),无需额外元数据。
而且默认使用全局配置的ack-mode,如果消息体是 JSON
格式的字符串,那就使用对象消费了
自定义对象消费consumeUserMessage
获取消息元数据consumeOrderMessage
在监听自定义对象消费的时候,如果需要获取更多消息的元数据,可以使用ConsumerRecord,其泛型可以这样定义ConsumerRecord<String, 消息对象> record
需要基于元数据做业务逻辑,或者单纯的日志审计的时候,都很有用
选择性获取元数据consumeWithHeaders
通过@Payload和@Header注解,只获取需要的参数(消息体
+ 指定元数据),代码更简洁。
其中,@Payload:标记消息体(必须有,对应生产者发送的value)。
@Header(KafkaHeaders.XXX):从KafkaHeaders获取指定元数据,常用枚举包括:r
RECEIVED_KEY:消息 keyRECEIVED_PARTITION:分区号OFFSET:消息 offsetRECEIVED_TOPIC:主题名 批量消费consumeBatchMessages
一次性接收多条消息(List<String>),减少单条消费的
IO 开销,提升吞吐量。但是全局开启批量消费模式,否则会报 “参数类型不匹配”
异常,或在@KafkaListener中设置 containerFactory
1 2 3 4 5 spring: kafka: listener: type: batch batch-listener: true
还可以配置max-poll-records,控制每次拉取的最大消息数
批量处理失败时,建议拆分单条重试(如循环遍历messages,单条处理
+ 捕获异常,避免 “一条失败导致整批重试”)。
手动 ACK 确认(consumeWithManualAck)
通过Acknowledgment对象手动提交 offset,确保
“消息处理成功后再确认”,避免消息丢失。其中需要配置containerFactory = "kafkaListenerContainerFactory"或者
spring.kafka.listener.ack-mode=MANUAL
1 2 3 4 5 spring: kafka: listener: ack-mode: MANUAL enable-auto-commit: false
在消费时,只需要在@KafkaListener监听方法的入参加入Acknowledgment
即可,执行到ack.acknowledge()代表提交了偏移量
1 2 3 4 5 6 @KafkaListener( topics = "user-message-topic", groupId = "manual-ack-group", containerFactory = "kafkaListenerContainerFactory" ) public void consumeWithManualAck (UserMessage message, Acknowledgment acknowledgment)
如果消息消费成功,就会调用下面的acknowledgment.acknowledge()提交
offset,Kafka
标记该消息已消费。如果失败,不调用acknowledge(),Kafka
会在消费者重启或会话超时后,重新发送该消息,一般在这里结合
“死信队列”(DLQ),处理失败 3
次以上的消息转发到死信主题,避免无限重试。
这里涉及到了@KafkaListener当需要差异化配置(如
“某个消费者用批量消费,其他用单条消费”)时,通过containerFactory指定自定义的容器工厂。
监听特定分区(consumeFromSpecificPartitions)
指定 offset 消费(consumeFromSpecificOffset)
需要重新消费历史数据(如
“回溯昨天的日志”)或跳过无效数据时,用@PartitionOffset指定每个分区的起始
Offset。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @KafkaListener( groupId = "log-backtrack-group", topicPartitions = @TopicPartition( topic = "log-topic", // 配置每个分区的起始Offset partitionOffsets = { @PartitionOffset(partition = "0", initialOffset = "1000"), // 分区0从Offset 1000开始 @PartitionOffset(partition = "1", initialOffset = "2000") // 分区1从Offset 2000开始 } ) ) public void backtrackLog (String logMessage) { log.info("回溯日志消息:{}" , logMessage); }
通过@PartitionOffset(initialOffset = "10")指定从某个
offset 开始消费,支持重新消费历史数据或跳过无效数据。
offset 规则:
initialOffset = "0":从分区的第一条消息开始消费(重新消费全量数据)。initialOffset = "100":从 offset 100 开始消费(跳过前
100 条消息)。
注意,该配置只在消费者组首次启动时生效;若已消费过(Kafka
保存了该组的 offset),需先删除 Kafka 中的消费组
offset,再重启消费者。
上述涉及到的消费者基础配置如下
配置项
推荐值
作用
spring.kafka.consumer.group-id服务名 + 功能(如order-service-payment)
避免不同服务共用一个组,导致消息被误消费
spring.kafka.listener.ack-modeMANUAL_IMMEDIATE核心业务用手动确认,非核心可用AUTO
spring.kafka.consumer.auto-offset-resetlatest(默认)首次启动时,只消费启动后的新消息;需回溯用earliest
spring.kafka.listener.concurrency等于主题分区数(如3)
并发数≤分区数(超过分区数的并发会空闲),提升消费速度
spring.kafka.consumer.max-poll-records100-500批量消费时控制单次拉取量,避免 OOM
编写控制器
最后就是编写接口了,发送消息
这个真没啥好说的,正常写然后调用就行
就是注意,一般情况下,会在发送消息的时候,设置创建时间
测试
我们简单的测试一下
来看一下服务的健康情况
image-20251102144503511
要注意确保Kafka默认在9092运行
先测试简单消息的发送
image-20251102144438949
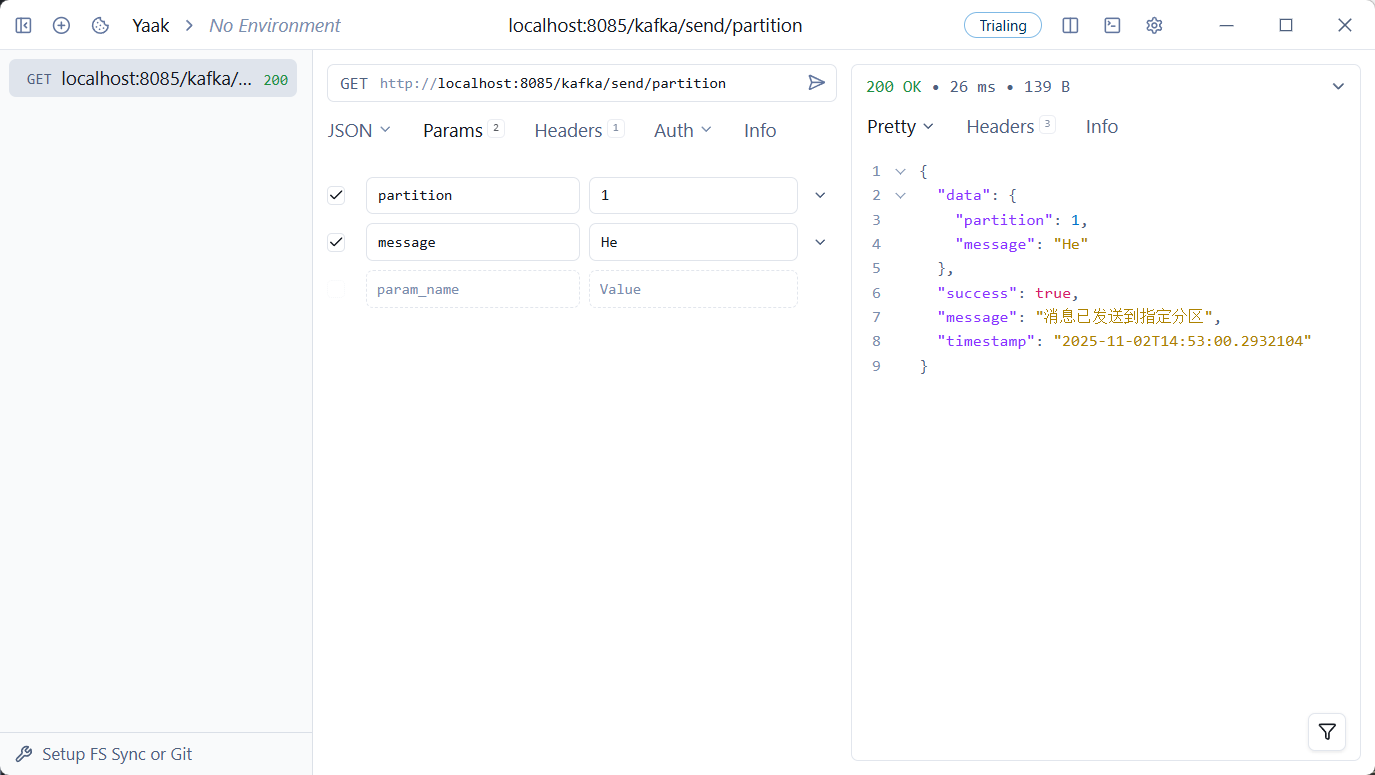
再测试带Key的消息
image-20251102144553033
相同Key的消息会发送到同一分区,便于保证顺序。
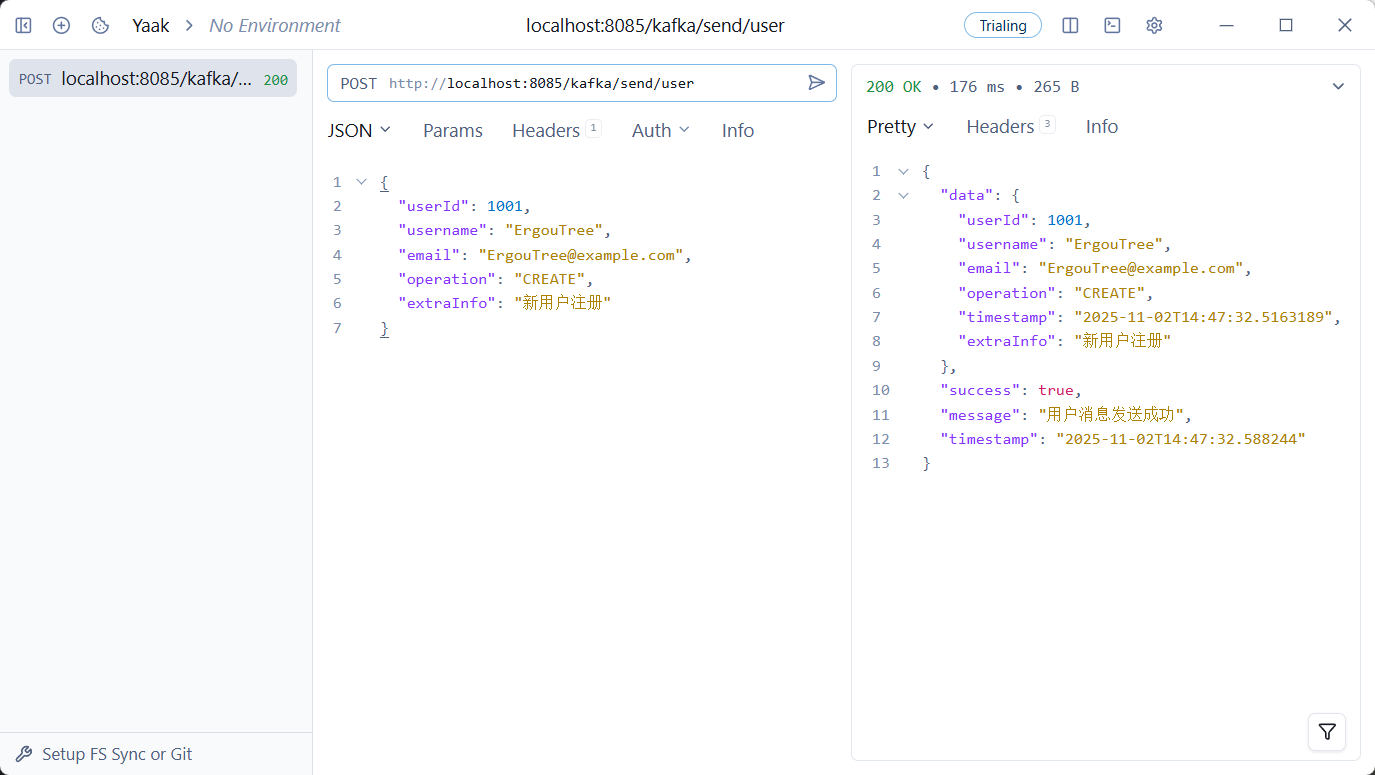
测试用户消息,也就是对象消息
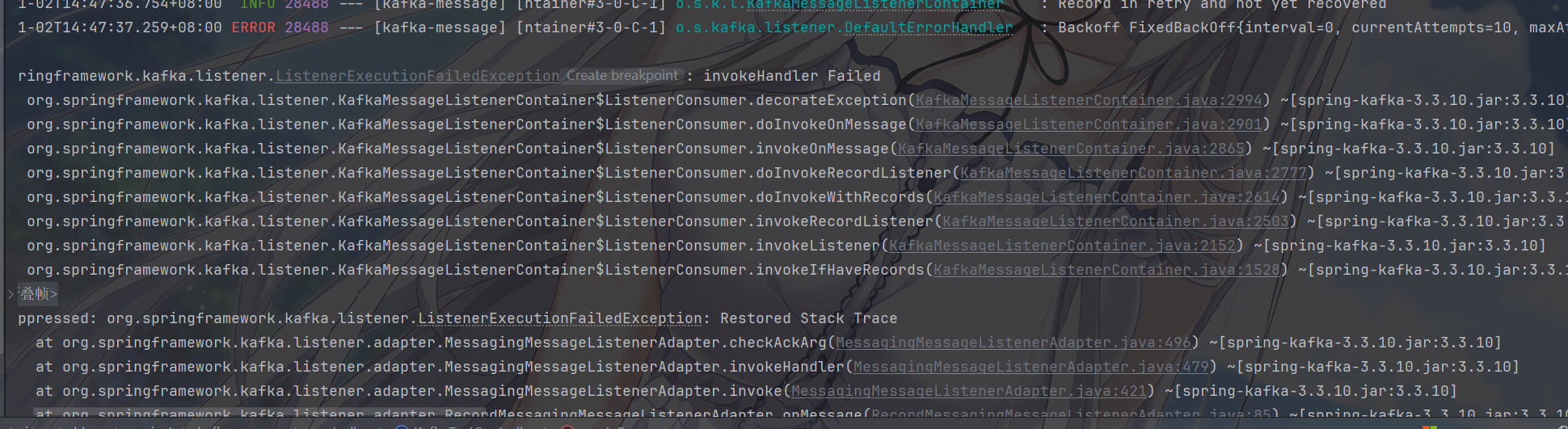
image-20251102144737618
这是同步发送的消息,阻塞线程到直到获取发送结果
别忘了,手动 ACK 使用了 Acknowledgment 参数,需要application.yml 中的
ack-mode 是 MANUAL,若指定了 containerFactory =
“kafkaListenerContainerFactory”,需要实现,我忘写了))
image-20251102145156914
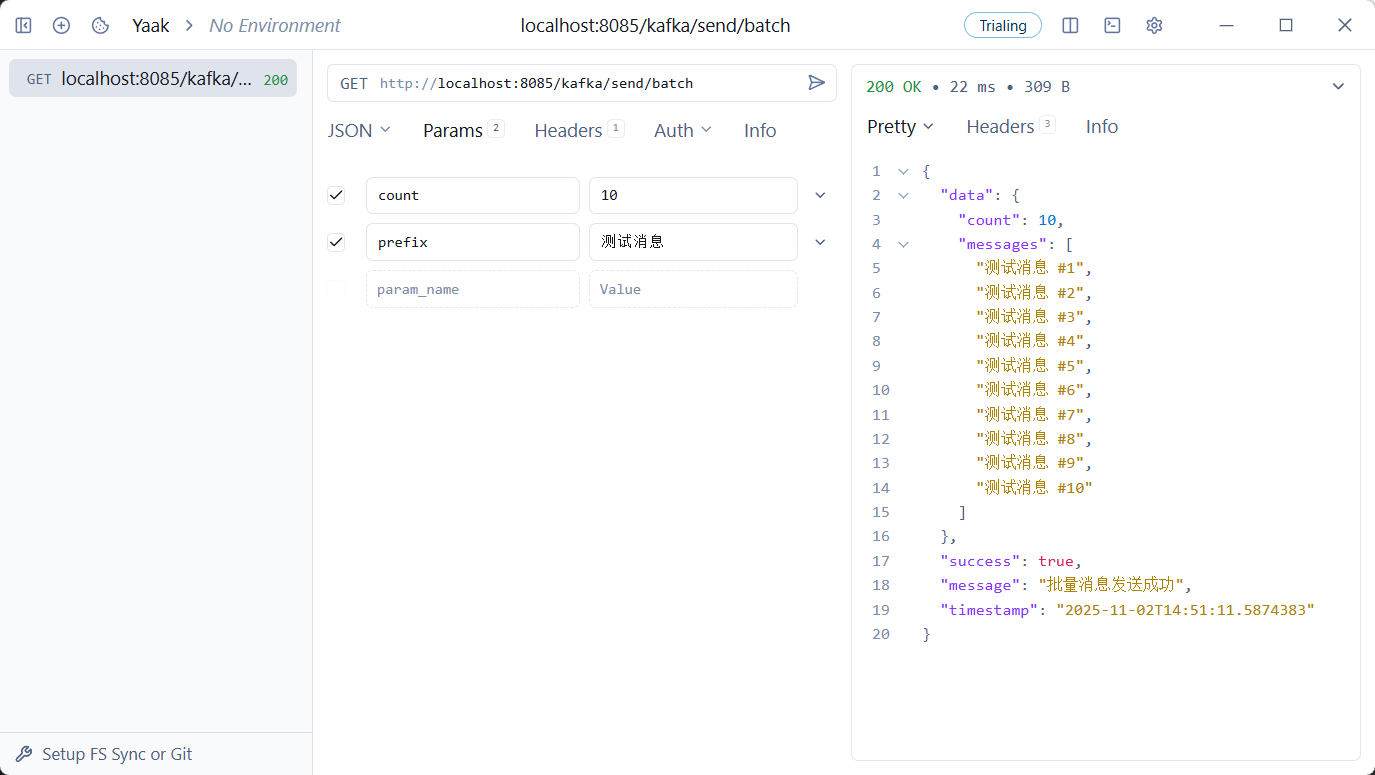
批量消息测试一下
image-20251102145126008
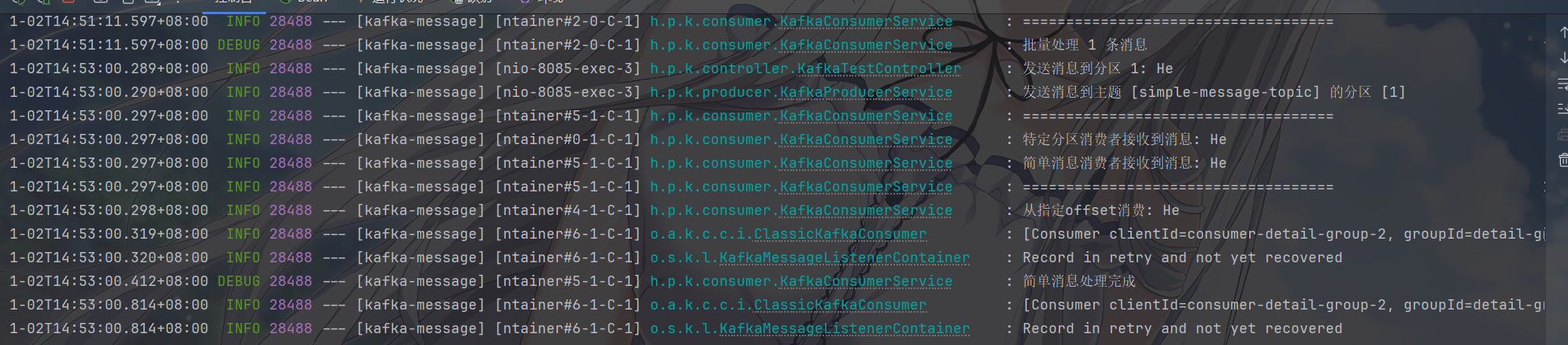
可以看到消息发送到了指定的分区
image-20251102145315279
image-20251102145341260
草,忘设置 key 了,下面爆了很多异常