
结构化查询语言SQL
关系数据模型
关系模型三要素:
- 关系数据结构
- 完整性约束
- 关系操作
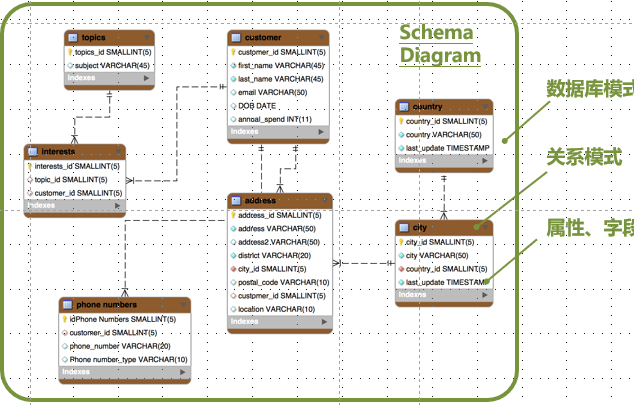
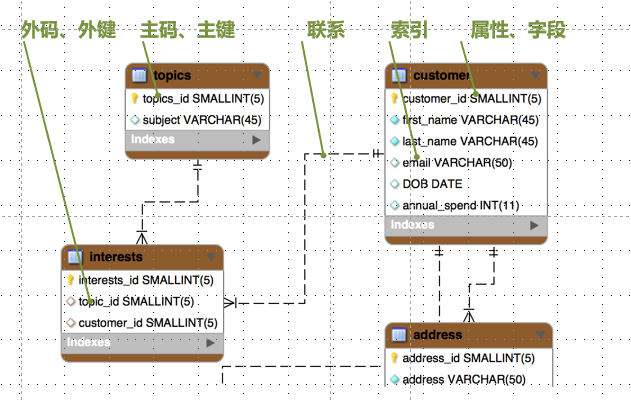
码:关系中某些属性集合具有区分不同元组的作用,称为码
- 超码:如果关系的某一组属性的值能唯一标识每个元组,则称该组属性为超码(super key)。
- 候选码:如果一个超码的任意真子集都不是超码,则称该超码为候选码。候选码是极小的超码。
- 主键:每个关系都有至少一个候选码,人为指定其中一个作为主键
- 外码:设 F 是关系 R 的属性子集。若 F 与关系 S 的主键 K 相对应,则称 F 是 R 的外键(foreign key)。
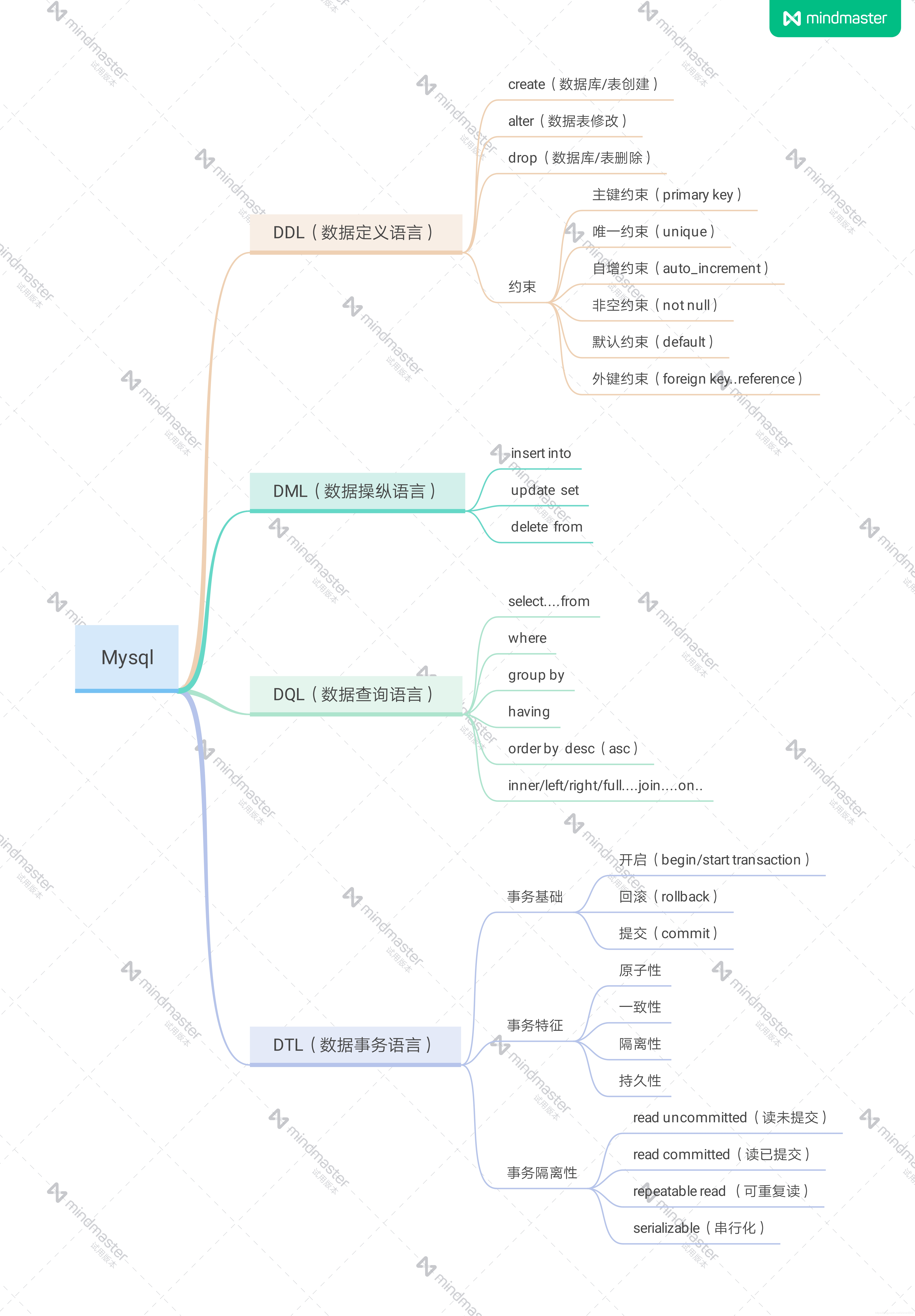
SQL分类
DDL:数据定义语言 定义了不同的数据库,表,视图,索引等数据库对象 还可以创建修改删除等操作数据库表的结构 CREATE ALTER DROP RENAME TRUMCATE
DML:数据操作语言 增删改查数据库记录 INSERT DELETE UPDATE SELECT
DCL:数据控制语言 定义数据库,表,字段,用户访问权限和安全级别的 COMMIT ROLLBACK SAVEPOINT
DQL:数据库查询语言 查询数据库中表的记录
DTL:数据库事务语言
SQL基本语法
SQL以分号结尾,可以用空格和缩进,windows不区分大小写,linux下大小写敏感,建议关键字大写
注释 –单行注释– # 单行注释
/* 多行注释*/
字符串类型和日期类型的数据可以用 ’’ 表示
列的别名,使用双引号 ”“ 不建议省略as
书写规范:
数据库名,表名,表别名,字段名,字段别名等小写
SQL关键字,函数名,绑定变量等大写
不能以SQL关键字来命名,如果要用,需要加上‘’着重号标记
DDL-数据定义语言
数据定义语言 定义了不同的数据库,表,视图,索引等数据库对象 还可以创建修改删除等操作数据库表的结构
DDL-数据库操作
查询数据库
1
SHOW DATABASES;
查询当前数据库
1
SELECT DATABASE{};
创建数据库
1
CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 指定使用的字符集] [COLLATE 指定排序规则];
删除数据库
1
DROP DATABASE [IF EXISTS] 数据库名;
使用数据库
1
USE 数据库名;
修改数据库
1
ALTER DATABASE 数据库名 修改部分;
表操作
DDL-表操作-查询
查询当前数据库所有表
1
SHOW TABLES
查询表结构
DESCRIBE 表名;简写如下1
DESC 表名;
SHOW CREATE TABLE语句会返回创建表时所用的 SQL 语句查询指定表的建表语句
1
SHOW CREATE TABLE 表名;
DDL-表操作-创建
利用 CREATE TABLE 创建表,必须给出下列信息:
- 新表的名字,在关键字 CREATE TABLE 之后给出;
- 表列的名字和定义,用逗号分隔;
1 | CREATE TABLE 表名{ |
快速复制表结构
1 | -- 只复制结构不复制数据 |
对于建表时候的对于字段指定的 NULL 和 NOT NULL,允许 NULL 值的列也允许在插入行时不给出该列的值。不允许 NULL 值的列不接受没有列值的行,换句话说,在插入或更新行时,该列必须有值。
1 | CREATE TABLE Orders |
SQL 允许指定默认值,在插入行时如果不给出值,DBMS 将自动采用默认值。默认值在 CREATE TABLE 语句的列定义中用关键字 DEFAULT 指定。
1 | CREATE TABLE OrderItems |
DDL-表操作-修改
更新表定义,可以使用 ALTER TABLE 语句
理想情况下,不要在表中包含数据时对其进行更新。
1 | ALTER TABLE 表名 ADD|DROP|MODIFY|CHANGE 字段名 类型 (长度) [COMMENT 注释] [约束]; |
添加字段
1
ALTER TABLE 表名 ADD 字段名 类型 (长度) [COMMENT 注释] [约束];
案例:
emp表添加一个新的字段 昵称为 nickname 类型 varchar(20)
1
ALTER TABLE emp ADD nickname VARCHAR(20) COMMENT "昵称";
修改数据类型
1
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
修改字段名和字段类型
1
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
删除字段
1
ALTER TABLE 表名 DROP 字段名;
修改表名
1
ALTER TABLE 表名 RENAME TO 新表名;
添加 / 删除 主键
1
2ALTER TABLE users ADD PRIMARY KEY (id);
ALTER TABLE users DROP PRIMARY KEY;
DDL-表操作-删除
删除表(删除整个表本身而不止是其内容)非常简单,使用 DROP TABLE 语句即可:
删除表
1
DROP TABLE [IF EXIST] 表名;
删除指定表,并重新创建
1
TRUNCATE TABLE 表名;
DDL-表操作-重命名表
使用 RENAME 语句
所有重命名操作的基本语法都要求指定旧表名和新表名。
DML-数据操作语言
数据操作语言 增删改查数据库记录
- 添加数据 INSERT
- 修改数据 UPDATE
- 删除数据 DELETE
DML-插入
顾名思义,INSERT 用来将行插入(或添加)到数据库表。插入有几种方式:
- 插入完整的行;
- 插入行的一部分;
- 插入某些查询的结果。
下面逐一介绍这些内容
给指定的字段添加数据
1
INSERT INTO (字段名1,字段名2) VALUES (值1,值2。。)
给全部字段添加数据
1
INSERT INTO 表名 VALUES (值1,值2。。)
批量添加数据
1
2
3INSERT INTO 表名 (字段名1,字段名2。。。) VALUES (值1,值2...) (值1,值2...) (值1,值2...);
INSERT INTO 表名 VALUES (值1,值2...) (值1,值2...) (值1,值2...);插入检索出的数据
INSERT一般用来给表插入具有指定列值的行。INSERT还存在另一种形式,可以利用它将SELECT语句的结果插入表中,这就是所谓的INSERT SELECT。顾名思义,它是由一条INSERT语句和一条SELECT语句组成的。1
2
3INSERT INTO Customers(cust_id, cust_contact, cust_email)
SELECT cust_id, cust_contact, cust_email,
FROM CustNew;
注意:
- 插入数据时,指定的字段顺序需要与值的顺序一一对应
- 字符串和日期的数据类型都应该包含在引号中
- 插入的数据大小,应该在这个字段的范围内
DML-修改
基本的 UPDATE 语句由三部分组成,分别是:
- 要更新的表;
- 列名和它们的新值;
- 确定要更新哪些行的过滤条件。
修改数据表中的字段值:
1 | UPDATE 表名 SET 字段名1=值1,字段名2=值2..... [WHERE 条件]; |
- 修改语句的条件可以有,如果没有就是针对整张表
- 所以说,在使用 UPDATE 时一定要细心。因为稍不注意,就会更新表中的所有行。
例如,
1 | UPDATE Customers |
更新多个列的语法稍有不同:
1 | UPDATE Customers |
- 在更新多个列时,只需要使用一条 SET
命令,每个
列=值对之间用逗号分隔
UPDATE 语句中可以使用子查询,使得能用 SELECT 语句检索出的数据更新列数据。
DML-删除
删除数据表中的数据
1 | DELETE FROM 表名 [WHERE 条件]; |
- DELETE 的条件可以有,如果没有,就是删除整张表的数据
- 在使用 DELETE 时一定要细心。因为稍不注意,就会错误地删除表中所有行。
- DELETE 不能删除某一个字段的值,可以用UPDATE
DQL-数据查询语言
数据查询语言,查询数据库中表的记录
- 关键字 SELECT
DQL 语法
1 | SELECT |
DQL-基础查询
检索单个列
1 | SELECT |
查询多个字段
SELECT 关键字后列出多个逗号分隔的字段
1 | SELECT 字段1,子段2。。。 FROM 表名; |
整表查询
*代表所有列
1 | SELECT * FROM 表名; |
设置别名
1 | SELECT 字段1 [AS 别名1],字段2 [AS 别名2] ... FROM 表名; |
- as 列的别名可以用一对“”引起来
去除重复记录
只返回具有唯一性的行
1 | SELECT DISTINCT 字段列表 FROM 表名; |
限制结果
如果你只想返回第一行或者一定数量的行。这是可行的,然而遗憾的是,各种数据库中的这一 SQL 实现并不相同。
MySQL 使用 LIMIT,例如下面语句就只检索前 5 行数据
1 | SELECT * FROM 表名 LIMIT 5; |
查询常数
查询常数指的是在查询结果里返回固定值,而非从表字段获取数据
1 | SELECT '这是一个常数' AS constant_value; |
假定有一个 employees 表,包含 id 和
name 字段,你能够在查询结果里既显示表数据,又显示常数。
1 | SELECT id, name, '固定部门' AS department FROM employeses; |
此查询会返回 employees 表中的 id 和
name 字段,同时为每一行添加一个名为 department
的列,其值均为 固定部门。
DQL-条件查询
使用 WHERE 子句
数据库表一般包含大量的数据,很少需要检索表中的所有行。通常只会根据特定操作或报告的需要提取表数据的子集。只检索所需数据需要指定搜索条件(search criteria),搜索条件也称为过滤条件(filter condition)。
WHERE
子句用于过滤记录,即缩小访问数据的范围。而且WHERE 可以与
SELECT,UPDATE 和 DELETE
一起使用。
WHERE 后跟一个返回 true 或
false 的条件。
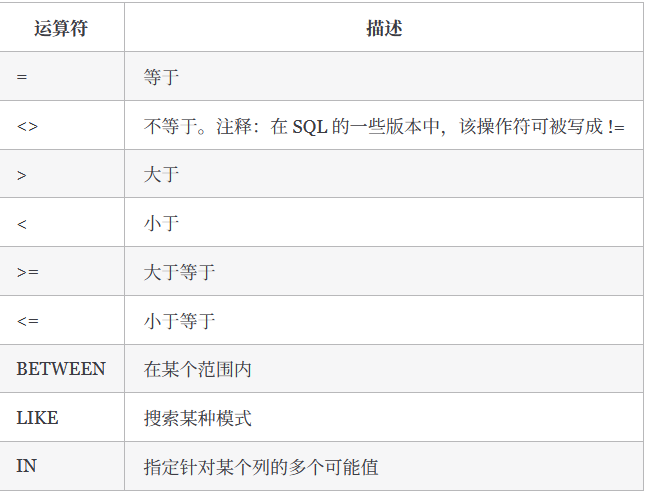
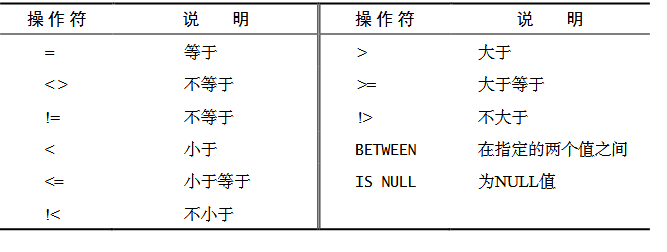
可以在 WHERE 子句中使用的操作符。
基本语句如下
1 | SELECT 字段列表 |
在同时使用
ORDER BY和WHERE子句时,应该让ORDER BY位于WHERE之后,否则将会产生错误
检查单个值
1 | SELECT prod_name, prod_price |
单引号用来限定字符串。如果将值与字符串类型的列进行比较,就需要限定引号。用来与数值列进行比较的值不用引号。
使用别名
别名(alias)是一个字段或值的替换名。别名用 AS 关键字赋予
SELECT
语句本身与以前使用的相同,只不过这里的计算字段之后跟了文本AS vend_title。它指示
SQL 创建一个包含指定计算结果的名为vend_title
的计算字段。从输出可以看到,结果与以前的相同,但现在列名为
vend_title,任何客户端应用都可以按名称引用这个列,就像它是一个实际的表列一样。
1 | SELECT RTRIM(vend_name) || ' (' || RTRIM(vend_country) || ')' AS vend_title |
别名的名字既可以是一个单词,也可以是一个字符串。如果是后者,字符串应该括在引号中。虽然这种做法是合法的,但不建议这么去做。多单词的名字可读性高,不过会给客户端应用带来各种问题。因此,别名最常见的使用是将多个单词的列名重命名为一个单词的名字。
比较运算符
等于:
=不等于:
<> 或!=大于:
>小于:
<大于等于:
>=小于等于:
<=BETWEEN...AND:范围查询,BETWEEN之后跟最小值,AND之后跟着最大值IN:在IN之后的列表中的值,多选一IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN取一组由逗号分隔、括在圆括号中的合法值1
2
3
4SELECT prod_name, prod_price
FROM Products
WHERE vend_id IN ('DLL01','BRS01')
ORDER BY prod_name;你可能会猜测 IN 操作符完成了与 OR 相同的功能,恭喜你猜对了
LIKE:模糊匹配,通配符如下_匹配单个字符,下划线的用途与%一样,但它只匹配单个字符,而不是多个字符。%匹配多个字符,%表示任何字符出现任意次数。
1
2
3
4
5
6
7
8-- 查询名字包含"张"的员工
SELECT * FROM employee WHERE name LIKE '%张%';
-- 查询名字以"张"开头且长度为3的员工
SELECT * FROM employee WHERE name LIKE '张__';
-- 查询手机号第二位是5的员工
SELECT * FROM employee WHERE phone LIKE '_5%';IS NULL:为 null 值1
2
3
4
5
6
7
8-- 查询奖金为NULL的员工
SELECT * FROM employee WHERE bonus IS NULL;
-- 查询奖金不为NULL的员工
SELECT * FROM employee WHERE bonus IS NOT NULL;
-- 使用IFNULL处理NULL值
SELECT name, salary, IFNULL(bonus, 0) AS total_income FROM employee;
逻辑运算符
为了进行更强的过滤控制,SQL 允许给出多个 WHERE 子句。这些子句有两种使用方式,即以 AND 子句或 OR 子句的方式使用。
AND/&&与要通过不止一个列进行过滤,可以使用 AND 操作符给 WHERE 子句附加条件。
1
2
3SELECT prod_id, prod_price, prod_name
FROM Products
WHERE vend_id = 'DLL01' AND prod_price <= 4;OR/||或OR操作符与AND操作符正好相反,它指示 DBMS 检索匹配任一条件的行。事实上,许多 DBMS 在
OR WHERE子句的第一个条件得到满足的情况下,就不再计算第二个条件了1
2
3SELECT prod_id, prod_price, prod_name
FROM Products
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';NOT/!非WHERE子句中的NOT操作符有且只有一个功能,那就是否定其后所跟的任何条件。因为NOT从不单独使用1
2
3
4SELECT prod_name
FROM Products
WHERE NOT vend_id = 'DLL01'
ORDER BY prod_name;
1 | -- 查询年龄 |
而组合 AND 和 OR 会带来了一个求值顺序问题,别忘了使用圆括号对操作符进行明确分组
1 | SELECT prod_name, prod_price |
计算字段
字段拼接
存储在数据库表中的数据一般不是应用程序所需要的格式,所以我们可能需要拼接字段
1 | SELECT vend_name || '(' || vend_country || ')' |
使用,||或者Concat(字段1,字段2,...)这样进行拼接
再看看上述 SELECT
语句返回的输出。结合成一个计算字段的两个列用空格填充。许多数据库(不是所有)保存填充为列宽的文本值,而实际上你要的结果不需要这些空格。为正确返回格式化的数据,必须去掉这些空格。这可以使用
SQL 的 RTRIM()函数来完成,如下所示:
1 | SELECT RTRIM(vend_name) || ' (' || RTRIM(vend_country) || ')' |
对字段算术运算
计算字段的另一常见用途是对检索出的数据进行算术计算。
举个例子,Orders
表包含收到的所有订单,OrderItems
表包含每个订单中的各项物品。下面的 SQL 语句检索订单号 20008
中的所有物品:
1 | SELECT prod_id, quantity, item_price |
item_price 列包含订单中每项物品的单价。
1 | SELECT prod_id, quantity, item_price, quantity * item_price AS expanded_price |
输出中显示的 expanded_price 列是一个计算字段,此计算为
quantity*item_price。客户端应用现在可以使用这个新计算列,就像使用其他列一样。

圆括号依旧可用来区分优先顺序。
DQL-聚合函数
我们经常需要汇总数据,而往往不需要它们的具体内容,此 SQL 提供了专门的函数,使用这些函数,SQL 查询可用于检索数据,以便分析和报表生成
那么这种函数就是聚合函数,一列数据作为一个整体,纵向计算,聚合函数都是作用于表的某一列
为方便这种类型的检索,SQL 给出了 5 个聚合函数
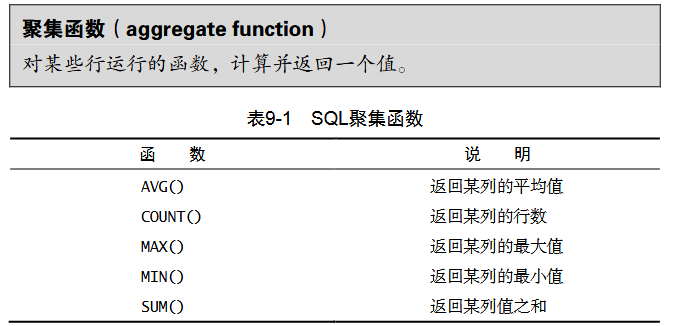
以上 5 个聚集函数都可以如下使用:
1 | -- 对所有行执行计算,指定 ALL 参数或不指定参数 |
如果发现需要聚集不同值的情况:
- 对所有行执行计算,指定 ALL 参数或不指定参数。
- 只计算不同的值,指定 DISTINCT 参数。
对于上述的描述,做如下例子
1 | SELECT AVG(DISTINCT prod_price) AS avg_price |
DISTINCT不能用于COUNT(*),如果指定列名,则DISTINCT只能用于COUNT()。类似地,DISTINCT必须使用列名,不能用于计算或表达式。
NULL 不参与聚合函数的计算,空值参与运算,结果一定为空
1 | -- 查询总数据 |
DQL-分组查询
理解分组
目前为止的所有计算都是在表的所有数据或匹配特定的 WHERE
子句的数据上进行的。
分组是使用 SELECT 语句的 GROUP BY
子句建立的:GROUP BY
语句:
1 | SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件]; |
理解分组的最好办法是看一个例子:
1 | SELECT vend_id, COUNT(*) AS num_prods |
上面的
SELECT语句指定了两个列:vend_id包含产品供应商的 ID,num_prods为计算字段,用COUNT(*)函数建立。而GROUP BY子句指示 DBMS 按vend_id排序并分组数据。这就会对每个vend_id而不是整个表计算num_prods一次。什么意思,可以把
GROUP BY vend_id理解成,把表中「同一个供应商vend_id」的所有行,打包成一个组例如有下面这样的表
prod_id(产品 ID) vend_id(供应商 ID) prod_name(产品名) 1001 A01 鼠标 1002 A01 键盘 1003 B02 显示器 1004 B02 主机 1005 B02 音箱 1006 C03 耳机 对应上面的表,会被分成 3 个小组:
- 小组 1:vend_id = A01 → 包含 2 行(鼠标、键盘)
- 小组 2:vend_id = B02 → 包含 3 行(显示器、主机、音箱)
- 小组 3:vend_id = C03 → 包含 1 行(耳机)
分组过滤
在这个例子中 WHERE 不能完成任务,因为 WHERE
过滤指定的是行而不是分组。事实上,WHERE
没有分组的概念。
那么,分组也可以过滤,SELECT 过滤使用
WHERE,GROUP BY 过滤使用
HAVING
WHERE 与 HAVING 区别
- 执行实际不同:
WHERE是分组前进行过滤,不满足WHERE条件不参与分组;HAVING是分组后对结果过滤 - 判断条件不同:
WHERE不能对聚合函数判断,HAVING可以
执行顺序 where > 聚合函数 > having
分组之后,查询的字段一般为聚合函数和分组字段,其他字段无意义
1 | SELECT name,gender,COUNT(*) FROM employee GROUP BY gender; |
1 | -- 根据性别分组统计男女员工数量 |
分组和排序
而且 GROUP BY 和 ORDER BY 经常完成相同的工作,但它们非常不同,理解这一点很重要。
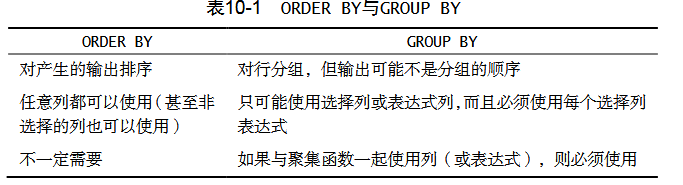
为说明 GROUP BY 和 ORDER BY 的使用方法,来看一个例子。
1 | SELECT order_num, COUNT(*) AS items |
要按订购物品的数目排序输出,需要添加 ORDER BY 子句,如下所示
1 | SELECT order_num, COUNT(*) AS items |
最后写一个题来模拟一下分组:确定最佳顾客的另一种方式是看他们花了多少钱。编写
SQL 语句,返回总价至少为 1000
的所有订单的订单号(OrderItems
表中的order_num)。提示:需要计算总和(item_price
乘以 quantity)。按订单号对结果进行排序。
1 | SELECT order_num, SUM(item_price * quantity) AS total_consume |
DQL-排序查询
为了明确地排序用 SELECT 语句检索出的数据,可使用
ORDER BY 子句。ORDER BY
子句取一个或多个列的名字,据此对输出进行排序。
1 | SELECT 字段列表 |
支持多字段排序,如果是多字段排序,当第一个字段值相同时候会按照第二个这样依次进行排序
通常,ORDER BY
子句中使用的列将是为显示而选择的列。但是,实际上并不一定要这样,用非检索的列排序数据是完全合法的。你完全可以按照一个没有被涉及到查询的列进行排序。
排序方式
- ASC 升序,默认,小的在前面
- DESC 降序,大的在前面
1 | -- 排序查询 |
而且 ORDER BY 还支持按相对列位置进行排序
1 | SELECT prod_id, prod_price, prod_name |
SELECT 清单中指定的是选择列的相对位置而不是列名下,
ORDER BY 2表示按 SELECT 清单中的第二个列prod_price进行排序。ORDER BY 2,3表示先按prod_price,再按prod_name进行排序。如果进行排序的列不在 SELECT 清单中,显然不能使用这项技术。
DQL-分页查询
1 | SELECT 字段列表 FROM 表名 LIMIT 起始索引, 每页记录数; |
注意:
起始索引从0开始,起始索引 = (查询页码-1)*每页显示记录数
分页查询是数据库的方言,不同的数据库之间不同,
mysql中是LIMIT如果查询的第一页数据,起始索引可以省略,直接简写
DQL-执行顺序
编写顺序
1 | SELECT |
执行顺序
- FROM 决定我要查询那一张表
- WHERE 指定查询的条件
- GROUP BY 和 HAVING 指定分组
- SELECT 字段列表
- ORDER BY 指定排序
- LIMIT 指定分页
DCL-数据控制语言
主要用来管理数据库的用户,控制数据库的访问权限
DCL–管理用户
本质上是对user表的修改
主机名可以用%通配
查询用户
1 | USE mysql; |
- 主机地址和用户名才能定位一个用户,本质上是查询user表
创建用户
1 | CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY '密码'; |
CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
修改用户密码
1 | ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码'; |
删除用户
1 | DROP USER ‘用户名’@‘主机名’; |
DCL-权限控制
MySQL中定义了多种权限,常用的就这些
ALL, ALL PRIVILEGES 所有权限
SELECT 查询数据
INSERT 插入数据
UPDATE 修改数据
DELETE 删除数据
ALTER 修改表
DROP 删除数据库/表/视图
CREATE 创建数据库/表
查询权限
1 | SHOW GRANTS FOR '用户名'@'主机名'; |
授予权限
1 | GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; |
撤销权限
1 | REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'; |
注意:
- 多个权限之间,使用逗号分隔
- 授权时,数据库名和表名可以使用*进行通配,代表所有
多表查询
多表关系
一对多 / 多对一:多的一方建立外键作为关联字段,指向一的一方的主键
多对多:建立第三张表,中间表至少包含两个外键,分别关联两方主键
一对一:拆分表
在任意一方加入外键,管理另外一方的主键,并且设置为UNIQUE
内连接
查询表1,表2 交集部分数据
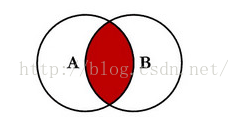
这种场景下得到的是满足某一条件的A,B内部的数据;正因为得到的是内部共有数据,所以连接方式称为内连接。
隐式内连接
1 | SELECT 字段列表 FROM 表1,表2 WHERE 筛选条件; |
显式内连接
1 | SELECT 字段列表 FROM 表1 INNER JOIN 表2 ON 连接条件; |
示例:
1 | -- 题目 1:查询每个用户的角色ID列表 |
使用 WHERE 子句建立联结关系似乎有点奇怪,但实际上是有个很充分的理由的。
WHERE 子句作为过滤条件,只包含那些匹配给定条件(这里是联结条件)的行。没有 WHERE 子句,第一个表中的每一行将与第二个表中的每一行配对,而不管它们逻辑上是否能配在一起。
外连接
许多联结将一个表中的行与另一个表中的行相关联,但有时候需要包含没有关联行的那些行。
联结包含了那些在相关表中没有关联行的行。这种联结称为外联结。

左右外连接
左外连接
左外连接查询左表所有数据,以及两张表交集部分数据
左外连接相当于查询表A(左表)的所有数据和中间绿色的交集部分的数据。
表1的位置为左表,表2的位置为右表
1 | SELECT 字段列表 |
右外连接
右外连接查询左表所有数据,以及两张表交集部分数据
右外连接相当于查询表B(右表)的所有数据和中间绿色的交集部分的数据。
表1的位置为左表,表2的位置为右表
1 | SELECT 字段列表 |
自连接
自连接是指将一张表与自身进行连接操作。通常用于处理表中存在层级关系或递归关系的数据。
如前所述,使用表别名的一个主要原因是能在一条 SELECT
语句中不止一次引用相同的表。
所以在自连接中,我们需要为同一张表创建两个别名(如 p1 和
p2),然后通过某种条件将这两个别名关联起来。
自连接表一定要起别名
对于自连接查询,可以是内连接查询,也可以是外连接查询。
连接条件通常是父子关系字段
1 | SELECT 字段列表 |
示例:
1 | -- permission_id:权限的唯一标识。 parent_permission_id:当前权限的父权限 ID。 |
连接条件:对于 p1 中的每个权限(父权限),查找
p2 中所有 parent_permission_id 等于该权限 ID
的记录(子权限)
- 使用
INNER JOIN时,只会返回有子权限的父权限。 - 使用
LEFT JOIN时,会返回所有父权限,即使它们没有子权限。
1 | -- 查询员工及其直接上级 |
自然连接
无论何时对表进行联结,应该至少有一列不止出现在一个表中。
标准的联结返回所有数据,相同的列甚至多次出现。自然联结排除多次出现,使每一列只返回一次。
怎样完成这项工作呢?
答案是,系统不完成这项工作,由你自己完成它。
自然联结要求你只能选择那些唯一的列,一般通过对一个表使用通配符SELECT *,而对其他表的列使用明确的子集来完成。
1 | SELECT C.*, O.order_num, O.order_date, OI.prod_id, OI.quantity, OI.item_price |
在这个例子中,通配符只对第一个表使用。所有其他列明确列出,所以没有重复的列被检索出来。
事实上,我们迄今为止建立的每个内联结都是自然联结,很可能永远都不会用到不是自然联结的内联结。
JOIN 和 ON
JOIN 是“连接”的意思,顾名思义,JOIN 子句用于将两个或者多个表联合起来进行查询。
连接表时需要在每个表中选择一个字段,并对这些字段的值进行比较,值相同的两条记录将合并为一条。连接表的本质就是将不同表的记录合并起来,形成一张新表。当然,这张新表只是临时的,它仅存在于本次查询期间。
1 | SELECT c.name, o.name FROM customers c JOIN orders o ON c.cust_id == o.cust_id ORDER BY c.name; |
当两个表中有同名的字段时,为了帮助数据库引擎区分是哪个表的字段,在书写同名字段名时需要加上表名。
另外,如果两张表的关联字段名相同,也可以使用
USING子句来代替 ON,改写上面的例子:
1 | SELECT c.name, o.name FROM customers c JOIN orders o USING(cust_id) ORDER BY c.name; |
ON 和 WHERE 的区别:
- 连接表时,SQL 会根据连接条件生成一张新的临时表。
ON就是连接条件,它决定临时表的生成。 WHERE是在临时表生成以后,再对临时表中的数据进行过滤,生成最终的结果集,这个时候已经没有 JOIN-ON 了。
所以总结来说就是:SQL 先根据 ON 生成一张临时表,然后再根据 WHERE 对临时表进行筛选。
SQL 允许在 JOIN
左边加上一些修饰性的关键词,从而形成不同类型的连接,就是上面提到的多表查询
对了,如果不加任何修饰词,只写 JOIN,那么默认为
INNER JOIN,返回两张表字段共有的列
联合查询(组合查询)
多数 SQL 查询只包含从一个或多个表中返回数据的单条 SELECT
语句。但是,SQL 也允许执行多个查询,也就是多条 SELECT
语句,并将结果作为一个查询结果集返回。
主要有两种情况需要使用组合查询:
- 在一个查询中从不同的表返回结构数据;
- 对一个表执行多个查询,按一个查询返回数据。
可用UNION
运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自
UNION 中参与查询的提取行。
1 | SELECT 字段列表 FROM 表A |
UNION ALL会将全部的数据合并,默认的UNION会对合并后的数据去重,对 NULL 也会处理
例如,假如需要 Illinois、Indiana 和 Michigan 等美国几个州的所有顾客的报表,还想包括不管位于哪个州的所有的 Fun4All 这位顾客的。
1 | SELECT cust_name, cust_contact, cust_email |
UNION 基本规则:
UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔,因此,如果组合四条SELECT语句,将要使用三个UNION关键字)。- 所有查询的列数和列顺序必须相同。
- 每个查询中涉及表的列的数据类型必须相同或兼容。
UNION结果集中的列名总是等于UNION中第一个SELECT语句中的列名。
JOIN vs UNION:
JOIN中连接表的列可能不同,但在UNION中,所有查询的列数和列顺序必须相同。UNION将查询之后的行放在一起(垂直放置),但JOIN将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积
对组合查询结果排序,SELECT 语句的输出用
ORDER BY 子句排序。在用 UNION
组合查询时,只能使用一条 ORDER BY子句,它必须位于最后一条
SELECT
语句之后。对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一
部分的情况,因此不允许使用多条 ORDER BY 子句。
下面的例子对前面 UNION 返回的结果进行排序:
1 | SELECT cust_name, cust_contact, cust_email |
子查询
使用子查询
子查询是嵌套在较大查询中的 SQL
查询,也称内部查询或内部选择,包含子查询的语句也称为外部查询或外部选择。简单来说,子查询就是指将一个
SELECT 查询(子查询)的结果作为另一个 SQL
语句(主查询)的数据来源或者判断条件。
子查询是指嵌套在另一个 SQL 语句中的 SELECT 查询。
查询可以嵌入
SELECT、INSERT、UPDATE 和
DELETE 语句中,也可以和
=、<、>、IN、BETWEEN、EXISTS
等运算符一起使用。
- 子查询外部的语句可以是
INSERTUPDATEDELETESELECT中的任意一个 - 标量子查询:子查询结果为单个值
- 列字查询:子查询结果为一列
- 行子查询:子查询结果为一行
- 表子查询:子查询结果为多行多列
而且它也可以出现在
WHERE、FROM、SELECT
等子句中,用于提供额外的数据过滤或计算条件。
- 当用于
WHERE子句时,根据不同的运算符,子查询可以返回单行单列、多行单列、单行多列数据。子查询就是要返回能够作为WHERE子句查询条件的值。 - 当用于
FROM子句时,一般返回多行多列数据,相当于返回一张临时表,而且需要使用 AS 关键字为该临时表起一个名字,这样才符合FROM后面是表的规则。这种做法能够实现多表联合查询。
子查询必须用括号 () 包裹
NULL 值处理:子查询返回 NULL 可能导致意外结果,需用
IS NULL 或 COALESCE 处理
1 | SELECT * FROM 表1 WHERE 字段列表1 = (SELECT 字段列表 FROM 表2) |
现在,假如需要列出订购物品 RGAN01 的所有顾客,应该怎样检索?
首先,我们肯定要检索包含物品 RGAN01 的所有订单的编号,再检索这些订单编号的所有顾客的 ID,再根据这些顾客 ID 来检索顾客信息。
1 | -- 第一条 SELECT 语句的含义很明确,它对 prod_id 为 RGAN01 的所有订单物品,检索其 order_num 列 |
那么,上面三步可以写到一起,作为一个子查询
1 | SELECT cust_name, cust_contact |
作为计算字段使用子查询
使用子查询的另一方法是创建计算字段。假如需要显示 Customers 表中每个顾客的订单总数。订单与相应的顾客 ID 存储在 Orders 表中。
那么,执行这个操作,要遵循下面的步骤:先从 Customers 表中检索顾客列表,然后对于检索出的每个顾客,统计其在 Orders 表中的订单数目。
1 | SELECT cust_name, |
子查询中的 WHERE 子句与前面使用的 WHERE 子句稍有不同,因为它使用了完全限定列名 , 而不只是列名,用一个句点分隔表名和列名,在有可能混淆列名时必须使用这种语法。
标量子查询
- 特点:返回单个值(一行一列)
- 常见场景:作为条件判断、赋值或计算的一部分
示例:查询工资高于平均工资的员工
1 | SELECT emp_name, salary |
- 子查询
(SELECT AVG(salary) FROM employees)返回一个标量值(平均工资) - 主查询通过
>比较每个员工的工资与平均值
列子查询(Column Subquery)
- 特点:返回一列多行的数据
- 常用操作符:
IN,NOT IN,ANY,ALL
示例:查询所有部门经理的员工信息
1 | SELECT * |
行子查询(Row Subquery)
- 特点:返回一行多列的数据
- 常用操作符:
=,<>,ALL
示例:查询与某个员工(ID=1001)部门和职位都相同的其他员工
1 | SELECT * |
- 子查询返回
emp_id=1001的员工的部门和职位信息 - 主查询使用行比较
(col1, col2) = (val1, val2)匹配条件
表子查询(Table Subquery)
- 特点:返回多行多列的数据(类似临时表)
- 常用位置:FROM 子句中,需使用别名
示例:查询每个部门的平均工资,并按降序排列
1 | SELECT dept_name, avg_salary |
- 子查询计算每个部门的平均工资
- 主查询将子查询结果(临时表
t)与部门表连接,获取部门名称
子查询中 EXISTS
EXISTS:子查询是否返回任何行。如果子查询返回至少一行,则EXISTS条件为真,外层查询将根据这个结果进行相应的操作。
EXISTS只关心子查询是否有结果返回,而不关心返回的具体内容
1 | SELECT columns |
1 | -- 查询有下属的员工 |
子查询与连接(JOIN)的对比
子查询和连接都可以实现多表数据关联,但适用场景不同:
| 子查询 | 连接(JOIN) |
|---|---|
| 适合单值条件过滤 | 适合多表数据关联展示 |
| 逻辑上更直观(分步处理) | 性能通常更高(优化器优化) |
| 可能导致多次执行子查询 | 通常一次性扫描所有表 |
示例对比:查询每个部门的经理姓名(子查询 vs JOIN)
1 | -- 子查询 |
使用联结和联结条件
在总结讨论联结的这两课前,有必要汇总一下联结及其使用的要点。
- 注意所使用的联结类型。一般我们使用内联结,但使用外联结也有效。
- 关于确切的联结语法,应该查看具体的文档,看相应的 DBMS 支持何种语法(大多数 DBMS 使用这两课中描述的某种语法)。
- 保证使用正确的联结条件(不管采用哪种语法),否则会返回不正确的数据。
- 应该总是提供联结条件,否则会得出笛卡儿积。
- 在一个联结中可以包含多个表,甚至可以对每个联结采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前分别测试每个联结。这会使故障排除更为简单。
函数
不同数据库的函数往往各不相同,因此不可移植。本节主要以 MySQL 的函数为例
文本处理
SQL 常用的文本处理函数
LEFT()、RIGHT() |
左边或者右边的字符 |
|---|---|
LOWER()、UPPER() |
转换为小写或者大写 |
LTRIM()、RTRIM() |
去除左边或者右边的空格 |
LENGTH() |
长度,以字节为单位 |
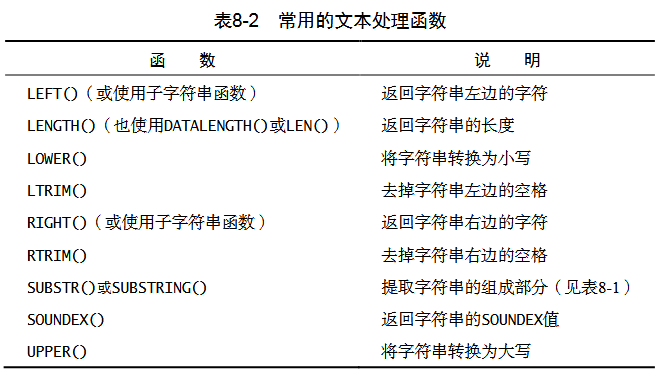
虽然 SOUNDEX() 不是 SQL 概念,但多数 DBMS 都提供对
SOUNDEX() 的支持。额额,确实 PostgreSQL 不支持
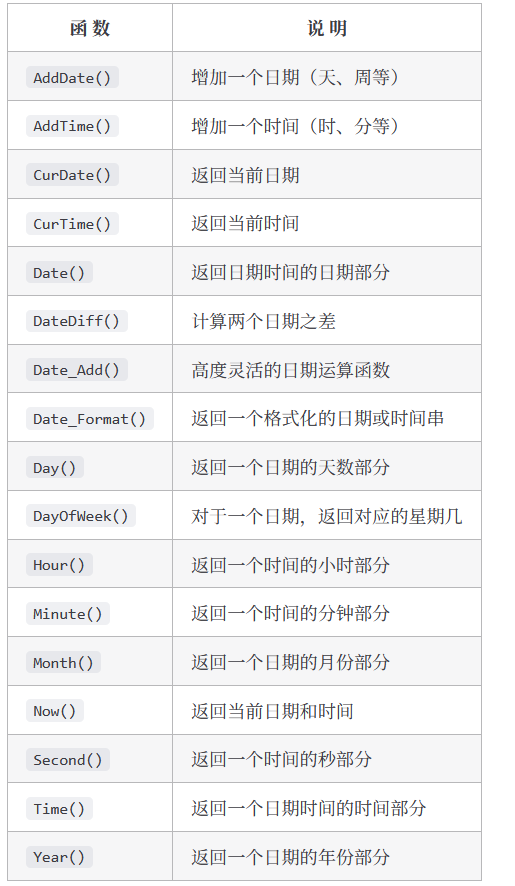
日期和时间处理
日期和时间采用相应的数据类型存储在表中,每种 DBMS 都有自己的特殊形式。
日期和时间值以特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
MySQL支持的:https://dev.mysqlserver.cn/doc/refman/8.4/en/date-and-time-functions.html
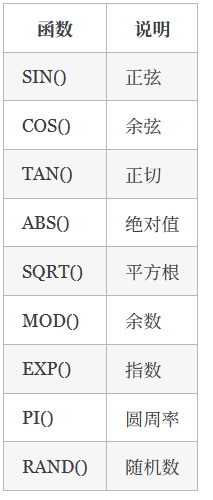
数值处理
统计
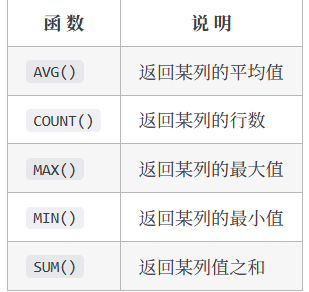
AVG() 会忽略 NULL 行。
使用
DISTINCT,因为DISTINCT是去重,可以让汇总函数值汇总不同的值。
1 | SELECT AVG(DISTINCT col1) AS avg_col FROM mytable |
专用窗口函数
MySQL 8.0 版本引入了窗口函数的支持,下面是 MySQL 中常见的窗口函数及其用法
ROW_NUMBER(): 为查询结果集中的每一行分配一个唯一的整数值。1
2SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY col1) AS row_num
FROM table;RANK(): 计算每一行在排序结果中的排名。1
2SELECT col1, col2, RANK() OVER (ORDER BY col1 DESC) AS ranking
FROM table;DENSE_RANK(): 计算每一行在排序结果中的排名,保留相同的排名。1
2SELECT col1, col2, DENSE_RANK() OVER (ORDER BY col1 DESC) AS ranking
FROM table;NTILE(n): 将结果分成 n 个基本均匀的桶,并为每个桶分配一个标识号。1
2SELECT col1, col2, NTILE(4) OVER (ORDER BY col1) AS bucket
FROM table;LEAD()和LAG(): LEAD 函数用于获取当前行之后的某个偏移量的行的值,而 LAG 函数用于获取当前行之前的某个偏移量的行的值。1
2
3SELECT col1, col2, LEAD(col1, 1) OVER (ORDER BY col1) AS next_col1,
LAG(col1, 1) OVER (ORDER BY col1) AS prev_col1
FROM table;FIRST_VALUE()和LAST_VALUE(): FIRST_VALUE 函数用于获取窗口内指定列的第一个值,LAST_VALUE 函数用于获取窗口内指定列的最后一个值。1
2
3SELECT col1, col2, FIRST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS first_val,
LAST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS last_val
FROM table;
窗口函数通常需要配合 OVER
子句一起使用,用于定义窗口的大小、排序规则和分组方式。
视图(VIEW)
理解视图
视图是基于 SQL 语句的结果集的可视化的表。
视图是由数据库中的一个表或多个表导出的虚拟表,其作用是方便用户对数据的操作。
因为视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。但是对视图的操作和对普通表的操作一样。
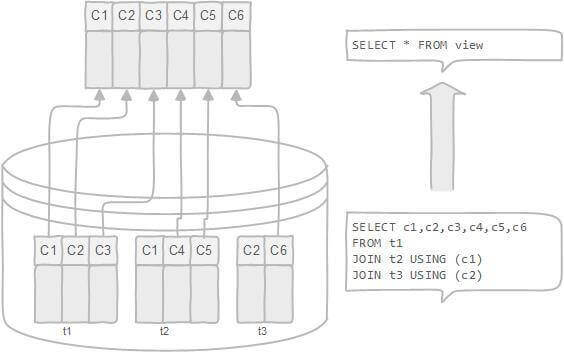
同真实的表一样,视图包含一系列带有名称的列和行数据。但是,数据库中只存放了视图的定义,而并没有存放视图中的数据,这些数据存放在原来的表中。
所以,视图是虚拟的表,本身不包含数据,无法添加索引等操作,但是对视图的操作和对普通表的操作一样。
使用 视图查询数据时,数据库系统会从原来的表中取出对应的数据。因此,视图中的数据是依赖于原来的表中的数据的。一旦表中的数据发生改变,显示在视图中的数据也会发生改变。同样对视图的更新,会影响到原来表的数据。
视图的作用主要是
- 安全原因:视图可以隐藏一些数据
- 可使复杂的查询易于理解和使用:这个视图就像一个“窗口”,从中只能看到你想看的数据列。
创建视图
创建视图是指在已经存在的数据库表上建立视图。视图可以建立在一张表中,也可以建立在多张表中。
1 | CREATE VIEW top_10_user_view AS |
删除视图
删除视图时,只能删除视图的定义,不会删除数据。
1 | DROP VIEW top_10_user_view; |
查询视图
可以使用SELECT语句来查询这些权限信息。查询语法别无二致
1 | SELECT col1, col2 FROM 视图名 WHERE col1='ErgouTree'; |
修改视图也类似,略了
索引
这里只讲索引相关的 SQL 语法
创建索引
如果是建表时顺便创建索引
1 | CREATE TABLE 表名 ( |
例如主键索引
1
2
3
4
5
6CREATE TABLE user (
id INT NOT NULL,
name VARCHAR(50),
PRIMARY KEY (id) -- 单列主键
-- 复合主键:PRIMARY KEY (id, name)
);
如果是建表后添加索引,就这样
1 | CREATE INDEX user_index ON user(id); |
ALTER TABLE 方式:意义倾向于为字段添加索引
1
2ALTER TABLE 表名
ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX [索引名] (字段1[,字段2...]) [USING 存储引擎];CREATE INDEX 方式:意义倾向于为字段创建索引
1
2CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名
ON 表名 (字段1[,字段2...]) [USING 存储引擎];
例如创建一个唯一索引,就可以这样
1 | CREATE UNIQUE INDEX ON users (id); |
前缀索引创建比较特殊
1 | -- 建表后创建(截取name前10个字符) |
索引是有命名规范的:
- 主键索引:默认
PRIMARY,无需手动命名; - 唯一索引:
uk_表名_字段名; - 普通索引:
idx_表名_字段名; - 复合索引:
idx_表名_字段1_字段2; - 全文索引:
ft_表名_字段名。
删除索引
1 | -- 方式1:ALTER TABLE(推荐,通用) |
查看索引
1 | -- 查看单表所有索引 |
约束
SQL 约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
约束类型
主键约束 PRIMARY KEY
唯一标识表中的每一行,确保数据的唯一性。
NOT NULL 和 UNIQUE 的结合。确保某列有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- 主键列的值必须唯一且不能为
NULL。 - 一个表只能有一个主键,但主键可以由多个列组成(复合主键)。
递增约束 AUTO_INCREMENT
自动为列生成唯一的递增值,通常用于主键列。
- 只能用于整数类型的列。
- 每个表只能有一个
AUTO_INCREMENT列。
唯一约束 UNIQUE
确保列中的值唯一,但允许 NULL 值。
- 一个表可以有多个唯一约束。
- 唯一约束可以作用于单列或多列(复合唯一约束)。
非空约束 NOT NULL
确保列中的值不能为 NULL。
- 非空约束只能作用于单列。
默认约束(DEFAULT)
为列设置默认值,当插入数据时未指定该列的值时,使用默认值。
- 默认值可以是常量、表达式或函数。
外键约束 FOREIGN KEY
确保表之间的引用完整性,用于关联两个表。
保证一个表中的数据匹配另一个表中的值的参照完整性。
- 外键列的值必须存在于被引用表的主键或唯一键中。
- 外键可以为
NULL。
检查约束 CHECK
确保列中的值满足指定条件。
- MySQL 8.0.16 及以上版本支持
CHECK约束。 - 条件可以是逻辑表达式。
复合约束
将多个列组合在一起作为约束条件。
- 复合主键:多个列共同作为主键。
- 复合唯一约束:多个列共同确保唯一性。
约束的添加
1 | ALTER TABLE 表名 ADD CONSTRAINT 约束名 约束类型 (列名); |
约束的删除
1 | ALTER TABLE 表名 DROP CONSTRAINT 约束名; |
约束的命名
1 | CREATE TABLE 表名 ( |
约束演示
1 | -- 约束建表 |
外键约束的级联操作
可以通过 ON DELETE 和 ON UPDATE
子句定义外键的级联行为。例如:
ON DELETE:当主表中的记录被删除时,自动删除从表中的相关记录。ON UPDATE:当主表中的记录被更新时,自动更新从表中的相关记录。
而外键约束的删除和更新行为如下
NO ACTION:父表中删除/更新对应记录时,先检查该记录是否有对应外键,有则不允许删除/更新,同·RESTRICTRESTRICT:父表中删除/更新对应记录时,先检查该记录是否有对应外键,有则不允许删除/更新CASCADE:父表中删除/更新对应记录时,先检查该记录是否有对应外键,有则也删除/更新外键在子表中的记录SET BULL:父表中删除/更新对应记录时,先检查该记录是否有对应外键,有则设置子表中该外键值为 NULL(外键允许 NULL 的前提下)SET DEFAULT:父表变更的时候,子表将外键设置成一个默认的值
NO ACTION和RESTRICT是默认的
1 | -- 设置 |
事务
不能回退 SELECT 语句,回退 SELECT
语句也没意义;也不能回退 CREATE 和 DROP
语句。
MySQL
默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现
START TRANSACTION 语句时,会关闭隐式提交;当
COMMIT 或 ROLLBACK
语句执行后,事务会自动关闭,重新恢复隐式提交。
通过 set autocommit=0 可以取消自动提交,直到
set autocommit=1 才会提交;autocommit
标记是针对每个 MySQL 连接而不是针对服务器的。
指令:
START TRANSACTION- 指令用于标记事务的起始点。SAVEPOINT- 指令用于创建保留点。ROLLBACK TO- 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到START TRANSACTION语句处。COMMIT- 提交事务。
1 | -- 开始事务 |
存储过程
理解存储过程
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
对于预编译,首次执行后,执行计划缓存到数据库,后续调用无需重新解析;
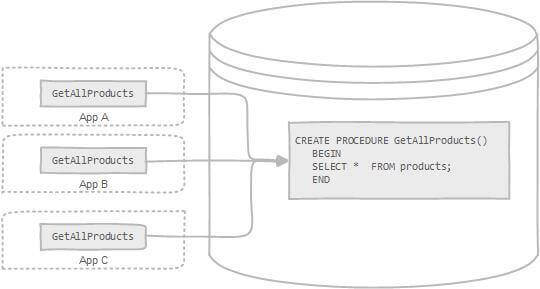
在传统企业级应用中,存储过程具有一定的实用价值。当业务逻辑复杂时,需要执行大量SQL语句才能完成一个业务操作,此时可以将这些语句封装成存储过程,简化调用过程。由于存储过程在创建时就已经编译并存储在数据库中,执行时无需重新编译,因此相比动态SQL语句具有更好的执行性能。同时,一旦存储过程调试完成,其运行相对稳定可靠。
然而,在现代互联网架构中,存储过程的使用越来越少。它调试困难,修改业务逻辑直接涉及到数据库对象,移植性差,不同数据库系统的存储过程语法差异较大,无法协作,无法水平扩展,分库分表不兼容,云原生不友好
将业务逻辑放在应用层实现,保持数据库的简单和高效是我们的常用做法
创建存储过程
创建存储过程:
- 命令行中创建存储过程需要自定义分隔符,因为命令行是以
;为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。 - 包含
in、out和inout三种参数。 - 给变量赋值都需要用
select into语句。 - 每次只能给一个变量赋值,不支持集合的操作。
1 | DROP PROCEDURE IF EXISTS `proc_adder`; |
使用存储过程
1 | set @b=5; |
游标
游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,它不是一条
SELECT 语句,而是被该语句检索出来的结果集。
在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
使用游标的几个明确步骤:
在使用游标前,必须声明(定义)它。这个过程实际上没有检索数据, 它只是定义要使用的
SELECT语句和游标选项。一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来。
对于填有数据的游标,根据需要取出(检索)各行。
在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具
体的 DBMS)。
1 | DELIMITER $ |
注意:在 MySQL 中,分号
;是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。这时就会用到
DELIMITER命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:DELIMITER new_delimiter。new_delimiter可以设为 1 个或多个长度的符号,默认的是分号;,我们可以把它修改为其他符号,如$-DELIMITER $。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了$,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来
触发器
触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
我们可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
使用触发器的优点:
- SQL 触发器提供了另一种检查数据完整性的方法。
- SQL 触发器可以捕获数据库层中业务逻辑中的错误。
- SQL 触发器提供了另一种运行计划任务的方法。通过使用 SQL 触发器,您不必等待运行计划任务,因为在对表中的数据进行更改之前或之后会自动调用触发器。
- SQL 触发器对于审计表中数据的更改非常有用。
Spring Data JPA 就是基于触发器实现的
使用触发器的缺点:
- SQL 触发器只能提供扩展验证,并且不能替换所有验证。必须在应用程序层中完成一些简单的验证。例如,您可以使用 JavaScript 在客户端验证用户的输入,或者使用服务器端脚本语言(如 JSP,PHP,ASP.NET,Perl)在服务器端验证用户的输入。
- 从客户端应用程序调用和执行 SQL 触发器是不可见的,因此很难弄清楚数据库层中发生了什么。
- SQL 触发器可能会增加数据库服务器的开销。
MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
BEFORE INSERT- 在将数据插入表格之前激活。AFTER INSERT- 将数据插入表格后激活。BEFORE UPDATE- 在更新表中的数据之前激活。AFTER UPDATE- 更新表中的数据后激活。BEFORE DELETE- 在从表中删除数据之前激活。AFTER DELETE- 从表中删除数据后激活。
但是,从 MySQL 版本 5.7.2+开始,可以为同一触发事件和操作时间定义多个触发器。
NEW 和 OLD:
- MySQL 中定义了
NEW和OLD关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。 - 在
INSERT型触发器中,NEW用来表示将要(BEFORE)或已经(AFTER)插入的新数据; - 在
UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据; - 在
DELETE型触发器中,OLD用来表示将要或已经被删除的原数据; - 使用方法:
NEW.columnName(columnName 为相应数据表某一列名)
创建触发器
CREATE TRIGGER 指令用于创建触发器。
1 | CREATE TRIGGER trigger_name |
说明:
trigger_name:触发器名trigger_time: 触发器的触发时机。取值为BEFORE或AFTER。trigger_event: 触发器的监听事件。取值为INSERT、UPDATE或DELETE。table_name: 触发器的监听目标。指定在哪张表上建立触发器。ON table_name:触发器建在哪张表上FOR EACH ROW: 行级监视,Mysql 固定写法,其他 DBMS 不同。BEGIN和END:触发器执行动作开始和结束定界符,当触发器的触发条件满足时,将会执行BEGIN和END之间的触发器执行动作。trigger_statements: 触发器执行动作。是一条或多条 SQL 语句的列表,列表内的每条语句都必须用分号;来结尾。
1 | DELIMITER $ |
查看触发器
1 | SHOW TRIGGERS; |
删除触发器
1 | DROP TRIGGER IF EXISTS trigger_insert_user; |






