
前言:这些是什么样的设计模式
之前,我们学习的是GoF(Gang of Four)提出的 23 种经典设计模式(5 创建型 + 7 结构型 + 11 行为型)
接下来,我提到的这些设计模式,他们属于更高层次的 架构模式(Architectural Patterns) 或 企业级设计模式(Enterprise Design Patterns),而不是 GoF 的微观设计模式。它们关注的是整个系统的组织结构、职责划分和控制流,而非单个类或对象之间的交互。
从经典设计模式迈向现代软件架构的关键节点就在这里。掌握这些高层次模式,将帮助你设计出可维护、可扩展、高内聚、低耦合的企业级系统。
他们有很多经典的实现,我只讲解最常使用的和看到的
架构设计模式
关注整个系统的高层结构,决定组件如何组织、通信和部署。
它的选择影响全局、难以后期修改、而且通常决定技术选型。
常见的架构模式如下
- MVC 模式
- MVVM 模式
- 三层架构(表现层-业务层-数据层)模式
- 管道-过滤器模式
- 微服务架构
- 事件驱动架构
- CQRS(Command Query Responsibility Segregation)
- 六边形架构(Hexagonal Architecture) / 端口与适配器
- 整洁架构
企业设计模式
而它关注企业应用中的常见问题(如数据访问、请求处理、服务调用等)。
解决特定场景问题、通常在框架或中间件中实现
- 前端控制器模式
- 拦截过滤器模式
- 服务定位器模式
- 数据访问对象模式(DAO)
- 传输对象模式(TO / DTO)
- 业务代表模式(Business Delegate)
- 组合实体模式(Composite Entity)
- 依赖注入(Dependency Injection, DI)
- 仓储模式(Repository Pattern)
- 工作单元(Unit of Work)
常见常用架构设计模式详解
MVC模式
首先,MVC 指的就是 Model-View-Controller ,是一种经典的软件架构模式,旨在通过职责分离提高代码的可维护性、扩展性和复用性。
这种模式用于应用程序的分层开发。特别适用于构建用户界面(UI)应用程序。
- Model(模型) - 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
- View(视图) - 视图代表模型包含的数据的可视化。
- Controller(控制器) - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
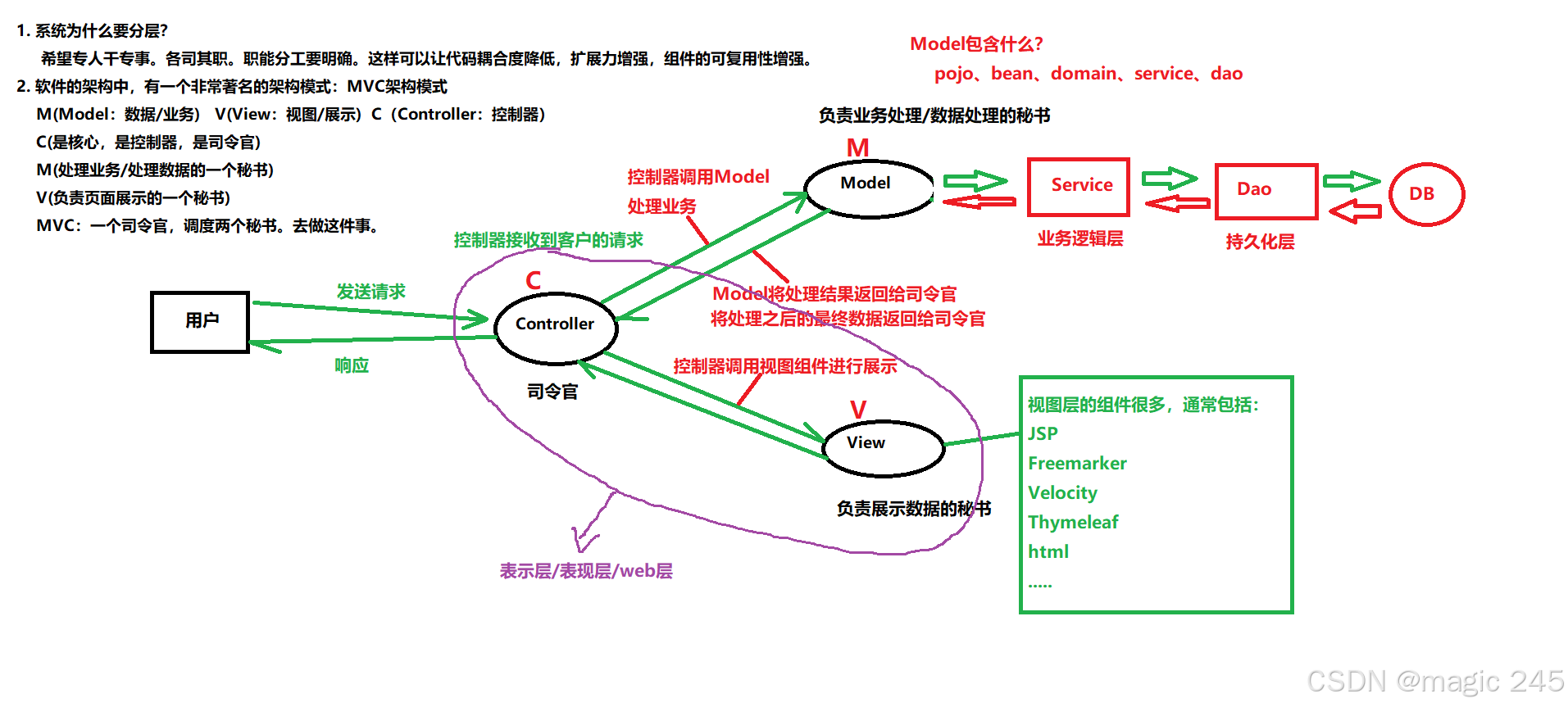
关注点分离是如何实现的,如下:
- Model 不知道 View 和 Controller 的存在;
- View 只读取 Model 的数据(或通过 Controller 获取);
- Controller 决定如何响应用户操作,并驱动 Model 和 View 的变化。
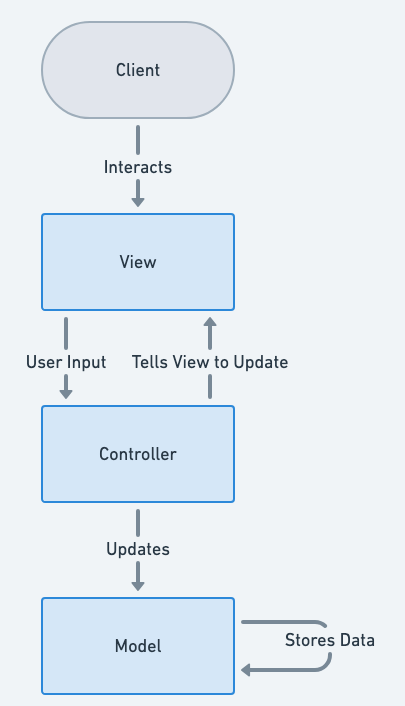
还是以一个例子来说明
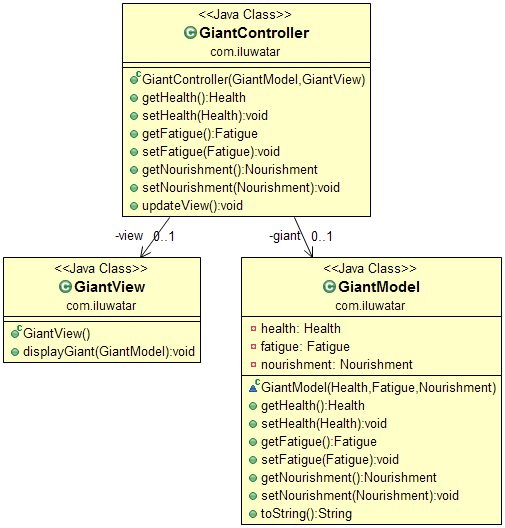
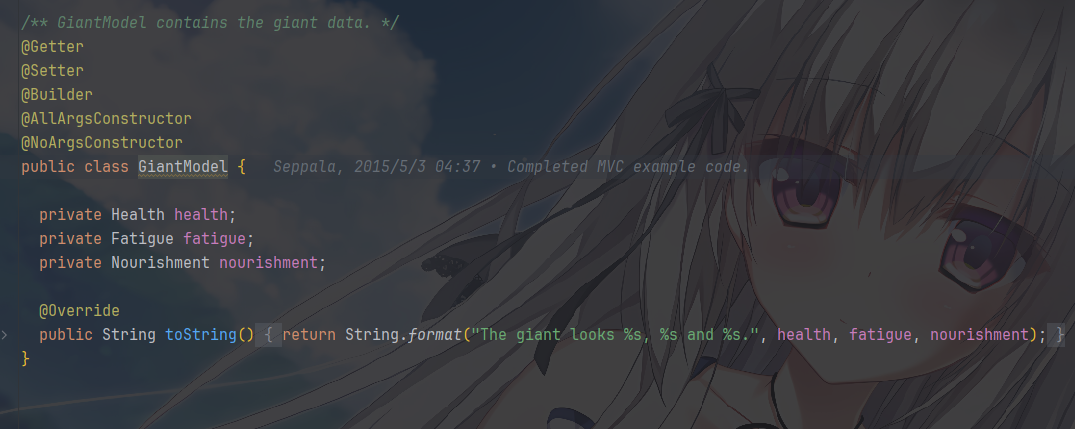
Model,可以看到这些就是一些字段的模型,就是POJO数据对象
这里只关心是什么的问题
View,将
GiantModel的状态以日志形式“显示”出来。只是被动展示。View 的职责就是“呈现”,它不知道用户如何操作,也不知道数据怎么变。
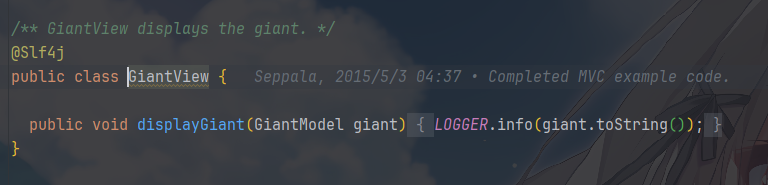
Controller,一般是接收外部指令来更新 Model,决定何时改数据、何时刷新界面。
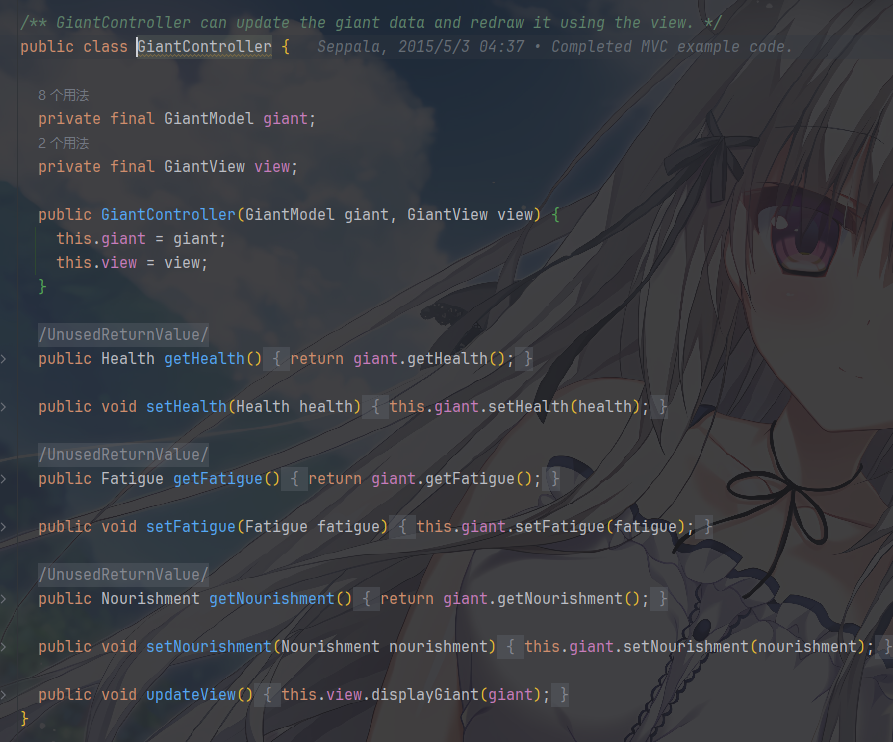
抛去一些枚举类带来的类型安全默认值外,主程序就是分别创建这些东西,然后调用对应的 View 和 Controller 来展示和操作 Model
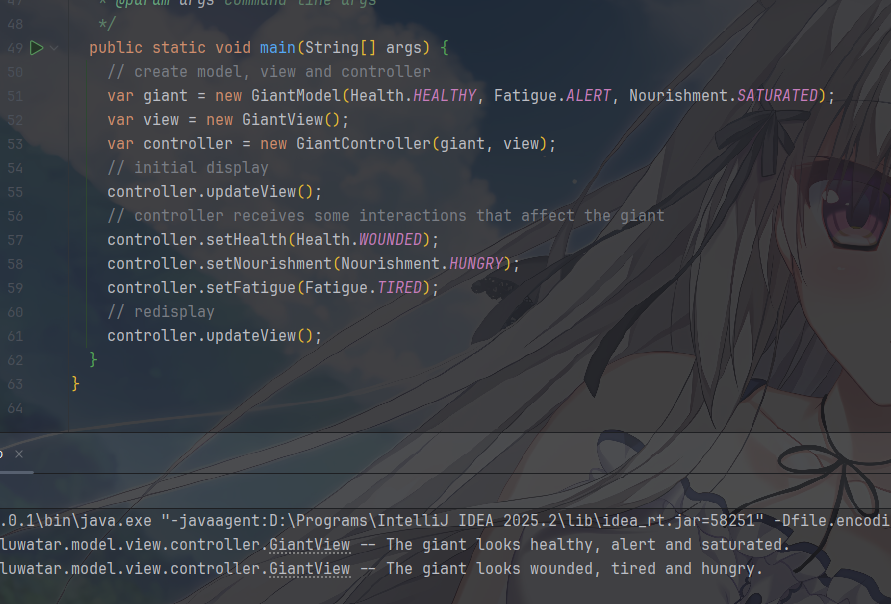
当开发中型应用程序,需要清晰分离数据、业务逻辑和用户界面时,考虑使用MVC模式。
而很多简单的 Web 应用程序就是用户通过浏览器(视图)发送请求,服务器端的控制器处理请求,模型进行数据处理。
MVVM模式
https://zhuanlan.zhihu.com/p/11669116019
MVVM 是 Model-View-ViewModel 的缩写,是一种用于构建用户界面的架构模式,特别适用于数据驱动型 UI(如 Web 前端、桌面应用、移动端)。它最早由微软在 WPF/Silverlight 中推广,现广泛应用于 Vue.js、Angular、Knockout.js 等框架。
MVVM 架构的最终目标是使视图完全独立于应用程序逻辑。
那么 MVVM 中的角色如下
- 模型:该模型代表应用的域模型,其中可能包括数据模型以及业务和验证逻辑。它与 ViewModel 进行通信,但无法感知 View。
- 视图:View 代表应用程序的用户界面,包含有限的、纯粹的展示逻辑,用于实现视觉行为。View 与业务逻辑完全无关。换句话说,View 是一个“哑”类,它从不包含数据,也不会直接操作数据。它通过数据绑定与 ViewModel 通信,并且不知道 Model 的存在。
- 视图模型:ViewModel 是 View 和 Model 之间的纽带。它通过数据绑定实现并公开 View 使用的公共属性和命令。如果发生任何状态更改,ViewModel 会通过通知事件通知 View。
理解 MVVM 架构的关键是理解 MVVM 中的三个关键组件如何相互作用。因为 View 只与 ViewModel 通信,而 ViewModel 只与 Model 通信。
所有用户交互都发生在 View 中,View 负责检测用户的输入(鼠标点击、键盘输入)并通过数据绑定将其转发给 ViewModel。数据绑定可以通过回调或属性实现,并构成 View 和 ViewModel 之间的具体链接。
ViewModel 实现视图可以绑定到的属性和命令。这些属性和命令定义了视图可以向用户提供的功能,尽管如何显示它完全取决于视图。
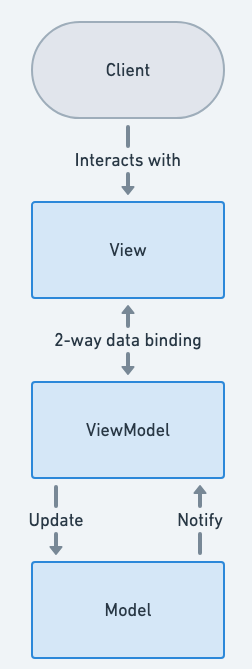
要注意如下内容,一般情况下,View 和 ViewModel 之间通过“数据绑定”自动同步,而且ViewModel 不知道 View 的具体实现,命令(Command)模式处理用户操作
使用一个例子来讲解其内容
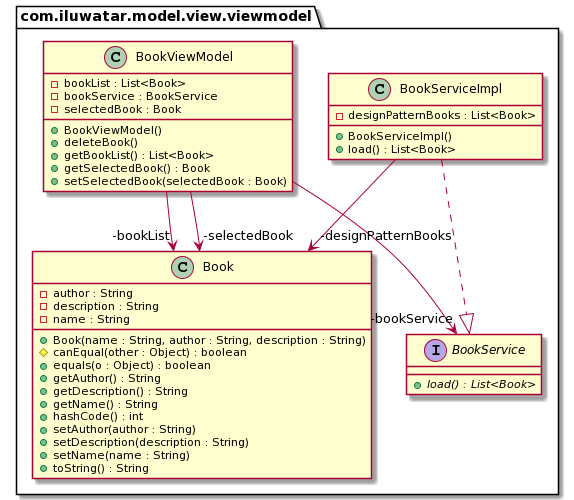
其中,Model:Book.java +
BookService.java
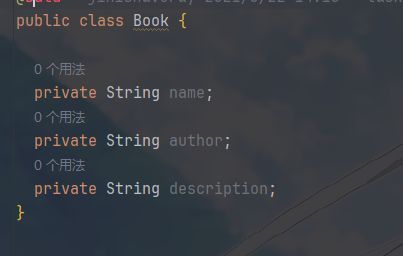
- 纯数据对象,代表书一本
其 Model 中的业务逻辑接口和业务逻辑实现如下
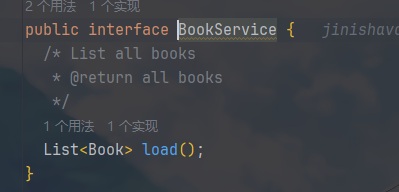
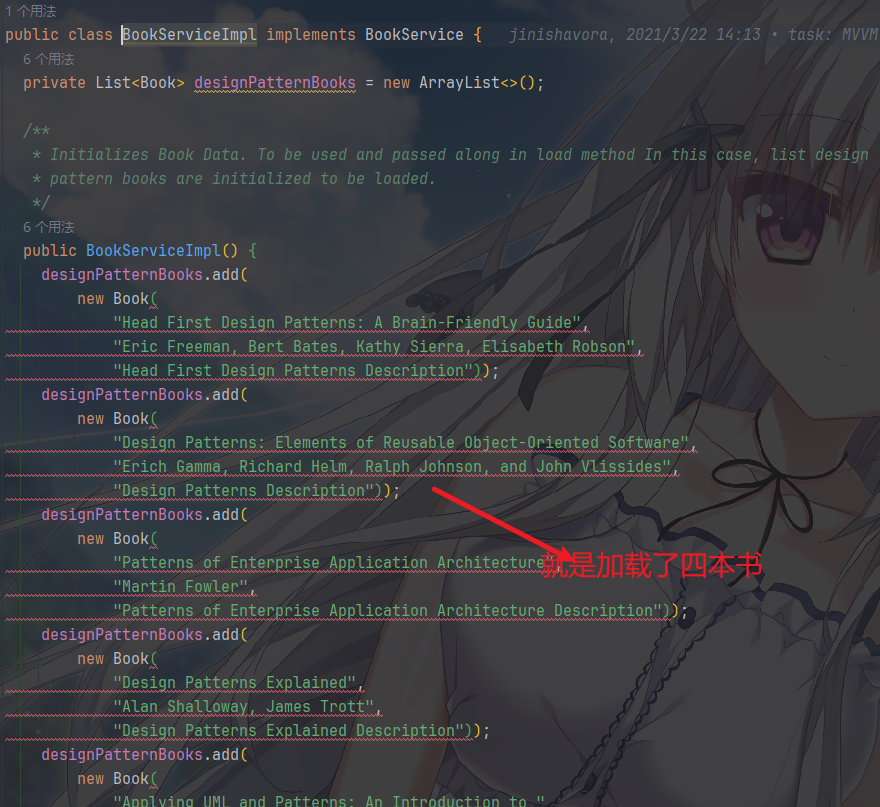
其中,Model 层的逻辑就是提供数据和业务逻辑,完全独立于 UI。
那么,其中 View 就是 zul 文件,但是由于 ZK 我确实不熟悉,只能放这里看看了
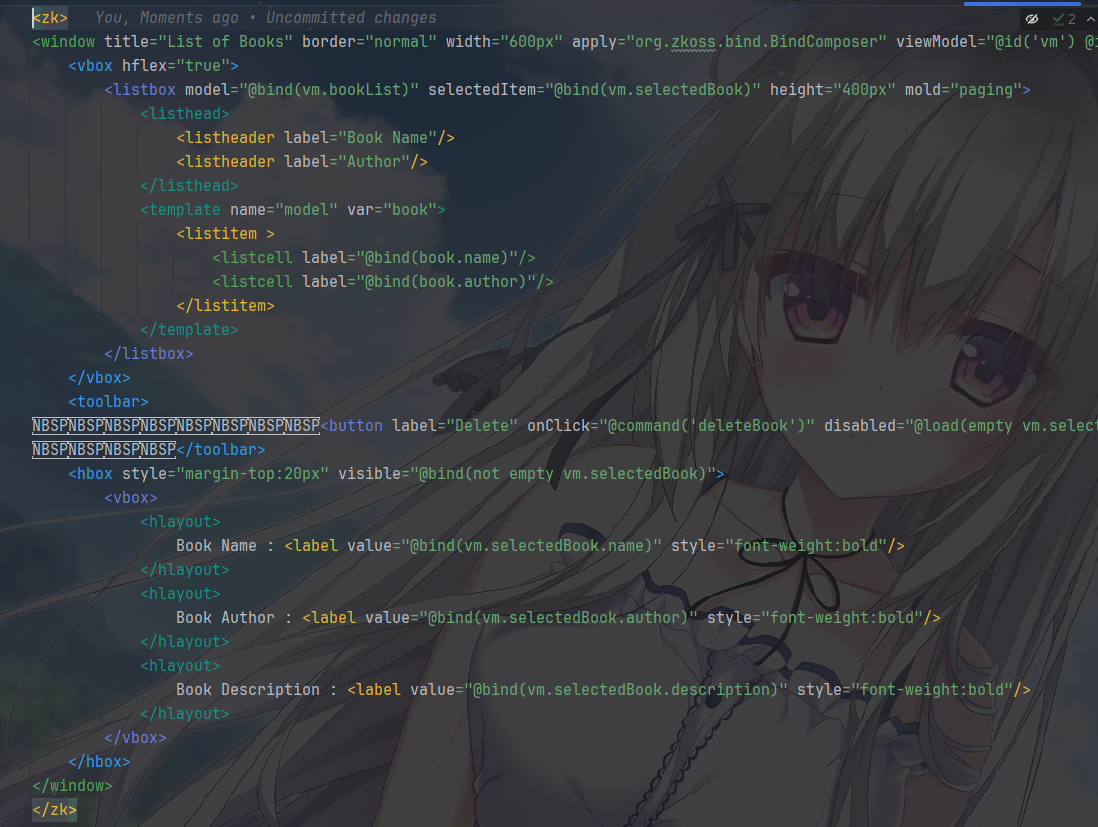
这个
@bind()应该也是双向绑定,而且查了一下@command('deleteBook')
绑定 的是 ViewModel 中的命令方法,ZK 是一个纯声明式 UI。
其中,ViewModel:BookViewModel.java,如下
1 | public class BookViewModel { |
其中,@Command标记该方法可被 View 通过
@command('methodName')
调用,@NotifyChange({"prop1", "prop2"})是而当方法执行后,通知
View 刷新指定属性的绑定值
什么意思,它暴露数据给 View,通过 getBookList() 和
getSelectedBook();而且用deleteBook()
是这个命令响应用户操作,再通过 @NotifyChange 告知 View
何时刷新,实现了把业务逻辑和代码逻辑几乎完全分离
| 特性 | MVC(巨人例子) | MVVM(书籍例子) |
|---|---|---|
| 数据流向 | Controller 主动调用 View.update() | View 通过绑定自动监听 ViewModel 变化 |
| UI 更新方式 | 手动(命令式) | 自动(声明式 + 数据绑定) |
| View 依赖 | View 依赖 Model(直接读取) | View 只依赖 ViewModel(通过绑定表达式) |
| 测试性 | Controller 需要 mock View | ViewModel 完全独立于 View,极易单元测试 |
| 适用场景 | 简单 UI、服务端渲染 | 复杂交互、富客户端应用 |
MVVM 是核心价值是通过数据绑定消除样板代码,让开发者专注于业务逻辑而非 UI 同步
Vue.js 的整体设计,就是基于这个设计模式
三层架构
三层架构(Three-Tier / Three-Layer Architecture)指的是哪三层?
实际上,三层架构的核心也是分离数据和视图,那么三层应该也是大差不差的
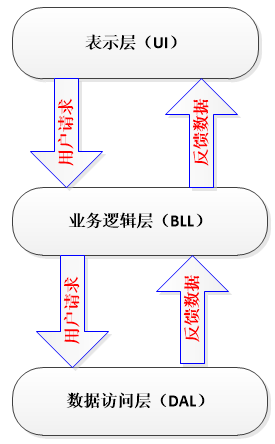
- UI(表现层): 主要是指与用户交互的界面。用于接收用户输入的数据和显示处理后用户需要的数据。
- BLL:(业务逻辑层): UI层和DAL层之间的桥梁。实现业务逻辑。业务逻辑具体包含:验证、计算、业务规则等等。
- DAL:(数据访问层): 与数据库打交道。主要实现对数据的增、删、改、查。将存储在数据库中的数据提交给业务层,同时将业务层处理的数据保存到数据库。(当然这些操作都是基于UI层的。用户的需求反映给界面(UI),UI反映给BLL,BLL反映给DAL,DAL进行数据的操作,操作后再一一返回,直到将用户所需数据反馈给用户)
| 层级 | 名称 | 职责 |
|---|---|---|
| 1. 表示层(Presentation Layer) | 又称 UI 层、视图层 | 负责与用户交互:接收输入、展示结果(如 Web 页面、命令行、移动端界面)。 |
| 2. 业务逻辑层(Business Logic Layer) | 又称服务层、应用层 | 封装核心业务规则、流程控制、事务管理等。它是系统“大脑”。 |
| 3. 数据访问层(Data Access Layer) | 又称持久层、DAO 层 | 负责与数据库或其他数据源交互:增删改查(CRUD),屏蔽底层存储细节。 |
一般来说
- 表示层 → 调用 业务逻辑层
- 业务逻辑层 → 调用 数据访问层
- 表示层不能直接访问数据访问层(违反分层原则)
联系他们的通常模式是使用实体类,那么,是不是有一点回到了我们编写 Spring 应用时候的设计思路了,一个 Model,一个 Repository,一个 Web 前端,但是纯三层模式写 Spring 还是比较吃力的,但是 Spring 应用在开发的时候,三层模式在其中很常见
其中,Entity在三层架构中,最主观的就是在三层之间传递数据,然后将实体与数据库字段对应,然后每一层(UI—>BLL—>DAL)之间的数据传递(单向)是靠变量或实体作为参数来传递的,其中,传递一般使用实体或者额外构建传输层DTO
综上所述,三层及实体层之间的依赖关系
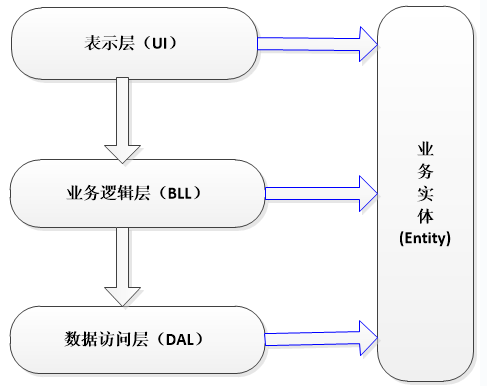
使用一个实际例子来讲解这个设计模式
首先,定义实体类(Entity),共享模型,被所有层共享。
1 | // model/User.java |
然后定义数据访问层,DAO 层只关心如何存取数据
1 | // dao/UserDao.java |
一般来说,你还需要一个服务层接口,目的就是在 DAO 中添加规定需要的业务逻辑,然后实现类来实现这些方法描述具体的业务逻辑,调用 DAO
表示层就不写了,写个 html 就够了用 Thymeleaf,一般来说,表示层只负责
- 接收用户输入
- 调用 Service
- 展示结果
| 对比项 | 三层架构 | MVC |
|---|---|---|
| 目的 | 整体系统分层(宏观架构) | UI 内部结构组织(微观模式) |
| 适用范围 | 整个应用程序 | 主要用于表示层内部 |
| 层级 | 表示层、业务层、数据层 | Model、View、Controller |
| 关系 | MVC 通常位于三层架构的“表示层”内部 | 三层架构可包含 MVC |
在一个 Web 应用中:
- 三层架构:前端(HTML/JS)←→ 后端 Controller(MVC 的 C)←→ Service ←→ DAO
三层架构的核心就是让代码结构清晰、职责分明,使大型项目可持续演进。
管道-过滤器模式
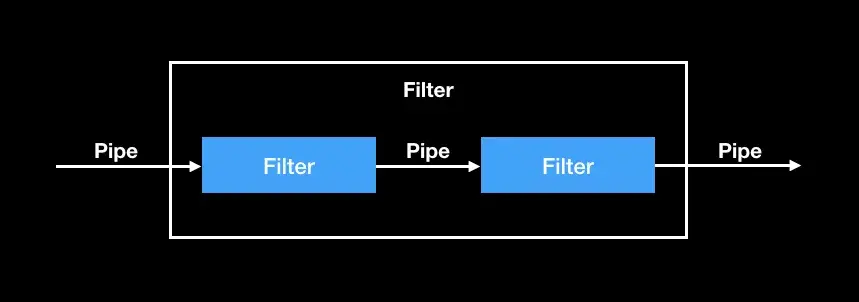
管道-过滤器模式 是一种用于处理数据流的架构模式。
它将复杂的处理过程分解为一系列独立的、可重用的处理单元(称为“过滤器”),这些单元通过管道(Pipe)连接起来,前一个过滤器的输出作为后一个过滤器的输入,形成一条数据处理流水线(Pipeline)。
这种模式与工业制造生产流水线非常类似
想象汽车装配线:
- 工件(原始数据)进入流水线;
- 第一个工位(Filter 1)安装轮胎;
- 第二个工位(Filter 2)喷漆;
- 第三个工位(Filter 3)安装座椅;
- 最终成品(处理结果)流出。
每个工位只关心自己的任务,不关心上游怎么来、下游怎么用。因为这么说我实际上是想说,过滤器之间通常松耦合,每个 Filter 只知道自己的输入/输出类型;所以可以像搭积木一样组合不同 Filter
用一幅图来形象描述这个过程,如下图所示
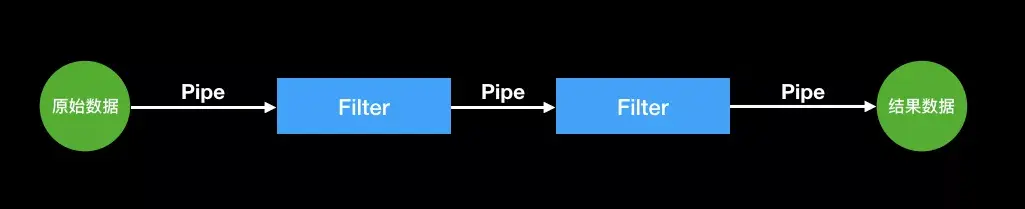
这个是一个极为重要的设计模式,我想起什么举什么例子了
在 Spring Web MVC
HandlerInterceptor的拦截器链,他就是管道过滤器模式,每个拦截器只关注自己的职责例如在 Spring Security 中的认证过滤器链(Spring Security 将整个认证/授权流程拆分为 16 个标准 Filter,组成一条
FilterChain。)和Security Filter Chain那一串一串的过滤器链,这是 最经典、最显式的管道-过滤器实现
那么,管道过滤器链需要如下角色
| 角色 | 职责 | 在你代码中的对应 |
|---|---|---|
| Filter(过滤器) | 执行单一数据处理任务,输入 → 处理 → 输出 | RemoveAlphabetsHandler,
RemoveDigitsHandler,
ConvertToCharArrayHandler |
| Pipe(管道) | 连接过滤器,传递数据(通常隐式实现) | Pipeline 类内部的函数组合逻辑 |
| Pipeline(流水线) | 组装多个过滤器,形成处理链 | Pipeline 类本身 |
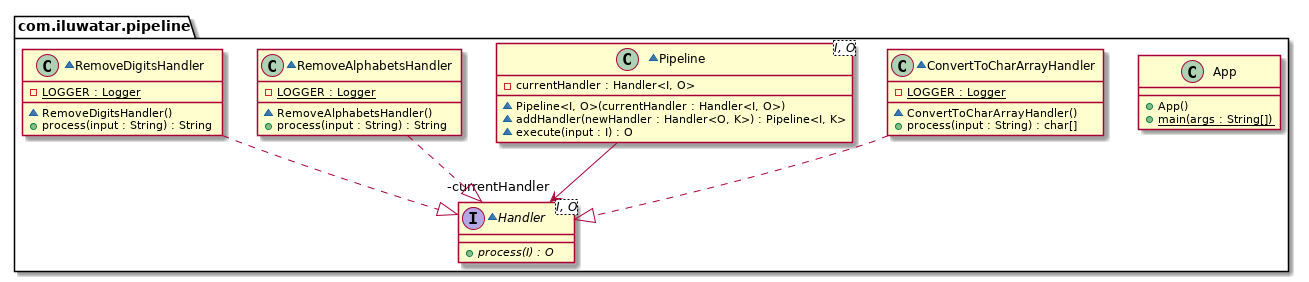
基础契约:Handler.java,他是一个 Filter 接口
- 输入类型 I,输入类型 O,这既是 Filter 的抽象接口。所以说,每个具体
Filter 必须实现
process方法
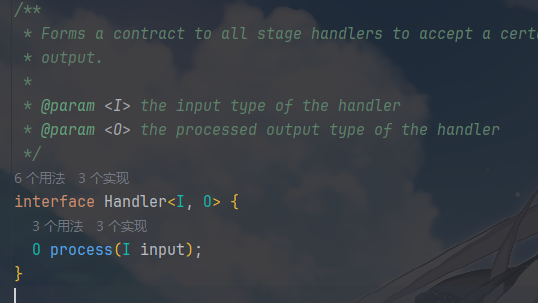
具体过滤器,例如
- 可以看到的, 每个 Filter 职责单一,例子中的核心体现是可独立测试
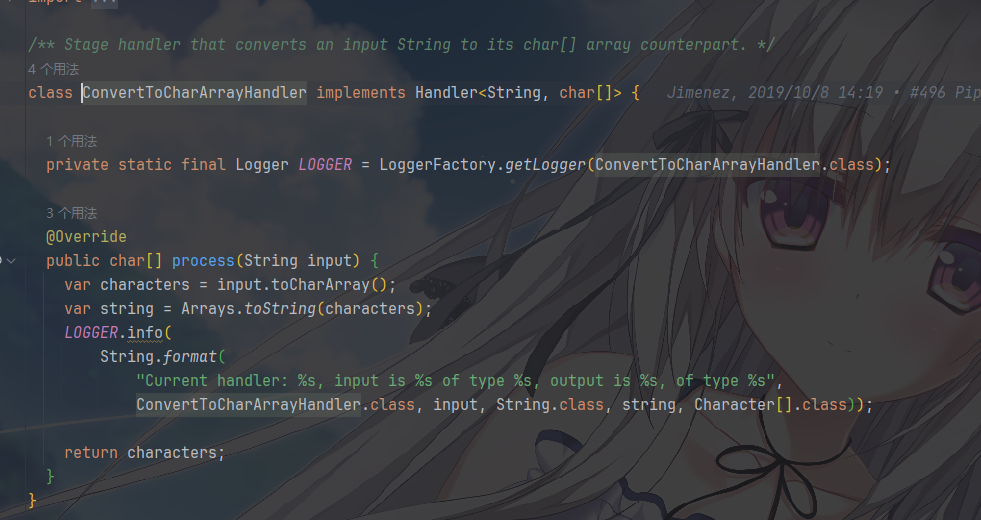
管道组装器:Pipeline.java,有了这么多过滤器实现,通常需要组成流水线才能更好处理业务
1 | class Pipeline<I, O> { |
- 说一下其中的组合逻辑,挺抽象的
addHandler并不是简单地把 Handler 存入列表;- 而是立即构建一个新的复合函数:
input → currentHandler → newHandler → output - 这种递归嵌套实现了隐式的管道连接。
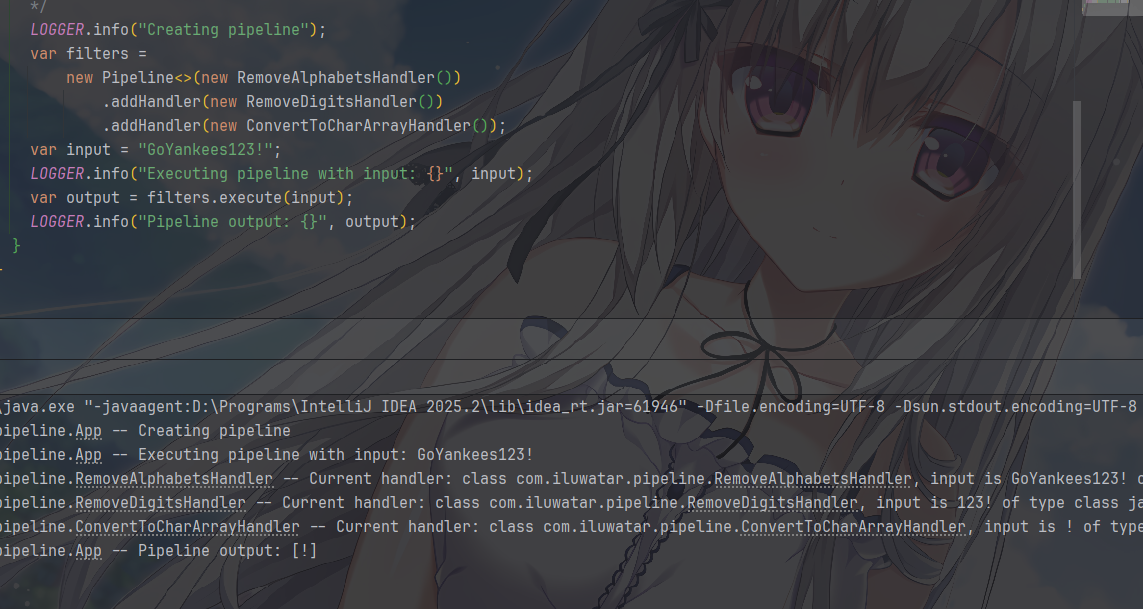
对应主程序App.java,使用起来就比较简单了 ——
构建并运行流水线
对于管道过滤器模式和责任链模式
| 对比项 | 管道-过滤器 | 责任链(Chain of Responsibility) |
|---|---|---|
| 目的 | 数据转换流水线 | 请求处理分发 |
| 数据流向 | 单向流动,每站加工 | 可能中途终止(如找到处理者就停) |
| 输出类型 | 可变化(String → char[]) | 通常相同(如都返回 boolean) |
| 耦合性 | 通过类型匹配自动连接 | 通常需显式设置 next handler |
而且这种设计模式对并行的实现,也相当友好,但是我就不特意去实现了))
而且,23 个经典设计模式里面有一个设计模式叫组合模式,当 Pipe-Filter 遇上组合模式时,多个 Filter 又可以再组合成一个新的 Filter,如下图所示,组合出来的 Filter 接收的数据与第一个 Filter 保持一致,返回的数据与最后一个 Filter 保持一致。通过组合,就可以将多个简单的 Filter 可以组合成一个更复杂的 Filter。应用这一套理论去实践,我们会发现,Filter 既可以做的很轻便,也可以做得很强大。
事件驱动模式
系统的行为由“事件”(Event)的产生、发布和响应来驱动,而不是通过直接的方法调用或紧耦合的流程控制。
事件驱动架构( Event-Driven Architecture,EDA),核心思想是让系统组件通过事件来传递信息,而不是直接互相调用。
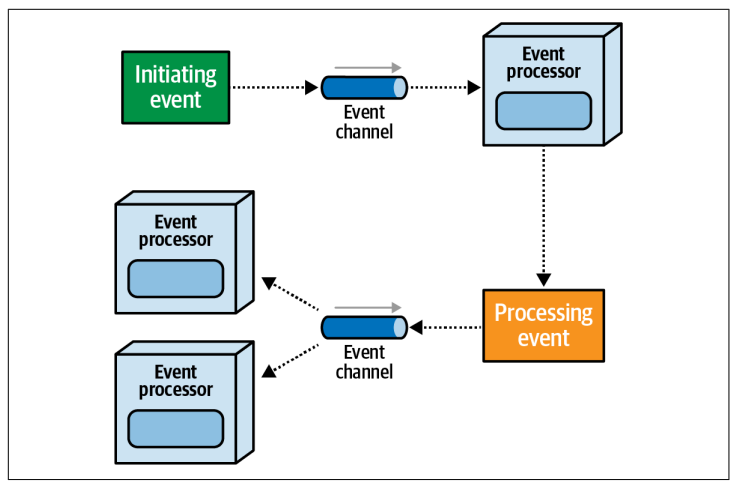
事件驱动架构是一种基于异步处理的架构风格,通过高度解耦的事件处理器来触发和响应系统中发生的事件。其中大多数事件驱动架构由以下组件组成:
- 事件(Event):系统中发生的任何有意义的变化(例如:用户下单、支付成功、库存不足)。
- 驱动(Driven):事件触发后续动作(例如:支付成功事件自动触发发货流程)。
- 架构(Architecture):组件之间不直接通信,而是通过事件管理器(如消息队列)
中转消息。
- 生产者:发现事件并通知(如:“订单已创建!”)。
- 消费者:订阅事件并行动(如:库存系统听到“订单创建”就扣库存)。
那么,事件驱动系统这件事情也很明显了
事件发布:
事件传递:
事件通道像邮局,把事件传递给所有订阅该事件的服务(消费者)。
事件处理:
服务B(消费者)收到事件,执行自己的逻辑(如通知用户支付成功)。
可以看到,Java 开发中几乎所有消息队列都是这种设计模式
而且Spring 内置了强大的事件机制,就是这种设计模式
1 | // 1. 定义事件 |
当然,事件驱动模式,我两个月前就做了一个很经典的 Kafka + Spring Cloud Stream 的分布式事件驱动
那么,还是来举一个具体的例子来掩饰这个设计模式如何实现
| 角色 | 职责 | 别名 |
|---|---|---|
| Event(事件) | 表示系统中发生的“事实”(如“用户已创建”)。它是不可变的数据载体。 | Message |
| Event Producer(生产者) | 检测到业务动作后,发布事件。 | Publisher, Emitter |
| Event Dispatcher/Bus(分发器/总线) | 路由事件到对应的处理器。 | Event Router, Mediator |
| Event Handler(处理器) | 监听并处理特定类型的事件。 | Listener, Subscriber, Consumer |
对于其中的事件
基础接口
1 | public interface Event { |
对于抽象基类AbstractEvent.java
1 | public abstract class AbstractEvent implements Event { |
具体事件:
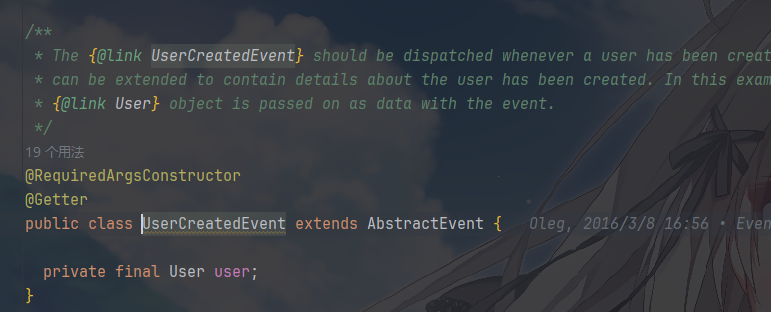
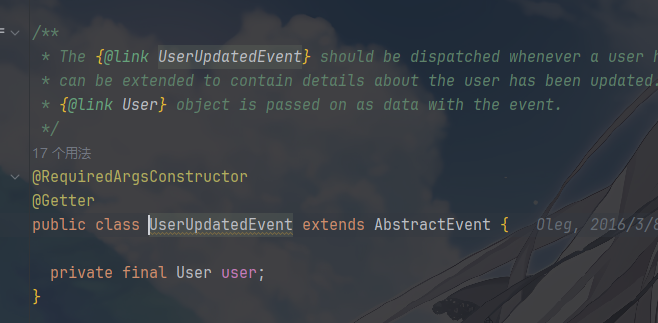
- 每个事件是一个独立的、语义明确的“事实”。它们携带数据(如
User对象),但不包含行为。
对于事件处理器
接口:
Handler.java1
2
3public interface Handler<E extends Event> {
void onEvent(E event); // 处理事件
}对于具体实现
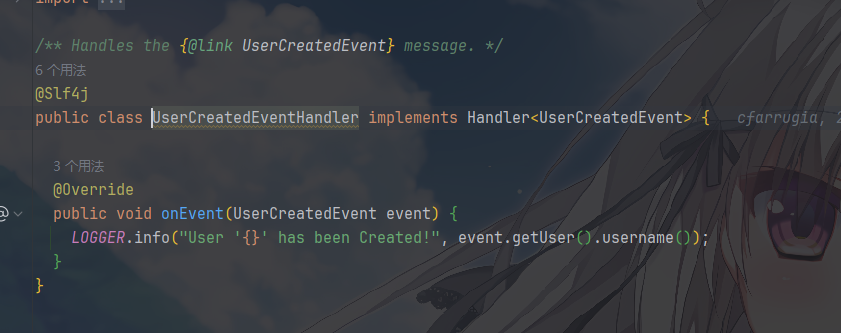
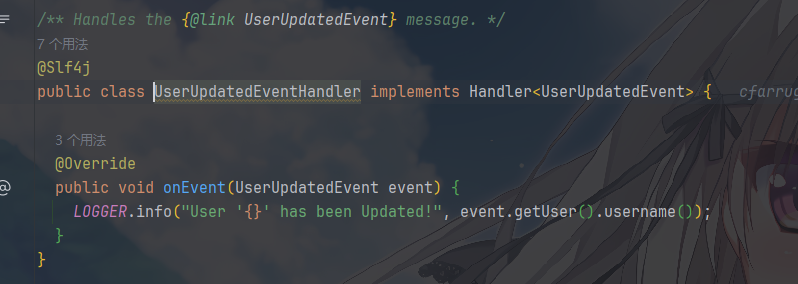
可以看到他们都是对上述具体事件的具体方法处理,是对事件语义的行为解释
然后核心是事件分发器EventDispatcher
1 | public class EventDispatcher { |
- 这就是“中介者”(Mediator)模式的体现!所有通信都通过
EventDispatcher中转,避免了生产者与消费者直接依赖。
其中,对于客户端
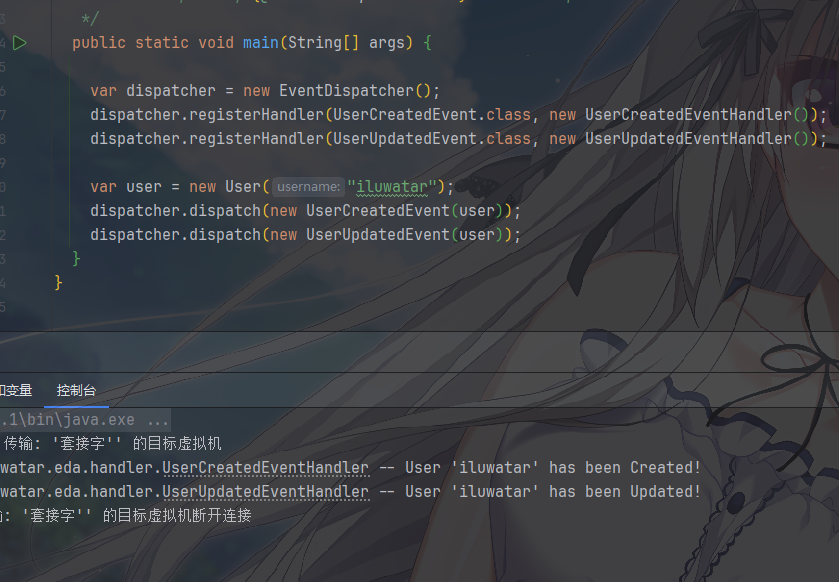
emmm,我一直感觉事件驱动很像观察者模式,因为都是都是“发布-订阅”模型,都是监听一个事件,而且通常是一对多,而且通过 中介(EventDispatcher) 解耦
而且,一般情况下,事件驱动模式通常需要和中介者模式一起使用,因为
EventDispatcher就是典型的
Mediator!它封装了多个对象(Handler)之间的交互逻辑,避免它们相互引用。
而且,每个 Handler
可以看作一种“处理策略”。EventDispatcher
在运行时根据事件类型动态选择策略。这是否又是策略模式?而且是不是其中也有命令模式的影子?
所以说,我认为,事件驱动模式是很多设计模式的组合
整洁架构模式
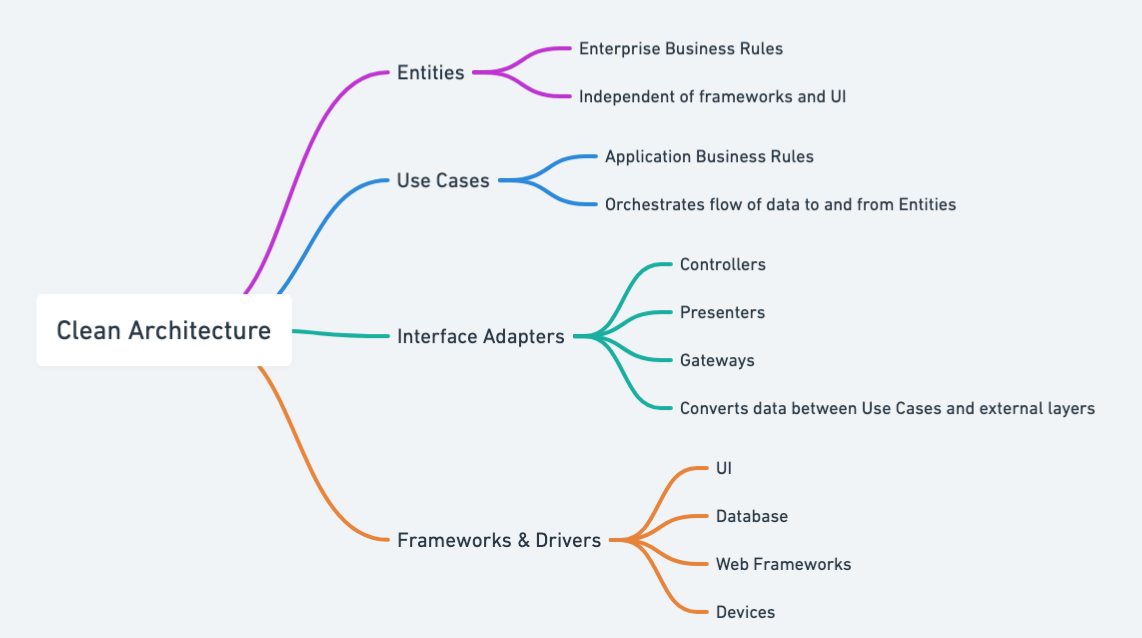
这张图描述的是著名的 “整洁架构”,The Clean Architecture
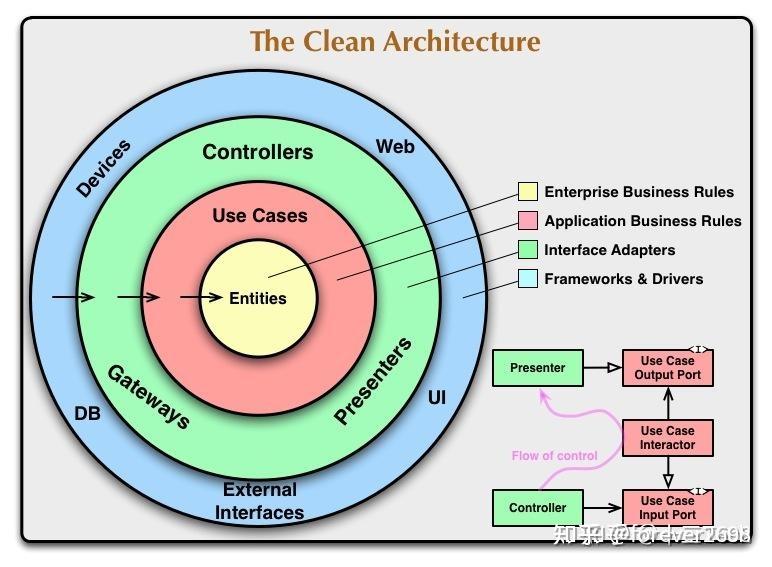
想象一个洋葱,它从内到外分成一层层的圈
- 最里圈:Entities,实体,是整个项目中最核心的、最稳定的业务规则和数据,所以,它是核心
- 中间圈:Use Cases,用例, 代表使用核心规则完成具体业务功能的逻辑,也就是核心的业务
- 再外圈:支持项目架构的一些内容,通常在这负责将数据在内外层之间进行转换,例如用于提供服务的接口,网关等等
- 最外圈:技术实现,把业务逻辑和技术细节连接起来的胶水和实现技术具体的内容部分
那么,这个圈就存在这样一个核心规则
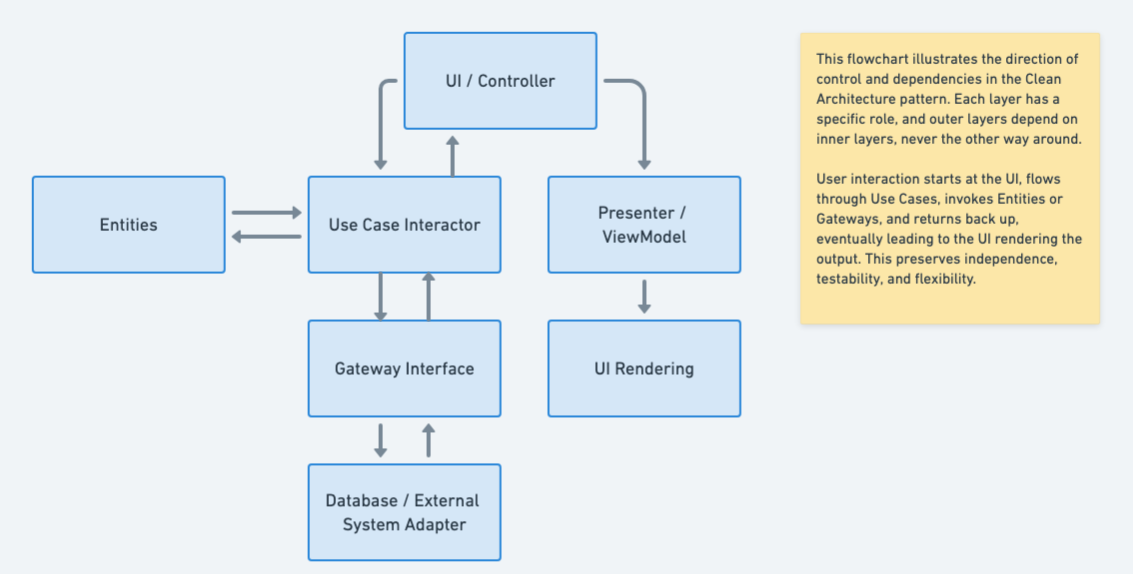
- 内向规则:外层(技术)可以依赖内层(业务),但内层绝对不能依赖外层! 也就是,业务逻辑只关心做什么,不关心怎么做,你不能换个实现方式就用不了这个东西了
- 抽象依赖:外层通过接口/适配器与内层沟通。内层定义需要什么(接口),外层提供具体实现(适配器)。这让核心业务与技术实现完全解耦。
最后还是一句话,源码依赖只能向内指向,不能向外。
内层不知道外层的存在。外层依赖并实现内层定义的接口。这使得核心业务逻辑完全独立于任何外部框架或数据库。
它解决了各种各样的代码搅在一起,牵一发而动全身的问题,而且主要解决的是技术绑架业务这样的问题
但是这样设计架构避免不了带来项目复杂的问题,也就是说,需要长期维护、演进的复杂业务系统,才考虑使用整洁架构,对于简单、生命周期短、技术栈稳定的项目,就用更简单的架构会更合适
然后,还是以一个例子来说明上述内容
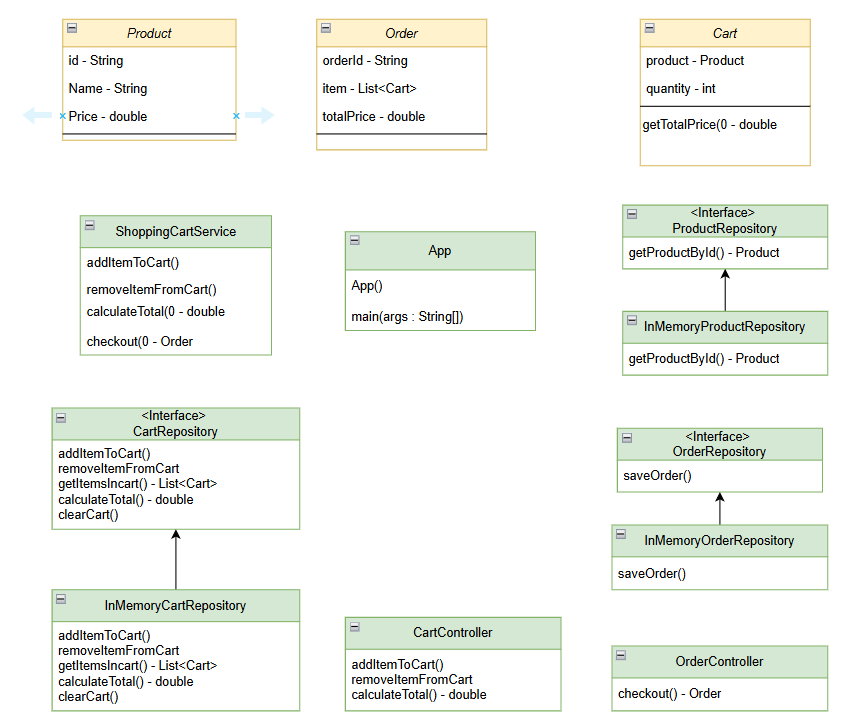
实体层:
实体层一般封装企业范围内的关键业务规则和数据。它们是系统中最纯粹的部分,不依赖任何外部库
其中,
Product.java: 代表一个商品
Cart.java: 代表购物车中的一项,Order.java: 代表一个订单,它们都代表了核心的业务规则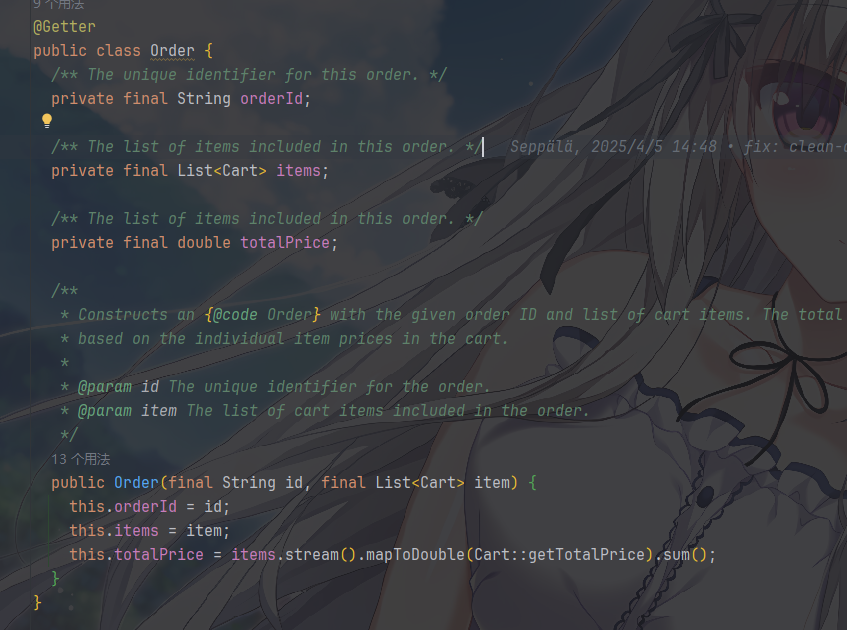
用例层 (Use Cases) - 代表应用业务逻辑
通过编排实体来完成特定的应用场景,它定义了软件要做的具体事情,并协调数据流向实体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79public class ShoppingCartService {
/** Repository for managing product data. */
private final ProductRepository productRepository;
/** Repository for managing cart data. */
private final CartRepository cartRepository;
/** Repository for managing order data. */
private final OrderRepository orderRepository;
/**
* Constructs a ShoppingCartService with the required repositories.
*
* @param pdtRepository The repository to fetch product details.
* @param repository The repository to manage cart operations.
* @param ordRepository The repository to handle order persistence.
*/
public ShoppingCartService(
final ProductRepository pdtRepository,
final CartRepository repository,
final OrderRepository ordRepository) {
this.productRepository = pdtRepository;
this.cartRepository = repository;
this.orderRepository = ordRepository;
}
/**
* Adds an item to the user's shopping cart.
*
* @param userId The ID of the user.
* @param productId The ID of the product to be added.
* @param quantity The quantity of the product.
*/
public void addItemToCart(final String userId, final String productId, final int quantity) {
Product product = productRepository.getProductById(productId);
if (product != null) {
cartRepository.addItemToCart(userId, product, quantity);
}
}
/**
* Removes an item from the user's shopping cart.
*
* @param userId The ID of the user.
* @param productId The ID of the product to be removed.
*/
public void removeItemFromCart(final String userId, final String productId) {
cartRepository.removeItemFromCart(userId, productId);
}
/**
* Calculates the total cost of items in the user's shopping cart.
*
* @param userId The ID of the user.
* @return The total price of all items in the cart.
*/
public double calculateTotal(final String userId) {
return cartRepository.calculateTotal(userId);
}
/**
* Checks out the user's cart and creates an order.
*
* <p>This method retrieves the cart items, generates an order ID, creates a new order, saves it,
* and clears the cart.
*
* @param userId The ID of the user.
* @return The created order containing purchased items.
*/
// 下单这个完整用例的流程如下
public Order checkout(final String userId) {
List<Cart> items = cartRepository.getItemsInCart(userId);
String orderId = "ORDER-" + System.currentTimeMillis();
Order order = new Order(orderId, items);
orderRepository.saveOrder(order);
cartRepository.clearCart(userId);
return order;
}
}- 就例如 checkout
下单来说,它的
checkout方法定义了“下单”这个完整用例的流程,获取购物车 -> 生成订单ID -> 创建订单 -> 保存订单 -> 清空购物车。而且它依赖于ProductRepository,CartRepository,OrderRepository这三个接口来获取和存储数据,但它完全不知道这些接口的具体实现是什么
所以说,这一层是业务流程的指挥,它知道需要哪些数据,但不知道数据如何被持久化,只是编排业务需要的具体逻辑。
- 就例如 checkout
下单来说,它的
对于接口适配器层 (Interface Adapters)
数据的交换和存储通常在这层进行,是在外层(如Web、DB)的数据格式和内层(实体、用例)的数据格式之间进行转换。控制器(Controller)、Presenter、Gateway都属于这一层。
例如,示例中的控制器
CartController.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53package com.iluwatar.cleanarchitecture;
/**
* Controller class for handling shopping cart operations.
*
* <p>This class provides methods to add, remove, and calculate the total price of items in a user's
* shopping cart.
*/
public class CartController {
/** Service layer responsible for cart operations. */
private final ShoppingCartService shoppingCartUseCase;
/**
* Constructs a CartController with the specified shopping cart service.
*
* @param shoppingCart The shopping cart service to handle cart operations.
*/
public CartController(final ShoppingCartService shoppingCart) {
this.shoppingCartUseCase = shoppingCart;
}
/**
* Adds an item to the user's cart.
*
* @param userId The ID of the user.
* @param productId The ID of the product to be added.
* @param quantity The quantity of the product.
*/
public void addItemToCart(final String userId, final String productId, final int quantity) {
shoppingCartUseCase.addItemToCart(userId, productId, quantity);
}
/**
* Removes an item from the user's cart.
*
* @param userId The ID of the user.
* @param productId The ID of the product to be removed.
*/
public void removeItemFromCart(final String userId, final String productId) {
shoppingCartUseCase.removeItemFromCart(userId, productId);
}
/**
* Calculates the total cost of items in the user's cart.
*
* @param userId The ID of the user.
* @return The total price of all items in the cart.
*/
public double calculateTotal(final String userId) {
return shoppingCartUseCase.calculateTotal(userId);
}
}可以看到,他接受指令,然后调用
ShoppingCartService来执行业务逻辑。它是外部数据与内部数据交换的桥梁。那么,Repository 仓库接口一般是做 CURD,所以也属于这一层
这一层的关键在于,用例层只依赖接口,而具体的实现在外层
框架与驱动层在例子中没有特殊体现,只是以
App.java来模拟这一层是最容易发生变化的,按照规则,这种变化不会也不能影响到内层的核心业务逻辑。
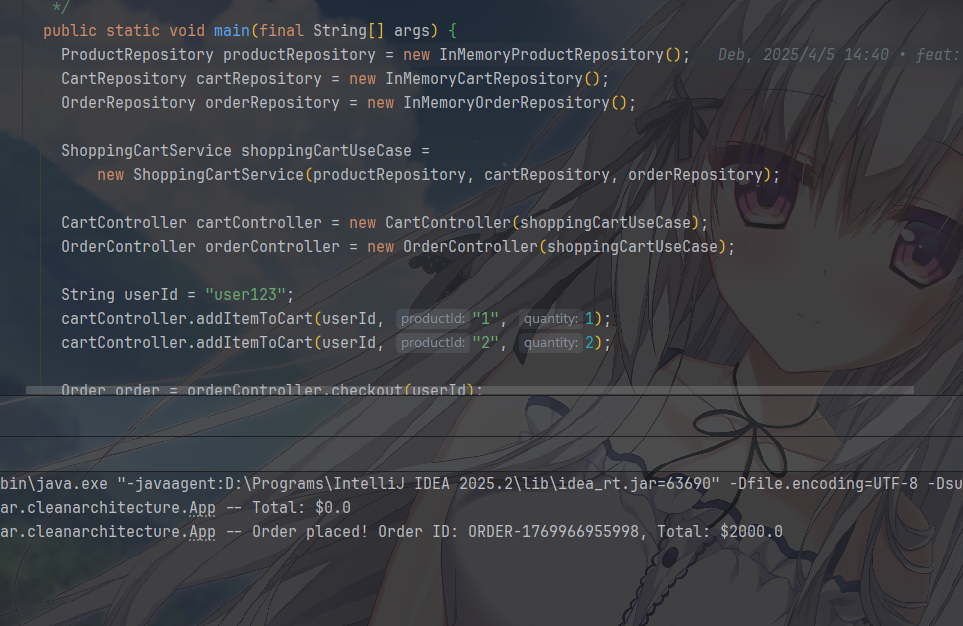
最后完整的分析一个业务在整个整洁架构中的流转,组件之间的交流特点
App.main(框架层) 创建了所有依赖对象,并将它们正确地连接起来。OrderController.checkout("user123")(接口适配器层) 被调用。OrderController调用ShoppingCartService.checkout("user123")(用例层)。ShoppingCartService开始执行“下单”用例:
- 调用
cartRepository.getItemsInCart("user123")。这里的cartRepository是一个CartRepository接口。 - 实际执行的是
InMemoryCartRepository.getItemsInCart(框架/驱动层),它从内存中取出List<Cart>。 ShoppingCartService使用这些Cart实体创建一个新的Order实体。- 调用
orderRepository.saveOrder(order)。这里的orderRepository是一个OrderRepository接口。 - 实际执行的是
InMemoryOrderRepository.saveOrder(框架/驱动层),它把订单存入内存。 - 调用
cartRepository.clearCart("user123")清空购物车。
- 调用
最终,
Order实体被返回给OrderController,再返回给调用者。
在整个流程中,核心的Order、Cart、ShoppingCartService对“数据存在内存里”这件事一无所知。它们只和抽象的接口打交道。
所以说,整洁架构的核心就是,用什么和做什么无关,业务逻辑不依赖于任何特定的框架,框架只是工具
每一层都有清晰的职责,层与层之间通过接口松耦合。
微服务架构模式
这个不多说了,估计懂得都懂
CQRS
CQRS 是 Command Query Responsibility Segregation 的缩写,也就是命令查询责任分离架构,它是一种基于微服务的设计模式,很多人说它是一个伟大的微服务模式
CQRS 是一种与领域驱动设计(DDD) 和事件溯源相关的架构模式。Greg Young 在 2010 年创造了这个术语,CQRS 的内容基于 Bertrand Meyer 的 CQS设计模式。但它的背后是什么?
CQS (命令查询分离)设计模式建议将对象的方法映射到两类
- 方法要么改变对象的内部状态,但不返回任何内容,要么只返回元数据。这种方法称为Command。
- 方法只是返回信息但不改变内部状态。这种方法称为Query。
根据 CQS,一个方法永远不应该同时存在上述的两种情况,所以说,它的核心思想非常简单,就是将系统中的操作明确拆分为上述两大独立的部分
在 CQS 模式的基础上,Greg Young 在 2010 年创造了 CQRS,它也将写入和读取分开,但在 API 方面。因此,它提出了单独的 API,一个专用于更改应用程序状态的命令路由,另一个专用于返回有关应用程序状态信息的查询路由。
传统开发中,我们通常用 统一的模型 处理读写,比如一个 UserService 既包含 createUser、updateUser,也包含 getUserById、listUsers,这种方式在简单场景下没问题,但在高并发、复杂业务场景下会暴露问题,因为它读写不隔离,互相影响,难以针对读写做差异化优化,而 CQRS 读写分离,就可以分别独立扩展
因此,请注意,CQRS 要求无副作用,Query 操作绝对不能修改数据,Command 操作只修改数据,这样在编写的时候别忘了细分
按照 Spring Boot 我们编写代码的思路,架构就可以这么拆分了
graph TD
A[客户端请求] --> B{请求类型}
B -->|Command(增删改)| C[Command 层]
B -->|Query(查询)| D[Query 层]
C --> C1[Command 模型(入参)]
C1 --> C2[Command Handler(命令处理器)]
C2 --> C3[写模型/领域服务(修改数据)]
C3 --> C4[写数据源(主库)]
D --> D1[Query 模型(入参)]
D1 --> D2[Query Handler(查询处理器)]
D2 --> D3[读模型(专用查询模型)]
D3 --> D4[读数据源(从库/缓存)]
C4 --> E[事件通知(可选,如CQRS+事件溯源)]
E --> D3[更新读模型]如上图,很多人在使用 CQRS 的时候,会把读写分开成两个数据库,一个应该针对写入进行优化,另一个针对读取进行优化,这样在写入时可以确保良好的完整性和一致性,同时在读取时实现高效率和高性能。
但是这他喵的代价也太大了,所以我就没用过,感觉很复杂了要是进行了这样的分离开发,所以我也就是了解一下其实)))
而 CQRS 常和 事件溯源(ES) 结合使用
因为发送到基于 CQRS 的应用程序的命令 API 的命令也可以在 DDD 意义上解释为聚合的命令。然后聚合按顺序生成一个或多个域事件,这些事件可以使用事件溯源存储在事件存储中,并用于聚合的稍后重放。






