
设计模式介绍
设计模式是一套被广泛接受和验证的软件设计解决方案,它描述了在特定情境下的解决问题的方法。设计模式提供了一套通用的设计原则和模式,用于解决软件设计和开发过程中的常见问题,例如对象创建、行为管理和结构组织等。
一般来说,设计模式解决的最经典的问题就是结构清晰,提高复用性
- 提高代码的可重用性:设计模式提供了经过验证的解决方案,可以在不同的项目和场景中重复使用。
- 提高代码的可维护性:设计模式使得代码结构更加清晰,易于理解和维护。
- 提高代码的可扩展性:设计模式使得系统更容易进行功能扩展和修改,同时降低了对现有代码的影响。
- 提高开发效率:设计模式提供了一种标准化的设计方法,可以加快开发过程,并减少出错的可能性。
- 提高代码的质量:设计模式经过多次验证和实践,可以帮助开发者编写更加优雅和高效的代码。
一些面向对象设计原则
单一职责原则
一个类应该只有一个引起它变化的原因。
每个类/模块/函数只负责一项功能。
这样很好的降低了耦合度,提高可读性和可维护性。
- 反例:一个
User类既处理用户数据存储,又负责发送邮件、生成报表。 - 正例:拆分为
UserRepository(数据)、EmailService(通知)、ReportGenerator(报表)。
开闭原则
软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。
当需求变化时,应通过新增代码来扩展功能,而不是修改已有代码。
实现方式一般就是多用抽象(接口/抽象类)+ 多态
经典应用:
- 策略模式(Strategy):新增策略无需改上下文。
- 工厂方法模式:新增产品类型只需加新工厂/产品类。
1 | // 定义支付接口 |
里氏替换原则
子类必须能够替换其基类,而不破坏程序的正确性。
含义:继承不是为了复用代码,而是为了“行为可被替换”。
- 子类不能削弱父类的前置条件;
- 子类不能加强父类的后置条件;
- 子类不应抛出父类未声明的异常。
接口隔离原则
客户端不应该依赖它不需要的接口。
把臃肿的大接口拆分成多个小而专注的接口。避免实现类被迫实现无用方法。
1 | interface Machine { |
依赖倒置原则
高层模块不应该依赖低层模块,二者都应该依赖抽象;抽象不应该依赖细节,细节应该依赖抽象。
通俗来说就是:面向接口编程,而不是面向实现编程。
DRY 原则
不要重复自己。
提倡抽象共性,避免代码复制粘贴。
注意:不是“不要出现相同代码”,而是“不要出现相同意图的逻辑分散在多处”。
KISS 原则
保持简单。
避免过度设计,能用简单方案就不用复杂模式。
简单 不等于简陋,而是恰到好处的清晰与直接。
YAGNI 原则
你不会需要它。
不要提前实现“可能未来会用到”的功能。
聚焦当前需求,避免无谓的复杂性。
组合优于继承
优先使用组合/聚合,而不是继承。
继承耦合强,组合更灵活。所以能组合就组合,没事别继承
设计模式如装饰器、策略、状态都体现了这一思想。
高内聚低耦合
高内聚:一个模块内部的元素紧密相关,最简单的反映就是一个类只做一件事
低耦合:模块之间依赖尽可能少、尽可能通过抽象交互。
设计模式总览
根据《设计模式:可复用面向对象软件的基础》这本书,23 种经典设计模式可分为三大类
创建型
创建型的设计模式关注对象的创建机制,提高灵活性和复用性。
- 单例模式(Singleton):确保一个类只有一个实例,并提供全局访问点。
- 工厂方法模式(Factory Method):定义创建对象的接口,由子类决定实例化哪个类。
- 抽象工厂模式(Abstract Factory):提供一个创建一系列相关或依赖对象的接口,而无需指定具体类。
- 建造者模式(Builder):将复杂对象的构建与表示分离,使得同样的构建过程可以创建不同表示。
- 原型模式(Prototype):通过复制现有对象来创建新对象,避免重复初始化开销。
结构型
结构型设计模式关注处理类或对象的组合,形成更大的结构。
- 适配器模式(Adapter):将一个类的接口转换成客户期望的另一个接口,使原本不兼容的类能一起工作。
- 桥接模式(Bridge):将抽象部分与实现部分分离,使它们可以独立变化。
- 组合模式(Composite):将对象组合成树形结构以表示“部分-整体”的层次关系,统一处理单个对象和组合对象。
- 装饰器模式(Decorator):动态地给对象添加额外职责,比继承更灵活。
- 外观模式(Facade):为子系统提供一个统一的高层接口,简化客户端使用。
- 享元模式(Flyweight):通过共享技术有效支持大量细粒度对象的复用。
- 代理模式(Proxy):为其他对象提供一种代理以控制对这个对象的访问。
行为型
行为型模式关注对象之间的职责分配和通信方式。
- 责任链模式(Chain of Responsibility):将请求沿处理链传递,直到有对象处理它为止。
- 命令模式(Command):将请求封装为对象,从而参数化客户、排队请求或记录日志。
- 解释器模式(Interpreter):定义语言的文法并解释该语言中的句子(适用于简单语法规则)。
- 迭代器模式(Iterator):提供一种顺序访问聚合对象元素的方法,而不暴露其内部表示。
- 中介者模式(Mediator):用一个中介对象封装一系列对象交互,降低耦合度。
- 备忘录模式(Memento):在不破坏封装性的前提下,捕获并外部化对象的内部状态以便恢复。
- 观察者模式(Observer):定义对象间一对多依赖关系,当一个对象状态改变时,所有依赖者自动更新。
- 状态模式(State):允许对象在其内部状态改变时改变其行为,看起来像改变了类。
- 策略模式(Strategy):定义一系列算法,把它们封装起来,并且使它们可以互相替换。
- 模板方法模式(Template Method):在一个方法中定义算法骨架,而将具体步骤延迟到子类中实现。
- 访问者模式(Visitor):表示一个作用于某对象结构中各元素的操作,可在不改变元素类的前提下定义新操作。
创建型模式
单例模式
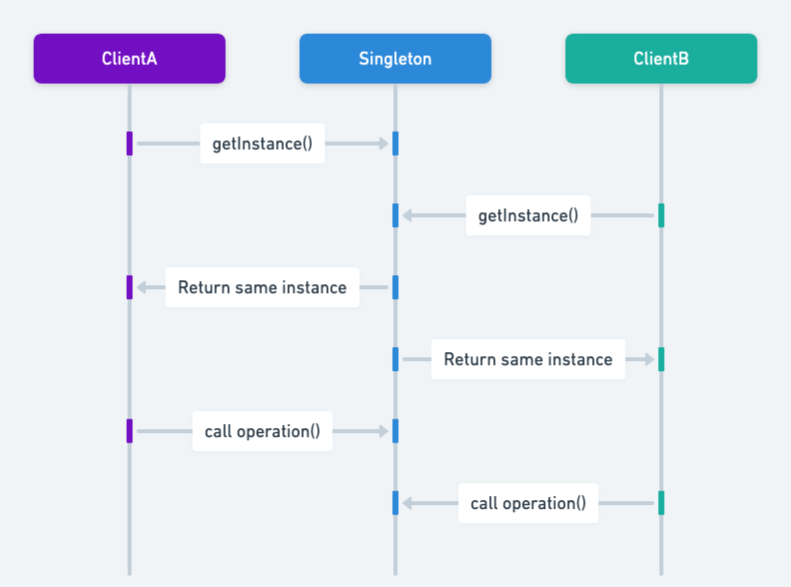
单例模式确保一个类在整个应用程序生命周期中只有一个实例,并提供一个全局访问点来获取该实例。
- 唯一性指的就是整个 JVM 中只存在一个该类的实例。
- 全局可访问指的就是提供一个静态方法(通常是
getInstance())供外部获取这个唯一实例。
要正确实现单例模式,需要在开发的时候注意满足这些内容
- 让类拥有私有构造函数:防止外部通过
new关键字创建实例。 - 私有静态成员变量:持有唯一的实例
- 拥有公共静态工厂方法:提供获取实例的入口
单例模式可以分为两种
- 预加载:也叫饿汉式,程序启动时就初始化对象,线程安全,不加锁
- 懒加载:也叫懒汉式,第一次访问时才创建实例,延迟加载,线程不一定安全

饿汉式 Eager Initialization
饿汉式是经典的预加载形式的单例
饿汉式,它会在类加载时就创建实例,因为 JVM 保证类初始化是线程安全的,所以它天然的线程安全,但是即使不用也会创建实例,存在浪费内存的情况,而且不支持懒加载
1 | // final确保类不会被继承 |
说一下其中的反射防护逻辑
- 正常情况下,
INSTANCE是静态常量,初始化时会调用构造方法,此时INSTANCE还未赋值(null),所以不会触发异常。 - 如果有人通过 Java 反射机制强行调用私有构造方法,此时
INSTANCE已经存在,就会抛出IllegalStateException,防止创建第二个实例。
它使用了 JVM 中对 static final (编译时常量)在类加载就创建其实例的机制,来确保 JVM 类加载时的静态变量初始化保证线程安全,但即使程序全程没有使用这个实例,也会占用内存
枚举单例 Enum Singleton
枚举单例,是《Effective Java》作者 Joshua Bloch 推荐的最优写法,是一种简单的懒加载形式
在 Java 中,枚举有几个天然适合做单例的特性:
- 枚举类的实例(枚举常量)在 JVM 加载枚举类时唯一且仅初始化一次,由 JVM 保证线程安全,是线程安全的简单可靠实现
- 枚举类默认继承
java.lang.Enum,其构造方法是隐式私有的,外部无法通过new创建实例。 - Java 序列化机制对枚举有特殊处理:反序列化枚举时不会创建新实例,而是直接返回已存在的枚举常量,避免序列化破坏单例。
- 反射无法创建枚举类的实例(
Constructor.newInstance()会直接抛出IllegalArgumentException),从根本上防止反射攻击。
但是枚举单例也是饿汉式,但是因为饿汉式这种情况下除了获取单例之外通常没有其他会导致这个类被加载的情况存在,所以我也认为,类加载机制本身就已经是一种懒加载了。
1 | package com.iluwatar.singleton; |
因为枚举类在编译后会被处理成一个继承 Enum
的最终类(final),且所有枚举常量都是
public static final 的,符合单例 “静态唯一实例”
的核心要求。
使用这个单例非常简单,直接通过枚举常量访问即可,无需调用任何方法:
1 | public class EnumSingletonDemo { |
枚举单例是最简洁、最安全的单例实现方式:天然线程安全,杜绝反射 / 序列化破坏单例,代码量极少。
但是它也有问题,它不能继承其他类(默认继承自Enum类),但是可以实现接口,扩展性差了一些
总结一下枚举单例,它是一种线程安全的预加载的单例模式,它对反射有天然防护,而且反序列化不新建,实现起来极其简单
线程安全的懒汉式Thread-Safe Lazy Loading
这是懒汉式也就是懒加载模式下的一个单例实现,它能在保证类只有一个实例的基础上而且是懒加载的情况下,解决基础懒汉式在多线程环境下可能创建多个实例的线程安全问题
因为基础的懒汉式设计
1 | // 基础懒汉式(非线程安全) |
首先,if 判断以及其内存执行代码是非原子性的。其次,new LazySingleton() 无法保证执行的顺序性。不满足原子性或者顺序性,线程肯定是不安全的
JVM 为了提高程序执行性能,会对没有依赖关系的代码进行重排序,所以说,上面的代码在初始化对象和设置其对象指向刚分配的内存地址这两步,概率会出现线程不安全。
那么,下面的代码就解决了这个多线程并发创建实例的问题,同时保留懒加载特性。
1 | public final class ThreadSafeLazyLoadedIvoryTower { |
其中核心就是 volatile 关键字,禁止 JVM 的指令重排优化,而且保证多线程间的内存可见性
new ThreadSafeLazyLoadedIvoryTower()实际分三步执行- 分配内存
- 初始化对象
- 给 instance 赋值(指向刚刚分配的内存地址)
如果没有
volatile,JVM 可能重排上述三步的后两步
那么,synchronized
实现了对类对象加锁,保证多线程下,同一时间只有一个线程能进入方法体,而且懒加载的核心就是只有当
instance == null 时才创建实例,第一次调用
getInstance() 前,instance 始终是
null,不会占用内存;
但是但是,如果要经常的调用 getInstance()
方法,不管有没有初始化实例,都会唤醒和阻塞线程。为了避免线程的上下文切换消耗大量时间,如果对象已经实例化了,我们没有必要再使用synchronized
加锁,直接返回对象。那么就是我们下一个说的,双重检查锁
双重检查锁懒汉式 Double-Checked Locking
为了解决 “每次调用都加锁” 的性能问题,所以,只需要把检查这步放在加锁前面,先检查有没有创建实例,在加锁
DCL 的核心思路是:只在实例未创建时加锁,实例创建后直接返回。
1 | public final class ThreadSafeDoubleCheckLocking { |
那么,简单说一下第二次检查
- 线程 A、B 同时调用
getInstance(),此时没有创建实例,所以可能都通过了第一次检查(instance == null); - 线程 A 先抢到锁,进入同步块,创建实例后释放锁;
- 线程 B 拿到锁后,进入同步块,第二次检查发现
instance != null,直接返回已有实例,避免重复创建。如果没有第二次检查,线程 B 会在线程 A 创建实例后,再次创建一个新实例,破坏单例。
对于var result = instance;,因为volatile
变量的读写有内存屏障开销,把 instance
赋值给局部变量后,后续只操作局部变量,也就是栈内存
这种写法既保留懒加载和线程安全,又大幅降低加锁的性能损耗,是目前最常用的懒汉式单例优化方案。
静态内部类懒汉式 InitializingOnDemandHolderIdiom
上面的代码还是太复杂了,想不好一步就容易寄,有没有更简单的打法
有点兄弟有的
JVM
对于内部类的加载是懒加载的,只有当内部类被主动引用时才会加载,所以,这个设计利用了这个特性,实现了懒加载,而且静态内部类初始化天然线程安全,无需
synchronized/volatile,依赖 JVM
保证了线程安全
1 | package com.iluwatar.singleton; |
那么,实际上就会
1 | // 1. 主类加载:无实例创建 |
它利用 JVM 的类加载机制保证线程安全。
- 外部类加载时,不会加载内部类;
- 只有调用
getInstance()时,才会触发InstanceHolder的加载和初始化; - 利用了 JVM 保证类的
<clinit>方法是线程安全的。全程不需要synchronized,避免锁竞争;
这个实现几乎没有缺点,但是
- 序列化问题:如果类实现
Serializable接口,反序列化时会创建新实例(可以重写readResolve()方法,返回HelperHolder.INSTANCE); - 不支持传参初始化:如果单例创建需要传入参数,这个实现无法直接支持,此时 DCL 或枚举单例更适合。
工厂方法模式
工厂方法模式分为两种
- 静态工厂(静态工厂方法模式)
- 工厂方法(多态工厂模式)
静态工厂
它并非 GoF(四人组)正式定义的 23 种设计模式之一,但却是工厂模式家族的基础,常被归类为工厂方法模式的简化版。
简单工厂模式通过一个工厂类(而非多个工厂子类),提供一个静态方法,根据入参的不同创建并返回不同类型的产品实例,客户端无需关心产品的创建细节,只需传入指定参数即可。
也就是定义了一个创建对象的类(工厂类),由这个类来封装实例化对象的行为。
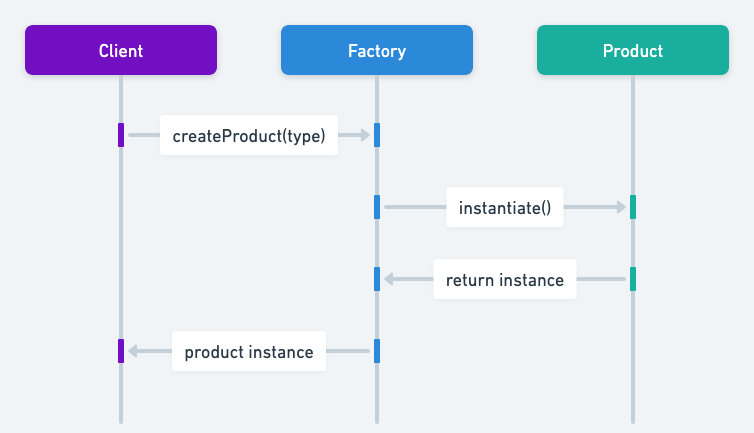
以 java-design-patterns 中的内容作为例子讲解
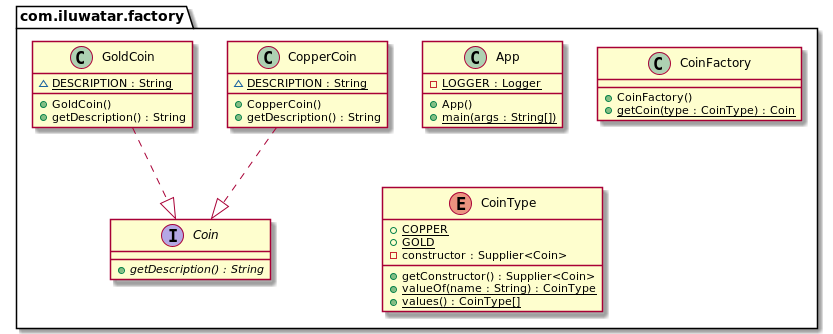
| 简单工厂模式角色 | 本示例对应类 / 枚举 | 作用说明 |
|---|---|---|
| 产品接口(Product) | Coin.java | 定义所有产品(不同类型硬币)的通用行为,这里通过getDescription()方法统一规范硬币的描述能力。 |
| 具体产品(Concrete Product) | CopperCoin.java、GoldCoin.java | 实现产品接口的具体类,分别对应 “铜币” 和
“金币”,各自重写getDescription()返回专属描述。 |
| 工厂类(Factory) | CoinFactory.java | 核心工厂类,提供静态方法getCoin(CoinType type),根据传入的硬币类型参数,创建并返回对应的具体硬币实例。 |
| 产品类型枚举(辅助) | CoinType.java | 封装不同硬币类型的创建逻辑(通过Supplier<Coin>函数式接口关联具体硬币的构造器),简化工厂类的判断逻辑。 |
| 客户端(Client) | App.java | 调用工厂类的静态方法,传入类型参数获取产品实例,无需直接 new 具体产品,聚焦于产品的使用。 |
产品接口
1 | package com.iluwatar.factory; |
- 定义了产品的抽象行为,是所有具体硬币类的统一规范
具体产品:CopperCoin.java &
GoldCoin.java,以CopperCoin为例:
1 | package com.iluwatar.factory; |
- 实现了
Coin接口,重写getDescription()
产品类型枚举
1 | package com.iluwatar.factory; |
- 这是对简单工厂模式的优化:传统简单工厂会用
if-else/switch判断类型,这里通过枚举 + 函数式接口,更好一些,而且Supplier<Coin>是 Java 8 + 的函数式接口,get()方法会返回一个新的 Coin 实例
其中的工厂类
1 | package com.iluwatar.factory; |
- 核心是静态方法
getCoin,无需创建工厂实例即可调用,而且直接通过枚举的constructor(Supplier)创建产品,也就是说,不用类内部判断类型了,只需要传入类型就可以
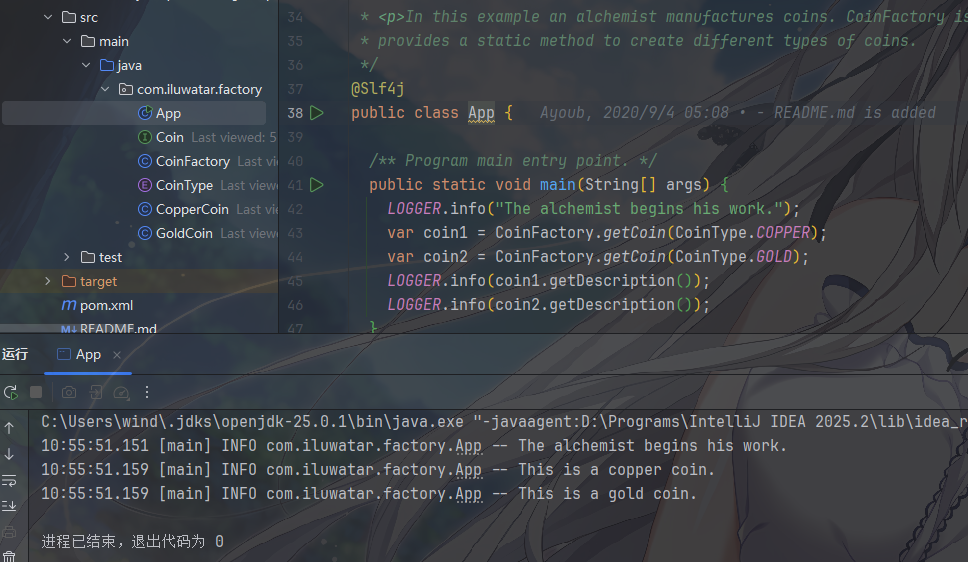
- 客户端完全隔离了产品的创建逻辑,只知道 “调用工厂方法,传入类型,得到硬币”
简单工厂模式有一个问题就是,类的创建依赖工厂类,也就是说,如果想要拓展程序,例如我添加了一个银币,需要新增SilverCoin.java实现Coin接口,枚举类中加一条SilverCoin等等等等,肯定有一步涉及到了必须对工厂类进行修改,这违背了开闭原则
所以,从设计角度考虑,它有一定的问题,如何解决?
我们可以定义一个创建对象的抽象方法并创建多个不同的工厂类实现该抽象方法,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
这种方法也就是我们接下来要说的工厂方法模式。
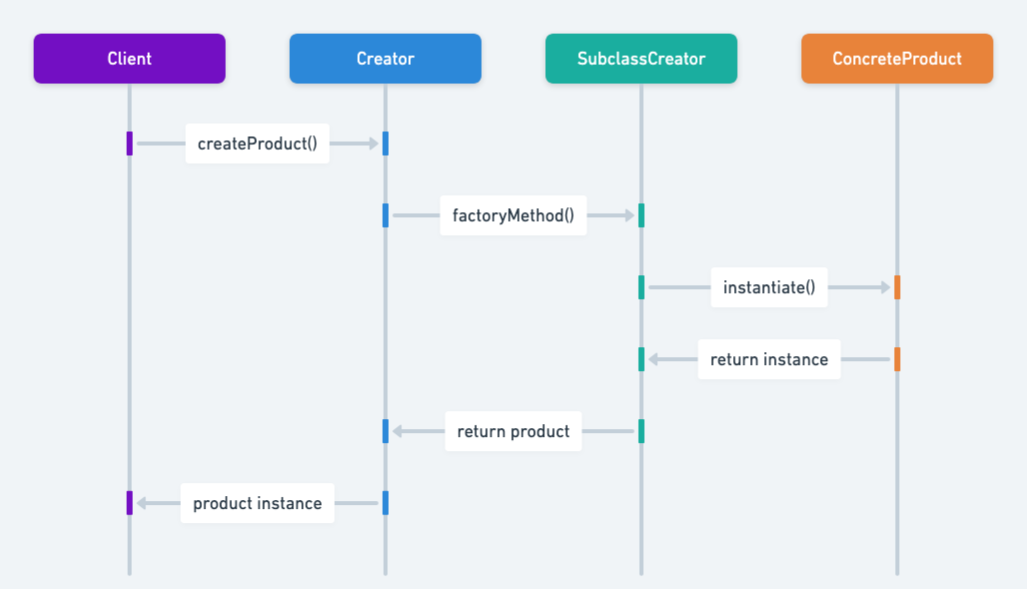
工厂方法模式
定义一个创建对象的接口,让子类决定实例化哪一个类,将对象的创建延迟到子类中完成。
继续上述的例子,工厂方法模式会为每种硬币创建对应的工厂类,但是这里换成武器了
| 工厂方法模式核心角色 | 代码中的对应类 / 接口 | 角色职责 |
|---|---|---|
| 产品接口(Product) | Weapon 接口 |
定义所有具体产品必须实现的统一接口(规范) |
| 具体产品(Concrete Product) | OrcWeapon、ElfWeapon |
实现产品接口的具体类,是工厂方法最终创建的对象 |
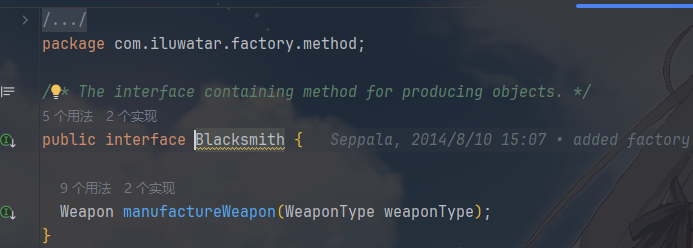
| 工厂接口(Creator) | Blacksmith 接口 |
声明工厂方法(manufactureWeapon),返回产品接口类型的对象 |
| 具体工厂(Concrete Creator) | OrcBlacksmith、ElfBlacksmith |
实现工厂接口,重写工厂方法,返回具体产品实例 |
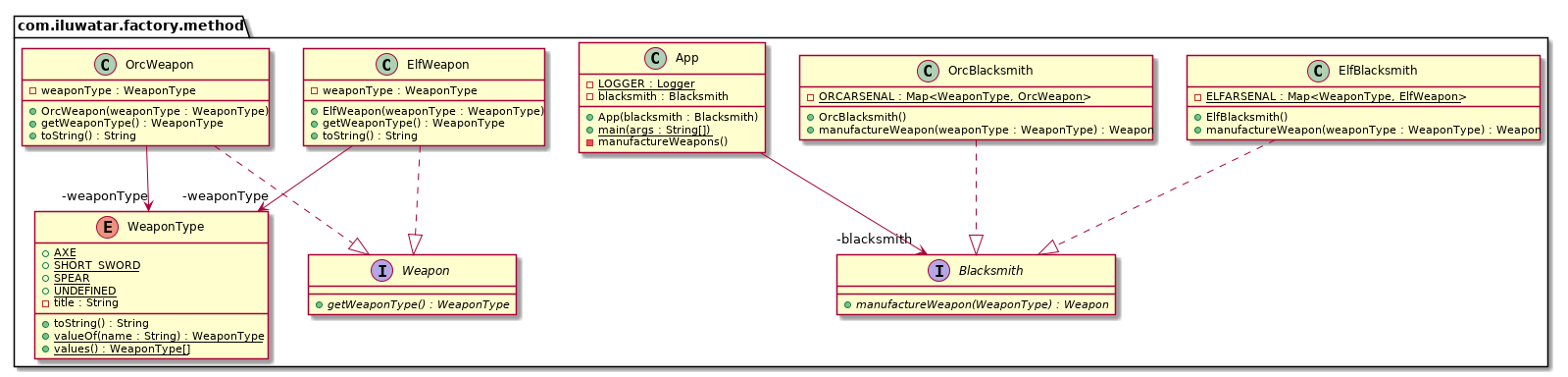
产品接口中只有一个方法,还是规范具体的产品需要实现的接口
1 | public interface Weapon { |
产品类型就还是那样,定义工厂支持生产的子产品
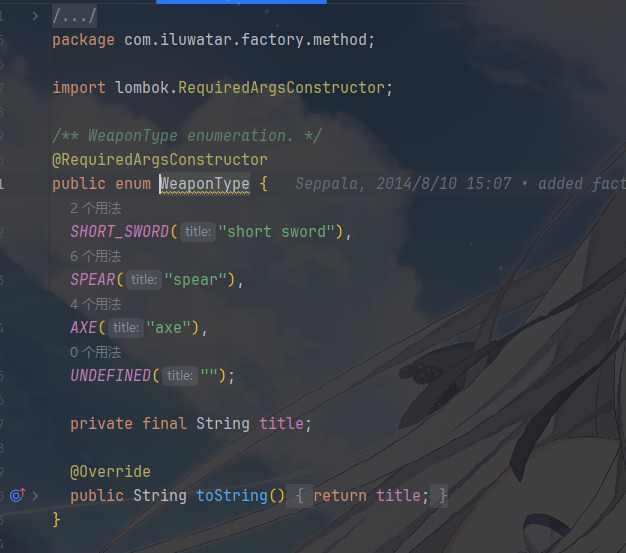
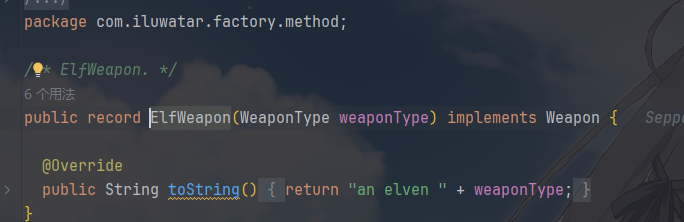
具体产品 OrcWeapon / ElfWeapon,都实现了 Weapon 接口,用
record 简化实现
产品层看上去没有太大差别,但是来到工厂层,这里定义 “造武器” 的工厂规范,就有很多不一样的了
工厂接口,声明工厂方法 manufactureWeapon,入参是
WeaponType(要造的武器类型),返回
Weapon(产品接口),仅定义 “造武器”
都需要的一系列行为,不关心具体的武器是怎么造的:
那么,上面对应的两种武器,在这里就有两种工厂,分别是兽人铁匠OrcBlacksmith
和 精灵铁匠ElfBlacksmith,它们都实现 Blacksmith
接口,负责创建 对应的武器 实例:
1 | public class OrcBlacksmith implements Blacksmith { |
来到客户端,客户端只依赖 工厂接口(Blacksmith) 和 产品接口(Weapon),不直接创建具体产品(OrcWeapon/ElfWeapon),完全通过工厂获取对象,符合 依赖倒置原则
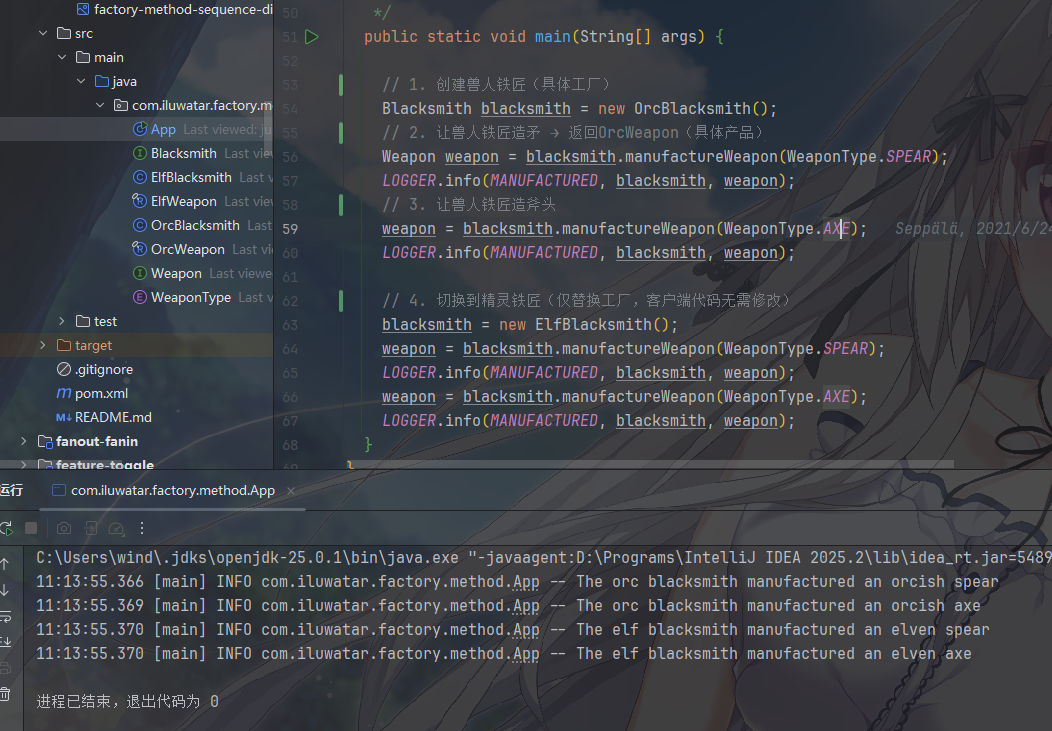
工厂方法模式的优点不言而喻
如果要新增 “人类武器” 和 “人类铁匠”,只需:
新增
HumanWeapon实现Weapon;新增
HumanBlacksmith实现Blacksmith;无需修改现有工厂(Orc/ElfBlacksmith)、产品(Orc/ElfWeapon)或客户端代码,仅扩展即可。
我最爱用这种设计模式
工厂工具包模式
它是简单工厂模式的一种现代化、函数式扩展变体,核心是通过 “工具包”(一组预定义的构建器)封装对象创建逻辑,支持灵活、类型安全的对象实例化,尤其适配 Java 8 + 的函数式编程特性。
与传统简单工厂不同,Factory Kit 通过注册式构建器将 产品类型 - 创建逻辑 这个映射关系解耦,更符合 开闭原则,也更易扩展。
如果按照上述例子,用这个设计模式写出来的例子就是这样的
| 设计模式角色 | 代码中的实现类 / 接口 | 作用 |
|---|---|---|
| 产品接口 | Weapon |
定义所有产品(武器)的通用接口,是工厂创建对象的统一返回类型 |
| 具体产品 | Sword/Axe/Bow/Spear |
实现Weapon接口的具体产品类,封装产品自身的行为(示例中仅重写toString) |
| 产品类型枚举 | WeaponType |
枚举所有可创建的产品类型,作为工厂创建对象的 “索引”,避免字符串硬编码 |
| 构建器接口 | Builder |
定义 “注册产品类型 - 创建逻辑” 的接口,是工厂工具包的核心扩展点 |
| 工厂工具包接口 | WeaponFactory |
定义工厂的核心能力(创建产品),并提供工厂实例的创建方法 |
| 客户端 | App |
使用工厂工具包创建具体产品,无需关心产品的实例化细节 |
个人只能认为这个算是一种工厂方法模式,但是是对 Java 的一个特别变体,简单说一下
产品类型枚举还是这样,只不过只规定了生产什么产品,只不过具体的映射逻辑在工厂里面
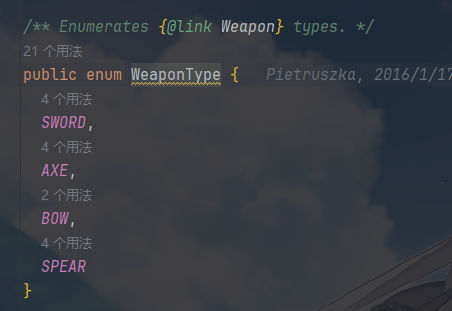
构造器接口
1 | public interface Builder { |
然后工厂接口中的静态方法根据入参,存储具体的映射来创建对应的产品
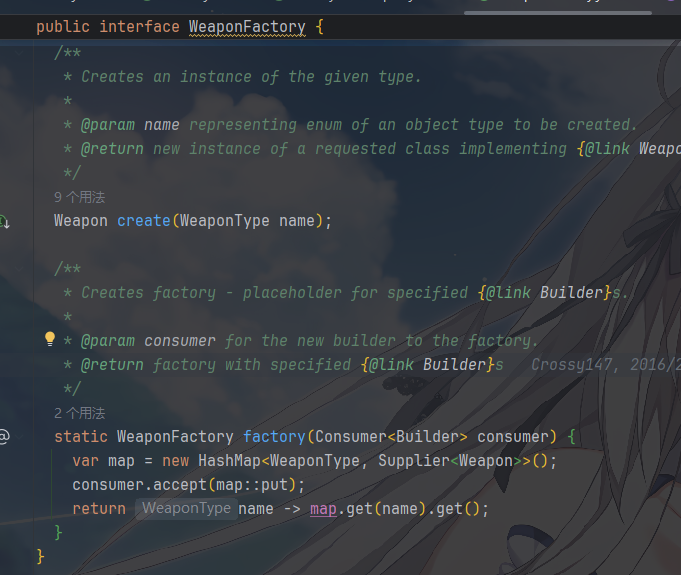
那么它的使用是这样的
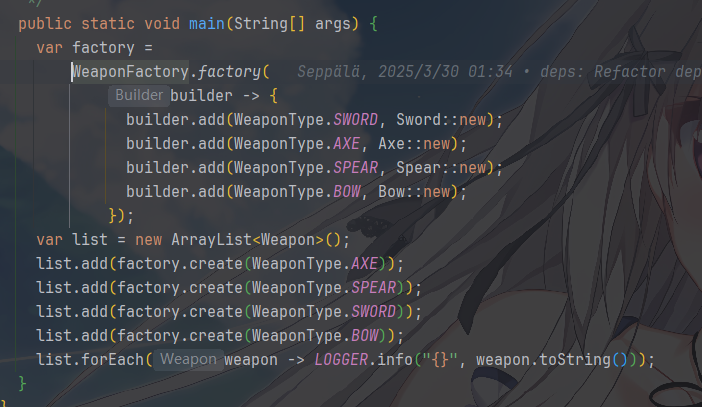
抽象工厂模式
抽象工厂模式的思路是提供一个接口,用于创建一系列相关或相互依赖的对象,而无需指定它们的具体类。
强调的是 “一组产品” 的创建,而非单个产品,适用于需要统一创建多个关联产品的场景
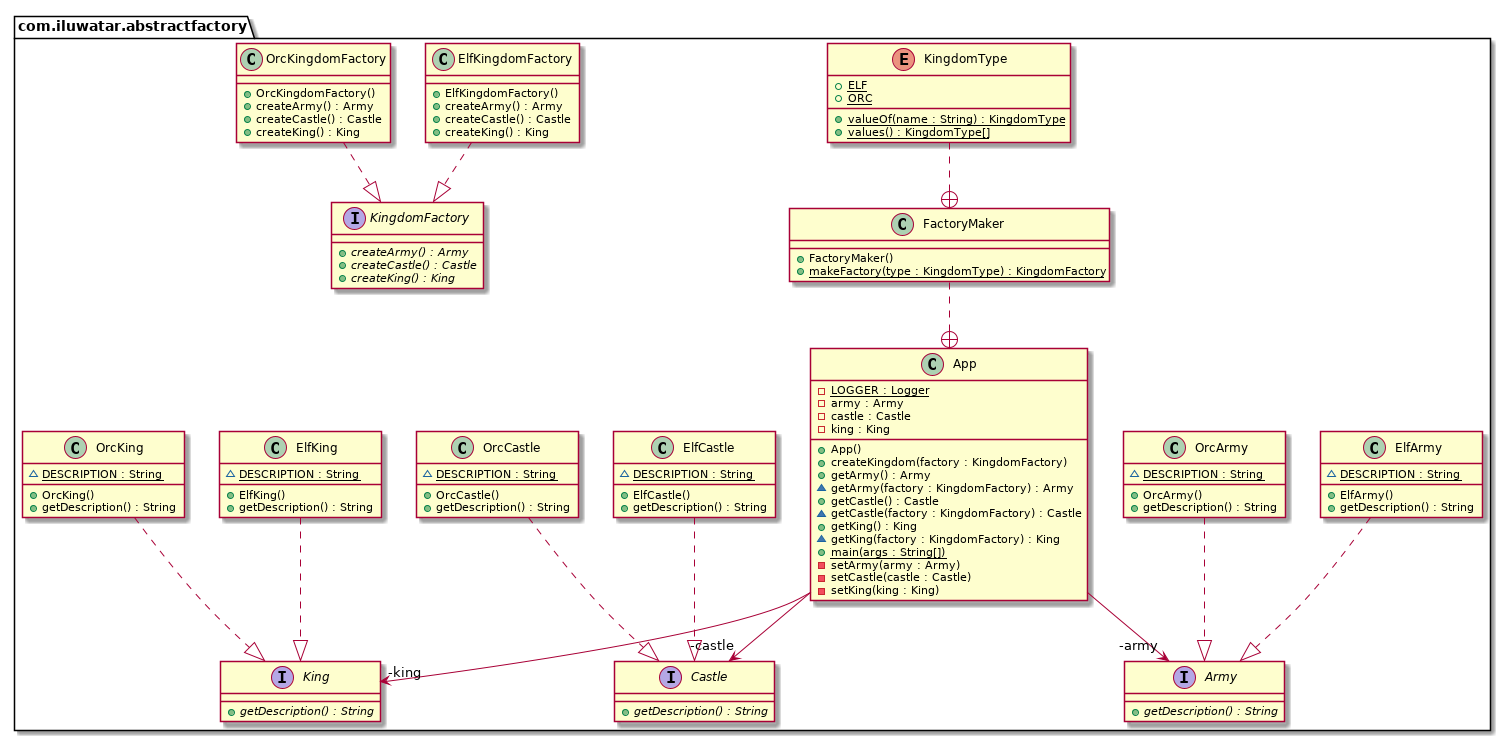
抽象工厂模式包含 4 个核心角色
| 角色 | 定义 | 示例代码对应类 / 接口 |
|---|---|---|
| 抽象工厂(Abstract Factory) | 声明创建一系列抽象产品的方法,每个方法对应一种抽象产品。 | KingdomFactory
接口(定义createCastle()、createKing()、createArmy()) |
| 具体工厂(Concrete Factory) | 实现抽象工厂的方法,创建一组具体产品(属于同一产品族)。 | ElfKingdomFactory、OrcKingdomFactory |
| 抽象产品(Abstract Product) | 为每种产品声明接口,定义产品的通用行为。 | Castle、King、Army
接口(都有getDescription()) |
| 具体产品(Concrete Product) | 实现抽象产品接口,是具体工厂创建的目标对象(属于某一产品族的具体产品)。 | ElfCastle/OrcCastle、ElfKing/OrcKing、ElfArmy/OrcArmy |
抽象产品层,在这里定义产品的通用行为,还是老套路,仅声明产品核心方法,不关注具体的实现,在这个例子里,王国这个产品族中有城堡、国王、军队三个产品,它们是互相关联的
1 | // 抽象产品:城堡 |
具体产品层,实现了抽象产品的具体逻辑,每个具体产品属于某一
“产品族”,,比如ElfCastle是 “精灵王国”
的城堡,OrcCastle是 “兽人王国” 的城堡
抽象工厂层用于定义创建一组产品的方法

KingdomFactory是抽象工厂接口,声明了创建 “城堡、国王、军队” 这一组产品的方法,约束所有具体工厂的行为:
具体工厂层用于对创建同一产品族的所有产品提供具体实现
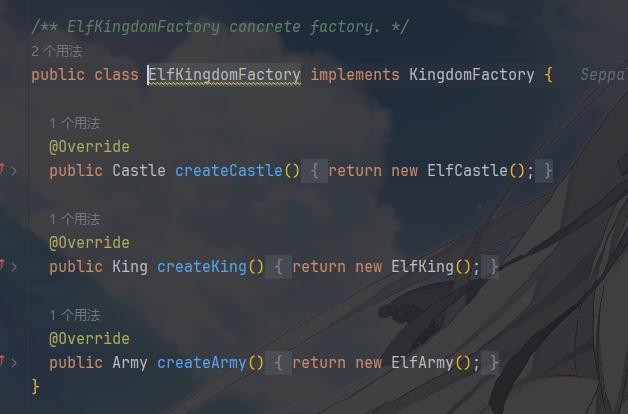
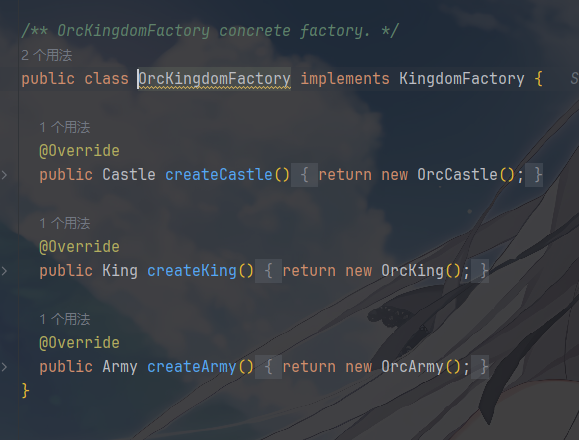
工厂制造者是封装工厂的创建逻辑,emmm他写在了产品族Kingdom的定义这里,如果是我的习惯,我可能会把 FactoryMaker 给分离出去
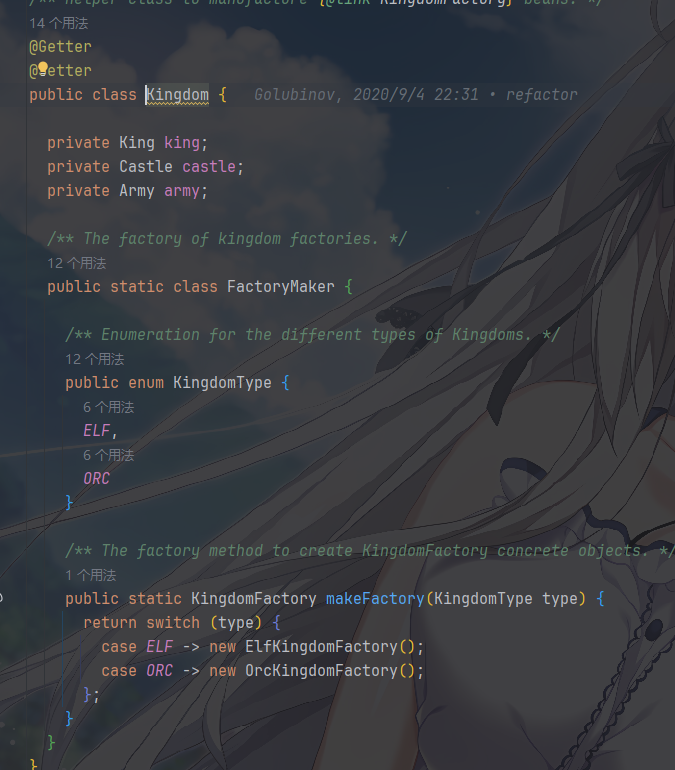
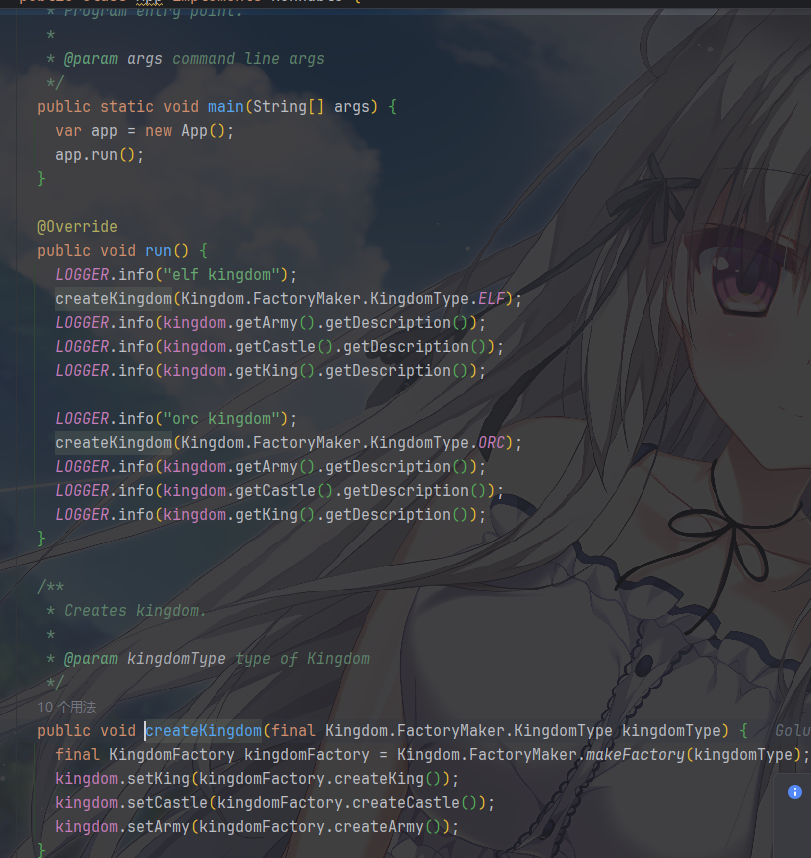
前面都很好懂,这里有一些事情要说一下,例子中Kingdom.FactoryMaker是一个辅助类,通过makeFactory()方法根据传入的类型来创建对应的具体工厂,这实际上是对客户端和创建具体工厂的又一步解耦,很值得学习
是客户端,它只依赖KingdomFactory(抽象工厂)和Castle/King/Army(抽象产品),无需知道具体创建的是精灵还是兽人产品,符合
“面向接口编程”:
建造者模式
建造者模式也叫生成器模式,它将一个复杂对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。
- 分步构建:客户端可以一步一步地设置对象的各个组成部分。
- 最终构建:当所有必要的部分都设置好后,调用一个
build()方法来生成最终的、完整且一致的对象。 - 不可变性:最终构建出的对象通常是不可变的
就类似于我们平常拼接字符串,其中,依旧使用例子来描述
其中,产品如下
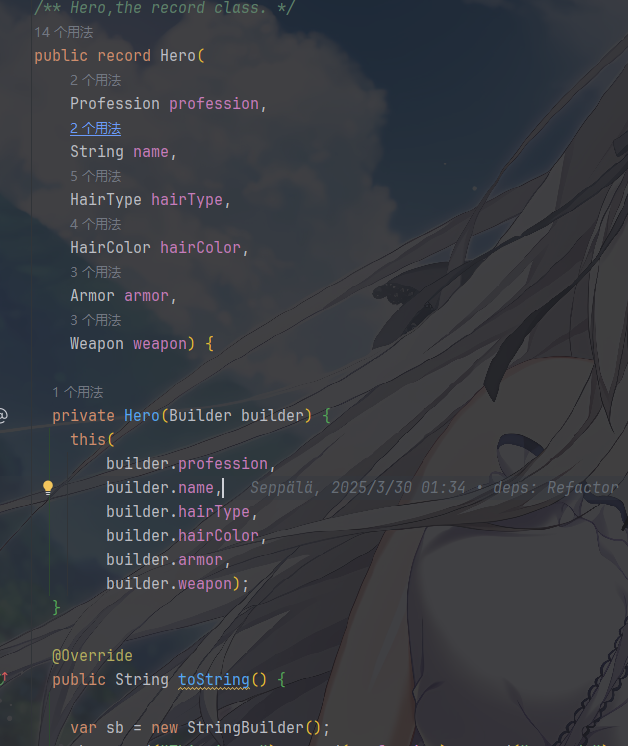
抽象建造器,一般来说,该接口需要定义产品的具体构造步骤,除了为创建一个Product对象的各个组件定义了若干个方法之外,还要定义返回Product对象的方法
它把建造者写到了上面产品类中,把接口和具体生产器二合一了,作为一个静态内部类表示构造,而且Hero
的主构造函数是 private 的,只能通过 Builder
来创建,控制了构建的过程
1 | /** The builder class. */ |
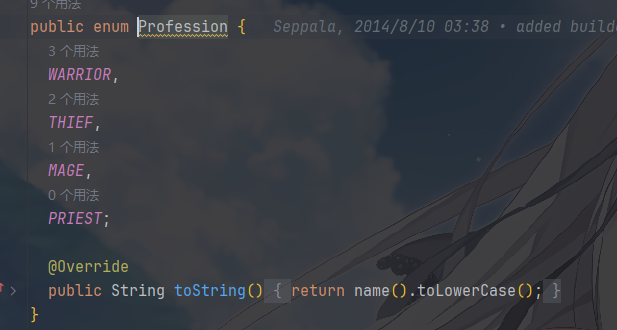
而且在这里,很简单的实现了必填和选填的实现,其中一些枚举类就是规定了可选值。例如
一般来说,如果你的生产过程比较复杂,需要有抽象建造器接口,然后具体生产器实现Builder接口中的方法
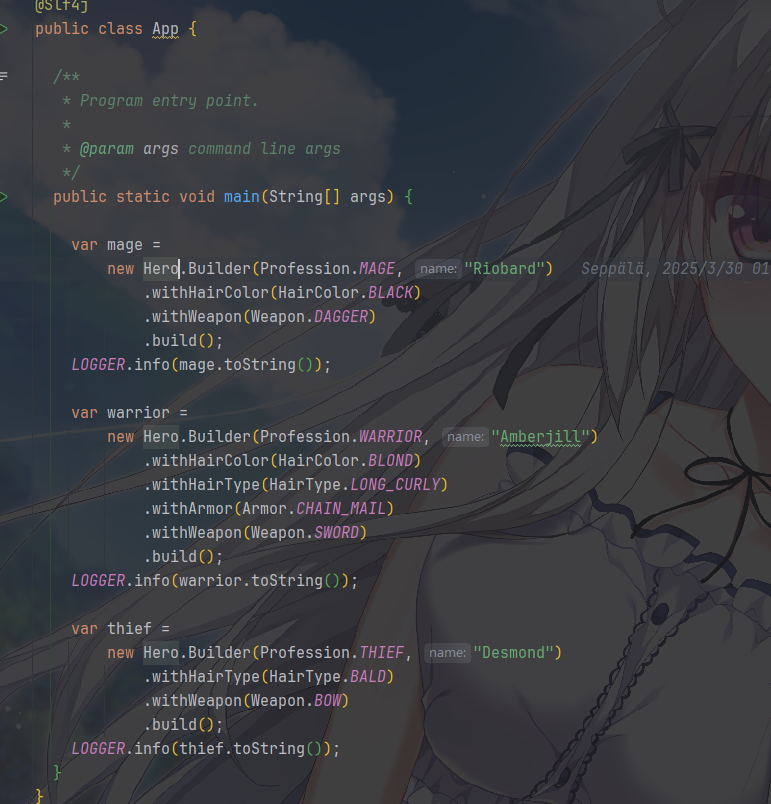
链式调用方法即可使用,估计写 Spring Boot 业务的就很熟悉这个设计模式了
原型模式
介绍及例子
原型模式的核心思路是通过复制(克隆)一个 “原型实例”
来创建新对象,而非通过 new
关键字从头初始化,以此避免重复创建对象的开销,同时简化对象创建流程。
原型模式的核心角色分为三类,代码中各角色的对应关系如下:
| 角色 | 职责 | 代码中的实现类 / 接口 |
|---|---|---|
| 抽象原型(Prototype) | 定义克隆自身的方法,是所有具体原型类的父类 / 接口 | Prototype<T>
抽象类 |
| 具体原型(Concrete Prototype) | 实现抽象原型的克隆方法,是被复制的 “原型对象” | ElfMage/OrcMage、ElfWarlord/OrcWarlord、ElfBeast/OrcBeast |
| 原型管理器(Prototype Manager) | 管理原型对象,提供创建原型副本的工厂方法(简化克隆调用) | HeroFactory 接口 +
HeroFactoryImpl 实现类 |
那么,来看具体的例子
抽象原型,Prototype<T>
类,这是所有可克隆对象的基类,封装了通用的克隆逻辑:
1 | public abstract class Prototype<T> implements Cloneable { |
- 它继承
Cloneable接口,这是 Java 中实现克隆的标记接口,因为这个接口里面没有方法,就是声明,通过super.clone()调用 Object 类的原生克隆方法,返回当前对象的浅拷贝副本;
原型模式通常需要泛型来保证返回值的类型安全
具体原型就是各类英雄,所有具体英雄类都继承自
Prototype,并定义空的拷贝构造函数给子类发挥重写,它们又各自抽象了对应英雄类的方法,作为一个抽象类声明了这三种英雄
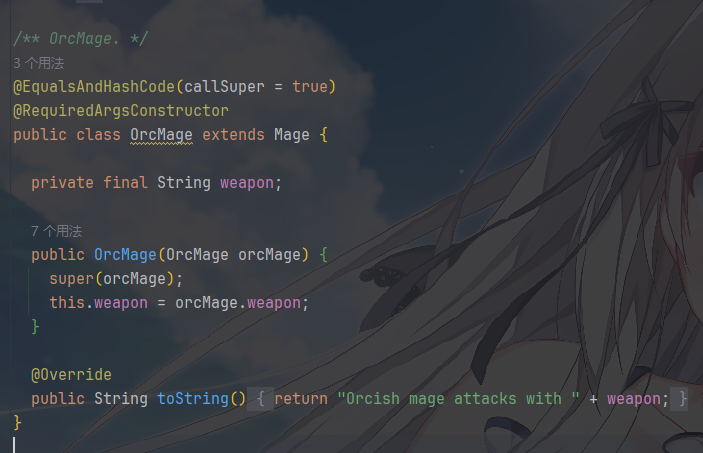
然后就是更具体的对象,通过调用父类的构造函数来克隆,保证克隆对象的属性与抽象原型Prototype<T>
是一致的,以 OrcMage 为例:
原型管理器:HeroFactory 工厂类接口及其对应的实现
工厂类封装了 “通过原型克隆创建对象” 的逻辑,对外提供统一的创建接口:
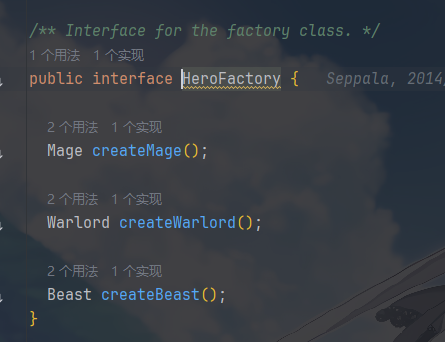
实现类实现它们,用于描述通过原型克隆创建对象的具体逻辑
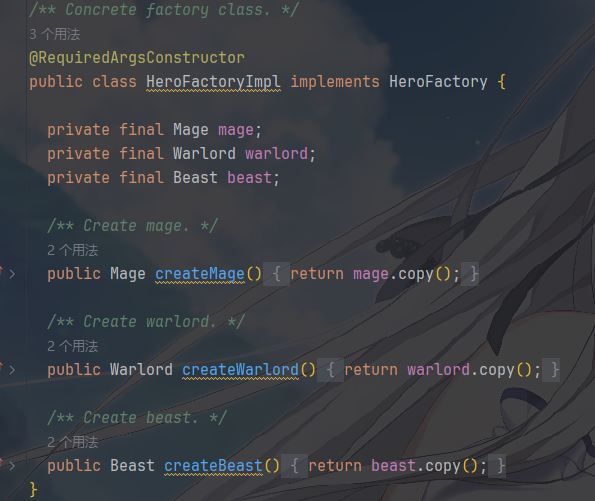
你看他们都是用原型的 copy() 方法克隆新对象,而非
new 关键字创建。
客户端只需初始化一次原型工厂,即可通过克隆快速创建新对象:
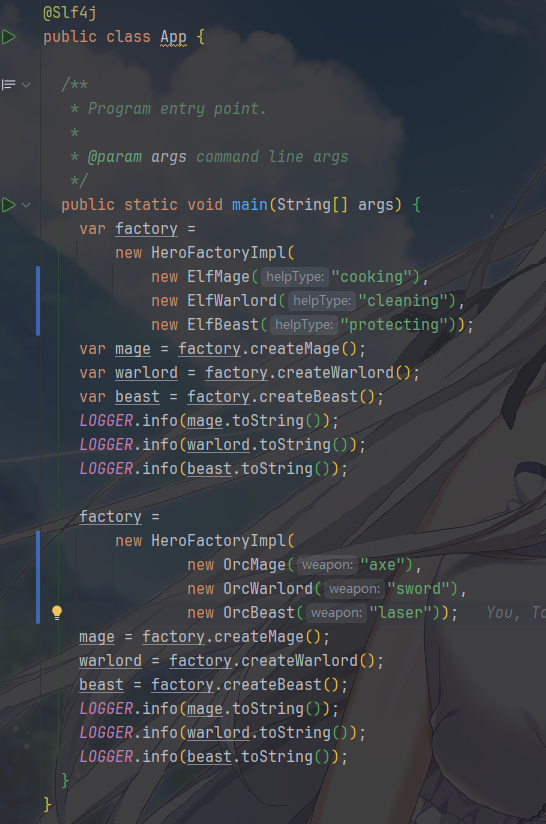
注意要使用浅拷贝,也就是代码中使用的 Object.clone()
- 浅拷贝:仅复制对象的基本类型成员变量,引用类型成员变量仅复制引用,也就是说,本质是直接复制内存块,无需递归创建新对象
- 深拷贝:复制对象的所有成员,原对象和克隆对象完全独立。深拷贝将创建完全独立的副本,原对象和副本之间不会共享引用
原型模式的核心价值之一是降低对象创建开销,如果为了深拷贝引入复杂的递归复制或序列化逻辑,会抵消克隆带来的性能收益;
但是也不是不能用深拷贝,涉及到需要深拷贝的三种的情况,深拷贝该用就用
- 原型对象包含可变引用类型成员(如
ArrayList、自定义对象User、Map等),否则修改克隆对象的可变引用成员会影响原型。 - 克隆后的对象需要独立修改引用成员,而且不能影响原对象
- 多线程环境下,克隆对象和原型对象可能并发修改引用成员
关于拷贝的内容,推荐看 https://blog.csdn.net/m0_53926113/article/details/142911152
什么地方广泛使用了原型模式?可以在什么地方使用原型模式






