
什么是Arthas
通常,本地开发环境无法访问生产环境,如果在生产环境中遇到问题,无法调试也无法暂停服务。那么,Arthas 作为生产环境中的观察者永远不会暂停正在运行的线程。
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,来帮助排查线上问题。
在你的生产环境上安装Arthas
Arthas 支持在 Linux/Unix/Mac
等平台上一键安装,请复制以下内容,并粘贴到命令行中,敲 回车
执行即可:
1 | curl -L https://arthas.aliyun.com/install.sh | sh |
上述命令会下载启动脚本文件 as.sh
到当前目录,你可以放在任何地方或将其加入到 $PATH 中。
直接在 shell 下面执行./as.sh,就会进入交互界面。
也可以执行./as.sh -h来获取更多参数信息
或者最新版本,点击下载:[Arthas](https://arthas.aliyun.com/download/latest_version?mirror=aliyun)
直接在 shell 下面执行./as.sh,就会进入交互界面

这里直接选择需要监控的 Java 进程就可以了,我这边服务器上就一个
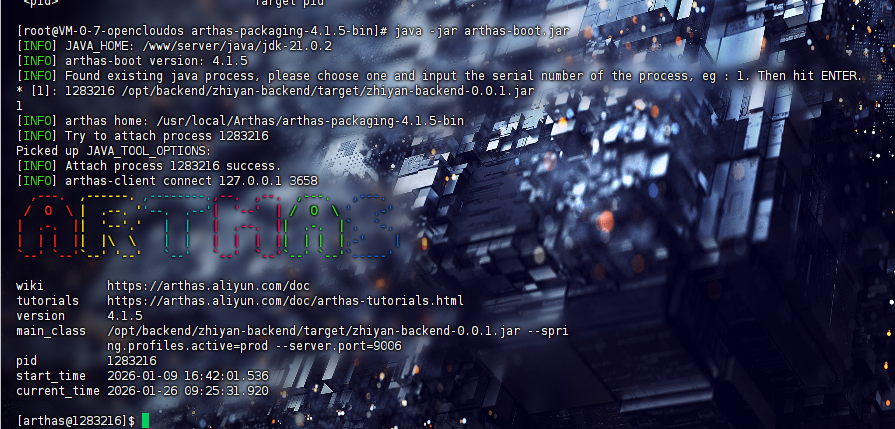
然后这样算是启动成功了,进入了 Arthas 交互界面
windows 上也可以这样安装,虽然 Arthas 是监控远程服务的,但是我也喜欢拿这个去排查本地服务存在的问题(一般是接口),也不一定就比 IDEA 调试不好用
Arthas 快速使用案例
进入到 Java 进程之后
查看整体运行状态
1
dashboard
实时显示CPU、内存、GC、线程数、JVM 信息等。全局视角了解应用健康状况。
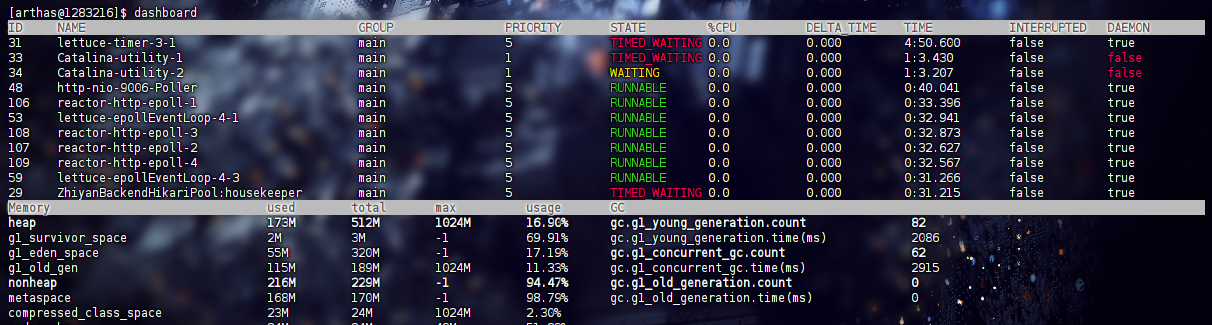
解释一下其中的内容,ID / NAME就是线程 ID 和名称,STATE就是线程状态,%CPU就是CPU占用率,DAEMON意味是否守护线程(一般情况下所有业务线程都是守护线程)
关于 Memory 内存区就是 Heap堆内存,G1 eden区、Survivor区,老年代区,然后GC了多少次,平均耗时多少,一般情况下无 Full GC,停顿时间短就正常
非堆内存就是 Metaspace元空间,CCS区,JIT 编译代码缓存
查看线程情况
1
thread
列出所有线程,按 CPU 使用率排序。一般情况下我们不用这个,用这些
1
2
3
4
5
6# 查看最忙的几个线程
thread -n 3
# 查看某个线程堆栈
# thread 1会打印线程 ID 1 的栈,通常是 main 函数的线程
thread 1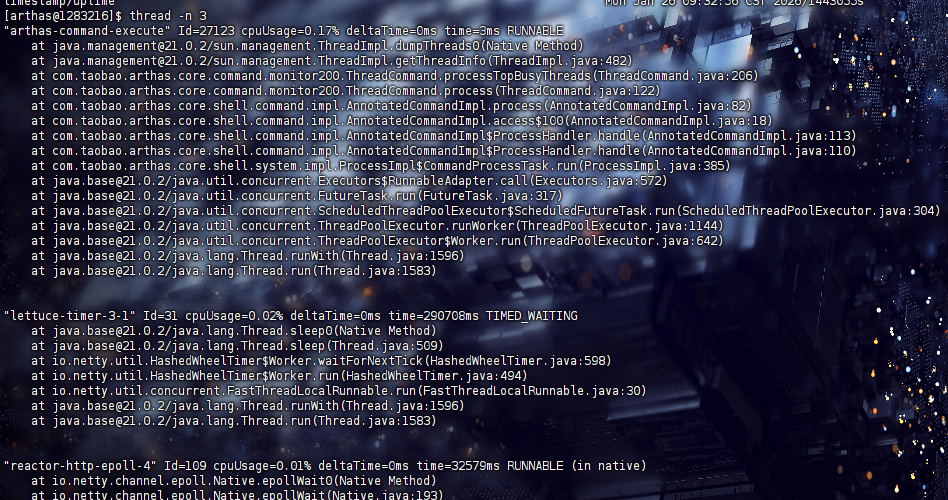
挺幽默的,当前 CPU 最忙的线程是arthas自己,其实也正常,想一下,因为
thread -n 3需要采集所有线程的 CPU 时间,这个操作本身会触发 JVM 的线程 dump,所以 Arthas 的命令执行线程会短暂“变忙”。第二忙的是 Lettuce,也就是 Spring Boot 在不设Redisson的情况下的默认客户端,然后就是 netty,这些内容都说比较清晰好读的搜索已加载的类
1
2sc *Controller
sc com.example.zhiyan.*Service这种都行,就是查看你的业务类是否被加载,也就是对应Arthas说的我改的代码有没有执行到?

在这里就能看到服务已加载的类
查看某个类的方法
1
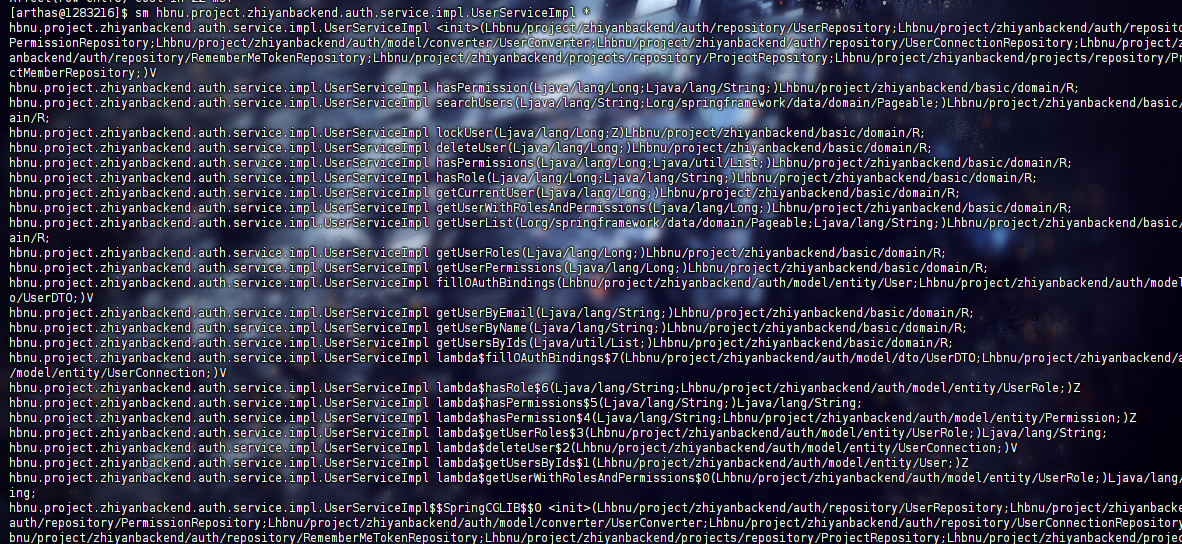
sm hbnu.project.zhiyanbackend.auth.service.impl.UserServiceImpl *
列出某个类的所有方法,注意要写全限定类名,为后续 trace/watch 做准备
监控方法调用耗时
它会统计该方法的调用次数、平均耗时、失败率等。
1
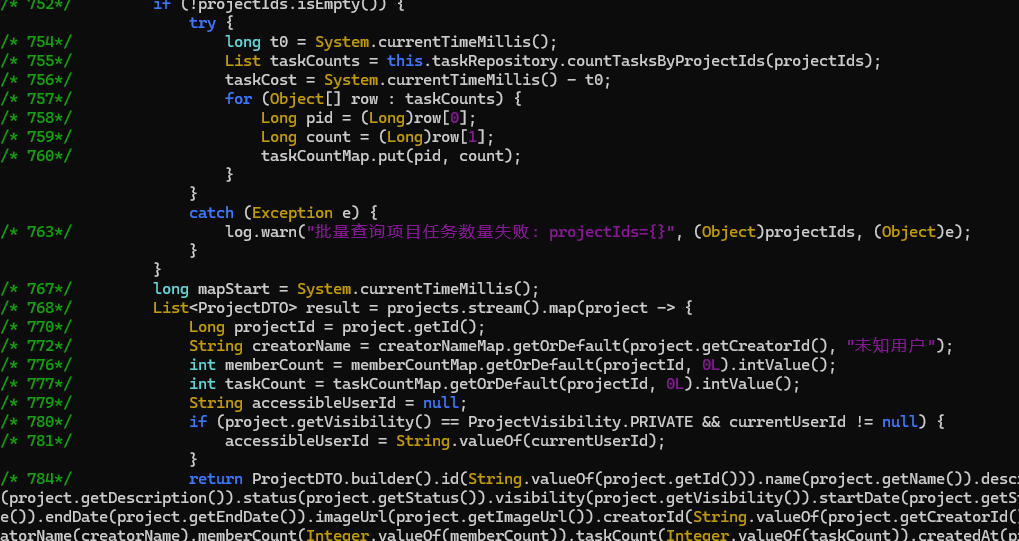
monitor hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl* getAllProjects
这里使用通配符来追踪原始类和代理类,一般情况下这样写要更简单
追踪方法的内部调用
1
trace hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl* getAllProjects
观察方法入参和返回值
1
watch hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl$$SpringCGLIB$$0 updateProjectStatus '{params, returnObj}' -x 3
查看 JVM 系统属性
1
2sysprop | grep port
sysenv | grep JAVA_HOME这个很有用,是确认运行环境配置的,一般是确认环境变量

反编译类
1
jad hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl
直接看到 JVM 中实际加载的字节码对应的 Java 源码。确认是否部署了最新代码
退出
1
2
3quit
exit
# 这俩都行Arthas agent 会自动 detach,原 Java 进程继续运行。
Arthas表达式核心变量
无论是匹配表达式也好、观察表达式也罢,他们核心判断变量都是围绕着一个
Arthas 中的通用通知对象 Advice 进行。
它的简略代码结构如下
1 | public class Advice { |
Arthas 使用 OGNL(Object-Graph Navigation Language) 作为表达式语言。你可以在命令中直接使用上述字段,就像它们是局部变量一样。
1 | # 观察方法参数 |
但是 Arthas 在解析 OGNL 表达式时,只将 Advice
对象的字段暴露为上下文变量。
常用的 ONGL 观察表达式如下
| 表达式 | 说明 |
|---|---|
{params} |
所有参数(数组) |
params[0] |
第一个参数 |
target |
当前对象(this) |
target.fieldName |
当前对象的某个字段 |
returnObj |
返回值 |
throwExp |
异常对象(仅 -e 时有效) |
#cost |
方法耗时(毫秒) |
@ClassName@staticField |
静态字段 |
@ClassName@staticMethod() |
静态方法 |
命令
基础命令
cls
清屏,清空当前屏幕
终端模式下才能使用 cls 指令
history
pwd

返回工作目录,和Linux的一样
reset
重置增强类,将被 Arthas 增强过的类全部还原,Arthas
服务端stop时会重置所有增强过的类
一般情况下,在 trace,monitor 等这种会向方法中放入切面的类需要重置
session
查看当前会话的信息,也就是监控的是哪个进程id的java进程
quit
退出当前 Arthas 客户端
stop
关闭 Arthas 服务端,所有 Arthas 客户端全部退出
JVM
dashboard
介绍过了,查看当前系统的实时数据面板
getstatic
查看类的静态属性,命令结构:
1 | getstatic class_name field_name |
heapdump
生成当前 Java 进程的堆内存快照,Heap Dump是堆转储,是一个
.hprof 文件。记录了 Java
虚拟机(JVM)在某一时刻堆内存中所有对象的状态,一般使用 JProfiler
分析
1 | heapdump arthas-output/dump.hprof |
生成文件在arthas-output目录,而且这个文件可以通过浏览器直接下载
1 | http://localhost:8563/arthas-output/dump.hprof |

可以看到多出来了一个文件,默认是 JProfiler 分析
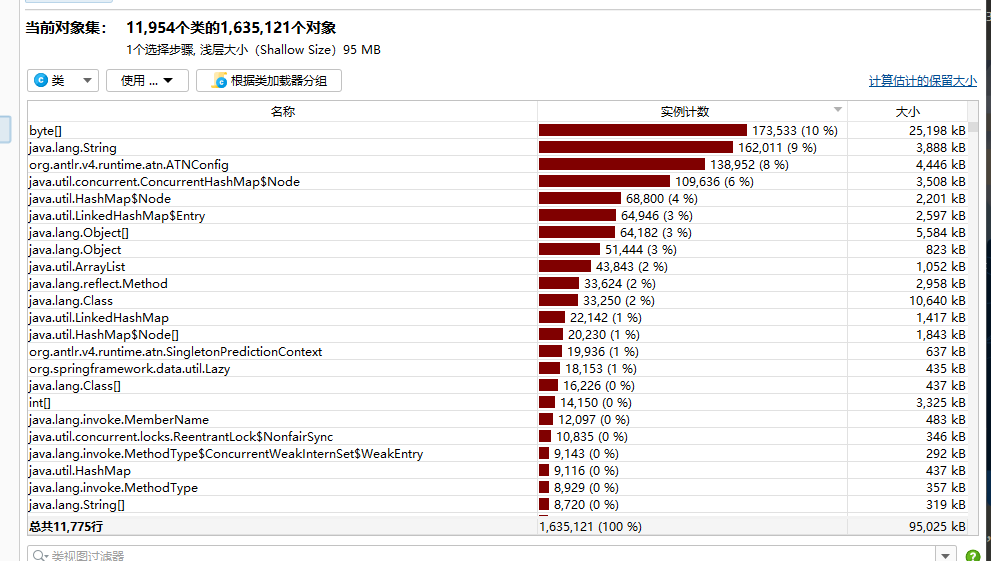
当然,这样看起来太混杂了,一般情况下,我们只导出存活的对象,即从 GC Roots 可达的对象
1 | heapdump --live /tmp/dump.hprof |
如果不加 --live,dump
文件会包含已经被标记为垃圾但尚未回收的对象
jvm
查看当前 JVM 信息,它是相对详细的当前 JVM 情况
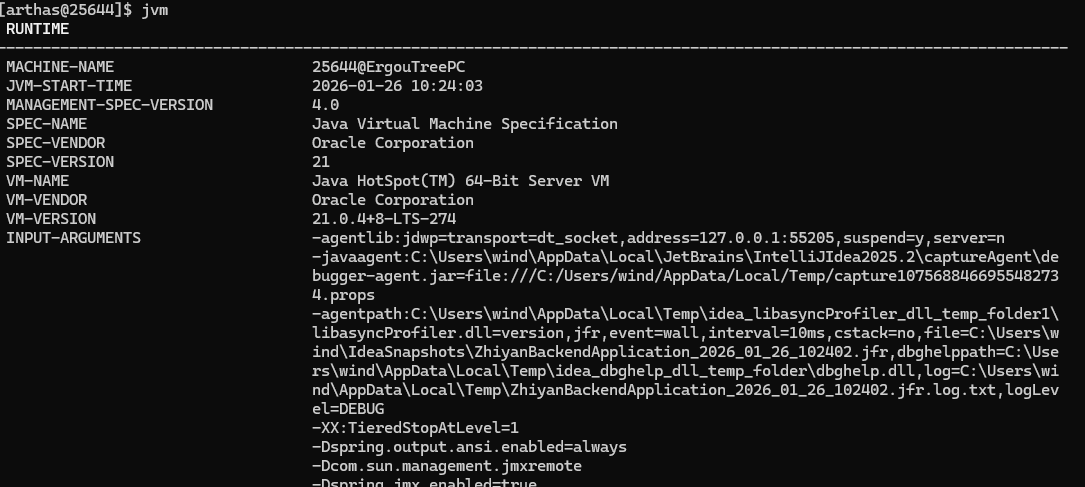
参数太多了,只挑里面最重要的说了
使用的虚拟机
1 | VM-NAME Java HotSpot(TM) 64-Bit Server VM |
内存使用情况
1 | HEAP-MEMORY-USAGE |
垃圾回收器(GC)情况
1 | GARBAGE-COLLECTORS |
线程情况
1 | THREAD |
类加载情况
1 | CLASS-LOADING |
启动参数
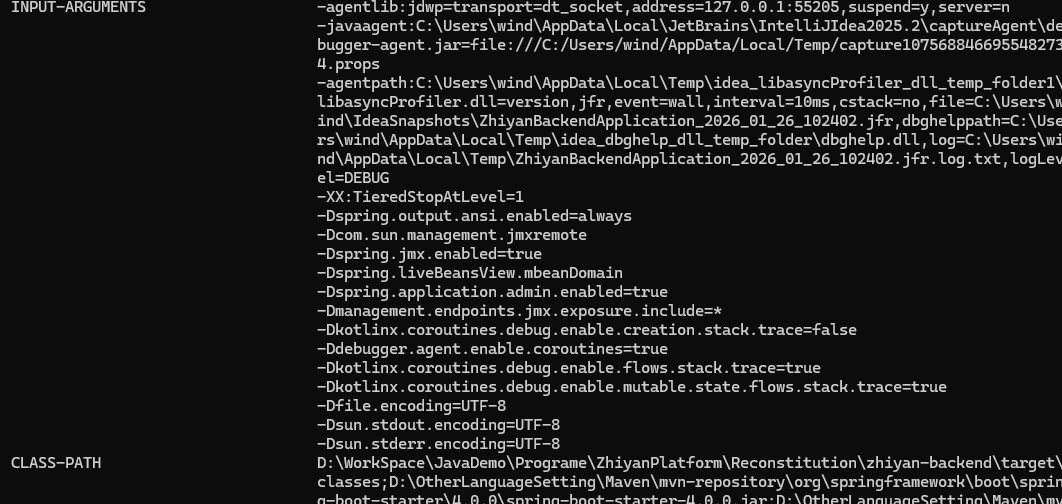
mbean
mbean,全称Managed Bean,意思是可管理的 bean,是 Java
应用实现 可观测性 的重要机制
mbean 命令让你在不离开 Arthas
控制台的情况下,直接查看或监控任意 MBean 的属性值
1 | # 列出所有 MBean 名称 |
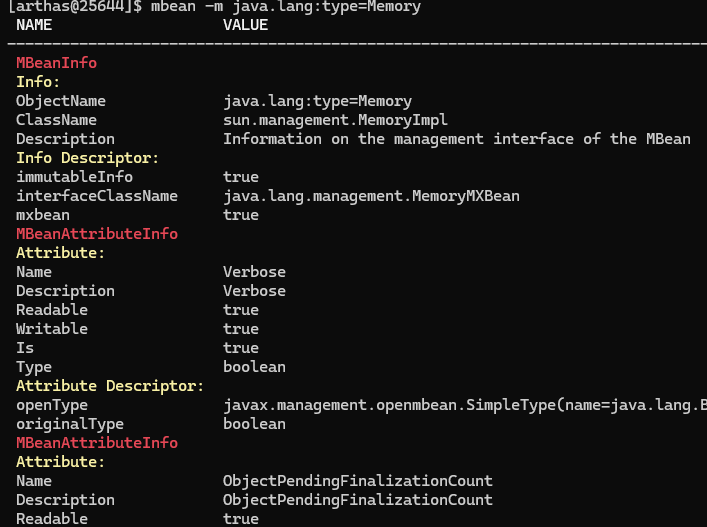
1 | # 实时监控 |
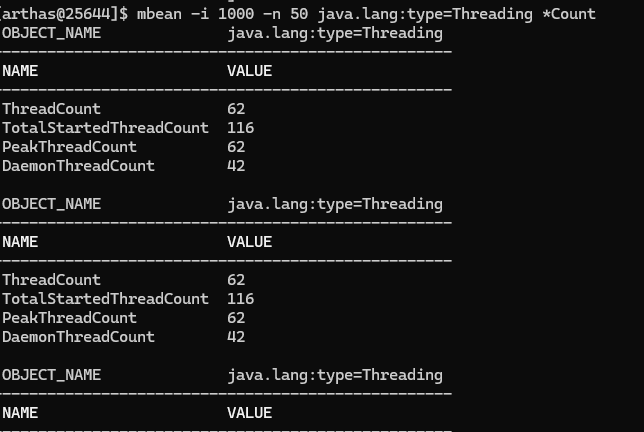
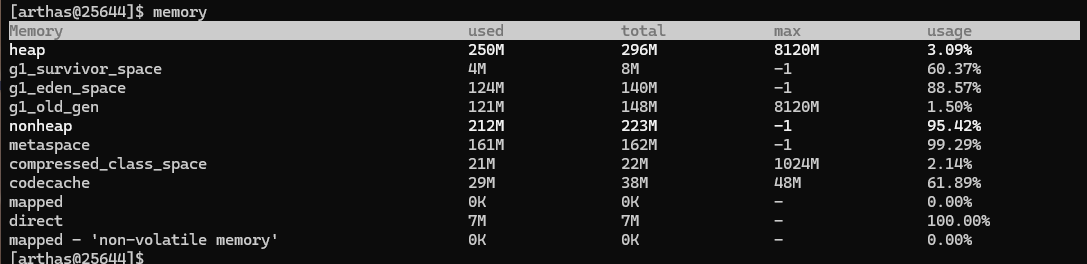
memory
相当于是把命令 jvm 中的内存部分给单独拿出来了,字段的解释是一样的
sysenv
查看当前 JVM 的环境属性
1 | # 查看所有环境变量 |
1 | # 查看单个环境变量 |

sysprop
查看当前 JVM 的系统属性
1 | # 查看所有属性 |
1 | # 查看单个属性 |
thread
查看当前 JVM 的线程堆栈信息
| 命令 | 参数名称 | 参数说明 |
|---|---|---|
| thread 23 | id | 线程 id |
| thread -n 3 | [n:] | 指定最忙的前 N 个线程并打印堆栈 |
| thread -b | [b] | 找出当前阻塞其他线程的线程 |
| thread -n 3 -i 1000 | [i <value>] |
指定 cpu 使用率统计的采样间隔,单位为毫秒,默认值为 200 |
| thread | [–all] | 显示所有匹配的线程 |
这个统计也会产生一定的开销(JDK 这个接口本身开销比较大),因此会看到 as 的线程占用一定的百分比,为了降低统计自身的开销带来的影响,可以把采样间隔拉长一些,比如 5000 毫秒。
就是额外说一下 thread -b,它仅支持
synchronized 关键字造成的阻塞,不支持
ReentrantLock、ReadWriteLock 等
java.util.concurrent 锁,因为 JMX 无法直接获取其持有者
二编:还有一个比较实用的命令thread --state 状态,只显示处于某个状态的线程
可用状态值:
NEWRUNNABLEBLOCKEDWAITINGTIMED_WAITINGTERMINATED
class/classloader 相关
有空再说吧
观测,追踪,分析方法相关命令
请注意,这些命令,都通过字节码增强技术来实现的,会在指定类的方法中插入一些切面来实现数据统计和观测,因此在线上、预发使用时,请尽量明确需要观测的类、方法以及条件,诊断结束要执行
stop或将增强过的类执行reset命令。
monitor
monitor 命令是一个非实时返回命令,需要等待目标 Java
进程返回信息,直到用户输入 Ctrl+C 为止。
monitor
命令用于对指定类和方法的调用进行周期性统计监控,每过一段时间(默认
60
秒)输出一次汇总数据,包括调用次数(total),成功次数(success),失败次数(fail),平均响应时间(avg-rt),失败率(fail-rate)
文档给出的参数是这样
| 参数 | 说明 | 示例 |
|---|---|---|
-c <秒> |
统计周期(必用!),单位秒,默认 60 秒 | -c 5 → 每 5 秒输出一次 |
"condition" |
条件表达式,只统计满足条件的调用(OGNL 语法) | "params[0] > 100" |
-b |
在方法执行前计算条件表达式(默认是在方法返回后) | -b "params[0] <= 2" |
-m <N> 或 --maxMatch <N> |
最大匹配类数量(防止匹配太多类影响性能) | -m 1 |
-E |
使用正则表达式匹配类/方法名(默认是通配符 *) |
-E "com\.service\..*Service" |
那么。监控某个核心接口的健康状况可以这样
1 | # 每 10 秒监控一次全部任务查询服务 |
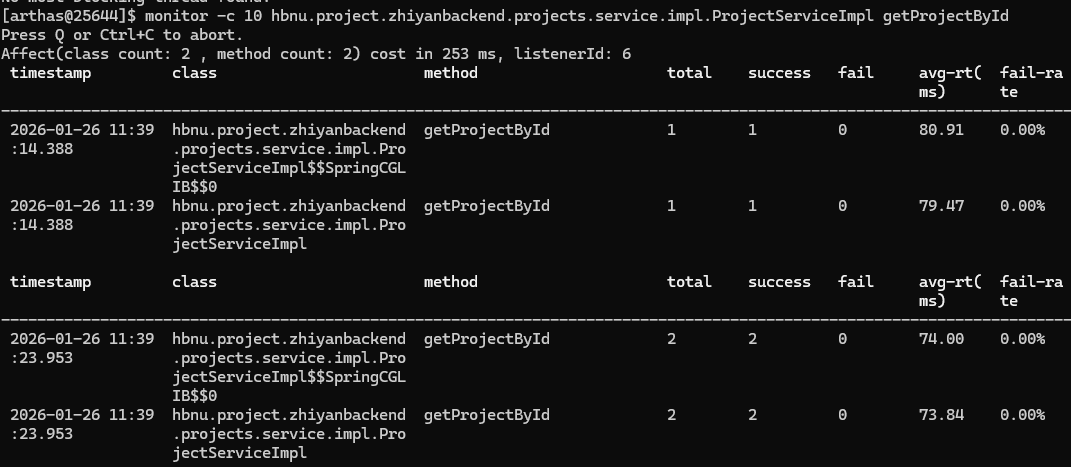
然后,我们也可以只监控特定参数的调用,也就是条件过滤
1 | # 只监控用户 ID = 123873434 的登录请求 |
这个 params 去看上面 Advice 的结构
还可以,在方法执行前就过滤,避免无效计入
1 | # 监控“小数值”输入的情况(在方法执行前判断) |
- 不加
-b:即使方法因参数非法快速抛异常,也会被计入统计。 - 加
-b:只有满足params[0] <= 2的调用才会被监控。
当然也可以用正则和通配符监控多个方法,官方文档给的是不要大于10个
1 | monitor -c 10 hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl get* |
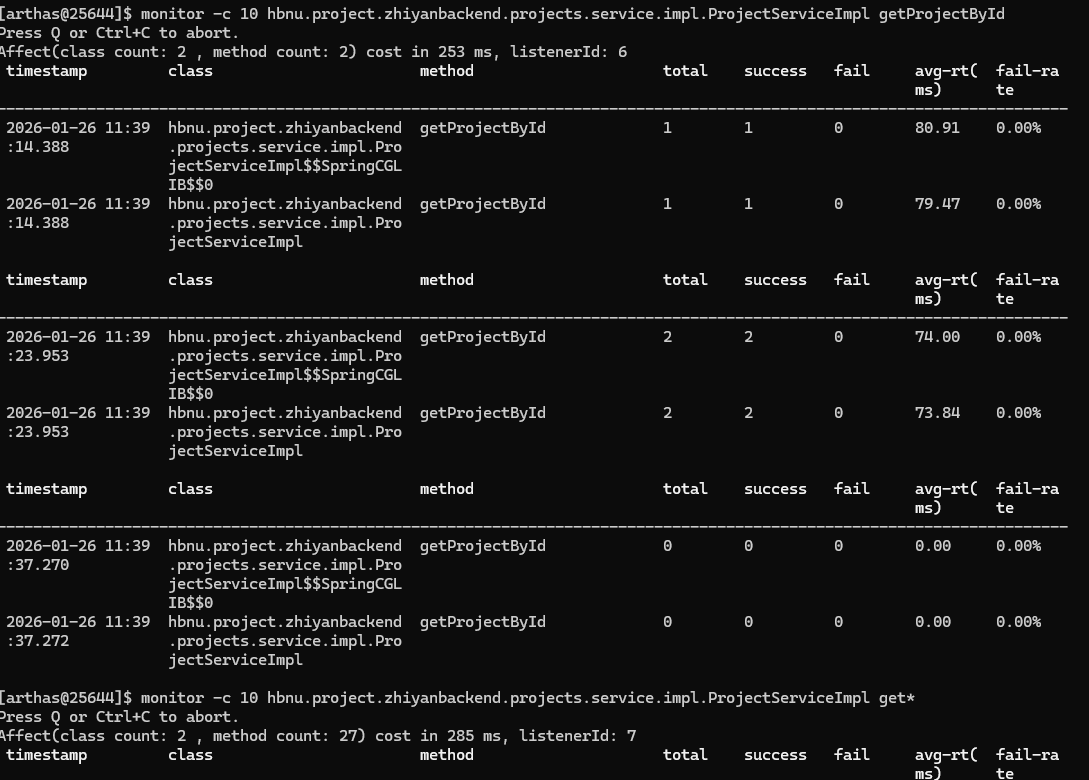
trace
trace
命令用于追踪指定方法内部的调用路径,并输出每一层子方法的执行耗时(RT)。
我说 arthas 就一个这个命令就神了,byd我无数次方法接口慢请求全是这个救下来的
它能回答:
- 这个方法为什么慢?
- 时间到底花在哪个子方法上了?
- 是数据库查询慢?还是 JSON 序列化慢?还是网络调用慢?
文档上关于参数的描述
| 参数 | 说明 | 实战建议 |
|---|---|---|
-n <N> |
最多捕获 N 次调用后自动退出 | 避免无限输出,强烈推荐使用(如 -n 3) |
'#cost > 10' |
只 trace 耗时 >10ms 的调用 | 快速聚焦慢请求,最常用技巧! |
--skipJDKMethod false |
包含 JDK 方法(如 StringBuilder.append) |
当怀疑是 JDK 操作慢时开启 |
-E |
使用正则匹配类/方法名 | 精确匹配多个类:trace -E com.service.A|com.service.B method |
--exclude-class-pattern |
排除某些类(如过滤掉日志) | trace javax.servlet.Filter * --exclude-class-pattern com.demo.TestFilter |
-m <N> |
限制最大匹配类数量 | 防止通配符匹配过多类导致性能问题 |
-v |
打印条件表达式计算详情 | 当 trace
无输出时,用它排查是“没调用”还是“条件不满足” |
例如常用的。找出慢接口的瓶颈。可以使用
1 | # 对于ProjectServiceImpl 中的get方法,只追踪耗时 >100ms 的调用,最多抓 5 次 |
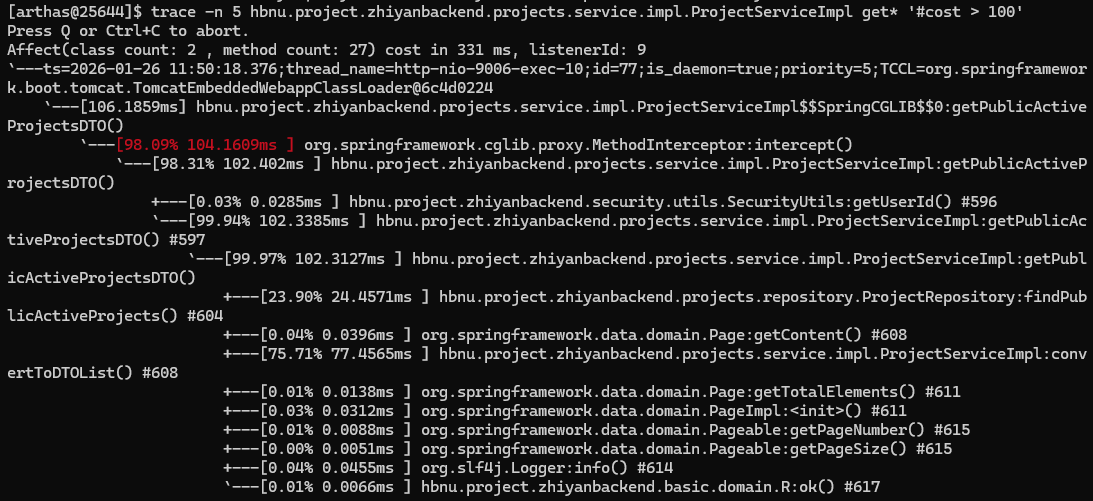
那么我们来分析一下输出,其中ProjectServiceImpl:getPublicActiveProjectsDTO()开始进入业务,业务部分消耗了
99.94%,convertToDTOList()和findPublicActiveProjects()分别占用了75.71%和23.9%,所以我们能知道。整个方法慢,主要因为
convertToDTOList()
太慢,然后就可以针对相关内容进行代码的寻思和我寻思了)),对了井号后面的是行号
别忘了 reset

针对项目的一些底层方法,就可以使用如下命令,带着 JDK 一块分析
1 | trace --skipJDKMethod false hbnu.project.zhiyanbackend.basic.utils.JsonUtils toJsonString |
一般使用 trace 只能追踪一级的调用。但通过
--listenerId,你可以动态深入其中的子方法
一般在输入完命令后,在 Arthas 自己的 cost
的后面,会有一个listenerId
看到上面我 trace 的 get 方法中 listenerId 是 9,所以,我们可以再开启一个终端,连接同一 Arthas 会话,针对上面感觉慢的请求,深入子方法
1 | trace -n 5 hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl convertToDTOList save --listenerId 9 |
回到原来的终端,现在输出会包含 convertToDTOList()
内部的调用链!
这样就能按需深入,避免一次性 trace 太多方法导致性能瞬间爆炸。
stack
输出当前方法被调用的调用路径
也就是说,看这个方法到底是谁调的?用于在目标方法被调用时,打印出完整的调用栈**
如下是我对文档中的该命令提供的参数的整理
| 参数 | 作用 | 示例 | 为什么重要? |
|---|---|---|---|
-n N |
最多捕获 N 次后自动退出 | stack -n 3 Service method |
避免无限输出,强烈推荐必加! |
'条件表达式' |
只在满足条件时打印栈 | stack Service delete "params[0] == 'admin'" |
精准定位特定场景 |
'#cost > X' |
只在方法耗时 >X ms 时打印 | stack Service query '#cost > 100' |
结合性能问题溯源 |
-E |
使用正则匹配类/方法 | stack -E com.service.* delete|remove |
一次性监控多个方法 |
-m N |
限制最大匹配类数量 | stack -m 1 Service * |
防止通配符匹配过多类 |
-v |
打印条件表达式计算详情 | stack -v Service method 'params[0]>10' |
当无输出时排查原因 |
那么,就可以使用下述命令,找出谁调用了上述convertToDTOList()的操作
1 | stack -n 3 hbnu.project.zhiyanbackend.projects.service.impl.ProjectServiceImpl convertToDTOList |
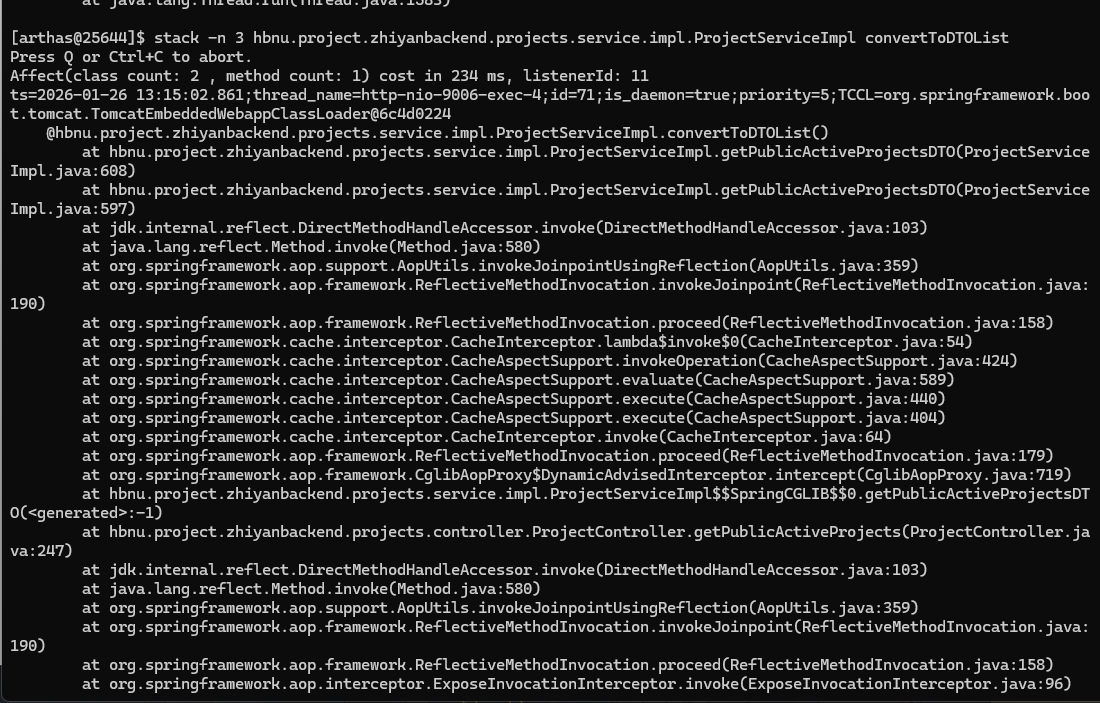
- 调用顺序是从上到下的类依次的一个调用链,顺序是
类.方法:行号
这个通常和上面的 trace 命令结合使用,例如在这里就可以结合耗时分析慢调用的来源,限制时间和匹配的数量
1 | # 只打印耗时 >100ms 的 findUserProjects 方法的调用栈 |
当然你可与监控多个相关方法
这个也可以追踪第三方库的内部调用
1 | # 查看谁调用了 Redis 的 set 方法 |
watch
watch
命令用于在指定方法的特定执行阶段(调用前/返回后/异常时),观测你关心的变量值(如参数、返回值、当前对象属性等)
最多的使用常见就是
- 方法返回了错误结果,但不知道输入参数是什么
- 想确认某个服务是否被传入了空值
- 怀疑对象状态被意外修改,想对比调用前后的字段值,=
- 验证缓存是否生效,观察返回值是否来自 DB
四个观察时机
| 参数 | 时机 | 能观测的内容 | 典型用途 |
|---|---|---|---|
-b |
Before(方法调用前) | params, target |
查看原始入参、对象初始状态 |
-s |
Success(正常返回后) | params, target,
returnObj |
查看返回值、最终对象状态 |
-e |
Exception(抛出异常后) | params, target, throwExp |
捕获异常 + 上下文 |
-f |
Finally(无论成功/异常) | 同上 | 默认开启,通用监控 |
如下是watch命令的参数
| 参数 | 作用 | 示例 | 为什么重要? |
|---|---|---|---|
express |
要观测的表达式(OGNL) | '{params, returnObj}' |
决定输出什么内容 |
condition-express |
过滤条件(OGNL) | 'params[0] == null' |
只关注特定场景 |
-x N |
对象展开深度(1~4) | -x 3 |
查看嵌套对象内部字段 |
-n N |
最多捕获 N 次 | -n 3 |
避免无限输出,强烈推荐! |
-v |
打印条件表达式计算详情 | -v 'params[0]>10' |
当无输出时排查原因 |
-E |
使用正则匹配类/方法 | -E com.service.* save|update |
精准匹配多个目标 |
那么,在我们调试空指针的时候,就会经常使用这样的命令
1 | # 当第一个参数为 null 时打印 |
那么,抛出异常的时候,就可以这样编写命令捕获异常上下文,但是通常情况下,这个可以看日志,不用这样,这里只是演示
1 | watch com.example.PaymentService charge '{params, throwExp}' -e -x 3 |
验证缓存是否命中也十分常用
1 | # 对比调用前后的返回值(如果是 DB 查询,第二次应更快且相同) |
也可以结合 trace 耗时分析慢请求,看看它返回了什么导致了这种问题
1 | # 只观察耗时 >200ms 的调用 |
注意,watch
会植入字节码,避免长期监控高频方法,watch是影响很大的命令
tt
watch
虽然很方便和灵活,但需要提前想清楚观察表达式的拼写,这对排查问题而言要求太高,因为很多时候我们并不清楚问题出自于何方,只能靠蛛丝马迹进行猜测。
这个时候如果能记录下当时方法调用的所有入参和返回值、抛出的异常会对整个问题的思考与判断非常有帮助。
于是乎,TimeTunnel 命令就诞生了
tt(Time
Tunnel)命令会自动记录指定方法每次调用的完整上下文(入参、返回值、异常、对象、耗时等),并支持后续按条件检索、查看细节,甚至“重放”该次调用!
tt 相关功能在使用完之后,需要手动释放内存,否则长时间可能导致OOM。退出 arthas 不会自动清除 tt 的缓存 map。
命令基本按照如下情况使用
1 | # 记录 demo.MathGame.primeFactors 的所有调用 |
列出所有记录
1 | # 查看已记录的调用列表 |
重放调用
1 | # 重放 INDEX=1004 的调用(用相同参数重新执行) |
别忘了清理记录,因为退出 arthas 不会自动清除 tt 的缓存 map
1 | # 删除单条记录 |
输出字段大约如下
| 字段 | 说明 |
|---|---|
INDEX |
唯一编号,后续操作都靠它(如 -i 1003) |
TIMESTAMP |
调用发生的时间 |
COST(ms) |
方法耗时(毫秒) |
IS-RET |
是否正常返回(true/false) |
IS-EXP |
是否抛出异常(true/false) |
OBJECT |
执行对象的 hashCode()(非内存地址!) |
CLASS/METHOD |
类名和方法名 |
我貌似就用过几次 tt,最近一次是这样的
1 | # 记录所有调用,等出错后查 |
profiler
profiler
命令支持生成应用热点的火焰图。本质上是通过不断的采样,然后把收集到的采样结果生成火焰图。
profiler 命令基本运行结构是
profiler action [actionArg]
这东西很有用了,对于如下情况
- 应用 CPU 使用率突然飙升到 100%,但不知道哪个方法在疯狂执行?
- 想知道哪些代码路径最耗时
- 接口响应慢,但
trace太细,需要全局视角? - 怀疑有内存泄漏,想看对象在哪里被大量创建?
它相当于 线上版的 JProfiler / YourKit
一般情况下这样使用
1 | # 1. 启动采样(默认 CPU) |
对于官方文档的参数整理如下
| 参数 | 作用 | 示例 | 为什么重要? |
|---|---|---|---|
-e EVENT |
采样事件类型 | -e cpu, -e alloc,
-e lock |
决定分析方向(CPU/内存/锁) |
-d SECONDS |
自动运行指定秒数 | -d 60 |
避免手动 Ctrl+C,适合自动化 |
-f FILE |
指定输出文件 | -f /tmp/cpu.html |
方便下载和查找 |
-o FORMAT |
输出格式 | -o flamegraph, -o jfr |
火焰图 or JFR(用于高级分析) |
-t |
按线程分别分析 | profiler start -t |
查看哪个线程最忙 |
-j DEPTH |
限制 Java 栈深度 | -j 256 |
避免过深栈干扰分析 |
--include/--exclude |
过滤栈帧 | --include 'com.myapp.*' |
聚焦业务代码,忽略框架 |
常见使用的场景如下
1 | # 采样 60 秒,生成火焰图 |
优先使用 -d:避免忘记停止采样

差不多火焰图就这样
宽度表示该函数占用 CPU 的比例,越宽越热点;高度表示栈的调用深度
jfr
Java Flight Recorder (JFR) 是一种用于收集有关正在运行的 Java 应用程序的诊断和分析数据的工具。它集成到 Java 虚拟机 (JVM) 中,几乎不会造成性能开销,因此即使在负载较重的生产环境中也可以使用。
jfr 命令支持在程序动态运行过程中开启和关闭 JFR 记录。
记录收集有关 event 的数据。事件在特定时间点发生在 JVM 或 Java
应用程序中。每个事件都有一个名称、一个时间戳和一个可选的有效负载。负载是与事件相关的数据,例如
CPU 使用率、事件前后的 Java 堆大小、锁持有者的线程 ID 等。
1 | # jfr 命令基本运行结构是 |
整理一下官网上的常用参数如下
| 参数 | 说明 | 示例 | 为什么重要? |
|---|---|---|---|
-n NAME |
指定记录名称 | -n cpu_analysis |
方便识别多个记录 |
--duration TIME |
自动停止时间 | --duration 60s |
避免无限记录 |
-f FILE |
指定输出文件 | -f /tmp/app.jfr |
控制文件位置 |
-s CONFIG |
指定配置文件 | -s profile.jfc |
控制采集粒度 |
--maxsize SIZE |
缓冲区最大大小 | --maxsize 500M |
防止磁盘爆满 |
--maxage TIME |
数据最长保留时间 | --maxage 1h |
自动滚动清理 |
--dumponexit true |
退出时自动 dump | --dumponexit true |
确保不丢数据 |
最多的情况下就是快速抓取 60 秒生产数据
1 | # 启动记录,60秒后自动停止,保存到 /tmp |
偶尔用到定期快照
1 | # 启动长期记录(不限时) |
生成的 .jfr 文件需要用专业工具打开,使用 JProfiler
是很好的
默认情况下,arthas 使用 8563 端口,则可以打开:
http://localhost:8563/arthas-output/
查看到arthas-output目录下面的 JFR 记录结果:







![[Arthas]](使用Arthas来监控线上服务并定位问题/arthas-packaging.svg+xml){kind=link}