
结构化输出
何为结构化输出,为什么结构化输出是必要的
在最初接触大模型时,人们通常会把 LLM 当成一个“会说话的程序”。例如:
1 | 用户:帮我总结这篇文章 |
这种模式本质上是“自然语言交互”。自然语言对人类极其友好,但对程序并不友好。因为程序友好的内容通常有如下特征:稳定,可预测,可解析,类型明确,字段固定,而自然语言天生是不稳定的。
例如你要求 AI 返回一个用户信息:
1 | 姓名:张三 |
下一次它可能返回:
1 | 用户叫张三,今年20岁 |
再下一次:
1 | { |
对于人类来说,这三种表达几乎等价。但对于程序来说,它们完全不同。因为程序无法像人类一样理解语义,程序依赖的是严格的数据结构。结构化输出的本质,是让 LLM 不再返回“人类语言”,而是返回“程序数据”。
Agent 的本质不是聊天,而是决策。而决策必须建立在结构化数据上。结构化输出是 AI 工程化的基础设施,因为它解决了 LLM 输出的不确定性问题。在大模型天然具有随机性的情况下,尽量约束成确定性的数据生成器。
结构化输出大致就是
1 | 用户 -> AI -> JSON/POJO/Schema -> Java系统 |
自然语言并不能直接构建可靠系统。你会发现,结构化输出和传统 Java 后端其实非常相似。
因为 Java 后端一直都在做同样的事情:
1 | HTTP请求 -> DTO -> Service -> Entity -> JSON |
而现在:
1 | 用户自然语言 -> LLM -> Structured Object -> Java System |
LLM 系统工程化的基础,一目了然
项目示例
简单类型结构化输出的 AI Service 接口
我们声明这样的一个接口,用于结构化输出 boolean 和 Enum 这两种返回类型。因为这两种类型本质上都属于有限输出空间。例如 boolean 只有 true 和 false 这两种的可能性,而简单类型结构化输出要求是把无限语言空间压缩到有限离散集合。这与其他类型可能不能一概而论。
1 | /** |
例如,对于这个方法
1 | boolean isPositiveSentiment(String text); |
实际上不是返回一句话。而是在二元分类任务中,让 LLM 充当分类器。而从提示词中,也能很明显的看到其目的,这就是一种简单的 Prompt Engineering。
接下来非常关键的一步出现了,模型返回的不是 Java boolean。模型永远只能返回 Token 也就是文本,例如,他可能返回一个 true 字符串,那么这样,解析结构化输出的工作就需要交给 LangChain4j,把 “true” 解析成 Boolean.TRUE
因此,AI Service 的结构化输出,本质上包含两个阶段:
1 | LLM生成文本 |
对枚举更是如此,枚举类型是最适合 LLM 的结构化输出之一,因为 LLM 擅长语义处理,真正让 “POSITIVE” 变成 Sentiment.POSITIVE 的也是 LangChain4j 的输出解析器。
现代 AI 工程会大量使用 enum,因为 enum 可以天然限制模型自由度。
例如 Agent 系统里:
1 | enum Intent { |
这样的一个枚举类,AI 就能变成 Intent Router。而不是聊天机器人。这实际上是 LLM 从文本生成向决策系统的转变。
接下来再看 Prompt 中这一句:只返回该枚举值本身,不要附加任何其他内容
这一句极其重要。因为:LLM
默认倾向于“解释”。例如你不加限制,它可能输出:我认为这段文本属于
POSITIVE。但,LangChain4j 在解析 enum 时,期望的是
POSITIVE,如果模型输出:情绪是 POSITIVE,那么
Enum.valueOf(...) 会可能直接失败。
所以会发现,结构化输出的核心之一,是约束 Prompt。这也是为什么,Structured Output 本质上并不仅仅是“返回 JSON。而是控制 LLM 输出空间。
那么下面对于这种复杂对象的结构化输出,我们又该如何处理,剧透一下,实际上,复杂对象结构化输出,本质上只是简单类型结构化输出的扩展。因为最终 JSON Object 本质上也是 key -> value 的类型,而 value 最终仍然会落到这些基础结构上。
从框架本身的角度出发,为什么要单独拆出来?
LangChain4j 对 boolean / Enum 的解析器(BooleanOutputParser、 EnumOutputParser)期待模型直接返回裸文本(true / POSITIVE)。
但若 ChatModel 开启了 responseFormat(“json_object”),模型会强制将所有输出包裹成 JSON 对象(如 {“answer”: true}),导致解析失败。
因此此接口绑定的是未开启 JSON 模式的普通 ChatModel,让模型可以自由输出裸文本,解析器可以正常工作。
复杂类型结构化输出的 AI Service 接口
1 | /** |
从这里开始,我们发现这些接口中期待 LLM 返回的不再是裸的文本,而是各种对象,LLM 不再只是 String -> String,而是开始真正进入 Java 类型系统,LLM 开始承担对象生成器的角色。
LangChain4j 如何把概率性文本生成,强行约束进 Java 的类型系统。
现在这个接口最重要的一句话,其实是我在上面注释中提到的responseFormat("json_object"),因为LLM
本身不理解 Java,模型只知道 Token Sequence,所以说上面实际上的流程是
1 | LLM输出JSON文本 |
但是我们看这个方法,实际上,类型会涉及到很多问题
1 |
|
这里 List<String>不是普通 Java 泛型那么简单。因为
List<String>运行时实际上只有 List,如果
LangChain4j 只是拿到了一个普通的 List,它在把 LLM 返回的
JSON 字符串反序列化时,就会不知道里面装的到底是
String、Integer 还是某个自定义的
POJO 对象,它意味着,LangChain4j
在运行时必须解决泛型类型擦除的问题。
Java 泛型在运行时被擦除这句话,其实只针对对象的实例(Instances)和局部变量。Java 编译器在编译时,并没有把所有的泛型信息都抹掉。对于类结构(Class Structure)级别的泛型信息,编译器将其保留在了字节码(Class 文件)的
Signature属性中。因为你的是一个接口(Interface)的方法声明,所以List<String>作为方法的返回值类型,完好无损地保存在了字节码中。当 LangChain4j 通过
AiServices为你生成这个接口的动态代理对象时,它在底层执行了主要通过Method.getGenericReturnType(),精确地知道了你需要的是一个装满String的List。
你会发现,AI Service 到这里已经越来越不像聊天框架,而越来越像那种 RPC Framework,现在看起来已经几乎很像那种声明式调用了,本质上,LLM 开始成为一个概率型远程服务。
对于这种普通的 POJO 复杂对象的提取,框架能根据 POJO 的字段 和
@Description 注解构建 JSON Schema,引导 LLM 生成符合结构的
JSON,然后自动反序列化为 POJO 实例。
1 |
|
那么,这个是什么意思呢,我们来看TextAnalysisResult这个实体类长什么样
1 |
|
什么意思,为什么@Description是像那种描述信息那样,而不是像那种
MyBatis 的 @TableField
注解这种严谨的对应形式,实际上,很多人认为结构化输出只是让 AI 返回
JSON,实际上远远不是。真正关键的是,LangChain4j 会先分析 Java
类型结构,然后生成一份约束模型输出的 Schema。Description 本质上是在教
LLM 理解字段语义。例如:
1 | record Person( |
LangChain4j 框架实际上会构建类似的 JSON Schema
1 | { |
然后,这份 Schema 会被加入 Prompt 或 API Request 中。于是模型会被强约束。你必须返回符合这个结构的JSON,所以,Structured Output 的本质,其实是 Schema-Constrained Generation。
那么同样,处理嵌套 POJO 和 POJO
集合也是类似,我们来看生成ArticleOutline这个嵌套结构递归
Schema 的方法
1 |
|
它是一个嵌套结构,那么框架也能按照正常的形式去处理,这里实际上已经涉及Object Graph Mapping了,你会发现这和 Hibernate 这种对象映射框架的思维是有些像的,因为,AI 工程最终一定会回到对象系统中。
1 | /** |
接下来,这个接口方法体现了生成型结构化输出,什么意思呢
1 |
|
结构化输出是必要的,但是内容生成同样需要结构化
1 |
|
我们发现,这个翻译接口实际上不止是提示词加原文打包过去,返回一个译文,而是返回的是译文 + 元信息 + 状态,因为,工程系统不止关心结果,关系各种各样过程中的信息,而结构化输出和信息提取完全是两回事,这里是AI生成新内容,而不是从已有内容里提取数据。
二遍进一步解释一下,对于程序来说翻译后的句子和用户年龄本质上没有区别。它们都只是系统中的字段,而不是给人看的内容。这是 AI 工程和普通聊天最大的区别。
例如传统聊天:
2
AI:Hello, nice to meet you.这已经结束了。因为,聊天系统的终点就是“显示给人”。但真实 AI 系统不是这样。真实系统里翻译结果这种内容通常只是整个系统中的一步,也就是说 LLM 生成的内容,如果必须进入系统的数据流。它必须结构化,把生成的内容也视为一个业务对象。让 AI 生成的内容,能够稳定进入后续系统。
最后,LangChain4j 的 Structured Output 本质上依赖三层协作:
第一层是:
1 | Prompt约束 |
第二层是:
1 | 模型JSON模式 |
第三层是:
1 | Java类型反序列化 |
上述的示例项目中的关键内容
LangChain4j 是如何让 LLM 输出结构化信息的
包括 LangChain4j 官方文档也在说,许多大型语言模型(LLMs)和 LLM 提供商都支持生成结构化格式的输出,通常是 JSON。这些输出可以轻松地映射到 Java 对象,并在应用程序的其他部分中使用。前面提到的 LLM 自动输出到 POJO 这部分,本质上还是框架帮你自动完成。
所谓 LLM 看上去返回了 Java对象,本质上只是 LLM 输出了一段符合结构的文本,然后,LangChain4j 再把它反序列化成 Java 对象。
目前,根据 LLM 和 LLM 提供商的不同,有三种方法可以实现这一目标(从最可靠到最不可靠):
- JSON Schema
- 提示 + JSON 模式:在这里不提及
- 提示:这是默认选择,除非启用了对 JSON Schema 的支持,不可靠,在这里不提及
所以说,什么是 JSON Schema,JSON Schema 是一套 JSON 数据的描述语言
JSON Schema——ChatModel API
一些 LLM 提供商允许为所需的输出指定 JSON schema。可以在这里的JSON Schema列中查看所有支持的 LLM 提供商。
当请求中指定了 JSON Schema 时,LLM 应该生成一个符合该 Schema 的输出。JSON Schema 它本质上是JSON 的类型系统。JSON Schema 在 LLM 那一层属于是解码层的约束了,固然等级比 Prompt 高,其中 Provider 会做 Grammar Constrained Decoding,不合法直接裁剪。
比如你有:
1 | class Person { |
它对应的 JSON:
1 | { |
而 JSON Schema 是:
1 | { |
那么,JSON Schema 是在向 LLM 提供商 API
发送的请求中的一个专用属性中指定的,不需要在提示中(例如在系统或用户消息中)包含任何自由形式的指令。LangChain4j
在低级 ChatModel API 和高级 AI Service API 中都支持 JSON
Schema 功能。
在低级 ChatModel API 中,可以在创建
ChatRequest 时使用与 LLM 提供商无关的
ResponseFormat 和 JsonSchema 来指定 JSON
Schema,就假如我们用低级 API 手动构建 ArticleOutline 的
JSON Schema,代码如下
1 | // 定义嵌套的 Section 结构 |
然后,绑定 JSON Schema 到
ResponseFormat,ResponseFormat 是 LangChain4j
抽象的响应格式配置,用于告诉 LLM 输出 JSON,且必须符合我定义的
Schema。
1 | ResponseFormat responseFormat = ResponseFormat.builder() |
这个
type(ResponseFormat.Type.JSON)对应下面会提到的responseFormat("json_object"),本质是向 LLM 提供商 API 传递 强制 JSON 输出 的指令;所以说,高级 API 中你无需手动写这些内容,框架会根据返回类型自动生成
ResponseFormat。
然后构造 ChatRequest 组装请求和调用 ChatModel 并解析响应了就是,这些步骤就不写了
JSON Schema 的结构是使用 JsonSchemaElement
接口定义的,是所有 JSON Schema 类型的父接口,它代表JSON Schema
里的任意一种节点,其中这个description()就是帮助 LLM
理解字段含义的一个描述节点的信息
所有
JsonSchemaElement子类型,除了JsonReferenceSchema,都有一个description属性。description是写给 LLM 看的自然语言指令,例如
2
3
.description("你需要填写一个人的名字的字符串, 例如: John Doe")
.build();
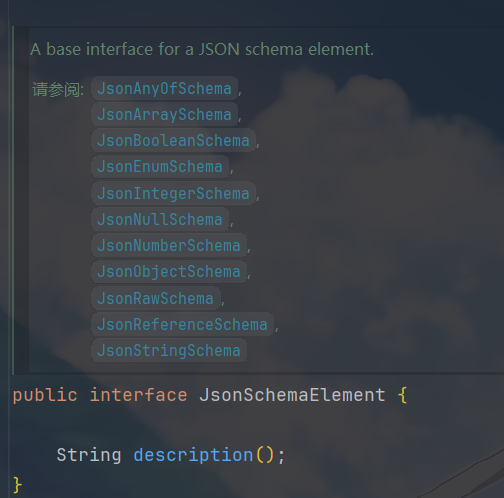
他有很多子类型,我们挑一些经常使用的简单说说,最经常使用的就是JsonBooleanSchema和JsonEnumSchema了
JsonObjectSchemaJsonObjectSchema表示一个带有嵌套属性的对象。它通常是JsonSchema的根元素。对应 JSON 类型:
"type": "object",它定义一个可嵌套的 JSON 对象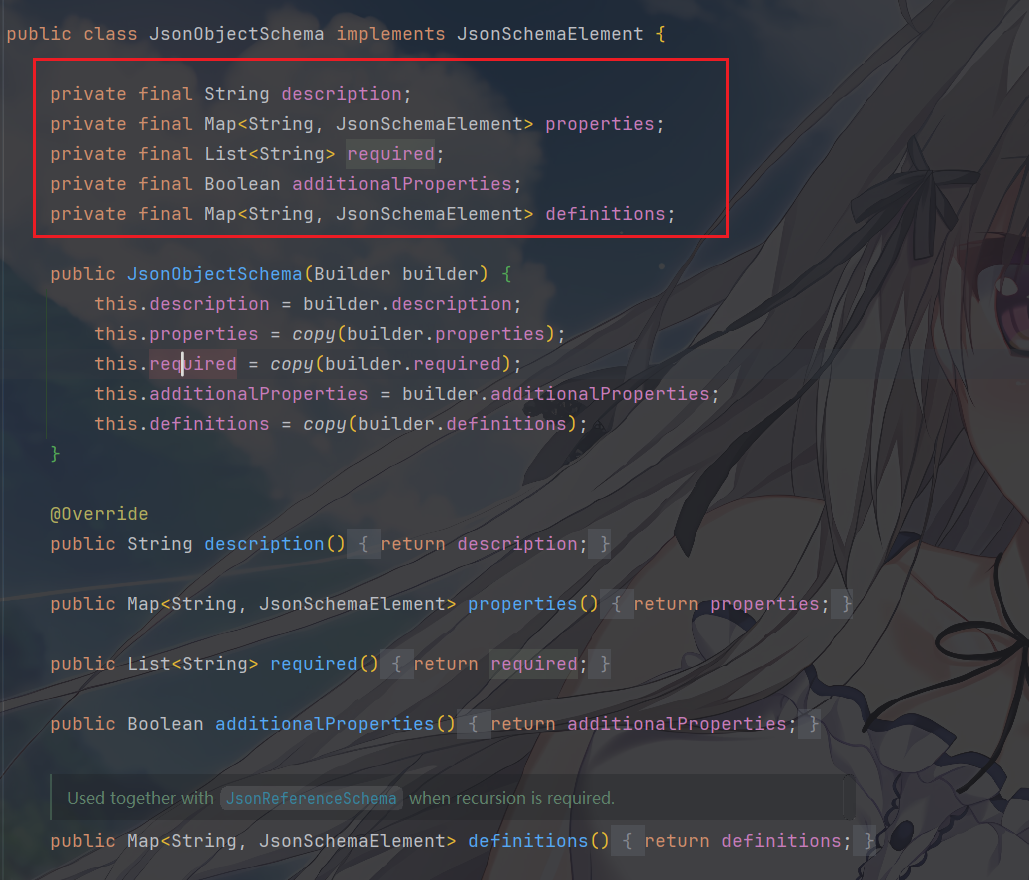
字段 作用 实际开发用途 description 对象说明 告诉 LLM 这个对象是什么 properties 对象的所有属性 例如 name、age、married required 必填属性 不填 LLM 可能漏返回字段 additionalProperties 是否允许额外字段 设为 false → LLM 不能乱加字段 definitions 递归定义 处理对象嵌套自己(如树结构) 这个如何添加属性,一般就是用
properties(Map<String, JsonSchemaElement> properties)方法一次性添加所有属性,也可以使用addProperty(String name, JsonSchemaElement jsonSchemaElement)方法单独添加属性,源码比较清楚,这里就不提了JsonBooleanSchema对应 JSON 类型:
"type": "boolean",期待 LLM 返回的是文本,它是一个叶子节点,不能嵌套任何子节点,只能表示true/false。
创建一个
JsonBooleanSchema的示例:1
2
3JsonBooleanSchema.builder()
.description("是否已婚:只能是 true 或 false")
.build();JsonStringSchema创建一个
JsonStringSchema的示例:1
2
3JsonSchemaElement stringSchema = JsonStringSchema.builder()
.description("The name of the person")
.build();JsonIntegerSchema/JsonNumberSchema创建一个
JsonNumberSchema的示例:1
2
3JsonSchemaElement numberSchema = JsonNumberSchema.builder()
.description("The height of the person")
.build();创建一个
JsonIntegerSchema的示例:1
2
3JsonSchemaElement integerSchema = JsonIntegerSchema.builder()
.description("The age of the person")
.build();JsonEnumSchema创建一个
JsonEnumSchema的示例:1
2
3
4JsonSchemaElement enumSchema = JsonEnumSchema.builder()
.description("Marital status of the person")
.enumValues(List.of("SINGLE", "MARRIED", "DIVORCED"))
.build();
JSON Schema——Al Service API
然后是在 AI Services 中使用 JSON Schema,可以更轻松地以更少的代码实现相同的目标,也是我们项目中大量使用的
在使用 Spring Boot 这种框架的时候,当满足所有以下条件时:
- AI Service 方法返回一个 POJO
- 所使用的
ChatModel支持 JSON Schema 功能 - 在所使用的
ChatModel上启用了 JSON Schema 功能
ResponseFormat 和 JsonSchema
将根据指定的返回类型自动生成。
请确保在配置 ChatModel 时显式启用 JSON Schema
功能,因为它默认是禁用的。通过responseFormat("json_object"),强制模型输出合法
JSON 字符串, AI Services 框架会在底层自动将其反序列化为目标 Java
类型(POJO、Enum、List 等)。
1 | // JSON 模式 ChatModel 需要强制 LLM 输出合法 JSON 对象 |
我们会发现,项目中我们没有在代码中没有直接写去构造 JSON Schema,因为在框架加持下 LangChain4j 根据 POJO 的字段 / 注解自动生成了 JSON Schema
我们有这样的一个接口
1 |
|
对应ArticleOutline这样的一个POJO,LangChain4j 会为
ArticleOutline 自动生成如下 JSON Schema
1 |
|
1 | { |
ArticleOutline类中即使包含了含嵌套Section,LangChain4j 生也能成嵌套结构的 JSON Schema@Description注解映射为 JSON Schema 的description字段,帮助 LLM 理解字段含义;请注意,放置在
enum值上的@Description没有效果 且不会包含在生成的 JSON Schema 中:1
2
3
4
5
6
7
8
9
10
11enum Priority {
// 这将被忽略
CRITICAL,
// 这将被忽略
HIGH,
// 这将被忽略
LOW
}
然后,框架自动反序列化,将 JSON 转换为 ArticleOutline
实例,返回给业务代码
默认情况下,生成的 JsonSchema
中的所有字段和子字段都被视为可选的,除非你手动声明必需,可选的含义就是
LLM 可以不返回这个字段,如果你不告诉 LLM
这个字段必须返回,LLM
就会认为“我不知道就可以不填”。这是因为当 LLM
缺乏足够的信息时,它倾向于虚构并用合成数据填充字段,我们需要避免这种事情发生
如果 LLM 未为可选的原始类型字段提供值,它们将被初始化为默认值,这样在序列化的时候不会出问题,但是可能会对其他的内容造成一些比较奇怪的影响,所以说,尽量使用包装类型,不要用原始类型
官方文档提到一个内容,就是当严格模式开启时 (strictJsonSchema (true)),可选的 enum 字段仍可能被虚构的值填充。大意就是,枚举如果重要,一定要设为必需!
那么,如何让字段变成必需,这个项目里没有演示,使用
@JsonProperty (required = true)
1 | record Person( |
提前提一下,当与工具一起使用时,所有字段默认都被视为必需!因为工具调用需要精确参数,少一个都无法调用方法。
LangChain4j 是如何获取对象信息并自动构建 JSON Schema 的
大致内容
当你使用 @AiService
注解一个接口(或者将一个服务的接口注册为容器中的bean),并声明返回类型为你的
POJO 时,LangChain4j
会在运行期通过动态代理拦截方法调用,并执行以下步骤:
- 分析返回类型 — 先通过动态代理拦截,获取你的 POJO 的
Class 对象,包括泛型信息(如
List<Person>)。 - 提取结构信息 —
反射分析字段、方法,读取注解(
@Description、@JsonProperty等),构建一个内部的结构化描述。 - 生成目标格式 Schema — 将提取的结构信息转换成 LLM 能理解的 JSON Schema 字符串。
- 将 JSON Schema 注入后(放入 ChatRequest.responseFormat),发送请求并获取 LLM 原始文本输出。
- 输出解析 — 使用解析器(OutputParser)将 LLM 返回的文本解析成目标 Java 对象。然后返回给你
首先,AI Service 本质是动态代理,只不过注入的 bean 通过 Spring Boot 自动管理了,所以只需要声明接口方法就可以,LangChain4j 会在运行时动态生成实现类
这和 Spring/OpenFeign/MyBatis 完全一样
Spring AOP 中你写:
2
public void save() {}Spring 动态创建代理:
2
3
4
5
6
7
↓
事务开启
↓
目标方法
↓
事务提交
然后就是来到了对对象结构信息的提取这一步,只有通过这一步才能知道你的对象长什么样,我该怎么反序列化
ServiceOutputParser如何工作的
对对象结构信息的提取,入口在ServiceOutputParser 和
OutputParserFactory中,但是他们两个离不DefaultOutputParserFactory
首先,ServiceOutputParser
是一个门面类,它不直接解析
JSON,而是负责根据返回类型(Type)决定
是否需要结构化输出
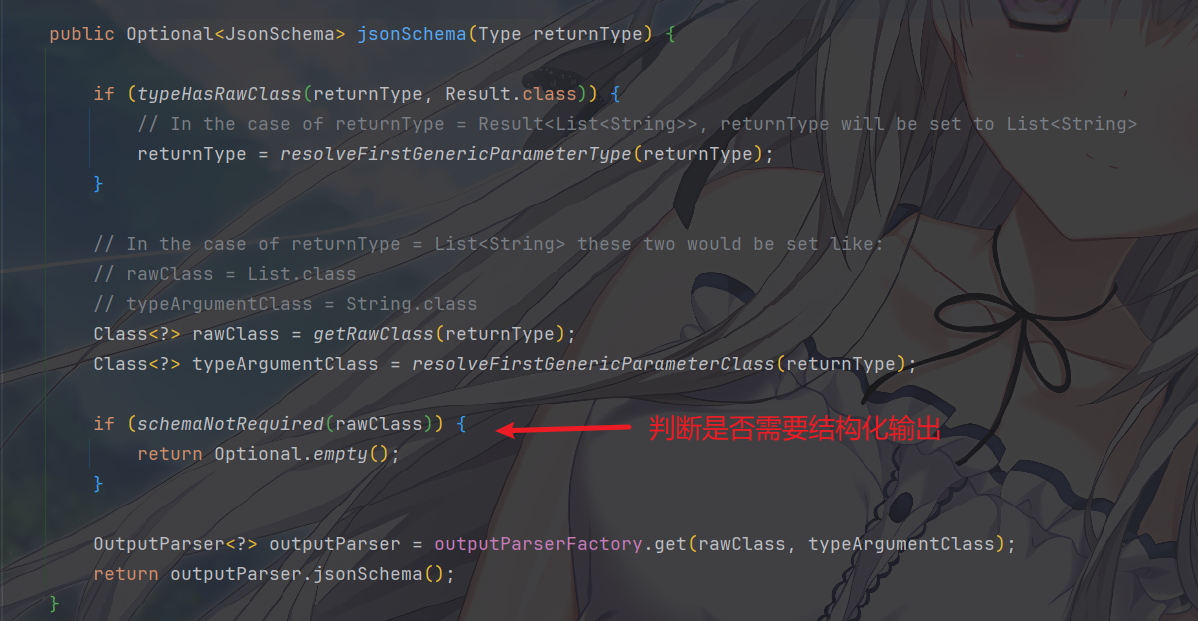
如果需要,从
OutputParserFactory获取对应的OutputParser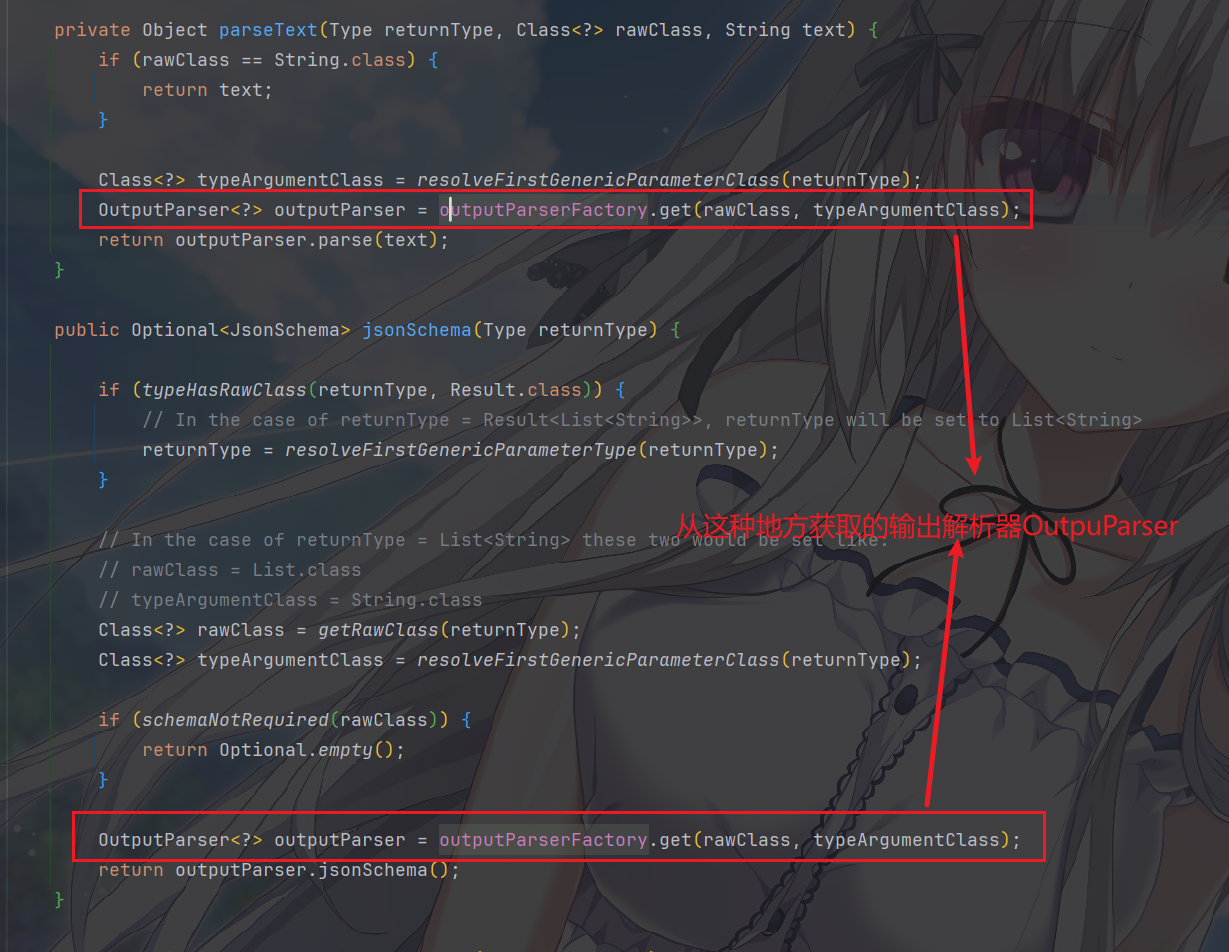
委托该
OutputParser完成最终的文本 → 对象转换,以及格式指令的生成。
然后,他会对类型解包,处理 Result<T>
和泛型提取,很明显,所有方法的入口第一步都是:

Result<T>是 LangChain4j 的一个包装类型,允许你在方法返回值外额外获得TokenUsage等信息。解析时它会脱去外包装,提取内层的实际类型T。这意味着后续整个流程看到的都是你想要的业务 POJO 或集合类型。接着,获取两个关键 Class
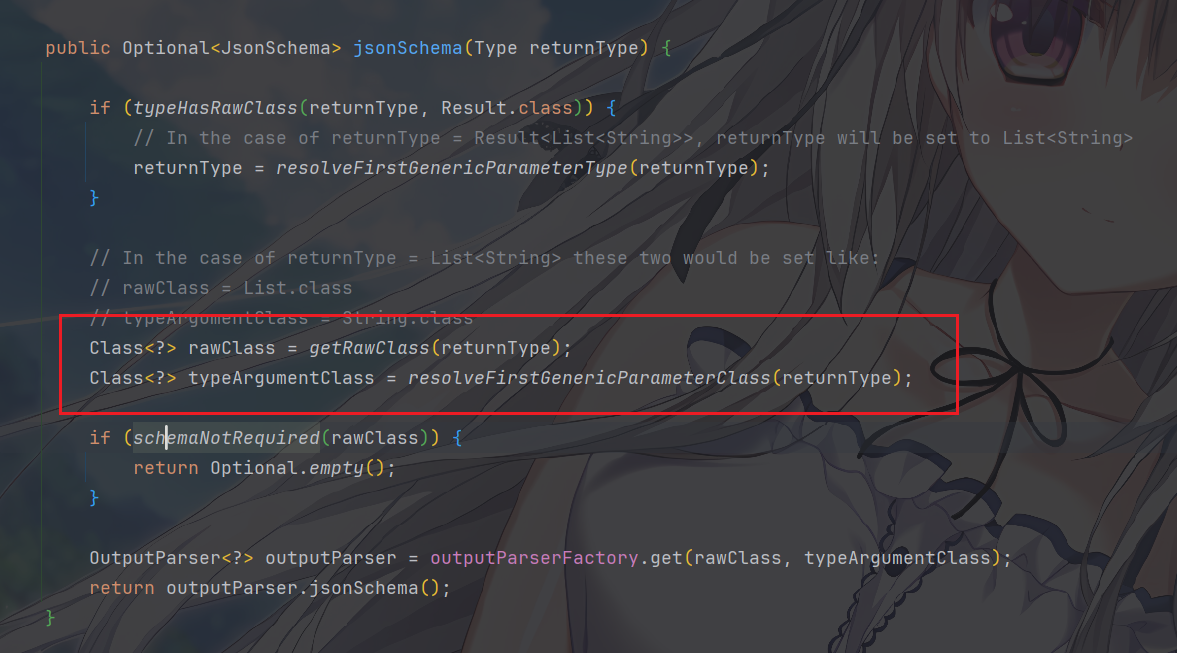
rawClass:擦除后的原始类,例如List<Person>→List.class;Person→Person.class。typeArgumentClass:第一个泛型参数,用于解决之前提到的泛型类型擦除的问题,例如List<Person>→Person.class;Set<String>→String.class;无泛型则为null。
这两个信息会传给
OutputParserFactory来选择具体的OutputParser。对于解析,以
parseText为例: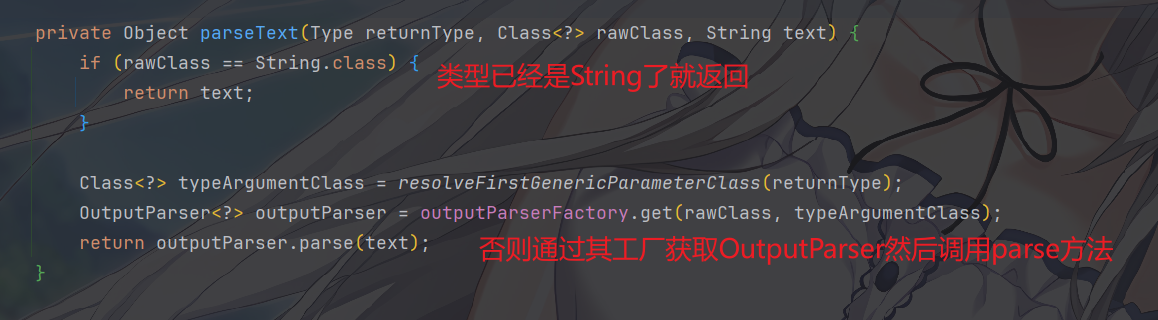
jsonSchema()和outputFormatInstructions()也是同样套路:获取OutputParser后,调它的jsonSchema()/formatInstructions()。对于简单类型(int、boolean 等),这些解析器会返回简单的自然语言指令,而对于 POJO 和集合,则会生成真正的 JSON Schema 或详细格式化说明。
DefaultOutputParserFactory是如何分发并处理不同类型的
当你调用一个返回类型非 String、非
ChatMessage、非基础类型的 AI
服务方法时(具体在ServiceOutputParser 内部通过私有方法
schemaNotRequired(rawClass)
提前拦截那些不需要格式化指令或 JSON Schema
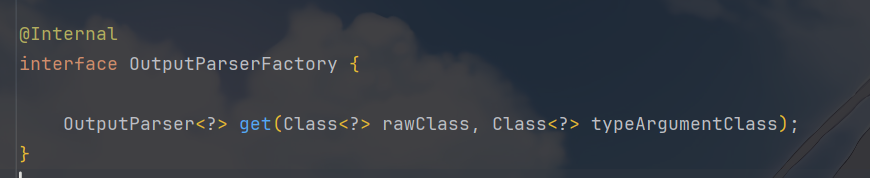
的类型),LangChain4j 会通过 DefaultOutputParserFactory
生成对应的 OutputParser,这就是解析器的注册与创建
工厂接口很简单:
DefaultOutputParserFactory
是默认实现,它在内部维护了一个静态映射表,覆盖了所有基础类型、日期时间、大数值等。对于映射表未命中的类型,它会按集合或复杂对象进行二次分发。
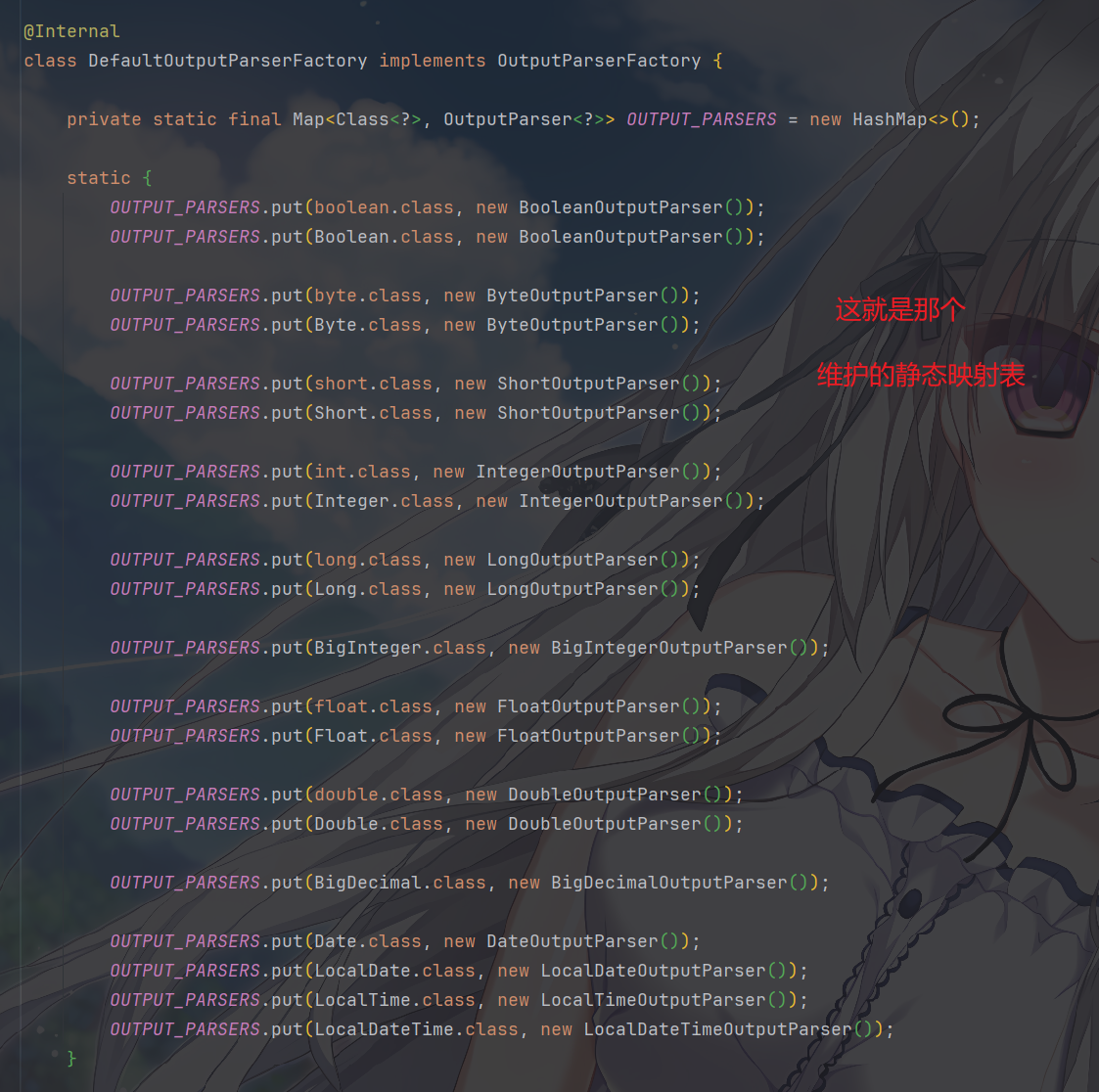
这里的每个 XxxOutputParser 都实现了:
parse(String text):把字符串解析为对应基础类型(例如Boolean.parseBoolean,Integer.parseInt)。formatInstructions():返回非常简短的自然语言指示,如"integer",而不是 JSON Schema。因为这些类型最终在 JSON 结构中只是叶子节点,不需要外层 schema 包含它们,但在 LLM 直接返回纯值时有用(比如上面的接口有些方法直接返回boolean)。
多说无益,我们看一个前面没有提到的枚举类型在这里面是如何被处理的
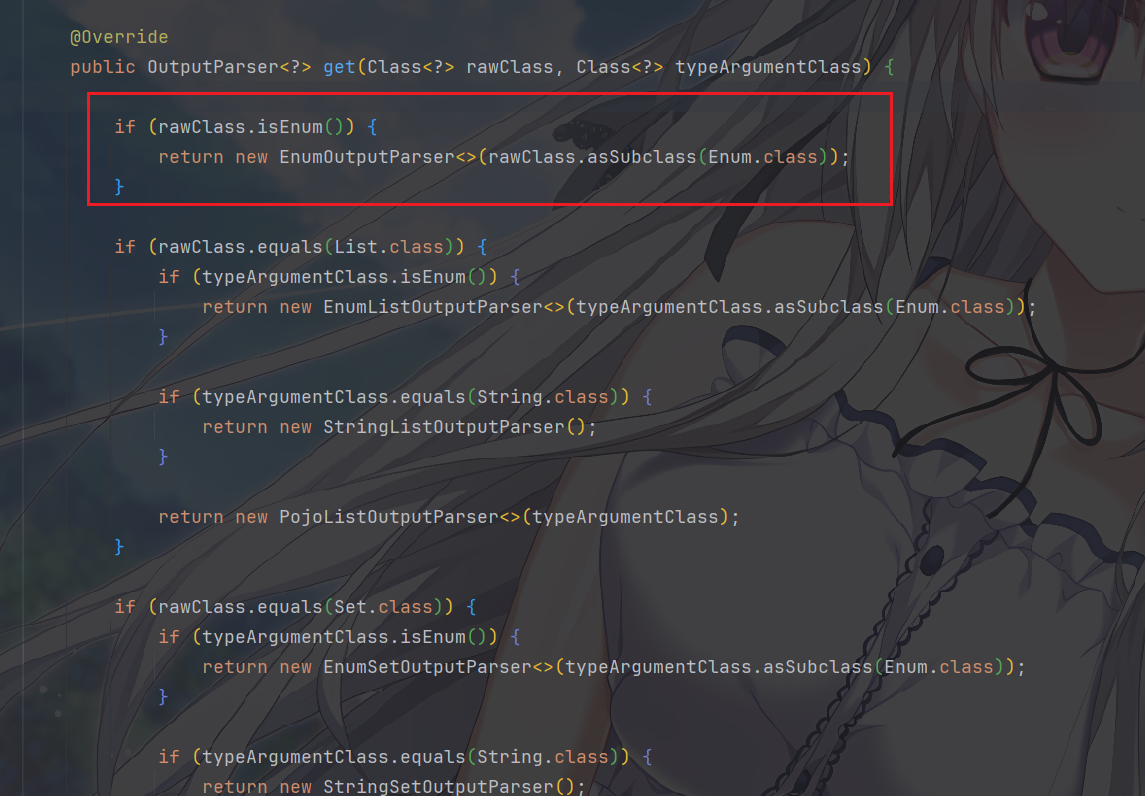
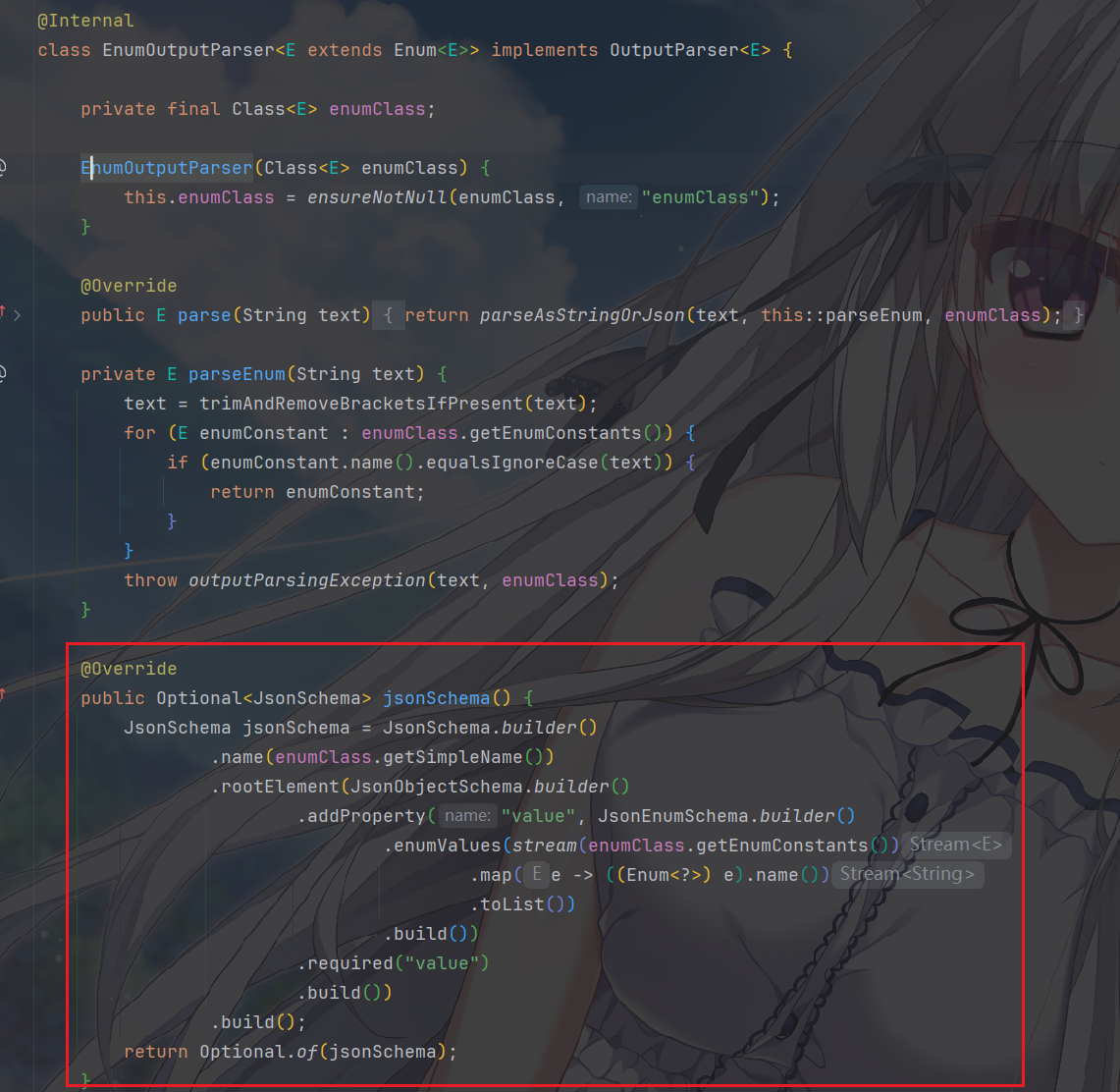
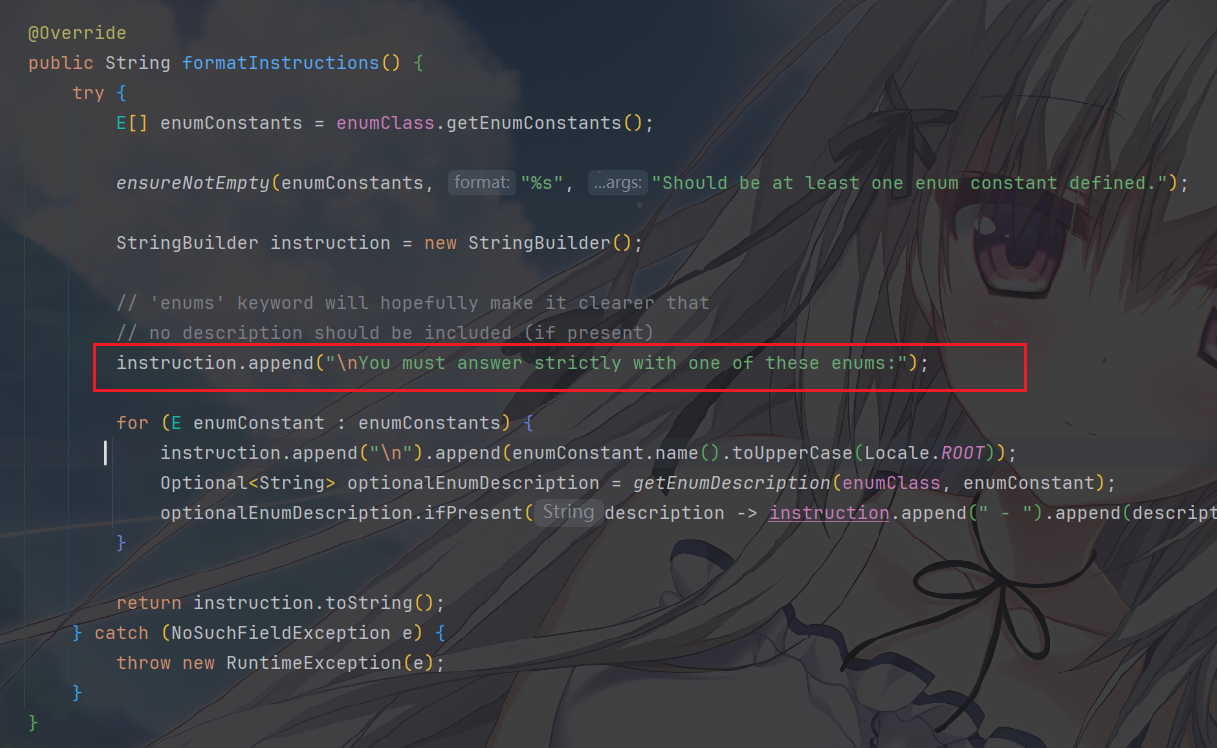
这还是比较好懂的,关键的就是EnumOutputParser 会在
formatInstructions() 中列举所有合法的 enum 值,然后注入 LLM
告诉他,你的输出必须是这些中的一个
使用PojoOutputParser处理 POJO
然后,很明显,上面提到的都是基础类型,那么如果 rawClass
不在基础类型映射表中,且不是枚举、List、Set,那么就认为它是一个
POJO,使用
PojoOutputParser。这就是结构化输出的真正起点。
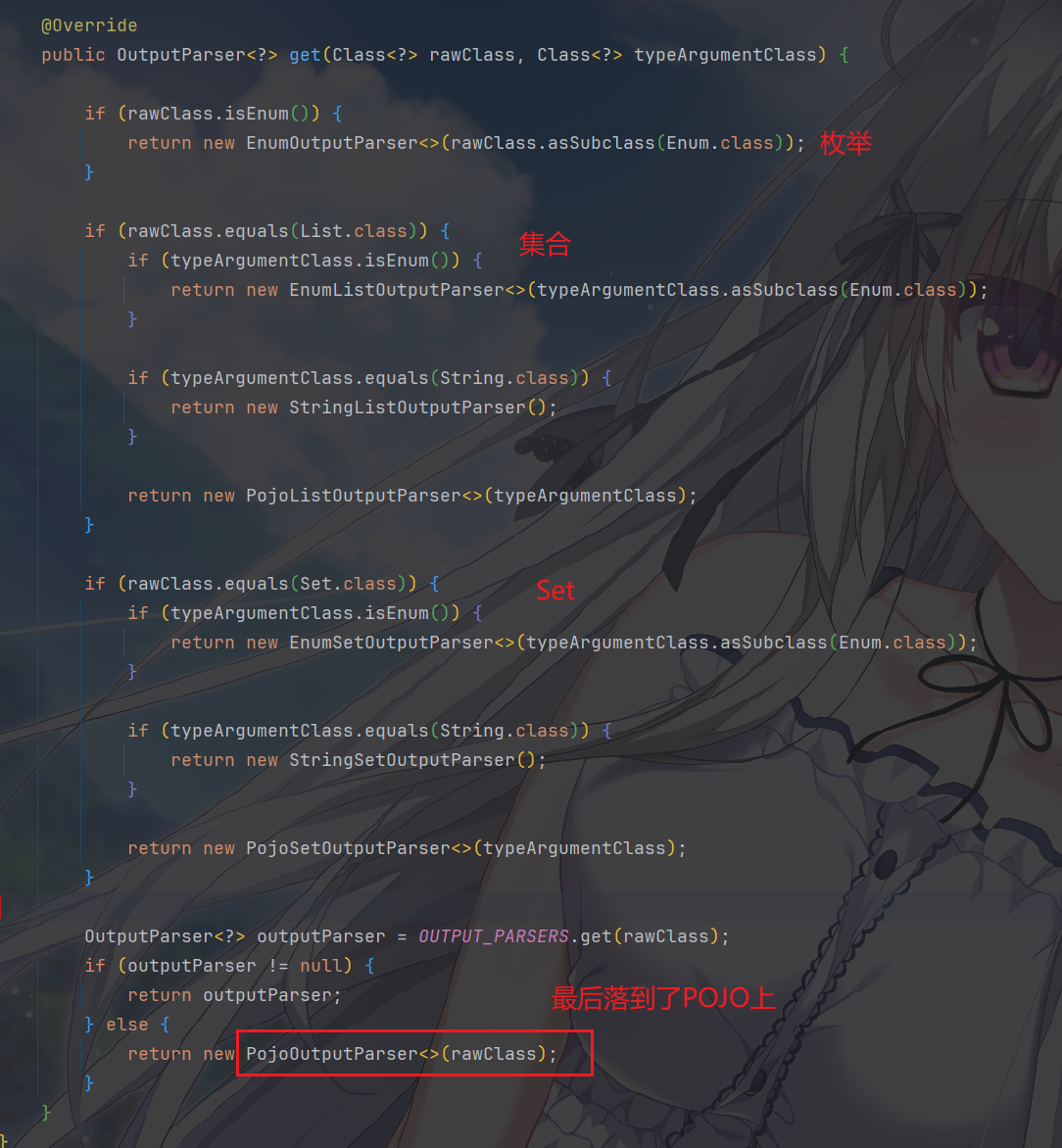
PojoOutputParser 内部会调用我们之前提到的
JsonSchemas.from(rawClass, ...) 来生成该类的 JSON
Schema,并用它构建格式指令和解析逻辑。它也是唯一直接调用
JsonSchemas
来提取对象结构信息的解析器(PojoListOutputParser
等也是间接通过它)。
当最终落入 PojoOutputParser
时,对象结构信息的提取 才真正发生。它会使用
JsonSchemas 利用反射读取字段、注解、泛型,递归生成完整的
JSON Schema 描述,然后再转换为 LLM 可理解的格式说明或原生 JSON
Schema。
PojoOutputParser 拿到了 rawClass(比如
Person.class),下一步就是
对象结构信息的真正提取,即
JsonSchemas.from() 的工作:遍历字段、读取
@Description、@JsonProperty
等注解、处理嵌套对象和集合,最终构建出 JSON Schema
树。来看看详细的情况
上述都是大致的步骤,我们这次结合源码详细了解一下。
DefaultOutputParserFactory在遇到非基础类型、非枚举、非 List/Set 时会创建PojoOutputParser,并把你的业务类(如Person.class)传入。此后所有操作都是基于这个type的反射信息。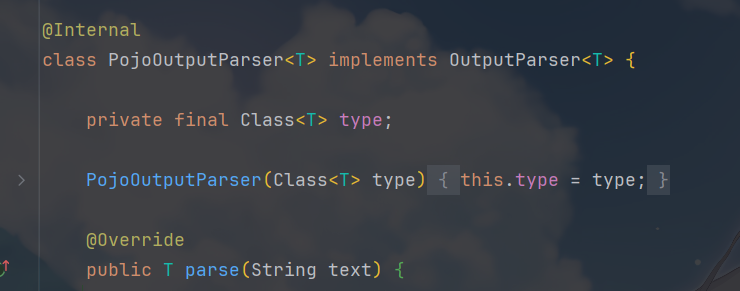
formatInstructions()是在没有原生 JSON Schema 支持时,用于注入提示词的格式指令。不细说,简单看看吧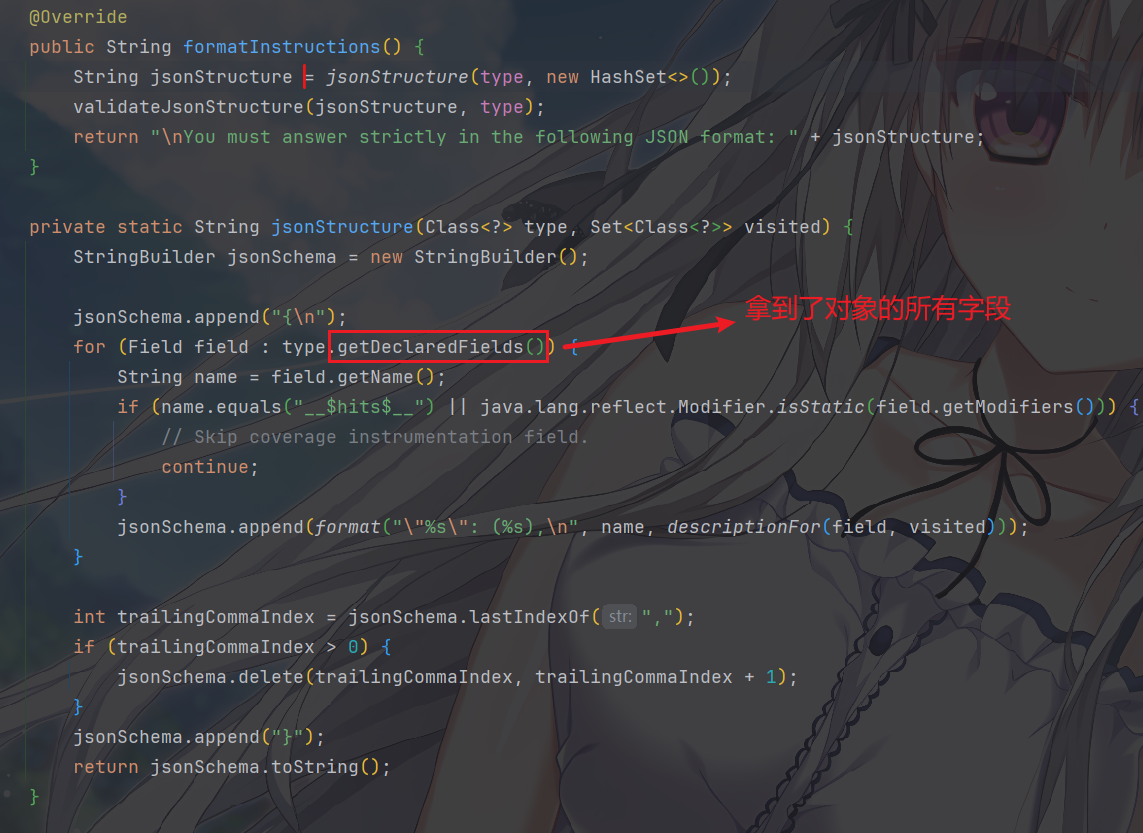
descriptionFor这部分处理融合@Description注解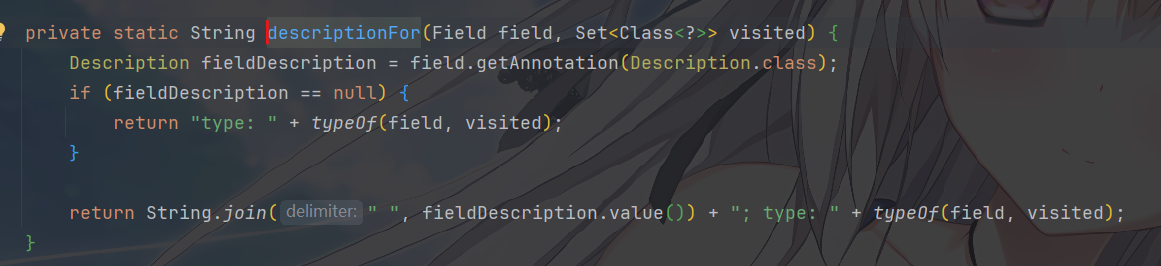
如果字段标注了
@Description,则输出其 value 的内容,否则只输出"type: string"。是
typeOf在做推断字段的类型描述它处理 Java 的各种类型并返回一个字符串描述,应该是最核心的部分了
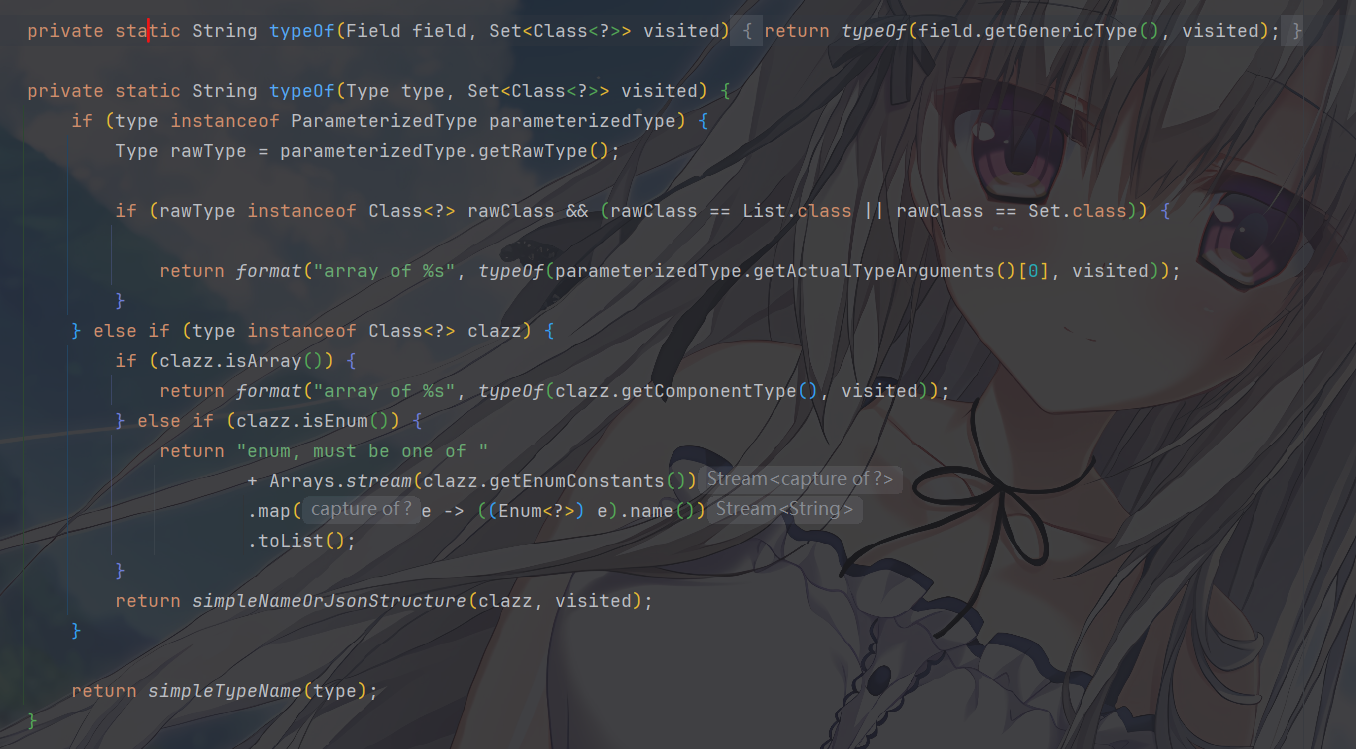
它处理五种情况:
- 参数化类型(泛型):如果是
List<SomeType>或Set<SomeType>,返回"array of SomeType",并且递归调用typeOf解析SomeType。 - 数组:返回
"array of 元素类型"。 - 枚举:直接列出所有枚举值的名字,例如
"enum, must be one of [MALE, FEMALE]"。 - 普通类:调用
simpleNameOrJsonStructure,决定是输出简单类型名,还是进一步递归展开嵌套对象。 - 兜底:其他未知类型使用
simpleTypeName(默认为全限定类名)。
- 参数化类型(泛型):如果是
实际上,formatInstructions() 完全不依赖外部
Schema 库,纯靠 Java 反射和注解,递归遍历你的 POJO
字段树,生成一个带注释的 JSON
模板字符串。这本身就是一次完整的“对象结构信息提取”,信息直接用于提示词工程。
最后,jsonSchema()就生成了标准 JSON Schema
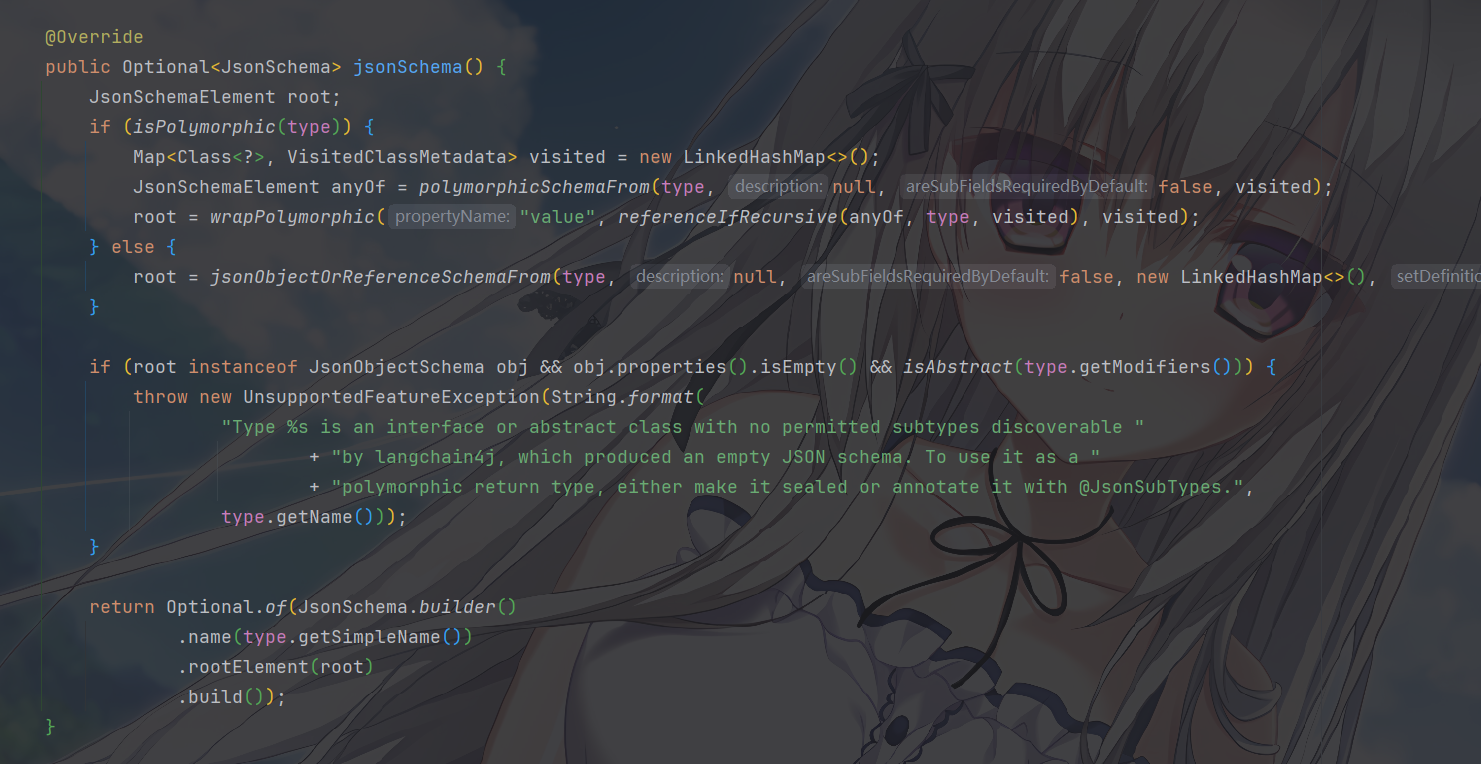
这里出现了两种分支:
isPolymorphic为 true,涉及到多态如果你的返回类型是接口、抽象类,或者标注了
@JsonSubTypes等,LangChain4j 会将其视为多态类型。此时:polymorphicSchemaFrom会扫描所有已知子类型,为每个子类型生成对应的 Schema,然后用anyOf组合起来。wrapPolymorphic会把它包装成一个{"value": ...}的结构,外层有一个"value"属性来承载实际对象- 解析时(
parse方法)也会检查多态,解析这块我就不多讲了
普通 POJO
直接调用
jsonObjectOrReferenceSchemaFrom(type, ...)。这个方法很复杂,总之,大概看一眼应该就是,反射拿到type的所有字段,读取@JsonProperty、@Description、@JsonSchema等注解,递归处理字段类型,构造JsonObjectSchema,最后还会检测一下循环引用
简单讲一下输出解析与反序列化
解析输出主要就是parse()
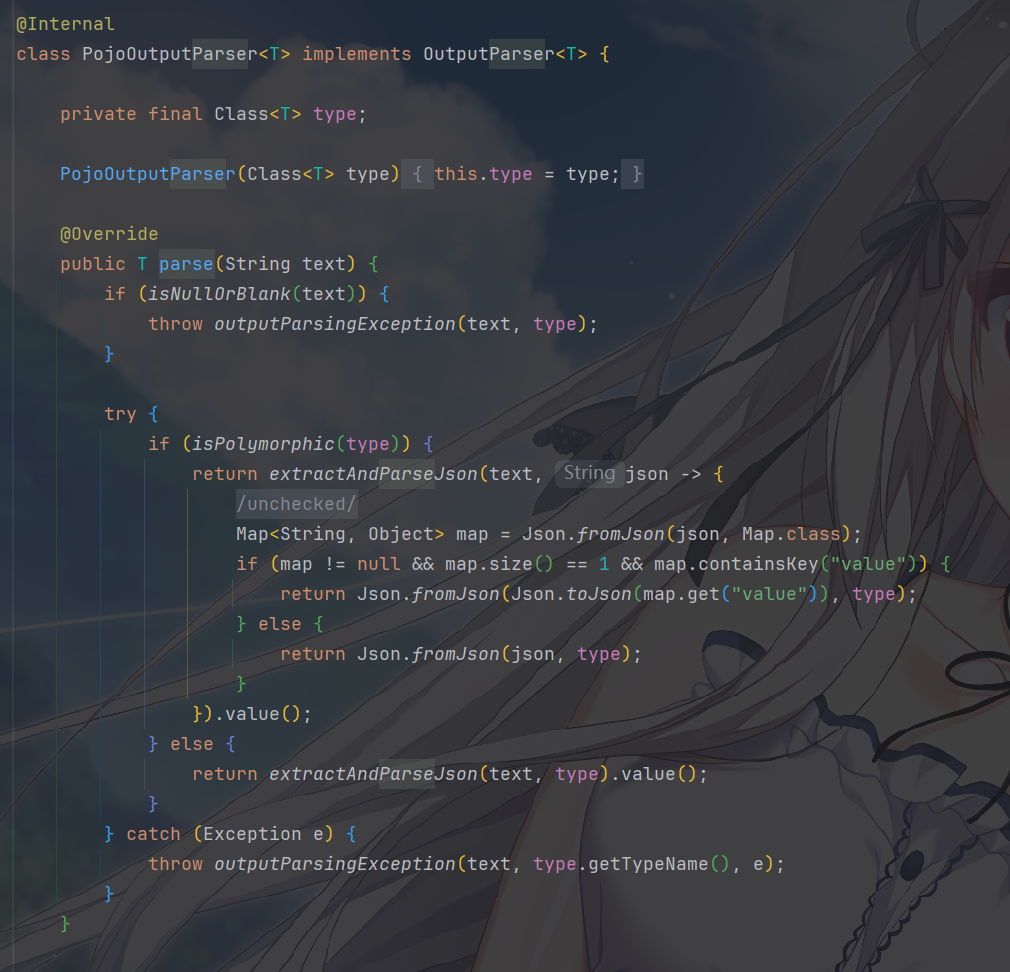
extractAndParseJson 是一个通用工具
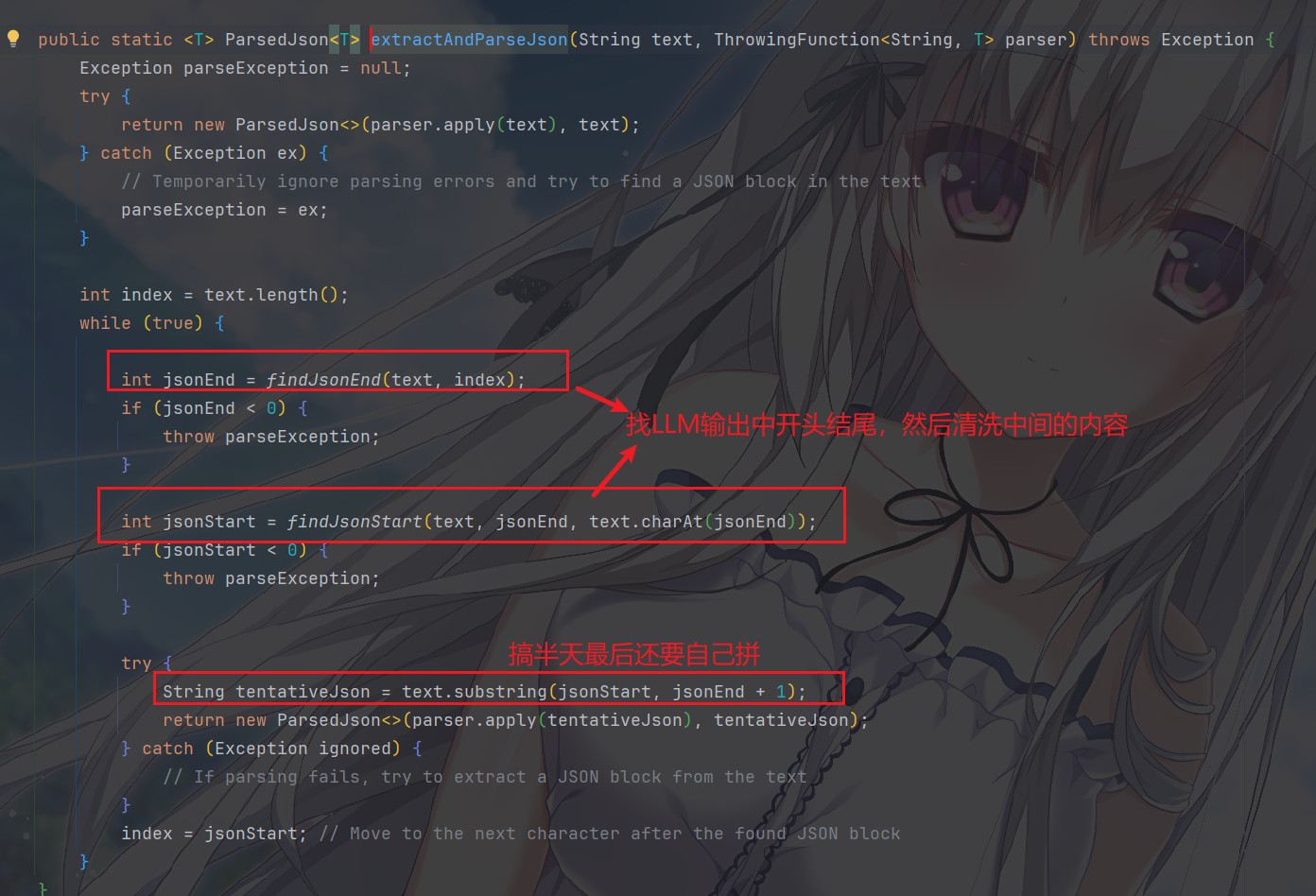
在这里,使用 Jackson 将干净的 JSON 字符串反序列化为 type
指定的 Java 对象。
此处的反序列化肯定也利用了 type
的完整类型信息包括泛型的处理,所以即使你的 POJO 里包含
List<Address>或者嵌套递归 POJO,也能正确还原。






