LangChain4j 简介
介绍
LangChain4j 是一个专为 Java
开发者设计的开源框架,旨在简化大语言模型(LLM)在 Java
应用中的集成。它的目标类似于 Python 生态中的 LangChain
,但针对Java生态进行了优化,提供统一的API抽象、上下文管理(Memory)、提示模板、文档检索(RAG)等功能。
统一的 API: LLM 提供商(如 OpenAI 或 Google Vertex
AI)和嵌入向量存储(如 Pinecone 或 Milvus)使用专有的 API。LangChain4j
提供统一的 API,以避免学习和实现每个 API 的特定 API 的需要。要试验不同的
LLM 或嵌入存储,您可以轻松地在它们之间切换,而无需重写代码。
全面的工具箱: 自 2023 年初以来,社区一直在构建许多由
LLM 驱动的应用程序,识别常见的抽象、模式和技术。LangChain4j
已将这些提炼成一个现成的包。我们的工具箱包括从低级别的提示模板、聊天记忆管理和函数调用到高级模式(如代理和
RAG)的工具。对于每个抽象,我们都提供一个接口以及基于常用技术的多个现成的实现。无论您是构建聊天机器人还是开发具有完整流程(从数据摄取到检索)的
RAG,LangChain4j 都能提供各种选项。
LangChain4j 旨在让 Java
开发者无需学习不同LLM提供商的专有API,快速构建智能应用(如聊天机器人、智能助手)。
目前主流的 Java AI 开发框架有 Spring AI 和 LangChain4j ,它们都提供了很多
开箱即用的 API 来帮你调用大模型、实现 AI
开发常用的功能,比如,对话记忆,结构化输出,RAG
知识库,工具调用,MCP,SSE 流式输出 等等内容
这两个框架的很多概念和用法都是类似的,毕竟它们的服务对象和目标都是一致的,而且也都提供了很多插件扩展,都支持和
Spring Boot 项目集成。就我个人而言,我更喜欢使用 LangChain4j
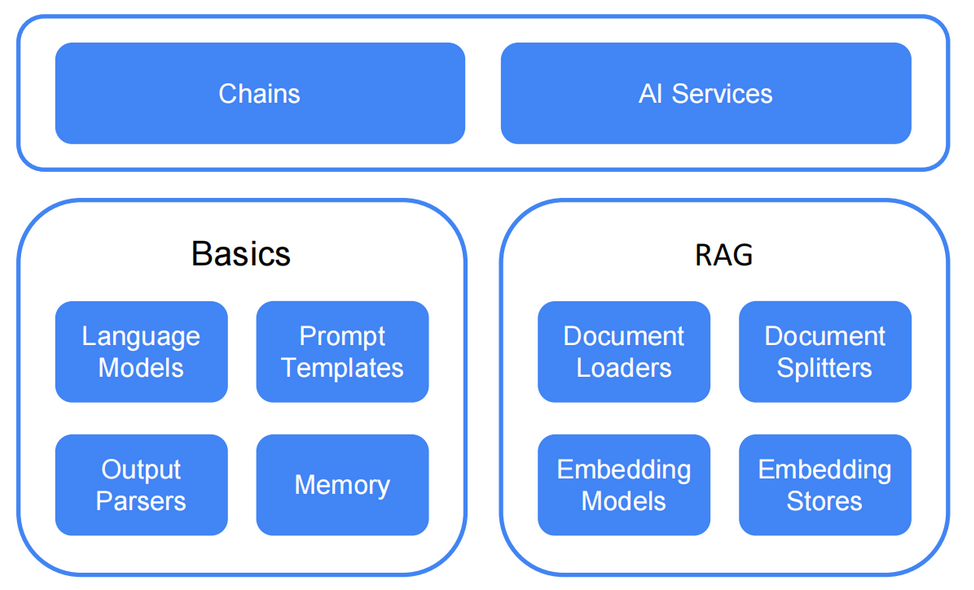
两个抽象级别
LangChain4j
在两个抽象级别上运行,与众多框架一样,这是为了兼顾不同开发者的需求,提供了封装和相对底层的两个级别用于快速构建和定制开发
image-20260521094158917
低级别抽象为开发者提供了与 LLM(大语言模型)交互的 原语
或基础构件。在这个层级,你可以获得最大的自由度和控制权。
你可以完全控制 LLM
应用的各个组件,手动组合消息流程、向量存储、嵌入生成等细节。但相对的,你需要编写较多的粘合代码,例如这样手动构建消息列表并调用模型
1 2 3 4 5 6 7 8 9 10 11 ChatLanguageModel model = OpenAIChatModel.withApiKey("your-api-key" );List<Message> messages = List.of( new SystemMessage ("你是一个乐于助人的助手。" ), new UserMessage ("请给我讲一个笑话。" ) ); AiMessage response = model.generate(messages).content();
高级别抽象通过封装复杂的底层逻辑,提供了更加简洁、声明式的开发体验。框架会自动处理细节。例如在高级别中,发送消息你只需要定义一个接口即可
1 2 3 4 5 6 7 8 9 @AiService interface Assistant { String chat (String userMessage) ; } Assistant assistant = AiServices.create(Assistant.class, model);String response = assistant.chat("请给我讲一个笑话。" );
区分并简单介绍它们的依赖
LangChain4j的依赖有很多,而且各个之间作用区分很明显,配置不好甚至容易导致冲突,所以这里简单提及一下这些依赖它们的作用,负责的内容,之前的兼容性等等内容
首先,LangChain4j 遵守版本对齐原则 ,LangChain4j
的核心模块(langchain4j-core、langchain4j)和主流集成模块(如
langchain4j-anthropic、langchain4j-open-ai)通常需要并且也会保持版本同步(比如都是
1.15.0)。这些必须保持版本号完全一致 。
所以我们最好使用 BOM 来管理依赖,你只需要在 Maven 的
<dependencyManagement> 中引入 BOM,之后引入任何
langchain4j 相关的依赖就不需要再写 <version>
标签了 ,它会自动帮你匹配最兼容的版本。
langchain4j模块化的特性非常明显,有时候一个完备的 AI Agent
应用可能会引入二三十个 LangChain4j
的依赖,图上没说的太多了,所有依赖的所有文档在这里
https://docs.langchain4j.dev/apidocs/index.html
langchain4j
这是框架的主模块 。它依赖于
langchain4j-core,并提供了核心接口的具体实现和高级功能。比如大家常用的
AI Services (声明式 AI
接口)、文档加载与分割(DocumentLoader、TextSplitter)、内存管理实现以及
RAG(检索增强生成)的核心逻辑都在这里。
它位于中间层,承上启下。实际开发中,通常引入这个模块,引入它,你就拥有了编排
AI 业务流程的能力,但依然需要配合具体的 模型集成模块
才能真正调用大模型。
image-20260521095013183
这是其依赖,截至文章编写的最新版本为1.15.0
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j</artifactId > <version > 1.15.0</version > <scope > compile</scope > </dependency >
langchain4j-core
langchain4j-core是整个 LangChain4j
框架的地基 。它只定义了最基础的接口和抽象类,比如
ChatModel(聊天模型接口)、EmbeddingStore(向量存储接口)、ChatMemory(对话记忆接口)以及各种核心数据类型(如
Document、ChatMessage)。
它处于依赖的最底层,几乎没有任何外部依赖。它不包含任何具体的模型实现 ,不能单独用来调用
AI。
正常情况下,我们几乎不直接引入它或者只引入它,但如果你只是想基于
LangChain4j
的标准开发自己的扩展插件,或者做一个非常轻量级的适配,可以只引入它。
在实际业务开发中,它通常作为其他模块的传递依赖被自动引入。
image-20260521095142646
这是其依赖,截至文章编写的最新版本为1.15.0
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-core</artifactId > <version > 1.15.0</version > <scope > compile</scope > </dependency >
langchain4j-mcp
这是一个扩展模块。MCP 全称是 Model Context
Protocol(模型上下文协议),旨在标准化 AI
模型与外部数据/工具的连接方式。
引入它可以让你的 LangChain4j 应用支持 MCP
协议,从而更规范地获取上下文或连接外部系统。
这属于进阶玩法,基础的对话或 RAG 应用通常不需要引入。
image-20260521095603598
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-mcp</artifactId > <version > 1.15.0-beta25</version > <scope > compile</scope > </dependency >
langchain4j-embeddings
嵌入模型工具层,这个依赖是专门用于文本向量化(Embedding) 的,它相当于一个本地
Embedding 模型运行引擎。
它的核心作用是提供在 Java 进程内通过 ONNX Runtime 加载和运行本地 AI
模型的基础设施,所以说,使用它,你需要自己去找向量化模型,并自定义加载逻辑,你就需要并且只需要依赖这个包就可以。
langchain4j-embeddings是一个基础工具包,提供了在 Java
进程中本地运行 Embedding 模型的基础设施和抽象。
如果你不想调用 OpenAI 等收费的在线 Embedding
API,而是想在本地(内存中)直接把一段文字转化成向量,就可以引入这个具体的模型包。它通常用于本地开发测试,或者对数据隐私要求极高、不能出网的
RAG 场景。
image-20260521095848234
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-embeddings</artifactId> <version>1.15 .0 -beta25</version> <scope>compile</scope> </dependency>
而 langchain4j-embeddings-all-minilm-l6-v2-q是我们本地化
Embedding 用的最多的一个了,它不仅依赖了上面的“运行引擎”,还直接内置了
all-MiniLM-L6-v2 这个特定模型的权重文件(.onnx
文件)和对应的配置文件。
引入它,你不需要自己去网上找模型文件,直接实例化对应的 Java 类(如
AllMiniLmL6V2QuantizedEmbeddingModel)就能立刻开始把文本转成向量。
image-20260521095356783
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-embeddings-all-minilm-l6-v2-q</artifactId > <version > 1.15.0-beta25</version > <scope > test</scope > </dependency >
langchain4j-{ai厂商或者模型名}
以 langchain4j-anthropic
举例子,这一类属于集成层 ,负责对接具体的 LLM
提供商或向量数据库。比如 langchain4j-anthropic 就是用来对接
Anthropic 的模型。同理还有
langchain4j-open-ai、langchain4j-ollama(本地模型)、langchain4j-milvus(向量数据库)等。
它们依赖 langchain4j-core(有时也依赖主模块),实现了
core 中定义的接口(如
ChatModel)。引入它,你的应用才能真实地 连接 到某个具体的
AI
模型或数据库。你可以根据业务需要,只引入你使用的那一两个厂商模块,保持项目轻量。
image-20260521095255539
这是其依赖,截至文章编写的最新版本为1.15.0
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-anthropic</artifactId > <version > 1.15.0</version > <scope > compile</scope > </dependency >
langchain4j-spring-boot-starter
该依赖是 Spring
框架的通用集成,是核心的自动配置中心,它本身不包含 具体的模型实现,它主要负责搭建
Spring 环境下的环境。它提供了 Spring Boot 的自动配置能力,定义了 Spring
环境下最基础的接口抽象。
image-20260522150643428
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-spring-boot-starter</artifactId > <version > 1.15.0-beta25</version > <scope > compile</scope > </dependency >
langchain4j-{模型名}-spring-boot-starter
这里以 open-ai 为例子,这是 组合依赖,内部已经包含了
langchain4jlangchain4j-open-ailangchain4j-spring-boot-starter
它负责把 OpenAI 的 API 包装成 LangChain4j 标准的
ChatModel
接口,并且提供对应的配置项和自动配置的相关内容,让 Spring
容器能识别,而且直接拥有对接对应模型的能力
image-20260522150739633
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-open-ai-spring-boot-starter</artifactId > <version > 1.15.0-beta25</version > <scope > test</scope > </dependency >
langchain4j-http-client
这一组是比较底层的依赖,通常被隐藏在上述 Starter 内部
langchain4j-http-client 是一个标准协议(SPI) 。LangChain4j
定义了一套“如何发送 HTTP 请求”的规范,但它自己不写具体的发送代码。这让
LangChain4j 变得很轻量,因为它不强制绑定任何特定的 HTTP 框架
image-20260522145704895
这是其依赖,截至文章编写的最新版本为1.15.0
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-http-client</artifactId > <version > 1.15.0</version > <scope > compile</scope > </dependency >
它相关的还有个这个内容,是上述规范的默认实现 。它使用了
Java 11+ 自带的 java.net.http.HttpClient
来发送请求,叫langchain4j-http-client-jdk
这意味着,如果你用的是 JDK 17+(LangChain4j
的门槛),你不需要引入任何第三方 HTTP 包(如 OkHttp 或 Apache
HttpClient) ,LangChain4j
就能直接工作,依赖自己少引一个是一个我说
image-20260522145622661
这是其依赖,截至文章编写的最新版本为1.15.0
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-http-client-jdk</artifactId > <version > 1.15.0</version > <scope > runtime</scope > </dependency >
langchain4j-document-parser-apache-tika
这是一个很好用的文件解析器,用于处理各种文档。
在 Java 中处理文件非常麻烦。读 PDF 需要 PDFBox,读 Word 需要 POI,读
Excel 又要 EasyExcel 什么的。如果还要处理编码问题,会非常头大。
它是对 Apache Tika 的封装。也是老牌 Java 内容分析工具了
无论你给它 PDF、Word、Excel、HTML
还是纯文本,它都能把它们扒下来,变成 LangChain4j
能理解的纯文本,一般是Document
对象。而且亲测它不仅能提取文字,还能顺便提取文件的元数据(如作者、创建时间、文件类型),这对于后续做元数据过滤非常有用。
image-20260522150038977
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-document-parser-apache-tika</artifactId > <version > 1.15.0-beta25</version > <scope > compile</scope > </dependency >
langchain4j-agentic
这是 LangChain4j 的智能体(Agent)核心框架。
如果说基础的语言模型是只会回答问题,那么加上这个模块,它就能帮你干活了。它提供了让
AI 能够自主规划、调用工具、循环思考 的 Agent 能力。支持
Human-in-the-loop(人机协作,AI
做事前询问人类意见)、多智能体协作、以及复杂的任务拆解逻辑,这些都是 AI
Agent 中比较常见而且实用的内容
当你需要 AI 不仅仅是聊天,而是要执行查询天气 -> 预定机票 ->
发送邮件这种复杂流程时,有必要进行使用。
image-20260522150328612
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-agentic</artifactId > <version > 1.15.0-beta25</version > <scope > compile</scope > </dependency >
langchain4j-easy-rag
这是一个 RAG 快速工具包,标准的 RAG
流程非常复杂,而且涉及到各种组件,如果你只是需要一个轻量的 RAG
功能,或者说就是自己本地研究一个 RAG,
使用这个会很简单,而且应该是开箱即用的
它把上述复杂的流程封装成了一个简单的工具类,你只需要告诉它文件夹路径和
Embedding
模型,它会自动帮你完成文件的加载、分块、向量化和存储,而且默认配置能完全本地的进行,不需要配置复杂的向量数据库
我说,预制 RAG 嗯造
image-20260522150554774
这是其依赖,截至文章编写的最新版本为1.15.0-beta25
1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-easy-rag</artifactId > <version > 1.15.0-beta25</version > <scope > compile</scope > </dependency >
搭建一个LangChain4j聊天项目
本项目会使用 SSE 流式的方式来进行请求和接受 AI
的回复,这样更符合现代大模型相关业务的需求,SSE 比阻塞好太多了))
我们就简单的建立一个能够进行基础流式对话,并且能够有记忆的就可以了,因为我用的
deepseek
模型它怎么弄也不支持多模态,按道理来说应该是支持的,我也不知道什么情况)))
项目依赖与配置
对于依赖,有了上面我的区分讲解,想必大家肯定都知道引入什么依赖了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 <properties > <java.version > 21</java.version > <langchain4j.version > 1.15.0</langchain4j.version > </properties > <dependencyManagement > <dependencies > <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-bom</artifactId > <version > ${langchain4j.version}</version > <type > pom</type > <scope > import</scope > </dependency > </dependencies > </dependencyManagement > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-webflux</artifactId > </dependency > <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j</artifactId > </dependency > <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-open-ai</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > </dependencies >
然后对于配置
1 2 3 4 5 6 7 8 9 10 11 12 spring.application.name =LangChain4jDemo server.port =8594 app.ai.deepseek.api-key =sk-1xxxx app.ai.deepseek.base-url =https://api.deepseek.com/v1 app.ai.deepseek.model-name =deepseek-v4-pro app.ai.deepseek.temperature =0.7 app.ai.deepseek.max-tokens =4096 app.ai.memory.max-messages =20
实体
对于我们在 LangChain4j 中与 LLM 进行沟通,可以这样构建请求体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Data public class ChatRequest { private String sessionId; private String message; }
那么 AI 的响应也就可以是这样,但是因为 SSE
不涉及到这个,所以这个就是给同步的请求演示的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Data @NoArgsConstructor @AllArgsConstructor public class ChatResponse { private String content; private String sessionId; public static ChatResponse of (String content, String sessionId) { return new ChatResponse (content, sessionId); } }
很明显我们能发现,sessionId是实现多用户/多会话记忆的核心
ChatLanguageModel 本身是无状态的 :每次调用
generate() 方法都是独立的,不知道之前的对话内容所以说,我们需要 LangChain4j 的 ChatMemory 组件通过
sessionId 来区分不同会话
这些内容在服务层部分会有进一步的体现
服务层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 import dev.langchain4j.data.message.*;import dev.langchain4j.memory.ChatMemory;import dev.langchain4j.model.chat.ChatModel;import dev.langchain4j.model.chat.StreamingChatModel;import dev.langchain4j.model.chat.response.ChatResponse;import dev.langchain4j.model.chat.response.StreamingChatResponseHandler;import hbnu.project.langchain4jdemo.config.AiConfig;import org.springframework.stereotype.Service;import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;import java.io.IOException;import java.util.Set;import java.util.concurrent.ConcurrentHashMap;@Service public class ChatService { private static final String SYSTEM_PROMPT = "你是一个友好、专业的 AI 助手。" + "你的目标是为用户提供准确、有帮助的回答。" + "在回答问题时,请保持简洁清晰,并在必要时提供示例。" ; private final ChatModel chatModel; private final StreamingChatModel streamingChatModel; private final AiConfig aiConfig; private final ConcurrentHashMap<String, ChatMemory> memoryMap = new ConcurrentHashMap <>(); public ChatService (ChatModel chatModel, StreamingChatModel streamingChatModel, AiConfig aiConfig) { this .chatModel = chatModel; this .streamingChatModel = streamingChatModel; this .aiConfig = aiConfig; } private ChatMemory getOrCreateMemory (String sessionId) { return memoryMap.computeIfAbsent(sessionId, id -> { ChatMemory memory = aiConfig.buildChatMemory(id); memory.add(SystemMessage.from(SYSTEM_PROMPT)); return memory; }); } public void clearMemory (String sessionId) { ChatMemory memory = memoryMap.remove(sessionId); if (memory != null ) { memory.clear(); } } public String chat (String sessionId, String userInput) { ChatMemory memory = getOrCreateMemory(sessionId); UserMessage userMessage = UserMessage.from(userInput); memory.add(userMessage); AiMessage aiMessage = chatModel.chat(memory.messages()).aiMessage(); memory.add(aiMessage); return aiMessage.text(); } public void streamChat (String sessionId, String userInput, SseEmitter emitter) { ChatMemory memory = getOrCreateMemory(sessionId); UserMessage userMessage = UserMessage.from(userInput); memory.add(userMessage); StringBuilder fullResponse = new StringBuilder (); streamingChatModel.chat(memory.messages(), new StreamingChatResponseHandler () { @Override public void onPartialResponse (String token) { try { fullResponse.append(token); emitter.send(SseEmitter.event().data(token)); } catch (IOException e) { emitter.completeWithError(e); } } @Override public void onCompleteResponse (ChatResponse response) { memory.add(response.aiMessage()); try { emitter.send(SseEmitter.event().name("done" ).data("[DONE]" )); } catch (IOException e) { } emitter.complete(); } @Override public void onError (Throwable error) { try { emitter.send(SseEmitter.event().name("error" ).data(error.getMessage())); } catch (IOException e) { } emitter.completeWithError(error); } }); } }
很明显,我们使用了两种的 AI 对话形式,包括同步和流式,这两种
ChatModel 的本质区别我们来看看
对于同步阻塞,使用的就是chatModel
1 2 3 4 5 6 7 8 9 10 11 12 public String chat (String sessionId, String userInput) { ChatMemory memory = getOrCreateMemory(sessionId); memory.add(UserMessage.from(userInput)); AiMessage aiMessage = chatModel.chat(memory.messages()).aiMessage(); memory.add(aiMessage); return aiMessage.text(); }
不需要实时反馈的场景下,阻塞实现起来还是很简单的,但是消息过长容易导致一些不必要的问题
对于流式,使用的就是streamingChatModel,我们发现,创建streamingChatModel对象后重写它的这三个方法,就能够正确使用流式对话了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 streamingChatModel.chat(memory.messages(), new StreamingChatResponseHandler () { @Override public void onPartialResponse (String token) { emitter.send(token); } @Override public void onCompleteResponse (ChatResponse response) { memory.add(response.aiMessage()); } @Override public void onError (Throwable error) { } });
流式不需要在服务端缓存完整响应,所以说会有那种一块一块的流式感,而且可以提前中断
至于这两个接口的详细内容,下面会提到
对于记忆,就是涉及到了 ChatMemory 的内容,而
ChatMemory 内部维护着一个消息列表,在与 AI
对话的时候,会发送上下文记忆,所以说,要限制好上下文的大小,防止成本太高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 memory.add(SystemMessage.from("你是一个专业助手" )); memory.add(UserMessage.from("我叫张三" )); memory.add(AiMessage.from("你好张三!" )); memory.add(UserMessage.from("我叫什么?" )); [ SystemMessage("你是一个专业助手" ), UserMessage("我叫张三" ), AiMessage("你好张三!" ), UserMessage("我叫什么?" ) ]
控制器
接口这边其实就没啥好说的了,正常调用就可以了,只不过对于 SSE
部分,要正确处理好
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 @RestController @RequestMapping("/api/chat") @CrossOrigin(origins = "*") public class ChatController { private final ChatService chatService; public ChatController (ChatService chatService) { this .chatService = chatService; } @PostMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public SseEmitter streamChat (@RequestBody ChatRequest request) { if (request.getSessionId() == null || request.getSessionId().isBlank()) { request.setSessionId(UUID.randomUUID().toString()); } SseEmitter emitter = new SseEmitter (3 * 60 * 1000L ); Thread.ofVirtual().start(() -> chatService.streamChat(request.getSessionId(), request.getMessage(), emitter) ); return emitter; } @PostMapping("/sync") public ResponseEntity<ChatResponse> syncChat (@RequestBody ChatRequest request) { if (request.getSessionId() == null || request.getSessionId().isBlank()) { request.setSessionId(UUID.randomUUID().toString()); } String reply = chatService.chat(request.getSessionId(), request.getMessage()); return ResponseEntity.ok(ChatResponse.of(reply, request.getSessionId())); } @DeleteMapping("/memory/{sessionId}") public ResponseEntity<String> clearMemory (@PathVariable String sessionId) { chatService.clearMemory(sessionId); return ResponseEntity.ok("会话 [" + sessionId + "] 的记忆已清除" ); } }
测试
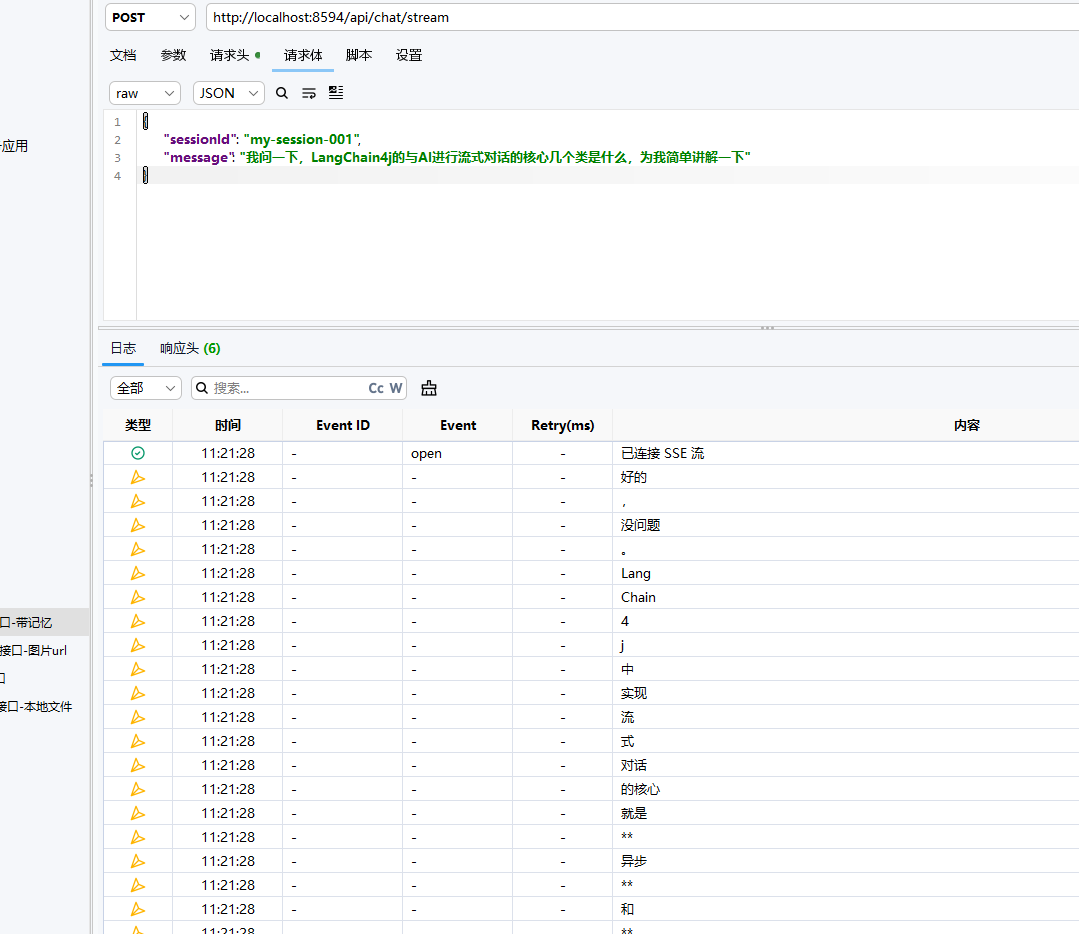
首先我们测试一下同步对话,可以发现我们能够正常的与 LLM 进行对话了
image-20260529112136263
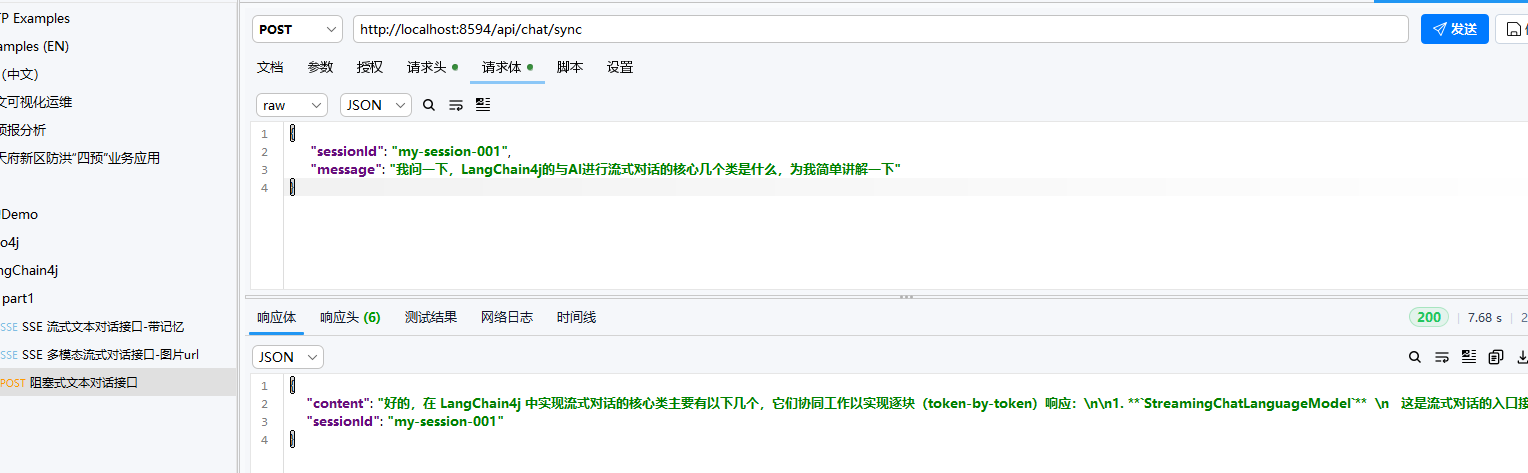
之后我们来测试一下同步对话请求的接口,可以发现阻塞式的体验是远远不如
SSE 的,等待时间也更长
image-20260527092040926
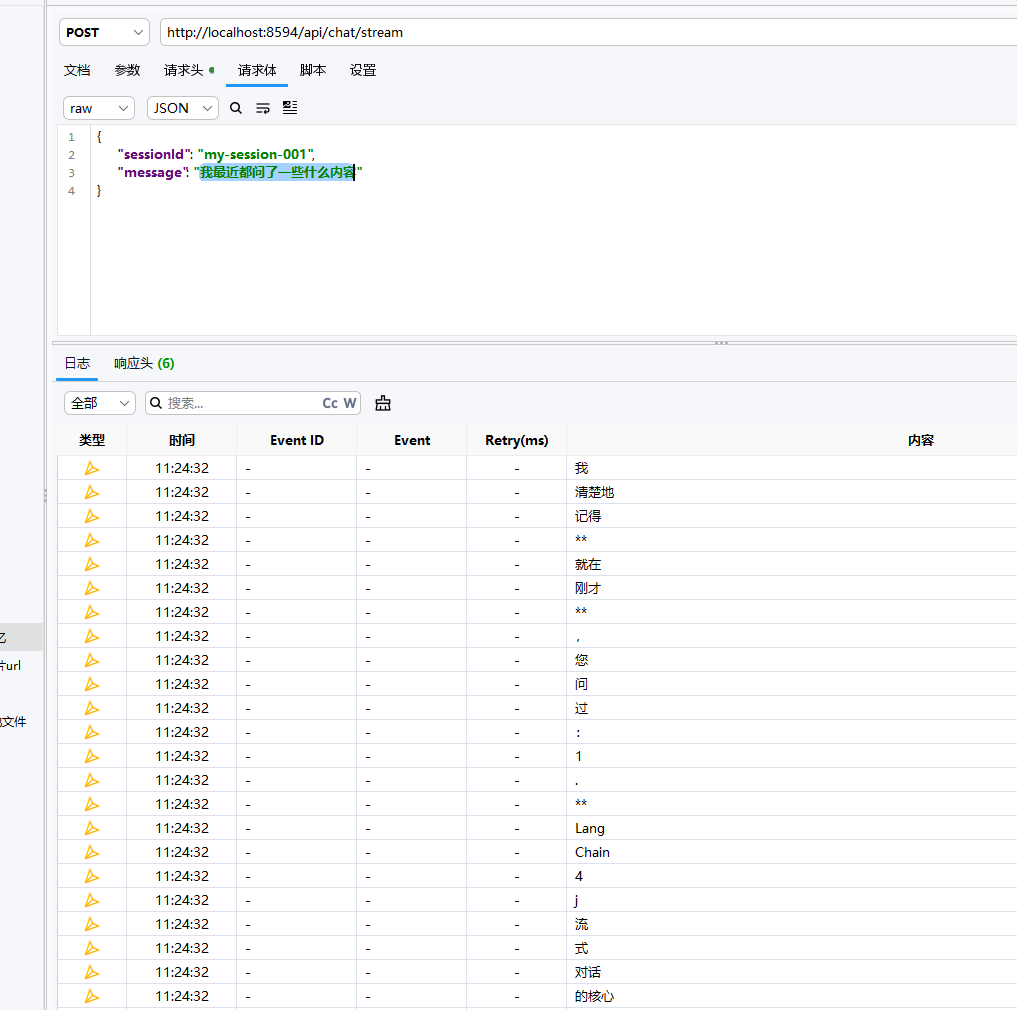
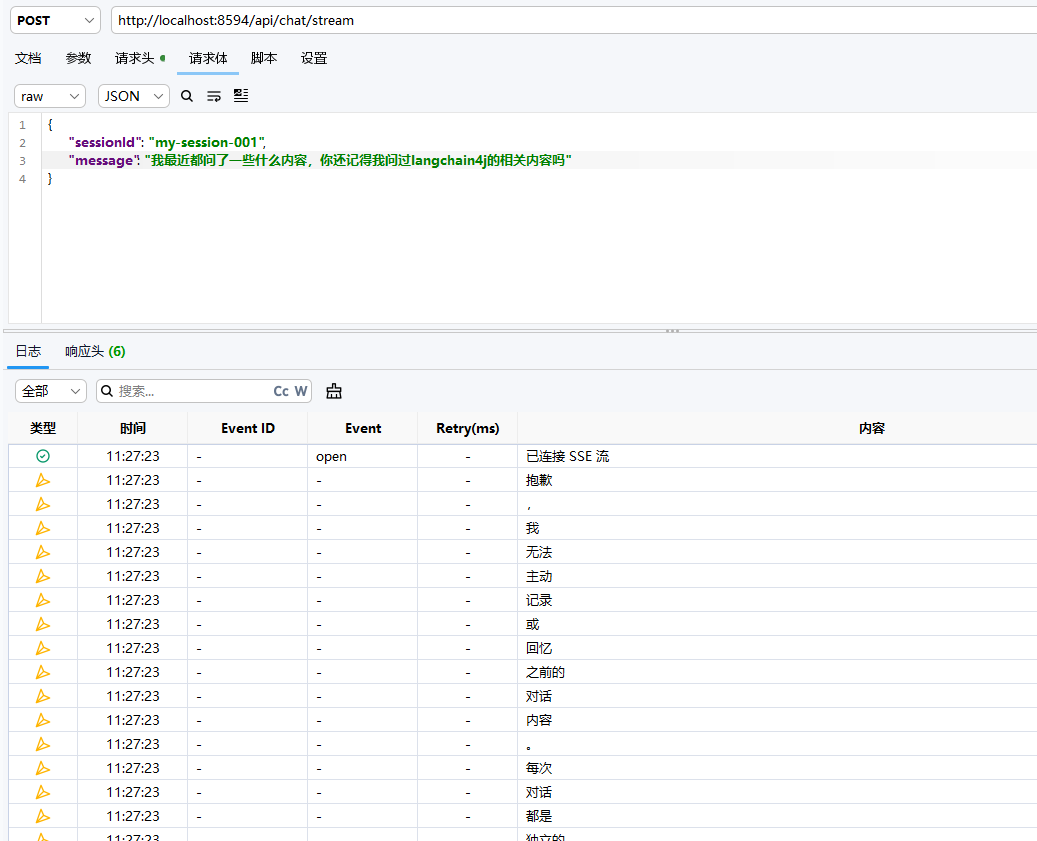
然后,我们一直使用的都是my-session-001,我们验证一下记忆的相关内容
首先问一下模型是否还保持记忆
image-20260529112506798
通过简单的诱导,虽然 deepseek
说自己不支持跨实例记忆这个那个的,但是还是能够回答最近我都问了什么,说明我们的
LangChain4j 是参与了相关的记忆的处理
我们使用我们项目中的接口来处理一下一轮对话的记忆,我们使用相同的sessionId,发现LLM怎么诱导也想不起来自己最近说过什么内容了,说明这个是真清理了
image-20260529112817548