
前期项目涉及到的内容
Spring Boot 集成
LangChain4j 提供了 Spring Boot Starter,用于:
- 常见的集成场景
- 声明式 AI Services
LangChain4j 的 Spring Boot 集成要求:
- Java 17
- Spring Boot 3.2
这些在前面提到依赖的时候都有提到过,总之,Spring Boot Starter
可以帮助你通过配置文件快速创建和配置语言模型、向量模型、向量存储,以及其他
LangChain4j
核心组件,依赖命名规范为:langchain4j-{integration-name}-spring-boot-starter。
例如,我们项目中,如果要使用
OpenAI(langchain4j-open-ai),首先要引入依赖如下:
1 | <dependency> |
然后在配置文件中配置模型参数
1 | langchain4j.open-ai.chat-model.api-key=${OPENAI_API_KEY} |
在这种情况下,OpenAiChatModel(ChatModel
的一个实现)会被自动创建, 你可以直接在需要的地方注入使用:
1 |
|
LangChain4j 聊天与语言模型
一般来说,LangChain4j 认为 LLM 目前提供两种 API 类型:
LanguageModel:它们的 API 非常简单,接收一个String作为输入,并返回一个String作为输出。 这种 API 现在逐渐被聊天 API(第二种 API 类型)取代。已不再扩展,逐渐被淘汰。ChatModel:它们接收多个ChatMessage作为输入,并返回一个单一的AiMessage作为输出。使用它能够支持多模态、工具调用、参数控制、上下文对话。而
ChatMessage通常包含在包含文本的基础上,但一些 LLM 还支持其他模态,例如图像、音频等
官方表示,对 LanguageModel 的支持在 LangChain4j
中将不再扩展,因此在之后我演示所有的功能中,我们将使用
ChatModel
的API。而且LanguageModel只会在这篇中得到演示和简单的讲解。
ChatModel
现在,让我们更深入地看看 ChatModel 的相关
API。LanguageModel就不看了
ChatModel是同步阻塞式对话接口
,是一次性等待模型返回完整回答,而 ChatModel
接口的目标就是定义标准的、统一的大模型同步调用规范,屏蔽不同厂商 API
差异。它们是所有 LLM 接入的顶层规范
对于顶层入口
1 | default ChatResponse chat(ChatRequest chatRequest) |
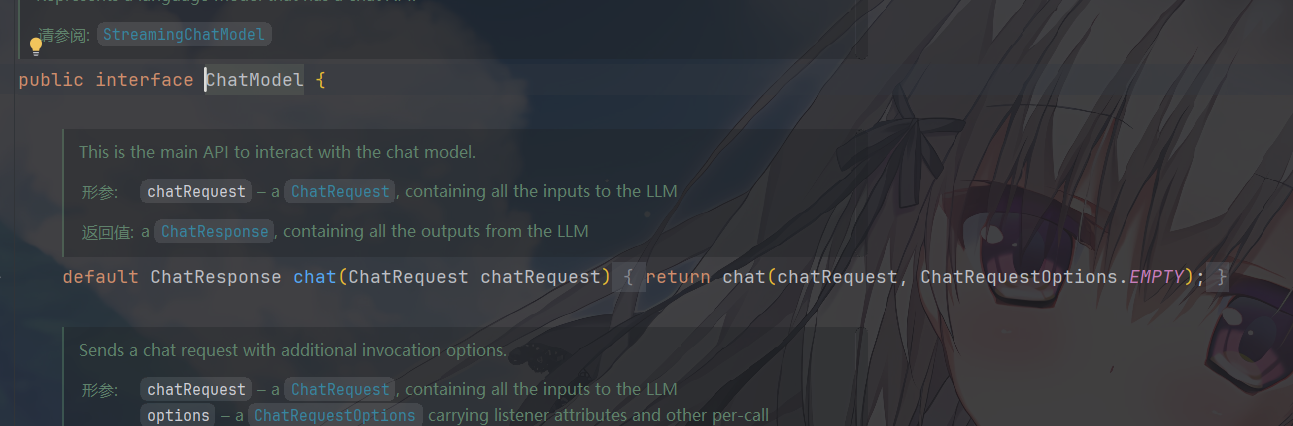
- 入参:
ChatRequest→ 包含消息列表、温度、最大 token 数等所有请求参数 - 出参:
ChatResponse→ 包含完整 AI 回答、元数据、工具调用结果等乱七八糟的内容
然后我们看到它实际上调用了一个这样的东西,它带上了一个选项
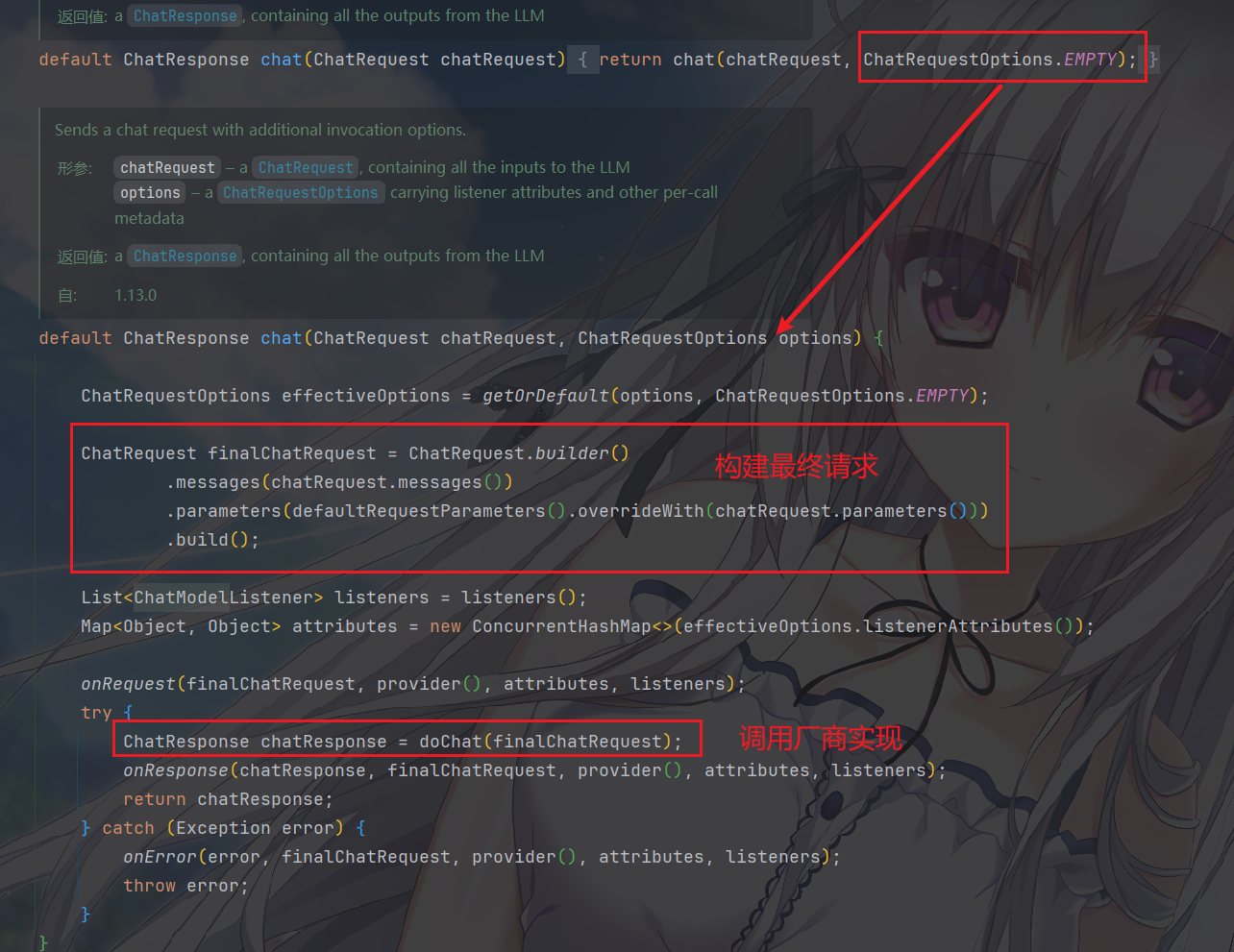
上述方法的一个事件监听链如下
1
2
3
4
5// 源码中的事件触发点
onRequest() → 请求发送前触发
doChat() → 实际调用模型 API
onResponse() → 成功响应后触发
onError() → 异常时触发这样,通用逻辑写在接口默认方法里,子类只需要实现
doChat()。这个钩子就是留给厂商实现的,模型商都要重写这个方法,调用自己的 HTTP 接口,它是真正与模型通信的地方。这样上层完全不用关心底层是哪家模型,引入依赖,注入需要的内容即可使用
这剩下的都是一些便捷工具方法和一些其他的能力支持
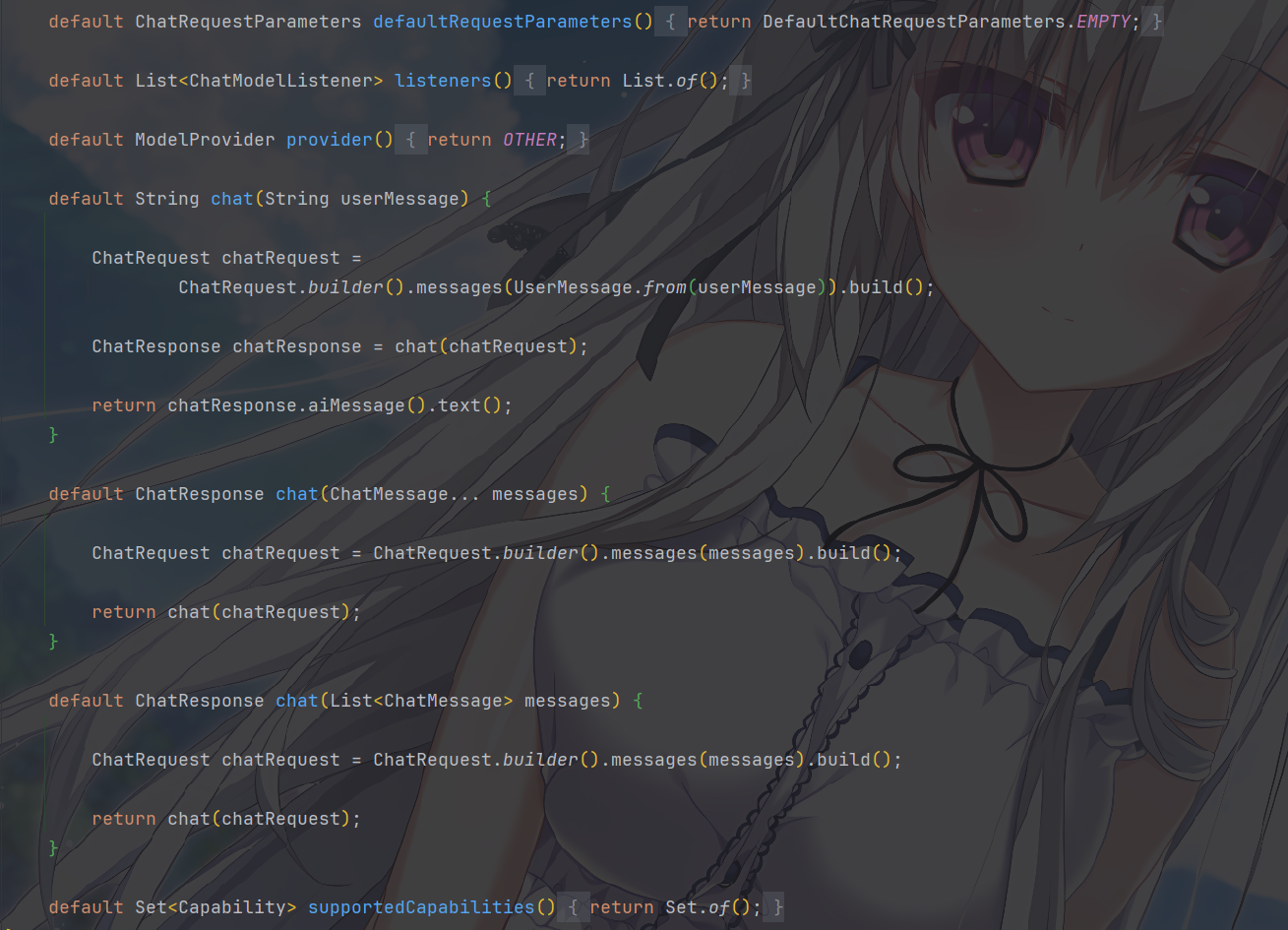
其中,提供了不用构建 ChatRequest 的快捷方法用起来非常舒服,一般我们都是用这个直接传字符串的方法,而且直接传消息数组 / 列表也是很常用的
1 | default String chat(String userMessage) { |
StreamingChatModel
因为 LLM 是逐个 token 生成文本的,因此许多 LLM 提供商提供了 流式传输响应 的方式,即逐个 token 地返回结果,而不是等待整个文本生成完成。
这样可以显著改善用户体验,因为用户不需要等待一个未知时长,几乎可以立即开始阅读响应。
对于 ChatModel 和 LanguageModel
接口,分别有对应的StreamingChatModel 和
StreamingLanguageModel 接口。
StreamingChatModel
接口的功能和ChatModel是类似的,只不过它是流式的,而且支持实时接收模型输出
我们看它的默认接口发现,没有返回值,用 Handler 回调
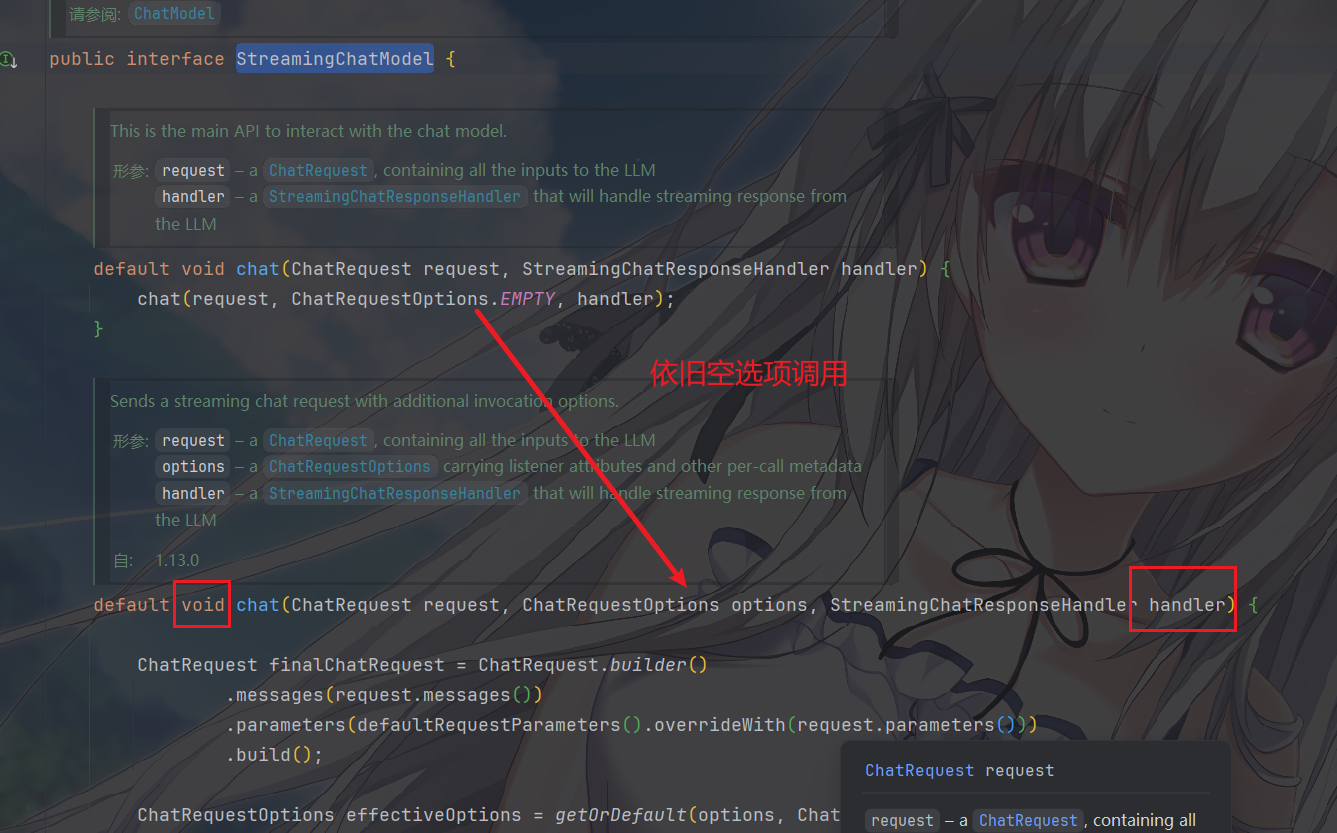
传入的这个 StreamingChatResponseHandler
处理器是模型实时回调用的
那么我们整理一下发现,StreamingChatModel
和ChatModel总体的接口结构基本是相同的,很类似,但返回值变成
void、多了 Handler 回调。
1 | public interface StreamingChatModel { |
那么,主要是 chat 方法,我们来看看这个方法里,是如何处理这个回调处理器的,然后去做的这个流式请求
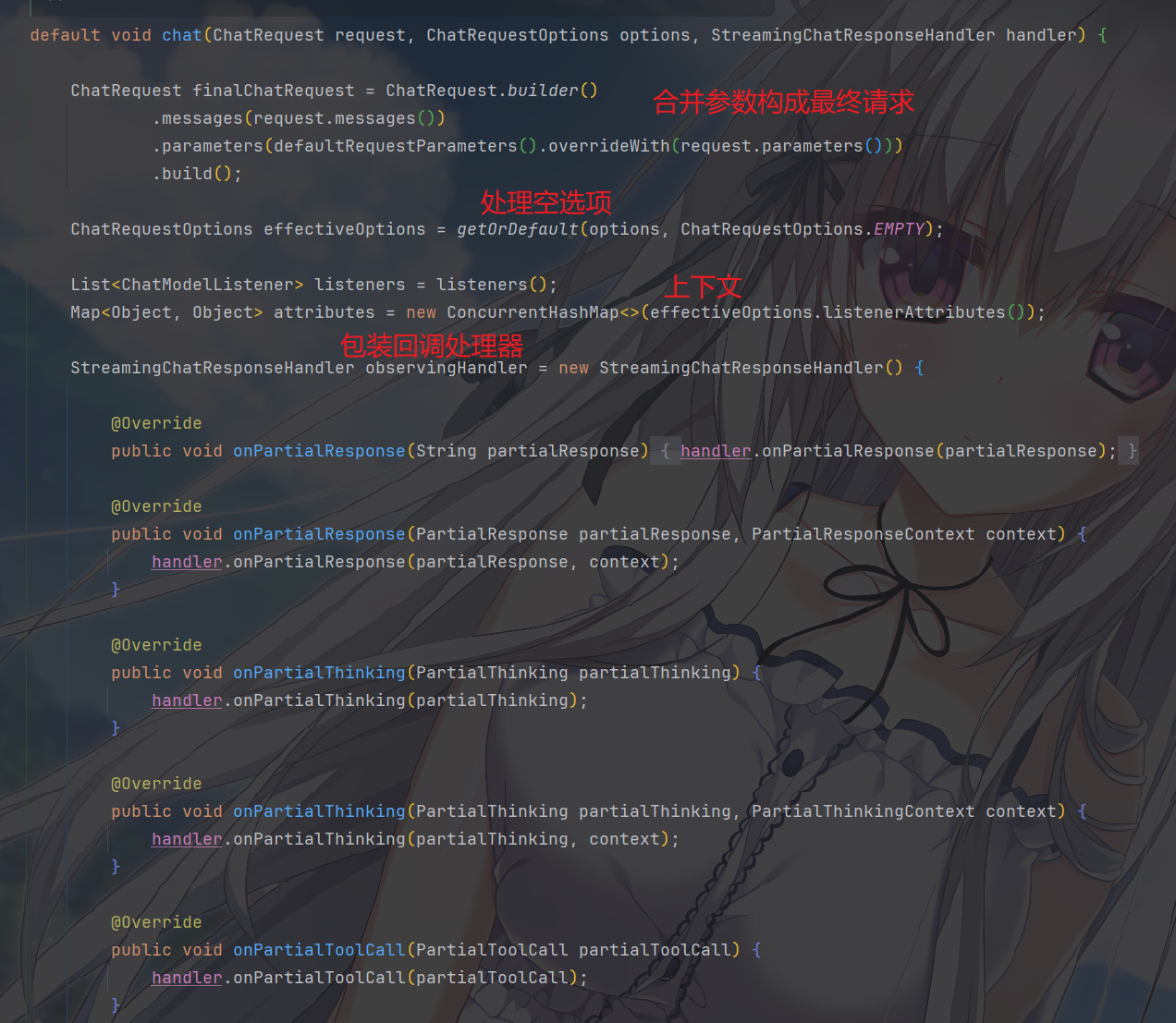
其中,StreamingChatResponseHandler observingHandler = new StreamingChatResponseHandler() {...}这部分对
StreamingChatResponseHandler进行了处理,可以发现,这部分创建一个了代理装饰
Handler,回调处理分为如下这些阶段
1 | StreamingChatResponseHandler observingHandler = new StreamingChatResponseHandler() { |
最后,才会调用厂商的流式实现,厂商必须实现这个doChat方法,推送实时流到
Handler,部分不支持的会报异常
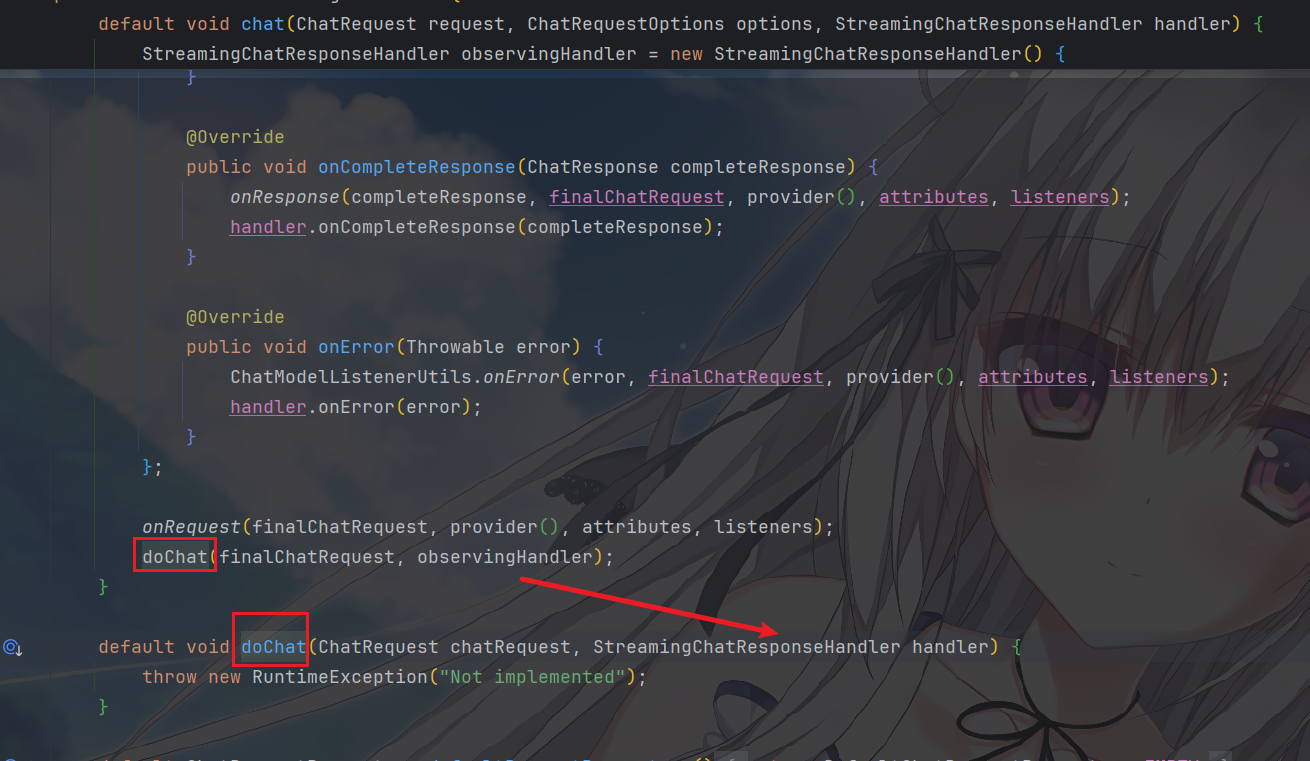
最后还是有几个便捷流式工具方法,和同步的使用起来没有区别
ChatMessage
目前有四种聊天消息类型,每种对应不同的消息来源
UserMessage:这是来自用户的消息。用户可以是应用程序的人类用户,也可以是你的应用程序本身。而根据 LLM 所支持的模态,UserMessage可以只包含文本(String),根据多模态的支持,可以包含其他模态内容,只不过咱们这个项目没用到1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 纯文本
UserMessage textMsg = UserMessage.from("今天的天气怎么样?");
// 多模态:文本 + 图像
UserMessage multimodalMsg = UserMessage.from(
TextContent.from("描述这张图片"),
ImageContent.from("https://example.com/cat.jpg")
);
// 支持的内容类型
// - TextContent: 文本
// - ImageContent: 图像(URL 或 Base64)
// - AudioContent: 音频
// - VideoContent: 视频
// - PdfFileContent: PDF 文件
// 等等AiMessage:这是 AI 生成的消息,通常是对UserMessage的回应,用于响应输入的消息。它可以包含:text():文本内容thinking():推理/思考内容toolExecutionRequests():执行工具的请求。attributes():额外属性,通常是提供商特定的
在我们的项目中这样使用到了
1
2
3
4
5
6
7
8
9// 同步调用
AiMessage aiMessage = chatModel.chat(memory.messages()).aiMessage();
memory.add(aiMessage); // 将 AI 回复存入记忆
// 流式调用——在 onCompleteResponse 中获取完整 AiMessage
public void onCompleteResponse(ChatResponse response) {
memory.add(response.aiMessage()); // 存入完整回复
}ToolExecutionResultMessage:这是ToolExecutionRequest的结果。这是 Function Calling(工具调用)流程中不可或缺的一环。当 AI 请求执行某个工具后,需要将执行结果以这种消息类型返回给 AI。1
UserMessage → AI 生成 ToolExecutionRequest → 执行工具 → ToolExecutionResultMessage → AI 生成最终回复
等到涉及到这部分的时候再细说
SystemMessage:这是系统发出的消息。通常由开发者定义其内容。一般你会在这里写明 LLM 在对话中的角色、它应如何表现、回答的风格等。LLM 被训练时会更加重视SystemMessage,因此要谨慎处理,不要让终端用户直接输入或注入SystemMessage造成提示词攻击。而且通常它位于对话的开头。例如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 基础用法
SystemMessage systemMsg = SystemMessage.from(
"你是一名资深影评人,回答需包含:\n" +
"1. 电影评分(IMDb/Rotten Tomatoes)\n" +
"2. 50字以内短评"
);
// 在你的 ChatService 中的实际用法
private ChatMemory getOrCreateMemory(String sessionId) {
return memoryMap.computeIfAbsent(sessionId, id -> {
ChatMemory memory = aiConfig.buildChatMemory(id);
// 每个新会话都注入系统提示,确保 AI 行为一致
memory.add(SystemMessage.from(SYSTEM_PROMPT));
return memory;
});
}SystemMessage存在如下行为- 一旦添加,总是被保留
- 一次只能持有一个
SystemMessage - 如果添加内容相同的新
SystemMessage,会被忽略 - 如果添加内容不同的新
SystemMessage,会替换之前的
CustomMessage:这是一种自定义消息,可以包含任意属性。仅当ChatModel实现支持时才能使用该消息类型(目前仅 Ollama 支持)。所以没啥好多说的
那么,在简要的介绍了上面的消息类型之后,其实我们虽然能大概知道有些消息需要区分,例如系统提示词,用户的消息,LLM的回复,这些肯定都不能一概而论,但是为什么呢
因为LLM本质上是无状态的,而 LangChain4j 中每次调用虽然有记忆管理,但是我们都认为都是独立的。为了让 AI 理解对话上下文、遵循特定行为规范,我们需要通过不同类型的消息来传递不同来源、不同作用的信息。
而且很明显,当你调用 chatModel.chat(messages)
时,返回的不是简单的字符串,而是一个 ChatResponse 对象
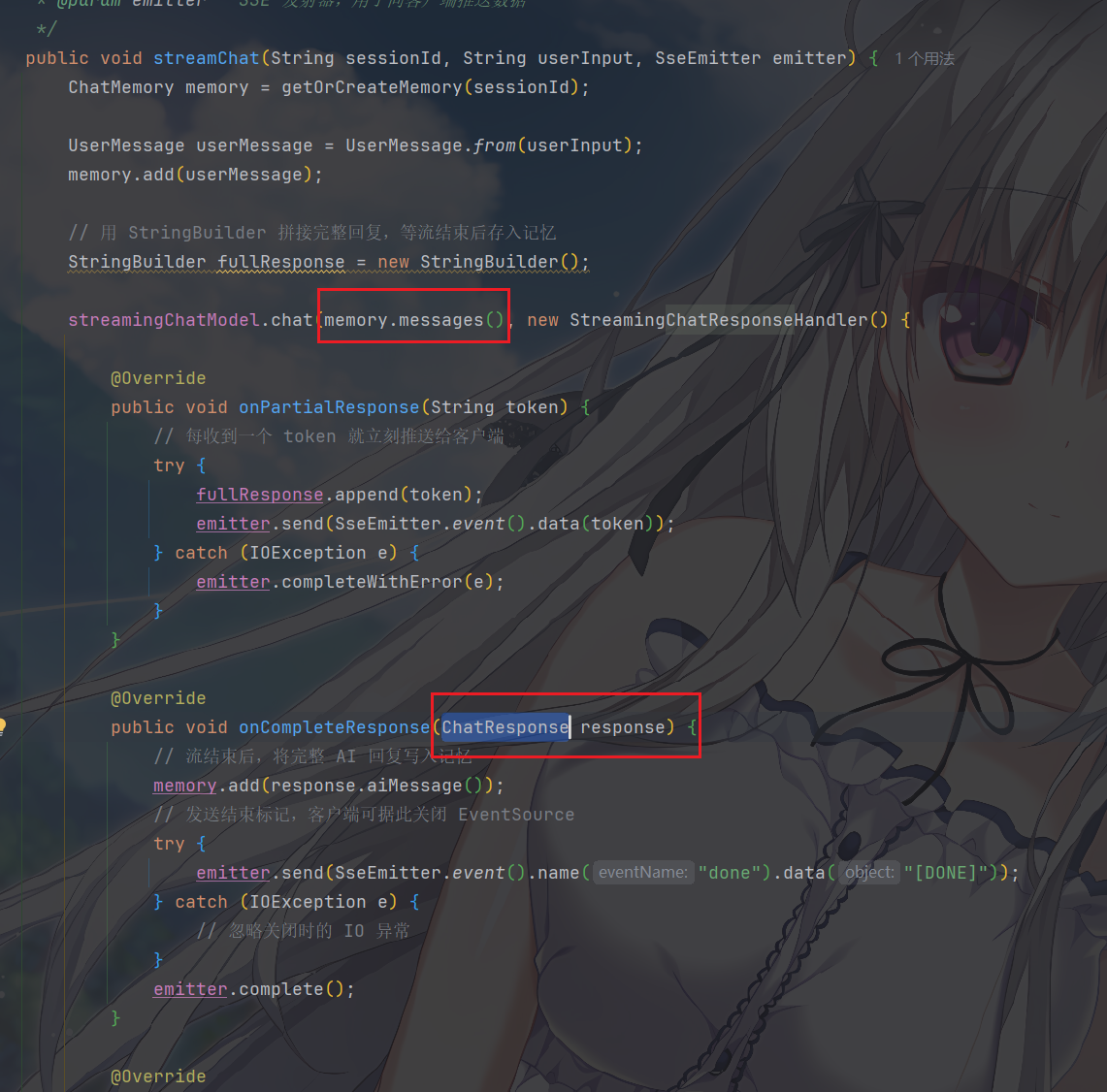
emmm,这个例子不是很直观,不如在一个更简单的场景下,我们可以在
chat 方法中提供一个 UserMessage 实例。这与
chat(String) 方法类似。主要区别在于它返回的不是
String,而是一个 ChatResponse。
1 | ChatResponse response = chatModel.chat(userMessage); |
而除了 AiMessage,ChatResponse 还包含
ChatResponseMetadata。它包含一系列元数据
TokenUsage这个对象就很有用,因为我们能使用它计算成本
inputTokenCount:输入消耗的 token 数(所有传入的 ChatMessage)outputTokenCount:输出生成的 token 数totalTokenCount:总计
1 | // 计算成本示例 |
那么,上述我们分析 ChatModel 的时候发现了一个快捷方法可以传入一个字符串数组,那么同样,多个 ChatMessage 作为输入而不是只提供一个的时候也很常见
这是因为 LLM 本质上是无状态的,它们不会维护对话的上下文状态。因此,如果你想支持多轮对话,就需要自己维护对话的状态。
而一般情况下,我们维护多轮对话之间的状态使用的都是 LangChain4j
的模型记忆的相关内容,主要就是ChatMemory,而在上文我们使用的时候也能清楚的感受到多轮对话中上下文连贯的重要性,这也就是为什么需要
ChatMemory,它自动帮你管理这些消息列表,你只需调用
memory.add() 和 memory.messages()就行了。
整个流程简单来讲就是
- 初始化时注入
SystemMessage - 将用户消息加入
ChatMemory - 传入完整
messages()列表 - 将 AI 回复加入记忆
LangChain4j 的模型记忆
自动记忆管理
上面提到了 LLM
本质上是无状态的,它们不会维护对话的上下文状态。因此,如果你想支持多轮对话,就需要自己维护对话的状态。而手动维护和管理
ChatMessage 是一件很麻烦的事。因此,LangChain4j 提供了
ChatMemory 抽象以及多个开箱即用的实现。
ChatMemory 可以作为独立的低级组件使用,也可以作为像 AI
服务这样的高级组件的一部分。
ChatMemory 作为 多个ChatMessage的容器(由
List 支持),并附带了以下附加功能:
- 淘汰策略
- 持久化
- 对
SystemMessage的特殊处理 - 对 工具(tool) 消息的特殊处理
但是请注意,请注意,“记忆”和“历史”是相似但又不同的概念。
- 历史保留了用户和 AI 之间所有完整的消息。历史是用户在 UI 中看到的内容,它能代表用户与 AI 交互过程中,实际说过的所有话,发送和接受的所有多模态消息。
- 记忆保留了部分信息,这些信息被呈现给大型语言模型(LLM),使其表现得像“记住”了对话一样。
因此记忆与历史大相径庭。根据所使用的记忆管理的算法,它可以以各种方式去修改记忆以实现一些目标,例如:淘汰一些消息、总结多条消息、总结独立消息、删除消息中不重要的细节、向消息中注入额外信息(例如,用于 RAG)或指令(例如,用于结构化输出)等等。
LangChain4j 目前只提供“记忆”,不提供“历史”。如果需要保留完整的历史,需要手动实现
而 ChatMemory 的自动管理记忆其实很简单,差不多只需要这样
1 | // 你只需要做这些 |
在上面我们提到 LLM 的无状态的时候,我们的项目中,我们了这样进行的处理,来保证上下文有记忆,对话连贯且和谐,这样的管理在使用 ChatMemory 的基础上,维护了多轮对话的状态
1 | public String chat(String sessionId, String userInput) { |
而我们使用 ChatMemory 作为消息容器,每个 sessionId
对应一个独立的 ChatMemory 对象,ChatMemory
内部维护了一个
List<ChatMessage>,按时间顺序存储所有消息
1 | private final ConcurrentHashMap<String, ChatMemory> memoryMap = new ConcurrentHashMap<>(); |
那么,用代码来展开展示整个自动消息管理的完整流程,差不多就是这样的
1 | // 第一次对话 |
持久化
根据上面,很明显,我们使用了一个ConcurrentHashMap来在本地缓存了记忆,这其实很不好,比较明显的一个就是应用重启后,所有对话历史丢失
而默认情况下,ChatMemory 的实现也是将
那一系列的ChatMessage存储在内存中。如果需要持久化,可以实现一个自定义的
ChatMemoryStore,将多条
ChatMessage存储在你选择的任何持久化存储中
1 | class PersistentChatMemoryStore implements ChatMemoryStore { |
updateMessages()方法在每次向ChatMemory添加新的ChatMessage时都会被调用。这通常在每次与 LLM 交互期间发生两次:一次是在添加新的
UserMessage时,另一次是在添加新的AiMessage时。这是什么意思,差不多就是代码这种
1
2
3
4
5
6
7
8
9
10
11
12
13// 在 ChatMemory 内部,每次 add() 都会触发 updateMessages
memory.add(userMessage); // ← 触发 updateMessages
memory.add(aiMessage); // ← 再次触发 updateMessages
public String chat(String sessionId, String userInput) {
ChatMemory memory = getOrCreateMemory(sessionId);
memory.add(userMessage); // 自动保存到数据库/Redis
AiMessage aiMessage = chatModel.chat(memory.messages()).aiMessage();
memory.add(aiMessage); // 自动保存到数据库/Redis
return aiMessage.text();
}而
updateMessages()方法应更新与给定记忆 ID 关联的所有消息。多条ChatMessage可以单独存储(例如,每条消息一个记录/行/对象)或一起存储(例如,整个ChatMemory一个记录/行/对象)。也就是说,在持久化的时候可以根据需要,整个 ChatMemory 存储为一个记录
1
2
3
4
5
6
7
8
9
10// Redis 中的存储结构
Key: "chat:memory:user-123"
Value: "[{\"type\":\"SystemMessage\",\"text\":\"你是AI助手\"},{\"type\":\"UserMessage\",\"text\":\"我叫张三\"},{\"type\":\"AiMessage\",\"text\":\"你好张三\"}]"
// 数据库中的存储
TABLE chat_memory (
session_id VARCHAR(100) PRIMARY KEY, -- "user-123"
messages_json TEXT, -- 完整的 JSON 数组
updated_at TIMESTAMP
)此时的
updateMessages()实现就变成了这样1
2
3
4
5
6
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// 一次性存储整个消息列表
String json = messagesToJson(messages); // 整个列表序列化
saveToDatabase(memoryId, json); // 覆盖写入
}你也可以把 ChatMemory 中的每条对话消息都拆开然后单独存储,这种情况是更多见的,因为这样易于管理记忆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Redis 中的存储结构(使用 List 结构)
Key: "chat:memory:user-123:messages" (List类型)
Value: [
"{\"type\":\"SystemMessage\",\"text\":\"你是AI助手\"}",
"{\"type\":\"UserMessage\",\"text\":\"我叫张三\"}",
"{\"type\":\"AiMessage\",\"text\":\"你好张三\"}"
]
// 数据库中的存储
TABLE chat_messages (
id BIGINT PRIMARY KEY,
session_id VARCHAR(100), -- "user-123"
message_index INT, -- 0, 1, 2...
message_type VARCHAR(50), -- "SystemMessage", "UserMessage"...
message_json TEXT, -- 单条消息的 JSON
created_at TIMESTAMP
)此时的
updateMessages()实现就变成了这样1
2
3
4
5
6
7
8
9
10
11
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// 1. 删除该会话的所有旧消息
deleteAllMessagesForSession(memoryId);
// 2. 逐条插入新消息
for (int i = 0; i < messages.size(); i++) {
String singleMessageJson = messageToJson(messages.get(i));
insertMessage(memoryId, i, singleMessageJson);
}
}而
getMessages()方法在 ChatMemory 的用户请求所有消息时被调用。这通常在每次与 LLM 交互期间发生一次。Object memoryId参数的值与创建ChatMemory时指定的 id 对应,可用于区分多个用户和/或对话。getMessages()方法应返回与给定记忆 ID 关联的所有消息这段是什么意思呢,也就是说,在你的 ChatService 中,你每次调用
memory.messages()或者类似的代码时都会触发getMessages(),也就是说,每次需要拿出记忆的时候,ChatMemory都会从 Store 中重新加载所有消息,把该用户的全部历史对话拿出来,一起发给大模型。而
memoryId就是sessionId,它的作用就是让系统知道,现在要取的是 哪轮对话 的记忆,因为并发的特征在 AI 应用处处存在,同时有几百几千个对话在进行很正常,必须靠 id 区分。而通常情况下你给我一个memoryId,就返回这轮对话的所有记忆deleteMessages()方法在调用ChatMemory.clear()时被调用。如果不使用,可以空实现。这个很明显,你就给clear()当成 清空当前对话的记忆即可
记忆的淘汰
上面很明显,我们在看记忆管理的时候,我们知道了,每次调用 LLM,会把记忆中的全部对话全发过去,如果不管理,很快就会出现问题
记忆的管理涉及到的内容很多,但是最重要的部分肯定就是记忆的淘汰,因为 LLM 的记忆(上下文大小)肯定是有限的,我们必须舍弃掉作用不大的记忆,来避免上下文膨胀带来的 Token 额外消耗和回答质量变低的问题,而且过长的上下文会大大增加 LLM 回答的延迟,但是很多时候,deleteMessages 被调用也不是一个很好的选择。
而且 LLM 一次可以处理的令牌(tokens)数量是有限制的。在某些时候,对话可能会超过这个限制。在这种情况下,需要淘汰一些消息。通常,最旧的消息会被淘汰,但如果需要,也可以实现更复杂的算法。
目前,LangChain4j
提供了两种开箱即用的实现,具体来说都是ChatMemory,两者都是
FIFO 的滑动窗口
MessageWindowChatMemory:按对话条数算的滑动窗口,设定一个最大消息数 N,只保留最近 N 条,超过就删掉最旧的一条1
2
3ChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(10) // 保留最近10条
.build();TokenWindowChatMemory:按Token数算的滑动窗口,设定 最大 token 数 M,计算每条消息的 token 数,从最新消息往前累加,直到接近 M,旧消息整条淘汰(消息不可分割,不能切一半,切一半没有意义)它需要一个组件
TokenCountEstimator来用来计算每条消息有多少 token,不同模型分词不同,各有自己的 tokenizer1
2
3
4
5
6Tokenizer tokenizer = new OpenAiTokenizer("gpt-3.5-turbo");
ChatMemory memory = TokenWindowChatMemory.builder()
.maxTokens(2000) // 保留最近2000 token
.tokenCountEstimator(tokenizer)
.build();
一般情况下,尤其是多模态的情况下,我们使用
TokenWindowChatMemory,因为它更精准
改造我们项目的代码
1 | // 初始化 |
LangChain4j 的多模态对话
上述我们在讲到 ChatMessage 的时候就知道,UserMessage
不仅可以包含文本,还可以包含其他类型的内容。
因为,UserMessage 包含一个
List<Content> contents,最普通的通常情况下,会注入文本类型的消息
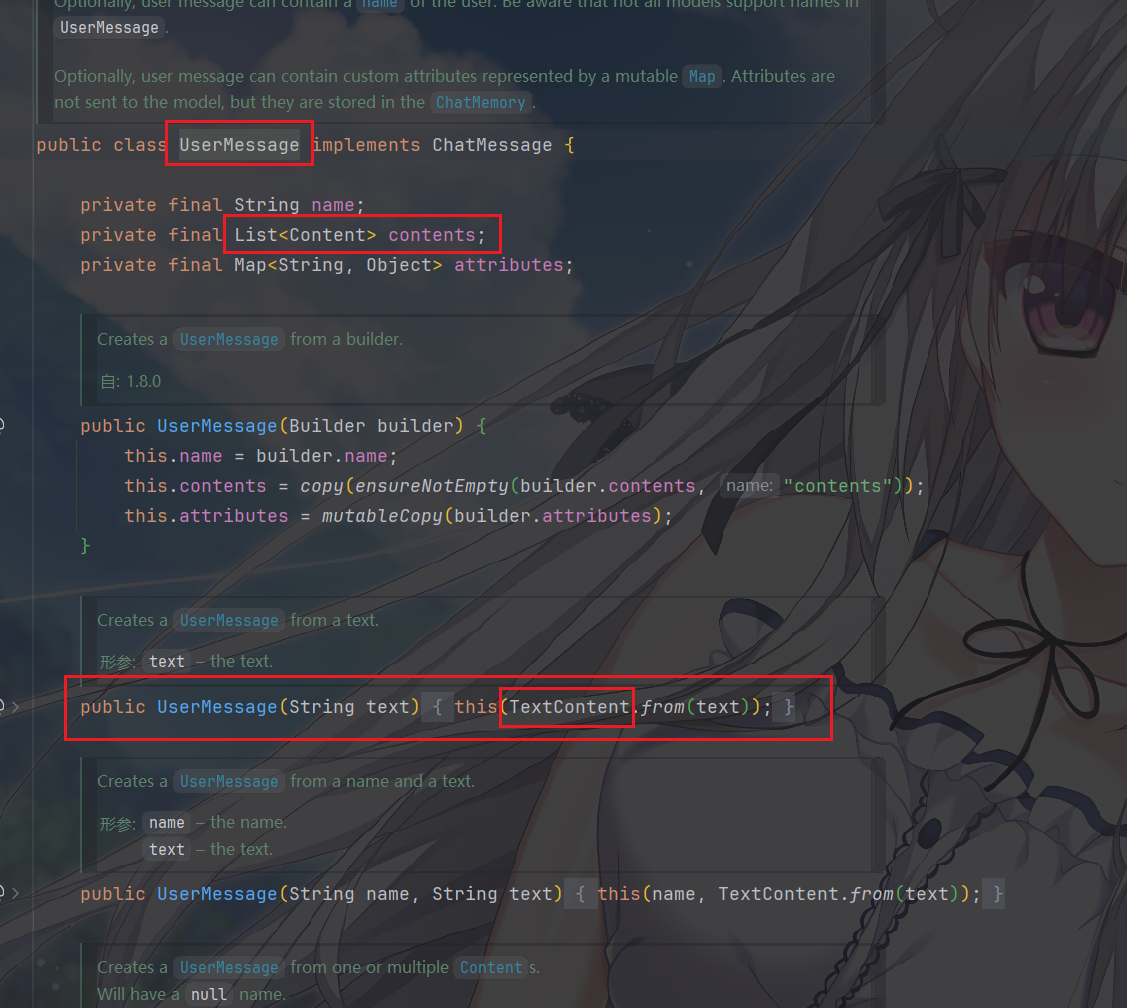
但是这个 Content 也是一个接口,具有以下实现:
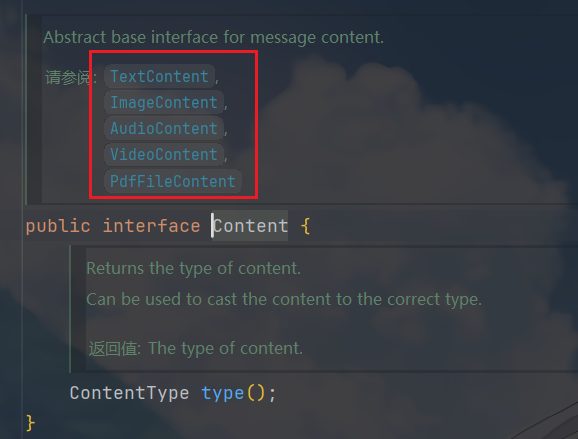
可以在 这里 的对比表中查看哪些 LLM 提供商支持哪些模态。目前 LangChain4j 支持的模态就这些。当然只要你的模型能够解析,你完全可以自己定义一个类型的 Content 然后注入去使用它
以下是我们项目中一个同时发送文本和图像给 LLM 的示例:
1 | if (imageUrl != null && !imageUrl.isBlank()) { |
文本内容(TextContent)
TextContent 是最简单最基础的 Content
形式,表示纯文本并包装一个 String作为一个消息的内容。
很明显,UserMessage.from(TextContent.from("Hello!"))
等价于 UserMessage.from("Hello!")。因为
1 | // 形式1:显式使用 TextContent(你的做法) |
而且,可以在 UserMessage 中提供一个或多个
TextContent:
1 | UserMessage userMessage = UserMessage.from( |
图像内容(ImageContent)/ 音频内容(AudioContent)/ 视频内容(VideoContent)/ PDF 文件内容(PDFFileContent)
他们都属于一类,你去查看他们的代码,会发现它们的代码几乎一致,所以我说完全可以自己定义各种文件类型,只要你接入的 AI 能够解析它们
以图像内容(ImageContent)为例子,ImageContent 有三种创建方式
通过 URL
1
2
3
4
5
6ImageContent.from(imageUrl)
// 等价于
ImageContent.builder()
.url(imageUrl)
.build()通过 Base64 本地文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public ImageContent loadLocalImage(String filePath) {
// 读取本地图片
byte[] imageBytes = Files.readAllBytes(Paths.get(filePath));
// Base64 编码
String base64Data = Base64.getEncoder().encodeToString(imageBytes);
// 创建 ImageContent(需要指定 MIME 类型)
return ImageContent.from(base64Data, "image/jpeg");
}
// 这种情况需要在你的服务中添加本地图片的支持
public void streamMultiModalChatWithLocalImage(
String sessionId,
String userInput,
MultipartFile imageFile, // 前端上传的图片
SseEmitter emitter
) throws IOException {
byte[] imageBytes = imageFile.getBytes();
String base64Data = Base64.getEncoder().encodeToString(imageBytes);
ImageContent imageContent = ImageContent.from(
base64Data,
imageFile.getContentType() // "image/jpeg", "image/png" 等
);
UserMessage userMessage = UserMessage.from(
TextContent.from(userInput),
imageContent
);
// ... 后续处理
}通过 Builder 完整配置,没啥人用,除非专用生图工作流
1
2
3
4
5
6// 完整配置示例
ImageContent imageContent = ImageContent.builder()
.url("https://example.com/photo.jpg")
.mimeType("image/jpeg")
.detailLevel(DetailLevel.HIGH)
.build();官方文档提到的
DetailLevel是控制模型如何处理图像的重要参数:1
2
3
4
5public enum DetailLevel {
LOW, // 低细节
HIGH, // 高细节
AUTO // 自动
}
多模态与 ChatMemory 的集成同样很重要,我们一视同仁,多模态消息也被存入 ChatMemory,这意味着 ChatMemory 内部存储了完整的 Content 列表,后续对话中,AI 也能记住之前发送过的多模态内容,只不过注意 Memory 膨胀






