
Spring Boot 原理
介绍一下 Spring Boot 整体的启动流程?
Spring Boot 启动流程的核心是通过自动配置和上下文初始化,将零散的组件装配成一个可运行的应用上下文(ApplicationContext),整体分为 前置准备、上下文初始化、核心刷新、启动收尾 四大步
首先从 main 找到
SpringApplication.run(主类.class, args)方法,在执行run()方法之前先 new 一个SpringApplication实例对象。实例化时做的具体核心内容:
然后进行应用类型推断,判断当前应用是 Servlet 应用(Spring Web MVC)、Reactive 应用(Spring WebFlux)还是普通非 Web 应用。
紧接着进行初始化器加载,从
META-INF/spring.factories中加载所有ApplicationContextInitializer的实现类,用于在上下文刷新前进行自定义配置,包括 Spring Boot 配置的默认实现和开发者添加的自定义实现。接着加载所有实现
ApplicationListener的类,监听启动过程中的应用生命周期事件进入
SpringApplication.run()后启动事件监听机制,创建SpringApplicationRunListeners对象,它是所有监听器的 总调度器,发布ApplicationStartingEvent事件,通知所有监听器“应用要开始启动了”。监听器可以做一些前置工作推断出主启动类
所以说这一步是启动前的资源预先加载的步骤
然后进入
run()方法,创建应用监听器SpringApplicationRunListeners开始监听然后加载 Spring Boot 配置环境
ConfigurableEnviroment,把配置环境Enviroment加入监听对象中这一步是环境准备,为整个应用提供配置来源,是配置中心初始化,把所有外部配置统一抽象成 Environment,供后续上下文和 Bean 使用。
然后进行上下文初始化,创建应用上下文
ConfigurableApplicationContext,当作 run 方法的返回对象。这里会根据推断的应用类型,创建对应类型的上下文,然后调用所有加载的
Initializer对上下文进行定制化配置,通知所有监听器应用开始启动。这一步是容器的空壳创建,只完成了基础结构搭建,还没开始加载 Bean。最后创建 Spring 容器,调用
refreshContext(context)进行容器上下文刷新,实现 starter 自动化配置和 Bean 加载和实例化,发布ApplicationReadyEvent通知应用就绪。
Spring Boot 只是在 Spring refresh()
之前加了自动配置、环境准备、内嵌容器等封装,核心容器逻辑还是
Spring 原生的。
Spring Boot 和 Spring 有什么区别?讲解一下 Spring Boot 的核心优势?为什么要用 Spring Boot?
Spring Boot 是基于 Spring 框架的快速开发脚手架,核心是 “约定大于配置”,解决了 Spring 框架配置繁琐、依赖管理复杂的问题。
而 Spring 是一套完整的企业级开发框架,核心是 IOC(控制反转)和 AOP(面向切面编程),提供基础的核心能力,但需要大量手动配置。
简单说:Spring 是 基础能力库,Spring Boot 是 基于 Spring 的高效的开发脚手架。
核心特点如下
约定大于配置
Spring Boot 内置了大量默认配置,而且无需手动编写 XML 配置即可启动,而且使用注解就可以进行配置,比如开发一个 Web 项目,只需引入
spring-boot-starter-web依赖,就会自动配置一系列框架起步依赖 Starter
将常用的依赖组合打包成 Starter,面对一个开发场景,直接引入 starter 就可以包含一系列的开发依赖
自动配置并且简化配置
基于条件注解
@Conditional等,根据类路径下的依赖、配置文件等自动创建 Bean而且不用各种复杂的 XML 配置,使用配置文件加上注解,可以让配置很轻松,把更多精力放在业务逻辑开发上
内嵌服务器
内置 Tomcat、Jetty、Undertow 等 Web 服务器,无需手动部署 WAR 包到外部服务器。项目可直接打成 JAR 包,通过
java -jar启动,部署、测试、运维更简单;简化监控与运维
总之,使用 Spring Boot,相比传统的Spring MVC,开发效率提升非常明显。
什么是自动装配?Spring Boot自动装配原理是什么?
Spring Boot 的自动装配原理是基于 Spring Framework
的条件化配置和@EnableAutoConfiguration注解实现的。
自动装配就是通过注解或一些简单的配置就可以在 Spring Boot 的帮助下很方便的开启和配置各种功能,比如数据库访问、Web开发。
这种机制允许开发者在项目中引入相关的依赖,Spring Boot 将根据这些依赖自动配置应用程序的上下文和功能。
Spring Boot 定义了一套接口规范,这套规范规定:
- Spring Boot 在启动时会扫描外部引用 jar
包中的自动配置元数据文件(Spring Boot 2.7 以前是
META-INF/spring.factories,2.7 及以后是META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports),将文件中配置的类型信息加载到 Spring 容器,并执行类中定义的各种操作。对于外部 jar 来说,只需要按照 Spring Boot 定义的标准,就能将自己的功能装进 Spring Boot。
对于 Spring Boot 自动装配的原理
@SpringBootApplication注解的内部有个@EnableAutoConfiguration, 这个注解是实现自动装配的核心注解,其中这个注解的内容如下@AutoConfigurationPackage,将项目 src 中 main 包下的所有组件注册到容器中,例如标注了 Component 注解的类等@Import({AutoConfigurationImportSelector.class}),是自动装配的核心AutoConfigurationImportSelector是 Spring Boot 中一个重要的类,它实现了ImportSelector接口,用于实现自动配置的选择和导入。具体来说,它通过分析项目的类路径,然后进行条件判断,来决定应该导入哪些自动配置类。
从启动和源码来看整个流程:
- 起点:
@SpringBootApplication。它是一个组合注解,包含了@EnableAutoConfiguration、@ComponentScan和@SpringBootConfiguration。- 核心入口:
@EnableAutoConfiguration。它通过@Import导入AutoConfigurationImportSelector。- 执行决策:
AutoConfigurationImportSelector.selectImports()。这个方法内部会调用getAutoConfigurationEntry()来完成自动配置类列表的最终确定。- 加载候选:
SpringFactoriesLoader。getCandidateConfigurations()方法使用SpringFactoriesLoader加载META-INF/spring.factories文件中org.springframework.boot.autoconfigure.EnableAutoConfiguration键对应的所有配置类名。- 过滤与生效。对这些候选类进行排除和条件过滤,最终返回符合条件的配置类全限定名数组,由Spring容器加载。
拦截器和过滤器的区别?各自的使用场景和执行时机?结合 Spring 框架聊聊
过滤器属于 Servlet 规范,工作在 Web 容器层面,主要处理字符编码、请求日志、跨域等底层 Web 层面的通用逻辑。
拦截器是 Spring MVC 的组件,运行在 Spring 容器内部,在 Controller 方法执行前后进行拦截。
过滤器的生命周期遵循 Servlet
规范的标准流程,过滤器只能访问ServletRequest和ServletResponse这些原始的
Servlet 对象,它看不到 Spring 的上下文,也无法进行依赖注入。
拦截器是Spring
MVC框架的组件,所以它运行在Spring容器内部,不仅可以访问
HttpServletRequest
和HttpServletResponse,还能通过@Autowired注入任何
Spring 管理的 Bean,甚至可以获取到即将执行的 Controller 方法信息。
在实际开发中有一个简单的判断原则
- 如果这个功能需要访问 Spring 容器中的 Bean,或者需要处理业务逻辑,就选择拦截器;
- 如果只是对HTTP请求响应做一些通用的预处理,就用过滤器。
例如,过滤器的经典应用场景包括字符编码处理,这是最基础但也最重要的场景。在处理中文参数时,会用过滤器统一设置字符编码,确保所有请求都能正确处理中文字符。CORS跨域处理也是过滤器的典型应用,前后端分离的项目中,经常用过滤器来处理跨域问题,因为跨域本质上是HTTP协议层面的限制,用过滤器处理最合适。
而拦截器的应用场景要突出它与业务逻辑的紧密结合。用户权限校验是最常见的场景,需要调用UserService来验证token,还要根据用户角色判断是否有访问特定接口的权限。
Spring Boot 框架知识
Spring IoC 和 AOP 介绍一下?IoC和AOP是通过什么机制来实现的?
IoC:控制反转,它是一种创建和获取对象的技术思想,依赖注入 DI 是实现这种技术的一种方式。
传统开发过程中,我们需要通过 new 关键字来创建对象。使用 IoC 思想开发方式的话,我们不通过 new 关键字创建对象,而是通过 IoC 容器来帮我们实例化对象,把创建对象和对象之间的依赖管理的权利从自己身上交给了 Spring 容器,这就是控制反转的含义。 通过 IoC 的方式,可以大大降低对象之间的耦合度。
AOP:是面向切面编程,能够将那些与业务无关,却为业务模块所共同调用的逻辑封装起来,以减少系统的重复代码,降低模块间的耦合度。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理。
在 Spring 框架中,IOC 和 AOP 结合使用,可以更好地实现代码的模块化和分层管理。例如:
- 通过 IOC 容器管理对象的依赖关系,然后通过 AOP 将横切关注点统一切入到需要的业务逻辑中。
- 使用 IOC 容器管理 Service 层和 DAO 层的依赖关系,然后通过 AOP 在 Service 层实现事务管理、日志记录等横切功能,使得业务逻辑更加清晰和可维护
Spring IoC 实现机制
- 反射:Spring IoC 容器利用 Java 的反射机制动态地加载类、创建对象实例及调用对象方法,反射允许在运行时检查类、方法、属性等信息,从而实现灵活的对象实例化和管理。
- 依赖注入:IoC 的核心概念是依赖注入,即容器负责管理应用程序组件之间的依赖关系。Spring 通过构造函数注入、属性注入或方法注入,将组件之间的依赖关系描述在配置文件中或使用注解。
- 设计模式 - 工厂模式:Spring IoC 容器通常采用工厂模式来管理对象的创建和生命周期。容器作为工厂负责实例化Bean 并管理它们的生命周期,将 Bean 的实例化过程交给容器来管理。
- 容器实现:Spring IoC 容器是实现 IoC
的核心,通常使用
BeanFactory或ApplicationContext来管理 Bean。BeanFactory是 IoC 容器的基本形式,提供基本的IoC功能;ApplicationContext是BeanFactory的扩展,并提供更多企业级功能。
Spring AOP 实现机制
Spring AOP的实现依赖于动态代理技术。
动态代理是在运行时动态生成代理对象,而不是在编译时,从而实现在不修改源码的情况下增强方法的功能。
Spring AOP支持两种动态代理:
- 基于JDK的动态代理:使用
java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口实现。这种方式需要代理的类实现一个或多个接口。 - 基于CGLIB的动态代理:当被代理的类没有实现接口时,Spring 会使用 CGLIB 库生成一个被代理类的子类作为代理。CGLIB(Code Generation Library)是一个第三方代码生成库,通过继承方式实现代理。
什么是依赖注入?DI 的实现方式有哪些?
传统编程中,对象直接使用 new 关键字创建依赖,这种硬编码方式让代码紧耦合,而 Spring 通过 DI 实现了 IoC 的设计思想,把对象创建和依赖管理的控制权从业务代码转移给外部容器。这样,业务代码只需要声明需要什么依赖,不用关心如何获取。
依赖注入(DI)其实是一种设计模式,通过外部容器向对象提供其所需的依赖对象,而不是对象内部主动创建依赖。
Spring IoC 容器启动时会扫描指定包路径,通过反射机制识别带有
@Component等注解的类,将它们实例化为 Bean 并存储在容器中。当某个 Bean 需要依赖时,容器会根据类型或名称自动匹配并注入相应的 Bean 实例。
DI的实现方式主要有三种
- 构造器注入:通过构造函数参数传入依赖
- 属性注入:通过 setter 方法或直接字段赋值
- 接口注入:通过实现特定接口来接收依赖
Spring 的态度是不支持接口注入,因为侵入性太强,违背 “面向接口编程” 的初衷,Spring 的 DI 实现仅覆盖构造器注入和设值注入。
在实际开发中,构造器注入因为能保证依赖的不可变性和完整性,被认为是最佳实践。
Spring框架作为DI容器的典型实现,通过 IoC 容器管理对象的生命周期和依赖关系。
你可以使用@Autowired注解实现自动装配,@Component、@Service、@Repository等注解标记组件让Spring管理。
当遇到循环依赖问题时,Spring 通过三级缓存机制解决单例Bean的循环依赖问题。简单来说,Spring 在 Bean 实例化和初始化过程中,会提前暴露正在创建的 Bean 引用,让其他依赖它的 Bean 能够获取到这个引用,从而打破循环依赖的死锁。不过要注意,构造器循环依赖 Spring 无法解决,这也是推荐使用构造器注入时需要注意的设计问题。
怎么理解SpringBoot中的约定大于配置
约定大于配置是 Spring Boot 的特点,通过预设合理的默认行为和项目规范,大幅减少开发者需要手动配置的步骤,从而提升开发效率和项目标准化程度。可以从以下几个方面来解释:
自动化配置:Spring Boot 提供了大量的自动化配置,通过分析项目的依赖和环境,自动配置应用程序的行为。开发者无需显式地配置每个细节,大部分常用的配置都已经预设好了。
例如,引入
spring-boot-starter-web后,Spring Boot 会自动配置内嵌 Tomcat 和 Spring MVC,无需像 Spring 那样还需要手动编写XML中的很多配置才能启动。默认配置:Spring Boot 为诸多方面提供大量默认配置,如连接数据库、设置 Web 服务器、处理日志等。开发人员无需手动配置这些常见内容,框架已做好基本的决策。
约定的项目结构:Spring Boot 提倡特定的项目结构,通常主应用程序类(含 main 方法)置于根包,控制器类、服务类、数据访问类等分别放在相应子包。此约定使团队成员更易理解项目结构与组织,规范项目开发,新成员加入项目时能快速定位各功能代码位置,提升协作效率。
Spring Boot 用到了哪些经典的设计模式?
- 代理模式:Spring 的 AOP 通过动态代理实现方法级别的切面增强。
- 策略模式:Spring AOP 支持 JDK 和 Cglib 两种动态代理实现方式,通过策略接口和不同策略类,运行时动态选择,其创建一般通过工厂方法实现。
- 观察者模式:Spring 观察者模式包含 Event
事件、Listener 监听者、Publisher
发送者,通过定义事件、监听器和发送者实现,观察者注册在
ApplicationContext中,消息发送由ApplicationEventMulticaster完成。 - 单例模式:Spring Bean 默认是单例模式,通过单例注册表实现
- 工厂方法模式:Spring 中的 FactoryBean 体现工厂方法模式,为不同产品提供不同工厂。
Spring Boot 框架相关注解
@Aspect注解的使用?如何定义切面和通知?结合
Spring 框架聊聊
@Aspect注解是 Spring AOP
中定义切面类的核心注解,需要配合@Component注册为
Bean。一个标准的切面类需要同时使用@Aspect和@Component两个注解
Spring AOP 基于代理机制,所以只有通过 Spring 容器调用的方法才能被拦截,这也是为什么我们要确保被拦截的类要注册为 Spring Bean 的原因。
切面定义通过在类上添加@Aspect实现,切点定义使用@Pointcut注解指定拦截规则,比如@Pointcut("execution(* com.example.service.*.*(..))")表示拦截
service 包下所有方法。
谈到 @Aspect 时,你需要明确 Spring AOP 和 AspectJ 的关系:Spring AOP 实际上借鉴了 AspectJ 的注解体系,包括 @Aspect、@Pointcut、@Before 等注解都来自 AspectJ,但底层实现机制不同。Spring AOP 基于动态代理实现,只能拦截 Spring 管理的 Bean 的方法调用,而 AspectJ 是通过字节码织入实现的,功能更强大但也更复杂。在日常开发中,Spring AOP 已经能满足大部分场景需求。
通知类型包括五种:@Before在目标方法执行前运行,常用于参数校验;@After在方法执行后运行,用于资源清理;@AfterReturning在方法正常返回后执行,可获取返回值进行后置处理;@AfterThrowing在方法抛异常时执行,用于异常日志记录;@Around环绕整个方法执行,最为灵活,常用于性能监控和事务控制。
Spring 会在运行时为被拦截的 Bean 创建代理对象,当调用目标方法时实际执行的是代理逻辑,从而实现横切关注点的分离。记住切面只对 Spring 容器管理的 Bean 生效,直接 new 的对象无法被拦截。
对于多个切面可以进行执行顺序控制,当有多个切面作用于同一个方法时,Spring通过@Order注解来控制执行顺序。数值越小,优先级越高。但是对于这些注解并不是优先级高就一定先执行,例如对于@Before通知,Order值小的先执行;对于@After通知,Order值小的后执行
@ComponentScan注解的配置?包扫描的规则和过滤器?结合
Spring 框架聊聊?
@ComponentScan 是 Spring 框架中用于自动扫描和注册 Bean
的核心注解,它告诉 Spring 容器在哪些包路径下寻找标注了
@Component、@Service、@Repository、@Controller
等注解的类。
Spring 容器的自动配置,依赖注入什么的都需要依赖于 Bean
的发现机制,当容器启动时需要知道哪些类应该被管理为
Bean,而@ComponentScan就是告诉容器去哪里找
基本配置很简单,通过 basePackages 或 value
属性指定扫描路径,而且还能配置excludeFilters
用于排除不需要的类等灵活处理的情况。如果不指定路径,默认扫描当前配置类所在包及其子包。你也可以用
basePackageClasses 指定基准类,Spring
会扫描这些类所在的包,这种方式在微服务和重构包名时的情况不容易出错。
包扫描规则遵循递归原则,在Spring容器的 refresh()
方法执行过程中,会有一个专门的阶段处理组件扫描,会递归遍历指定包路径下的所有
class
文件,通过反射机制检查每个类上的注解,符合条件的类会被实例化并注册到 IoC
容器中。
@Configuration和@Component的区别?配置类的特殊性?结合
Spring 框架聊聊?
@Configuration和@Component都是 Spring 中
标识受容器管理的 Bean 的注解
@Component是通用的 Bean
标识注解,而@Configuration是专门为配置类设计的,承载了
Spring 容器初始化、Bean 定义注册、依赖注入的核心逻辑。
@Configuration是@Component的子类注解,它定义
Bean 的创建规则、管理 Bean 之间的依赖关系,是 Spring Java Config
的核心。
@Component标记的类会被 Spring 容器管理,但方法调用遵循普通Java语义。@Configuration标记的类会被CGLIB代理增强,确保@Bean方法之间的调用返回同一个实例,维护Bean的单例特性。@Configuration作为配置类,支持@Import导入其他配置类,支持@PropertySource加载外部配置文件,支持@Enable*系列注解开启 Spring 特定功能;@Component不具备上述内容@Component仅能通过@Autowired/@Resource实现依赖注入,无法直接通过方法调用管理 Bean 依赖。@Configuration支持@Bean方法间的依赖传递,通过方法调用实现 Bean 依赖,无需手动注入。
简单说,@Component用于业务组件,@Configuration专门用于配置Bean的定义和装配,最重要的是区分这个
@Configuration注解的核心在于它会触发Spring的ConfigurationClassPostProcessor后置处理器。Spring容器在解析配置类时,会检测到@Configuration注解,然后使用CGLIB创建一个子类代理,这个代理类会拦截所有@Bean方法的调用。CGLIB代理不是简单的方法拦截,而是保证Bean实例的唯一性。代理的核心作用是确保当一个@Bean方法调用另一个@Bean方法时,返回的是Spring容器中已经存在的Bean实例,而不是重新创建。在
@Component类中定义了多个@Bean方法,并且方法间有调用关系。结果发现每次调用都创建了新的实例,导致数据库连接数异常飙升。后来改成@Configuration注解,问题立即解决。
在实际项目中,一般在三种场景下会选择@Configuration。第一是基础设施配置,比如数据库连接池、Redis客户端这些需要严格单例的组件。第二是第三方框架集成,像Swagger、定时任务框架的配置。第三是复杂的Bean依赖关系配置,特别是Bean之间有相互调用的场景。
@Profile注解的作用是什么?你都如何使用它?多环境配置下如何进行实践来进行环境隔离?
@Profile 注解是 Spring 框架中用于条件化加载
Bean
的一个注解,通过指定激活的环境配置来控制特定组件的实例化。
可以在类级别或方法级别使用它,比如 @Profile("dev") 或
@Profile({"prod", "staging"})。标注在 @Bean 方法上就是精准控制单个
Bean 的加载,标注在配置类上就是控制整个配置类的加载
在多环境配置的实际应用中,我通常会为不同数据源创建专门的配置类,开发环境使用
@Profile("dev") 配置开发用的数据库,生产环境用
@Profile("prod") 配置 MySQL 集群。
激活 Profile 的方式包括在 application.properties 中设置
spring.profiles.active=dev,或通过 JVM 参数
-Dspring.profiles.active=prod 启动应用,这样就能用
@Profile 隔离差异化 Bean
一般情况下,环境隔离需要通过多文件配置策略实现,将
application-dev.yml作为开发环境配置、application-prod.yml作为生产环境配置,等环境特定配置分离,主配置文件只保留公共配置。
对于复杂的微服务架构,可以组合使用多个 Profile,比如
@Profile("prod & !docker")
这样的表达式来处理更精细的环境区分。
另外,避免在业务代码中硬编码环境判断,而是通过
@ConditionalOnProfile 或直接使用 @Profile 让
Spring
容器自动处理依赖注入,这样既保证了代码的清洁性,又提高了环境切换的灵活性。
Spring
Boot 中都有哪些注入 Bean
的方式?@Autowired、@Resource、@Inject注解的区别?为什么
Spring 官方不推荐使用 @Autowired?
虽然我们常说 注解注入,但从底层机制上,Spring 主要支持以下三种方式来进行 DI:
构造器注入
这是官方推荐的,它通过类的构造函数来明确依赖关系。通过
final修饰,能够保证依赖不为空1
2
3
4
5
6private final UserService userService;
// 4.3+ 单构造器可省略@Autowired
public UserController(UserService userService) {
this.userService = userService;
}通过
setXxx方法注入依赖。它比较灵活,允许依赖在之后被修改或重新注入。但是无法保证依赖在对象使用前已完全初始化,可能导致NPE
1
2
3
4
5
6private UserService userService;
public void setUserService(UserService userService) {
this.userService = userService;
}字段注入
直接在成员变量上注解
1
2
private UserService userService;
而
@Autowired、@Resource、@Inject
这三个注解都能实现自动装配 Bean,但是,
@Autowired、@Resource、@Inject本身是
依赖注入的注解,不是
固定的某一种注入方式,只是日常开发中大家最常用在字段上。
它们之间的区别就是
| 注解 | 所属规范 | 匹配优先级 | 支持的注入形式 | 核心区别 |
|---|---|---|---|---|
@Autowired |
Spring 专属 | 优先类型(byType)→ 再按名称(byName) | 字段 /setter/ 构造器 | 支持required=false、@Qualifier指定 Bean
名 |
@Resource |
JSR-250(Java 标准) | 优先名称(byName)→ 再按类型(byType) | 字段 /setter(不支持构造器) | 可通过name属性指定 Bean 名 |
@Inject |
JSR-330(Java 标准) | 优先类型(byType) | 字段 /setter/ 构造器 | 需导入javax.inject依赖,支持@Named指定
Bean 名 |
详细的查找逻辑是这样的
@Autowired:首先根据 类型 (Type) 查找。
如果找到多个同类型的 Bean,则尝试按 名称 (Name) 匹配。
如果名称也匹配不上,且没有
@Qualifier,则报错。
@Resource:首先根据 名称 (Name) 查找(默认取字段名)。
如果按名称没找到,则回退到按 类型 (Type) 查找。
它的逻辑更符合 Java 原生语义,且与框架解耦。
为什么 Spring 官方不推荐使用 @Autowired 字段注入呢?明明只有它是 Spring 生态中的内容?难道考虑的是兼容性吗?只能说是不止,其实是这样
违反了单一职责原则
使用字段注入太方便了,以至于开发者很容易在一个类里塞入 10 个甚至 20 个依赖,而不会觉得有什么问题。那么就可能出现了类违反单一职责,循环依赖或无用依赖的情况。如果是构造器注入,看到一个拥有 20 个参数的构造函数,开发者会立刻意识到这个类承载了太多职责,需要重构。
无法使用
final修饰符字段注入是无法使用
final修饰符的,因为字段注入是在对象实例化之后通过反射设置的。这破坏了 不可变对象 (Immutable Objects) 的设计模式,可能在高并发等情况下出现问题与 Spring 容器过度耦合
这是最致命的一点。字段注入必须依赖 Spring 的反射机制。如果你想在不启动 Spring 容器的情况下(如纯 JUnit 测试)实例化这个类,你必须手动编写反射代码来注入依赖,否则该字段永远是
null。隐藏了循环依赖风险
如果是构造器注入,存在循环依赖,Spring 在项目启动时就会抛出
BeanCurrentlyInCreationException,提醒你设计有问题。而字段注入因为反射不会在启动时候检查,而是等问题出现才报错。
既然官方不推荐,那为什么我看到的 demo 全是 @Autowired
字段注入?
- 没办法,字段注入太简单了,以至于在实际开发中,它仍然主流
- 但是,我们可以配合 Lombok 的
@RequiredArgsConstructor注解,它能自动生成带final字段的构造函数,这样,使用构造器注入就很方便了
@Qualifier注解的作用?如何解决多个候选
Bean 的问题?结合你的实践聊聊?
首先,我们都知道,@Autowired默认按类型匹配进行注入,@Resource默认按名称匹配,而在实际开发中,如果你的项目可能迁移到其他容器或需要标准化,@Resource更具可移植性,所以说我们用的更多的都是@Resource
当 Spring 容器中存在多个同一类型的 Bean
实例时,依赖注入会触发NoUniqueBeanDefinitionException异常。但在实际开发中,同一类型存在多个
Bean 实例
的场景很常见(比如多数据源、多缓存实现、多支付渠道),例如,在项目中,我需要同时集成
PostgreSQL 和 MongoDB
两种数据源,且都实现了DataSource接口,此时容器中会存在两个DataSource类型的
Bean,直接注入就会冲突
除了@Resource加name属性,我们使用@Qualifier
+ @Autowired也能解决这个问题。
@Qualifier是 Spring 提供的 Bean
名称限定注解,在按类型匹配的基础上,进一步按 Bean
名称筛选,解决多候选 Bean 的歧义问题。
使用方式很直接,在@Autowired旁边添加@Qualifier("beanName")来指定具体的Bean名称。比如你有两个DataSource类型的Bean,一个叫primaryDataSource,另一个叫secondaryDataSource,注入时就用@Qualifier("primaryDataSource")明确告诉Spring要哪个。
如何理解@SpringBootApplication注解,为什么标注了这个注解的类能够作为主启动类?
@SpringBootApplication 是 Spring Boot
核心的组合注解,它整合了 3 个注解。
@ComponentScan做组件扫描,扫描当前包及子包下的@Controller/@Service/@Component等注解的类@EnableAutoConfiguration开启自动配置,自动加载 Spring Boot 内置的默认配置@SpringBootConfiguration也是标记该类为配置类,本质是@Configuration
标注了该注解的类之所以能作为主启动类,是因为它完成了 开启自动配置、扫描组件、标记配置类 三大核心工作,是 Spring Boot 约定大于配置 思想的集中体现。
1 |
|
启动类的核心是 main 方法 +
SpringApplication.run(),但真正让它成为 启动入口 的是
@SpringBootApplication 的三大能力:
@ComponentScan会从启动类所在包开始,递归扫描所有子包下的组件如果你的 Controller 放在启动类的上层包,会扫描不到,我被坑过,需要指定路径
@EnableAutoConfiguration会通过SpringFactoriesLoader加载META-INF/spring.factories文件中的自动配置类,自动配置类通过@Conditional注解实现按需生效,只需配置配置文件yaml中的相关信息,无需手动创建 Bean,就是自动配置的体现。@SpringBootConfiguration让启动类具备配置类的能力,可直接在启动类中通过@Bean定义全局组件
执行SpringApplication.run(),进行的是 Spring Boot
项目启动那一套了
- 加载
@SpringBootApplication注解的配置; - 扫描组件并注册到 Spring 容器;
- 启动自动配置流程;
- 启动内嵌 Tomcat(如果引入 web 依赖);
- 初始化 Spring 上下文,项目启动完成。
Spring Boot 实践相关
如何在 Spring Boot 中定义和读取自定义配置?Spring Boot 配置文件加载优先级你知道吗?
Spring Boot 支持多种配置文件格式,而自定义配置项的核心就是定义配置项 + 读取配置项
先在配置文件中定义自定义配置项,这就是我们把配置写到配置文件里
1 | # application.yml |
而读取配置项有几种方式
@Value注解:${配置项key:默认值}直接注入单个配置项,需要注意配置文件需要成为 Bean 交给 Spring Boot 管理,加
@Component1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
// 必须交给Spring容器管理,否则无法注入
public class AppConfig {
// 注入单个配置项,冒号后是默认值
private String appName;
private String appVersion;
// 注入嵌套配置项
private String dbUrl;
}@ConfigurationProperties它是批量绑定配置项,适合配置项多、有层级的场景。一般情况下,我们需要自定义一系列自定义配置,就使用这个注解编写对应的配置类,业务中可以直接注入使用
一般需要如下几步
编写配置绑定类,也就是在这里声明里的
yaml中需要绑定哪些自定义配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.util.List;
// 前缀:绑定yaml配置文件中以app开头的配置项
// Spring Boot 2.2+ 也可通过 @EnableConfigurationProperties 启用
// 必须有getter/setter,否则无法绑定
public class AppProperties {
// 字段名与配置项后缀一致(name → app.name)
private String name;
private String version;
private String env;
// 嵌套配置(对应 app.database)
private Database database;
// 数组配置(对应 app.servers)
private List<String> servers;
// 内部类:绑定嵌套配置
public static class Database {
private String url;
private String username;
private String password;
}
}如果不写
@Component,可在启动类加@EnableConfigurationProperties然后就可以使用配置,注入依赖后直接使用就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
public class ConfigController {
private AppProperties appProperties;
public String getConfig() {
return "应用名称:" + appProperties.getName() +
"<br>数据库地址:" + appProperties.getDatabase().getUrl() +
"<br>服务器列表:" + appProperties.getServers();
}
}
然后,Spring Boot 会从多个位置加载配置文件,优先级高的配置会覆盖优先级低的,从高到低优先级如下
命令行参数
启动时通过启动命令传入的参数,会覆盖所有配置,适合临时修改配置。
操作系统环境变量
Spring Boot 会自动识别操作系统的环境变量
JVM系统属性
启动时通过 JVM 属性传入的配置,
-Dapp.name=prod传入,如java -Dapp.name=prod -jar app.jar。外置的配置文件
(项目根目录
config/> 项目根目录)项目根目录下的
config/文件夹:./config/application.yml项目根目录:
./application.yml内置的配置文件
(
classpath/config/ >classpath根目录)类路径(resources)下的
config/文件夹:classpath:/config/application.yml类路径根目录:
classpath:/application.yml配置类中的默认值
如
@Value("${app.name:default}")中的default,是最后兜底的默认值
如果配置了多环境,优先级规则如下
- 通过
spring.profiles.active=dev指定环境后,对应环境的配置(如application-dev.yml)会覆盖application.yml中的同名配置; - 多环境配置的加载优先级遵循上述「外置 > 内置」规则。
如何实现自定义的AOP功能?如何在AOP中获取方法参数和返回值?ProceedingJoinPoint的使用?
在Spring中,你可以通过@Aspect注解标记一个
@Component 的 Bean 作为 AOP
切面对象,配合@Around、@Before、@After等注解快速实现切面逻辑
在实际项目中,AOP的应用场景主要集中在四个方面:日志记录、性能监控、权限校验和缓存处理。自定义注解配合AOP是一种优雅的设计思路
1 |
|
切面最佳实践方面,建议遵循单一职责原则,一个切面只处理一类横切关注点,避免在切面中写复杂业务逻辑。切点表达式要精确,防止误拦截不相关方法。异常处理要谨慎,避免切面异常影响主业务流程。在Spring环境下,@Transactional就是经典的AOP应用,声明式事务通过切面自动管理事务边界。
那么,在 AOP 中获取方法参数和返回值主要通过
ProceedingJoinPoint 实现。这个接口是Spring
AOP提供的连接点对象,专门用于环绕通知@Around中。
通过 joinPoint.getArgs()
可以获取目标方法的所有参数数组,获取返回值则需要调用
joinPoint.proceed()
执行目标方法,这个方法会返回目标方法的执行结果。
在@Around通知的整个处理中,先通过getArgs()获取入参进行前置处理,然后调用proceed()执行目标方法并捕获返回值,最后对返回值进行后置处理。
需要注意的是,
proceed()方法必须被调用,否则目标方法不会执行。如果目标方法抛出异常,proceed()会将异常向上传播,这时你可以在catch块中处理异常情况。通过joinPoint.getSignature()还能获取方法签名信息,包括方法名、参数类型等元数据,这在动态日志记录和权限校验中特别有用。
写过 Spring Boot Starter 吗?
创建Maven项目
首先,需要创建一个新的Maven项目。在 pom.xml 中添加 Spring Boot 的 starter parent 和一些依赖
然后添加自动配置
在
resources文件夹下,在META-INF/spring.factories中添加自动配置的元数据。1
org.springframework.boot.autoconfigure.EnableAutoConfiguration = com.example.starter.MyAutoConfiguration
创建配置属性类
一般情况下,我们的 starter 中需要有供用户定义的配置,创建一个配置属性类,使用
@ConfigurationProperties注解来绑定配置文件中的属性。1
2
3
4
5
6
7
8
9
10
11
12
public class MyAutoConfiguration {
private MyProperties properties;
public MyService myService() {
return new MyServiceImpl(properties);
}
}创建服务和控制器
创建一个服务类和服务实现类,以及一个控制器来展示和测试你的 starter 的功能。
发布 Starter
测试后,将你的 starter 发布到Maven仓库,可以是私有的或是公共的
使用 Starter
在你的主应用的
pom.xml中添加你的 starter 依赖,然后在application.yml或application.properties中配置你的属性。
Spring Boot 如何处理跨域请求(CORS)?
跨域只存在于浏览器端,之所以会跨域,是因为受到了同源策略的限制,同源策略要求源相同才能正常进行通信,即协议、域名、端口号都完全一致。不同的请求类型,CORS的处理也不一样
- 简单请求:
GET/POST/HEAD,且请求头只有默认字段(如Content-Type为text/plain),直接触发跨域检查; - 预检请求(OPTIONS):
PUT/DELETE/ 自定义请求头,Content-Type为application/json时,浏览器会先发送OPTIONS预检请求,确认后端允许跨域后,再发送真实请求。
Spring Boot 处理跨域的 3 种方案如下
全局跨域配置
通过配置类统一设置跨域规则,覆盖所有接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.cors.CorsConfiguration;
import org.springframework.web.cors.UrlBasedCorsConfigurationSource;
import org.springframework.web.filter.CorsFilter;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
// 标记为配置类
public class CorsConfig {
// 方式 1:通过 WebMvcConfigurer 配置(更简洁,推荐)
public WebMvcConfigurer corsConfigurer() {
return new WebMvcConfigurer() {
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**") // 对所有接口生效
// 允许的跨域源(前端域名),* 表示允许所有(生产环境建议指定具体域名)
.allowedOriginPatterns("*")
// 允许的请求方法(GET/POST/PUT/DELETE 等)
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
// 允许的请求头
.allowedHeaders("*")
// 是否允许携带 Cookie(跨域认证需要)
.allowCredentials(true)
// 预检请求的缓存时间(秒),减少 OPTIONS 请求次数
.maxAge(3600);
}
};
}
// 方式 2:通过 CorsFilter 配置(更灵活,面试可提)
/*
@Bean
public CorsFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
// 允许的源(Spring Boot 2.4+ 推荐用 allowedOriginPatterns,替代 allowedOrigins)
config.addAllowedOriginPattern("*");
// 允许的请求方法
config.addAllowedMethod("*");
// 允许的请求头
config.addAllowedHeader("*");
// 允许携带 Cookie
config.setAllowCredentials(true);
// 预检缓存时间
config.setMaxAge(3600L);
// 配置生效的路径
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", config);
return new CorsFilter(source);
}
*/
}局部跨域配置
@CrossOrigin 注解针对单个接口 / 控制器生效,接口级
@CrossOrigin> 控制器级@CrossOrigin> 全局配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
// 对整个控制器的所有接口生效
public class TestController {
// 对单个接口生效(优先级高于控制器注解)
public String testCors() {
return "跨域请求成功";
}
}通过网关处理
如果项目中使用 Spring Cloud Gateway/Zuul 网关,可在网关层统一配置跨域,避免每个微服务重复配置
一般情况下,除非开发时测试,否则禁止使用
allowedOriginPatterns("*"),必须指定具体的前端域名(如
http://www.xxx.com),避免安全风险。而且开启
allowCredentials(true) 时,前端必须同步设置
withCredentials: true;
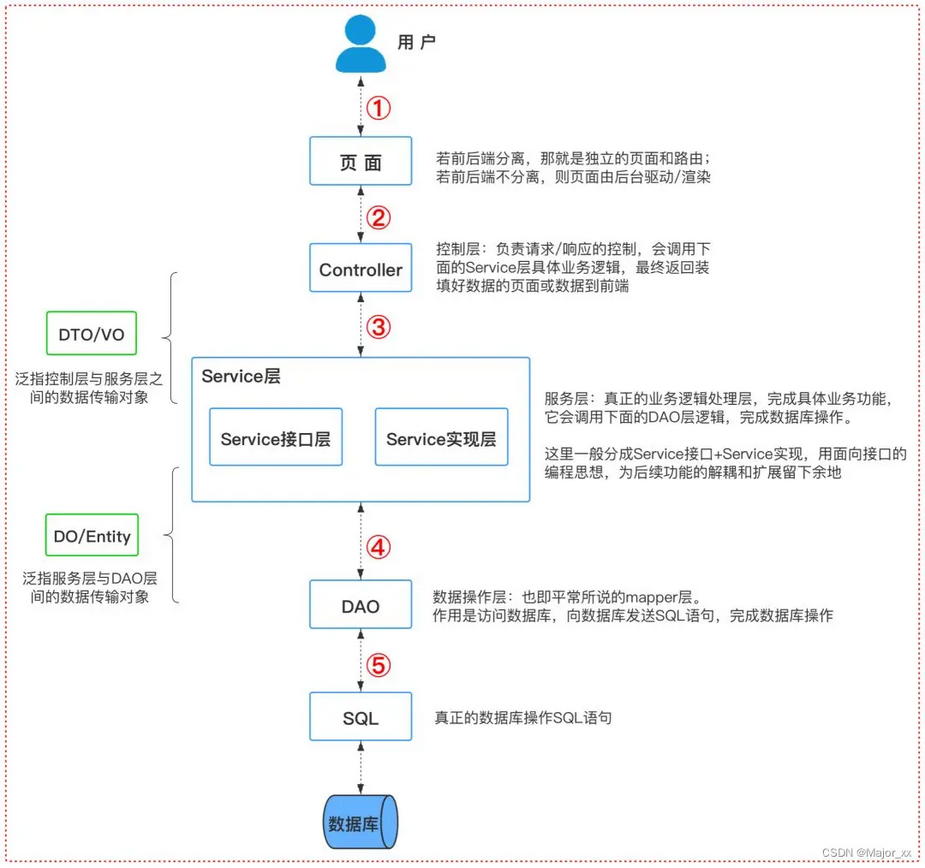
Spring Boot 的项目结构是怎么样的?
一个正常的企业项目里,通常会使用一种通用的项目结构和代码层级划分,来规范化项目开发和便于团队协作
一般情况下,一个 Spring Boot 项目里会有这样的一个结构
1 | com |
配置层 config
存放所有配置:Redis、Security、跨域配置、线程池等。包括你自定义配置中的内容。
控制器层 controller
接收前端请求、参数校验、调用 service、返回统一结果。
业务逻辑层 service
核心业务处理、调用DAO持久层,调用第三方服务等
数据访问层 dao
和数据库交互,CRUD。
数据模型层 model
- 数据库实体 entity:对应数据库表结构
- 数据传输对象 dto /vo:
- dto:前端传给后端的请求
- vo:后端返回给前端的视图对象
通用模块 common
里面可以放工具类,异常处理,自定义的一些注解啊什么
安全模块 security
登录、认证、授权、JWT、OAuth2、2FA等安全业务在这里处理
AOP 切面层 aspect
日志、操作记录、权限校验、接口耗时统计、网站 UV 收集等
所以说,Spring Boot
的标准结构是典型的三层架构,Controller → Service → Mapper,结构清晰、职责明确、便于团队协作和维护。
Spring Boot 当中,你是如何实现统一异常处理的?
在 Spring Boot 里,我是通过 @ControllerAdvice +
@ExceptionHandler
实现全局统一异常处理的,同时配合自定义业务异常和统一返回格式,让所有接口的异常都能集中处理、格式一致、便于排查。
@ExceptionHandler异常处理器注解,指定方法处理某一类异常,比如业务异常、参数异常、系统异常。
@ControllerAdvice开启全局控制器增强,能捕获所有
Controller 抛出的异常。
这样代码不冗余、返回格式统一、安全不泄露堆栈、方便日志记录、便于前端处理。
首先肯定要定义统一返回结果
所有接口成功 / 失败都用同一个格式
然后写一个自定义业务异常
BusinessException区分业务错误和系统错误
然后写一个全局异常处理器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class GlobalExceptionHandler {
// 1. 处理业务异常
public Result<?> handleBusinessException(BusinessException e) {
log.error("业务异常:{}", e.getMessage());
return Result.fail(e.getCode(), e.getMessage());
}
// 2. 处理参数校验异常(@Valid 校验失败)
public Result<?> handleValidException(MethodArgumentNotValidException e) {
String msg = e.getBindingResult().getFieldError().getDefaultMessage();
return Result.fail(400, "参数错误:" + msg);
}
// 3. 兜底:处理所有未知系统异常
public Result<?> handleException(Exception e) {
log.error("系统异常", e);
return Result.fail(500, "服务器繁忙,请稍后重试");
}
}
这样,所有 Controller 不写
try/catch,直接抛自定义业务异常,代码非常干净,而且能够全局捕获,分类处理,让异常不再飞升老冯
Spring
Boot 中,你如何结合 Java
的多线程去做异步任务进行异步处理的?如何使用@Async,@Async什么时候会失效?
在传统的同步请求中,主线程会阻塞等待每一个任务完成,发送邮件、生成报表、调用第三方接口,这种完全可以异步的耗时任务,我们就可以开启异步处理,让 Spring 交给辅助线程池处理,主线程立即返回响应。
使用 @Async 是 Spring 提供的一种基于 AOP
的简便实现。
首先,就是在启动类或配置类上标注
@EnableAsync。然后,在方法上标注注解@Async。如果需要获取返回值,推荐使用
CompletableFuture
1 |
|
而@Async
失效的根本原因就一个:代理没生效。
Spring 的 @Async 底层是通过 AOP
代理来实现的,只有调用走代理对象的方法,才能被拦截然后丢到线程池里执行。任何绕过代理的情况,都会让
@Async 变成摆设。
最常见的失效场景有这几种:
同一个类里内部调用。
在 Service 的 A 方法里直接调
this.B(),这个 B 方法上的@Async压根不生效。因为 this 指向的是原始对象,不是代理对象,调用根本没经过 AOP 拦截。1
2
3
4
5
6
7
8
9
10
11
12
public class OrderService {
public void createOrder() {
// 失效!this 指向原始对象,不是代理
this.sendNotification();
}
public void sendNotification() {
// 期望异步执行,但实际是同步的
}
}方法不是 public 的
Spring 默认用的是基于接口的 JDK 动态代理或者基于类的 CGLIB 代理,这两种代理都只能拦截 public 方法
不能是 static 方法
静态方法属于类,不属于 Spring Bean 实例,无法被代理
压根没开启异步支持
@Async不是开箱即用的,必须在配置类或启动类上加@EnableAsync,Spring 才会去扫描@Async注解并创建代理。不加这个注解,@Async就是个装饰品。返回值类型不对。
@Async方法的返回值只能是void、Future、CompletableFuture这几种。你要是让它返回个普通 String,其实也不会报错,方法也执行了,但是调用方拿到的就是 null,异步执行的结果你拿不到,在需要结果的场景下,看起来好像就失效了。
@Async的实现靠的是AsyncAnnotationBeanPostProcessor这个后置处理器。Spring 容器启动时,这个处理器会扫描所有 Bean,发现有@Async注解的方法,就给这个 Bean 套一层代理。代理对象在方法被调用时,会先判断方法上有没有
@Async。有的话,就把这次调用包装成一个Callable任务,丢给TaskExecutor线程池去执行,然后立即返回。这就是异步的本质。
多说一句,@Async 默认用的是
SimpleAsyncTaskExecutor,这玩意每来一个任务就 new
一个线程,没有线程复用,生产环境直接用会出事。正确做法是自定义
ThreadPoolTaskExecutor,然后在 @Async
注解里指定用哪个线程池
Spring Boot 中你如何实现定时任务?
Spring Boot 内置了对定时任务的支持,实现起来非常简单
开启定时任务: 在启动类或配置类上标注
@EnableScheduling。创建定时方法: 在 Bean 的方法上标注
@Scheduled。1
2
3
4
5
6
7
8
public class MyTask {
// 每隔5秒执行一次
public void task() {
System.out.println("执行定时任务: " + LocalDateTime.now());
}
}
@Scheduled 注解的参数决定了定时的情况
fixedRate:固定频率,以任务开始执行的时间点算起。例如fixedRate = 5000,无论任务执行多久,每隔 5 秒都会尝试启动下一个任务。fixedDelay:固定延迟,以任务执行完成的时间点算起。例如fixedDelay = 5000,任务执行完后,再等 5 秒才执行下一个。cron:使用 Cron 表达式,最常用,因为能通过表达式控制精确时间。格式为[秒] [分] [时] [日] [月] [周]
我们都知道 JUC 中有一个专门用于执行定时任务的线程池,那么 Spring 的定时任务也是这样吗?是这样,但是
Spring 默认使用单线程的调度器。
什么意思,如果你有多个定时任务(Task A 和 Task B),如果 Task A 阻塞了,Task B 即使到了时间也不会执行。
所以说,我们需要自定义 ScheduledExecutorService
线程池,设置合理的核心线程大小
1 |
|
分布式场景下的定时任务也有一些要注意的内容
例如,在微服务架构下,如果你部署了 3 个服务实例,
@Scheduled会在 3 台机器上同时运行,导致任务重复执行怎么办?
分布式锁
使用 Redisson 配合 Redis 或 MySQL。在执行任务前尝试抢占锁,抢到的机器执行,抢不到的跳过。
分布式任务调度平台
- XXL-JOB:支持中心化管理、调度中心与执行器分离、失败重试、执行日志监控、分片任务等。
- Quartz:老牌调度框架,功能强大但配置较复杂。
Spring Boot 中你如何使用拦截器,说说你在什么业务下如何使用的拦截器?
说说你对 Spring Boot 事件机制的了解?
Spring Boot的事件机制,本质上是一个基于观察者模式的、用于应用内部组件间通信。
它允许一个组件(发布者)发出信号(事件),而无需知道谁会处理它;其他组件(监听器)可以订阅这些信号,并在信号发出时自动执行相应逻辑。
- 事件(Event):信息的载体,封装了要传递的数据。可以继承
ApplicationEvent类 - 事件发布者(Publisher):负责发出事件。通过实现
ApplicationEventPublisher接口(其实现类通常是ApplicationContext)来发布事件。 - 事件监听者(Listener):负责监听并处理特定类型的事件。实现方式有两种:
- 实现接口:实现
ApplicationListener接口,并重写onApplicationEvent方法。 - 使用注解(更常用):在方法上添加
@EventListener注解,并指定要监听的事件类型。
- 实现接口:实现
整个流程是:发布者通过ApplicationEventPublisher发布一个事件
->
事件广播器ApplicationEventMulticaster将事件分发给所有已注册的监听器
-> 匹配的监听器执行其业务逻辑。
以最常用的注解方式为例
自定义事件类
1
2
3
4public class OrderCreatedEvent {
private String orderId;
// 构造方法、getter、setter...
}定义监听器
1
2
3
4
5
6
7
8
public class OrderEventListener {
public void handleOrderCreated(OrderCreatedEvent event) {
// 处理订单创建后的逻辑,如发送邮件、更新库存等
System.out.println("收到订单创建事件,订单号:" + event.getOrderId());
}
}发布事件
1
2
3
4
5
6
7
8
9
10
public class OrderService {
private ApplicationEventPublisher publisher;
public void createOrder() {
// ... 订单创建逻辑
publisher.publishEvent(new OrderCreatedEvent("123456"));
}
}
默认情况下,事件的发布和监听是同步的,即发布者会等待所有监听器执行完毕后才继续。若要实现异步,需在配置类上添加
@EnableAsync,并在@EventListener方法上添加@Async注解。这对于发送邮件、记录日志等非核心业务非常有用。如果一个事件有多个监听器,可以通过
@Order注解来控制它们的执行顺序。
@EventListener注解支持SpEL表达式,可以根据事件对象的属性决定是否触发监听。
你的项目中涉及到了多数据源啊?那么在 Spring Boot 中你是如何配置和实现多数据源的?
在 Spring Boot 中实现多数据源,本质上是绕过 Spring
Boot 的自动装配机制,手动创建并管理多个 DataSource
实例。
例如,我的平台使用 PostgreSQL 处理结构化业务、MongoDB 存储非结构化文档,那么基本是这样实现的
首先在启动类上排除默认的数据源自动配置类,避免和自定义数据源冲突,这是基础步骤,必须先做:
1
2
3
4
5
6
public class ZyPlatformApplication {
public static void main(String[] args) {
SpringApplication.run(ZyPlatformApplication.class, args);
}
}在 application.yml 中配置所有数据源的连接参数,我项目里配了 PostgreSQL、MySQL、MongoDB 三个,核心是给每个数据源单独指定连接池、驱动、url、账号密码,用自定义前缀区分,同时配置连接池参数,按数据源的业务压力单独调优,示例核心配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22spring:
datasource:
# 结构化业务- PostgreSQL数据源
pg:
driver-class-name: org.postgresql.Driver
jdbc-url: jdbc:postgresql://ip:port/zy_platform
username: xxx
password: xxx
hikari:
minimum-idle: 5
maximum-pool-size: 20
# 备用结构化- MySQL数据源
mysql:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/zy_platform?useUnicode=true&characterEncoding=utf8
username: xxx
password: xxx
# MongoDB非结构化数据源(单独配置,基于Spring Data MongoDB)
data:
mongodb:
uri: mongodb://ip:port/zy_mongo
database: zy_platformMongoDB 是非关系型数据库,基于 Spring Data MongoDB 单独配置,和关系型数据源的配置逻辑分离,这是多源异构的关键。
新建配置类,通过
@ConfigurationProperties绑定 yml 中的多数据源配置,然后为每个数据源手动创建对应的「数据源 + 会话工厂 + 事务管理器」,给每个数据源的组件单独命名,然后用@Primary指定主数据源,避免容器中 bean 冲突。分库路由,指定不同包 / 方法对应不同数据源,项目中用包扫描 + 注解结合的方式,简单高效
- 包扫描路由:在配置类中,给不同数据源的
EntityManagerFactory/SqlSessionFactory指定专属的 Repository 包路径,比如 PostgreSQL 对应com.zy.platform.repository.pg,MySQL 对应com.zy.platform.repository.mysql,MongoDB 对应com.zy.platform.repository.mongo,框架会自动根据包路径匹配数据源,开发时只需按包分层开发就能自动对应得上 - 注解式路由:针对少数跨库操作的方法,自定义一个注解,结合 AOP 实现方法级的数据源动态切换
- 包扫描路由:在配置类中,给不同数据源的
事务管理,多数据源事务的处理方式
- 单库:直接在 Service
方法上用
@Transactional,指定对应的事务管理器,框架自动管理,和单数据源用法一致; - 跨库:如果是跨库事务,就涉及到分布式事务了,一般情况下使用
Seata 的 AT 模式都能搞定,整合 Seata
后,只需在跨库方法上加
@GlobalTransactional,Seata 会自动管理多数据源的事务一致性,无需手动处理回滚;
- 单库:直接在 Service
方法上用
注意,多数据源下禁用二级缓存共享,每个数据源单独配置缓存,要不然极容易脏读,嗷嗷





