
了解Kafka
什么是Kafka
Kafka 是一款高吞吐量的分布式消息队列
Apache Kafka是分布式发布-订阅消息系统,Kafka最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
初衷是解决 “大规模实时数据传输与存储” 问题,因此它的设计更偏向 “高吞吐、可持久化、分布式” 的日志系统,而消息队列只是其核心功能之一。
kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒。而且kafka集群支持热扩展,同时支持数千个客户端同时读,拥有很好的高并发。
简单说:RabbitMQ 更像 “快递中转站”(强调消息路由、即时投递),而 Kafka 更像 “大型仓库”(强调批量存储、高效读写)。
所以开发中,Kafka多使用在
- 日志收集:多服务的日志实时写入 Kafka,下游消费端(如 ELK)统一处理分析;
- 实时数据管道:数据库变更数据(CDC)通过 Kafka 同步到数据仓库、缓存或其他系统;
- 实时计算:作为 Flink/Spark Streaming 的数据源,支撑实时数据分析(如实时报表、监控告警);
- 高吞吐消息通信:秒杀、大促等场景下,用 Kafka 缓冲峰值流量,避免下游服务被压垮。
作为MQ有什么特点
Kafka作为 MQ 的核心特点是超高吞吐量,适合大数据场景
- 设计支撑:
- 消息采用 磁盘顺序写入(而非内存随机读写),配合操作系统的页缓存(Page Cache),写入性能远超内存操作(避免频繁 GC 问题)。
- 消息分 分区(Partition) 存储,分布式并行读写(类似数据库分表),吞吐量随集群规模线性扩展。
- 数据对比:
- Kafka 单节点吞吐量轻松达到 10 万 +/ 秒(甚至更高),而 RabbitMQ 通常在 万级 / 秒(受限于内存和交换机路由开销)。
- 适用场景:日志收集(如 ELK 栈)、大数据同步(如 Flink/Spark 实时计算)、海量用户行为追踪等。
在消息持久化上,有这样的特点
消息默认写入磁盘(可配置持久化策略),且支持 多副本(Replication) 存储(分区数据复制到多个节点),即使某节点宕机,数据也不丢失。
持久化文件按 segment 分段 存储,方便过期删除(按时间 / 大小自动清理,适合日志等 “过期无效” 的数据)。
与 RabbitMQ 对比:
- RabbitMQ 也支持持久化,但默认依赖内存,大量消息堆积时容易触发内存告警,需频繁刷盘,性能下降明显;
- Kafka 从设计上就以磁盘为核心,天然适合海量消息长期存储。
而在消费模型上,kafka使用“拉取式”+“偏移量(Offset)”,这是 Kafka 与 RabbitMQ 最核心的差异之一,直接影响消费灵活性和吞吐量:
- 拉取式消费(Pull):
- 消费者主动从 Kafka 拉取消息(可自主控制速率),避免 RabbitMQ“推模式(Push)” 可能导致的消费者过载问题(尤其是消费者处理能力不足时)。
- 偏移量(Offset):
- 每个消费者组(Consumer Group)对每个分区的消费进度用 Offset 记录(本质是一个整数,代表已消费到第几条消息)。
- 消费者可通过修改 Offset 实现 重复消费、跳过消费、回溯消费(例如:数据处理失败后,重新从指定位置消费)。
- 与 RabbitMQ 对比:
- RabbitMQ 采用 “推模式”,消息被消费后默认从队列删除(需手动 ACK 确认),不记录消费进度,无法直接回溯;
- Kafka 的 Offset 机制让消费更灵活,尤其适合需要重放历史数据的场景(如数据重算、故障恢复)。
消费者组(Consumer Group),kafka分布式消费的核心
- 定义:多个消费者组成一个 “消费者组”,共同消费一个主题(Topic)的消息,同一条消息只会被组内一个消费者消费(类似 RabbitMQ 的 “工作队列模式”,但更强大)。
- 分区与消费的绑定:
- 主题的每个分区只能被消费者组内的 一个消费者 消费(反之,一个消费者可消费多个分区)。
- 例:主题有 3 个分区,消费者组有 2 个消费者,则可能 “消费者 1 消费分区 0/1,消费者 2 消费分区 2”,实现负载均衡。
- 优势:
- 轻松实现分布式消费(增加消费者数量即可提高消费能力,前提是分区数 ≥ 消费者数);
- 不同消费者组可独立消费同一主题的消息(互不干扰),适合 “一条消息被多系统处理” 的场景(类似 RabbitMQ 的 “扇形交换机”,但更高效)。
Kafka使用主题(Topic)与分区(Partition)作为数据组织的核心
- 主题(Topic):消息的逻辑分类(类似 RabbitMQ 的 “队列”,但更灵活),生产者向 Topic 发送消息,消费者从 Topic 消费。
- 分区(Partition):
- 每个 Topic 可分为多个分区(物理存储单元),消息按一定规则(默认轮询或指定 Key)分配到不同分区,实现并行读写。
- 分区内的消息是 有序的(按写入顺序),但跨分区无序(若需全局有序,需将 Topic 设为单分区)。
- 与 RabbitMQ 对比:
- RabbitMQ 的队列是 “单队列单存储”,消息有序但吞吐量受限;
- Kafka 用分区实现 “并行化”,牺牲全局有序换取高吞吐,更适合大数据场景。
Kafka 的弱路由也是其重要特点之一,实现了简化设计,专注于吞吐
Kafka 的消息路由非常简单:生产者直接指定 Topic(最多通过 Key 路由到分区),没有 RabbitMQ 中 “交换机(Exchange)+ 绑定键(Binding Key)+ 路由键(Routing Key)” 的复杂路由规则(如扇出、主题匹配、 headers 匹配等)。
- 优势:减少路由计算开销,提高吞吐量;
- 劣势:灵活度低,复杂路由需在业务层实现。
Kafka对比RabbitMQ
首先要知道,Kafka 不是 “RabbitMQ 的升级版”,而是 “为不同场景设计的产品”,天天都有人说 RabbitMQ 不如 Kafka 一根,我真晕了
核心差异
一表说明核心差异
| 维度 | Kafka | RabbitMQ |
|---|---|---|
| 吞吐量 | 极高(十万级 / 秒),适合大数据 | 中等(万级 / 秒),适合中小规模 |
| 消息模型 | 基于 Topic + 分区,拉取式 + Offset | 基于队列 + 交换机,推模式 + ACK |
| 路由能力 | 简单(仅 Topic/Key 路由) | 强大(多种交换机类型,灵活路由) |
| 持久化 | 磁盘优先,天然支持海量存储 | 内存优先,大量堆积易性能下降 |
| 消费灵活性 | 支持回溯、重复消费(Offset 控制) | 消费后默认删除,回溯困难 |
| 适用场景 | 日志收集、大数据同步、实时计算 | 业务解耦、即时通信、复杂路由场景 |
本质上的差异我们可以这样理解
| 产品 | 核心定位 | 类比场景 | 设计优先级 |
|---|---|---|---|
| RabbitMQ | 通用型消息队列(AMQP 协议实现) | 快递中转站(精准投递) | 灵活性 > 吞吐量 > 持久化 |
| Kafka | 分布式日志系统(兼顾 MQ 功能) | 大型仓库(批量存储 + 分发) | 吞吐量 > 持久化 > 灵活性 |
RabbitMQ 追求 “消息投递的精准与灵活”(比如支持多种路由规则、即时 ACK 确认),适合业务层的 “解耦通信”;
Kafka 追求 “海量数据的高效存储与传输”(比如磁盘顺序读写、分区并行),适合 “大数据场景”(日志、实时计算)。
设计和工作流程
我们在前面学习了 RabbitMQ,反正都是消息队列,借助RabbitMQ的设计理念,我们这样对比着先看一下Kafka的基本概念
| RabbitMQ 概念 | Kafka 对应概念 | 核心差异说明 |
|---|---|---|
| 队列(Queue) | 主题(Topic)+ 分区(Partition) | RabbitMQ 的 Queue 是 “物理存储单元”,一个 Queue 对应一个存储队列;Kafka 的 Topic 是 “逻辑分类”,物理存储靠 Partition(一个 Topic 可拆成多个 Partition)。 |
| 交换机(Exchange) | 无(或简化为 Topic/Key) | RabbitMQ 靠 Exchange 实现复杂路由(扇出、主题匹配等);Kafka 无 Exchange,路由仅靠 “Topic 名称” 或 “消息 Key”(Key 相同的消息进入同一 Partition)。 |
| 消费者(Consumer) | 消费者组(Consumer Group)成员 | RabbitMQ 单个消费者独立消费一个 Queue;Kafka 消费者必须属于某个 Group,Group 内消费者共同消费 Topic(同一条消息仅被 Group 内一个消费者消费)。 |
| 消息 ACK | 偏移量(Offset) | RabbitMQ 靠 ACK 确认 “消息已消费”,确认后消息从 Queue 删除;Kafka 靠 Offset 记录 “消费进度”,消息不删除,消费者可通过修改 Offset 回溯 / 重复消费。 |
| 持久化(Durability) | 分区副本(Replication) | RabbitMQ 持久化需手动开启(Queue + 消息都设为持久化),大量堆积易性能下降;Kafka 消息默认写入磁盘,且支持多副本(Partition 数据复制到多个节点),天然抗故障。 |
RabbitMQ 中 “一个 Queue 对应一个消费者组”,而 Kafka 中 “一个 Topic 可对应多个 Consumer Group”(每个 Group 独立消费)
Offset 和 Consumer Group,这两个是 Kafka 消费模型的核心 —— Offset 决定 “消费到哪”,Consumer Group 决定 “谁来消费”,理解这两个概念,就能解决 80% 的消费相关问题。
我们以 用户下单 → 生产者发送 “订单消息” → 消费者接收消息并发送短信通知 为例子,说明 Kafka 和 RabbitMQ 之间消息流转的差异
RabbitMQ
graph LR
A[生产者(订单服务)] -->|1. 发送消息+RoutingKey=“order.notify”| B[Exchange(类型:Direct)]
B -->|2. 按 RoutingKey 匹配绑定| C[Queue(“sms-queue”)]
C -->|3. 推送给消费者| D[消费者(短信服务)]
D -->|4. 发送 ACK| C[Queue(“sms-queue”)]
C -->|5. 收到 ACK 后删除消息| E[消息删除]- 路由依赖 Exchange + RoutingKey,灵活但有额外开销;
- 消息是 “推模式”(Queue 主动推给消费者),消费者处理慢时易过载;
- 消息消费后立即删除,无法回溯(除非手动备份)。
Kafka
graph LR
A[生产者(订单服务)] -->|1. 发送消息到 Topic=“order-topic”+Key=“user123”| B[Topic(“order-topic”)]
B -->|2. 按 Key 分配到 Partition 0| C[Partition 0(磁盘存储)]
C -->|3. 消费者组(“sms-group”)的消费者 1 主动拉取| D[消费者 1(短信服务)]
D -->|4. 消费后更新 Offset=100(记录已消费到第 100 条)| E[Offset 存储(Kafka 或本地)]
C -->|5. 消息保留(按时间/大小清理,默认保留 7 天)| F[消息持久化]- 无 Exchange,路由仅靠 Topic 名称,简单高效;
- 消息是 “拉模式”(消费者主动从 Partition 拉取),可自主控制消费速率(避免过载);
- 消息不删除,消费者可通过修改 Offset 重新消费(比如短信发送失败,重新拉取 Offset=99 的消息)。
吞吐能力
Kafka 的优势是高吞吐,为什么 Kafka 适合高吞吐,而 RabbitMQ 就没这么高
| 对比维度 | RabbitMQ | Kafka |
|---|---|---|
| 存储方式 | 内存优先(消息先放内存,定期刷盘) | 磁盘优先(消息直接写入磁盘,用操作系统页缓存加速) |
| 读写模式 | 随机读写(消息从内存 / 磁盘随机读取) | 顺序写入(消息按顺序追加到 Partition 末尾,磁盘顺序读写性能 ≈ 内存) |
| 并行能力 | 单 Queue 单线程读写,并行依赖多 Queue | 多 Partition 并行读写(一个 Topic 拆成 N 个 Partition,N 个线程同时处理) |
| 实际吞吐量 | 单节点 ≈ 1-5 万条 / 秒 | 单节点 ≈ 10-50 万条 / 秒(甚至更高) |
消费能力
而 RabbitMQ 出现消费失败后需手动将消息重新放入 Queue,而 Kafka 能直接将 Offset 回退到失败前的位置,重新拉取
也就是说,Kafka 支持 “回溯消费”,RabbitMQ 不支持,这是两者在 “消费能力” 上的核心差异
| 场景需求 | RabbitMQ 处理方式 | Kafka 处理方式 |
|---|---|---|
| 消费失败后重新处理 | 需手动将消息重新放入 Queue(或依赖死信队列) | 直接将 Offset 回退到失败前的位置,重新拉取 |
| 需重新计算历史数据 | 无法实现(消息已删除) | 修改 Offset 到历史位置(比如 1 小时前),重新消费所有消息 |
| 多系统独立消费同一消息 | 需创建多个 Queue,生产者发送多次消息 | 多个 Consumer Group 独立消费同一 Topic,生产者只需发送一次 |
持久化与可靠性
| 对比维度 | RabbitMQ | Kafka |
|---|---|---|
| 持久化触发 | 需手动开启(Queue 设为 durable,消息设为 persistent) | 默认持久化(消息写入磁盘,可配置保留时间) |
| 存储上限 | 受内存限制(大量消息堆积会触发内存告警,刷盘频繁导致性能下降) | 受磁盘空间限制(支持 TB 级存储,按时间 / 大小自动清理过期数据) |
| 抗故障能力 | 单节点故障后,需依赖镜像队列(Mirror Queue)恢复 | 支持多副本(Replication Factor,默认 3),一个节点故障,其他副本自动接管 |
很明显,Kafka 更适合海量的存储,感觉 RabbitMQ 的持久化类似缓存,Kafka 的持久化是更适合长期存储
路由能力:RabbitMQ 更灵活,Kafka 更简单
| 对比维度 | RabbitMQ | Kafka |
|---|---|---|
| 路由组件 | Exchange(支持 4 种类型:Direct、Topic、Fanout、Headers) | 无 Exchange,仅靠 Topic 名称 + 消息 Key |
| 支持的路由规则 | 精准匹配、模糊匹配(通配符 * #)、headers 匹配、广播 | 仅 “精准匹配 Topic” 或 “Key 哈希分区”(Key 相同进同一 Partition) |
| 路由开销 | 有(Exchange 需计算路由) | 无(直接按 Topic/Key 分配,开销极小) |
因为高吞吐高并发,那么 Kafka 在路由上必须要简单一些
该选 Kafka 还是 RabbitMQ
根据上述的对比,我们其实比较清除了,但是我还是简单的说一下
若优先 “高吞吐、持久化、回溯消费”,选 Kafka;若优先 “灵活路由、即时通信、中小规模”,选 RabbitMQ。
举几个例子
| 场景类型 | 推荐产品 | 原因说明 |
|---|---|---|
| 日志收集(ELK 栈) | Kafka | 需处理海量日志(每秒十万条),且需持久化保留(供 Elasticsearch 分析)。 |
| 实时计算(Flink/Spark) | Kafka | 需作为 “数据源头”,支持高吞吐写入,且计算失败后需回溯消费历史数据。 |
| 业务解耦(订单→库存) | RabbitMQ | 消息量不大(每秒几百条),需灵活路由(比如 “秒杀订单” 走特殊队列)。 |
| 即时通信(聊天 / 通知) | RabbitMQ | 需低延迟(毫秒级投递),且需确保消息不丢失(靠 ACK 确认)。 |
| 峰值流量缓冲(秒杀) | Kafka | 秒杀时每秒几万条请求,需用 Kafka 缓冲峰值,避免下游服务被压垮。 |
| 多系统数据同步 | Kafka | 需将数据库变更数据(CDC)同步到多个系统,Kafka 支持多 Group 独立消费。 |
Windows下安装配置 Kafka
下载和解压
https://kafka.apache.org/downloads 这是 Kafka 的官网
Kafka需要Java 8或更高版本支持。而且请自行配置 JAVA_HOME 变量
下载 tgz 压缩包
解压到你需要的位置,避免路径中包含空格和中文字符
配置 Kafka
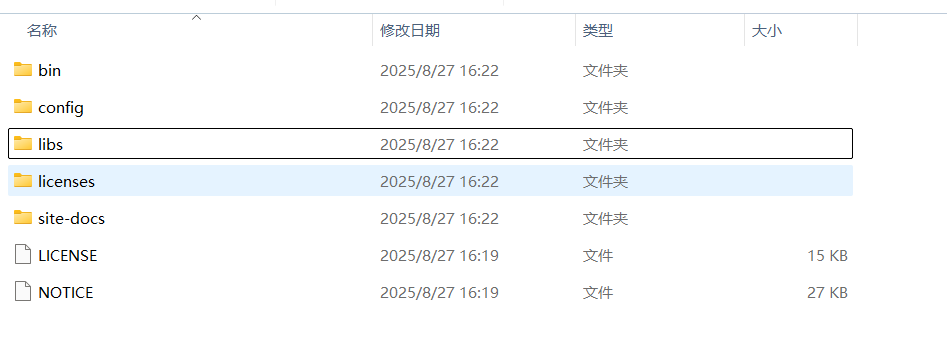
解压后的Kafka目录包含以下重要文件夹:
bin/windows/ - Windows批处理脚本
config/ - 配置文件
libs/ - 依赖库
logs/ - 日志文件(启动后生成)我们进入config目录,在server.properties文件中添加一些配置
1 | # 数据存储目录 |
虽然日志默认位置也可以

启动Kafka
Zookeeper 模式(兼容旧架构)
Kafka 自带简化版 Zookeeper,配置文件在
config/zookeeper.properties(默认端口 2181)。
打开 cmd,进入 bin\windows 目录,启动
Zookeeper,并且指定其配置文件:
1 | zookeeper-server-start.bat ../../config/zookeeper.properties |
新打开一个 cmd,进入 bin\windows 目录,启动
Kafka(配置文件 config/server.properties 中默认关联
Zookeeper 地址 localhost:2181),并且指定其配置文件:
1 | kafka-server-start.bat ../../config/server.properties |
但是这种情况,在我这个版本里,是没有zookeeper-server-start.bat等的文件,也就是说,目前新版本 Kafka 是没有内置 Zookeeper 启动脚本的
Kafka 从 3.0.0 版本开始,为了推动 KRaft 模式(无
Zookeeper)成为主流,默认移除了自带的 Zookeeper
启动脚本(包括 zookeeper-server-start.bat
和相关配置)。
我的 4.1.0 版本属于高版本,因此 bin/windows
目录中不再包含 Zookeeper 的启动脚本,这意味着:
若要使用 Zookeeper 模式,需要单独下载 Zookeeper 并手动启动(不能再依赖 Kafka 自带的简化版 Zookeeper);
推荐直接使用 KRaft 模式(无需 Zookeeper,步骤更简单,也是 Kafka 官方主推的模式)。
KRaft 模式
无需依赖 Zookeeper,直接通过 Kafka 自身的 KRaft 协议管理元数据,步骤如下:
打开 cmd,进入 Kafka 的 bin\windows 目录:
1 | cd D:\kafka_2.13-4.1.0\bin\windows |
执行命令生成唯一集群 ID(记下来,后续用):
1 | kafka-storage.bat random-uuid |

在 Kafka 目录下创建数据存储文件夹(例如
D:\kafka_2.13-4.1.0\data)。
执行格式化命令(替换 <你的集群ID> 为上一步 生成的
ID):
1 | kafka-storage.bat format -t <你的集群ID> -c ../../config/kraft/server.properties |
成功会显示 Formatting completed successfully。
但是我好像没成功
 什么情况,就是说,这个错误是因为在 KRaft
模式下,
什么情况,就是说,这个错误是因为在 KRaft
模式下,server.properties 配置文件中缺少
控制器集群相关的关键配置,导致格式化存储时无法确认集群初始化方式。具体来说,controller.quorum.voters
参数未设置,而系统需要你明确指定集群的初始化模式。
KRaft 模式下,Kafka 集群由 控制器(Controller) 和
broker 组成,需要通过配置指定控制器节点信息。当
controller.quorum.voters
未配置时,格式化存储必须通过命令行参数明确初始化方式(单机模式、初始控制器列表等)。
如果你只是在本地启动一个单节点
Kafka(测试用),最简单的方式是在格式化命令中添加
--standalone 参数(表示单机模式),控制器配置。
1 | kafka-storage.bat format -t uuid -c server.properties位置 --standalone |
修改config/kraft/server.properties
1 | # 表示此节点,既是broker又可以当controller |
初始化数据存储目录,格式化存储
1 | .\bin\windows\kafka-storage format -t 你的uuid -c ./config/kraft/server.properties |
哦草,我格式化过了

直接启动 Kafka 即可:
守护进程启动加-daemon 参数
1 | kafka-server-start.bat ../../config/server.properties |
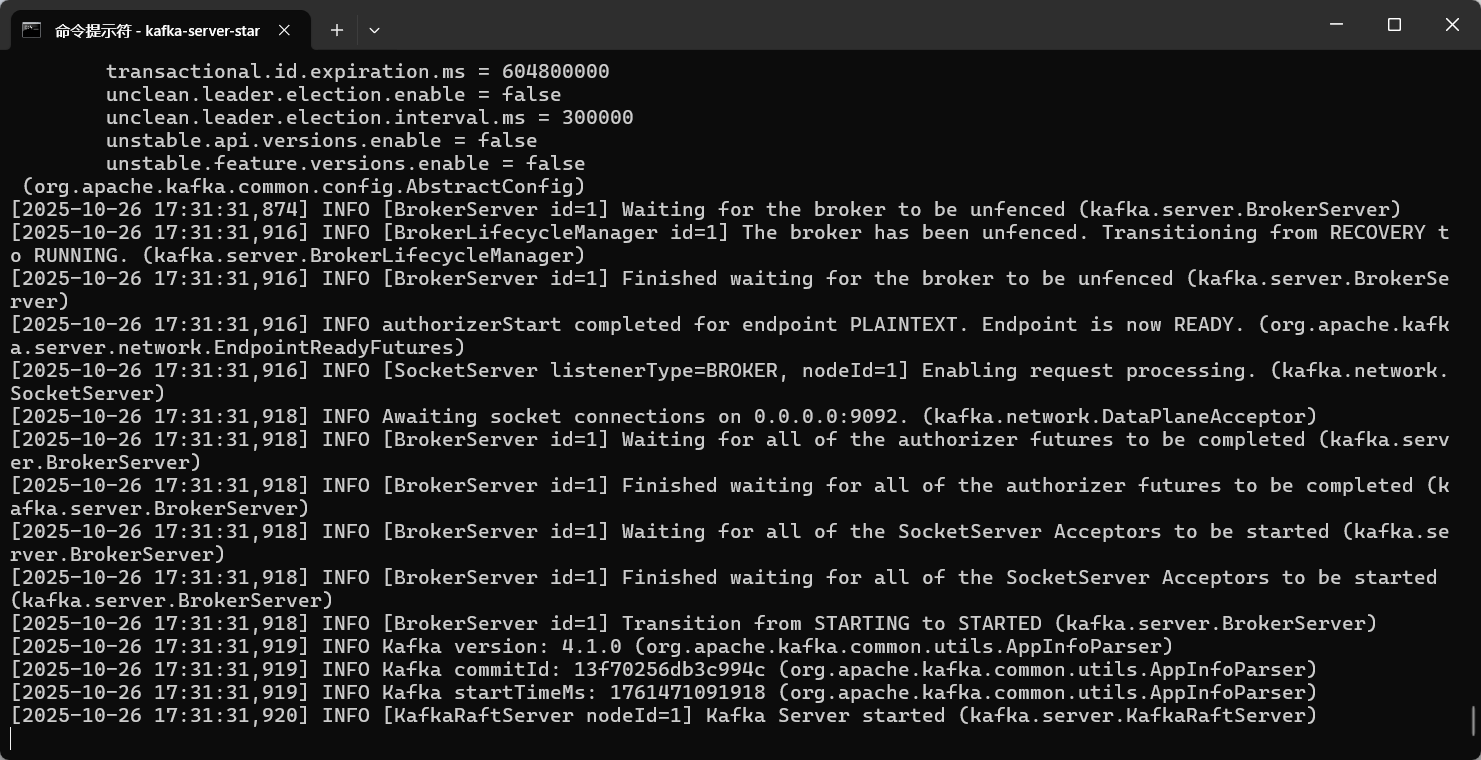
启动成功了
测试
保持启动窗口开启,并新打开 2-3 个 CMD
窗口(分别用于创建主题、发送消息、消费消息),所有窗口都先进入
Kafka 的 bin\windows 目录:
在第一个 CMD 窗口中,执行以下命令创建一个名为 test-topic
的主题(单分区、单副本,适合测试):
1 | kafka-topics.bat --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 |
- 参数说明:
--bootstrap-server localhost:9092:指定 Kafka 服务地址(默认端口 9092)。--partitions 1:主题的分区数(测试用 1 即可)。--replication-factor 1:副本数(单机环境只能设为 1)。

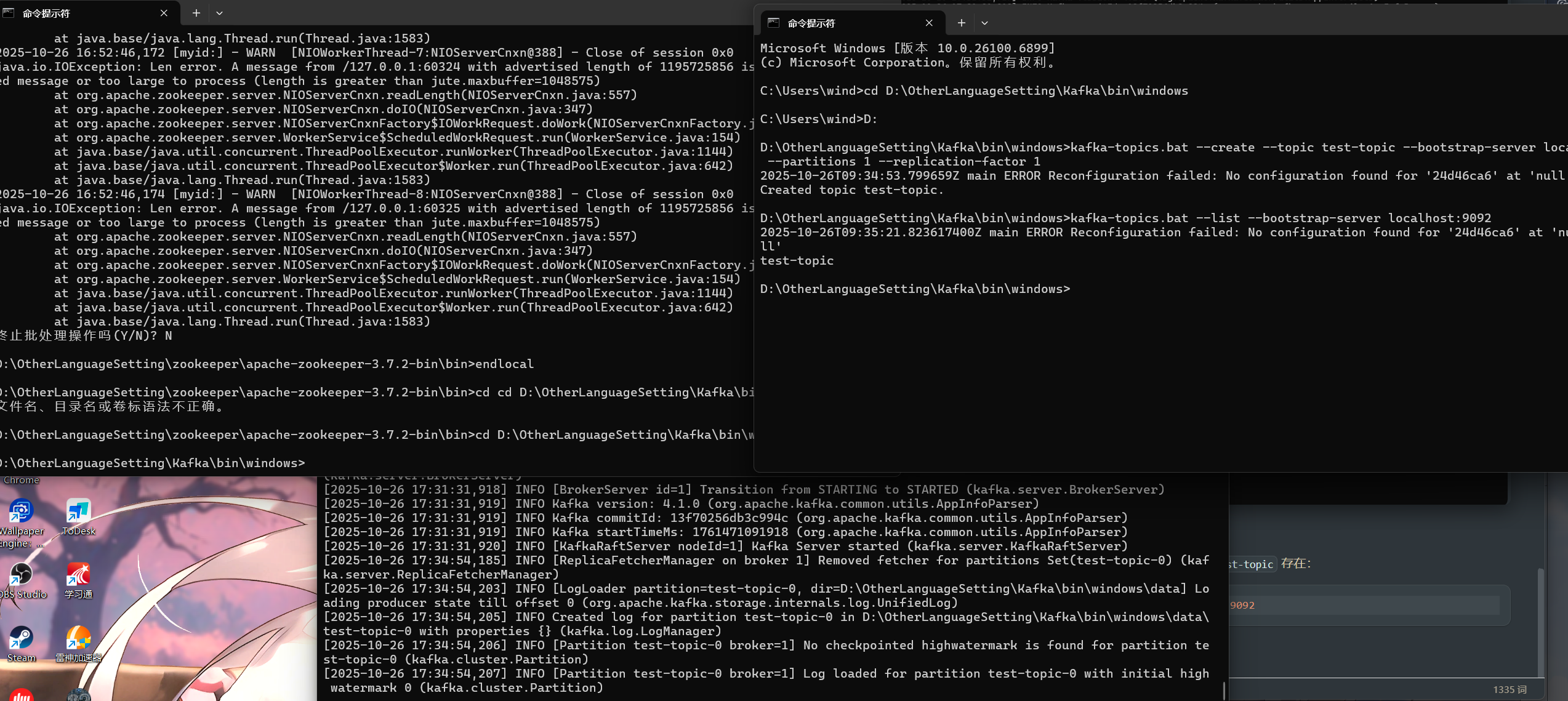
然后查看主题是否创建成功
在同一窗口或新窗口中,执行以下命令列出所有主题,确认
test-topic 存在:
1 | kafka-topics.bat --list --bootstrap-server localhost:9092 |
启动消费者接收消息,在第二个 CMD 窗口中,启动一个消费者,监听
test-topic 主题的消息:
1 | kafka-console-consumer.bat --topic test-topic --bootstrap-server localhost:9092 --from-beginning |
在第三个 CMD 窗口中,启动一个生产者,向 test-topic
主题发送消息:
1 | kafka-console-producer.bat --topic test-topic --bootstrap-server localhost:9092 |
启动后,会显示 > 提示符,此时可以输入任意消息(例如
Hello Kafka!、这是一条测试消息),每输入一条按回车发送。


说明消息从生产者成功发送到 Kafka 集群,并被消费者正常接收,测试通过
乱码不要紧,默认 utf8 导致的)
若需清理测试数据,可在 CMD 窗口中执行以下命令删除主题:
1 | kafka-topics.bat --delete --topic test-topic --bootstrap-server localhost:9092 |






