
介绍 Redis
REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
Redis 简介
Redis(Remote Dictionary Server)是一个开源的内存数据库,遵守 BSD 协议,它提供了一个高性能的键值(key-value)存储系统,常用于缓存、消息队列、会话存储等应用场景。
- 性能极高:Redis 以其极高的性能而著称,能够支持每秒数十万次的读写操作24。这使得Redis成为处理高并发请求的理想选择,尤其是在需要快速响应的场景中,如缓存、会话管理、排行榜等。
- 丰富的数据类型:Redis 不仅支持基本的键值存储,还提供了丰富的数据类型,包括字符串、列表、集合、哈希表、有序集合等。这些数据类型为开发者提供了灵活的数据操作能力,使得Redis可以适应各种不同的应用场景。
- 原子性操作:Redis 的所有操作都是原子性的,这意味着操作要么完全执行,要么完全不执行。这种特性对于确保数据的一致性和完整性至关重要,尤其是在高并发环境下处理事务时。
- 持久化:Redis 支持数据的持久化,可以将内存中的数据保存到磁盘中,以便在系统重启后恢复数据。这为 Redis 提供了数据安全性,确保数据不会因为系统故障而丢失。
- 支持发布/订阅模式:Redis 内置了发布/订阅模式(Pub/Sub),允许客户端之间通过消息传递进行通信。这使得 Redis 可以作为消息队列和实时数据传输的平台。
- 单线程模型:尽管 Redis 是单线程的,但它通过高效的事件驱动模型来处理并发请求,确保了高性能和低延迟。单线程模型也简化了并发控制的复杂性。
- 主从复制:Redis 支持主从复制,可以通过从节点来备份数据或分担读请求,提高数据的可用性和系统的伸缩性。
- 应用场景广泛:Redis 被广泛应用于各种场景,包括但不限于缓存系统、会话存储、排行榜、实时分析、地理空间数据索引等。
- 社区支持:Redis 拥有一个活跃的开发者社区,提供了大量的文档、教程和第三方库,这为开发者提供了强大的支持和丰富的资源。
- 跨平台兼容性:Redis 可以在多种操作系统上运行,包括 Linux、macOS 和 Windows,这使得它能够在不同的技术栈中灵活部署。
Redis 与其他 key-value 存储有什么不同
Redis 与其他 key-value 存储系统的主要区别在于其提供了丰富的数据类型、高性能的读写能力、原子性操作、持久化机制、以及丰富的特性集。
以下是 Redis 的一些独特之处:
- 丰富的数据类型:Redis 不仅仅支持简单的 key-value 类型的数据,还提供了 list、set、zset(有序集合)、hash 等数据结构的存储。这些数据类型可以更好地满足特定的业务需求,使得 Redis 可以用于更广泛的应用场景。
- 高性能的读写能力:Redis 能读的速度是 110000次/s,写的速度是 81000次/s。这种高性能主要得益于 Redis 将数据存储在内存中,从而显著提高了数据的访问速度。
- 原子性操作:Redis 的所有操作都是原子性的,这意味着操作要么完全执行,要么完全不执行。这种特性对于确保数据的一致性和完整性非常重要。
- 持久化机制:Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,以便在系统重启后能够再次加载使用。这为 Redis 提供了数据安全性,确保数据不会因为系统故障而丢失。
- 丰富的特性集:Redis 还支持 publish/subscribe(发布/订阅)模式、通知、key 过期等高级特性。这些特性使得 Redis 可以用于消息队列、实时数据分析等复杂的应用场景。
- 主从复制和高可用性:Redis 支持 master-slave 模式的数据备份,提供了数据的备份和主从复制功能,增强了数据的可用性和容错性。
- 支持 Lua 脚本:Redis 支持使用 Lua 脚本来编写复杂的操作,这些脚本可以在服务器端执行,提供了更多的灵活性和强大的功能。
- 单线程模型:尽管 Redis 是单线程的,但它通过高效的事件驱动模型来处理并发请求,确保了高性能和低延迟。
Redis的安装
下载地址:https://github.com/redis-windows/redis-windows/releases。
下载完了解压就行,然后配一下环境变量,把 redis 的目录加进去
启动命令如下
1 | redis-server.exe redis.windows.conf |
介绍 NoSQL
什么是 NoSQL,特点是什么
要学习 Redis,首先理解 NoSQL 的核心概念和特点非常重要,因为 Redis 是 NoSQL 数据库中最具代表性的产品之一。
NoSQL 的全称是 “Not Only SQL”(不仅仅是 SQL),它是一类非关系型数据库的统称。与传统的关系型数据库(如 MySQL、Oracle)不同,NoSQL 不依赖于固定的表结构(Schema),也不强制遵循关系模型(如外键关联),而是采用更灵活的数据模型来存储和管理数据。
核心定位:NoSQL 并非要取代关系型数据库,而是作为其补充,用于解决关系型数据库在特定场景下的瓶颈(如高并发、海量数据、灵活结构等)。
NoSQL 的兴起与互联网的快速发展密切相关。传统关系型数据库在以下场景中逐渐暴露出不足:
- 海量数据存储:随着用户和业务增长,数据量从 GB 级飙升到 TB 甚至 PB 级,关系型数据库的单表性能瓶颈明显。
- 高并发读写:如社交平台、电商秒杀等场景,需要每秒处理数万甚至数十万请求,关系型数据库的锁机制(表锁、行锁)会成为瓶颈。
- 灵活的数据结构:互联网业务需求多变(如商品属性、用户行为等),关系型数据库的固定 Schema(表结构)难以快速适配。
- 分布式扩展:关系型数据库的 “垂直扩展”(升级服务器配置)成本高,而 “水平扩展”(多机集群)实现复杂(如分库分表需额外工具)。
为解决这些问题,NoSQL 数据库应运而生,它通过简化数据模型、优化分布式架构,在性能、扩展性和灵活性上做出了针对性设计。
与关系型数据库相比,NoSQL 的核心特点可以总结为 “灵活、高效、可扩展”,具体表现为:
| 对比维度 | 关系型数据库(如 MySQL) | NoSQL 数据库(如 Redis) |
|---|---|---|
| 数据模型 | 基于表结构(行列),严格遵循 Schema | 多样化(键值、文档、列族等),Schema 灵活 |
| 关系处理 | 支持外键、JOIN 等复杂关系 | 弱化关系,通常不支持 JOIN(需应用层处理) |
| 事务支持 | 强事务(ACID 特性) | 多数支持弱事务(BASE 理论),部分支持强事务(如 Redis 的 Multi) |
| 扩展性 | 垂直扩展为主,水平扩展复杂 | 天然支持水平扩展(分片、集群) |
| 查询能力 | 支持复杂 SQL 查询(多表关联、聚合等) | 查询能力较简单,依赖特定 API |
| 适用场景 | 结构化数据、强事务需求(如金融交易) | 非结构化数据、高并发、海量数据(如缓存、日志) |
NoSQL的分类
NoSQL 并非单一类型的数据库,而是根据数据模型的不同分为四大类。其中,Redis 属于 “键值存储” 类型,这是你学习 Redis 的核心定位。
1. 键值存储(Key-Value)
- 数据模型:以 “键(Key)- 值(Value)” 对存储数据,类似字典。Key 是唯一标识,Value 可以是字符串、数字、二进制等(Redis 的 Value 支持更复杂的结构,如列表、哈希等)。
- 特点:查询速度极快(O (1) 复杂度),适合简单的读写操作。
- 代表产品:Redis、Memcached、RocksDB。
- 典型场景:缓存(如 Redis 缓存热点数据)、会话存储(如用户登录状态)、计数器(如点赞数)。
2. 文档存储(Document)
- 数据模型:以 “文档” 为单位存储,文档格式通常是 JSON/BSON(类似字典的嵌套结构),支持复杂的嵌套字段。
- 特点:Schema 灵活(同一集合的文档可以有不同字段),支持对文档内字段的查询。
- 代表产品:MongoDB、CouchDB。
- 典型场景:内容管理(如博客、新闻)、电商商品信息(不同商品属性差异大)。
3. 列族存储(Column-Family)
- 数据模型:以 “列族” 为单位组织数据,每个列族包含多个列,类似 “二维表的垂直拆分”,适合按列查询。
- 特点:高写入性能,适合海量数据的离线分析。
- 代表产品:HBase、Cassandra。
- 典型场景:日志存储、时序数据(如监控指标)、大数据分析。
4. 图存储(Graph)
- 数据模型:以 “节点(Node)” 和 “边(Edge)” 存储数据,专注于描述实体间的关系(如社交网络中的 “好友关系”)。
- 特点:高效处理多对多关系,支持复杂的路径查询。
- 代表产品:Neo4j、JanusGraph。
- 典型场景:社交网络(好友推荐)、知识图谱(如百度百科的关联关系)。
Redis数据库的结构
Redis 是一种基于内存的键值(Key-Value)型 NoSQL 数据库
Redis 的核心是 “键值对”,但它的 Value 支持多种复杂数据结构,这是其区别于普通键值数据库(如 Memcached)的核心优势。
- 键(Key)的特点:
- 类型固定:Key 只能是字符串(String),且最大长度不超过 512MB。
- 唯一性:每个 Key 在 Redis 中是唯一的,类似关系型数据库的 “主键”。
- 命名规范:通常用 “业务:对象:ID: 属性”
的格式命名(如
user:100:name),便于管理。
值(Value)的 5 种基本数据结构(核心!):
Redis 的 Value 支持多种结构,每种结构对应不同的使用场景:
| 数据结构 | 说明 | 典型场景 |
|---|---|---|
| 字符串(String) | 最简单的键值对,Value 可以是文本、数字或二进制(如图片) | 缓存用户信息、计数器(点赞数)、分布式锁 |
| 哈希(Hash) | 类似 JSON 对象,由多个 “字段 - 值” 对组成(Field-Value) | 存储对象属性(如用户的姓名、年龄、性别) |
| 列表(List) | 有序的字符串集合,支持两端插入 / 删除,可看作 “双向链表” | 消息队列、最新消息列表(如朋友圈动态) |
| 集合(Set) | 无序的字符串集合,自动去重,支持交集、并集等运算 | 标签(如文章标签)、好友关系(共同好友) |
| 有序集合(Sorted Set) | 类似 Set,但每个元素关联一个 “分数(Score)”,按分数排序 | 排行榜(如游戏积分排名)、带权重的消息队列 |
Redis 内部通过 “字典(Dict)” 管理所有键值对,类似 Python 的字典或 Java 的 HashMap。
顶层结构:Redis 服务器维护一个全局字典(
redisDb结构中的dict),所有 Key-Value 对都存储在这个字典中。- 字典的 Key 是字符串对象(
robj结构,类型为OBJ_STRING)。 - 字典的 Value 是多态对象(
robj结构),根据实际类型指向不同的数据结构(如字符串、哈希表等)。
- 字典的 Key 是字符串对象(
Value 的底层实现(优化细节):
Redis 会根据数据量自动选择更高效的底层结构(“编码转换”),例如:
- 字符串(String):短字符串用
embstr编码(内存连续),长字符串用raw编码。 - 哈希(Hash):元素少的时候用 “压缩列表(ZipList)”,多的时候用 “哈希表(HashTable)”。
- 列表(List):元素少的时候用 “压缩列表”,多的时候用 “双向链表(LinkedList)”。这种设计让 Redis 在不同数据规模下都能保持高性能。
- 字符串(String):短字符串用
用一个表格直观感受 Redis 结构的差异:
| 维度 | 关系型数据库(如 MySQL) | Redis |
|---|---|---|
| 数据组织 | 表(Table)→ 行(Row)→ 列(Column) | 数据库(DB)→ 键值对(Key-Value)→ Value 多结构 |
| 结构约束 | 严格 Schema(表结构固定) | 无 Schema,Value 结构灵活 |
| 关系处理 | 支持外键、JOIN 关联 | 无内置关系,需通过应用层维护 |
| 存储位置 | 主要在磁盘 | 主要在内存(可持久化到磁盘) |
AnotherRedisDesktopManager
以 AnotherRedisDesktopManager 这种可视化工具理解 Redis 结构
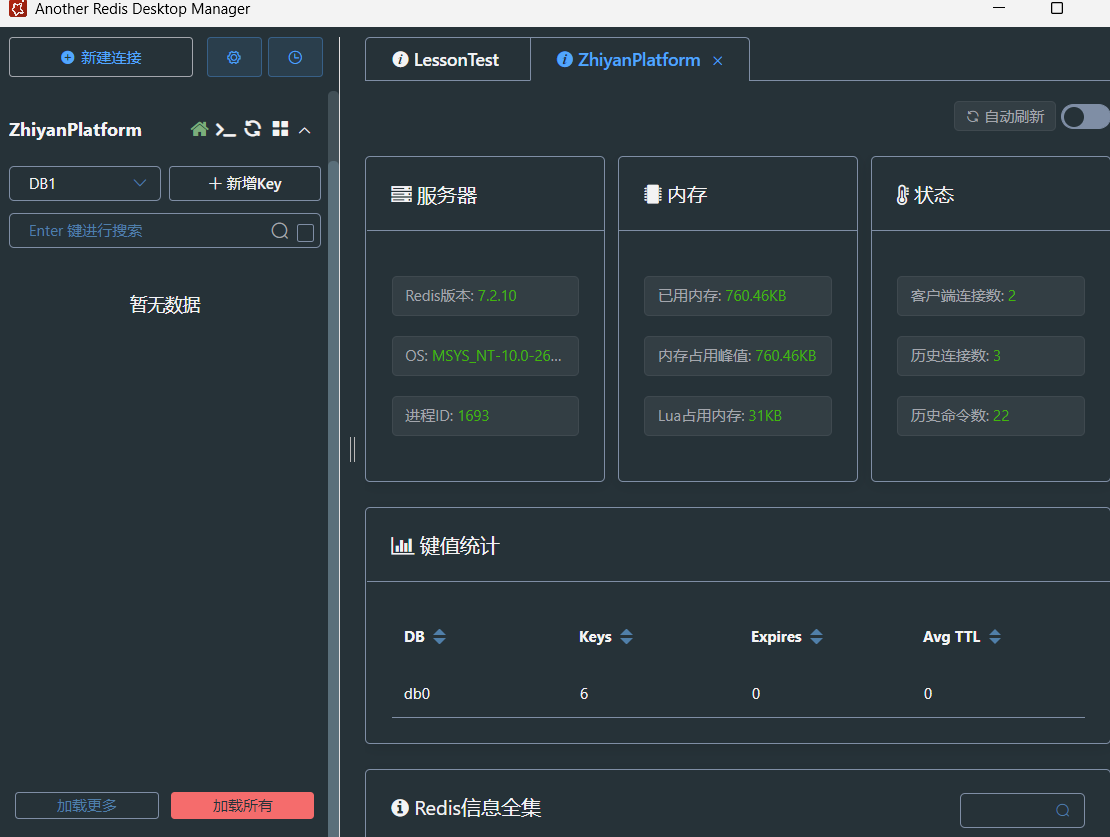
Redis 是 C/S(客户端 - 服务器)架构,客户端(如这个可视化工具、代码中的 Redis 客户端库)需要通过 IP + 端口 + 密码(可选) 连接到 Redis 服务器。界面中 “新建连接” 就是用于配置这些信息,建立与 Redis 服务的通信。
Redis 支持多个逻辑数据库,默认用数字
0 - 15 标识(共 16 个),这是 Redis 内置的 “命名空间”
机制,用于隔离不同业务的数据(类似关系型数据库的
“库”,但更轻量)。每个数据库之间关系如下
- 相互独立:每个
DB是独立的键值空间,DB1的key和DB2的key互不干扰。 - 切换方式:客户端通过
SELECT <dbid>命令切换数据库(如SELECT 1切换到DB1)。 - 默认行为:Redis 客户端默认连接
DB0,若需操作其他DB,需显式切换。
实际上,DB 数量可通过 Redis 配置文件
redis.conf 中的 databases
参数修改,但官方默认且推荐保持 16 个






