
什么是布隆过滤器
布隆过滤器简介
首先,布隆过滤器不是 redis
特有的东西,它是一种通用的数据结构,日常开发中,Redis 4.0
的时候官方提供了插件机制,布隆过滤器正式登场,使用
redisbloom 插件版本,但是 8.0.0 中 redis
正式添加了布隆过滤器。
布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,它是一种 space efficient 的概率型数据结构,用于判断一个元素是否在集合中。
当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在。
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,本质是 “一个二进制数组 + 多个哈希函数” 的组合。它的核心作用是:快速判断一个元素 “是否在集合中”,特点是 “存在误判(可能把不在的误判为在),但绝不会漏判(不在的一定能判断出不在)”,且占用内存极小。
其中,我们可能想到能用哈希表用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的 1/8 或 1/4 的空间复杂度就能完成同样的问题。
布隆过滤器可以插入元素,但不可以删除已有元素。
其中的元素越多,false positive rate(误报率)越大,但是 false negative (漏报)是不可能的。
为什么选布隆过滤器
如果需要在很大很大量的数据中去判断没有一个东西,很适合
- 超省内存:存储的是二进制位(1 个位置仅占 1 bit),例如存储 1 亿个元素,仅需约 12MB 内存(传统数组需几十 GB)。
- 查询极快:仅需执行
k次哈希计算和数组查询,时间复杂度是O(k)(k通常是 3~10,几乎可视为常数时间)。 - 支持海量数据:即使数据量过亿,也能保持高效的读写性能,适合 Redis 这类内存数据库。
必须注意的问题
- 存在误判率:无法 100% 准确判断 “元素存在”,误判率与
m(数组长度)和k(哈希函数数量)相关 ——m越大、k越合理,误判率越低(通常可控制在 0.1% 以下)。 - 不支持删除元素:一旦把数组位置从
0改为1,无法再改回0(因为多个元素可能共享同一个位置,删除会影响其他元素的判断)。 - 需提前规划参数:使用前要确定
m和k(需根据 “预计存储的元素数量n” 和 “可接受的误判率p” 计算,有现成公式)。
布隆过滤器的数据结构
上面说了,布隆过滤器本质是 “一个二进制数组 + 多个哈希函数” 的组合成的数据结构
相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。
这种数据结构也就是如此,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。

这是存储数据的 “载体”,本质是一个只存 0 和
1 的连续内存块,每个位置称为一个 “bit 位”(1 bit = 1
个二进制位)。所以说,这种结构奠定了它的大小会比较小。
那么一组独立的哈希函数是如何体现的
这是 “映射元素到数组” 的 “工具”,需要满足两个要求:
- 独立性:多个哈希函数的计算逻辑完全不同,避免同一元素被映射到重复的 bit 位(减少误判)。
- 均匀性:能将任意输入的元素(如字符串、数字)均匀分布到二进制数组的各个位置,避免某段 bit 位过度被标记(防止 “哈希碰撞” 集中导致误判率上升)。
- 常见选择:
redisbloom插件默认使用 MurmurHash 系列(如 MurmurHash2),这类哈希函数计算速度快、分布均匀,适合布隆过滤器场景。
我们来讨论布隆过滤器的运行过程来理解
添加数据
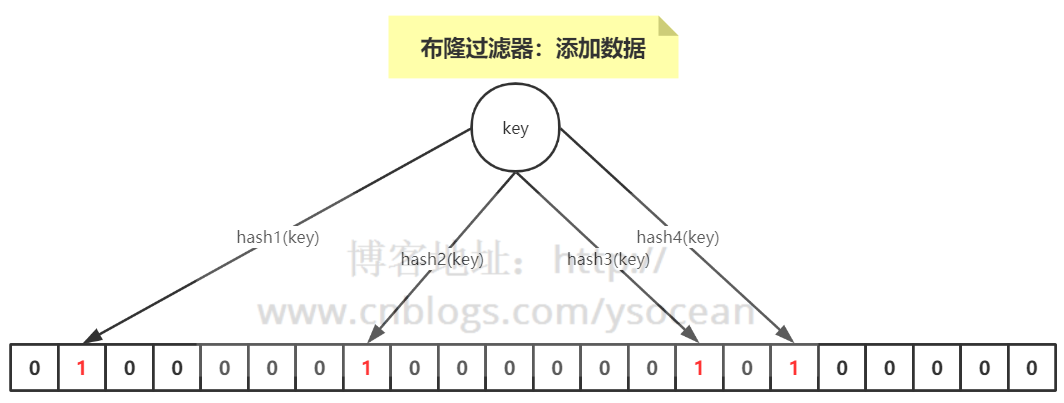
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对要添加的元素值 key 进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
比如,下图 hash1(key)=1,那么在第2个格子将0变为1(数组是从0开始计数的),hash2(key)=7,那么将第8个格子置位1,依次类推。
那么一组独立的哈希函数是什么情况呢?
我们考虑 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
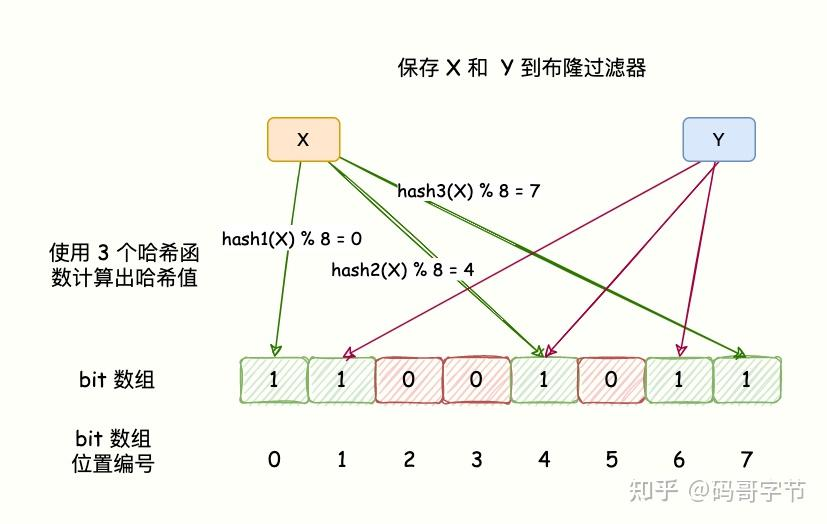
元素存在性判断
知道了如何向布隆过滤器中添加一个数据,那么新来一个数据,我们如何判断其是否存在于这个布隆过滤器中呢?
我们只需要将这个新的数据通过上面自定义的几个哈希函数,分别算出各个值,然后看其对应的地方是否都是1
如果存在一个不是1的情况,那么我们可以说,该新数据一定不存在于这个布隆过滤器中。
所以说,当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值可能在布隆过滤器中,如果存在一个值不为 1,说明该元素一定不在布隆过滤器中。
反过来说,如果通过哈希函数算出来的值,对应的地方都是1,那么我们能够肯定的得出:这个数据一定存在于这个布隆过滤器中吗?
貌似不行,也许你这个本来应该是 0 的地方,是有其他的哈希函数计算得到 1 了,在计算的时候,把你算进去了。
布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在。
那么一组的计算情况就是这样考虑,当我们需要检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 可能存在,否则一定不存在。
这种结构,必然快,必然小,但是,存储数据越多,越容易产生哈希碰撞,越容易误判,而且这种结构,存进去了一定是没法反过来删除的。
因为二进制数组中的每个 bit 位不是 “专属” 某个元素的 —— 多个元素的哈希映射可能指向同一个 bit 位,布隆过滤器的设计初衷就是 “只增不删”,适合无需删除元素的场景
最后来看一个完整的例子
元素添加:3 步完成 bit 位标记
假设要向布隆过滤器中添加元素
user:123,数组长度m=1000,哈希函数数量k=3(hash1、hash2、hash3):- 哈希计算:用 3 个哈希函数分别计算
user:123的哈希值,得到 3 个整数(例如hash1=156、hash2=489、hash3=722)。 - 索引映射:对每个哈希值做
“取模运算”,得到对应的数组索引(
156%1000=156、489%1000=489、722%1000=722)。 - bit 位置 1:将数组中 156、489、722 这 3 个索引的
bit 位从
0改为1(若已为1,则不做任何操作)。
- 哈希计算:用 3 个哈希函数分别计算
此时数组的这 3 个位置就代表 “元素 user:123
已被标记”。
元素查询:3 步判断 “是否存在”
假设要查询元素
user:456是否在布隆过滤器中,流程与添加对称:- 哈希计算:用同样的 3 个哈希函数计算
user:456的哈希值,得到 3 个整数(例如hash1=233、hash2=489、hash3=722)。 - 索引映射:取模后得到索引
233、489、722。 - bit 位检查:
若这 3 个索引的 bit 位有任何一个是
0:直接判断 “user:456一定不在集合中”(因为添加过的元素会把所有映射位置置 1,只要有一个位置是 0,说明从未添加过)。若这 3 个索引的 bit 位全是
1:判断 “user:456可能在集合中”(存在误判 —— 其他元素的映射可能刚好把这 3 个位置置 1,例如user:123已把 489、722 置 1,若另一个元素user:789把 233 置 1,则user:456会被误判为存在)。
- 哈希计算:用同样的 3 个哈希函数计算
redis 是如何管理二进制数组的
redisbloom
插件会将布隆过滤器的二进制数组封装成一个独立的 Redis 数据类型(区别于
String、Hash 等基础类型),其内存存储有两个关键设计:
二进制数组的 “分块存储”
为了支持大容量的二进制数组(例如 10 亿 bit),Redis 不会把数组作为一个整体连续存储,而是拆分成多个 “块”(Chunk),每个块的大小固定(通常是 2KB 或 4KB,与操作系统页大小对齐)。
- 好处:减少内存碎片,提升读写效率(修改某个 bit 位时,只需加载对应的块,无需加载整个数组)。
哈希函数结果的 “取模映射”
当用哈希函数计算出元素的哈希值(通常是 64 位或 128 位整数)后,需要通过 “取模运算” 将其映射到二进制数组的具体索引位置,公式如下:
1 | 索引位置 = 哈希值 % 数组总长度(m) |
- 示例:若数组长度
m=1000,某元素的哈希值为2025,则映射到2025 % 1000 = 25号 bit 位。 - 注意:由于哈希函数输出是均匀分布的,取模后每个 bit 位被映射到的概率基本一致,保证数组标记的 “均匀性”。
Redis如何实现布隆过滤器
我们在前面说了,redis 存在一个神奇的数据结构就是,bitmaps
Bitmaps 提供了一套命令用来操作字符串中的每一个位
布隆过滤器的核心是通过一个位数组(Bitmap) 和多个哈希函数实现快速存在性判断。其原理上面已经说过了。
Redis 的 Bitmap 提供了对位的直接操作能力,是实现布隆过滤器的底层基础。
Redis 提供了以下关键命令用于操作 Bitmap,支撑布隆过滤器的实现:
设置位值(
setbit)语法:
setbit key offset value功能:将
key对应的 Bitmap 中,第offset位(从 0 开始)设置为value(0 或 1),返回该位的原始值。1
2
3set k1 "ergoutree" # 存储字符串"big"(底层为Bitmap)
setbit k1 15 1
get k1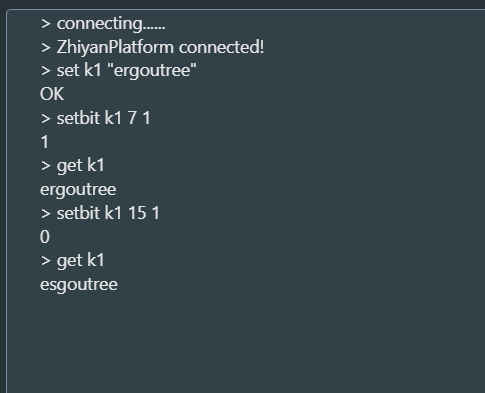
可以看到修改了字符串的二进制位,取出来的完全是两个字符串对象
获取位值(
getbit)语法:
getbit key offset功能:返回
key对应的 Bitmap 中第offset位的值(0 或 1)。1
2getbit k1 0 # 返回0("c"的二进制第0位为0)
getbit k1 1 # 返回1("c"的二进制第1位为1)上面演示过了
统计位为 1 的数量(
bitcount)语法:
bitcount key [start end]功能:统计
key对应的 Bitmap 中,值为 1 的位的总数。start和end指字节索引(非位索引),默认统计全部。1
2bitcount k1 # 总共有41个1(3个字符的二进制中1的总和)
bitcount k1 0 0 # 统计第0个字节中1的数量,返回3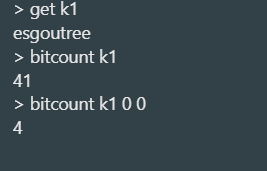
布隆过滤器的使用场景
先理解什么地方使用布隆过滤器是好的
布隆过滤器的核心价值在于用极小的内存和极快的速度,解决 “元素是否存在” 的判断问题,尤其适合 “海量数据”“允许一定误判” 的场景。
选择用布隆过滤器前,可参考这两个核心条件:
- 业务能接受一定的 “数据误判率”(通常可控制在 0.1% 以下,具体场景需评估);
- 需要处理 “海量数据”,且对 “内存占用” 和 “查询速度” 要求极高。
缓存穿透防护(数据库 / 缓存层)
用户请求一个不存在的缓存 Key,导致请求直接穿透到数据库,引发数据库压力飙升。
完全感觉这个就是为布隆过滤器量身打造的
把所有存在的缓存 Key提前存入布隆过滤器。当请求到达时,先通过布隆过滤器判断 Key 是否 “可能存在”:
- 若布隆过滤器返回 “不存在”,直接返回空结果,避免穿透数据库;
- 若返回 “可能存在”,再去缓存 / 数据库查询,保证流程正确性。
例如,电商平台的商品缓存,用布隆过滤器存储所有有效商品 ID,拦截 “无效商品 ID” 的请求。
海量数据去重(避免重复处理)
场景:处理海量数据时(如日志、用户行为、爬虫数据),需要快速判断 “某条数据是否已处理过”。
布隆过滤器的作用:
每处理一条新数据,先通过布隆过滤器判断是否 “已存在”:
- 若 “不存在”,则处理该数据,并将其加入布隆过滤器;
- 若 “可能存在”,则跳过(接受极低的误判率,避免重复处理)。
举例:
- 日志系统:过滤重复的日志条目;
- 爬虫:判断某 URL 是否已爬取过,避免重复请求。
防止消息队列重复消费
- 场景:分布式消息队列中,消费者可能因网络波动等原因 “重复消费同一条消息”,导致业务逻辑重复执行(如重复下单、重复扣款)。
- 布隆过滤器的作用:用布隆过滤器存储已消费的消息
ID,消费者处理消息前,先判断 ID 是否 “已存在”:
- 若 “不存在”,则处理消息,并将 ID 加入布隆过滤器;
- 若 “可能存在”,则跳过消费,避免重复执行。
- 举例:订单消息队列中,用布隆过滤器拦截重复的 “创建订单” 消息。
URL 黑白名单过滤(高效拦截)
- 场景:需要快速判断一个 URL 是否属于 “黑名单”(如恶意链接、广告链接)或 “白名单”(如可信资源)。
- 布隆过滤器的作用:
- 黑名单场景:把所有恶意 URL 存入布隆过滤器,请求到来时判断是否 “可能在黑名单”,若 “是” 则拦截;
- 白名单场景:把所有可信 URL 存入布隆过滤器,请求到来时判断是否 “可能在白名单”,若 “否” 则拦截。那还是黑名单靠谱一些
- 举例:浏览器插件拦截恶意广告 URL,或企业内网只允许白名单 URL 访问。
Redis实际操作使用布隆过滤器
Redis 实现布隆过滤器的底层就是通过 bitmap 这种数据结构,至于如何实现,这里就不重复造轮子了,介绍业界比较好用的一个客户端工具——Redisson。
直接使用 Bitmap 命令实现布隆过滤器需要手动处理哈希函数和位运算,而 Redisson 客户端已封装了布隆过滤器的实现,可直接使用。
Redisson 是用于在 Java 程序中操作 Redis 的库,利用Redisson 我们可以在程序中轻松地使用 Redis。
下面我们就通过 Redisson 来构造布隆过滤器。
引入 Redisson 依赖
1 | <dependency> |
代码实现:
1 | import org.redisson.Redisson; |
tryInit(long expectedInsertions, double falseProbability):初始化布隆过滤器,需指定预计插入元素数和可接受的误判率(误判率越低,所需位数组长度和哈希函数数量越多)。- 分布式场景:Redisson 支持分布式布隆过滤器,可应对单节点内存不足的问题,原理是将位数组分片存储在多个 Redis 节点。
除了 Redis,Google Guava 工具包也提供了本地布隆过滤器实现(适用于单节点场景),当你手头想用布隆过滤器处理小事的时候,而且此时与 Redis 无关的情况下,可以使用这个:
1 | <dependency> |
使用起来还是比较简单的
1 | import com.google.common.hash.BloomFilter; |
Guava 实现是本地内存的,不适合分布式系统,这算是它很大的缺陷了;Redis + Redisson 实现则适用于分布式场景,支持多节点共享布隆过滤器。






