
Redis的常用命令
Redis 的两种命令
Redis 有两种命令
在 Windows 的 cmd 命令提示符中,可以在不进入 Redis
内部终端的情况下执行 Redis
命令,一般格式是:redis-cli.exe [options] command [arguments]
,options 是连接相关的参数,command 是具体的
Redis 命令,arguments 是命令的参数。
关于这个部分的命令,常用的比较少,下面说的常用命令都是基于第二种
一般情况下,我们在 Redis 内部终端输入命令,要进入 Redis
内部终端,你需要先连接到 Redis
服务器,打开命令提示符,redis-server.exe redis.conf即可启动
。如果 Redis 已经启动,和MySQL 一样,Redis 也需要新建连接,在 Windows
环境下,可以进入 Redis 安装目录,之后使用如下格式的命令新建链接,执行
redis-cli.exe -h 127.0.0.1 -p 6379 (默认端口是 6379
,如果修改过请使用实际端口;-h
用于指定主机地址,-p 用于指定端口 ),如果 Redis
设置了密码,需要使用 -a 参数指定密码,如
redis-cli.exe -h 127.0.0.1 -p 6379 -a yourpassword
,连接成功后就进入了 Redis
内部终端,我们对Redis内部存储的数据基本都在这里操作
Redis keys 命令
下表给出了与 Redis 键相关的基本命令:
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | DEL key | 用于在 key 存在时删除 key |
| 2 | DUMP key | 序列化给定 key,并返回被序列化的值 |
| 3 | EXISTS key | 检查给定 key 是否存在 |
| 4 | EXPIRE key seconds | 为给定 key 设置过期时间,以秒计 |
| 5 | EXPIREAT key timestamp | 作用和 EXPIRE 类似,用于为 key 设置过期时间,不同在于接受的时间参数是 UNIX 时间戳 |
| 6 | PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计 |
| 7 | PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp)以毫秒计 |
| 8 | KEYS pattern | 查找所有符合给定模式(pattern)的 key |
| 9 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中 |
| 10 | PERSIST key | 移除 key 的过期时间,key 将持久保持 |
| 11 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间 |
| 12 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live) |
| 13 | RANDOMKEY | 从当前数据库中随机返回一个 key |
| 14 | RENAME key newkey | 修改 key 的名称 |
| 15 | RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey |
| 16 | SCAN cursor [MATCH pattern] [COUNT count] | 迭代数据库中的数据库键 |
| 17 | TYPE key | 返回 key 所储存的值的类型 |
| 18 | OBJECT subcommand [arguments …] | 提供关于 Redis 对象的内部信息,比如编码类型、引用计数等。例如
OBJECT ENCODING key 查看 key 对应值的编码 |
| 19 | RESTORE key ttl serialized-value [REPLACE] | 将序列化后的值反序列化并存储到 key 中,ttl 为过期时间(毫秒),若指定 REPLACE 且 key 存在则覆盖 |
| 20 | TOUCH key [key …] | 更新 key 的最后访问时间,若 key 不存在则不做操作 |
| 21 | UNLINK key [key …] | 异步地删除 key,在非阻塞的情况下释放内存,适合删除大键 |
| 22 | WAIT numreplicas timeout | 等待数据复制到指定数量的从节点,timeout 为超时时间(毫秒) |
| 23 | SCAN cursor [MATCH pattern] [COUNT count] | 从 cursor 位置开始,以 MATCH pattern 的规则进行遍历键,每次返回的键的数量为count |
服务器相关命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | INFO [section] | 获取服务器的各种信息和统计数值。如果指定 section ,则只返回对应部分的信息,比如 INFO SERVER 会返回服务器运行的相关信息,INFO MEMORY 会返回内存相关信息等。 |
| 2 | PING | 检查 Redis 服务器是否运行正常。如果服务器正常运行,会返回 PONG 。 |
| 3 | SHUTDOWN [NOSAVE / SAVE] | 关闭 Redis 服务器。使用 NOSAVE 选项时,不会进行持久化操作,直接关闭;使用 SAVE 选项时,会先执行持久化操作,再关闭服务器 。如果不指定选项,默认行为和 SAVE 类似,会先尝试进行持久化。 |
| 4 | BGSAVE | 在后台执行 SAVE 操作,将数据持久化到磁盘。该命令不会阻塞 Redis 服务器处理其他客户端请求。 |
| 5 | SAVE | 同步地将数据持久化到磁盘,执行期间会阻塞 Redis 服务器,直到持久化完成 。 |
| 6 | BGREWRITEAOF | 异步地重写 AOF(Append Only File)文件。AOF 文件用于记录 Redis 服务器执行的写命令,随着时间推移文件会变大,通过重写可以优化文件结构,减少文件体积 。 |
| 7 | CONFIG GET parameter | 获取 Redis 服务器的配置参数值。parameter 可以使用通配符 * 来获取多个参数,例如 CONFIG GET * 会返回所有配置参数及其值 。 |
| 8 | CONFIG SET parameter value | 设置 Redis 服务器的配置参数值。例如 CONFIG SET maxmemory 1073741824 可以设置 Redis 服务器的最大内存为 1GB 。 |
| 9 | SLAVEOF host port | 将当前 Redis 服务器设置为指定主机(host)和端口(port)的 Redis 服务器的从服务器 。 |
| 10 | ROLE | 返回当前 Redis 服务器的角色信息,如主服务器会返回 {“role”:“master”,“connected_slaves”:0,“master_replid”:“…”} ,从服务器会返回 {“role”:“slave”,“master_host”:“…”,“master_port”:…} 等。 |
| 11 | MONITOR | 实时监控 Redis 服务器接收到的所有命令请求,包括命令参数等信息 。 |
| 12 | SYNC | 旧版本用于从服务器和主服务器进行全量同步的命令,新版本已逐渐被 PSYNC 替代 。 |
| 13 | PSYNC replid offset | 用于从服务器和主服务器进行部分重同步或全量重同步,replid 是主服务器的复制 ID,offset 是从服务器的复制偏移量 。 |
| 14 | CLIENT LIST | 列出当前连接到 Redis 服务器的所有客户端的相关信息,如客户端的 ID、地址、已闲置时间等 。 |
| 15 | CLIENT KILL [IPADDR ip:port / ID client-id] | 关闭指定的客户端连接,可以通过 IP 地址和端口号(IPADDR ip:port 形式)或者客户端 ID(ID client-id 形式)来指定要关闭的客户端 。 |
Redis的基本数据类型
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:
| String | List | Hash | Set | Zset |
|---|---|---|---|---|
| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
字符串String
相关内容
String 是 Redis 中最简单同时也是最常用的一个数据类型。
String 类型在 Redis 中用于存储字符串值,String 是一种二进制安全的数据类型,可以用来存储任何类型的数据,对于字符串可以是简单的文本字符串,整数(例如 “123” ,Redis 可以对这种存储整数的字符串进行一些数学运算),JSON对象等类型,甚至可以是二进制数据(如图片、音频等数据的二进制形式 ,不过一般不建议在 Redis 中存储大体积二进制数据,因为 Redis 基于内存,内存成本较高)。
虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(Simple Dynamic String,SDS)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
而且 String 的数据结构是简单的 Key-Value 模型,Value
可以是字符串,也可以是数字。每个键key都与一个字符串值value相关联,且键必须是唯一的。
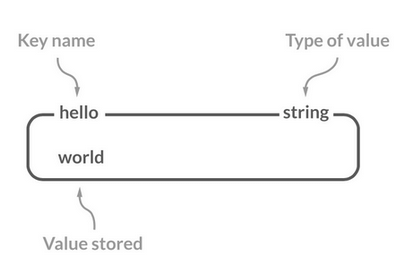
一个字符串类型的键允许存储的数据最大容量是 512MB,而且 Redis 字符串是字节序列。Redis 字符串是二进制安全的,这意味着他们有一个已知的长度没有任何特殊字符终止,所以你可以存储任何东西
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | SET key value [EX seconds] [PX milliseconds] [NXXX] | 设置指定键的值。EX seconds
用于设置键的过期时间,单位为秒;PX milliseconds
用于设置键的过期时间,单位为毫秒;NX
表示只有键不存在时才进行设置操作;XX
表示只有键已存在时才进行设置操作 |
| 2 | GET key | 获取指定键的值,如果键不存在,返回 (nil) |
| 3 | INCR key | 将存储在指定键中的整数值递增 1 。若键不存在,先将其初始化为 0 再递增,返回递增后的值。仅当值为整数时可使用,否则返回错误 |
| 4 | DECR key | 将存储在指定键中的整数值原子性地递减 1 。若键不存在,先将其初始化为 0 再递减,返回递减后的值。仅当值为整数时可使用,否则返回错误 |
| 5 | INCRBY key increment | 将指定键中的整数值原子性地增加指定的整数 increment
,返回增加后的结果。若键不存在,先将其初始化为 0
再执行操作。仅当值为整数时可使用,否则返回错误 |
| 6 | DECRBY key decrement | 将指定键中的整数值原子性地减少指定的整数 decrement
,返回减少后的结果。若键不存在,先将其初始化为 0
再执行操作。仅当值为整数时可使用,否则返回错误 |
| 7 | APPEND key value | 将给定的 value
追加到键对应值的末尾。若键不存在,先创建该键并将 value
设置为给定的值,返回追加后字符串的长度 |
| 8 | STRLEN key | 返回指定键对应值的字符串长度,若键不存在,返回 0 |
| 9 | SETEX key seconds value | 以秒为单位设置指定键的值,并设置键的过期时间。等价于
SET key value 与 EXPIRE key seconds
两个命令的组合操作 |
| 10 | PSETEX key milliseconds value | 以毫秒为单位设置指定键的值,并设置键的过期时间 |
| 11 | GETSET key value | 将指定键的值设置为 value
,并返回键在设置之前的旧值。若键不存在,返回 (nil)
并设置新值 |
| 12 | MSET key value [key value …] | 同时设置一个或多个键值对,所有给定键都会被设置,操作是原子性的,即要么所有键都设置成功,要么都不设置 |
| 13 | MGET key [key …] | 获取一个或多个键的值,返回一个包含所有给定键对应值的列表,若某个键不存在,对应位置返回
(nil) |
| 14 | SETNX key value | 只有在指定键不存在时,才设置键的值为 value
。若设置成功,返回 1 ;若键已存在,不进行设置操作,返回 0 |
应用场景
- 缓存:这是 String 类型最常见的应用场景。例如在 Web
应用中,将数据库查询结果缓存起来。当应用程序需要获取数据时,先从 Redis
中查找,如果存在则直接返回,减少对数据库的访问压力,提升系统性能。比如将用户信息(以
JSON 字符串形式存储)缓存起来,键可以是
user:123(假设 123 是用户 ID),值是该用户详细信息的 JSON 字符串。 - 计数器:利用 INCR、DECR
等命令可以很方便地实现计数器功能。例如统计网站的访问量,以一个键(如
page_view_count)来记录,每次有用户访问页面时,就执行INCR page_view_count命令 ;还可以用于记录微博的点赞数、评论数等。 - 分布式锁:通过 SET 命令的
SETNX key value(即Not eXists,只有在键不存在时才设置成功)选项来实现。例如多个进程或线程需要访问共享资源时,只有一个进程能成功设置某个特定键(代表锁),从而获得对资源的访问权限,其他进程等待或重试,直到获取到锁。但是这样存在一些缺陷,通常不建议这样实现分布式锁 - 存储配置信息:可以将一些应用的配置信息以键值对形式存储在 Redis 中,应用启动或运行过程中直接从 Redis 读取配置,并且修改 Redis 中的配置后,应用可以实时感知到变化并更新配置。
散列表Hash
相关内容
Redis 的 Hash(散列表)是一种键值对集合,类似于其他编程语言中的字典或哈希表结构。它允许将多个字段(field)和值(value)关联到同一个键(key)下,非常适合存储对象类数据
Hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 +
链表)。不过,Redis 的 Hash 做了更多优化。
Hash 更适合用于对象的存储,String 更适合字符串存储。
Hash 类型的特点:
- 每个 Hash 可以包含多个字段 - 值对,字段和值都是字符串类型
- 适合单个键下管理多个相关属性,节省内存空间
- 支持对单个字段进行操作,无需修改整个对象
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | HSET key field1 value1 field2 value2 … | 为指定哈希表设置一个或多个字段 - 值对。如果字段已存在,会覆盖旧值,返回设置成功的字段数量 |
| 2 | HGET key field | 获取哈希表中指定字段的值。如果字段或哈希表不存在,返回
(nil) |
| 3 | HMSET key field value [field value …] | 批量设置哈希表的多个字段 - 值对(Redis 4.0.0 后已废弃,建议使用 HSET 替代) |
| 4 | HMGET key field [field …] | 获取哈希表中多个指定字段的值,返回与字段顺序对应的 values
列表,不存在的字段返回 (nil) |
| 5 | HGETALL key | 返回哈希表中所有字段和值,以字段 - 值交替的列表形式呈现 |
| 6 | HEXISTS key field | 检查哈希表中是否存在指定字段,存在返回 1,不存在返回 0 |
| 7 | HDEL key field [field …] | 删除哈希表中一个或多个字段,返回成功删除的字段数量 |
| 8 | HLEN key | 返回哈希表中字段的数量,若哈希表不存在返回 0 |
| 9 | HKEYS key | 返回哈希表中所有字段的列表 |
| 10 | HVALS key | 返回哈希表中所有值的列表 |
| 11 | HINCRBY key field increment | 为哈希表中指定字段的整数值增加指定增量(increment 可正可负),返回增加后的结果。若字段不存在,先初始化为 0 再操作 |
| 12 | HINCRBYFLOAT key field increment | 为哈希表中指定字段的浮点数值增加指定增量,返回增加后的结果 |
| 13 | HSETNX key field value | 只有当哈希表中指定字段不存在时,才设置该字段的值,成功返回 1,失败返回 0 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的字段 - 值对,用于增量遍历大哈希表,避免 HGETALL 可能导致的阻塞 |
应用场景
- 存储对象数据:如用户信息(id、姓名、年龄、邮箱等),键可以是
user:1001,字段对应各属性 - 商品属性管理:存储商品的各类属性(价格、库存、规格等),便于单独更新某个属性
- 计数器集合:为不同维度的计数创建字段,如文章的阅读量、点赞数、评论数等
- 用户偏好设置:存储用户的各项配置信息,支持单独修改某项配置
列表List
相关内容
Redis 中的 List 其实就是链表数据结构的实现。
Redis 的 List(列表)是一种有序的字符串集合,允许存储多个字符串元素,并且元素可以重复,排序插入顺序。
许多高级编程语言都内置了链表的实现比如 Java 中的
LinkedList,但是 C 语言并没有实现链表,所以 Redis
实现了自己的链表数据结构。Redis 的 List
类型在底层采用双向链表或压缩列表实现,因此支持高效的首尾元素操作,适合构建队列、栈等数据结构,但是带来了一些额外的内存开销。
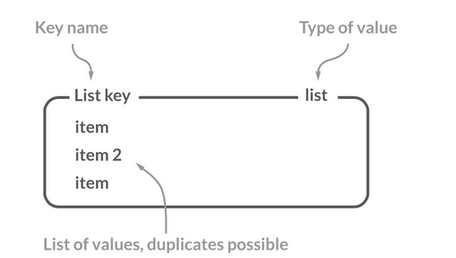
List 类型的特点:
- 元素按插入顺序排序,可通过索引访问
- 支持在列表的两端或指定位置插入 / 删除元素
- 列表可以包含重复元素
- 最多可存储 2^32 - 1 个元素
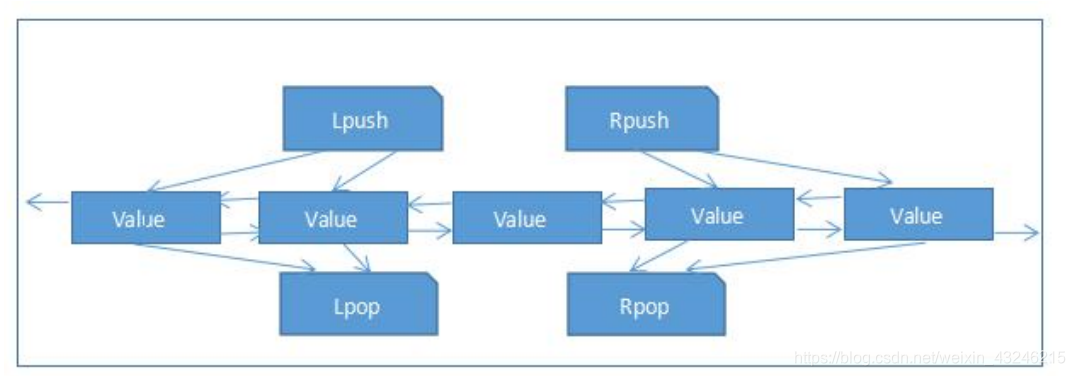
List 类型特别适合需要维护元素顺序且频繁在两端操作数据的场景,其阻塞命令为分布式环境下的同步操作提供了便利。
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | LPUSH key element1 element2 ….. | 在列表的左侧(头部)插入一个或多个元素,返回插入后列表的长度 |
| 2 | RPUSH key element1 element2 ….. | 在列表的右侧(尾部)插入一个或多个元素,返回插入后列表的长度 |
| 3 | LPOP key | 移除并返回列表左侧(头部)的第一个元素,若列表为空返回
(nil) |
| 4 | RPOP key | 移除并返回列表右侧(尾部)的最后一个元素,若列表为空返回
(nil) |
| 5 | LRANGE key start stop | 返回列表中从 start 到 stop
索引范围内的元素(包含两端),索引从 0 开始,负数表示从尾部计数(如 -1
表示最后一个元素) |
| 6 | LLEN key | 返回列表的长度,若列表不存在返回 0 |
| 7 | LREM key count value | 从列表中删除 count 个与 value
相等的元素。count > 0
从左侧开始删除;count < 0
从右侧开始删除;count = 0
删除所有匹配元素,返回实际删除的数量 |
| 8 | LINDEX key index | 返回列表中指定索引位置的元素,索引规则同 LRANGE,若索引超出范围返回
(nil) |
| 9 | LSET key index value | 将列表中指定索引index位置的元素设置为
value,若索引超出范围返回错误 |
| 10 | LINSERT key BEFORE|AFTER pivot value | 在列表中 pivot 元素的前面(BEFORE)或后面(AFTER)插入
value,返回插入后列表的长度,若 pivot
不存在返回 -1 |
| 11 | LTRIM key start stop | 保留列表中从 start 到 stop
索引范围内的元素,删除其他元素,执行成功返回 OK |
| 12 | RPOPLPUSH source destination | 移除 source 列表的尾部元素,并将其插入到
destination 列表的头部,返回该元素,常用于构建安全队列 |

应用场景
- 消息队列:利用 LPUSH + BRPOP 组合实现生产者 -
消费者模型,当然这也可以对队列进行模拟,从而支持多消费者并发处理。相对来说,Redis
5.0 新增加的一个数据结构
Stream更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。 - 最新列表:如博客的最新文章列表,使用 LPUSH 加入新文章,LRANGE 获取最新 N 篇,这个就可以用来做最新文章和最新动态的更新等
- 排行榜:结合 LTRIM 维护固定长度的热门数据排行
- 模拟栈与队列:LPUSH + LPOP 实现栈(先进后出),LPUSH + RPOP 实现队列(先进先出)
无序集合Set
相关内容
Redis 的 Set(无序集合)是一种无序的字符串集合,与 List 不同的是,Set
中的元素具有唯一性(不允许重复),且元素之间没有固定的顺序,有点类似于
Java 中的 HashSet。
当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
Set 类型在底层通过哈希表或整数集合实现,因此添加、删除和查找元素的操作复杂度均为 O (1),效率极高。
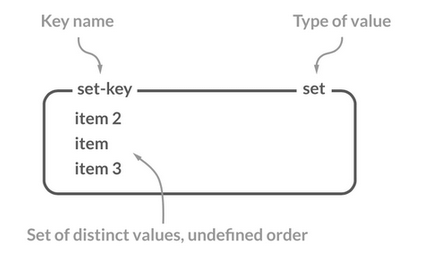
Set 类型的特点:
- 元素唯一,不会重复存储
- 无序性,无法通过索引访问元素
- 支持丰富的集合运算(如交集、并集、差集)
- 最多可存储 2^32 - 1 个元素
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | SADD key member [member …] | 向集合中添加一个或多个元素,返回成功添加的元素数量(已存在的元素不会被重复添加) |
| 2 | SREM key member [member …] | 从集合中删除一个或多个元素,返回成功删除的元素数量 |
| 3 | SMEMBERS key | 返回集合中所有的元素,元素顺序是无序的 |
| 4 | SISMEMBER key member | 检查元素是否是集合的成员,是则返回 1,否则返回 0 |
| 5 | SCARD key | 返回集合中元素的数量(基数),若集合不存在返回 0 |
| 6 | SPOP key [count] | 随机移除并返回集合中的一个或多个元素(count
为可选参数,指定移除的数量),若集合为空返回 (nil) |
| 7 | SRANDMEMBER key [count] | 随机返回集合中的一个或多个元素(不会移除元素),count 为正数时返回不超过 count 个的随机元素;count 为负数时可能返回重复元素,总数为 count 的绝对值 |
| 8 | SMOVE source destination member | 将元素从源集合移动到目标集合,若源集合中存在该元素则移动并返回 1,否则返回 0 |
| 9 | SDIFF key [key …] | 返回第一个集合与其他集合的差集(即存在于第一个集合但不存在于其他集合的元素) |
| 10 | SDIFFSTORE destination key [key …] | 计算第一个集合与其他集合的差集,并将结果存储到 destination 集合中,返回结果集中元素的数量 |
| 11 | SINTER key [key …] | 返回所有集合的交集(即同时存在于所有集合中的元素) |
| 12 | SINTERSTORE destination key [key …] | 计算所有集合的交集,并将结果存储到 destination 集合中,返回结果集中元素的数量 |
| 13 | SUNION key [key …] | 返回所有集合的并集(即存在于任意一个集合中的元素,去重后) |
| 14 | SUNIONSTORE destination key [key …] | 计算所有集合的并集,并将结果存储到 destination 集合中,返回结果集中元素的数量 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素,用于增量遍历大集合,避免 SMEMBERS 可能导致的阻塞 |
应用场景
- 去重存储:如存储用户的浏览记录,自动去重避免重复数据
- 好友关系管理:需要获取多个数据源交集、并集和差集的场景,存储用户的好友列表,利用集合运算实现 “共同好友”(交集)、“可能认识的人”(差集)等功能
- 标签系统:为文章、商品等添加标签,通过集合查询具有相同标签的内容
- 抽奖系统:使用 SPOP 或 SRANDMEMBER 实现随机抽奖功能
- 数据过滤:存储黑名单、白名单,快速判断某个元素是否在名单中
有序集合 SortedSet(Zset)
相关内容
SortedSet 凭借其有序性和高效的范围查询能力,在需要排序和排名的场景中表现出色,是 Redis 中功能最丰富的数据类型之一
Redis 的 SortedSet(有序集合)是一种特殊的集合类型,它兼具 Set 的唯一性(元素不重复)和 List 的有序性,同时为每个元素关联一个浮点数类型的分数(score),并基于分数对元素进行排序。
SortedSet 底层通过跳跃表(skiplist)和哈希表实现,既保证了高效的插入、删除和查找操作,又支持按分数范围快速获取元素。
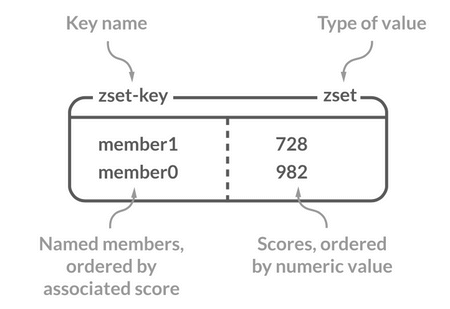
SortedSet 类型的特点:
- 元素唯一,不允许重复,但不同元素可以有相同的分数
- 基于分数自动排序,支持升序或降序访问
- 分数可以是整数或浮点数,可动态修改
- 最多可存储 2^32 - 1 个元素
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | ZADD key [NX|XX] [CH] [INCR] score1 member1 score2 member2 … | 向有序集合中添加一个或多个元素(指定分数)。NX
表示元素不存在时才添加;XX
表示元素存在时才更新;CH 表示返回变化的元素数量(新增 +
更新);INCR
表示将元素分数自增,返回更新后的分数。默认返回新增元素数量 |
| 2 | ZREM key member [member …] | 从有序集合中删除一个或多个元素,返回成功删除的元素数量 |
| 3 | ZSCORE key member | 返回指定元素的分数,若元素不存在返回 (nil) |
| 4 | ZINCRBY key increment member | 为指定元素的分数增加
increment(可正可负),返回更新后的分数。若元素不存在,先初始化为
0 再操作 |
| 5 | ZCARD key | 返回有序集合中的元素数量(基数),若集合不存在返回 0 |
| 6 | ZCOUNT key min max | 返回分数在 [min, max] 范围内的元素数量 |
| 7 | ZRANK key member | 返回元素在有序集合中的排名(按分数升序,排名从 0
开始),若元素不存在返回 (nil) |
| 8 | ZREVRANK key member | 返回元素在有序集合中的排名(按分数降序,排名从 0
开始),若元素不存在返回 (nil) |
| 9 | ZRANGE key start stop [WITHSCORES] | 按分数升序返回索引 [start, stop]
范围内的元素,WITHSCORES 选项会同时返回元素的分数 |
| 10 | ZREVRANGE key start stop [WITHSCORES] | 按分数降序返回索引 [start, stop]
范围内的元素,其他特性同 ZRANGE |
| 11 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] | 按分数升序返回分数在 [min, max]
范围内的元素,LIMIT 用于分页,(min 或
(max 表示不包含边界 |
| 12 | ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] | 按分数降序返回分数在 [min, max]
范围内的元素,其他特性同 ZRANGEBYSCORE |
| 13 | ZREMRangeByRank key start stop | 移除按分数升序排名在 [start, stop]
范围内的元素,返回删除的元素数量 |
| 14 | ZREMRangeByScore key min max | 移除分数在 [min, max]
范围内的元素,返回删除的元素数量 |
| 15 | ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX] | 计算多个有序集合的交集,将结果存储到 destination
中,numkeys 为集合数量。WEIGHTS
为每个集合设置权重(分数乘以权重),AGGREGATE
指定分数合并方式(默认 SUM),返回结果集中的元素数量 |
| 16 | ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX] | 计算多个有序集合的并集,参数含义同 ZINTERSTORE,返回结果集中的元素数量 |
| 17 | ZDIFFSTORE destination numkeys key1 key2 … | 求差集,其它和 ZINTERSTORE 类似 |
| 18 | ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素(按分数排序),用于增量遍历大集合,避免 ZRANGE 可能导致的阻塞 |
使用场景
需要随机获取数据源中的元素根据某个权重进行排序的场景
- 排行榜系统:如游戏积分排行、商品销量排行等,利用 ZADD 更新分数,ZREVRANGE 获取前 N 名
- 延时任务队列:将任务执行时间作为分数,通过 ZRANGEBYSCORE 定期获取到期任务
- 范围查询:如查询分数在 80-100 之间的用户、活跃度在某区间的文章等
- 带权重的关系管理:如社交网络中 “好友亲密度” 排序,按亲密度分数展示好友列表
- 计数器聚合:结合 ZUNIONSTORE 对多个维度的计数进行合并计算
Redis的特殊数据类型
超日志HyperLogLog
相关内容
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting(LLC)优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
Redis 的 HyperLogLog 是一种用于高效计算集合基数,即集合中不重复元素的数量,的数据结构。它的核心优势是在牺牲极小精度的情况下,以恒定且极小的内存空间(约 12KB)处理海量数据的基数统计,非常适合需要统计独立用户数、独立访问量等场景。
基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此,
HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为
0.81% )。
HyperLogLog 的使用非常简单,但原理非常复杂。
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k
的空间就能存储接近2^64个不同元素。因为,Redis 对
HyperLogLog 的存储结构做了优化,采用两种方式计数:
- 稀疏矩阵:计数较少的时候,占用空间很小。
- 稠密矩阵:计数达到某个阈值的时候,占用 12k 的空间
HyperLogLog 的特点:
空间效率极高:无论统计的元素数量多少,单个 HyperLogLog 结构仅占用约 12KB 内存
存在极小误差:标准误差约为 0.81%,可满足大多数非精确计数场景
支持合并操作:可以将多个 HyperLogLog 结构的基数统计结果合并
不存储实际元素:仅记录用于基数计算的概率性数据,无法获取具体元素
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | PFADD key element [element …] | 向 HyperLogLog 结构中添加一个或多个元素。如果 HyperLogLog 内部结构被修改则返回 1,否则返回 0(无论添加多少元素,只要结构有更新就返回 1) |
| 2 | PFCOUNT key [key …] | 计算一个或多个 HyperLogLog 结构的基数(不重复元素数量)。如果传入多个 key,会计算这些结构的并集的基数,返回估算的基数结果 |
| 3 | PFMERGE destkey sourcekey [sourcekey …] | 将多个源 HyperLogLog
结构(sourcekey)合并到目标结构(destkey)中,合并后的 destkey
的基数接近于所有源结构的并集的基数,返回 OK |
使用场景
数量巨大(百万、千万级别以上)的计数场景
- UV 统计:统计网站或页面的独立访客数(Unique Visitors),无需存储用户 ID 等实际数据
- 独立设备计数:统计访问应用的独立设备数量,适用于移动应用或 IoT 设备
- 搜索关键词去重:统计用户搜索过的独立关键词数量
- 社交关系基数统计:如统计某用户的好友中使用某功能的独立人数
- 大型活动参与人数统计:无需记录所有参与者信息,高效统计独立参与人数
位图 Bitmaps
相关内容
Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 2^32 个不同的位
Redis 的 Bitmaps(位图)并不是一种独立的数据类型,而是基于 String 类型实现的位操作功能。它允许将字符串中的每个字节拆分为 8 个二进制位(bit),存储的是连续的二进制数字(0 和 1),通过位级别的操作来高效存储和处理能用二进制表示其状态的数据。
通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身,数组中每个元素的下标叫做 offset(偏移量)。
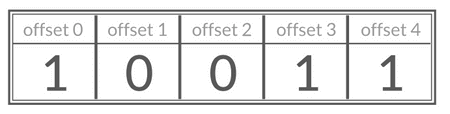
Bitmaps 特别适合处理大量二值状态(是 / 否、已完成 / 未完成)的数据,其空间效率和位运算能力使其在统计和标记场景中具有明显优势
Bitmaps 的特点:
- 极高的空间效率:1 个字节可存储 8 个状态(如 100 万个状态仅需约 125KB 内存)
- 支持快速的位级操作(设置、获取、统计等)
- 基于 String 类型实现,可与其他字符串命令兼容
- 偏移量(offset)支持从 0 到 2^32-1,理论上可表示超过 40 亿个状态
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | SETBIT key offset value | 为指定键的位图设置偏移量 offset
处的位值(value 只能是 0 或
1)。若键不存在则自动创建,偏移量超出当前字符串长度时会自动扩展,返回该位的旧值 |
| 2 | GETBIT key offset | 获取指定键的位图中偏移量 offset 处的位值(0 或
1)。若键不存在或偏移量超出范围,返回 0 |
| 3 | BITCOUNT key [start end] | 统计位图中值为 1 的位数量。start 和 end
为字节索引(可选),用于指定统计范围(默认统计整个位图),返回统计结果 |
| 4 | BITOP operation destkey key1 key2 ….. | 对多个位图执行位运算,并将结果存储到 destkey
中。operation
可取值:AND(与)、OR(或)、XOR(异或)、NOT(非,仅支持单个键),返回结果的字节长度 |
| 5 | BITPOS key bit [start] [end] | 查找位图中第一个值为 bit(0 或
1)的位的偏移量。start 和 end
为字节索引(可选),用于指定查找范围,返回找到的偏移量,若未找到返回
-1 |
| 6 | BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL] | 对 bitmap
执行多字节操作,支持获取、设置、自增等操作,可指定数据类型(如
u8 无符号 8 位、i16 有符号 16
位等),OVERFLOW 定义自增溢出策略 |
使用场景
需要保存状态信息(0/1 即可表示)的场景
用户行为统计:如记录用户每日登录状态(1 表示登录,0 表示未登录),键为
user:login:20231001,偏移量为用户 ID,通过 BITCOUNT 统计当日登录人数签到系统:存储用户每月签到情况,1 个字节可存储 8 天的签到状态,一年仅需 46 字节 / 用户
权限控制:用位表示不同权限,通过位运算快速判断用户是否拥有某项权限(如
AND操作验证权限)布隆过滤器:结合多个哈希函数和位图实现快速去重判断(存在一定误判率)
状态标记:如文章是否已读、消息是否已处理等二值状态的高效存储
地理空间Geospatial
相关内容
Redis 的 Geospatial(地理空间索引,简称 GEO)类型是用于存储和操作地理位置信息的数据结构。
它基于有序集合(SortedSet)实现,通过将经纬度坐标转换为 52 位整数进行存储,从而支持高效的距离计算和范围查询。GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换成了一个整数,这个整数作为 Sorted Set 的 score(权重参数)使用
通过 GEO 我们可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能。
Geospatial 的特点:
- 支持存储经纬度坐标(精度约为 1 米)
- 提供距离计算、范围查询等地理空间操作
- 底层基于 SortedSet 实现,可兼容部分有序集合命令
- 经度范围为 [-180, 180],纬度范围为 [-85.05112878, 85.05112878](超出范围会返回错误)
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | GEOADD key longitude latitude member [longitude latitude member …] | 向地理空间集合中添加一个或多个地理位置(经度、纬度、成员名)。返回成功添加的成员数量,已存在的成员会被更新 |
| 2 | GEOPOS key member [member …] | 返回指定成员的经纬度坐标,格式为 [longitude,
latitude]。若成员不存在,对应位置返回 (nil) |
| 3 | GEODIST key member1 member2 [unit] | 计算两个成员之间的距离。unit
可选单位:m(米,默认)、km(千米)、mi(英里)、ft(英尺)。若任一成员不存在,返回
(nil) |
| 4 | GEOHASH key member [member …] | 返回指定成员的地理位置的 Geohash 编码(一种将经纬度转换为短字符串的编码方式),便于存储和比较 |
| 5 | GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] | 以指定经纬度为中心,查找半径 radius
范围内的成员。WITHCOORD 显示坐标,WITHDIST
显示距离,WITHHASH 显示哈希值,COUNT
限制返回数量,ASC/DESC 排序,STORE
存储结果到集合 |
| 6 | GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] | 与 GEORADIUS 功能相同,但以指定成员的位置为中心,而非手动输入的经纬度 |
| 7 | ZREM key member [member …] | 删除地理空间集合中的指定成员(因基于 SortedSet 实现,直接使用有序集合的删除命令) |
使用场景
需要管理使用地理空间数据的场景
- 附近的人 / 地点:如社交应用中 “附近的用户”、外卖平台 “附近的餐厅” 等功能
- 地理位置排序:按距离远近排序展示周边服务或资源
- 地理围栏:判断用户是否进入或离开某个指定地理区域
- 路径规划辅助:计算多个地点之间的距离,辅助规划最优路线
- 位置签到系统:存储用户签到的地理位置,统计特定区域的签到人数
流Streams
相关内容
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
Redis 的 Streams 是一种专为处理流式数据设计的数据结构,类似于日志文件的结构,支持持久化、多消费者组、消息确认等特性,适合构建消息队列、事件日志等场景。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容
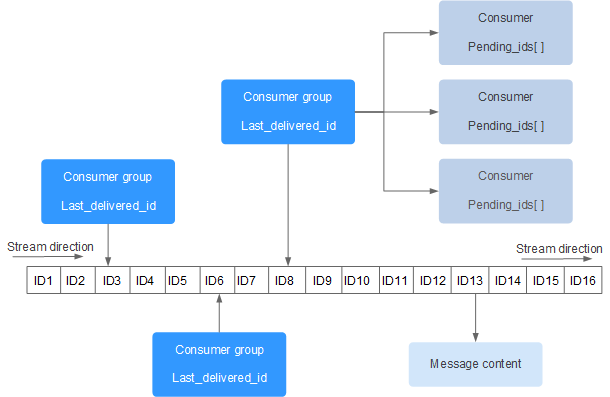
Streams 的特点:
- 以时间序列方式存储消息,每条消息有唯一 ID(格式为
timestamp-sequence) - 支持多消费者组(Consumer Group),实现消息的负载均衡和重复消费控制
- 提供消息确认机制,确保消息被正确处理
- 支持消息的范围查询和迭代,可回溯历史消息
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | XADD key ID field value [field value …] | 向队列 key 中添加消息,ID为消息id, field value 就是键值对 |
| 2 | XTRIM key MAXLEN count | 对队列key中的流进行修剪,限制长度为count |
| 3 | XLEN key | 返回流中的消息数量,若流不存在返回 0 |
| 4 | XRANGE key start end [COUNT count] | 返回流中 ID 在 [start, end]
范围内的消息,- 表示最小 ID,+ 表示最大
ID,COUNT 限制返回数量 |
| 5 | XREVRANGE key end start [COUNT count] | 与 XRANGE 类似,但按 ID 降序返回消息 |
| 6 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …] | 读取一个或多个流中的新消息,BLOCK
表示阻塞等待,ID 为上次读取的最后一个消息
ID($ 表示从最新消息开始) |
| 7 | XGROUP CREATE key groupname ID [MKSTREAM] | 为流创建消费者组,ID 指定消费起始位置($
表示从创建后新消息开始),MKSTREAM
表示若流不存在则创建 |
| 8 | XREADGROUP GROUP groupname consumername [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …] | 以消费者组方式读取消息,ID 为 >
表示读取未分配的消息,或具体 ID 表示读取已分配但未确认的消息 |
| 9 | XACK key groupname ID [ID …] | 确认消费者组中已处理的消息,返回确认成功的消息数量 |
| 10 | XDEL key ID [ID …] | 从流中删除指定消息,返回删除的消息数量(实际是标记删除,不影响长度统计) |
| 11 | XINFO [STREAM key] [GROUPS key] [CONSUMERS key groupname] | 查看流、消费者组或消费者的详细信息 |
| 12 | XGROUP DESTROY key groupname | 删除流的消费者组,返回 1 表示成功,0 表示组不存在 |
| 13 | XGROUP DELCONSUMER key groupname consumername | 从消费者组中删除指定消费者,返回被删除消费者的未确认消息数 |
使用场景
- 消息队列:替代传统消息队列,一般 Redis 这个 Stream 轻量一些,但是也比较基类,虽然支持多消费者组和消息确认,能够在一定程度上确保消息可靠投递,但是大伙用它用的也很少
- 事件溯源:存储系统事件日志,支持按时间范围查询和回溯
- 实时数据分析:收集实时产生的数据流,供后续分析处理
- 分布式系统日志:汇总多个节点的日志信息,便于集中查询和监控
模块(Modules)
相关内容
Redis 模块是 Redis 提供的扩展机制,允许开发者通过 C 语言或其他支持的语言编写自定义模块,为 Redis 添加新的数据结构、命令或功能,扩展 Redis 的能力边界。
Modules 的特点:
- 可扩展性强:通过模块添加 Redis 原生不支持的功能
- 高性能:模块运行在 Redis 进程内部,与核心功能享有相同的性能特性
- 生态丰富:社区提供了众多成熟模块(如 RedisJSON、RediSearch 等)
- 版本兼容:模块需要与特定 Redis 版本兼容,更新需注意兼容性
常用命令
| 序号 | 命令 | 解释 |
|---|---|---|
| 1 | MODULE LOAD path | 加载指定路径的模块,返回 OK
表示成功,失败返回错误信息 |
| 2 | MODULE UNLOAD name | 卸载指定名称的模块,返回 OK 表示成功 |
| 3 | MODULE LIST | 返回当前已加载的所有模块信息,包括名称、版本、路径等 |
| 4 | MODULE HELP | 返回模块相关命令的帮助信息 |
典型模块及应用场景
- RedisJSON:添加 JSON 数据类型支持,提供 JSON Path 查询和修改命令,适合存储和操作 JSON 格式数据
- RediSearch:提供全文搜索功能,支持索引、分词、复杂查询,适合构建搜索服务
- RedisGraph:添加图数据库功能,支持节点和关系存储及图查询,适合社交网络、推荐系统等
- RedisTimeSeries:优化时间序列数据存储和查询,适合 IoT 传感器数据、监控指标等场景
- RedisBloom:提供布隆过滤器、计数布隆过滤器等数据结构,适合去重和概率性查询
通过模块机制,Redis 可以根据业务需求扩展为具备特定功能的数据库,极大增强了其适用范围和灵活性。
Redis的一些额外内容补充
Redis脚本
相关内容
Redis 脚本是基于 Lua 语言的功能扩展,允许用户在 Redis 服务器端执行自定义脚本,实现复杂的原子操作。其核心价值在于减少网络交互(将多步命令合并为一次请求)和保证操作原子性(脚本执行过程中不会被其他命令打断)
- 原子性:脚本执行过程中,Redis 不会处理其他任何命令,确保复杂逻辑的原子性。
- 高效性:脚本在服务器端执行,减少客户端与服务器的网络往返次数。
- 复用性:脚本可以被缓存,重复执行时无需重新传输脚本内容。
- 灵活性:基于 Lua 5.1 语法,复杂逻辑。
Redis 为 Lua 脚本提供了专属函数,用于操作 Redis 数据:
redis.call(command, key, arg1, ...):执行 Redis 命令,若出错则返回错误信息。redis.pcall(command, key, arg1, ...):执行 Redis 命令,若出错则返回 nil(不抛出异常)。KEYS[i]:获取脚本传入的第 i 个键(从 1 开始索引,推荐用此方式传递键,便于 Redis 集群路由)。ARGV[i]:获取脚本传入的第 i 个参数(从 1 开始索引)。
这其实设计 Lua 的内容,我简单写个示例代码,这里就是说 Redis 对 Lua 有原生支持
1 | -- 脚本内容 |
常用 Redis 脚本命令
| 命令格式 | 功能描述 | 关键参数说明 |
|---|---|---|
EVAL script numkeys key [key ...] arg [arg ...] |
执行指定 Lua 脚本 | - script:Lua 脚本内容-
numkeys:后续参数中键(KEYS)的数量-
key:传递给脚本的键(对应KEYS数组)-
arg:传递给脚本的参数(对应ARGV数组) |
EVALSHA sha1 numkeys key [key ...] arg [arg ...] |
通过脚本 SHA1 哈希值执行缓存的脚本 | - sha1:脚本的 SHA1
校验和(由SCRIPT LOAD返回)其他参数同EVAL |
SCRIPT LOAD script |
将脚本加载到 Redis 缓存,返回其 SHA1 哈希值 | - script:Lua
脚本内容(加载后可通过EVALSHA调用,避免重复传输脚本) |
SCRIPT EXISTS sha1 [sha1 ...] |
检查指定 SHA1 哈希值的脚本是否存在于缓存中 | - sha1:一个或多个脚本的 SHA1 值返回值为 1(存在)或
0(不存在)的数组 |
SCRIPT FLUSH |
清空所有缓存的脚本 | 无参数,执行后所有通过SCRIPT LOAD加载的脚本失效 |
SCRIPT KILL |
终止当前正在执行的长时间运行的脚本 | 仅在脚本未执行写操作时有效(若已执行写操作,需用SHUTDOWN NOSAVE强制终止) |
Redis 连接
相关内容
Redis 连接命令主要是用于连接 redis 服务。
Redis 连接是客户端与服务器进行交互的基础,涉及连接建立、认证、管理等操作。合理的连接管理能提升 Redis 服务的稳定性和性能,尤其在高并发场景下至关重要。
- TCP 连接:Redis 客户端与服务器通过 TCP 协议通信(默认端口 6379),采用请求 - 响应模式。
- 长连接:默认情况下,Redis 连接为长连接(非短连接),客户端可通过一次连接发送多个命令,减少连接建立开销。
- 连接限制:Redis
可通过配置限制最大连接数(
maxclients),避免过多连接耗尽服务器资源。 - 认证机制:支持密码认证,客户端需通过
AUTH命令验证身份后才能执行操作。
连接的生命周期(连接的过程)也很清楚
- 建立连接:客户端通过 TCP 三次握手与 Redis 服务器建立连接。
- 认证(可选):若服务器配置了密码(
requirepass),客户端需发送AUTH命令验证。 - 执行命令:客户端通过连接发送命令,服务器处理后返回结果。
- 保持连接:客户端可通过发送
PING命令维持连接(避免被防火墙断开)。 - 关闭连接:客户端主动发送
QUIT命令,或服务器因超时(timeout配置)、连接数超限等原因关闭连接。
常用 Redis 连接命令
| 命令格式 | 功能描述 | 关键参数说明 |
|---|---|---|
AUTH password |
对当前连接进行身份认证 | - password:Redis
服务器配置的密码(requirepass
指定)若认证失败,服务器会拒绝后续命令 |
PING [message] |
测试连接是否存活,服务器返回响应 | - 无参数时返回 PONG- 带 message
时返回该消息(如 PING "hello" 返回
"hello") |
QUIT |
关闭当前连接,服务器返回 OK 后断开连接 |
无参数,客户端主动终止连接的推荐方式 |
SELECT db |
切换当前连接的数据库(Redis 默认有 16 个数据库,编号 0-15) | - db:数据库编号(如 SELECT 1 切换到第 2
个数据库) |
CLIENT LIST |
列出当前所有客户端连接的详细信息 | 无参数,返回内容包括连接 ID、地址、状态、最后一次活动时间等 |
CLIENT ID |
获取当前连接的唯一标识 ID | 无参数,可用于 CLIENT KILL 命令指定关闭某个连接 |
CLIENT KILL [ip:port | ID client-id] |
关闭指定的客户端连接 | - ip:port:客户端的 IP 和端口(如
CLIENT KILL 127.0.0.1:63790)-
ID client-id:通过 CLIENT ID 获取的连接 ID(如
CLIENT KILL ID 10) |
CLIENT PAUSE timeout |
暂停所有客户端连接(指定毫秒数),期间不处理命令 | -
timeout:暂停时间(毫秒),用于维护操作(如备份) |
CLIENT SETNAME name |
为当前连接设置名称,便于通过 CLIENT LIST 识别 |
- name:连接名称(如
CLIENT SETNAME "order-service") |
CLIENT GETNAME |
获取当前连接的名称(未设置则返回 nil) |
无参数 |
使用实践
- 使用连接池:在应用中使用 Redis 连接池(如 Java 的 JedisPool、Python 的 redis-py 连接池),避免频繁创建 / 关闭连接,减少性能损耗。
- 设置合理的超时时间:通过配置
timeout(单位秒)让服务器自动关闭长期闲置的连接(建议设为 300 秒以上)。 - 限制最大连接数:根据服务器资源配置
maxclients(默认 10000),避免连接数过多导致服务器崩溃。 - 连接命名:通过
CLIENT SETNAME为不同业务的连接设置名称,便于通过CLIENT LIST排查连接泄漏问题。 - 认证保护:生产环境必须配置
requirepass,并通过AUTH命令验证连接,防止未授权访问。
Redis服务器
相关内容
Redis 服务器是 Redis 生态的核心组件,负责存储数据、处理客户端命令、管理内存等核心功能。了解服务器的工作机制、配置与管理方式,对优化 Redis 性能和保障稳定性至关重要。
- 单线程模型:Redis 服务器采用单线程处理命令(6.0+ 版本引入多线程处理 IO,但命令执行仍为单线程),避免了多线程上下文切换的开销。
- 内存数据库:数据主要存储在内存中,访问速度极快(微秒级响应),同时支持持久化到磁盘。
- 多数据库:默认提供 16 个数据库(编号 0-15),可通过
SELECT命令切换,用于隔离不同业务数据。 - 丰富的数据结构:支持字符串、哈希、列表、集合、有序集合等多种数据结构,满足复杂业务需求。
- 可扩展性:支持主从复制、哨兵模式、集群(Cluster)等部署方式,实现高可用和横向扩展。
Redis 服务器的核心组件如下
网络处理器:负责监听 TCP 端口(默认 6379),接收客户端连接和命令请求。
命令执行器:解析并执行客户端发送的命令,操作数据结构并返回结果。
内存管理器:管理内存分配与回收,通过过期策略(如 LRU、LFU)清理无效数据。
持久化模块:通过 RDB(快照)和 AOF(追加文件)机制将内存数据持久化到磁盘。
事件循环:基于 IO 多路复用(epoll/kqueue 等)处理网络事件和定时任务(如过期键删除)。
常用命令
| 命令格式 | 功能描述 | 关键参数说明 |
|---|---|---|
INFO [section] |
获取服务器状态信息,返回键值对格式的统计数据 | - section:可选,指定信息类别(如 server
服务器基本信息、memory 内存使用、replication
主从状态等)不指定则返回所有信息 |
CONFIG GET parameter |
获取服务器配置参数的值 | - parameter:配置项名称(如
maxmemory、requirepass)支持 *
通配符(如 CONFIG GET "max*") |
CONFIG SET parameter value |
动态修改服务器配置参数(部分参数需重启生效) | - parameter:配置项名称- value:新值(如
CONFIG SET timeout 300) |
CONFIG REWRITE |
将当前动态修改的配置写入配置文件(redis.conf) | 无参数,确保配置修改持久化 |
CONFIG RESETSTAT |
重置 INFO 命令中的部分统计数据(如命令执行次数、连接数等) | 无参数,不影响核心数据 |
DBSIZE |
返回当前数据库中键的总数 | 无参数,仅统计当前选中的数据库(通过 SELECT 指定) |
FLUSHDB |
清空当前数据库中的所有键 | 无参数,操作不可逆,生产环境慎用 |
FLUSHALL |
清空所有数据库中的所有键 | 无参数,会影响所有业务数据,需谨慎操作 |
SAVE |
同步执行 RDB 持久化,阻塞服务器直到完成 | 无参数,可能导致短时间不可用,建议用 BGSAVE 替代 |
BGSAVE |
异步执行 RDB 持久化,服务器后台 fork 子进程处理,不阻塞主线程 | 无参数,适合生产环境 |
BGREWRITEAOF |
异步重写 AOF 文件(压缩冗余命令) | 无参数,优化 AOF 文件大小 |
LASTSAVE |
返回最近一次 RDB 持久化(SAVE 或
BGSAVE)的完成时间(Unix 时间戳) |
无参数 |
SHUTDOWN [NOSAVE | SAVE] |
关闭 Redis 服务器 | - 无参数:先执行持久化,再关闭-
NOSAVE:不执行持久化直接关闭-
SAVE:强制执行持久化后关闭 |
TIME |
返回服务器当前时间(Unix 时间戳 + 微秒数) | 无参数,格式如 1620000000 123456 |






