
HTTP协议
对HTTP协议的详解先不放到这里,移到了另外一章,看到这篇的默认认为了解 HTTP 协议
https://www.ergoutreegal.cn/posts/30445.html
RPC协议
为什么要有RPC协议
RPC,全称 Remote Procedure Call,远程过程调用,是一种允许程序调用另一个地址空间(通常是在网络中的另一台计算机上)的程序的协议。它使得程序能够像调用本地函数一样调用远程函数,而无需显式编码这些远程交互的细节。
但这个名字起的一点都不好,过分强调了和LPC(本地过程调用)的对比。没有突出出来 RPC 本身涉及到的一些技术特点。
我非常同意上述观点,跟他妈的鲁棒性那个翻译似的
什么意思
假设你有两台电脑:
- 本地电脑 A:你写的程序运行在这里,想获取用户信息;
- 远程电脑 B:数据库在这,有一个
getUserInfo(userId)函数能查用户信息。
如果没有 RPC,你要实现 “调用 B 的函数”,得自己做这些事:
- 手动写网络通信代码,比如用 Socket,把
userId打包成字节流; - 处理网络传输,比如 TCP 连接、IP 地址、端口,把数据发给 B;
- B 收到数据后,手动解析字节流,拿到
userId,调用本地的getUserInfo; - B 把返回的用户信息再打包成字节流,发回给 A;
- A 收到后,手动解析字节流,拿到用户信息。
整个过程你要操心各种事情,数据怎么序列化怎么反序列化两主机网络如何握手怎么处理超时怎么粘包拆包….这些都是和 查用户信息无关的底层细节。
RPC 就是帮你把上面这些底层细节全封装了,你在 A 电脑的代码里,只需要像调用本地函数一样写就可以
Dubbo!
那么在上述内容中说,其实,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的思想。
客户端在不知道调用细节的情况下,调用存在于远程计算机上的某个对象,就像调用本地应用程序中的对象一样,即允许像调用本地服务一样调用远程服务。
而且,从微服务的角度来考虑,RPC 的大量使用也是必然的,因为当我们的系统访问量增大、业务增多时,我们会发现一台单机运行此系统已经无法承受,必然会去进行微服务化的相关内容,而服务之间的通讯手段,RPC就必然会大显身手
常见的 RPC 框架
回到本质,RPC 是一种协议,那么一个协议内容再多,终究只是一套规范,需要有人遵循这套规范来进行实现
gRPC
gRPC 是跨语言的高性能 RPC 框架,基于 HTTP/2 + Protobuf(二进制序列化),Google 主导,Java 生态支持完善,适合跨语言通信、高性能场景。
基于 Protobuf 定义服务接口,可生成 Java、Go、Python 等多语言客户端 / 服务端代码,是 GO 项目下的最多的需求
而且 RPC 性能很好,基于 HTTP/2 + Protobuf,而且支持简单 RPC、服务端流、客户端流、双向流
你可以理解ProtoBuf是一种更加灵活、高效的数据格式,与XML、JSON类似,在一些高性能且对响应速度有要求的数据传输场景非常适用。
我们知道使用XML、JSON进行数据编译时,数据文本格式更容易阅读,但进行数据交换时,设备就需要耗费大量的CPU在I/O动作上,自然会影响整个传输速率。Protocol Buffers不像前者,它会将字符串进行序列化后再进行传输,即二进制数据。所以它非常非常快
原生异步,Java 端提供异步 API,适配高并发场景,微服务使用可靠,而且对 Spring Boot 的支持也相当好
Duboo
Dubbo 是专为 Java 打造的高性能、高扩展性的分布式服务框架,对 Java 开发者好感度拉满。
它原生 Java 友好,实际上,是 Java RPC 远程调用中用的最多的实践方案,基于 Java 接口定义服务,无缝集成 Spring Boot 和 Spring Cloud Alibaba
而且Dubbo自带多协议支持,默认推荐 dubbo
私有二进制协议(性能最优),也支持 HTTP、gRPC、Hessian 等
Dubbo 全链路能力极强,内置负载均衡、服务降级、熔断、限流、链路追踪,微服务涉及到的管理,容灾,高性能,高可靠的相关内容,基本全涉及到了
本内容的所有案例都基于 Dubbo,但是会使用其中最简单最清晰的内容
Thrift
这位更是老资历
Thrift是Facebook开源项目,其是一个跨语言的服务开发框架。用户只需在进行二开即可,对底层的RPC通讯透明。
理解RPC
只要涉及到网络通信,必然涉及到网络协议,应用层也是一样。在应用层最标准和常用的就是HTTP协议,但是很多性能要求较高的场景各大企业内部也会自定义的 RPC 协议,HTTP相当于普通话,而RPC就相当于是一个方言。
RPC可以分为两部分:用户调用接口 + 具体网络协议。前者为开发者需要关心的,后者需要由框架来实现。
实际上,这两部分其实包括的是完整的 RPC 五个逻辑层
| 层次 | 职责 | 技术关键点 |
|---|---|---|
| User (客户端) | 发起逻辑调用。 | 对远程细节完全无感。 |
| Client Stub (客户端存根) | 核心环节:序列化 (Marshaling)。 | 将函数名、参数类型、参数值封装成网络包。 |
| RPC Runtime | 传输管理。 | 负责建立连接、处理超时重试、请求/响应映射(Request ID)。 |
| Server Stub (服务端存根) | 反序列化 (Unmarshaling)。 | 解析网络包,通过反射或分发器找到对应的本地实现类并执行。 |
| Service (服务端实现) | 执行具体业务逻辑。 | 将结果交给 Server Stub。 |
用户调用接口
这是一套展示给用户的契约与抽象
在 RPC 的世界里,开发者操作的是“存根(Stub)”,而 RPC 强制要求先定义“契约”(IDL,如 Protobuf)。这解决了分布式系统中最头疼的沟通成本问题。
举个例子,我们定义一个函数,我们希望函数如果输入为“Hello World”的话,输出给一个“OK”,那么这个函数是个本地调用。如果一个远程服务收到“Hello World”可以给我们返回一个“OK”,那么这是一个远程调用。
所以说,用户会关心调用哪个远程方法、传什么参数、拿什么返回值,所以,我们会和服务约定好远程调用的函数名,因此,我们的用户接口就是:输入、输出、远程函数名
这是 Dubbo 中 用户调用接口 的核心 —— 所有通信双方(服务提供方、消费方)都依赖这个接口,有着上面的契约型
比如,使用 Dubbo,client 端的代码就会长这样
1 | // 单独抽离的接口(通常打jar包,提供方/消费方都依赖) |
而且开发者只需要实现接口的业务逻辑,Dubbo
通过注解@DubboService标记
“这是一个远程服务”,无需写任何网络代码:
1 | // 服务提供方:实现接口(纯业务逻辑,无网络代码) |
消费方通过@DubboReference注入远程接口,调用方法时完全感知不到
“远程”,和你平常调用本地Math.abs()这种方法没有区别:
1 | // 服务消费方:调用远程接口(无任何网络代码) |
可以看到,RPC是有很好的语义对齐的,本地调用是同步的,RPC 框架通过封装,让远程调用在语义上也接近同步,尽管底层是复杂的异步 IO
具体网络协议
这部分就是对应框架的有自己的具体实现了,是 RPC 希望用户不用关心的底层内容,把开发者要发出和接收的内容以某种应用层协议打包进行网络收发。
这里可以和HTTP进行一个明显的对比,以 Dubbo 中的私有二进制协议(默认) 为 RPC 实现的例子:
| 协议类型 | 结构特点 | RPC 协议(Dubbo默认) | HTTP 协议 |
|---|---|---|---|
| 核心结构 | 固定 / 自定义 | 自定义二进制结构(灵活、高性能) | 固定结构(请求行 + 请求头 + 请求体) |
| 传输层 | - | TCP(长连接,多路复用) | TCP(短连接为主) |
| 序列化 | - | 默认 Hessian2(二进制,小而快) | 默认 JSON(文本,大而慢) |
一般 RPC 协议的实现,其具体结构的核心大部分是 协议头 + 协议体,目的是,让接收方能快速解析出 “要调用的服务、消息长度、内容等重要信息,而且不少 RPC 协议的实现都会在协议头去做无需解析体就能拿到的核心信息的实现方式
而协议体是 序列化后的业务数据,Protobuf 和 Hessian2 是两种用到的很多的序列化协议体方式
而 RPC 也存在三大核心问题。也就是我们想要实现用户接口,需要怎么做?最重要需要支持以下三个功能:
- 定位要调用的服务
- RPC 一般是通过服务注册中心来实现的,而HTTP就是经典 URL 实现,通过 URL 直接指定服务地址
- 把完整的消息切下来
- 网络传输中可能出现 “粘包 / 拆包”,如何准确读取完整的一条请求 /
响应。RPC 使用协议头中的
Data Length字段,它代表数据长度,而 HTTP就是 请求头中的Content-Length字段实现这功能
- 网络传输中可能出现 “粘包 / 拆包”,如何准确读取完整的一条请求 /
响应。RPC 使用协议头中的
- 让消息向前 / 向后兼容
- 不同 RPC 协议的实现会有不同的版本控制逻辑,而HTTP协议需要开发者在 HTTP Body 中自行处理
所以说,RPC 与 HTTP 协议是天然互通的,要不然 Feign 怎么做到的使用 HTTP 实现轻量 RPC,因为,大家都会需要类似的结构去组装一条完整的用户请求,而第三部分的body只要框架支持
因此开发者完全可以根据自己的业务需求进行选型,下面会对 HTTP 和 RPC 的互通做出进一步的解释。
这里先拿 Dubbo 举个例子:
- RPC 框架之间互通:协议层更换就行,只要协议层 / 序列化层兼容(比如都用 HTTP+JSON),就能互通。
- RPC 与 HTTP 互通:协议层替换为 HTTP,序列化层替换为
JSON,业务层的
UserService接口完全不变;也就是 RPC 中的一些定制化内容使用 HTTP 协议的内容。
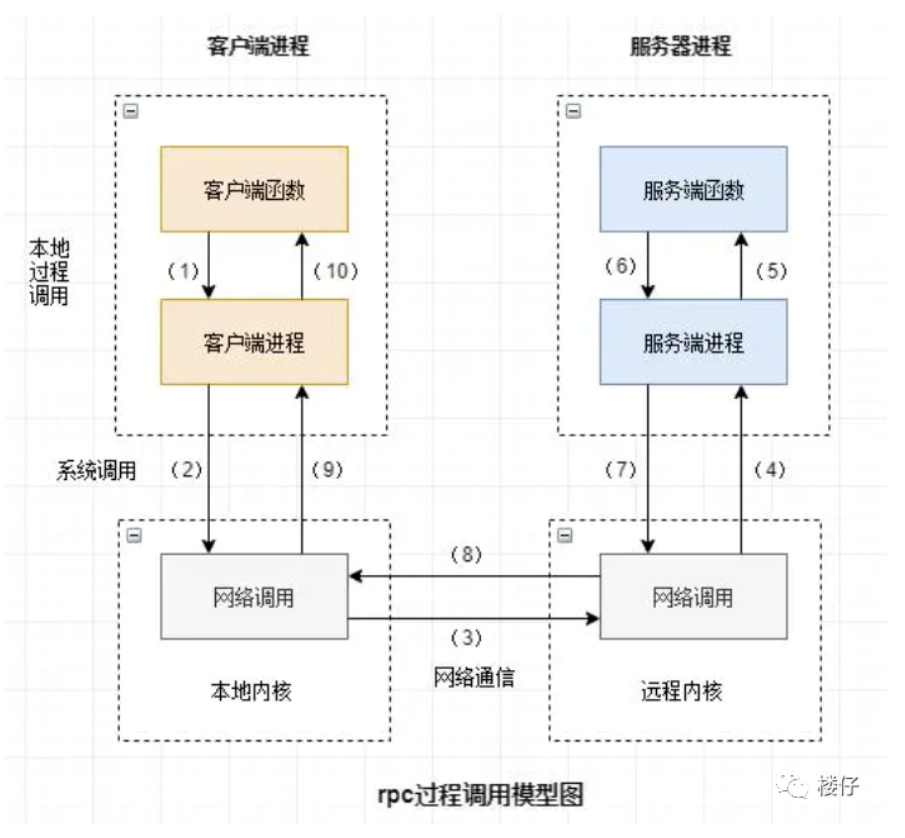
RPC调用流程
要让网络通信细节对使用者透明,我们就需要对通信细节进行封装,我们先看一下一个RPC调用的流程都会涉及到哪些通信细节,就根据我网上找到的图来说吧
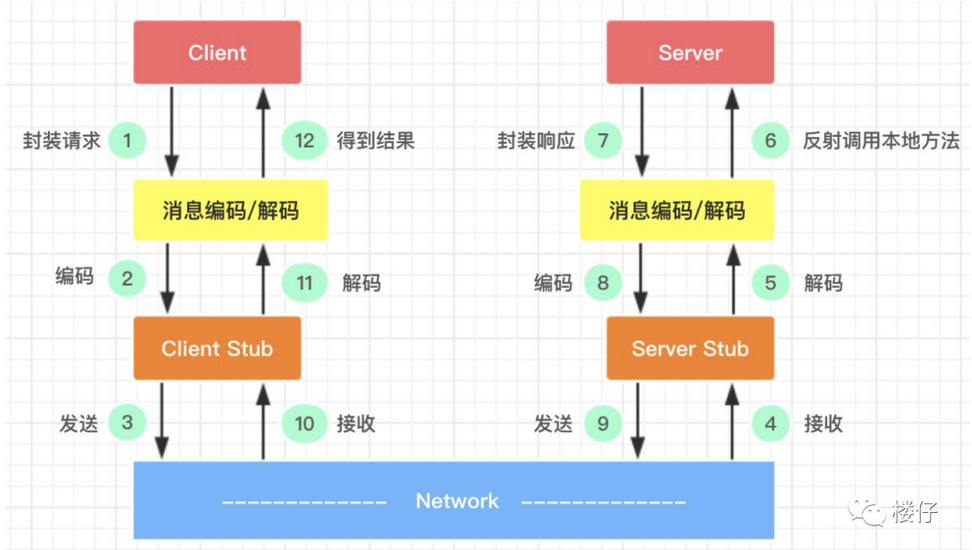
- Client 封装请求:客户端像调用本地方法一样发起请求,那么它就需要把要调用的方法、参数等信息打包好。
- 消息编码:把请求信息(比如对象、参数)转换成能在网络上传输的格式,比如二进制、JSON。
- Client Stub 发送请求:客户端存根(Stub,相当于客户端的 “代理”)把编码后的请求通过网络发送给服务端。
- Server Stub 接收请求:服务端存根(服务端的 “代理”)从网络中接收到客户端发来的请求。
- 消息解码:把网络传输的格式还原成服务端能识别的方法、参数信息。
- 反射调用本地方法:服务端存根根据解码后的信息,通过反射(感觉更像是预设的映射)调用服务端本地的实际方法。
- 封装响应:服务端本地方法执行完成后,把结果(返回值)打包成响应信息。
- 消息编码:把响应信息转换成网络传输格式。
- Server Stub 发送响应:服务端存根把编码后的响应通过网络发回客户端。
- Client Stub 接收响应:客户端存根从网络中接收到服务端的响应。
- 消息解码:把响应的网络格式还原成客户端能识别的结果。
- Client 得到结果:客户端拿到最终的调用结果,就像调用本地方法一样完成整个流程。
那么,RPC协议的目标就算要把上面 2 - 11 的步骤给封装起来,让用户不用关心这些内容,完成对远程方法的调用
那么,这个过程中肯定会涉及到一些额外的问题,例如如何做到透明化远程服务调用,如何对消息进行编码和解码等,这个不同协议对此实现的不一样的,下面再说
RPC 协议的组成
这部分聚焦于 RPC 有什么,也即是 RPC 框架从系统到用户都有哪些层次
上面说了RPC协议跑通的流程,那么,这些流程中的每一部分,肯定对应着协议中的不同层级
RPC 框架的层级是 “分层封装” 的 —— 越上层越贴近用户,越下层越贴近网络 或 系统,每个层级解决一类问题:
用户代码层
这部分是用户直接写的代码,是 RPC 的 出入口,在这部分,客户端写调用远程方法的逻辑就像调用本地函数一样,或者两者差不多,服务端写远程方法的实际实现和写本地业务逻辑无差。所以,在这层级核心是 “对用户透明”:用户不用关心远程调用的细节,只需要按框架约定写代码。
例如,Dubbo 中这样定义服务接口,服务端实现不需要特别的处理,只需要加上一个注解就可以
1
2
3
4
5
6// 服务接口(用户定义,对应RPC的“业务契约”)
public interface UserService {
UserDTO getUserById(String userId);
}
// 数据传输对象DTO省略接口定义层(IDL)
这部分解决 客户端和服务端如何约定请求 与 响应的结构 的问题,是 RPC 的 契约层
客户端要传什么参数,服务端要返回什么结果,都要在这里定义,而这里是保证双方能理解对方的数据的关键,刚才说到的用户接口和前后兼容问题,都是IDL层来解决的
数据组织层
这部分解决 请求和响应的数据用什么格式存储 的问题,是 IDL 层的落地格式,把 IDL 定义的结构转换成具体的二进制或者文本等格式(比如 Protobuf 的二进制格式、JSON 的文本格式)
这一层和下面的一层,在Dubbo中都说以配置文件的方式就可以进行控制
压缩层
这层很好理解,就是对数据组织层生成的内容进行压缩,减少网络传输的字节数。比较常用的就是 lz4 和 gzip 算法
协议层
这层就是贴近网络底层的协议了,它解决 网络中传输的数据包要怎么打包 的问题,例如给数据加上 “协议头”(包含 “数据长度、协议类型、压缩方式” 等元信息),让服务端能识别 这是什么协议的包、怎么解析。TRPC 就是腾讯自研的 RPC 协议
而 Dubbo 支持多种 RPC 协议,通过
protocol.name配置通信层
这部分就是解决数据如何通过网络发送出去的问题,RPC其实也是基于底层网络协议(TCP/HTTP)实现数据的发送 与接收。
这部分就是实现RPC与HTTP协议互通的关键,可以理解为把 RPC 的协议包 伪装 成 HTTP 请求,服务端收到后按 HTTP 解析出 Body,再按 RPC 协议解析,相当于 用 HTTP 的壳子装 RPC 的内容。在下面说明好理解一些
RPC 的各种实现最重要的就是屏蔽这些传输细节
再看下图
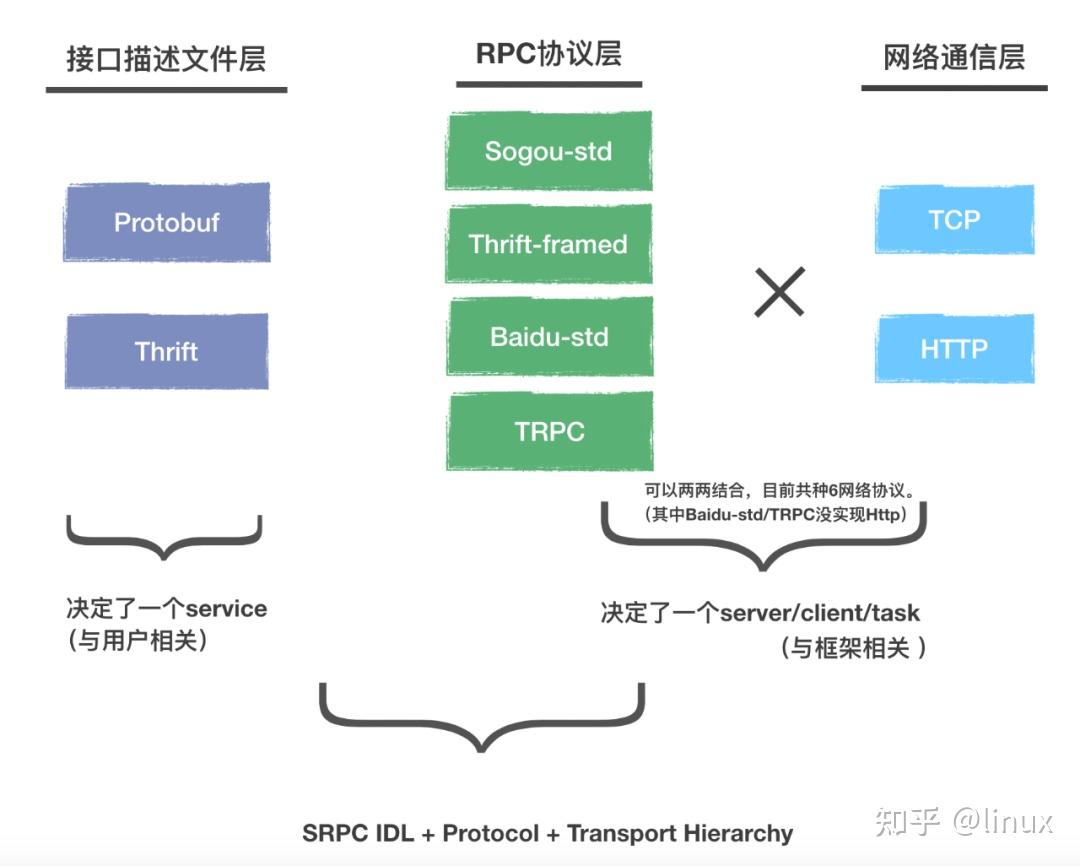
从左到右,是用户接触的最多到最少的层次。
中间那列是具体的网络协议,而各RPC能互通,就是因为大家实现了对方的“语言”,因此可以协议互通。
而RPC作为和HTTP并列的层次,第二列和第三列理论上是可以两两结合的,只需要第二列的具体RPC协议在发送时,把HTTP相关的内容进行特化,不要按照自己的协议去发,而按照HTTP需要的形式去发,就可以实现RPC与HTTP互通。
其中,Dubbo 是可以支持 protobuf 自定义协议的,也就是说,Dubbo 可以把用户编写的 Protobuf 的 IDL,转换成Dubbo框架自己的 Java 生成代码,配置Dubbo的 Protobuf 代码生成插件后,在 maven 编译的时候,就会生成 Dubbo 框架对应的代码,所以说,如果你使用 protobuf,中间 client 和 service 还会有一个生成代码的过程
如何实现层级解耦
RPC 框架的实现都很注重层次之间的解耦,层级之间做什么不会互相干扰,Dubbo 核心通过 SPI 机制 实现这一点,不少人认为这是 Dubbo 的灵魂设计,就以 Dubbo 作为完全的例子来说了
SPI 是 Service Provider Interface,是 Dubbo 实现 “插件化扩展” 的基础 , 每个层级(序列化 / 压缩 / 协议)都定义了标准接口,扩展新实现时只需新增插件,无需修改框架核心代码。
假如,我们希望新增一种 LZ4 压缩算法
Dubbo 中横向增加压缩算法无需改现有代码,只需要新定义即可,对应的上面的设计理念
定义对应的标准接口,这只是一个对Dubbo压缩层标准接口的简单的展示
1
2
3
4public interface Compressor {
byte[] compress(byte[] data);
byte[] decompress(byte[] data);
}因为框架的协议层在处理报文的时候,只调用
compressor.compress(data),它根本不关心底层是 Gzip、Snappy 还是你要新增的 LZ4。实现 LZ4 压缩插件
1
2
3
4public class Lz4Compressor implements Compressor {
public byte[] compress(byte[] data) { /* LZ4 压缩逻辑 */ }
public byte[] decompress(byte[] data) { /* LZ4 解压逻辑 */ }
}然后注册进去
1
lz4=com.yourcompany.project.Lz4Compressor
然后业务代码直接使用或者配置类配置就行,这是一个自适应调用的过程,Dubbo 会通过
ExtensionLoader扫描这些配置文件,将lz4这个 Key 和你的类关联起来。当 RPC URL 中携带compressor=lz4参数时,框架会自动实例化并注入你的Lz4Compressor。
那么,Dubbo 是这样解耦实现各个层级的,通过提供不同的接口,什么意思,在任何解耦的系统中,核心框架只认识接口,不认识实现。在 Dubbo 中,这些层级都被抽象为一个个的接口。
| 层级 | Dubbo 标准接口 | 扩展示例(新增无需改核心代码) |
|---|---|---|
| 序列化层 | Serialization |
Protobuf/Thrift/JSON/Hessian2 |
| 压缩层 | Compressor |
Gzip/LZ4/Snappy/None |
| 协议层 | Protocol |
Dubbo/HTTP/Thrift/TRPC |
| 通信层 | Transporter |
Netty4/TCP/HTTP2 |
而切换 Server 类型,也只需要在Dubbo 中只需修改配置即可,可以说,这种解耦和方便配置是很多框架的核心设计,RPC 协议的各种实现也把这些内容视为了重要的设计理念
1 | # 1. 使用 Dubbo 原生 Server(基于 TCP) |
透明化远程服务调用
怎么封装通信细节才能让用户像以本地调用方式调用远程服务呢?还是接着上面,拿 Dubbo 作为 RPC 协议的实现框架作为例子来说吧,其中Dubbo 实现 “透明化远程服务调用” 的核心逻辑,还是通过上面说的生成代码(Stub / 代理)+ 框架自动封装,实现的伪装
Dubbo 会基于服务接口(或 IDL)生成 客户端 Stub 代理类,用户调用这个代理类的方法时,实际是触发远程调用逻辑,但用户感知上和调用本地方法完全一致。
例如,用户定义的
EchoService接口,Dubbo 生成EchoServiceDubboStub代理类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 用户眼中的“本地接口”
public interface EchoService {
EchoResponse echo(EchoRequest request);
}
// Dubbo生成的代理类(用户无感知)
public class EchoServiceDubboStub implements EchoService {
private DubboInvoker invoker; // 框架的远程调用器
public EchoResponse echo(EchoRequest request) {
// 代理类偷偷把“本地方法调用”转成远程调用
return invoker.invoke(
new RpcInvocation("echo", new Object[]{request})
).recreate();
}
}那么,如果需要使用,只需通过
@DubboReference注入EchoService,调用echo()就像调用本地方法,完全不知道背后是远程请求。
而框架层对远程调用的细节更是封装到了极致,Dubbo 框架在代理类的背后,自动完成 序列化、协议打包、网络传输、响应解析 等所有远程细节,用户无需写一行相关代码。
具体封装的细节包括:
- 序列化 / 反序列化:自动把请求 和 响应对象转成二进制,比如 Protobuf/Hessian2;
- 压缩 / 解压:自动对大请求大响应做压缩,比如 Gzip/LZ4;
- 协议封装:自动给数据加 “Dubbo 协议头”,包含接口名、方法名、版本等元信息;
- 网络通信:自动用 Netty 建立长连接,发送 / 接收数据。
而服务发现与地址的透明就需要注册中心来实现了,以前是 ZooKeeper,现在是 Nacos 更多一点,这些注册中心会自动注册服务,自动完成服务地址的发现与管理,完全不用关心服务端部署在哪里
那么方法写在了哪里更不需要复杂的思索,因为服务端只需通过
@DubboService 注解标记实现类,Dubbo 会自动把这个类
暴露为远程服务,用户不用手动实现这部分
如何对消息进行编码和解码
对消息进行编码解码的本质上就是为了让跨进程跨语言的对象能在网络上传输,并在对方进程中还原成可用的对象
首先回顾一下序列化相关内容
- 序列化就是将数据结构或对象转换成二进制串的过程,也就是编码的过程。
- 反序列化就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程,也就是解码
为什么需要序列化?转换为二进制串后才方便进行网络传输,为什么需要反序列化?将二进制转换为对象才方便进行后续处理
这部分就是 RPC 的兼容性,而还是像上述那样,Dubbo 把 编码 解码封装成了可插拔的组件,不详细说明
说一下一些 RPC 框架中常用的序列化方案
| 序列化方案 | 特点 |
|---|---|
| Hessian2(默认) | 轻量、跨语言(Java/Go 等)、性能中等 |
| Protobuf | 体积小、编解码快、跨语言(全语言支持) |
| JSON | 可读性强、跨语言,但体积大、性能差 |
| Thrift | 自带 IDL、跨语言、性能优 |
不同序列化方案的核心差异,在于 怎么把对象转成二进制” 的规则,因为转过去,就能转回来
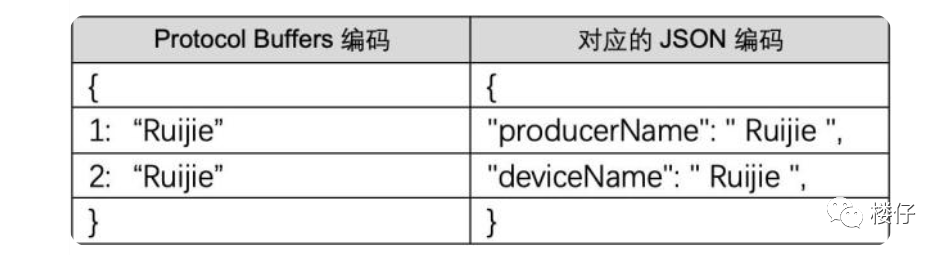
Protobuf 是
“二进制紧凑编码”,比如把EchoRequest(message="hello")转成二进制
给每个字段分配数字标签(比如
message字段的标签是 1)用 “标签 + 类型 + 值” 的紧凑格式存储:
比如
message="hello"会被编码成 08 05 68 65 6C 6C 6F,其中08是标签 + 类型,05是字符串长度,后面是 “hello” 的 ASCII 码。好处不言而喻,体积小、编解码快,不用存字段名,只存标签
JSON 不多说,人类可读,编码解码慢,体积大
那么这部分也和上面说的版本兼容有关系,比如服务端新增了字段,旧客户端没这个字段怎么办?选支持 字段兼容 的序列化方案(比如 Protobuf/Thrift),会自动忽略未知字段。 Protobuf/Thrift 更是很好的支持跨语言,不同语言用同一份 IDL 生成代码即可
RPC 对比 HTTP ——既生瑜何生亮
协议设计:RPC 与 HTTP 的本质区别
“既然有了 HTTP,为什么还要 RPC 协议?” 这是一个深层的技术考量,他们的选择并非简单的谁优谁劣,而是设计哲学与应用场景权衡的结果。直到今日,我依旧无限感慨 RPC 还是太牛逼了
首先,无论是微服务还是分布式服务,他们都面临着服务间的远程调用的问题,而 HTTP 和 RPC 都是作为服务间的远程调用的方式,但是他们负责的各个部分,还是很不一样的,这就要从协议的设计说起
RPC (Action-Oriented): 它的协议设计的核心思想是“像调用本地函数一样调用远程函数”。你关注的是做什么。这种方式对开发者非常友好,屏蔽了底层网络细节。
HTTP/REST (Resource-Oriented): 它的核心是状态转移。你关注的是资源是什么。通过标准的 HTTP 动词(GET, POST, PUT, DELETE)对特定的 URL(资源)进行操作。
RPC 倾向于远程操作的业务导向,HTTP 倾向于资源操作的业务导向
而且,RPC 的设计目标是 服务间高效、透明的远程调用,它核心面向的是后端服务,HTTP 的设计目标是通用的跨系统数据交互,是面向 Web 倾向性更大,如浏览器→服务器、前端→后端
所以说,光用 RPC 不用 HTTP 不太可行,只用 HTTP 不用 RPC 还很不方便
本质区别一目了然
传输效率与序列化
在高性能场景下,这也是考量的关键点。
虽然,两者底层通讯都是基于socket,都可以实现远程调用,都可以实现服务调用服务,简单对比一下
| 维度 | RPC (以 gRPC/Dubbo 为例) | HTTP (通常指 REST/JSON) |
|---|---|---|
| 序列化 | 通常使用 Protobuf 或 Thrift(二进制格式),体积小,解析极快。 | 通常使用 JSON/XML(文本格式),包含大量冗余标签,解析开销大。 |
| 协议层 | 现代 RPC 多基于 HTTP/2(多路复用、头部压缩),甚至自定义 TCP 协议。 | 传统 REST 多基于 HTTP/1.1(存在头部阻塞问题),尽管 HTTP/2 已普及,但 JSON 的文本本质仍是瓶颈。 |
| 连接管理 | 通常维持长连接,减少握手开销。 | HttpClient默认为短连接或带超时的 Keep-alive。 |
实际上,传续效率受到很多的影响,两者协议头开销也是不同的
- RPC:协议头极简,不是必要信息不放
- HTTP:协议头冗余,即使是 HTTP 2(二进制帧),也保留了大部分 HTTP 语义头,
连接方式上来看,两者更是有一定的区别
- RPC:默认 TCP 长连接
- HTTP:虽然HTTP 2 支持长连接 + 多路复用,但是,HTTP核心还是短连接
但是,RPC 的高效不是我从技术上比 HTTP 厉害,这样的设计是有场景严格限制和一定代价的
因为 RPC 面向 已知的服务间调用,可以预先通过 IDL 约定数据格式、接口定义,省去 HTTP 中通用语义头、弱类型兼容的开销。而 HTTP 要兼容浏览器、网关等通用场景,无法放弃通用性换性能。
契约与耦合度
HTTP 与 RPC 之间,对类型的要求是不同的,这直接影响到大型团队协作和代码质量的控制。
首先,RPC是强契约的,因为RPC 的强契约是通过 IDL接口定义语言+ 编译时生成代码 实现的,这个耦合度虽然很高,但是是完全可以控制的,而且编译时就能拦截各种问题,不仅如此,生成的代码自带序列化反序列化,几乎不会出现各种运行时的异常,代码质量是比较高的,协作成本是一个前期高,后期低的过程
而 HTTP 是弱契约的,实际上,经常 HTTP 的契约实现是离不开接口文档的,这东西以前就是个纸,直到现在的 OpenAPI,实际上也只是一个字面上的参考,方便协作的,你不写完全不能怎么样,而双方是松散适配的,耦合度肯定低,我不信你没出现过文档更新不及时,客户端调用旧字段的问题))
HTTP 弱契约也严格代表代码质量严格依靠人工,双方靠 约定的 JSON 结构 交互,编译时候几乎没有检查,这是运行时适配,协作成本是一个前期低,后期高的过程
所以说,在不同的情况下,要分清上述的内容
服务治理
在微服务规模扩大时,治理能力的差异会显现。
- RPC 框架: 像 Dubbo 或 gRPC 往往自带服务发现、负载均衡、熔断、限流、重试策略等功能。这些功能深度集成在框架内,性能和稳定性更可控。
- HTTP 生态: 协议本身不包含治理功能。通常需要通过外部工具链(如 Nginx、API Gateway、Service Mesh/Envoy)来实现治理逻辑。
这个其实没啥好说的,微服务会自带各种服务高可靠高性能的套件,这是 RPC 框架的特性能够实现的
内敛还是开放
很明显,两者的定位不同,使用场景不一致的情况下,可以探讨一下内敛还是开放的问题
- RPC: 适合微服务内部、高并发、低延迟的场景。如果你的服务都在内网,且由同一技术团队维护,RPC 是首选。
- HTTP: 适合对公众开放、浏览器端调用、跨语言/平台的场景。它是互联网的“通用语言”,几乎任何设备、任何语言都能轻松发起 HTTP 请求。






