
线程池介绍
如何理解线程池
池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、HTTP 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
但是池化技术离不开多线程,多线程根本的池化技术就是 Java 线程池
我们都知道启动一个新线程非常方便,但是,创建线程需要操作系统资源,频繁创建和销毁大量线程需要在资源分配和切换上消耗大量时间。
所以说,线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
- 频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大。
- 对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险。
- 系统无法合理管理内部的资源分布,会降低系统的稳定性。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。所以,我们可以使用池化思想来复用一组线程:
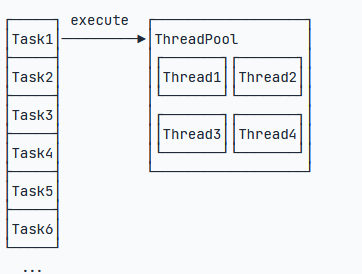
那么我们就可以把很多小任务让一组线程来执行,而不是一个任务对应一个新线程。这种能接收大量小任务并进行分发处理的就是线程池。
线程池内部维护了若干个线程,没有任务的时候,这些线程都处于等待状态。如果有新任务,就分配一个空闲线程执行。如果所有线程都处于忙碌状态,新任务要么放入队列等待,要么增加一个新线程进行处理。
线程池提供了一种限制和管理资源,包括执行一个任务的方式。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。使用线程池主要带来以下几个好处:
- 降低资源消耗:线程池里的线程是可以重复利用的。一旦线程完成了某个任务,它不会立即销毁,而是回到池子里等待下一个任务。这就避免了频繁创建和销毁线程带来的开销。
- 提高响应速度:因为线程池里通常会维护一定数量的核心线程(或者说“常驻工人”),任务来了之后,可以直接交给这些已经存在的、空闲的线程去执行,省去了创建线程的时间,任务能够更快地得到处理。
- 提高线程的可管理性:线程池允许我们统一管理池中的线程。我们可以配置线程池的大小(核心线程数、最大线程数)、任务队列的类型和大小、拒绝策略等。这样就能控制并发线程的总量,防止资源耗尽,保证系统的稳定性。同时,线程池通常也提供了监控接口,方便我们了解线程池的运行状态(比如有多少活跃线程、多少任务在排队等),便于调优
JUC 线程池中都有哪些内容
Executor 框架是 Java5 之后引进的,在 Java 5 之后,通过
Executor 来启动线程比使用 Thread 的
start
方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免
this 逃逸问题。
this 逃逸是指在构造函数返回之前其他线程就持有该对象的引用,调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
Executor
框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor
框架让并发编程变得更加简单。
JUC 线程池基于 Executor 框架构建,其核心接口与实现关系如下
1 | Executor |
其中,最核心的实现类就是 ThreadPoolExecutor,这是 JUC
线程池的灵魂类,几乎所有自定义线程池都基于它。
所以说,Executor 框架结构主要由三大部分组成
任务:
Runnable/Callable执行任务需要实现的
Runnable接口 或Callable接口。Runnable接口或Callable接口 实现类都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor执行。任务的执行(
Executor)包括任务执行机制的核心接口
Executor,以及继承自Executor接口的ExecutorService接口。ThreadPoolExecutor和ScheduledThreadPoolExecutor这两个关键类实现了ExecutorService接口。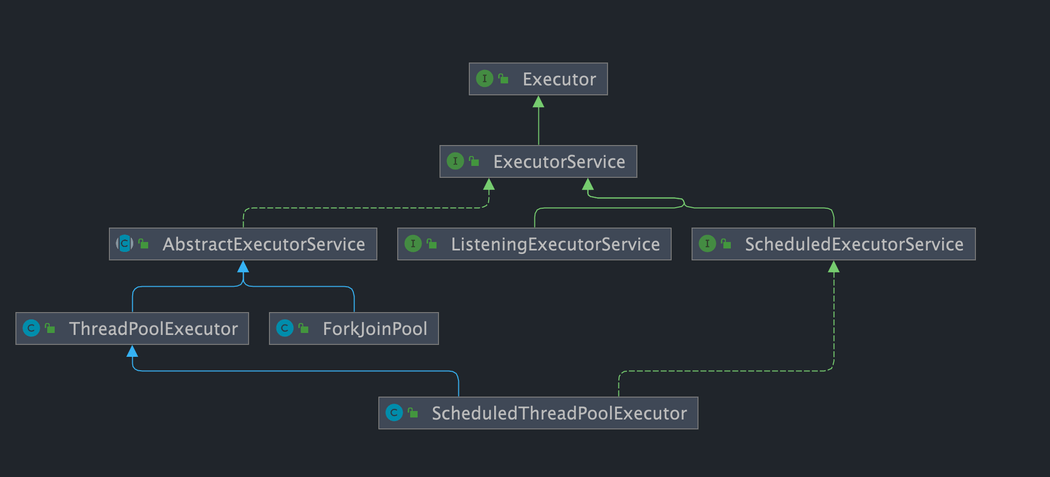
异步计算的结果(
Future)Future接口以及Future接口的实现类FutureTask类都可以代表异步计算的结果。这就是我们在在多线程开发中启动一个任务去执行耗时操作不阻塞主线程然后接收结果的组件我们把
Runnable接口 或Callable接口 的实现类提交给ThreadPoolExecutor或ScheduledThreadPoolExecutor执行。(调用submit()方法时会返回一个FutureTask对象)
那么,使用Executor 框架就是这样使用
主线程首先要创建实现
Runnable或者Callable接口的任务对象。把创建完成的实现
Runnable/Callable接口的 对象直接交给ExecutorService执行,或者也可以把Runnable对象或Callable对象提交给ExecutorService执行如果执行
ExecutorService.submit(…),也就是把Runnable对象或Callable对象提交给ExecutorService执行了,ExecutorService将返回一个实现Future接口的对象。但是由于FutureTask实现了Runnable,我们也可以创建FutureTask,然后直接交给ExecutorService执行。最后,主线程可以执行
FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行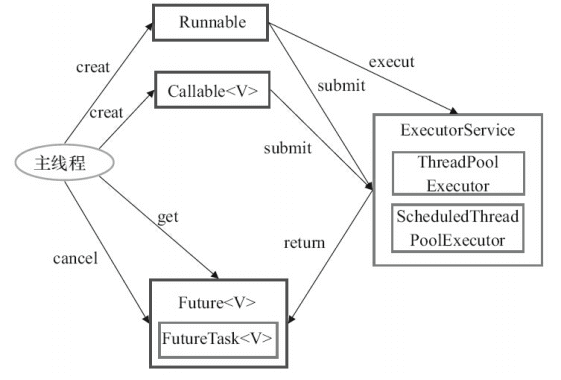
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import java.util.concurrent.*;
public class FutureDemo {
public static void main(String[] args) throws Exception {
// 1. 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(2);
try {
// 2. 创建一个 Callable 任务(带返回值)
Callable<String> task = new Callable<String>() {
public String call() throws Exception {
Thread.sleep(2000); // 模拟耗时操作
return "Hello from thread!";
}
};
// 3. 提交任务,返回 Future 对象
Future<String> future = executor.submit(task);
// 4. 主线程可以继续做其他事情...
System.out.println("主线程继续执行...");
// 5. 等待任务完成,获取结果
String result = future.get(); // 这里会阻塞,直到任务完成
System.out.println("任务结果:" + result);
} finally {
// 6. 关闭线程池
executor.shutdown();
}
}
}
使用线程池框架中重要的接口
Executor接口
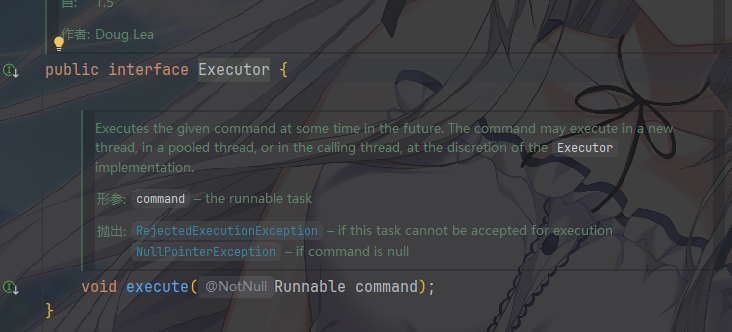
可以看到,它就一个方法,所以说,Executor
是最简单的线程池执行器,只负责任务的提交,它定义了一个最简单的契约,接受一个
Runnable 任务,并在某个时间点执行它。
可以看出,它什么都没有说,Executor
不保证异步,也不提供任何控制手段
Executor 负责执行,那么ExecutorService
负责服务管理,而且也保证了让上层业务代码不依赖具体实现
永远使用
ExecutorService,不要用
Executors 工厂方法创建线程池
ExecutorService 接口
而对于ExecutorService 接口,继承了 Executor
的能力,并扩展出更多高级功能,很多线程池是继承它来实现各种功能的

总结一下,它的方法有这些
线程池生命周期控制:
1
2
3
4
5
6
7// 平滑关闭:不再接受新任务,但执行完已有任务
void shutdown();
// 强制关闭:中断正在执行的任务,返回未执行的任务列表
List<Runnable> shutdownNow();
boolean isShutdown(); // 是否已调用 shutdown()
boolean isTerminated(); // 是否所有任务都已完成(即真正关闭)
boolean awaitTermination(long timeout, TimeUnit unit); // 等待关闭完成- 其中,
close()方法是在 JDK 19+ 中,ExecutorService增加的一个默认方法,它通过实现了AutoCloseable接口获得的能力,所以说,线程池这才支持使用try-with-resources自动关闭线程池
- 其中,
提交任务并获取结果,这是它的核心方法
1
2
3<T> Future<T> submit(Callable<T> task); // 提交可返回结果的任务
Future<?> submit(Runnable task); // 提交无返回值任务
<T> Future<T> submit(Runnable task, T result); // 提交任务,指定返回结果线程池的
execute和submit是基础方法 入参 返回值 核心逻辑 execute(Runnable)Runnablevoid直接执行任务,无返回值,无法获取结果 / 状态 submit(Runnable/Callable)Runnable/CallableFuture<V>封装任务为可执行的 Future 实现类(默认是 FutureTask),执行后返回该 Future 供调用方使用
一些相对高级的操作
1
2
3
4
5
6
7// invokeAll():执行所有任务,等待全部完成
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
// invokeAny():执行多个任务,只要有一个成功就返回
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
Runnable 和
Callable 接口
Runnable 和 Callable 这两个接口的内容很简单
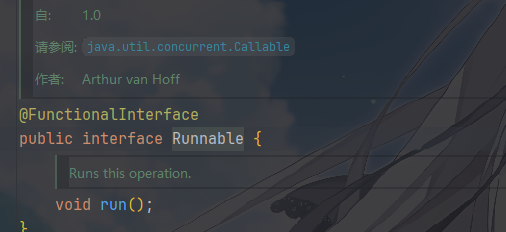
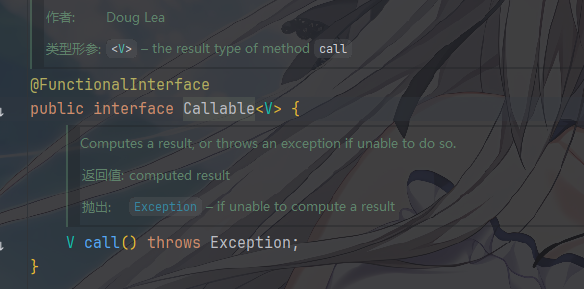
- 两者都只有一个抽象方法,因此都可以用 Lambda 表达式简化编写
在执行多个任务的时候,使用Java标准库提供的线程池是非常方便的,我们提交的任务只需要实现Runnable接口,就可以让线程池去执行:
有两种核心用法:
方式 1:
execute(Runnable):无返回值,无法获取执行结果 / 状态;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class RunnableExecuteDemo {
public static void main(String[] args) {
// 1. 创建标准线程池(核心2,最大4,队列容量10)
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10)
);
// 2. 提交Runnable任务(无返回值)
executor.execute(() -> {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println("Runnable任务执行完成:" + Thread.currentThread().getName());
} catch (InterruptedException e) {
// Runnable中必须捕获检查型异常
Thread.currentThread().interrupt();
System.err.println("任务被中断");
}
});
// 3. 关闭线程池
executor.shutdown();
}
}方式 2:
submit(Runnable):返回Future<?>,仅能判断任务是否完成 / 取消,无法获取结果,因为Runnable接口的对象不存储结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class RunnableSubmitDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10)
);
// 1. 提交Runnable,获取Future<?>
Future<?> future = executor.submit(() -> {
System.out.println("Runnable任务执行中...");
TimeUnit.SECONDS.sleep(1);
});
// 2. 通过Future判断状态
System.out.println("任务是否完成:" + future.isDone());
// 3. 获取结果
Object result = future.get();
System.out.println("任务结果:" + result); // null
executor.shutdown();
}
}
Runnable接口有个问题,它的方法没有返回值。如果任务需要一个返回结果,那么只能保存到变量,还要提供额外的方法读取,非常不便。
所以,Java标准库还提供了一个Callable接口,和Runnable接口比,它多了一个返回值,并且Callable接口是一个泛型接口,可以返回指定类型的结果。
只有一种核心用法:
submit(Callable<V>):返回Future<V>,既能判断状态,也能通过Future.get()获取返回值,或捕获执行中的异常。
1 | public class CallableSubmitDemo { |
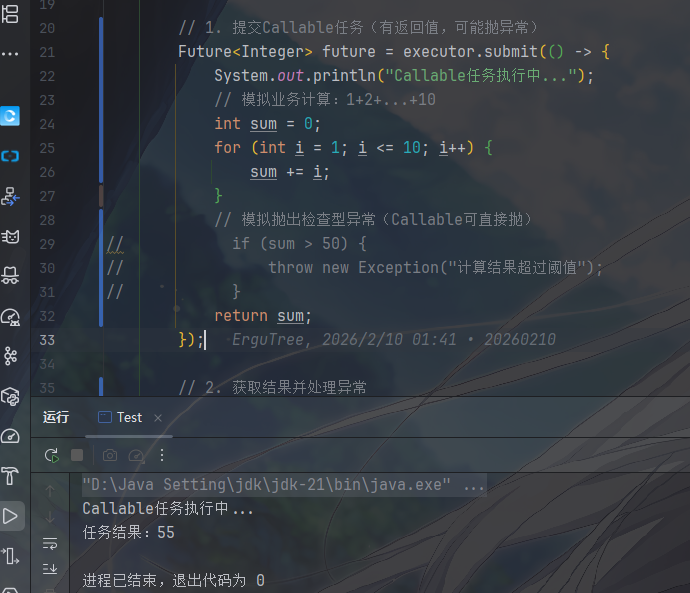
对于 Runnable 转 Callable,JDK 提供了
Executors.callable(Runnable task, V result)
工具方法,可以将 Runnable 包装成 Callable
- 包装后执行
call()会调用Runnable.run(),并返回指定的result; - 如果不需要返回值,可传入
null,即Executors.callable(runnable, null),而FutureTask内部就是这么做的。
1 | public class RunnableToCallableDemo { |
最后来对比一下二者
| 特性 | Runnable |
Callable<V> |
|---|---|---|
| 核心方法 | void run() |
V call() throws Exception |
| 返回值 | 无(void) | 有返回值(泛型 V) |
| 异常处理 | 只能捕获运行时异常,无法抛出检查型异常 | 可以抛出任意异常(包括检查型异常) |
| 引入版本 | JDK 1.0 | JDK 1.5(并发包) |
| 函数式接口 | 是(@FunctionalInterface) |
是(@FunctionalInterface) |
| 线程池直接执行 | 支持(executor.execute()) |
不支持直接执行,需包装 / 通过 submit() |
| 与 Future 结合 | 无直接关联,需手动包装 | 天然结合(submit() 返回 Future) |
对于二者在捕获异常上的区别
Runnable.run()没有throws声明,因此如果在run()中抛出检查型异常(如IOException),必须手动try-catch,否则编译报错;Callable.call()有throws Exception,可以直接抛出任何异常,由调用方(线程池)捕获并封装到Future.get()时的ExecutionException中。
那么,他们都是同步的,会即时提交给线程池然后返回结果,那么,现在的问题是,如何获得异步执行的结果?
仔细看ExecutorService.submit()方法,可以看到,它返回了一个Future类型,一个Future类型的实例代表一个未来能获取结果的对象
1 | ExecutorService executor = Executors.newFixedThreadPool(4); |
当我们提交一个Callable任务后,我们会同时获得一个Future对象,然后,我们在主线程某个时刻调用Future对象的get()方法,就可以获得异步执行的结果。在调用get()时,如果异步任务已经完成,我们就直接获得结果。如果异步任务还没有完成,那么get()会阻塞,直到任务完成后才返回结果。对于这个接口,下面细说
Future 接口
Future<T> 接口
Future<T>
是一个接口,代表异步计算的结果。
你提交一个耗时任务到线程池后,主线程不用阻塞来等待结果,线程池会返回一个
Future
对象。这个对象就像一个提货单,你可以在需要使用到这个结果的时候,通过它获取任务的最终结果,也能查询任务状态、取消任务。
那么,Future<T> 接口的核心方法如下
1 | public interface Future<V> { |
Future
必须结合线程池(ExecutorService)使用,因为它本身只是一个结果容器,不负责执行任务。
1 | import java.util.concurrent.*; |
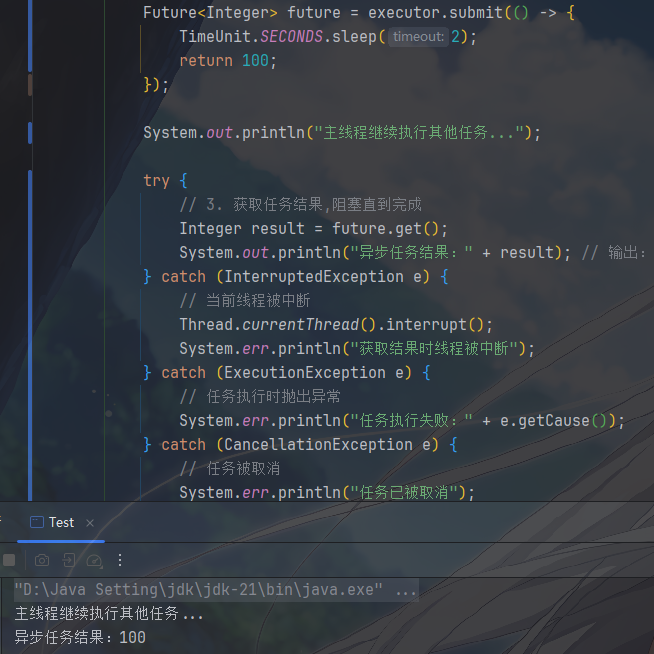
线程池的核心是 任务提交 - 任务执行 - 结果获取
这三个步骤,Future就是结果的载体,把结果获取这个步骤成功分离,实现了按需获取结果,之所以线程池的核心方法
executor.submit(Callable<T>) 会返回
Future<T>,本质是
- 线程池负责执行任务(在工作线程中跑
Callable.call()); Future负责存储结果(任务完成后,结果会被写入Future);- 调用方负责获取结果(通过
Future.get()读取)。
FutureTask
而平时,大家更爱用FutureTask ,它是 Future
的唯一官方实现类,同时实现了
Runnable接口,因为RunnableFuture 接口它继承了
Runnable + Future,所以它也可以直接交给线程池执行

因为它既包含要执行的任务(Callable/Runnable),也实现了
Future
接口的所有管控方法e,所以它可以直接被线程池(Executor)执行,还可以直接被普通的Thread执行
它把结果容器和任务载体合二为一
对于FutureTask 的源码,核心是状态机 + CAS +
等待队列,所以它线程安全
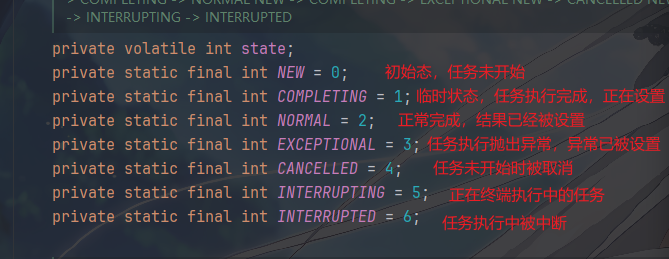
FutureTask 用一个 volatile int state
变量维护任务生命周期,所有状态转换都是单向的、不可逆的,且通过
CAS 保证原子性。
核心执行逻辑是run()方法,它本质上是一个状态机的状态转换,直接拿群友的分析的了
1 | public void run() { |
FutureTask
有两种典型使用方式,交给线程池执行和交给Thread执行,本质都是利用它可执行
+ 可获取结果的特性,虽然来说,使用起来并无很明显的差别
二编:很多人认为Future 和 FutureTask 两者差不多,使用起来确实是这样的,但是要说一些其他的问题
所以说,
FutureTask能被execute执行,调用方还能通过它的 Future 方法取结果(向上转型),但是对于调用线程池submit (),传入封装了Runnable或者Callable的Future对象,它内部实际执行者是FutureTask,其中有自动创建的逻辑,它是submit ()能返回Future的核心
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1, 1, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10)
);
// 1. 手动创建FutureTask(封装Callable任务)
FutureTask<Integer> futureTask = new FutureTask<>(() -> {
System.out.println("任务执行中:" + Thread.currentThread().getName());
return 100;
});
// 2. 传入线程池执行(execute接收Runnable,FutureTask实现了Runnable)
executor.execute(futureTask);
// 3. 调用Future接口方法(futureTask向上转型为Future)
Future<Integer> future = futureTask; // 本质是同一个对象
System.out.println("任务是否完成:" + future.isDone());
System.out.println("任务结果:" + future.get());
executor.shutdown();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1, 1, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10)
);
// 1. 调用submit,传入Callable,返回Future(底层是FutureTask)
Future<Integer> future = executor.submit(() -> {
System.out.println("任务执行中:" + Thread.currentThread().getName());
return 100;
});
// 2. 调用Future接口方法(实际调用的是FutureTask的实现)
System.out.println("任务是否完成:" + future.isDone());
System.out.println("任务结果:" + future.get());
// 验证:返回的Future本质是FutureTask
System.out.println("Future的实际类型:" + future.getClass().getName());
// 输出:java.util.concurrent.FutureTask
executor.shutdown();
}
1 | import java.util.concurrent.*; |
对了,FutureTask 还提供了 runAndReset()
方法,执行任务但不设置结果,执行完后重置为 NEW
状态,但是使用它需要重写FutureTask中的runAndReset()
方法,因为它是protected,这样就针对结果不怎么总要的任务,可复用FutureTask
对象
CompletableFuture
在上面我们提到了,使用Future获得异步执行结果时,要么调用阻塞方法get(),要么轮询看isDone()是否为true,这两种方法都不是很好,因为主线程也会被迫等待。
从Java
8开始引入了CompletableFuture,它针对Future做了改进,可以传入回调对象,当异步任务完成或者发生异常时,自动调用回调对象的回调方法。
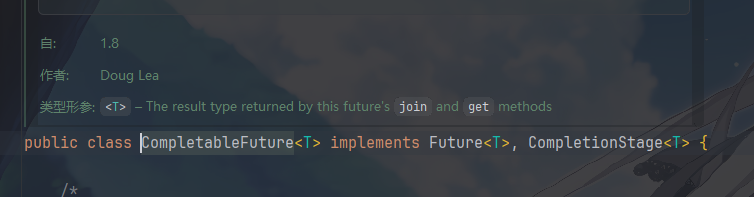
它实现了两个核心接口:
- Future:传统异步获取结果、取消、判断完成。
- CompletionStage:灵魂—— 支持异步编排、链式调用、多任务组合
它有两个关键字段

result == null,代表任务未完成result != null,代表任务已完成普通对象,代表正常结果
AltResult,代表异常 /null/ 取消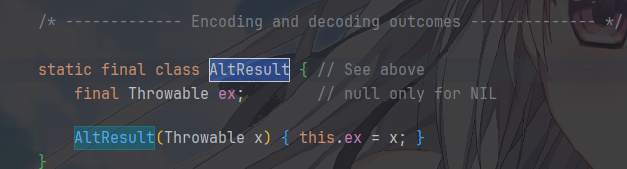
它的完成机制是这样的,用 CAS 原子设置
result,一旦完成,自动遍历 stack
链中的各种回调方法,执行所有回调,全程无锁,高并发性能好
CompletionStage 核心 API
基础链式回调
1
2
3
4// 基础链式回调
future.thenApply(s -> s.length()) // 转换结果(有入参、有返回)
.thenAccept(i -> System.out.println(i)) // 消费结果(有入参、无返回)
.thenRun(() -> System.out.println("done")); // 完成后执行后续任务(无入参、无返回)thenApply(Function<T, R>)- 接收上一阶段的结果
s(类型 T) - 返回新结果(类型 R),供后续阶段使用
- 同步执行:由完成
future的线程直接调用此 lambda
- 接收上一阶段的结果
thenAccept(Consumer<T>)- 接收上一阶段结果
i,但不返回新值(返回CompletableFuture<Void>) - 用于“消费”结果,如日志、通知等
- 接收上一阶段结果
thenRun(Runnable)- 不接收任何参数,也不关心前序结果
- 只在前序任务完成后执行某个动作(如清理、计数)
异步版本(交给默认的线程池执行)
1
2
3
4// 所有上述方法都有 .xxxAsync() 重载:
future.thenApplyAsync(s -> s.length()) // 异步转换
.thenAcceptAsync(i -> System.out.println(i)) // 异步消费
.thenRunAsync(() -> System.out.println("done")); // 异步执行组合两个任务(AND:两者都完成)
1
2
3
4
5
6
7
8
9
10
11
12// 合并两个结果,返回新值
future1.thenCombine(future2, (r1, r2) -> r1 + r2);
// 两个都完成,消费两个结果(无返回)
future3.thenAcceptBoth(future2, (r1, r2) -> {
System.out.println("r1=" + r1 + ", r2=" + r2);
});
// 两个都完成后执行无参任务(注意:**不能有参数!**)
future4.runAfterBoth(future2, () -> {
System.out.println("Both done!");
});任选一个完成(OR:谁先完成就用谁)
1
2
3
4
5
6
7
8// 谁先完成,就用它的结果做转换
CompletableFuture<String> result = futureA.applyToEither(futureB, s -> "Winner: " + s);
// 谁先完成,就消费它的结果
futureA.acceptEither(futureB, s -> System.out.println("First: " + s));
// 谁先完成,就执行无参任务
futureA.runAfterEither(futureB, () -> System.out.println("One of them finished!"));异常处理
1
2
3
4
5
6
7
8
9future.exceptionally(e -> "默认值") // 仅异常时触发,返回 fallback 值
.whenComplete((r, e) -> { // 无论成功/失败都执行(消费型)
if (e != null) System.err.println("Error: " + e);
else System.out.println("Result: " + r);
})
.handle((r, e) -> { // 无论成功/失败都处理,并返回新结果
if (e != null) return "Recovered";
else return r.toUpperCase();
});方法 触发条件 是否影响结果 返回类型 exceptionally仅异常 可返回新正常值 CompletableFuture<T>whenComplete总是 不改变结果(只是 side-effect) CompletableFuture<T>handle总是 可基于异常/结果返回新值 CompletableFuture<R>多任务批量组合
1
2
3
4
5
6
7// 所有任务完成才完成(返回 CompletableFuture<Void>)
CompletableFuture<Void> allDone = CompletableFuture.allOf(f1, f2, f3);
allDone.join(); // 阻塞等待全部完成
// 任意一个完成就完成(返回 CompletableFuture<Object>)
CompletableFuture<Object> firstDone = CompletableFuture.anyOf(f1, f2, f3);
Object result = firstDone.join(); // 获取最先完成的那个结果
创建 CompletableFuture 的 4 种方式
1 | // 1. 空任务,手动 complete |
Future 做不到 CompletableFuture
的手动控制完成
1 | // 正常完成 |
CompletableFuture 的三种获取结果
1 | // 1. 会抛检查异常 InterruptedException / ExecutionException |
- 开发 99% 用
join(),代码干净
最后,我们搞一些例子,看看如何使用CompletableFuture:
异步执行一个任务,任务完成时自动回调消费结果,出错时自动回调处理异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 异步执行任务,做咖啡
CompletableFuture<String> makeCoffee = CompletableFuture.supplyAsync(() -> makeCoffee());
// 任务成功完成时的回调:喝掉咖啡(Consumer 接口,只消费结果,无返回)
makeCoffee.thenAccept(coffee -> {System.out.println("成功拿到:" + coffee + ",开喝!");});
// 任务异常时的回调
makeCoffee.exceptionally(e -> {
System.out.println("做咖啡失败了:" + e.getMessage());
return "速溶咖啡"; // 异常时的兜底方案
});
makeCoffee.join();
}
// 模拟做咖啡:30%概率失败,70%成功返回咖啡名称
private static String makeCoffee() {
try {
Thread.sleep(100); // 模拟制作耗时
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 随机模拟失败场景
if (Math.random() < 0.3) {
throw new RuntimeException("咖啡机坏了!");
}
return "拿铁咖啡";
}
}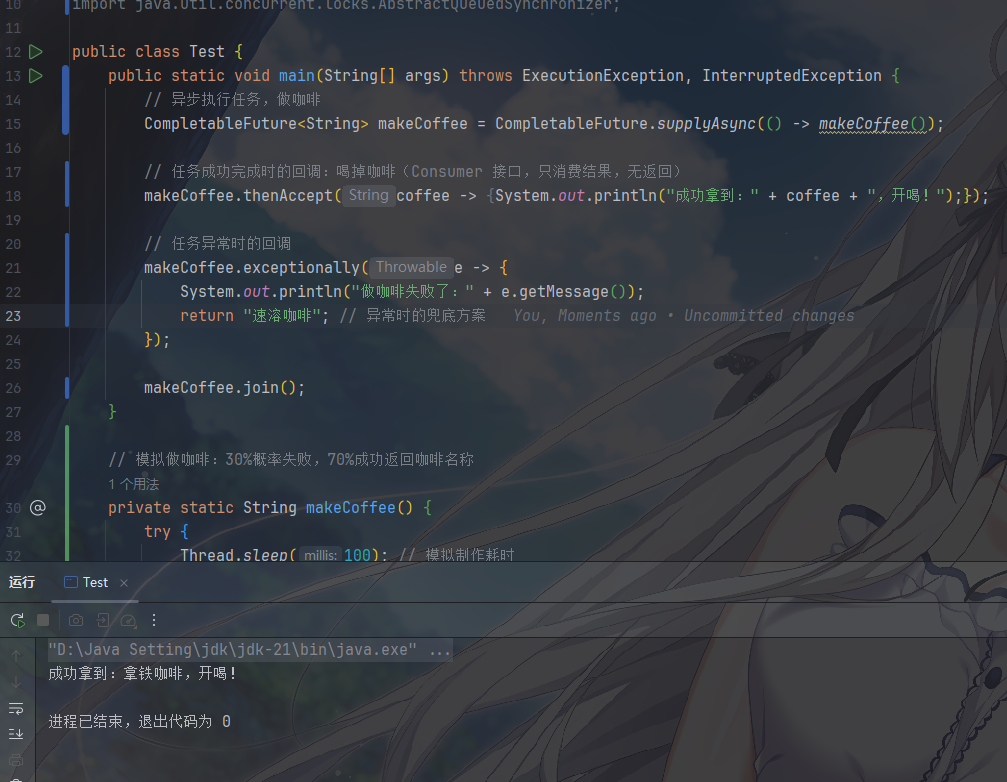
supplyAsync把 “做咖啡” 这个任务丢到默认线程池异步执行,返回一个CompletableFuture对象代表未来的结果;全程主线程不用阻塞等结果,任务完成 / 失败会自动触发对应的回调
那么,如果只是实现了异步回调机制,我们还看不出
CompletableFuture相比Future的优势。CompletableFuture更强大的功能是,多个CompletableFuture可以串行执行1
2
3
4
5
6
7
8
9
10
11
12
13public static void main(String[] args) throws ExecutionException, InterruptedException {
// 异步烤面包
CompletableFuture<String> bakeBread = CompletableFuture.supplyAsync(Test::bakeBread);
// 面包烤好后异步摸果酱
CompletableFuture<String> addJam = bakeBread.thenApplyAsync(Test::addJam);
// 抹好果酱后,吃面包(消费最终结果)
addJam.thenAccept(food -> {System.out.println("最终拿到:" + food + ",开吃!");});
addJam.join();
}
// 其他方法省略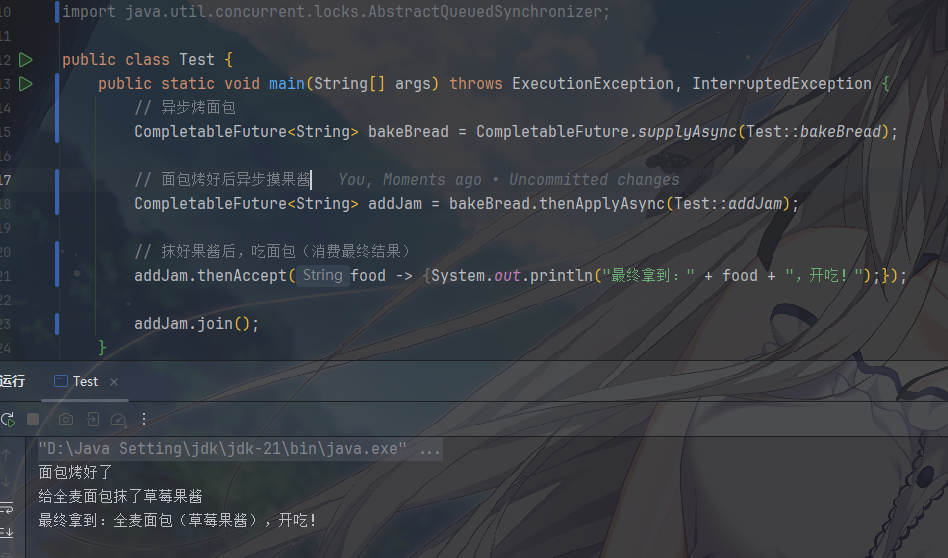
- 串行的核心是
thenApplyAsync,它会等上一个任务(烤面包)完成后,再执行下一个任务(抹果酱),并且能拿到上一个任务的结果 thenApplyAsync带Async表示 “抹果酱” 也在异步线程执行(不带Async则用完成 “烤面包” 的线程执行);- 一步接一步,不用手动等待每一步的结果。
- 串行的核心是
那么,最后来看看,多个任务同时做,取最快的结果如何编写
多个任务同时执行,只要有一个完成就用它的结果。比如 “查快递,同时问顺丰和京东,谁先回复就用谁的”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class CompletableFutureParallel {
public static void main(String[] args) throws InterruptedException {
// 1. 同时异步查两个快递(并行执行)
CompletableFuture<String> sfExpress = CompletableFuture.supplyAsync(() -> checkExpress("顺丰"));
CompletableFuture<String> jdExpress = CompletableFuture.supplyAsync(() -> checkExpress("京东"));
// 2. anyOf:合并两个任务,只要有一个完成就拿到结果(谁快用谁)
CompletableFuture<Object> fastExpress = CompletableFuture.anyOf(sfExpress, jdExpress);
// 3. 拿到最快的结果后,打印
fastExpress.thenAccept(result -> System.out.println("最快查到的快递信息:" + result));
// 等待任务完成
Thread.sleep(1000);
}
// 模拟查快递:不同快递耗时不同(随机)
private static String checkExpress(String company) {
try {
// 模拟随机耗时:100-300毫秒(模拟网络延迟)
long delay = (long) (Math.random() * 200 + 100);
Thread.sleep(delay);
System.out.println(company + " 查快递耗时:" + delay + "ms");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return company + ":你的快递已到楼下";
}
}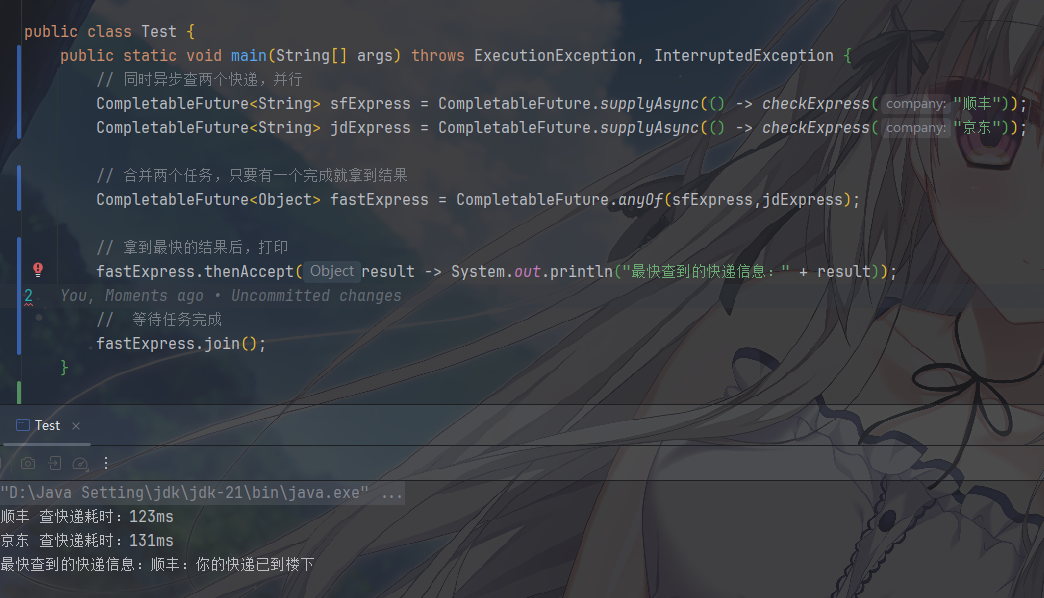
sfExpress和jdExpress是两个同时执行的异步任务CompletableFuture.anyOf(...),合并多个任务,只要有一个完成,就返回这个任务的结果,每次运行都会拿到 “顺丰” 或 “京东” 中耗时更短的那个结果- 如果是等所有任务都完成,用
CompletableFuture.allOf(...)。
如何使用线程池
关于对使用ExecutorService和Executors的说明
只是作为例子和示范,为如何使用线程池提供一个最基本的思路,但是生产环境禁止用 Executors 创建线程池,这是阿里的规范
先开门见山的讲一下如何使用最基本的线程池,通过Executors的静态工厂方法来直接创建ExecutorService的子类
首先,Java标准库提供了ExecutorService接口表示线程池,它的典型用法如下:
1 | // 创建固定大小的线程池: |
因为ExecutorService只是接口,Java标准库提供的几个常用实现类有,除了AbstractExecutorService这个默认骨架实现,我都说一下
ThreadPoolExecutor:它是核心通用实现,是Java 线程池的核心底层实现,所有常规线程池的基础ScheduledThreadPoolExecutor:支持定时 / 周期性任务的线程池,是newScheduledThreadPool()的底层实现1
2
3
4
5ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(2);
// 延迟1秒执行
scheduledPool.schedule(() -> System.out.println("延迟任务"), 1, TimeUnit.SECONDS);
// 延迟2秒后,每3秒执行一次(固定频率)
scheduledPool.scheduleAtFixedRate(() -> System.out.println("周期任务"), 2, 3, TimeUnit.SECONDS);ForkJoinPool:适用于分治任务的线程池1
2
3
4
5
6
7
8
9ForkJoinPool forkJoinPool = new ForkJoinPool(4); // 指定并行度(CPU核心数)
// 计算1~100的和(分治)
Integer sum = forkJoinPool.invoke(new RecursiveTask<Integer>() {
protected Integer compute() {
return IntStream.rangeClosed(1, 100).sum();
}
});
System.out.println(sum); // 输出5050ThreadPerTaskExecutor:极简实现,每次提交任务都新建一个线程,等价于new Thread(r).start(),别的啥也没有1
2
3
4ExecutorService threadPerTaskPool = Executors.newThreadPerTaskExecutor(Executors.defaultThreadFactory());
threadPerTaskPool.execute(() -> System.out.println("每次新建线程:" + Thread.currentThread().getId()));
threadPerTaskPool.execute(() -> System.out.println("每次新建线程:" + Thread.currentThread().getId()));
// 输出两个不同的线程ID,证明每次新建ConInvoker/Win32ShellFolderManager2:写挂专用线程池))因为操作的是Windows
创建这些线程池的方法都被封装到Executors这个工厂类中,作为静态方法
1 | public class Test { |
我们观察执行结果,一次性放入6个任务,由于线程池只有固定的5个线程,因此,前5个任务会同时执行,等到有线程空闲后,才会执行后面的两个任务。
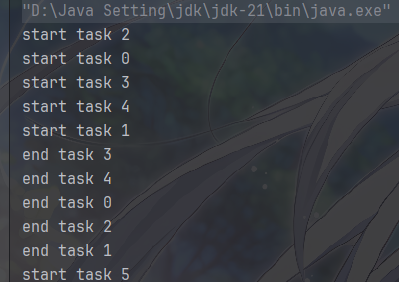
这是线程池池化思想的最基础也是最直观的体现
线程池在程序结束的时候要关闭。使用shutdown()方法关闭线程池的时候,它会等待正在执行的任务先完成,然后再关闭。而shutdownNow()会立刻停止正在执行的任务,awaitTermination()则会等待指定的时间让线程池关闭。这个上面也提到了
如果我们把线程池改为CachedThreadPool,由于这个线程池的实现会根据任务数量动态调整线程池的大小,所以6个任务可一次性全部同时执行。
还有一种任务,需要定期反复执行,就可以使用ScheduledThreadPool,可以通过Executors类创建ScheduledThreadPool
1 | ScheduledExecutorService ses = Executors.newScheduledThreadPool(4); |
Java标准库还提供了一个java.util.Timer类,这个类也可以定期执行任务,但是在这里就不细说了
Executors 类
而 Executors
类是线程池的一个工具类,其中大部分是创建线程池的静态方法,它的作用是封装
ThreadPoolExecutor 等实现类的创建逻辑,相当于
“线程池工厂”;
其中的静态方法看名字大家估计就能知道是创建的什么线程池。例如
FixedThreadPool:线程数固定的线程池;FixedThreadPool最多只能创建核心线程数的线程CachedThreadPool:线程数根据任务动态调整的线程池;SingleThreadExecutor:仅单线程执行的线程池。SingleThreadExector只能创建一个线程ScheduledThreadPool:给定的延迟后运行任务或者定期执行任务的线程池
对于Executors ,它的方法大部分返回的是
ExecutorService,而非具体的
ThreadPoolExecutor,部分方法返回的是代理类,而Executor
接口是 规范,Executors 是
规范的工厂工具,他们之间的关系就可以这样概括
graph LR
A[Executors 工具类] -->|静态工厂方法创建| B[ThreadPoolExecutor]
A -->|静态工厂方法创建| C[ScheduledThreadPoolExecutor]
A -->|静态工厂方法创建| D[ForkJoinPool]
A -->|包装| E[DelegatedExecutorService]
B -->|实现| F[ExecutorService]
C -->|实现| G[ScheduledExecutorService]
D -->|实现| F
E -->|实现| F
F -->|继承| H[Executor]
G -->|继承| F但是,开发规范中,有这样一条规定,就是生产环境禁止用 Executors 创建线程池,因为它的快捷方法有致命缺陷,虽然我上面用了只是做个演示,例如
newFixedThreadPool()/newSingleThreadExecutor():用LinkedBlockingQueue(无界队列),任务堆积会导致 OOM;newCachedThreadPool()/newScheduledThreadPool():最大线程数 =Integer.MAX_VALUE,任务过多会创建大量线程导致 OOM;
一般情况下我们通常手动创建
ThreadPoolExecutor,指定有界队列和合理的拒绝策略。经常使用的线程池主要就下面会讲到的三个
使用
ThreadPoolExecutor
正确声明线程池
线程池必须手动通过 ThreadPoolExecutor
的构造函数来声明,避免使用Executors 类创建线程池,会有 OOM
风险。
除了避免 OOM 的原因之外,不推荐使用
Executors提供的两种快捷的线程池的原因还有:
实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
我们应该显示地给我们的线程池命名,设置线程池名称前缀,这样有助于我们定位问题
给线程池里的线程命名通常有下面两种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 利用 guava 的 ThreadFactoryBuilder
ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setNameFormat(threadNamePrefix + "-%d")
.setDaemon(true).build();
ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
// 自己实现 ThreadFactory
public final class NamingThreadFactory implements ThreadFactory {
private final AtomicInteger threadNum = new AtomicInteger();
private final String name;
/**
* 创建一个带名字的线程池生产工厂
*/
public NamingThreadFactory(String name) {
this.name = name;
}
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
return t;
}
}
正确配置线程池参数
ThreadPoolExecutor
正确声明的关键在于合理设置核心参数,它的构造方法如下
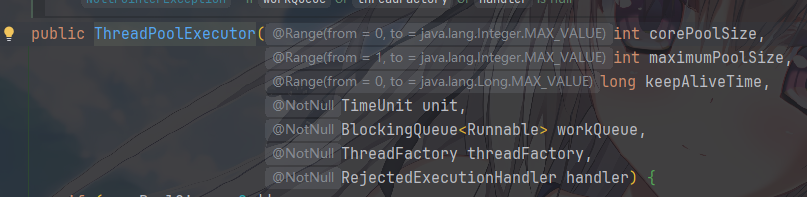
corePoolSize:核心线程数,它是线程池长期保持的线程数,即使线程空闲也不会销毁maximumPoolSize:最大线程数,线程池允许创建的最大线程数,核心线程数满、任务队列满后,才会创建非核心线程。keepAliveTime + unit:空闲存活时间及其单位,非核心线程空闲超过该时间会被销毁,释放资源。workQueue:任务队列,存储等待执行的任务,核心线程满后,任务先进入队列而非直接创建新线程。十次九次情况下,使用ArrayBlockingQueue指定大小的有界阻塞队列threadFactory:线程工厂,用于创建线程,自定义线程工厂可以给线程命名,方便定位问题handler:拒绝策略,当线程数达到最大、队列也满时,新任务的处理方式AbortPolicy:抛出RejectedExecutionException(默认,需捕获);CallerRunsPolicy:由提交任务的线程执行(如主线程),降低任务丢失风险;DiscardPolicy:直接丢弃任务,无提示;DiscardOldestPolicy:丢弃队列中最旧的任务,尝试提交新任务。
很明显,线程池配置大一些并不是就一定好的,对于多线程这个场景来说主要是增加了上下文切换 成本,类比于现实世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
- 如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的,CPU 根本没有得到充分利用。
- 如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
有一个简单并且适用面比较广的公式:
- CPU 密集型任务 (N): 这种任务消耗的主要是 CPU 资源,线程数应设置为 N,也就是CPU 核心数。由于任务主要瓶颈在于 CPU 计算能力,与核心数相等的线程数能够最大化 CPU 利用率,过多线程反而会导致竞争和上下文切换开销。
- I/O 密集型任务(M * N): 这类任务大部分时间处理 I/O 交互,线程在等待 I/O 时不占用 CPU。 为了充分利用 CPU 资源,线程数可以设置为 M * N,其中 N 是 CPU 核心数,M 是一个大于 1 的倍数,建议默认设置为 2 ,具体取值取决于 I/O 等待时间和任务特点,需要通过测试和监控找到最佳平衡点。
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
CPU 密集型任务不再推荐 N+1,原因如下:
- “N+1” 的初衷是希望预留线程处理突发暂停,但实际上,处理缺页中断等情况仍然需要占用 CPU 核心。
- CPU 密集场景下,CPU 始终是瓶颈,预留线程并不能凭空增加 CPU 处理能力,反而可能加剧竞争
线程数更严谨的计算的方法应该是 $$ \text{最佳线程数} = N_{\text{CPU核心数}} \times \left(1 + \frac{WT_{\text{线程等待时间}}}{ST_{\text{线程计算时间}}}\right) WT_{\text{线程等待时间}} = \text{线程运行总时间} - ST_{\text{线程计算时间}} $$ 上述公式的核心要点就在于,线程等待时间所占比例越高,需要越多线程。线程计算时间所占比例越高,需要越少线程。
我们可以通过 JDK 自带的工具 VisualVM 来查看 WT/ST
比例
CPU 密集型任务的 WT/ST 接近或者等于
0,因为线程运行总时间和线程计算总时间大概相近,一直在计算,因此,一约分,线程数可以设置为
N
IO 密集型任务下,几乎全是线程等待时间,从理论上来说,你就可以将线程数设置为 2N,按道理来说,WT/ST 的结果应该比较大,这里选择 2N 的原因应该是为了避免创建过多线程吧。
美团技术团队在《Java 线程池实现原理及其在美团业务中的实践》这篇文章中介绍到对线程池参数实现可自定义配置的思路和方法。
省流一下就是:
对于动态设置线程池参数,主要就是针对这三个参数
corePoolSize: 核心线程数定义了最小可以同时运行的线程数量。maximumPoolSize: 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中
JDK允许线程池使用方通过ThreadPoolExecutor的实例来动态设置线程池的核心策略,在运行期线程池使用方调用此方法设置一些参数之后,线程池会直接覆盖原来的值,并且基于当前值和原始值的比较结果采取不同的处理策略。

例如setCorePoolSize(int)就是按如下策略处理线程池在运行期间的线程数量修改
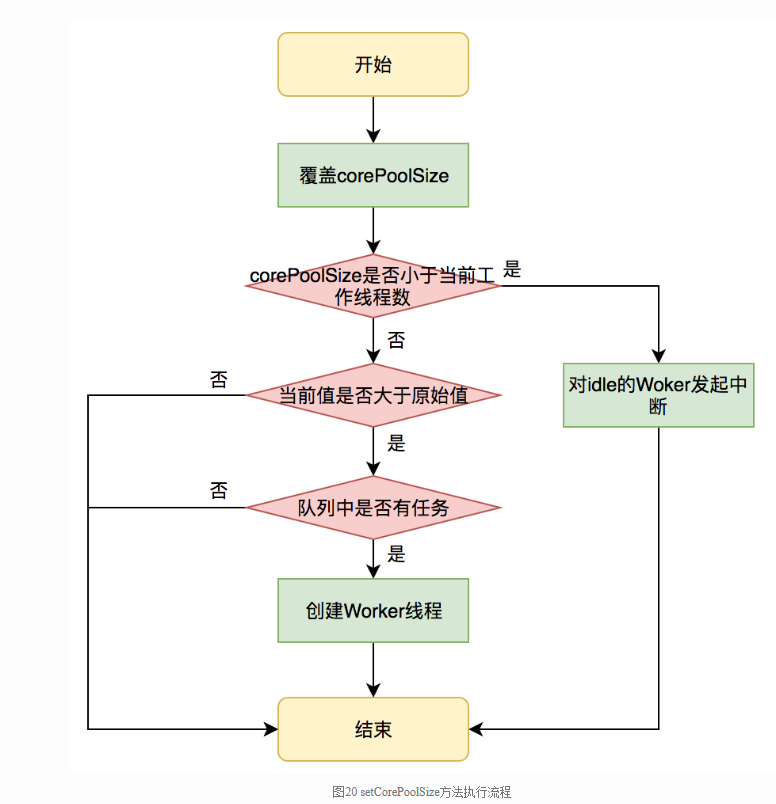
对于如何监控线程池,基于JDK原生线程池ThreadPoolExecutor提供的几个public的getter方法,可以读取到当前线程池的运行状态以及参数,如下图所示
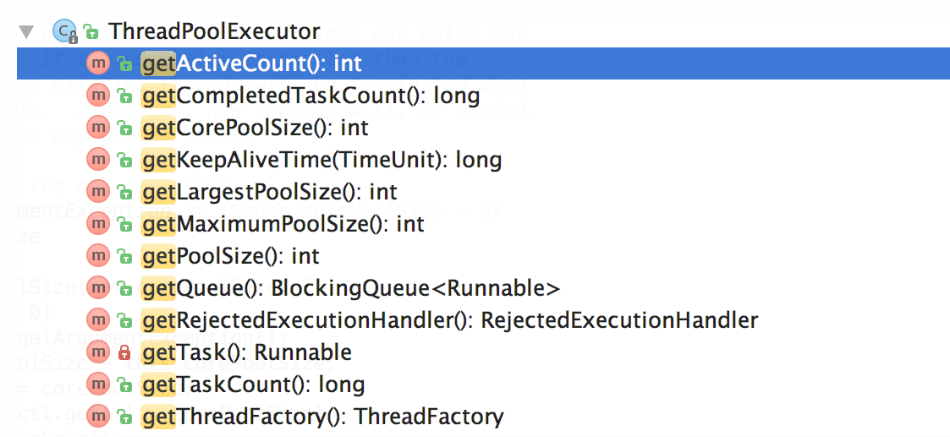
所以说,就算你尽管经过谨慎的评估,仍然不能够保证一次计算出来合适的参数,可以将线程池的参数从代码中迁移到分布式配置中心上,或者在运行到不同的情况下动态修改,这样对于线程池的配置中心和针对线程池的监控单独出来,就能随时出现问题随时改,降低了修改线程池的代价
那么,最后相关架构就变成了这样
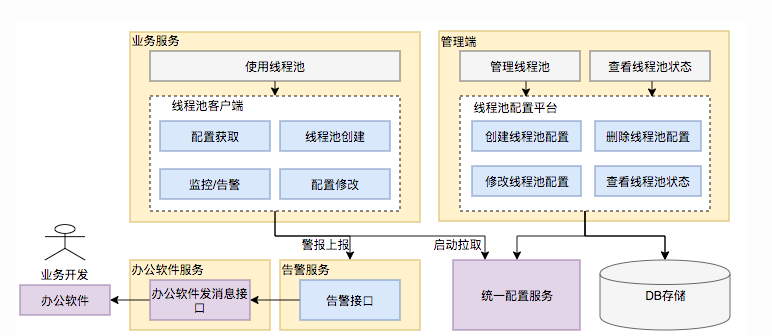
如果我们的项目也想要实现这种效果的话,可以借助现成的开源项目:
- Hippo4j:异步线程池框架,支持线程池动态变更&监控&报警,无需修改代码轻松引入。支持多种使用模式,轻松引入,致力于提高系统运行保障能力。
建议不同类别的业务用不同的线程池
很多人在实际项目中都会有类似这样的问题:我的项目中多个业务需要用到线程池,是为每个线程池都定义一个还是说定义一个公共的线程池呢?
建议不同类别的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重心优化系统性能瓶颈相关的业务。
这和我们上述提到的动态修改线程池参数的核心内容就相连了,所以说,再结合上述的内容,我们可以这样开发代码
1 | import java.util.concurrent.*; |
对于实际开发使用
在当今的互联网业界,为了最大程度利用CPU的多核性能,并行运算的能力是不可或缺的。通过线程池管理线程获取并发性是一个非常基础的操作,让我们来看两个典型的使用线程池获取并发性的场景。
快速响应用户请求
用户发起的实时请求,服务追求响应时间。比如说用户要查看一个商品的信息,那么我们需要将商品维度的一系列信息如商品的价格、优惠、库存、图片等等聚合起来,展示给用户。
从用户体验角度看,这个结果响应的越快越好,我们往往会选择使用线程池这种简单的方式,将调用封装成任务并行的执行,缩短总体响应时间。这种场景最重要的就是获取最大的响应速度去满足用户,所以应该不设置队列去缓冲并发任务,使用
SynchronousQueue它没有容量,调高corePoolSize和maxPoolSize去尽可能创造多的线程快速执行任务,使用RejectedExecutionHandler,因为一旦线程池满了,通常建议抛出异常或降级处理,而不是让主线程执行,那会阻塞用户请求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import java.util.concurrent.*;
public class UserResponseService {
// 假设这是一个并发极高的详情页聚合器
private final ThreadPoolExecutor executor = new ThreadPoolExecutor(
20, 40, // 比推荐参数较大一些
0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<>(), // 关键:直接交付,不排队
new ThreadPoolExecutor.AbortPolicy() // 满了直接报错,触发降级
);
public ProductDetail getProductDetail(String productId) {
long start = System.currentTimeMillis();
// 使用 CompletableFuture 配合自定义线程池
CompletableFuture<String> priceFuture = CompletableFuture.supplyAsync(() -> fetchPrice(productId), executor);
CompletableFuture<String> stockFuture = CompletableFuture.supplyAsync(() -> fetchStock(productId), executor);
CompletableFuture<String> promoFuture = CompletableFuture.supplyAsync(() -> fetchPromo(productId), executor);
try {
// 等待所有任务完成,或者超时
CompletableFuture.allOf(priceFuture, stockFuture, promoFuture).get(500, TimeUnit.MILLISECONDS);
return new ProductDetail(priceFuture.get(), stockFuture.get(), promoFuture.get());
} catch (Exception e) {
// 快速失败,返回降级数据
return ProductDetail.fallback();
}
}
private String fetchPrice(String id) { /* 模拟网络调用 */ return "100.00"; }
private String fetchStock(String id) { /* 模拟网络调用 */ return "In Stock"; }
private String fetchPromo(String id) { /* 模拟网络调用 */ return "Buy 1 Get 1"; }
}快速处理批量任务
离线的大量计算任务,需要快速执行。比如说,统计某个报表,需要计算出全国各个门店中有哪些商品有某种属性,用于后续营销策略的分析,那么我们需要查询全国所有门店中的所有商品,并且记录具有某属性的商品,然后快速生成报表。
这种场景需要执行大量的任务了那肯定,所以我们也会希望任务执行的越快越好。这种情况下,也应该使用多线程策略,并行计算。但与响应速度优先的场景区别在于,这类场景任务量巨大,并不需要瞬时的完成,而是关注如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先的问题。
所以应该合理的设置队列去缓冲并发任务,一般使用有界阻塞队列
LinkedBlockingQueue(capacity),通过队列缓冲任务,平滑流量尖峰,而且调整合适的corePoolSize去设置处理任务的线程数,就按照上面的公式来进行计算,因为设置的线程数过多可能还会引发线程上下文切换频繁的问题,也会降低处理任务的速度,降低吞吐量。而对于RejectedExecutionHandler使用CallerRunsPolicy。当线程池和队列都满了,让提交任务的线程(主线程)自己去执行任务,这样主线程忙于执行任务,就没法继续提交新任务,给了线程池喘息的机会,而且保证任务不丢失1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class BatchReportProcessor {
// 获取 CPU 核心数
private static final int CPU_CORES = Runtime.getRuntime().availableProcessors();
private final ThreadPoolExecutor executor = new ThreadPoolExecutor(
CPU_CORES, // 核心线程:紧贴 CPU
CPU_CORES * 2, // 最大线程:允许一定的 I/O 阻塞抖动
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000), // 缓冲区:任务排队等候处理
new ThreadPoolExecutor.CallerRunsPolicy() // 满了主线程自己干,实现自动限流
);
public void processNationalStores(List<Store> stores) {
CountDownLatch latch = new CountDownLatch(stores.size());
for (Store store : stores) {
executor.execute(() -> {
try {
analyzeStoreData(store);
} finally {
latch.countDown();
}
});
}
try {
latch.await(); // 等待所有门店报表生成完毕
System.out.println("All reports generated.");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private void analyzeStoreData(Store store) {
// 耗时的计算与数据库操作
}
}
还是那句话,无论哪种场景,固定参数往往难以应付变化的流量。在深入使用
ThreadPoolExecutor 时应对复杂的业务时,建议:
- 暴露监控指标: 定时打印
getQueue().size()、getActiveCount()、getCompletedTaskCount()。 - 动态调整: 使用
setCorePoolSize和setMaximumPoolSize在不重启服务的情况下,根据线上压力动态调整参数。
一些需要注意的内容
当线程池不再需要使用时,应该显式地关闭线程池,释放线程资源。
线程池提供了两个关闭方法:
shutdown():关闭线程池,线程池的状态变为SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。shutdownNow():关闭线程池,线程池的状态变为STOP。线程池会终止当前正在运行的任务,停止处理排队的任务并返回正在等待执行的 List。
调用完 shutdownNow 和 shuwdown
方法后,并不代表线程池已经完成关闭操作,它只是异步的通知线程池进行关闭处理,具体如何关闭,什么时候关闭,里面的线程怎么办,这些是操作系统和JVM的事情,所以说根本上不太可能是一个即使的操作。
如果要同步等待线程池彻底关闭后才继续往下执行,需要调用awaitTermination方法进行同步等待。在调用
awaitTermination()
方法时,应该设置合理的超时时间,以避免程序长时间阻塞而导致性能问题。另外。由于线程池中的任务可能会被取消或抛出异常,因此在使用
awaitTermination() 方法时还需要进行异常处理。
1 | // ... |
注意,线程池是可以复用的,一定不要频繁创建和关闭线程池,比如一个用户请求到了就单独创建一个线程池。
而且,线程池尽量不要放耗时任务,你想想,线程池的目的是避免频繁创建,销毁和上下文切换线程带来的开销,如果将耗时任务提交到线程池中执行,可能会导致线程池中的线程被长时间占用,无法及时响应其他任务,甚至会导致线程池崩溃或者程序假死。
对于一些比较耗时的操作,可以采用 CompletableFuture
等其他异步操作的方式来处理,以避免阻塞线程池中的线程
别忘了给线程池命名
合理使用ScheduledThreadPoolExecutor
什么时候会用到你
项目中经常会遇到一些非分布式的调度任务,需要在未来的某个时刻周期性执行。实现这样的功能,我们有多种方式可以选择:
- Timer 类
- Spring的
@Scheduled注解等定时任务框架 - 使用
ScheduledThreadPoolExecutor实现调度任务
对于ScheduledThreadPoolExecutor,它继承自
ThreadPoolExecutor,这意味着它不仅能做定时任务,还具备普通线程池的所有特性,它为任务提供延迟或周期执行,属于线程池的一种。和
ThreadPoolExecutor 相比,它还具有以下几种特性:
- 使用专门的任务类型—
ScheduledFutureTask来执行周期任务,也可以接收不需要时间调度的任务 - 使用专门的存储队列—
DelayedWorkQueue来存储任务,DelayedWorkQueue是无界延迟队列DelayQueue的一种。它固定使用这个内部队列。这意味着maximumPoolSize这个参数在定时线程池里其实是失效的,因为,任务只会在队列中等待,不会创建新线程
因为队列理论上无界,但是如果任务堆积过多(比如任务执行比产生的慢),依然会有 OOM 的风险,亲测
两种主要的调度模式
这是很多人最容易翻车的地方,请务必区分:
T:你设置的调度周期 / 延迟时间
S:任务实际执行时间
scheduleAtFixedRate(固定频率)逻辑:以任务开始的时间为基准。每隔 T 时间触发一次。
- 如果上一次任务在
T时间内执行完成(S < T):下一次任务会在基准时间 + T准时执行; - 如果上一次任务执行时间超过
T(S > T):下一次任务会在上一次任务结束后立刻执行(不会并发,只会 “补位”); - 如果任务长期阻塞(
S远大于T):会导致任务 “堆积” 在队列中,形成 “丢拍子”(原本每分钟 1 次,阻塞阻塞着结果变成任务做完就立刻执行,完全偏离频率)。
例如,正常情况下
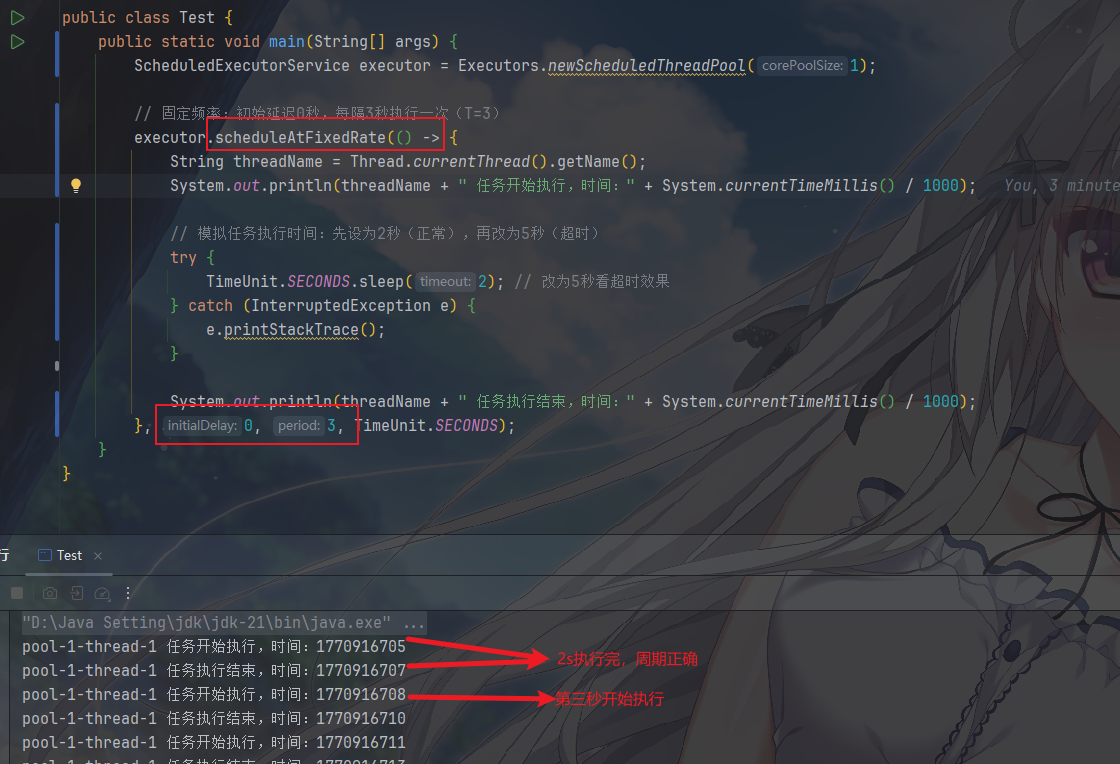
第二种情况,任务执行时间长于周期
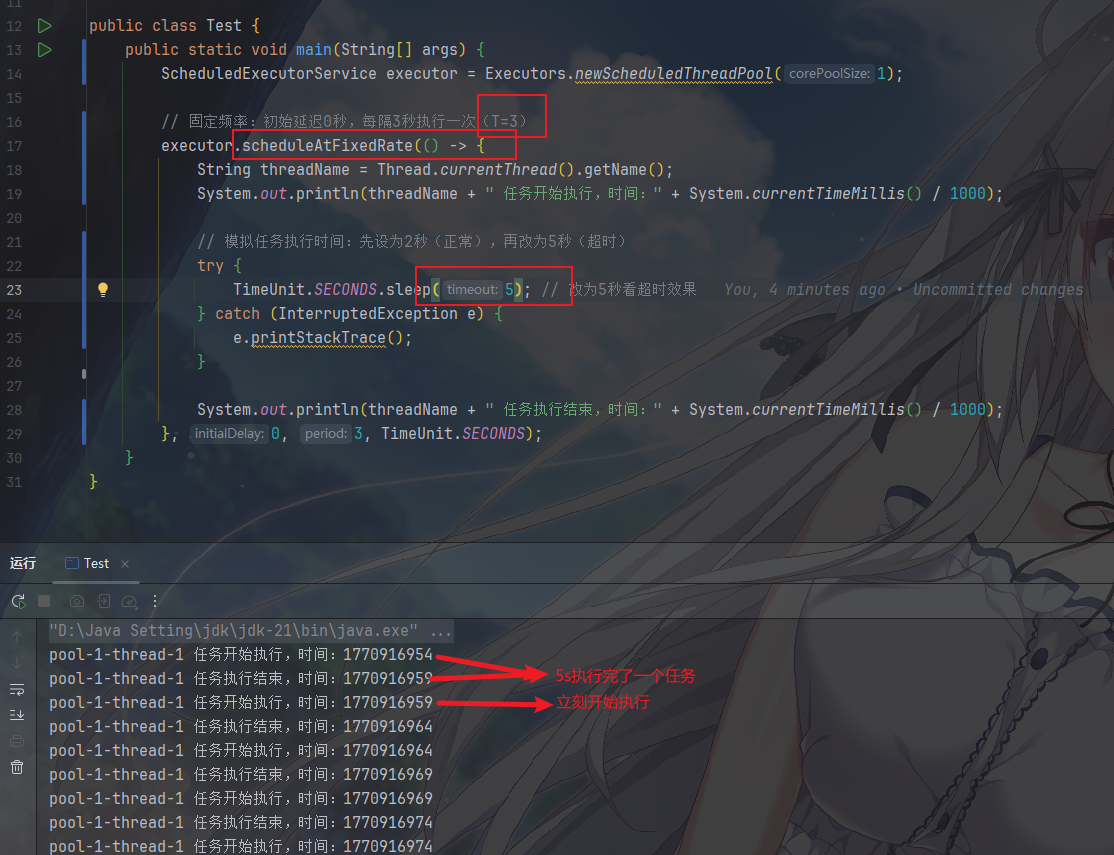
- 如果上一次任务在
注意:如果任务执行时间大于周期 T,下一次任务会立刻开始,而不会并发执行。如果任务一直堵塞,就会“丢拍子”。
scheduleWithFixedDelay(固定延迟)- 逻辑:以任务结束的时间为基准。任务执行完,等 T 时间再跑下一个。
- 优势:非常稳健,它保证了两次任务之间永远有足够的“喘息时间”,不会导致任务堆积。
对于实际开发使用
ScheduledThreadPoolExecutor
最常见的应用场景就是实现调度任务,它的参数没那么多
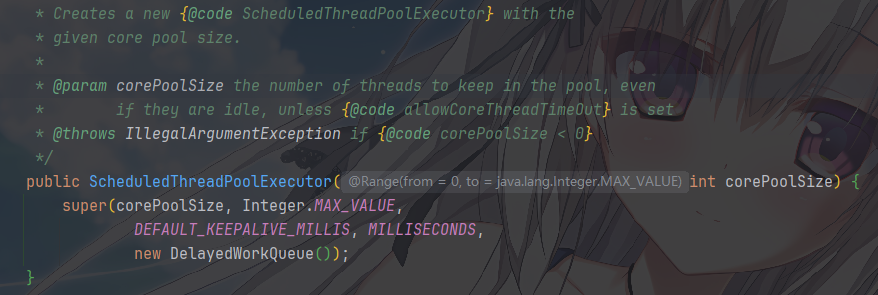
corePoolSize:没啥区别,也是核心工作的线程数量,但是通常定时任务不会像 Web 请求那样爆发。如果只是跑几个简单任务,1-2足够,但是如果是支撑核心业务,建议设为CPU 核心数。threadFactory:线程工厂,用来创建线程。也没啥区别,也是一样,建议自定义。加上业务前缀handler:拒绝策略,也没啥区别,但是建议使用AbortPolicy。因为任务是定时触发的,如果池子满了,通常意味着系统已经严重过载或逻辑死锁,需要报错报警。
那么,使用它的场景也就如下
心跳检测与服务发现
这类业务代表着周期性任务,很多定时xxx的业务都可以视作这种类型的
想一下,分布式框架中,很多都涉及到了这种情况,这类任务要求精准的时间间隔,用于告诉注册中心“我还活着”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class HeartbeatService {
private final ScheduledThreadPoolExecutor scheduler = new ScheduledThreadPoolExecutor(1,
new NamingThreadFactory("heartbeat-node-A"));
public void startHeartbeat() {
// 使用 scheduleAtFixedRate 保证频率稳定
scheduler.scheduleAtFixedRate(() -> {
try {
log.info("Checking connection to Registry...");
// 模拟业务逻辑:向注册中心发送心跳
boolean success = registryProxy.ping();
if (!success) {
log.warn("Heartbeat failed, retrying in next cycle.");
}
} catch (Throwable t) {
// 绝对不能让异常抛到线程池外,否则该任务后续不再触发
log.error("CRITICAL: Heartbeat task unexpected error!", t);
}
}, 0, 10, TimeUnit.SECONDS);
}
}但是,如果你真是分布式定时任务(比如多机器集群执行定时任务)、需要 cron 表达式(如
0 0 2 * * ?)的复杂调度,优先选 Quartz/Spring Task,而非ScheduledThreadPoolExecutor。因为分布式的时间调度往往比你想的复杂智能指数退避重试
当某个接口(如第三方支付回调)调用失败时,我们不希望立即重试,也不希望固定每 3 秒重试,而是希望延迟 3s, 9s, 27s… 这样可以有效避开网络抖动高峰。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class SmartRetryService {
private final ScheduledThreadPoolExecutor retryExecutor = new ScheduledThreadPoolExecutor(
4, new NamingThreadFactory("retry-handler"));
public void retryWithBackoff(Runnable task, int attempt) {
if (attempt > 5) {
log.error("Maximum retry attempts reached. Giving up.");
return;
}
// 计算延迟时间:3的n次方
long delay = (long) Math.pow(3, attempt);
log.info("Scheduling retry attempt #{} in {} seconds", attempt, delay);
retryExecutor.schedule(() -> {
try {
task.run();
log.info("Retry success!");
} catch (Exception e) {
// 如果失败,递归提交下一个延迟任务
retryWithBackoff(task, attempt + 1);
}
}, delay, TimeUnit.SECONDS);
}
}延迟执行的异步任务
这类一般就是跟业务相关,例如用户下单后 5 分钟未支付则自动取消订单,资源清理与缓存预热等
虽然分布式系统建议用 RocketMQ 延迟消息,但在一些小型后台系统或本地测试中,STPE 是最轻量级的方案。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class OrderTimeoutManager {
private final ScheduledThreadPoolExecutor timer = new ScheduledThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
new NamingThreadFactory("order-timeout-"));
public void watchOrder(String orderId) {
log.info("Order [{}] created, timer started.", orderId);
// 5分钟后执行取消逻辑
timer.schedule(() -> {
try {
// 1. 检查数据库状态是否已支付
if (isOrderUnpaid(orderId)) {
cancelOrder(orderId);
log.info("Order [{}] timeout and cancelled.", orderId);
}
} catch (Exception e) {
log.error("Error processing timeout for order " + orderId, e);
}
}, 5, TimeUnit.MINUTES);
}
private boolean isOrderUnpaid(String id) { /* ... */ return true; }
private void cancelOrder(String id) { /* ... */ }
}
在普通的 ThreadPoolExecutor 中,如果使用
CallerRunsPolicy(让调用者线程执行),可能只是接口慢一点。
但在 ScheduledThreadPoolExecutor 中,由于它的队列是无界的
DelayedWorkQueue,默认拒绝策略几乎只有在线程池关闭(Shutdown)时才会被触发。平时它会一直往队列里塞,直到
OOM。所以说,监控队列大小 getQueue().size()
比设置拒绝策略更重要。
别忘了,无论是
ThreadPoolExecutor还是ScheduledThreadPoolExecutor,拒绝策略只有在 “线程池无法接收新任务” 时才会触发,也即是线程池满了,空不出来了
ScheduledThreadPoolExecutor强制使用DelayedWorkQueue(无法替换),这个队列是无界的,ScheduledThreadPoolExecutor的核心线程数是你设置的数值,,非核心线程数永远为 0,因为它所有定时任务都由核心线程执行,多余任务全进队列结合拒绝策略的触发条件,
ScheduledThreadPoolExecutor只有如下情况会触发拒绝策略:
- 线程池被调用
shutdown()/shutdownNow(),状态变为非 RUNNING,此时提交新任务会触发拒绝策略队列装满在物理机上永远不会发生,因为内存早被占满 OOM 了
注意,他会出现沉默的异常,这是
ScheduledThreadPoolExecutor
最坑的地方,如果任务执行过程中抛出未捕获的异常,线程池会直接停止该任务后续的所有调度,且没有任何报错!
所以说,任务最外层必须 try-catch。
1 | executor.schedule(() -> { |
而且和ThreadPoolExecutor一样,如果你在一个
corePoolSize=2 的池子里跑一个耗时 2
小时的同步任务,那么这两个线程就被占死了,其他的闹钟全部失效。如果任务重,请在定时任务里只做“派发”动作,把重体力活交给另一个专门的
ThreadPoolExecutor。
关于 setRemoveOnCancelPolicy,默认情况下,如果你调用
future.cancel(true),任务虽然不执行了,但它依然会留在队列里直到时间到期。
1 | // 在初始化时设置,这样一旦 cancel,任务立即从队列移除,节省内存 |
这样就好了
海量任务的时间轮不说了,你要是真那么大并发量,你不如去用 Kafka






