
文档基本操作
Elasticsearch(ES)中的 “文档(Document)” 是存储数据的基本单元(类似数据库中的 “行”),所有业务数据最终都以文档形式存储在索引中。
- 文档结构:JSON
格式,包含多个字段(如
id、name),字段值需符合索引映射(Mapping)定义的类型。 - 文档 ID:唯一标识文档,可手动指定或由 ES 自动生成。
- 元数据:文档自带的系统字段,如
_index(所属索引)、_id(文档 ID)、_version(版本号,每次修改递增)。
文档创建
新增文档有两种方式:指定
ID(PUT)或自动生成
ID(POST)
指定 ID 新增(PUT)
适用于已知唯一 ID 的场景(如用业务 ID 作为文档 ID)。
1 | PUT /索引名/_doc/文档ID |
示例(向users_test索引新增 ID
为100的文档):
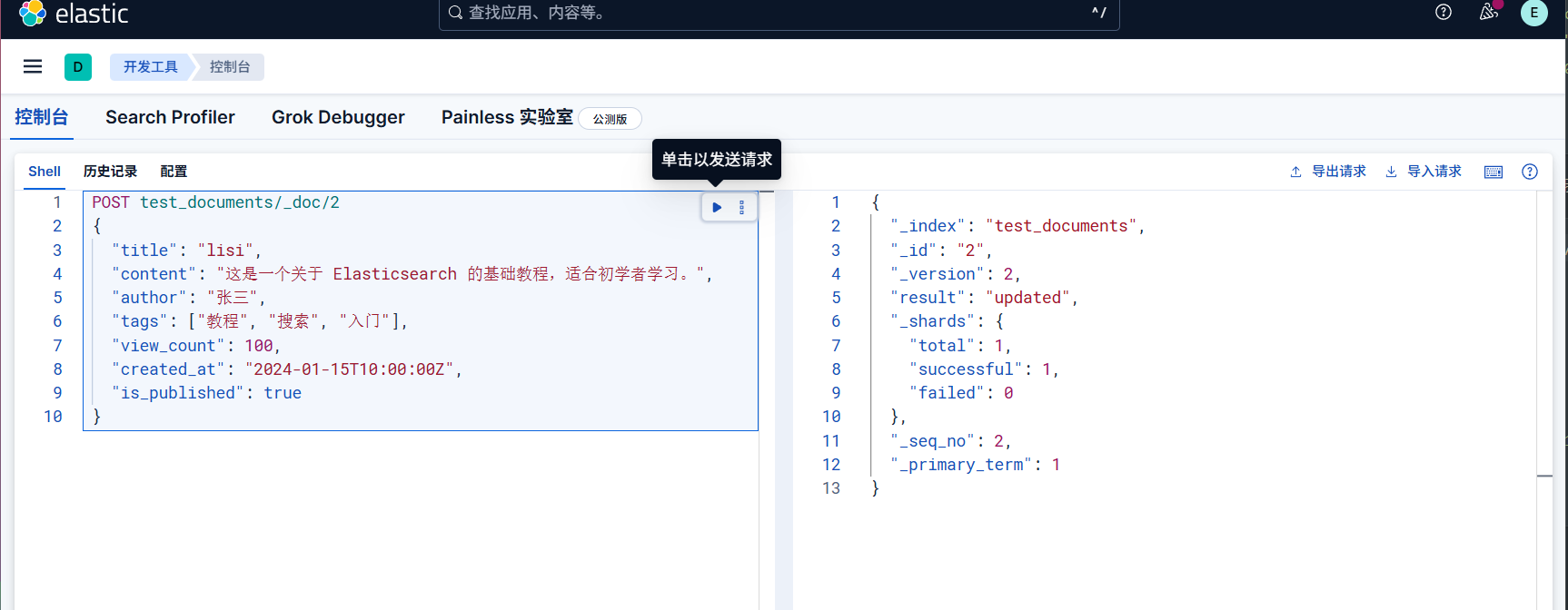
1 | PUT /users_test/_doc/100 |
貌似POST请求也可以,只不过我习惯是指定id用PUT
1 | POST /test_documents/_doc/1 |
自动生成 ID(POST)
适用于无需手动指定 ID 的场景(ES 会生成一个随机字符串作为 ID)。
1 | POST /索引名/_doc |
示例(自动生成 ID 新增文档):
1 | POST /test_documents/_doc |
批量创建文档
1 | POST /test_documents/_bulk |
简单查询文档(GET)
查询文档包括单文档查询(按 ID)和多文档查询(按条件)。
根据 ID 查询文档
快速获取指定 ID 的文档详情。
1 | GET /索引名/_doc/文档ID |
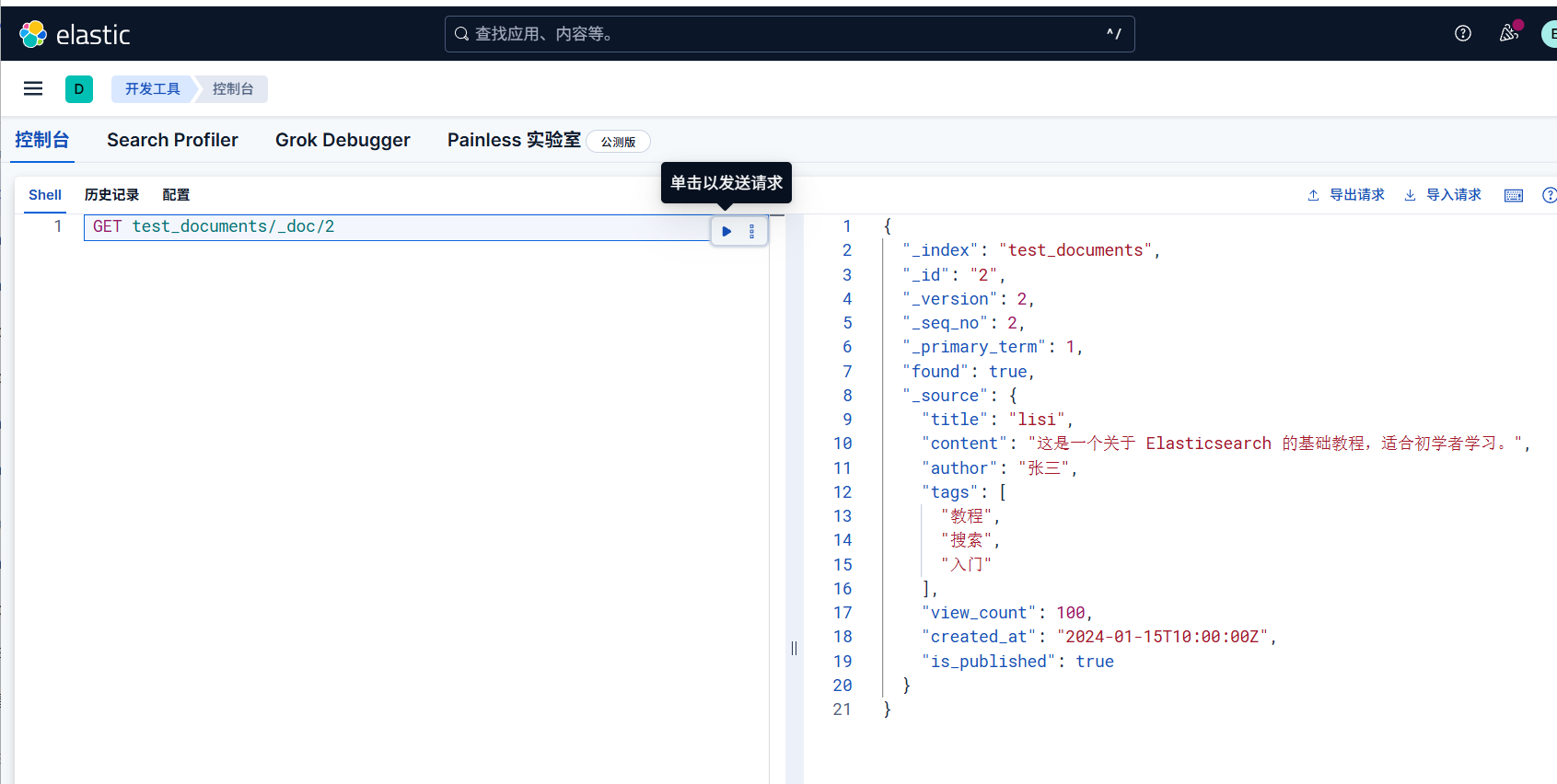
示例(查询users_test索引中 ID
为100的文档):
1 | GET /users_test/_doc/100 |
查询多个文档
一次性查询多个 ID 的文档,减少网络请求。
1 | GET /索引名/_mget |
示例
1 | GET /test_documents/_mget |
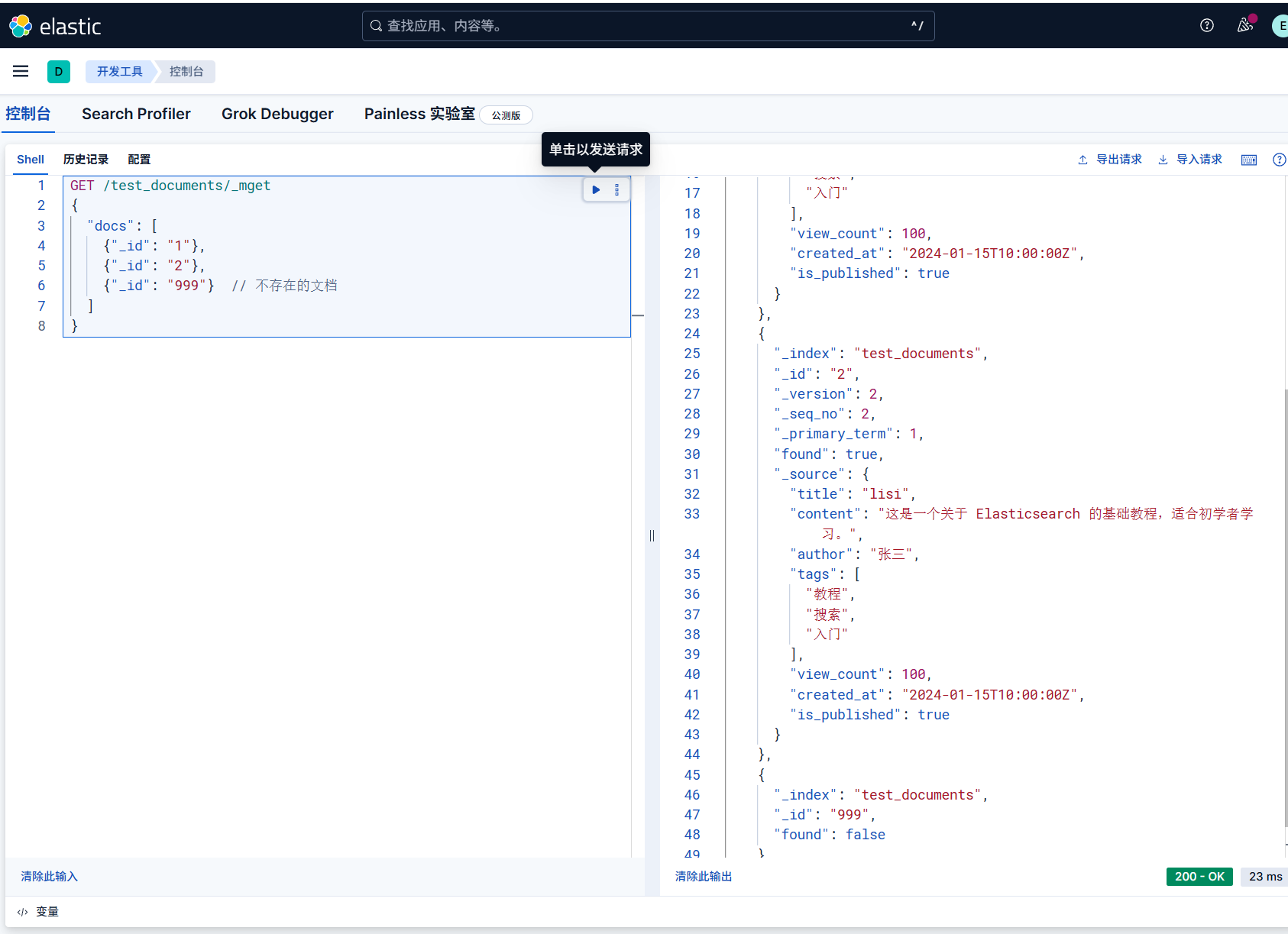
响应的docs 数组包含每个 ID 对应的文档数据(不存在的 ID
会返回found: false)。
搜索所有文档
1 | GET /test_documents/_search |
这个比较固定,就是条件查询上匹配全部(match_all)
文档更新操作(_update
或 PUT 覆盖)
修改文档有两种方式:局部修改(仅改指定字段)和全量覆盖(替换整个文档)。
局部修改(_update,推荐)
仅修改指定字段,不影响其他字段,效率更高。
1 | POST /索引名/_doc/文档ID/_update |
示例(修改 ID
为100的文档,更新age和address):
1 | POST /users_test/_doc/100/_update |
全量覆盖(PUT)
用新文档替换旧文档,需包含所有字段(否则未指定的字段会被删除)。
1 | PUT /索引名/_doc/文档ID |
例如,假如我这里面就一条
1 | PUT /test_documents/_doc/1 |
注意:若遗漏某个字段,该字段会从文档中删除,因此谨慎使用。
删除文档(DELETE)
删除指定 ID 的文档(不会立即释放磁盘空间,ES 会在后台异步清理)。
1 | DELETE /索引名/_doc/文档ID |
示例(删除 ID 为100的文档):
1 | DELETE /users_test/_doc/100 |
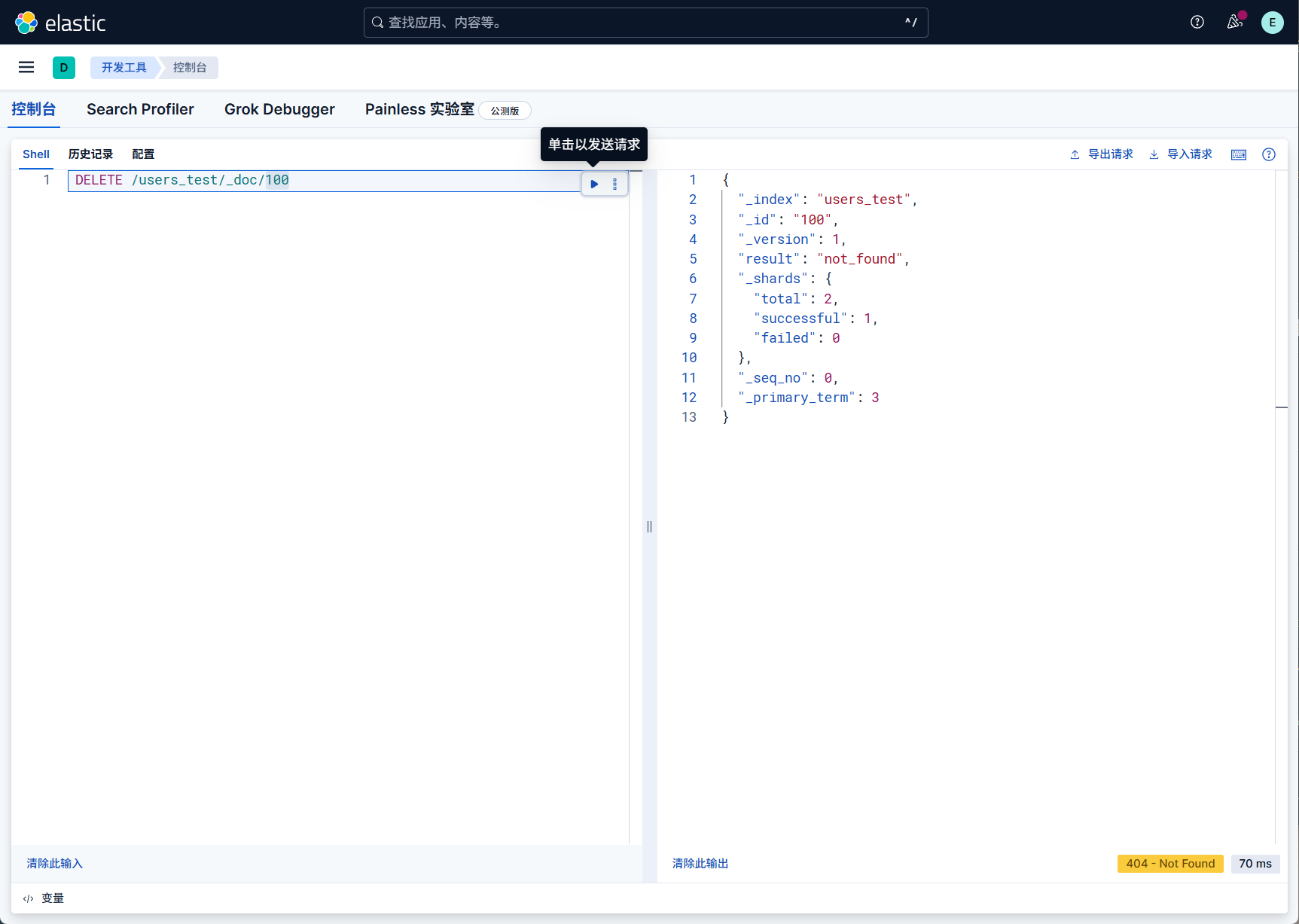
不存在,我没建这个))))))
字段过滤(_source)
存储原始数据:_source
会完整保存文档写入时的所有字段(除非手动禁用),是查询时获取文档原始内容的主要途径。
例如,写入文档:
1 | PUT /users_test/_doc/100 |
查询时 _source 会返回上述完整 JSON:
1 | { |
而且它是默认启动的,默认启用:创建索引时,_source
默认开启,无需额外配置。若需禁用(节省存储空间,但会失去原始数据),需在映射中手动设置:
1 | PUT /test_index |
注意:禁用 _source
后,无法通过查询获取原始字段值,也无法使用 _update
局部修改或 _reindex
重建索引,除非业务明确不需要原始数据,否则不建议禁用。
过滤查询—仅返回指定字段(白名单)
_source
的主要价值在于查询时灵活控制返回的字段,避免传输无关数据,减少网络开销。
通过 _source: ["字段1", "字段2"]
指定需要返回的字段,其他字段不返回。
示例:查询文档时仅返回 content 和
title:
1 | GET /test_documents/_doc/2?_source=content,title |
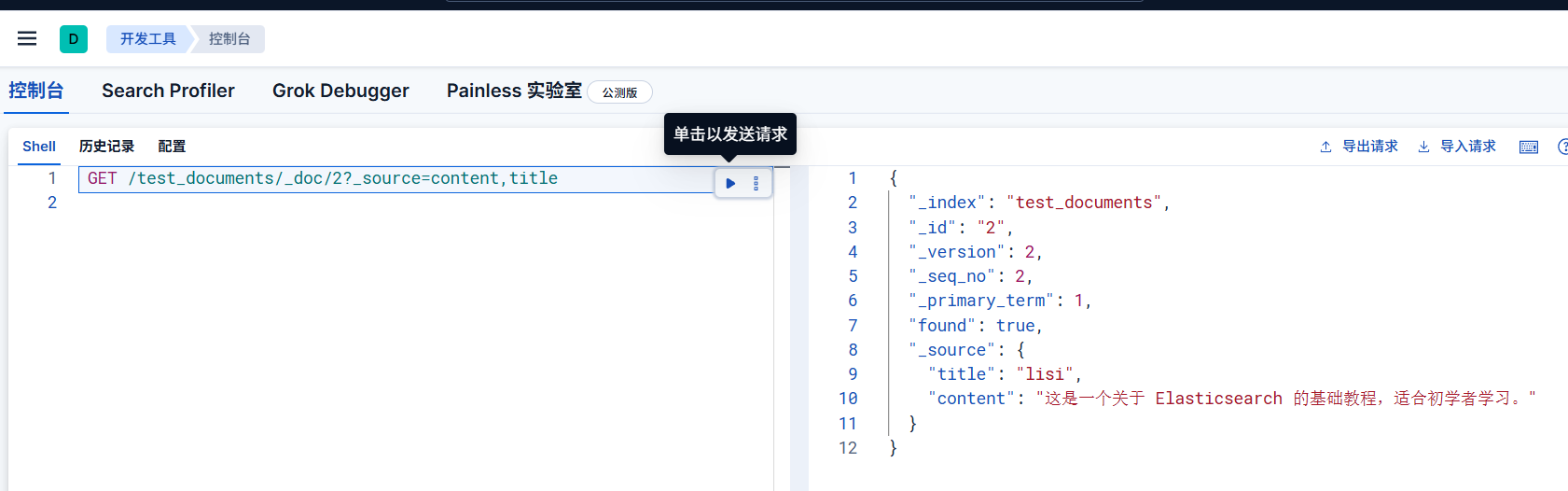
但是感觉这么写太别扭了,因为 GET 请求不能有请求体,所以我们使用 POST,请求改成如下
Elasticsearch 仅允许 _search 端点使用 POST 风格的 GET 请求
1 | POST /test_documents/_search |
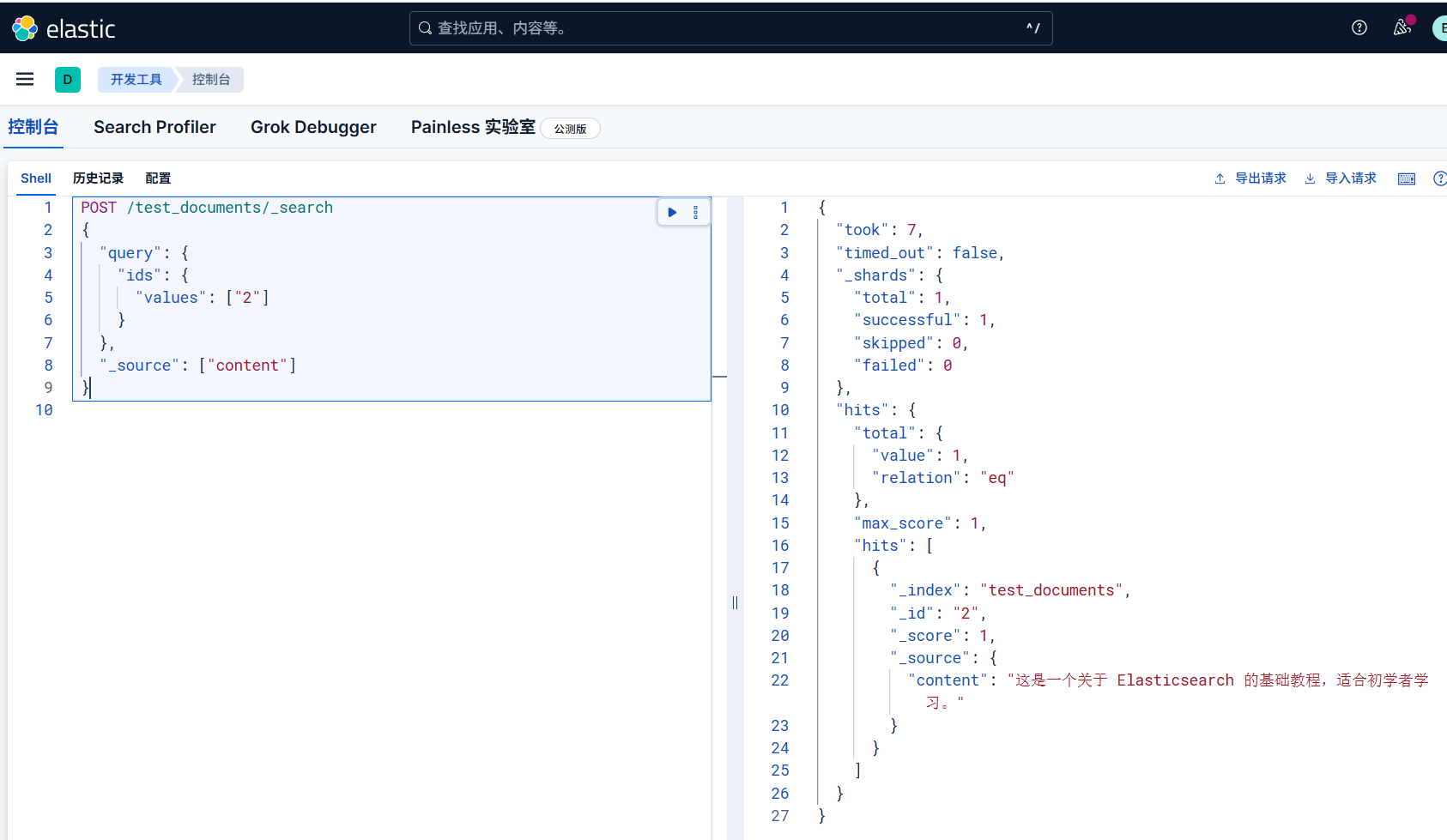
排除指定字段(黑名单)
通过 _source: { "exclude": ["字段1", "字段2"] }
排除不需要的字段,返回其余所有字段。
示例:查询时排除 title 字段:
1 | GET /test_documents/_doc/2?_source_excludes=title |
POST 请求就是这样写
1 | POST /test_documents/_search |
可以这样排除多个字段
1 | GET /test_documents/_doc/2?_source_excludes=title,view_count,created_at |

混合使用:包含 + 排除
通过 include 和 exclude
组合,先指定包含的字段,再从包含的字段中排除部分字段。
示例:包含 username 和
address,但排除 address 中的子字段(若
address 是对象类型):
1 | # 假设文档有嵌套对象 address: { "city": "广州", "district": "天河区" } |
我没有建立这样的,我就不演示了
存在性检查
通过 _source: false 不返回 _source
内容,仅获取文档的元数据(如
_index、_id、found
等),适合仅需判断文档是否存在的场景。
1 | # 使用 HEAD 请求(在 Kibana Dev Tools 中无法直接使用) |
一般情况下,我们发送这样的一个请求
1 | GET /test_documents/_doc/1?_source=false |
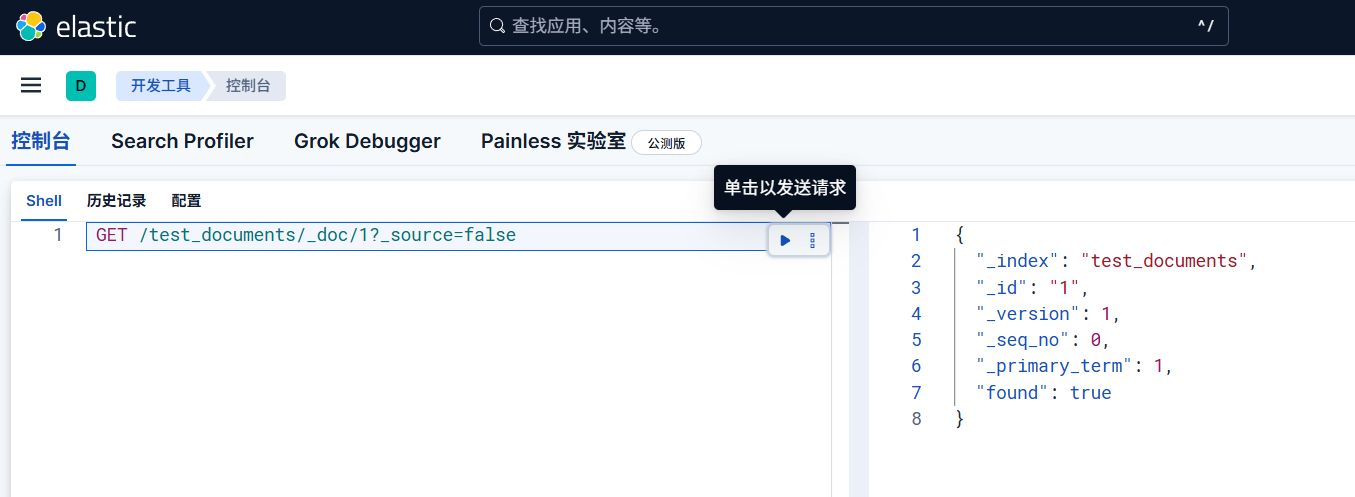
可以发现存在,这样就简单的检验了文档的存在性,避免了返回大量无关内容
批量操作(_bulk)
通过_bulk API
一次性执行多个操作(新增、修改、删除),适合批量导入或批量更新数据,减少网络开销。
每行一个操作指令,格式为:
1 | POST /_bulk |
支持的操作类型:
create:新增文档(若 ID 已存在则失败);index:新增或全量覆盖文档(ID 存在则覆盖);update:局部修改文档;delete:删除文档。
示例(批量执行新增、修改、删除):
1 | POST /_bulk |
注意:
- 每行必须是完整的
JSON,且指令行与数据行需一一对应(
delete操作无数据行); - 末尾需空一行,否则可能报错。
在最后总结一下
| 操作 | 方法 / 语法 | 核心特点 |
|---|---|---|
| 新增(指定 ID) | PUT /索引/_doc/ID { ... } |
适合已知唯一 ID 的场景 |
| 新增(自动 ID) | POST /索引/_doc { ... } |
ES 生成随机 ID,适合无业务 ID 的场景 |
| 单文档查询 | GET /索引/_doc/ID |
快速获取指定 ID 的文档 |
| 多文档查询 | GET /索引/_mget { "ids": [...] } |
批量查询多个 ID,减少请求次数 |
| 条件查询 | GET /索引/_search { "query": {...} } |
支持复杂条件、排序、分页 |
| 局部修改 | POST /索引/_doc/ID/_update { "doc": {...} } |
仅改指定字段,高效安全 |
| 全量覆盖 | PUT /索引/_doc/ID { ... } |
需包含所有字段,否则丢失数据 |
| 删除文档 | DELETE /索引/_doc/ID |
逻辑删除,版本号递增 |
| 批量操作 | POST /_bulk 配合指令行 + 数据行 |
批量处理多操作,适合大数据量场景 |
文档的search复杂查询操作(_search)
查询(Query)是Elasticsearch中用于查找匹配文档并计算其相关性分数的机制。与过滤器不同,查询不仅关心文档是否匹配,还关心 匹配的程度如何,并据此计算相关性分数(_score)。
查询的执行过程如下

- 解析查询:解析查询DSL,确定查询类型和参数
- 文档遍历:根据查询条件找出潜在匹配的文档
- 分数计算:为每个匹配文档计算相关性分数(_score)
- 结果排序:根据分数对文档进行降序排列
- 返回结果:返回排序后的文档列表
条件查询
按自定义条件查询文档(如筛选年龄大于 25 的用户),支持复杂过滤、排序、分页等。
条件查询的基本格式如下,query 子句中嵌套具体的
“查询类型”(如 term、range、bool
等),每个查询类型针对特定字段和条件进行筛选:
1 | GET /索引名/_search |
例如
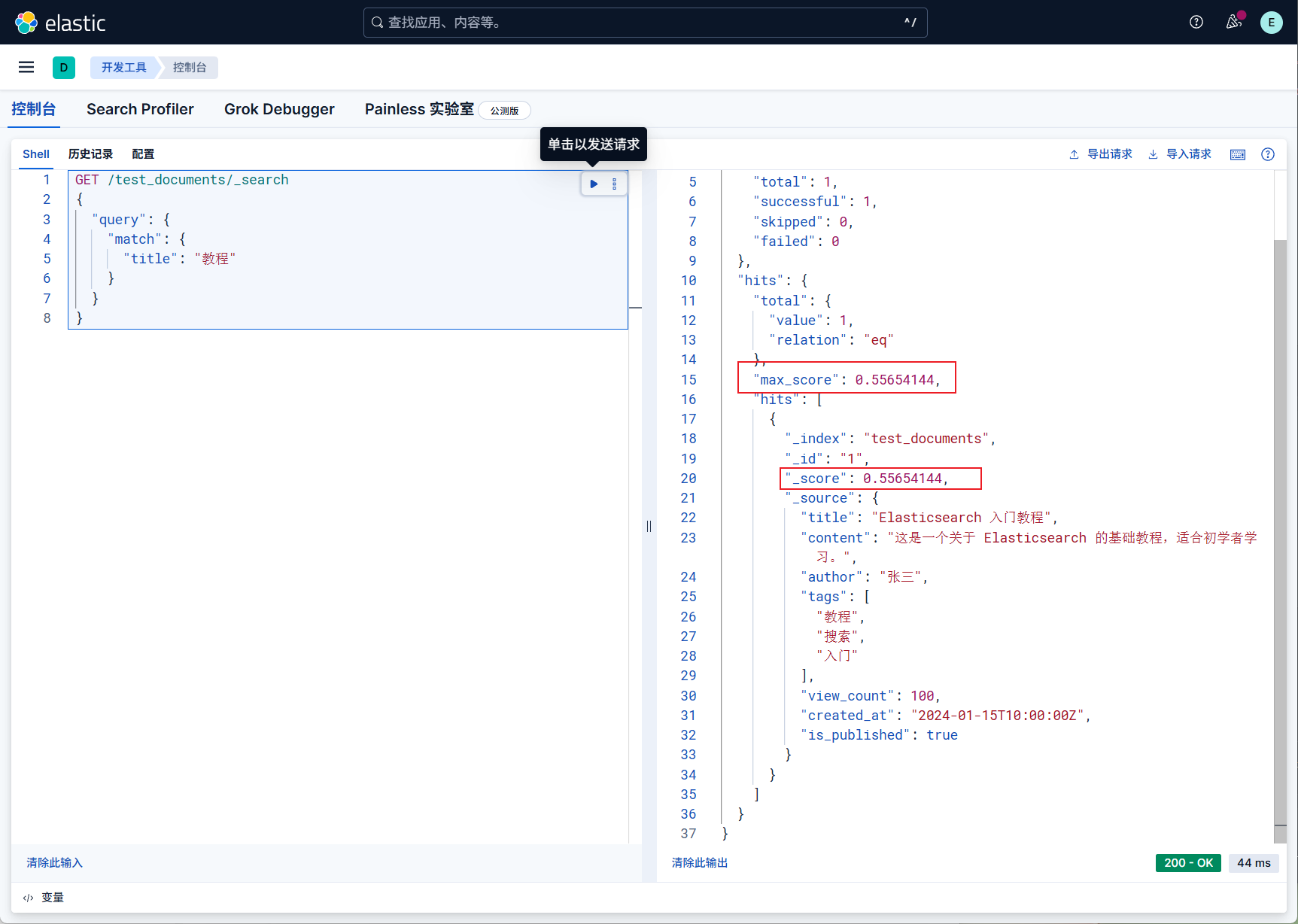
1 | GET /test_documents/_search |
他会有一个分数的排序,分数高的匹配度高,在前面
匹配所有文档
无筛选条件,返回索引中所有文档,常用于测试或全量数据遍历
1 | GET /索引名/_search |
例如
1 | GET /users_test/_search |
全文检索
这是针对文本字段的分词匹配,用于 text 类型字段(如
address、tags),会先分词再匹配,支持模糊查询。
match:单字段全文检索1
2
3
4
5
6
7
8GET /索引名/_search
{
"query": {
"match": {
"字段名": "检索词" # 检索词会被分词(如“北京 朝阳”拆分为“北京”和“朝阳”)
}
}
}示例:查询
address中包含 “北京” 或 “上海” 的文档(address是text类型,用 IK 分词):1
2
3
4
5
6
7
8GET /users_test/_search
{
"query": {
"match": {
"address": "北京 上海" # 分词后匹配“北京”或“上海”
}
}
}补充:默认是 “或” 逻辑(
OR),可通过operator指定 “与” 逻辑(AND):1
2
3
4
5
6
7# 需同时包含“北京”和“朝阳”
"match": {
"address": {
"query": "北京 朝阳",
"operator": "AND"
}
}multi_match:多字段全文检索他会同时在多个
text字段中检索,适合 “关键词在标题或正文中匹配” 等场景。1
2
3
4
5
6
7
8
9GET /索引名/_search
{
"query": {
"multi_match": {
"query": "检索词",
"fields": ["字段1", "字段2"] # 要检索的多个字段
}
}
}示例:在
address和tags中检索 “工程师”:1
2
3
4
5
6
7
8
9GET /users_test/_search
{
"query": {
"multi_match": {
"query": "工程师",
"fields": ["address", "tags"]
}
}
}
精确匹配查询
用于
keyword、数值、日期等类型字段,不分词,完全匹配字段值。
term:单值精确匹配
1 | GET /索引名/_search |
示例:查询 username 为 “lisi”
的文档(username 是 keyword 类型):
1 | GET /users_test/_search |
terms:多值精确匹配(OR 逻辑)
匹配字段值在指定列表中的文档(类似 SQL 的 IN)。
1 | GET /索引名/_search |
示例:查询 username 为 “lisi” 或
“wangwu” 的文档:
1 | GET /users_test/_search |
range:范围匹配(数值 / 日期)
针对数值、日期字段筛选范围(如年龄 > 25、注册时间在近 30 天内)。
1 | GET /索引名/_search |
例如 数值范围 查询age大于 28
的文档:
1 | GET /users_test/_search |
日期范围(查询 register_time 在 2024
年之后的文档)
1 | GET /users_test/_search |
日期简化写法:用 now 表示当前时间(如近
7 天:"gte": "now-7d")。
组合查询
多条件联合筛选(bool),通过 bool
组合多个查询条件(must/should/must_not),实现复杂逻辑(如
“年龄> 25 且 地址包含北京”)。
bool 子句说明:
must:必须匹配(类似AND);should:至少匹配一个(类似OR);must_not:必须不匹配(类似NOT);filter:过滤条件(与must类似,但不影响评分,性能更高)。
查询形式如下
1 | GET /索引名/_search |
示例:查询 “年龄> 28 且 地址包含‘广州’ 或 标签包含‘工程师’,且 邮箱不为空” 的文档:
1 | GET /users_test/_search |
过滤与排序
结果过滤(_source)
只返回需要的字段,减少数据传输。
示例:只返回 username 和
age 字段:
1 | GET /users_test/_search |
排序(sort)
按指定字段排序(数值、日期、keyword 类型支持排序,text 类型默认不支持)。
查询形式如下
1 | GET /索引名/_search |
示例:按 age 降序,再按
register_time 升序:
1 | GET /users_test/_search |
分页(from+size)
控制返回结果的起始位置和数量(适合前端分页)。
查询形式如下
1 | GET /索引名/_search |
示例:查询第 2 页数据(每页 2 条):
1 | GET /users_test/_search |
特殊查询
前缀查询(prefix)
匹配字段值以指定前缀开头的文档(适合 keyword
类型)。
示例:查询 username 以 “ergou”
开头的文档:
1 | GET /users_test/_search |
通配符查询(wildcard)
支持 *(任意字符序列)和
?(单个字符)匹配(性能巨几把低,慎用)。
示例:查询 email 以 “ergou” 开头且以
“example.com” 结尾的文档:
1 | GET /users_test/_search |
模糊查询(fuzzy)
允许输入存在拼写错误(最多 2 个字符差异),适合容错场景。
示例:查询 username 类似
“ergou”(容错匹配 “ergout”):
1 | GET /users_test/_search |
查询到的结果也可以高亮显示
默认高亮
1 | GET /test_documents/_search |
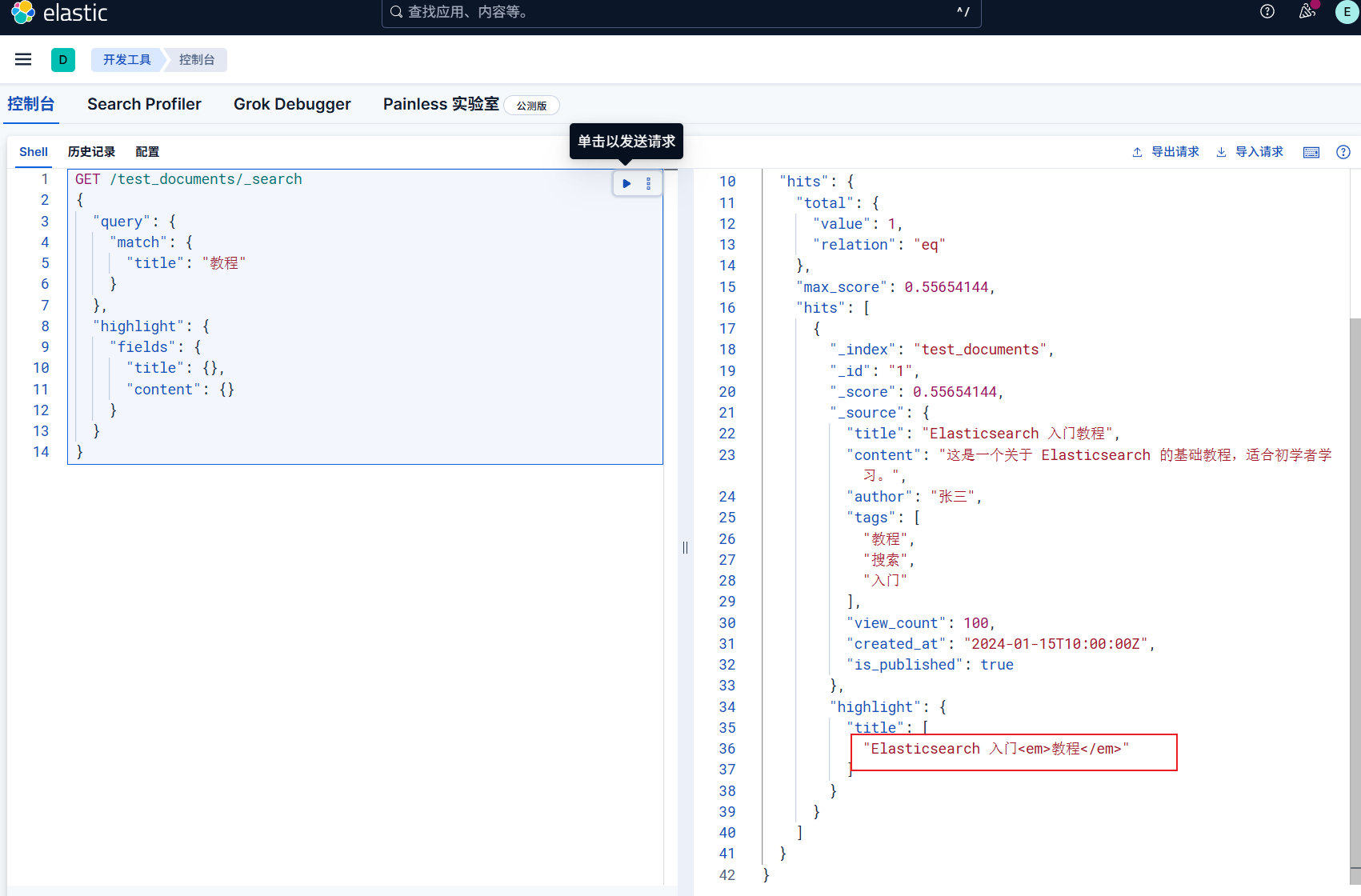
自定义高亮
pre_tags:前缀 post_tags:后缀
1 | GET /test_documents/_search |
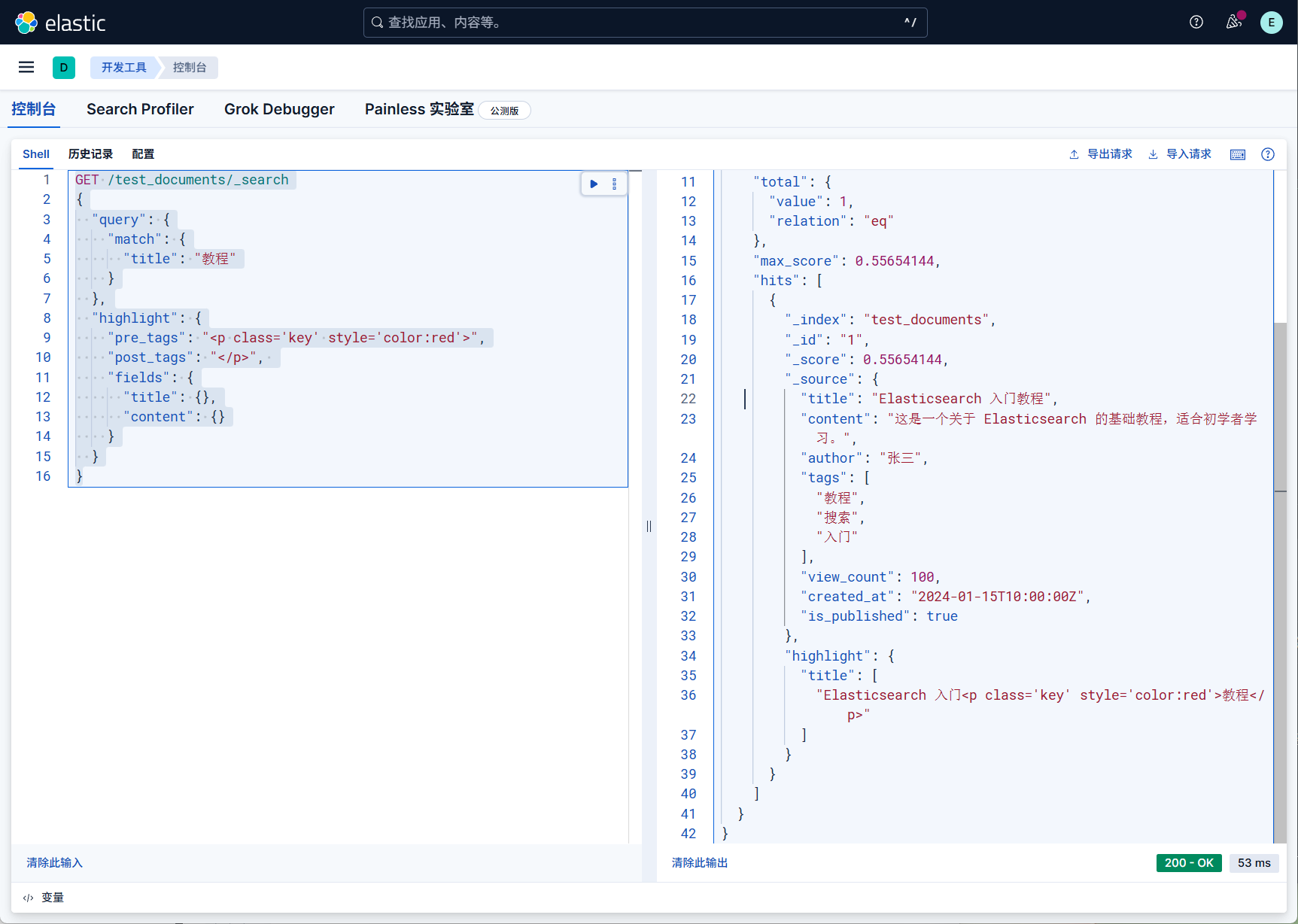
查询操作总结
| 查询类型 | 核心用途 | 适用字段类型 | 示例场景 |
|---|---|---|---|
match_all |
匹配所有文档 | 无 | 全量数据导出 |
match |
单字段全文检索(分词) | text |
搜索 “地址包含北京” |
multi_match |
多字段全文检索 | text |
搜索 “标题或内容包含关键词” |
term/terms |
精确匹配(单值 / 多值) | keyword、数值、日期 |
筛选 “用户名 = 张三” 或 “状态 = 启用” |
range |
范围匹配 | 数值、日期 | 筛选 “年龄> 25” 或 “注册时间在近 7 天” |
bool |
组合多条件(AND/OR/NOT) | 任意 | 复杂业务逻辑(如 “年龄> 25 且地址在上海”) |
prefix/wildcard |
前缀 / 通配符匹配 | keyword |
搜索 “邮箱以 xxx 开头” |
fuzzy |
容错匹配(允许拼写错误) | keyword、text |
处理用户输入错误(如 “lis” 匹配 “lisi”) |
过滤器
再讲过滤器
在 Elasticsearch 中,过滤器(Filter)
是用于筛选文档的一种机制,核心作用是根据条件过滤出符合要求的文档,但不影响文档的评分(relevance
score)。与普通查询(如
match、term)相比,过滤器更注重 “是否匹配”
而非
“匹配程度”,因此性能更高(可缓存结果),适合用于业务规则性的筛选(如状态、时间范围、数值区间等)。
这个在前面part2我说了一下,在这里只是简单提及了
1 | { |
在这样的情况下,使用过滤器的时候尤其多
- 筛选状态(如 “订单状态 = 已支付”);
- 限定时间范围(如 “创建时间在近 7 天内”);
- 过滤数值区间(如 “价格> 100 且 < 500”);
- 排除特定条件(如 “排除已删除的文档”)。
过滤器的查询操作
ES 中没有单独的 “过滤器 API”,而是通过 bool 查询的
filter 子句实现过滤功能。bool
查询支持以下子句组合过滤条件:
filter:必须匹配,不影响评分(核心过滤器);must_not:必须不匹配,不影响评分(反向过滤)。
假设 users_test 索引中有以下文档:
1 | PUT users_test/_doc/1 |
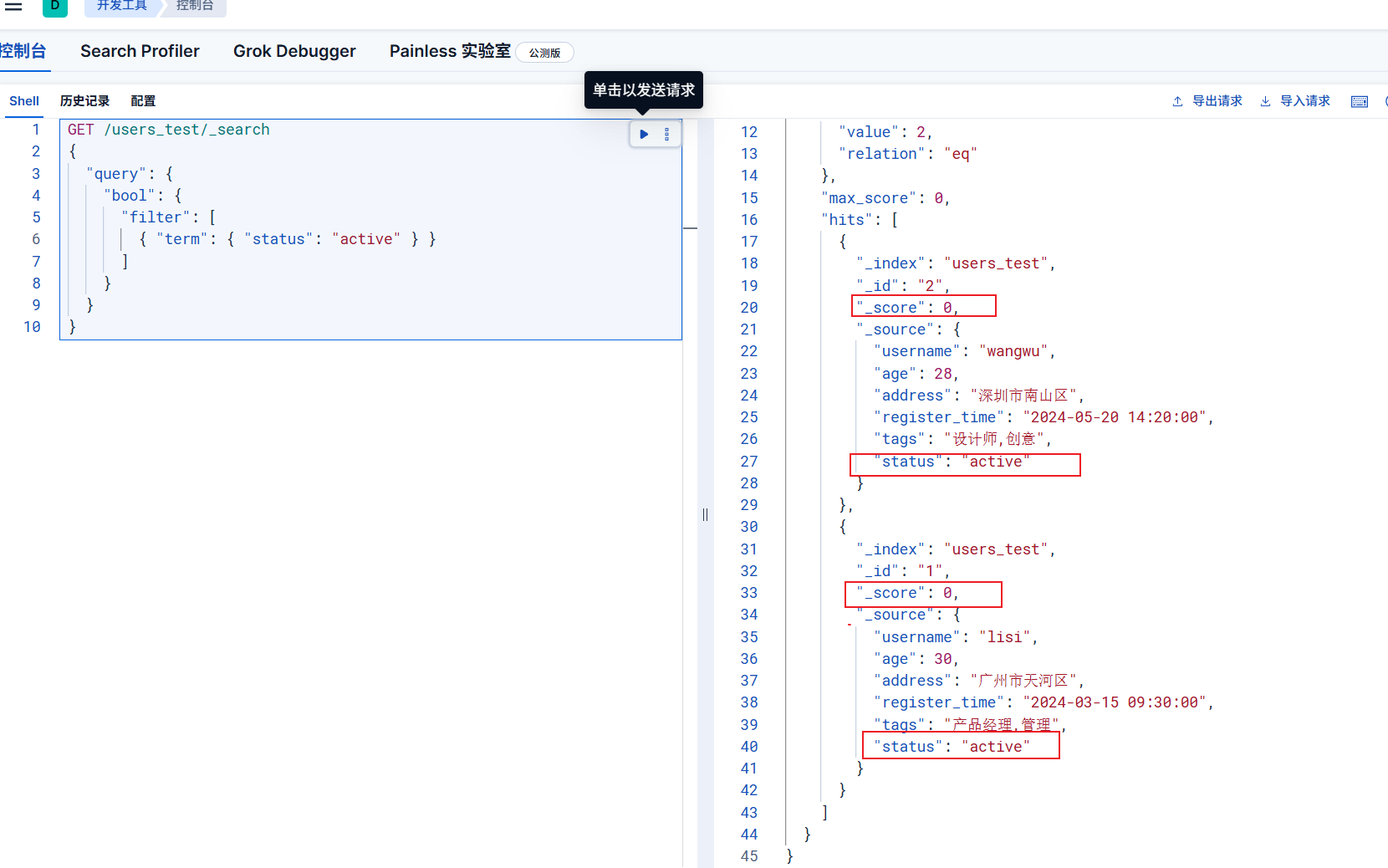
当我们进行基础过滤(单条件),筛选 status 为
“active”(活跃)的用户。查询就可以这么写
1 | GET /users_test/_search |
仅返回 status 为 “active”
的文档(lisi、wangwu),且所有文档的 _score 均为
0(因为过滤器不计算评分)。
当我们进行多条件过滤(且关系),需要筛选 “活跃用户(status=active)且年龄> 29 岁”,查询可以这么写
1 | GET /users_test/_search |
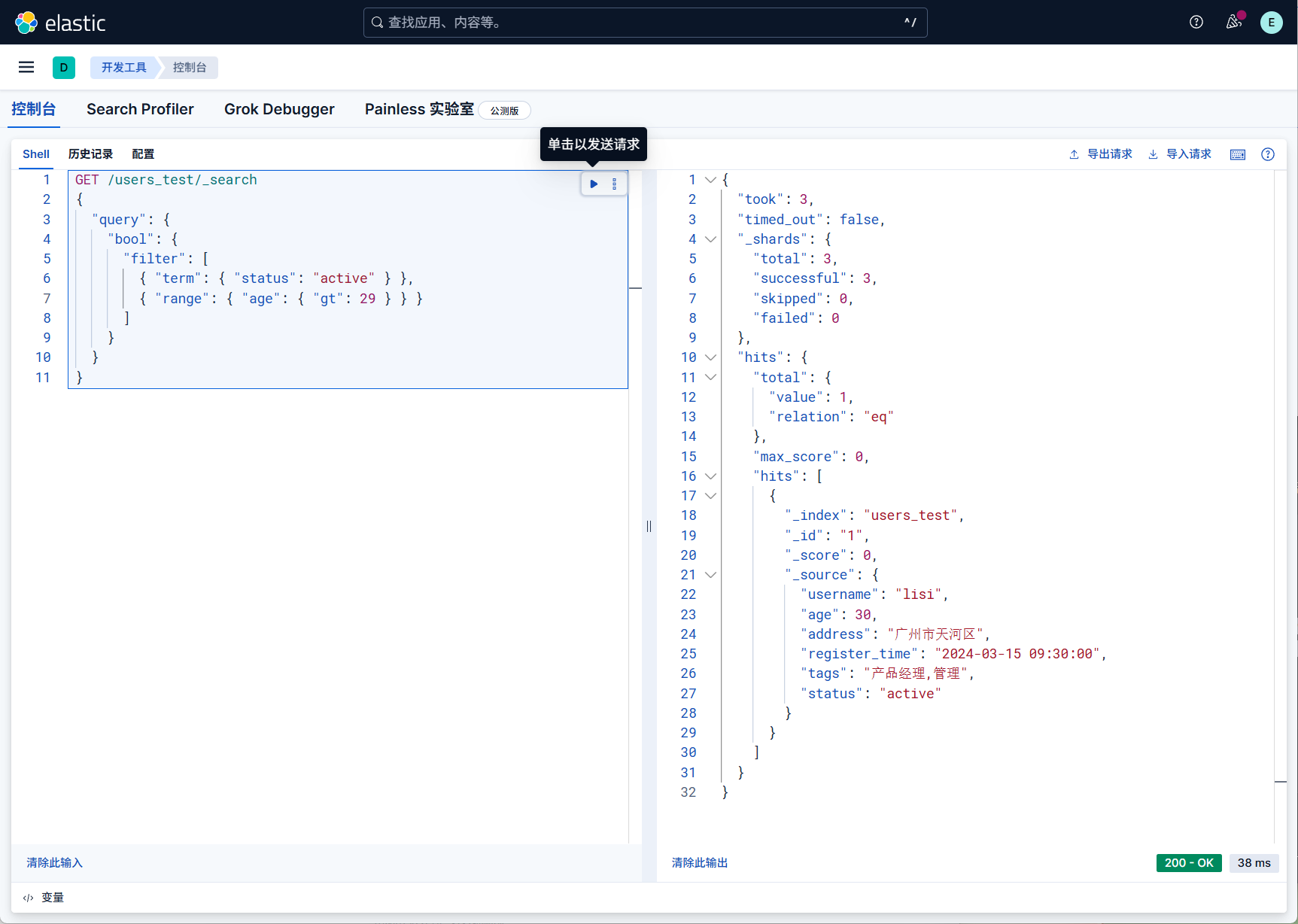
也就是说过滤器是可以无缝支持上面提到的任何条件以及复杂查询
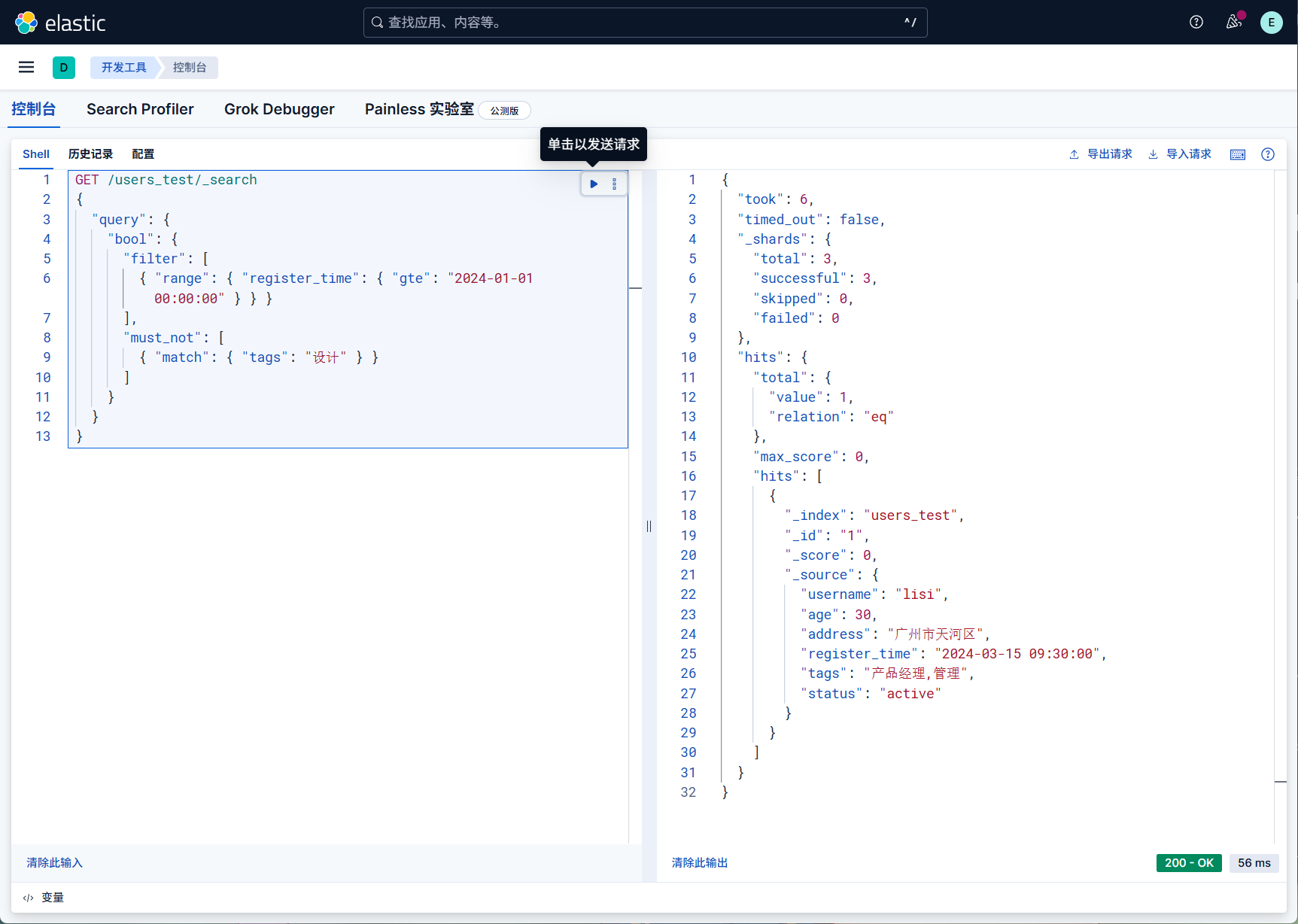
而且也可以过滤 + 排除(结合 must_not),筛选 “2024
年注册的用户,且排除标签包含‘设计’的用户”。
1 | GET /users_test/_search |
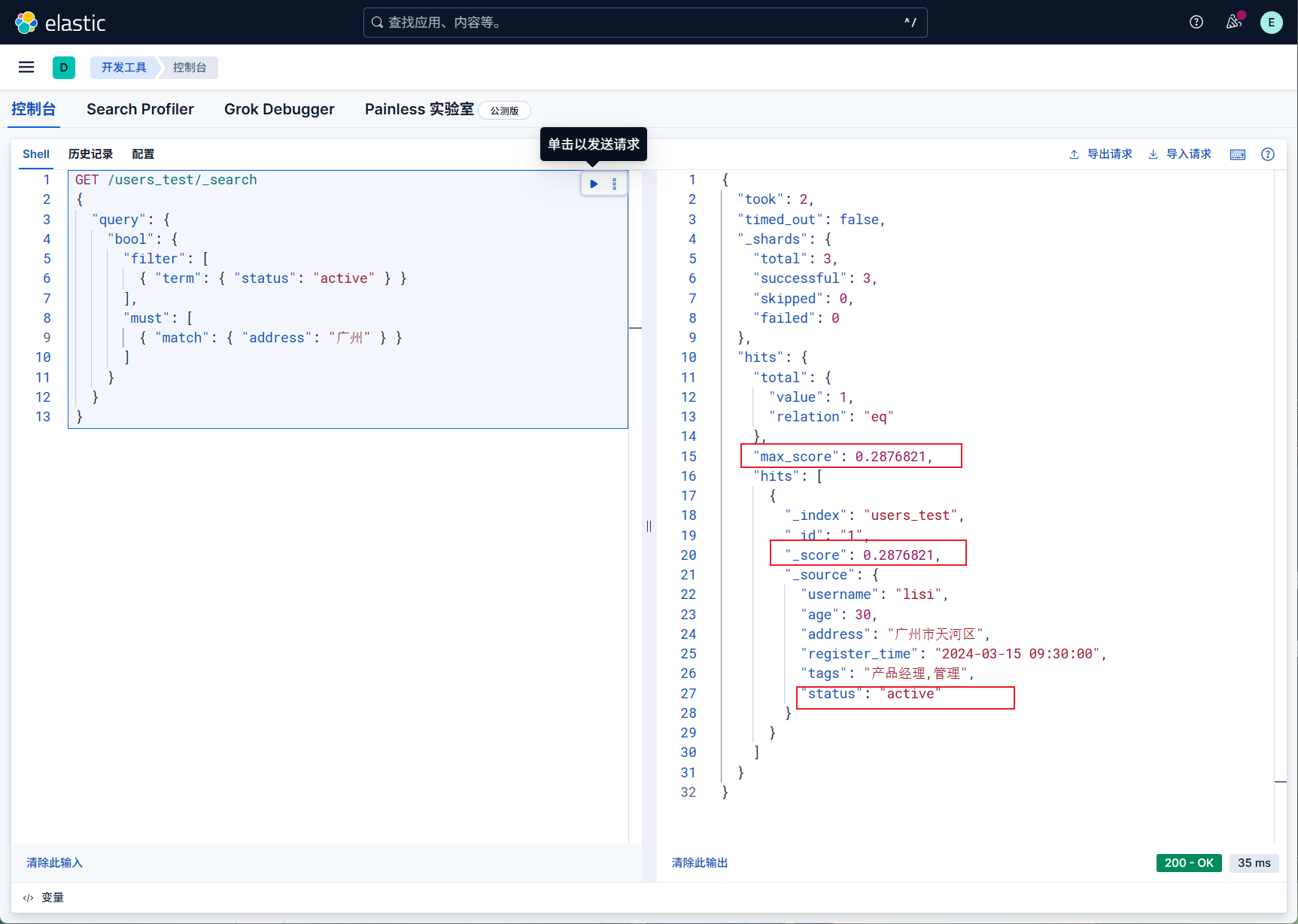
而且过滤器可与普通查询结合,实现 “先过滤范围,再按相关性排序”。
当需要筛选 “活跃用户(status=active),且地址包含‘广州’的文档,并按相关性评分排序”。
1 | GET /users_test/_search |
过滤器的工作原理
过滤器的执行过程

接收过滤请求
当客户端发送包含
filter子句的查询(如bool.filter)时,ES 进入过滤流程。检查过滤器缓存
ES 会先检查过滤器缓存(内存中的键值对,键为 “过滤条件的哈希值”,值为 “匹配文档的位图 / BitSet”)。
缓存命中:若当前过滤条件(如
status: active)已被缓存,则直接返回缓存的 BitSet,跳过后续过滤计算。缓存未命中:若条件未被缓存,则执行完整的过滤流程。
执行过滤操作(缓存未命中时)
对目标索引的文档,逐条判断是否符合过滤条件(如
status是否为active)。构建位图(BitSet)
ES 用 位图(BitSet)记录匹配结果:
位图长度等于索引的文档总数;
每个二进制位对应一个文档(位置为文档 ID);
若文档匹配过滤条件,对应位设为
1;否则为0。
例如,索引有 5 个文档,其中文档 1、3 匹配,则 BitSet 为
10100(二进制)。缓存过滤结果
将本次过滤生成的 BitSet,以 “过滤条件的哈希值” 为键,存入过滤器缓存,供后续请求复用。
返回匹配文档
根据 BitSet 中为
1的位,找到对应的文档,最终返回这些匹配的文档。
普通查询(如
match)需要计算**相关性评分(_score),而过滤器仅需
“是 / 否”
判断,且可复用缓存,因此过滤器的延迟通常远低于普通查询**,适合高频、低延迟的筛选场景(如状态过滤、时间范围过滤)。
所以过滤器的核心是 “快速筛选文档,且不影响相关性评分”。
为实现高性能,ES 对过滤器做了两点关键优化:
- 结果缓存:重复的过滤请求可直接复用缓存,避免重复计算;
- 位图(BitSet)匹配:用二进制位标记文档是否匹配,比遍历文档更高效。
这两个内容都在 part2 都进行了详细的流程分析和原理讲解,在这里只是说一下比较重要的
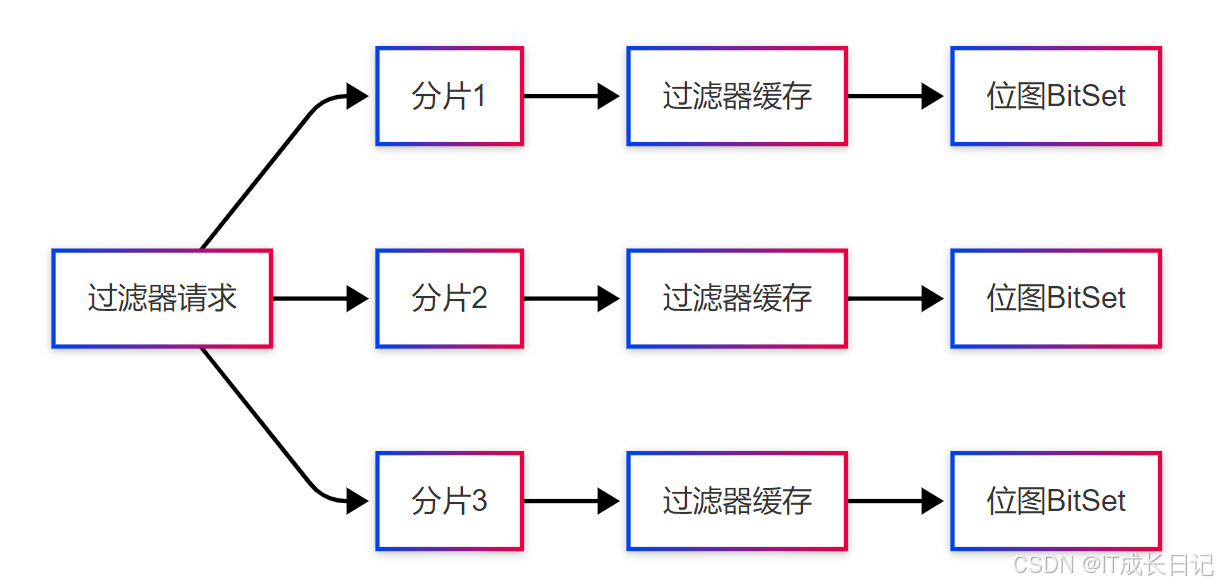
Elasticsearch的过滤器缓存是基于分片(Shard)级别的,其架构如下:
而且ES 会自动管理过滤器缓存:
- 缓存淘汰:采用 LRU(最近最少使用)策略,移除长时间未使用的缓存项;
- 缓存失效:当索引有文档新增 / 删除 / 更新时,相关的过滤器缓存会自动失效,保证结果准确性。
可通过indices.queries.cache.size配置缓存大小






