
分词器
什么是分词器
分词器是 Elasticsearch 中用于处理文本数据的核心组件。它的任务是将一串原始的、连续的文本(比如一个句子或一段话),切分成一个个独立的、有意义的词条,并可能对这些词条进行规范化处理。
分词器是将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具。
想象一下你在处理英文句子
"I'm loving the beautiful scenery!"。
- 未经处理:对计算机来说,这只是一长串字符。
- 经过分词器处理后:它会被切分成
["i'm", "loving", "the", "beautiful", "scenery"],并且可能进一步规范化为["i", "love", "beautiful", "scenery"](去停用词、词干提取等)。 这样,计算机才能基于这些独立的词条来构建倒排索引,并进行高效的搜索。
其中,ES 内置了许多分词器:
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
- Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当做输出
- Pattern Analyzer - 正则表达式,默认 +
- Language - 提供了 30 多种常见语言的分词器
- Customer Analyzer - 自定义分词器
英文等拉丁语系的语言天然地使用空格作为词语的分隔符,因此标准分词器就能工作得很好。例如:
"I love Beijing" ->
["i", "love", "beijing"]
但中文、日文、韩文等语言没有明显的词语分隔符。一个句子是由连续的字符组成的。
"我爱北京"
- 如果使用标准分词器:它会逐字切分,结果为
["我", "爱", "北", "京"]。 - 这会导致严重问题:
- 索引词条数量爆炸,全是单字。
- 搜索精度极差。搜索
"北京"时,实际上是在搜索"北" AND "京",那么包含"北方的东京塔"的文档也会被匹配出来,产生大量无关结果。 - 无法进行准确的短语查询。
因此,我们需要中文分词器来智能地识别出句子中的词语边界。IK 分词器就是其中最流行和优秀的一个。
分词器的结构
一个标准的分词器由三个低层级的模块串联而成,形成一个处理管道:
- 字符过滤器
- 作用:在文本被实际分词之前,对原始文本进行预处理。接收原字符流,通过添加、删除或者替换操作改变原字符流
- 工作内容:添加、删除或更改字符流。
- 常见例子:
- HTML 剥离过滤器: 将
<p>I'm so <b>happy</b>!</p>处理成I'm so happy!,去除 HTML 标签。 - 映射过滤器: 例如将表情符号或缩写替换成文字,如将
:)替换为_smile_。 - 正则替换过滤器: 使用正则表达式修改文本。
- HTML 剥离过滤器: 将
- 分词器
- 作用:这是整个分词器的核心。它接收来自字符过滤器的字符流,并将其切分成一个个独立的词条(Token)。简单的说就是将一整段文本拆分成一个个的词。
- 工作内容:定义具体的切分规则。一个文本字符串只能有一个分词器。
- 常见例子:
- 标准分词器: 根据 Unicode 文本分割准则进行切分,对于大多数欧洲语言很有效。它会移除大部分标点符号。
- 关键词分词器: 将整个文本作为一个单独的词条输出,不做任何切分。
- 模式分词器: 使用正则表达式来切分文本。
- 词条过滤器
- 作用:对分词器产出的词条进行再加工。
- 工作内容:对每个词条进行添加、删除或修改的操作。
- 常见例子:
- 小写转换过滤器: 将所有词条转换为小写,确保搜索时不区分大小写。
- 停用词过滤器:
移除常见的、无实际意义的词,如英语中的
"a","an","the", 中文中的"的","了","在"。 - 同义词过滤器: 在索引时或查询时添加同义词。例如,将
"jump"和"leap"视为同一个词条。 - 词干还原过滤器: 将单词还原为其词根形式,如
"running"->"run","flies"->"fly"。
工作流程总结: 原始文本 ->
字符过滤器 -> 处理后的文本 ->
分词器 -> 词条流 ->
词条过滤器 -> 最终词条
所以说文本分词会发生在两个地方:
创建索引:当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。搜索:当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
什么是 IK 分词器
IK Analyzer 是一个专为中文分词设计的开源 Elasticsearch 插件。它采用了基于词典的切分算法,并辅以智能的消歧义能力。
IK 分词器的两种核心模式
ik_smart- 智能切分模式- 目标:做最粗粒度的切分,保证语义的准确性。
- 特点:切分的词条数量少,覆盖关键概念。
- 示例:
"中华人民共和国国歌"- 分词结果:
["中华人民共和国", "国歌"]
- 适用场景: 查询模式。因为切分粒度大,搜索时更精准,召回的结果不会太杂乱。
ik_max_word- 最细粒度切分模式- 目标:将文本做最细粒度的拆分,尽可能多地吐出可能的词语组合。
- 特点:切分的词条数量多,覆盖所有可能的情况。
- 示例:
"中华人民共和国国歌"- 分词结果:
["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和", "国歌", "歌"]
- 适用场景: 索引模式。因为切分出的词条多,所以被搜索命中的概率也更高,能提高召回率。
如何工作?
IK 分词器内部维护了一个庞大的主词典。当它处理文本时:
- 它会尝试在词典中匹配最长的词条(最长匹配算法)。
- 同时,它会考虑文本的上下文,对歧义句子进行智能切分。
- 例如,对于
"乒乓球拍卖完了",它能正确地切分为["乒乓球拍", "卖", "完", "了"],而不是["乒乓球", "拍卖", "完", "了"]。
- 例如,对于
安装IK分词器
首先,到 github 仓库下载你需要的版本的zip
https://github.com/infinilabs/analysis-ik/releases/tag/Latest

https://release.infinilabs.com/analysis-ik/stable/
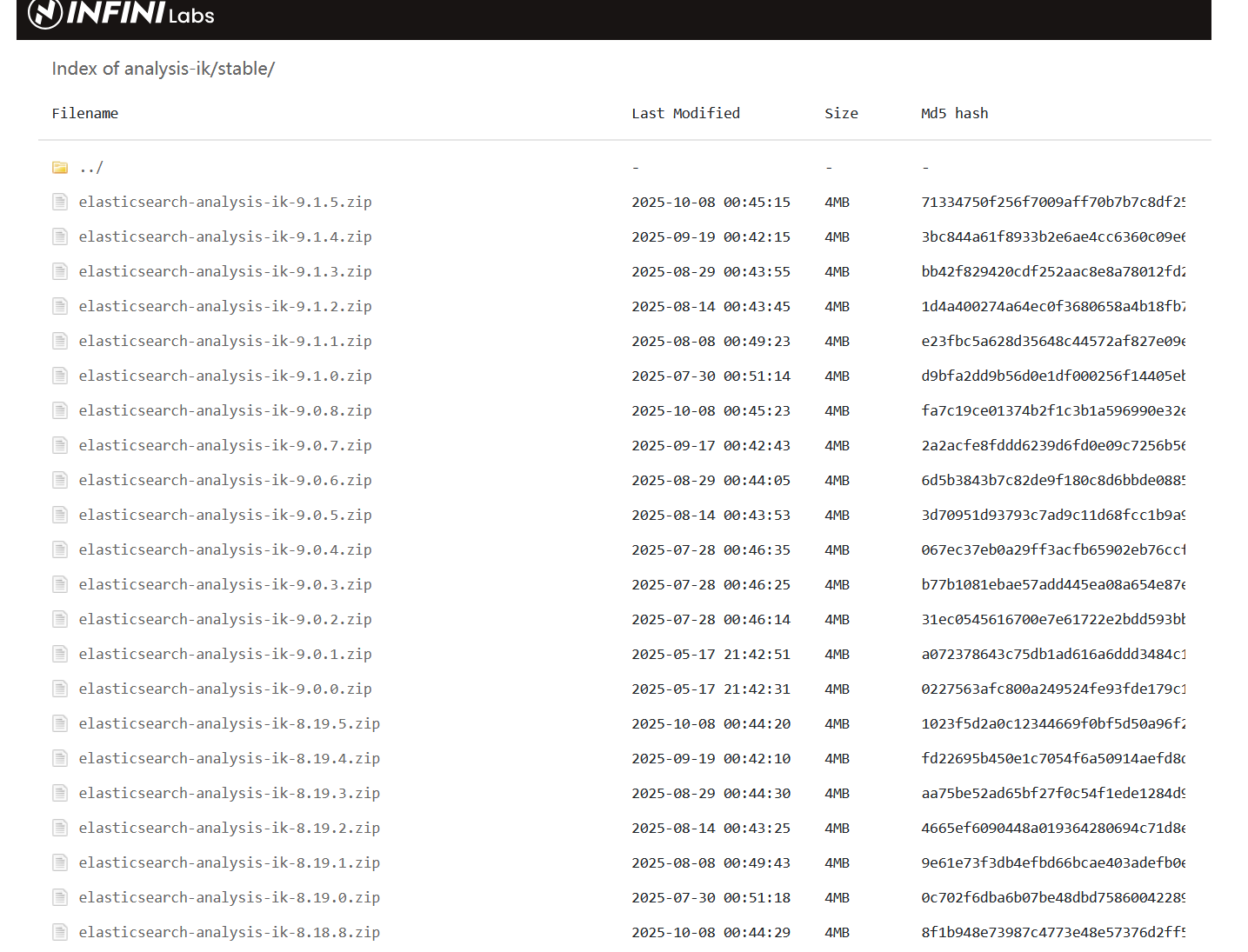
下载后,解压到 ES 中的 plugin 文件夹中
重新启动 ES,可以看到加载了 ik 分词器
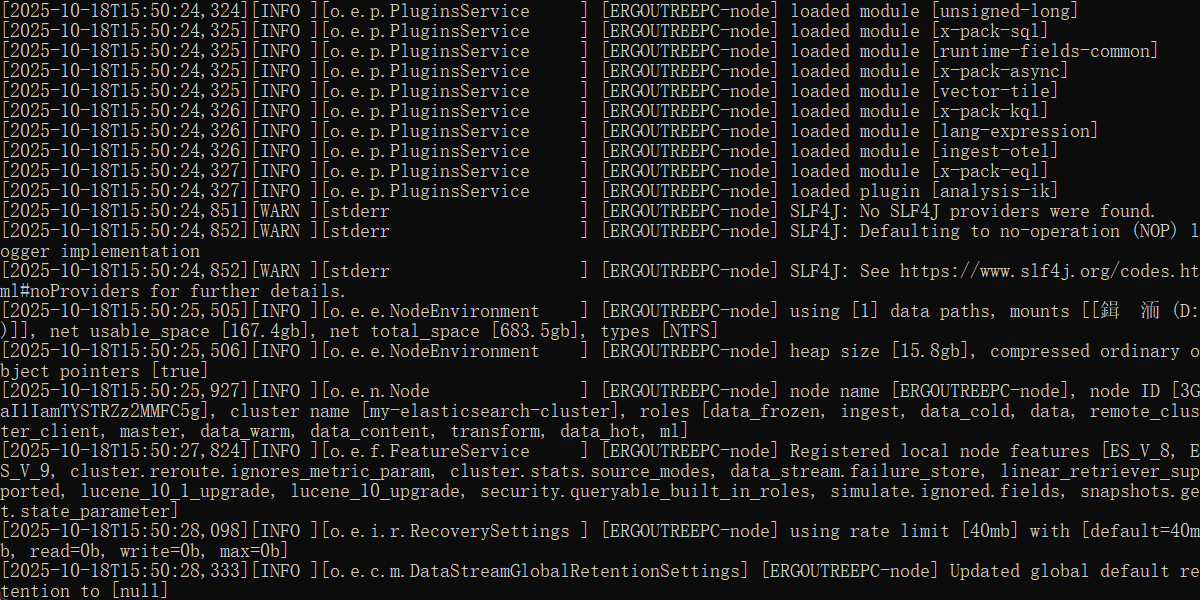
进入kibana测试,选择开发者工具,发送一个最简单的请求
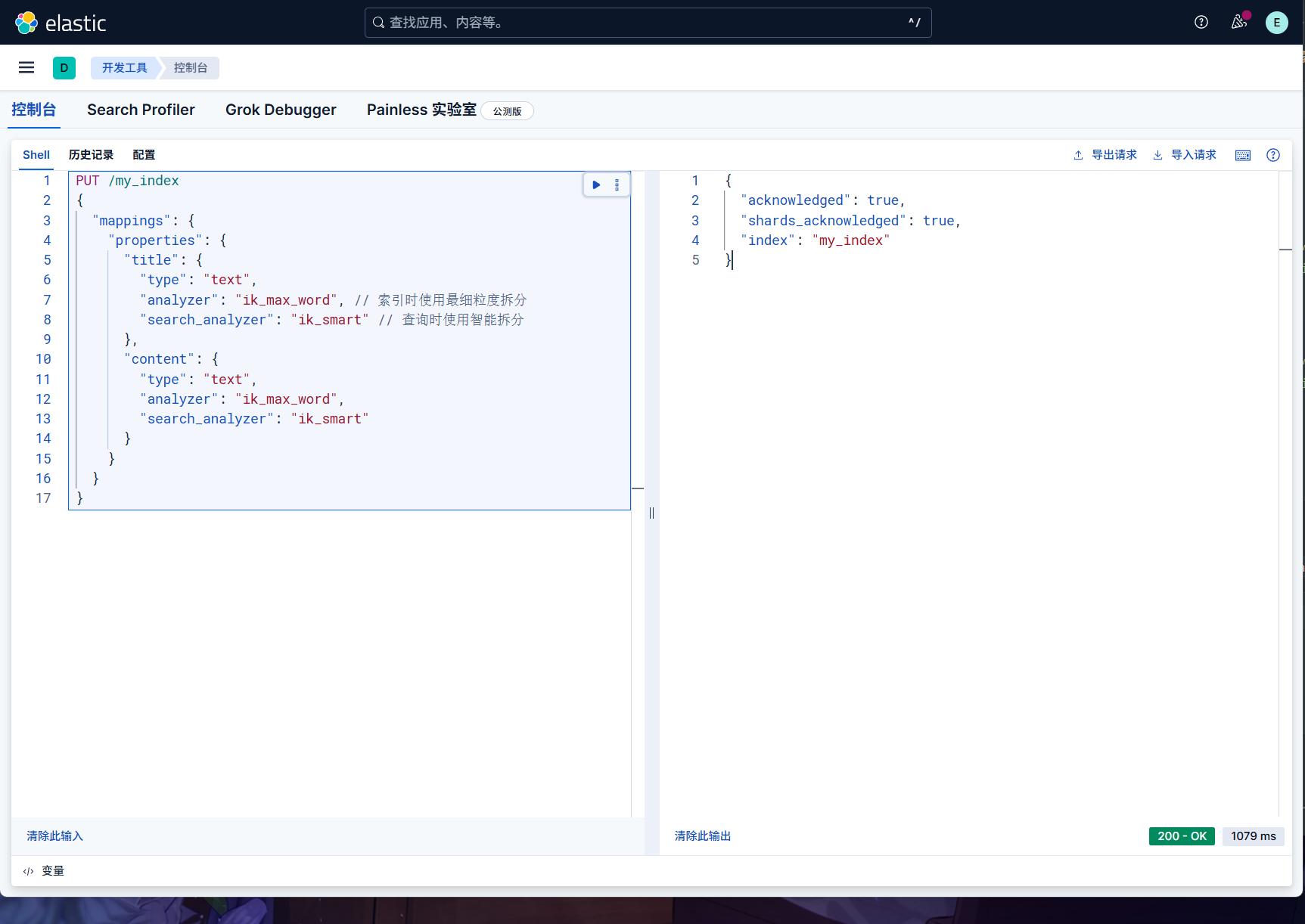
我们创建一个索引,并且在在创建索引时,为需要中文分词的字段指定使用 IK 分词器。
1 | PUT /my_index |
而一般情况下,为了提高搜索的效果,需要这两种分词器配合使用。
既建索引时用 ik_max_word 尽可能多的分词,而搜索时用
ik_smart 尽可能提高匹配准度,让用户的搜索尽可能的准确。
测试一下分词效果,可以使用 _analyze API
来测试分词效果。
1 | GET /my_index/_analyze |
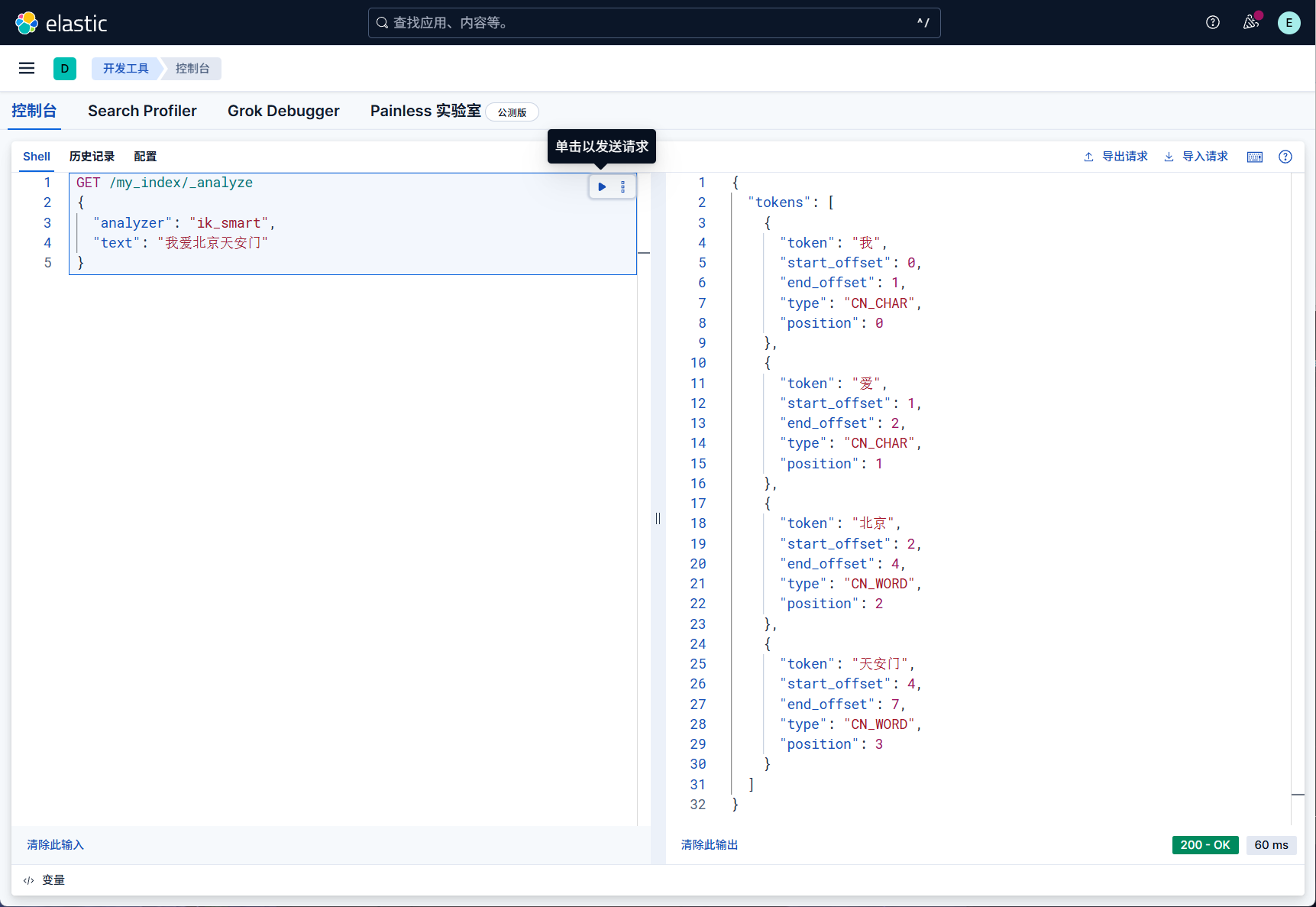
测试一下中英文一起的分词

我们调整到最细粒度的划分
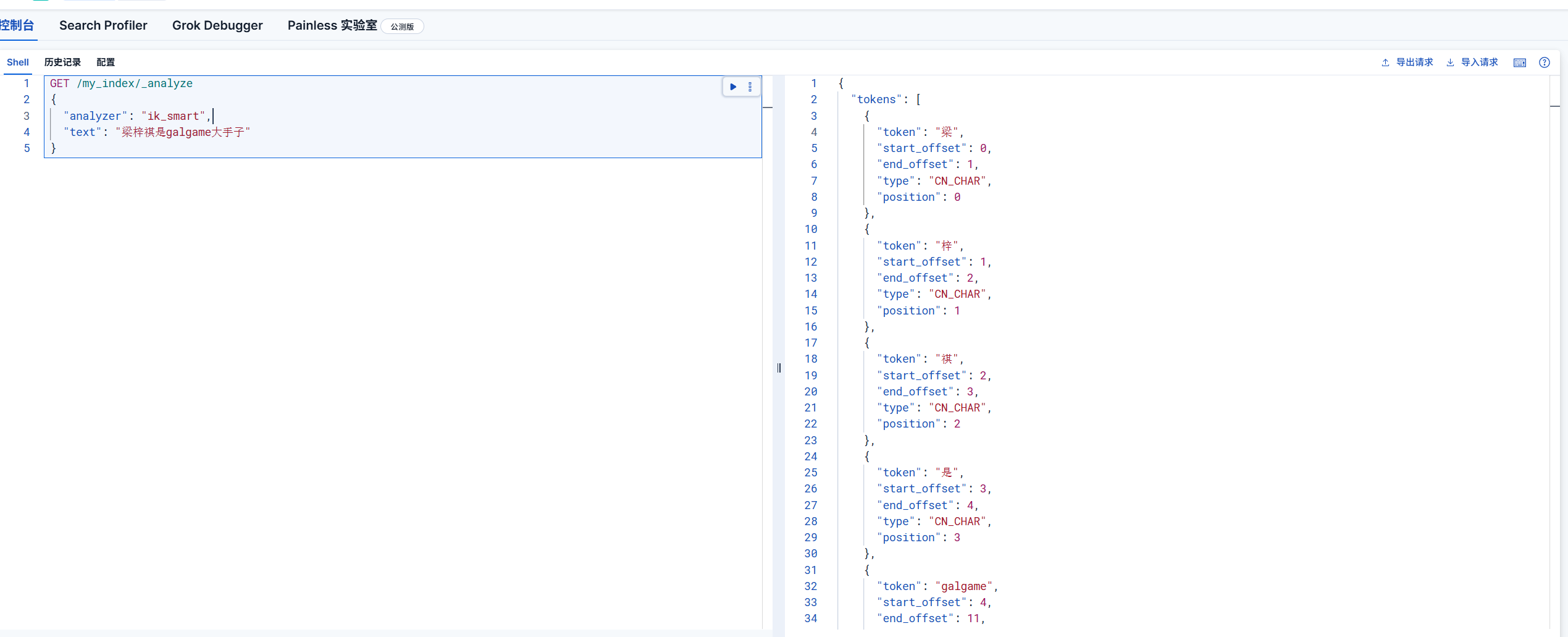
从上面的分词中我们不难能看出一个问题
那就是其中词组“大手子”和“梁梓祺”都是一个词,这样我想要的结果是通过最细力度切分后还能打印大手子这个词组而不是被切分成多个词组的单字,那么有没有办法了?
办法就是新建一个属于自己的词库,因为我们之前都是使用的默认的词库,使用默认的词库可能达不到我们所预期的目标或者想法,所以我们可以通过新建词库来实现自己想要的词组
词库
什么是词库
词库是包含词汇的数据库,用于文本分析时识别和分割词语。
本质是结构化存储词汇的数据库,核心作用是在文本分析(如自然语言处理任务)中,帮助系统准确识别、分割词语,避免因 “逐字拆解” 或 “误判词汇边界” 导致的分析误差。
其核心价值体现在 3 个关键场景:
提升分词准确性:解决通用分词工具的 “歧义问题”。例如 “苹果手机”,若无词库标注,系统可能拆分为 “苹果 / 手机”(正确),也可能误拆为 “苹 / 果 / 手 / 机”(错误);加入词库后,会强制按 “苹果手机” 整体识别。
识别特殊词汇
:覆盖通用词典未收录的内容。
- 专业术语:如法律领域的 “表见代理”、医疗领域的 “靶向治疗”;
- 新词汇:如网络热词 “内卷”“躺平”、新兴事物 “直播带货”;
- 专属名称:如企业内部项目名 “星辰计划”、特定人名 “马斯克”。
统一业务分词标准:确保同一业务场景下词汇拆分结果一致。例如电商平台将 “无线蓝牙耳机” 统一标注为整体词汇,避免不同环节(搜索、推荐、订单分析)拆分为 “无线 / 蓝牙 / 耳机” 或 “无线蓝牙 / 耳机”,保证数据统计和业务逻辑统一。
词库相关操作
新建词库
构建是词库的基础,需明确 “收录什么词” 和 “怎么收录”,常见步骤:
- 确定词库类型:根据使用场景分类,避免词汇混乱。
- 通用词库:收录基础常用词(如 “吃饭”“工作”),通常直接复用成熟词典(如哈工大 LTP 词库、jieba 默认词库);
- 行业词库:针对特定领域,如金融行业收录 “年化收益率”“ETF 基金”,教育行业收录 “选课系统”“学分绩点”;
- 业务词库:贴合企业具体需求,如某电商平台收录 “店铺优惠券”“7 天无理由退换”。
- 收集词汇来源:确保词汇全面性和准确性。
- 内部来源:企业业务文档(如产品手册、客服话术)、用户行为数据(如搜索关键词、评论内容);
- 外部来源:行业报告、权威术语库(如国家标准术语库)、公开词库(需注意版权);
- 人工整理:由业务专家筛选、校验词汇(避免错误词汇,如将 “错别字” 纳入词库)。
- 定义词汇属性:让词库更 “智能”,支持复杂分析。
- 基础属性:词汇本身(如 “区块链”)、拼音(辅助语音相关任务);
- 业务属性:词性(如 “区块链” 是名词)、所属分类(如 “技术 / 信息技术”)、权重(如核心业务词 “会员费” 权重高于普通词 “收据”)。
进入IK 分词器加载路径:
1 | D:\OtherLanguageSetting\Elasticsearch\elasticsearch-9.1.4\config\analysis-ik\ |
这是我的
IKAnalyzer.cfg.xml 配置文件是 IK 分词器的核心配置文件:
1 |
|
我们这样加入自己的扩展词典
1 |
|
然后在 config/analysis-ik/custom/ 目录下创建上面写的两个词典文件
写入对应的词,我演示的是停用词词典
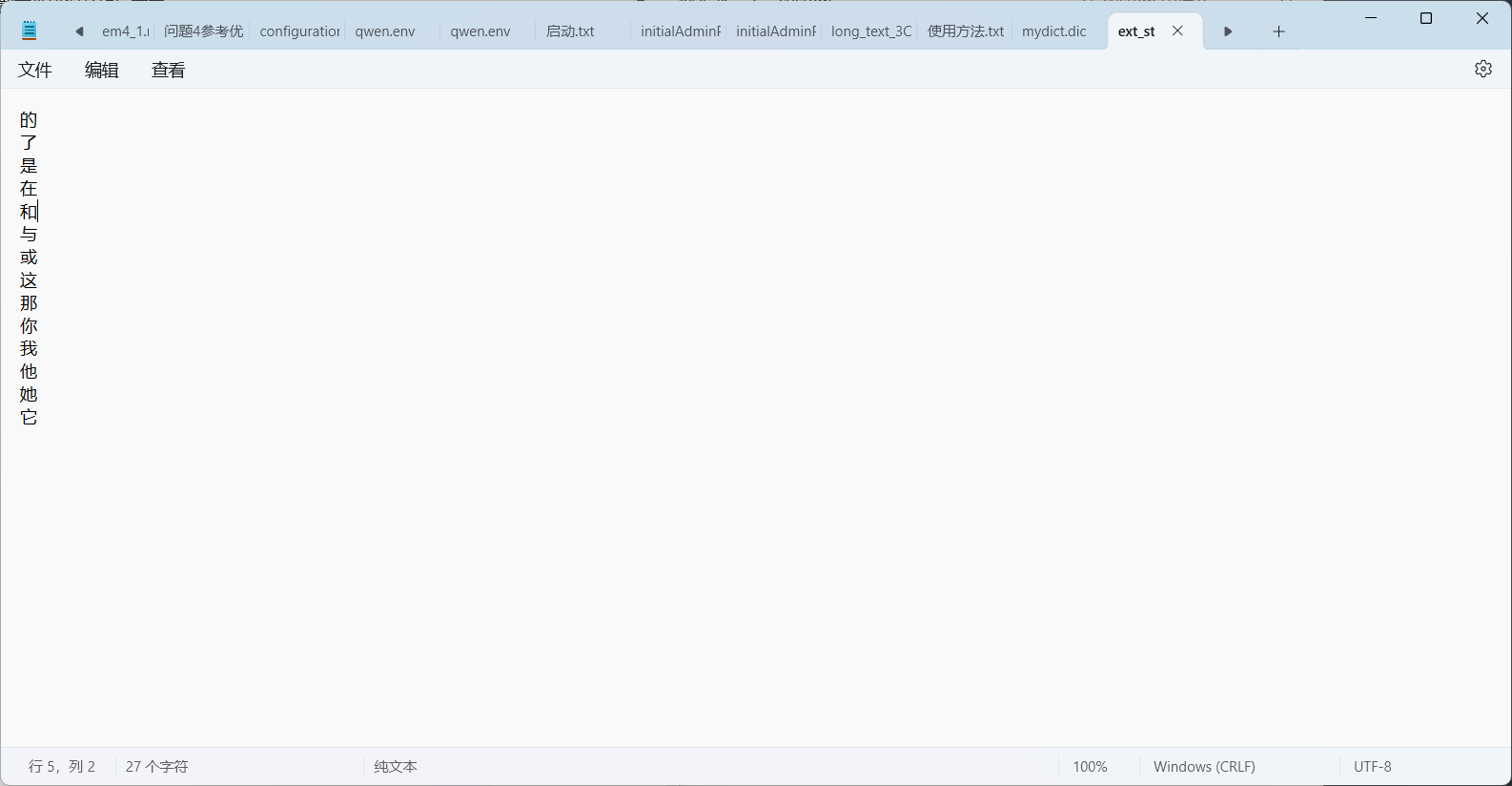
词典文件格式是有要求的
- 每行一个词
- 使用 UTF-8 编码(无 BOM)
- 词条不需要排序
- 文件扩展名通常为
.dic
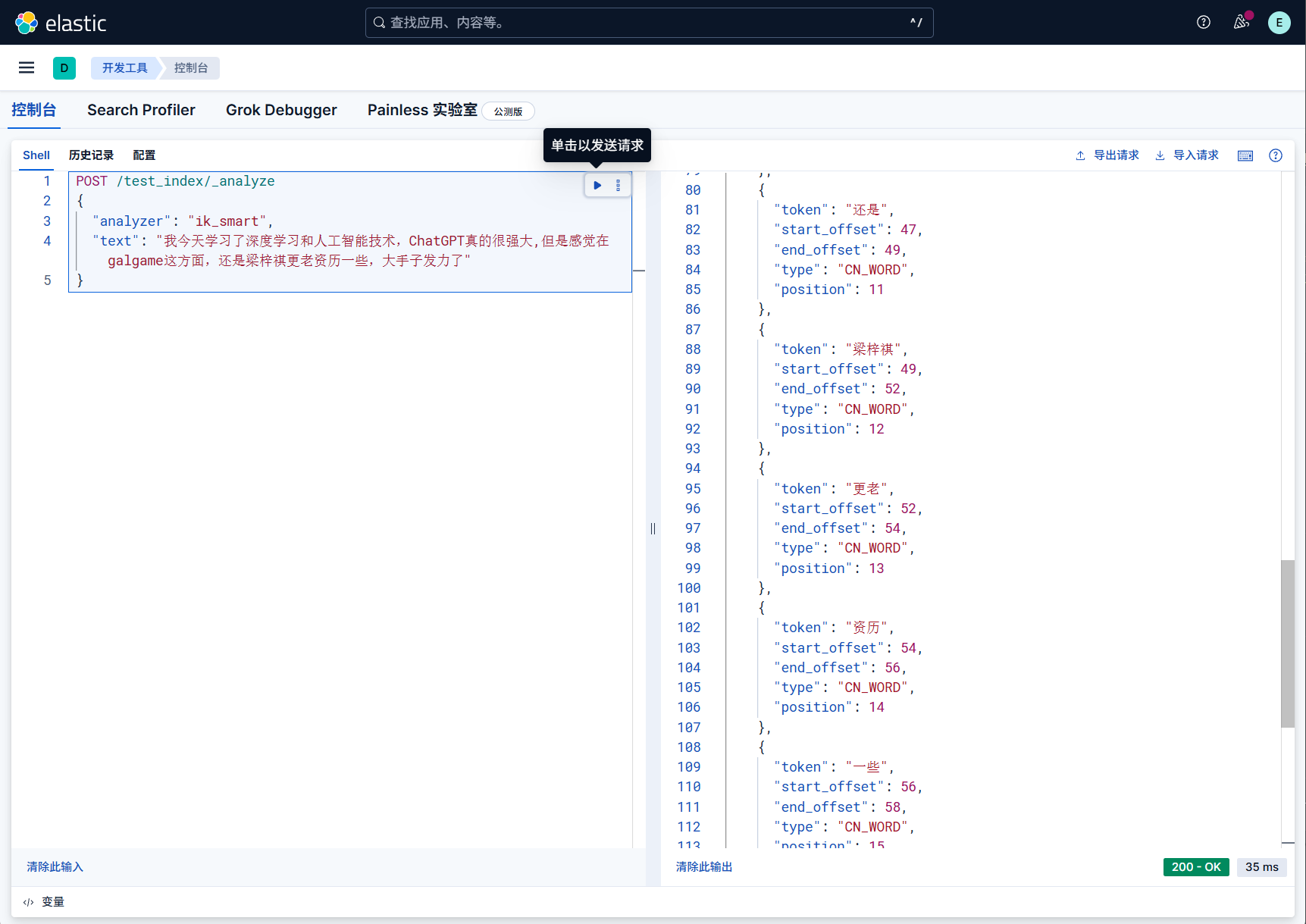
我们测试一下词库效果
创建测试索引
1 | PUT /test_index |
测试分词效果,注意要重启es,使其生效
1 | POST /test_index/_analyze |
这样,添加词库后的效果就很好了,分词出现了我们想要的词组,而不是单字
其实也可以动态更新词库,使用远程词典配置,IK 分词器会定期检查更新:
修改 IKAnalyzer.cfg.xml:
1
2<entry key="remote_ext_dict">http://localhost:9200/dict/custom_dict</entry>
<entry key="remote_ext_stopwords">http://localhost:9200/dict/stop_words</entry>创建热更新接口:
1
2
3
4
5
6
7
8
9PUT /dict/custom_dict/1
{
"content": "深度学习\n人工智能\n机器学习\n大数据\n云计算\n区块链\n物联网\n边缘计算\n数字孪生\n元宇宙\nChatGPT\n新词1\n新词2"
}
PUT /dict/stop_words/1
{
"content": "的\n了\n是\n在\n和\n与\n或\n这\n那\n你\n我\n他\n她\n它\n一些\n某个"
}
词库应用
应用是词库发挥价值的环节,需结合具体工具和场景,常见方式:
- 对接分词工具:将词库导入主流分词工具(如
jieba、HanLP),强制工具按词库规则分词。例如在 jieba
中通过
add_word()函数添加自定义词,确保 “lzq直播间” 不被拆分。 - 支撑核心业务
- 文本搜索:用户搜索 “华为 Mate60” 时,词库识别该短语为整体,快速匹配相关商品;
- 情感分析:分析用户评论时,词库识别 “性价比高”(正面)、“售后差”(负面)等情感词汇,提升分析准确性;
- 数据统计:统计 “新能源汽车” 的销量时,词库确保不拆分为 “新 / 能源 / 汽车”,避免统计口径错误。
在项目中使用分词工具自动识别然后写入词典的操作会在后面进行讲解
词库更新
词库需定期更新,避免 “脱节”,更新频率取决于业务场景:
- 高频更新场景:网络热词、电商新品(如每月更新 1 次);
- 中频更新场景:行业术语、业务流程(如每季度更新 1 次);
- 低频更新场景:通用基础词汇(如每年更新 1 次)。
更新流程通常为:先通过工具(如爬虫抓取行业数据、用户评论)或人工收集新词,再经过 “筛选 - 校验 - 导入” 三步,确保新增词汇准确有效。
管理是避免词库 “过期”“冗余” 的关键,核心操作包括:
新增词汇:当出现新场景、新词汇时补充。例如某科技公司新增 “生成式 AI”“大模型” 到技术词库。
这种直接在词典中写入新词就可以
1
2
3
4
5
6
7
8# 编辑扩展词典
notepad mydict.dic
# 在文件末尾添加新词,每行一个:
深度学习平台
人工智能助手
机器学习模型
大数据分析也可以使用追加命令
1
2
3
4
5
6
7
8
9
10# 追加单个词
echo "云计算服务" >> mydict.dic
# 追加多个词
cat >> mydict.dic << EOF
区块链技术
物联网设备
边缘计算节点
数字孪生系统
EOF删除词汇:清理无效、过时词汇。例如删除旧网络热词 “给力”(若业务不再需要)、废弃业务术语 “线下充值点”。
直接操作词典就不说了,也可以使用命令,进而实现自动操作
1
2
3
4
5# 删除包含特定字符串的词条
sed -i '/要删除的词/d' mydict.dic
# 示例:删除包含"测试"的词
sed -i '/测试/d' mydict.dic修改词汇:修正错误或更新属性。例如将 “移动支付” 的分类从 “金融工具” 调整为 “日常服务”,或修正错词 “支 fu 宝” 为 “支付宝”。
修改词汇直接操作词典就不说了,也可以使用命令,进而实现自动操作
1
2
3
4
5# 使用 sed 替换
sed -i 's/旧词汇/新词汇/g' mydict.dic
# 示例:将"手机"改为"智能手机"
sed -i 's/^手机$/智能手机/g' mydict.dic在这里列举一下我常用的停用词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 创建详细停用词分类
cat > stopwords_detail.dic << EOF
# 语气词
啊
哦
嗯
呃
呀
吧
吗
呢
# 连接词
然后
所以
但是
然而
因此
# 代词
这个
那个
这些
那些
它
他们
EOF分类管理:按层级或场景划分词库,方便调用。例如将 “电商词库” 细分为 “商品词库”(衣服、手机)、“营销词库”(满减、秒杀)、“物流词库”(包邮、保税仓)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 创建专业术语词典
cat > professional_terms.dic << EOF
机器学习
深度学习
自然语言处理
计算机视觉
数据挖掘
EOF
# 创建产品名称词典
cat > product_names.dic << EOF
微信
支付宝
淘宝
京东
抖音
EOF
# 创建技术名词词典
cat > technical_terms.dic << EOF
Java
Python
JavaScript
SpringBoot
Vue.js
React
EOF然后配置中使用多词典
1
2
3
4
5
6
7<entry key="ext_dict">
mydict.dic;
single_word.dic;
professional_terms.dic;
product_names.dic;
technical_terms.dic
</entry>
ES字段类型
总览
Elasticsearch(ES)的字段类型(Field Type)决定了数据的存储方式、索引策略及可支持的查询 / 聚合操作,选择正确的字段类型是保障 ES 性能和查询准确性的核心。
ES 字段类型可分为 6 大类,各类别下包含多个具体类型,核心用途如下表:
| 分类 | 包含类型(示例) | 核心用途 |
|---|---|---|
| 文本类型 | Text、Keyword | 处理字符串(文字、标识、标签) |
| 数值类型 | Integer、Long、Float、Double 等 | 存储数字(计数、金额、评分) |
| 日期类型 | Date | 存储时间(时间戳、日期字符串) |
| 布尔类型 | Boolean | 存储布尔值(true/false) |
| 复杂类型 | Object、Nested | 存储嵌套 / 结构化数据(对象、数组) |
| 特殊类型 | IP、GeoPoint、Completion | 处理特殊场景(IP 地址、地理位置、搜索补全) |
其中,核心数据类型如下
| 类型 | 说明 | 适用场景与特点 |
|---|---|---|
| text | 用于全文检索的字符串字段,会经过分词器拆分成词项并建立倒排索引。 | 适合长文本、描述、文章内容等需要模糊匹配、分词查询的场景。不支持排序和精确聚合。 |
| keyword | 不分词的字符串字段,整体作为一个词项索引。 | 适合存储结构化短文本,如用户名、邮箱、标签、状态码等。支持精确匹配、过滤、排序和聚合。 |
| long | 64位整数 | 存储时间戳、ID、计数等大范围整数。支持范围查询、排序、聚合。 |
| integer | 32位整数 | 存储较小范围的整数,如数量、等级等。支持范围查询、排序、聚合。 |
| float/double | 单精度/双精度浮点数 | 存储金额、权重、评分等带小数的数值。支持范围查询、排序、聚合。 |
| boolean | 布尔值,true 或 false | 存储二元状态,如开关、是否激活等。支持过滤和聚合。 |
| date | 日期时间类型 | 存储日期时间,支持多种格式。方便时间范围查询、排序和时间聚合。 |
| binary | 二进制数据,不支持检索和聚合 | 存储图片、文件等二进制内容,主要用于存储,不用于搜索。 |
复合数据类型如下
| 类型 | 说明 | 适用场景与特点 |
|---|---|---|
| object | JSON
对象,包含多个字段,存储单个对象(如user: { name: "张三", age: 25 }),处理
“对象数组”
时,会将数组扁平化(如orders: [ { id: 1 }, { id: 2 } ]会被拆为orders.id: [1,2]),无法关联对象内的字段。 |
存储结构化数据,字段之间无独立索引,数组中对象匹配可能出现跨对象匹配问题。 |
| nested | 嵌套对象数组,每个对象独立索引,专门处理 “对象数组”,会将数组中的每个对象视为独立文档存储,保留对象内字段的关联关系。 | 解决数组中对象字段交叉匹配问题,适合复杂数组结构,支持嵌套查询。 |
| array | Elasticsearch 不单独定义数组类型,字段可直接存储数组值 | 支持存储同类型多个值,数组中元素类型由字段类型决定。 |
| 类型 | 核心说明 | 适用场景 | 关键差异 |
|---|---|---|---|
| Object | 存储单个对象(如user: { name: "张三", age: 25 });处理
“对象数组”
时,会将数组扁平化(如orders: [ { id: 1 }, { id: 2 } ]会被拆为orders.id: [1,2]),无法关联对象内的字段。 |
单个嵌套对象(如商品的
“品牌信息”brand: { id: 1, name: "华为" }) |
不支持 “对象数组” 的精准查询(如无法查询 “同时满足 id=1 且 name = 华为” 的订单)。 |
| Nested | 专门处理 “对象数组”,会将数组中的每个对象视为独立文档存储,保留对象内字段的关联关系。 | 对象数组(如用户的
“订单列表”orders: [ { id: 1, price: 100 }, { id: 2, price: 200 } ]) |
支持 “对象数组” 的精准查询(如查询 “订单 id=1 且价格 = 100”
的用户),但性能略低于Object。 |
地理空间类型如下
| 类型 | 说明 | 适用场景与特点 |
|---|---|---|
| geo_point | 存储地理位置坐标(纬度 +
经度,如{ "lat": 39.9042, "lon": 116.4074 }),支持距离查询、范围筛选。 |
存储地理位置点,支持基于距离的查询和排序。 |
| geo_shape | 复杂地理形状,如多边形、线等 | 适合存储区域边界、路径等复杂地理信息,支持空间关系查询。 |
特殊类型如下
| 类型 | 说明 | 适用场景与特点 |
|---|---|---|
| ip | IPv4 或 IPv6 地址,支持 IP 范围查询。 | 存储IP地址,支持范围查询。 |
| completion | 自动补全建议字段,专门用于 “搜索补全” 场景(如输入 “苹果” 时,自动补全 “苹果手机”“苹果电脑”),基于前缀匹配,性能极高。 | 用于实现搜索自动补全功能。 |
| token_count | 统计字符串中词条数量 | 用于分析文本长度或复杂度。 |
| murmur3 | 哈希值字段 | 用于快速哈希计算和索引。 |
| percolator | 存储查询以便反向匹配文档 | 实现基于查询的索引反向匹配。 |
字符串类型
文本类型也就是字符串类型是 ES 中最常用的类型,专门处理字符串,但根据 “是否需要分词” 分为两类,二者不可混用,需根据业务场景选择。
Elasticsearch 5.x 以后,string 类型被拆分为
text 和
keyword,分别满足全文检索和精确匹配需求
| 类型 | 核心说明 | 适用场景 | 关键特性 |
|---|---|---|---|
| Text | 会进行分词处理(将字符串拆分为单个词元,如 “苹果手机” 拆为 “苹果”“手机”),支持全文检索。 | 长文本内容(文章正文、用户评论、商品描述) | 不支持精确匹配和聚合操作(需通过fielddata临时开启,性能差);-
可通过analyzer指定分词器(如 IK 分词器、standard
分词器)。 |
| Keyword | 不进行分词,按完整字符串存储和索引,支持精确匹配、聚合、排序。 | 短文本标识(ID、标签、状态、用户名) | 适合 “精确查询”(如查询状态为 “已支付” 的订单);-
支持doc_values(默认开启,优化聚合 / 排序性能);-
可通过ignore_above设置最大长度(超过部分不索引)。 |
示例:商品数据中,product_name(商品名)用
Text 类型(支持 “搜索手机” 匹配
“苹果手机”),product_id(商品 ID)用 Keyword 类型(支持
“精确查询 ID=12345 的商品”)。
数值类型
根据数值大小和精度选择合适类型:
| 类型 | 说明 | 典型范围/用途 |
|---|---|---|
| byte | 8位整数 | -128 到 127 |
| short | 16位整数 | -32768 到 32767 |
| integer | 32位整数 | -2^31 到 2^31-1 |
| long | 64位整数 | 大整数,如时间戳、ID |
| float | 单精度浮点数 | 金额、评分等带小数数据 |
| double | 双精度浮点数 | 高精度小数 |
| scaled_float | 通过缩放因子存储浮点数 | 节省存储空间,适合定点数存储 |
优先选择 “能覆盖数据范围的最小类型”(如 “年龄” 用 Integer 而非 Long),减少存储和内存占用;
金额类数据建议用
Double(避免Float的精度误差),或按 “分” 存储为Long(如 100 元 = 10000 分,避免小数问题)。
日期类型
ES 不直接存储 “日期字符串”,而是将日期转换为UTC 时间戳(毫秒级整数) 存储,支持多种输入格式,是处理时间相关查询(如 “查询近 7 天订单”)的核心类型。
核心特性:
- 输入格式灵活:支持字符串(如
"2024-05-20"、"2024/05/20 14:30:00")、时间戳(如1716234600000),需在映射(Mapping)中指定format(默认支持strict_date_optional_time,即 “yyyy-MM-dd’T’HH:mm:ss.SSSZ”); - 支持时间运算:可直接用于范围查询(如
range: { create_time: { gte: "now-7d", lte: "now" } },查询近 7 天数据); - 默认开启
doc_values:优化按日期排序、聚合(如 “按天统计订单量”)的性能。
适用场景:
- 时间相关字段(订单创建时间
create_time、日志时间log_time、文章发布时间publish_time)。
示例映射:
1 | { |
索引基本操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
新建索引(PUT请求)
创建索引时可指定分片配置、映射规则等。若不指定映射,ES 会在插入文档时自动推断字段类型(建议手动指定映射,避免类型错误)。
1 | PUT /索引名/类型名/文档id |
创建一个基础索引(默认配置)可以这样的简单写
1 | # 创建名为 "products" 的索引(默认1个主分片,1个副本分片) |
如果需要自定义分片和映射的索引,就需要这样建立,例如
创建一个 “用户索引”,指定:
3 个主分片,2 个副本分片(高可用);
手动定义字段类型(如
username为keyword,age为integer)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15PUT /users
{
"settings": {
"number_of_shards": 3, // 主分片数量(创建后不可修改)
"number_of_replicas": 2 // 副本分片数量(可动态修改)
},
"mappings": {
"properties": {
"username": { "type": "keyword" }, // 用户名(精确匹配)
"age": { "type": "integer" }, // 年龄(数值类型)
"register_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, // 注册时间
"address": { "type": "text", "analyzer": "ik_max_word" } // 地址(中文分词)
}
}
}

那么这些 Json 中的字段都是干什么的,新建索引的时候这些字段应该如何写,规则可用这样总结一下
索引创建的基本结构如下
1 | PUT /{index_name} |
Settings(索引设置)中
静态设置(创建后不可修改)
分片相关
1
2
3
4
5
6
7
8{
"settings": {
"number_of_shards": 3, // 主分片数,默认1
"number_of_routing_shards": 30, // 路由分片数,用于后续拆分
"shard_check_on_startup": false, // 启动时分片检查
"codec": "default" // 压缩算法:default, best_compression
}
}索引基础设置
1
2
3
4
5
6
7
8{
"settings": {
"index.uuid": "abc123", // 索引唯一ID(自动生成)
"index.version.created": 8010099, // 创建版本(自动)
"index.creation_date": "1640995200000", // 创建时间戳(自动)
"index.provided_name": "my_index" // 提供的名称
}
}
动态设置(创建后可修改)
缓存和合并相关:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19{
"settings": {
"number_of_replicas": 1, // 副本分片数,默认1
"auto_expand_replicas": "0-1", // 自动扩展副本
"refresh_interval": "1s", // 刷新间隔:1s, 30s, -1(禁用)
"max_result_window": 10000, // 最大结果窗口
"max_inner_result_window": 100, // 内层查询最大结果
"max_rescore_window": 10000, // 重评分窗口
"max_docvalue_fields_search": 100, // 最大docvalue字段数
"max_script_fields": 32, // 最大script字段数
"max_ngram_diff": 1, // NGram最大差异
"max_shingle_diff": 3, // Shingle最大差异
"blocks.read_only": false, // 只读块
"blocks.read_only_allow_delete": false, // 允许删除的只读
"blocks.read": false, // 读块
"blocks.write": false, // 写块
"blocks.metadata": false // 元数据块
}
}缓存和合并相关:
1
2
3
4
5
6
7
8
9
10
11
12{
"settings": {
"max_refresh_listeners": 1000, // 最大刷新监听器
"analyze.max_token_count": 10000, // 分析最大token数
"highlight.max_analyzed_offset": 1000000, // 高亮最大分析偏移
"max_terms_count": 65536, // 最大terms数
"max_regex_length": 1000, // 最大正则长度
"routing.allocation.enable": "all", // 路由分配:all, primaries, new_primaries, none
"routing.rebalance.enable": "all", // 重新平衡:all, primaries, replicas, none
"gc_deletes": "60s" // 删除保留时间
}
}
Mappings(字段映射)中
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
那么 Mappings(字段映射)中 的索引创建的 JSON 如下
元字段(Meta Fields)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"mappings": {
"_source": { // 存储原始文档
"enabled": true,
"includes": ["field1", "field2"], // 包含字段
"excludes": ["sensitive_field"] // 排除字段
},
"_routing": { // 路由字段
"required": false
},
"_meta": { // 自定义元数据
"app_version": "1.0",
"created_by": "admin"
},
"dynamic": "true" // 动态映射:true, false, strict
}
}属性字段(Properties)
核心数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28{
"mappings": {
"properties": {
"title": {
"type": "text", // 全文文本
"analyzer": "ik_max_word", // 索引分词器
"search_analyzer": "ik_smart", // 搜索分词器
"fields": { // 多字段
"keyword": {
"type": "keyword", // 精确值
"ignore_above": 256 // 忽略长度
},
"english": {
"type": "text",
"analyzer": "english"
}
}
},
"content": {
"type": "text",
"index": true, // 是否索引:true, false
"store": false, // 是否单独存储
"norms": true, // 评分因子
"index_options": "positions" // 索引选项:docs, freqs, positions, offsets
}
}
}
}数值类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
"properties": {
"price": {
"type": "float", // 浮点:float, double
"scaling_factor": 100 // 缩放因子
},
"quantity": {
"type": "integer", // 整数:byte, short, integer, long
"coerce": true // 类型转换
},
"percentage": {
"type": "scaled_float", // 缩放浮点
"scaling_factor": 100
}
}
}日期和布尔:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24{
"properties": {
"author": {
"type": "object", // 对象
"properties": {
"name": {"type": "text"},
"age": {"type": "integer"}
}
},
"tags": {
"type": "nested", // 嵌套对象
"properties": {
"name": {"type": "keyword"},
"value": {"type": "text"}
}
},
"locations": {
"type": "geo_point" // 地理点
},
"area": {
"type": "geo_shape" // 地理形状
}
}
}复杂类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24{
"properties": {
"author": {
"type": "object", // 对象
"properties": {
"name": {"type": "text"},
"age": {"type": "integer"}
}
},
"tags": {
"type": "nested", // 嵌套对象
"properties": {
"name": {"type": "keyword"},
"value": {"type": "text"}
}
},
"locations": {
"type": "geo_point" // 地理点
},
"area": {
"type": "geo_shape" // 地理形状
}
}
}特殊类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
"properties": {
"ip_address": {
"type": "ip" // IP地址
},
"version": {
"type": "version" // 版本号
},
"json_data": {
"type": "flattened" // 扁平化JSON
},
"user_agent": {
"type": "wildcard" // 通配符查询优化
}
}
}
其中,字段命名规则如下
- 不能包含:
.,.. - 不能以
_,+,-开头 - 不能超过 255 字节
类型选择原则差不多就是这样
- 精确匹配:
keyword - 全文搜索:
text+keyword多字段 - 数值范围:选择最小够用类型
- 日期:明确指定格式
- 对象数组:考虑使用
nested
查看索引(GET 请求)
GET /索引名/类型/id/,通过GET
索引名的方式可以查看索引的信息
查询的时候加上文档类型和id可以看到文档的详细信息
查看单个索引详情
1 | # 查看 "users" 索引的配置和映射 |
响应包含settings(分片配置)和mappings(字段规则)等信息。
查看多个索引
1 | # 查看 "users" 和 "products" 索引 |

仅查看所有索引的名字
1 | # 仅显示所有索引的名字(一行一个索引名) |
- 参数
h=index表示只返回index列(即索引名),过滤其他信息(如状态、大小等)。
查看所有索引
1 | # 通配符 "*" 表示所有索引 |
查看集群健康状况
1 | GET _cat/health |

查看集群信息
1 | GET _cat/indices?v |
修改索引(PUT)
注意:主分片数量(number_of_shards)创建后不可修改,仅可修改副本分片数量等可动态调整的配置。
在 Elasticsearch 中,修改索引的字段名(即修改映射中的字段名称)无法直接实现,因为映射一旦创建,字段的名称和类型属于 “刚性结构”,不能直接重命名。
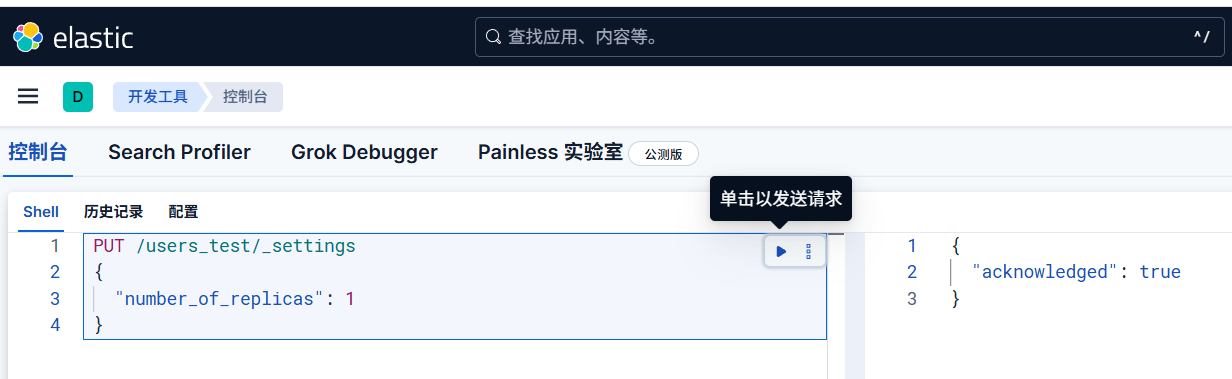
例如,修改副本分片数量
将 “users” 索引的副本分片从 2 个改为 1 个(减少存储占用):
1 | PUT /users/_settings |
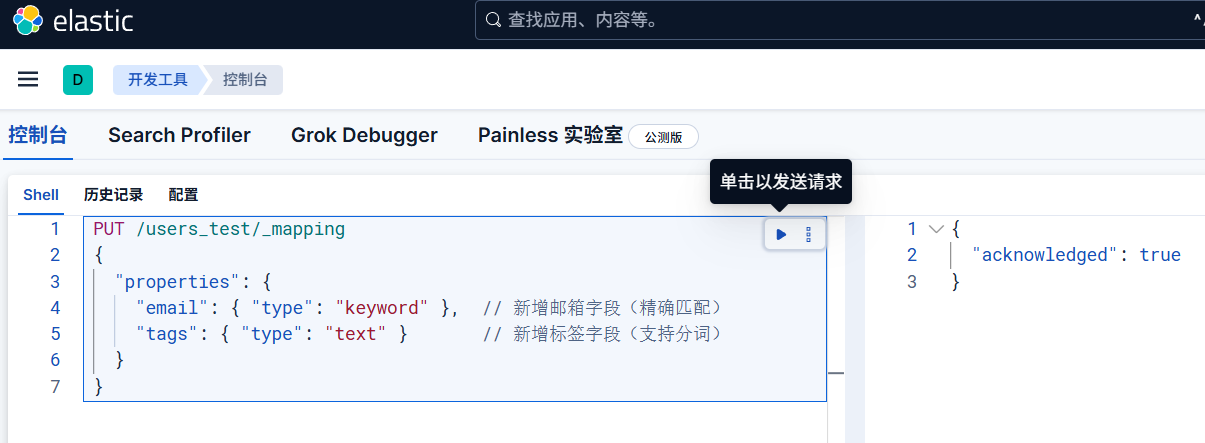
修改一下映射看看
但是注意已创建的索引可以新增字段,但不能直接修改已有字段的类型(若需修改,需重建索引)。
1 | PUT /users/_mapping |
删除索引(DELETE)
删除索引会永久删除所有数据,操作需谨慎!
所以我就不真实演示了
示例:删除 “products” 索引
1 | DELETE /products |
示例:删除多个索引
1 | # 删除 "test1" 和 "test2" 索引 |
禁止通配符删除(安全配置)
为避免误删所有索引,可在elasticsearch.yml中配置:
1 | action.destructive_requires_name: true # 禁止使用通配符 "*" 删除所有索引 |
索引别名操作
索引别名(Alias)是给索引起的 “别名”,可实现:
- 隐藏真实索引名,方便后续索引重建(如从
users_v1迁移到users_v2,别名users不变); - 关联多个索引(如用
logs_2024关联logs_2024_01到logs_2024_12)。
给索引添加别名
1 | # 给 "users" 索引添加别名 "user_index" |
替换别名(从旧索引迁移到新索引用的多)
1 | # 先删除别名与旧索引的关联,再关联新索引(原子操作,无 downtime) |
查看别名关联的索引
1 | GET /_alias/user_index # 查看 "user_index" 别名关联的索引 |
关闭 / 打开索引
暂时不需要的索引可关闭(释放资源,不占用内存),需要时再打开。
关闭索引
1 | POST /users/_close |
打开索引
1 | POST /users/_open |
总结一下常见操作场景
| 操作需求 | 命令示例 |
|---|---|
| 创建带映射的索引 | PUT /index_name { "settings": {...}, "mappings": {...} } |
| 查看索引配置 | GET /index_name |
| 调整副本分片数量 | PUT /index_name/_settings { "number_of_replicas": 1 } |
| 新增字段映射 | PUT /index_name/_mapping { "properties": { "new_field": {...} } } |
| 删除索引 | DELETE /index_name |
| 给索引添加别名 | POST /_aliases { "actions": [ { "add": {...} } ] } |
索引库的CRUD简单描述:
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库(添加字段):PUT /索引库名/_mapping






