RabbitMQ 的可靠性
RabbitMQ 的可靠性核心目标是
“确保消息不丢失、不重复消费,最终被正确处理”。其中,避免重复消费是可靠性的关键环节
——
即使因网络波动、系统故障等导致消息被重复投递,业务结果也需保持一致。
避免重复消费就是保证消息就算被重复发送也只被消费一次,这就是我们下面要讲的消息幂等性。
举个例子,我们在购物的时候,已经支付完成,但是消息没有正确的被消费,前端发送请求查询支付状态时,肯定是查询交易服务状态,会发现业务订单未支付,而用户自己知道已经支付成功,这就导致用户体验不一致。
生产者可靠性
生产者重试机制,通过在配置文件中添加相关配置打开重试机制
1
2
3
4
5
6
7
8
9
10
| spring:
rabbitmq:
connection-timeout: 1s
template:
retry:
enabled: true
initial-interval: 1000ms
multiplier: 1
max-attempts: 3
|
分布式系统的网络不稳定的话,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
生产者的重试机制可能会导致消息被重复发送,生产者发送消息后,因网络波动未收到
RabbitMQ 的确认(Publisher
Confirm),误认为消息未发送成功,触发重试机制,导致同一消息被多次发送到队列。
所以也会有一个生产者确认机制,确保 RabbitMQ
成功接收消息后,生产者才停止重试。
生产者发送消息后,RabbitMQ 在
成功接收并处理消息(如持久化到磁盘、路由到队列)后,会向生产者返回一个
确认信号(acknowledgement)。
- 若生产者收到确认信号:说明消息已被 RabbitMQ 接收,无需重试;
- 若未收到确认信号(或收到否定确认):说明消息未被正确处理,生产者可根据原因决定是否重试。
但是,生产者确认机制对性能影响较大,无特殊需要不要开启,而且一般情况下,只要生产者与MQ之间的网路连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。
RabbitMQ 的 生产者消息确认机制 包含
Publisher Confirm(发布确认) 和 Publisher
Return(发布回退) 两个核心子机制
| 机制 |
触发阶段 |
核心作用 |
反馈结果类型 |
| Publisher Confirm |
消息到达 MQ 后的 最终处理 |
告知生产者 “消息是否被 MQ 成功接收并稳定存储” |
成功(ACK) / 失败(NACK) |
| Publisher Return |
消息到达交换机,但 路由失败 |
告知生产者 “消息已到交换机,但未找到匹配队列” |
仅失败回退(含失败原因) |
所以会存在如下四种结果
消息成功到达交换机,但因路由规则不匹配(如路由键错误、队列未绑定),无法投递到任何队列,此时触发
Return 回退,同时 Confirm 返回 ACK。
- 为什么路由失败还返回 ACK? 因为
Confirm 的核心是 “确认
MQ 是否接收消息”,而非 “消息是否最终入队”。消息到达交换机即视为 MQ
已接收,路由失败是后续的业务配置问题,不影响 Confirm 的 ACK
反馈。
- 如何处理这种情况? 需在
Return
回调中记录日志,人工排查路由配置(如补充队列绑定),不建议重试(路由键错误属于永久故障,重试仍会失败)。
临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功。也就是消息为非持久化(deliveryMode=1),成功到达交换机并路由到队列,MQ
仅将消息存入内存(不写磁盘),此时 Confirm 返回
ACK,Return 不触发。
- 临时消息若 MQ 重启,内存中的消息会丢失,但
Confirm
已返回 ACK,生产者会误认为消息安全。
持久消息(deliveryMode=2)投递到
MQ,入队并完成持久化,此时 Confirm 返回
ACK,Return 不触发。
- 持久消息的 ACK 条件需同时满足 “入队成功 +
持久化完成”,确保消息不会因 MQ 重启丢失;
- 持久化会增加磁盘 I/O 开销,吞吐量低于临时消息
可能存在其它情况,消息未被 MQ 成功接收或稳定存储,此时
Confirm 返回
NACK(ack=false),Return
不触发(因消息未到达交换机,无路由环节),常见情况包括
| 失败场景 |
具体流程 |
| 交换机不存在 |
生产者指定不存在的交换机 exchange-not-exist → MQ
接收消息后检查交换机不存在 → Confirm 返回
NACK,cause 为 “NOT_FOUND” |
| 网络波动导致消息丢失 |
生产者发送消息后,网络中断 → 消息未到达 MQ → MQ 无反馈,生产者超时后
Confirm 返回 NACK,cause 为 “Connection
reset” |
| MQ 磁盘满(持久化失败) |
持久消息入队后,MQ 尝试持久化但磁盘满 → 无法完成持久化 →
Confirm 返回 NACK,cause 为 “disk full” |
- NACK 的核心含义:“MQ
未成功接收消息,或无法稳定存储消息”,生产者需根据
cause
判断是否重试;
- 一般我们这样配置重试策略,仅对
临时故障(如网络波动、MQ
临时过载)重试,且限制重试次数(如 3 次);对
永久故障(如交换机不存在、磁盘满)直接记录日志,人工介入。
默认两种机制都是关闭状态,需要通过配置文件来开启。
1
2
3
4
| spring:
rabbitmq:
publisher-confirm-type: correlated
publisher-returns: true
|
Spring AMQP 中通过
spring.rabbitmq.publisher-confirm-type
配置确认模式,支持三种类型:
| 模式 |
说明 |
|
NONE |
关闭确认机制(默认值) |
|
CORRELATED |
异步回调确认:消息发送后,RabbitMQ 处理完成后触发回调方法 |
|
SIMPLE |
同步确认:发送消息后阻塞等待确认,或批量确认(性能较差) |
|
CORRELATED
模式是首选,通过回调函数异步处理确认结果,不阻塞主线程,性能要好一些。
配置 RabbitMQ 配置,初始化交换机,队列和回调策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitConfig {
@Bean
public DirectExchange businessExchange() {
return ExchangeBuilder.directExchange("business.exchange")
.durable(true)
.build();
}
@Bean
public Queue businessQueue() {
return QueueBuilder.durable("business.queue")
.build();
}
@Bean
public Binding businessBinding(DirectExchange businessExchange, Queue businessQueue) {
return BindingBuilder.bind(businessQueue)
.to(businessExchange)
.with("business.key");
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (correlationData == null) {
return;
}
String messageId = correlationData.getId();
if (ack) {
System.out.println("[Confirm] 消息处理成功:" + messageId);
} else {
System.err.println("[Confirm] 消息处理失败:" + messageId + ",原因:" + cause);
recordFailedMessage(messageId, cause);
}
});
rabbitTemplate.setReturnsCallback(returnedMessage -> {
String messageId = returnedMessage.getMessage().getMessageProperties().getMessageId();
System.err.println("[Return] 消息路由失败:" +
"消息ID=" + messageId +
",交换机=" + returnedMessage.getExchange() +
",路由键=" + returnedMessage.getRoutingKey() +
",原因=" + returnedMessage.getReplyText());
recordRoutingError(messageId, returnedMessage);
});
rabbitTemplate.setMandatory(true);
return rabbitTemplate;
}
private void recordFailedMessage(String messageId, String cause) {
System.err.println("【失败记录】消息ID=" + messageId + ",原因=" + cause);
}
private void recordRoutingError(String messageId, ReturnedMessage returnedMessage) {
System.err.println("【路由错误记录】消息ID=" + messageId + ",详情=" + returnedMessage);
}
}
|
MQ的可靠性
MQ的可靠性我们一般从数据的持久化入手,在控制台的Exchanges页面,添加交换机时可以配置交换机的Durability参数,设置为Durable就是持久化模式,Transient就是临时模式。
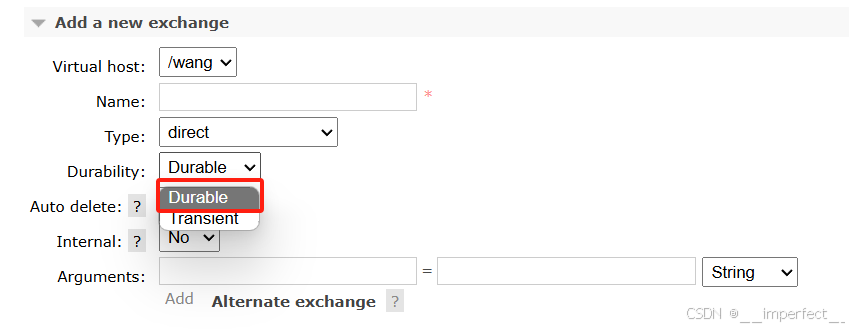 image-20250919165538605
image-20250919165538605
在控制台的Queues页面,添加队列时,同样可以配置队列的Durability参数
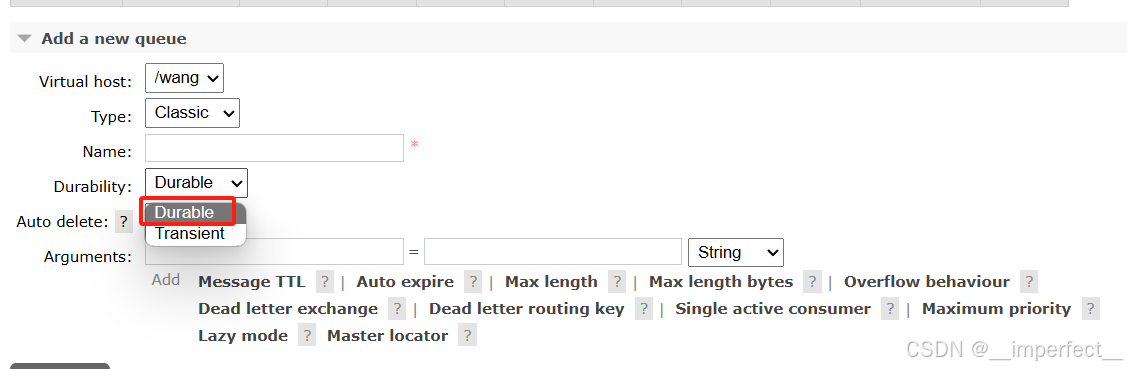 image-20250919165546810
image-20250919165546810
消费者可靠性
消费者确认机制
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制,当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
一般reject方式用的较少,除非是消息格式有问题。因此大多数情况下我们需要将消息处理的代码通过try catch机制捕获,消息处理成功时返回ack,处理失败时返回nack
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
| 模式 |
核心逻辑 |
适用场景 |
AUTO(默认) |
Spring 自动根据业务代码是否抛出异常决定 ACK 类型: 无异常:自动发送
ack(删除消息) 如果是业务异常:自动发送
nack(重新入队,或进入死信队列)
如果是消息处理或校验异常,自动返回reject; |
大多数场景,无需手动处理 ACK,简化代码 |
MANUAL(手动) |
完全由开发者控制 ACK 发送:需通过 Channel 对象手动调用
basicAck/basicNack,否则消息会一直处于
Unacked 状态 |
复杂业务场景(如需批量确认、根据业务结果动态决定是否重入队) |
NONE(无确认) |
消费者不发送任何 ACK 回执,RabbitMQ 认为消息
“被投递即成功处理”,直接删除消息 |
对消息可靠性要求极低的场景(如日志收集),不推荐用于核心业务 |
AUTO 模式是 Spring AMQP 的默认配置,核心是
“业务无异常则 ACK,有异常则 NACK”,无需手动操作
Channel,适合大多数简单业务。
1
2
3
4
5
6
7
8
9
10
| spring:
rabbitmq:
listener:
simple:
acknowledge-mode: AUTO
prefetch: 1
retry:
enabled: true
max-attempts: 3
initial-interval: 2000
|
而业务代码无需关注 ACK 逻辑,只需专注业务处理,异常会自动触发
NACK:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Component
public class AutoAckConsumer {
@RabbitListener(queues = "business.queue")
public void processMessage(String message) {
try {
System.out.println("收到消息:" + message);
doBusiness(message);
} catch (RuntimeException e) {
System.err.println("消息处理失败,触发重试:" + e.getMessage());
throw e;
} catch (){
System.err.println("消息处理失败,触发重试:" + e.getMessage());
throw new MessageConversionException("故意的");
}
}
private void doBusiness(String message) {
if (message.contains("error")) {
throw new RuntimeException("业务处理异常:包含非法内容");
}
System.out.println("业务处理成功:" + message);
}
}
|
- 重试与 NACK 的关系:
AUTO
模式下,业务抛出异常后,Spring
会先触发重试机制(若开启),重试耗尽仍失败则发送 nack
并拒绝重入队,这就代表需提前配置死信队列,否则消息会被丢弃;
- 异常捕获注意:若手动捕获异常且不重新抛出,Spring
会认为处理成功并发送
ack,导致失败消息被误删,因此
必须抛出异常 才能触发 NACK。
MANUAL 模式下,开发者需通过 Channel
对象手动调用 ACK 方法,适合需要 “精细控制消息状态”
的场景(如批量确认、根据业务结果动态决定是否重入队)。
1
2
3
4
5
6
| spring:
rabbitmq:
listener:
simple:
acknowledge-mode: MANUAL
prefetch: 5
|
消息消费者的业务代码需通过
@Header(AmqpHeaders.DELIVERY_TAG) 获取消息的
deliveryTag(RabbitMQ 分配的消息唯一标识),再调用
Channel 方法发送 ACK/NACK:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| @Component
public class ManualAckConsumer {
@RabbitListener(queues = "business.queue")
public void processMessage(
Message message, // 消息对象(含消息体、消息头)
Channel channel, // RabbitMQ 原生 Channel 对象
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag // 消息唯一标识
) throws IOException {
String msgContent = new String(message.getBody());
try {
boolean isSuccess = doBusinessWithResult(msgContent);
if (isSuccess) {
channel.basicAck(deliveryTag, false);
System.out.println("手动 ACK 成功:" + msgContent);
} else {
channel.basicNack(deliveryTag, false, true);
System.out.println("手动 NACK 并重新入队:" + msgContent);
}
} catch (Exception e) {
channel.basicNack(deliveryTag, false, false);
System.err.println("手动 NACK 并拒绝入队:" + msgContent + ",原因:" + e.getMessage());
}
}
private boolean doBusinessWithResult(String message) {
return !message.contains("retry");
}
}
|
basicAck(deliveryTag, multiple)
deliveryTag:当前消息的唯一标识(从消息头获取);multiple:true 表示
“确认当前及之前所有未确认的消息”(批量确认),false 表示
“仅确认当前消息”。
basicNack(deliveryTag, multiple, requeue)
requeue:true 表示
“消息重新入队”(可重试),false 表示
“消息拒绝入队”(需配置死信队列,否则消息被删除)。
basicReject(deliveryTag, requeue)
- 功能与
basicNack
类似,但不支持批量操作(multiple
参数),仅能拒绝单条消息,实际使用中 basicNack
更灵活。
注意,无论是 AUTO 还是 MANUAL
模式,当消息处理失败需要重试时,需注意 “避免无限重试”——
重试耗尽后应将消息转入死信队列(DLQ),而非反复重入队占用资源,关于这部分在下面消费者重连机制进行说明
消费者的重试机制
在未开启本地重试时,若消费者处理消息失败,如抛出异常,会触发 RabbitMQ
的 nack
机制,消息会被重新入队(requeue),然后再次投递到消费者。如果消费者始终处理失败,消息会陷入
“失败 → 重入队 → 再投递 → 再失败”
的无限循环,这会导致很严重的性能问题
针对消费者的重试机制通过限制重试的次数和本地处理,避免了这种无限循环,同时给消息处理失败一个补救机会
Spring AMQP 通过 spring.rabbitmq.listener.simple.retry
配置本地重试
1
2
3
4
5
6
7
8
9
10
| spring:
rabbitmq:
listener:
simple:
retry:
enabled: true
initial-interval: 1000ms
multiplier: 1
max-attempts: 3
stateless: true
|
当开启本地重试后,消息处理的完整流程如下(以
max-attempts=3 为例):
- 首次处理:消费者接收到消息,执行业务逻辑;
- 若成功(无异常):正常返回
ack,消息被 MQ 删除;
- 若失败(抛异常):不回退消息到 MQ,进入本地重试流程。
- 第一次重试:等待
initial-interval(1
秒)后,重新执行业务逻辑;
- 若成功:返回
ack,消息删除;
- 若失败:继续等待(间隔 = initial-interval ×
multiplier),准备第二次重试。
- 第二次重试:等待指定间隔后再次执行;
- 若成功:返回
ack;
- 若失败:重试次数耗尽(已达
max-attempts=3),进入最终处理。
- 重试耗尽后:Spring AMQP 会自动抛出
AmqpRejectAndDontRequeueException 异常
重试耗尽了消息一定就要被删除吗?我看未必,实际上也是配置死信队列,重试耗尽后,可以让
Spring 返回 nack 而非 reject,并指定
requeue=false,消息会自动路由到死信队列。
1
2
3
4
5
6
7
8
9
10
| @RabbitListener(queues = "business.queue")
public void processMessage(String message) {
try {
doBusiness(message);
} catch (Exception e) {
throw new AmqpRejectAndDontRequeueException("重试耗尽,路由到死信队列", e);
}
}
|
默认情况下,所有未捕获的异常都会触发重试,但可通过
RetryTemplate 自定义 “可重试异常” 和 “不可重试异常”:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
RetryTemplate retryTemplate = new RetryTemplate();
retryTemplate.setRetryPolicy(new SimpleRetryPolicy(3,
Collections.singletonMap(NetworkException.class, true),
false));
factory.setRetryTemplate(retryTemplate);
return factory;
}
|
消费者重连机制
当消费者与 RabbitMQ 服务器的连接因网络波动、MQ
服务重启、连接超时等原因中断时,消费者能自动尝试重新建立连接并恢复消息消费,避免因连接中断导致的消费停滞。
Spring AMQP(基于 Spring 生态的 RabbitMQ
客户端封装)已经内置了成熟的消费者重连机制,无需开发者手动编写复杂的重连逻辑,只需理解其核心原理、默认配置及自定义优化方式即可。当消费者与
MQ
的连接中断,通常由以下「非预期故障」触发,此时重连机制会自动生效。
Spring AMQP 的重连能力依赖于其底层的
RabbitConnectionFactory(连接工厂)和
SimpleMessageListenerContainer(消息监听容器,消费者核心组件),核心逻辑如下:
- 连接状态监听:
SimpleMessageListenerContainer
会持续监控与 MQ 的连接 /
通道状态,一旦检测到「连接断开」「通道关闭」等异常(如
IOException、ConnectionShutdownException),立即触发重连流程;
- 重连任务调度:连接中断后,容器会通过
定时任务(ScheduledExecutorService)
周期性尝试重新创建连接;
- 连接重建与消费恢复
- 若重连成功(成功创建
Connection 和
Channel),容器会自动重新声明队列、交换机、绑定关系(若配置了
declarables),并恢复消息监听(从队列头部或上次消费位置继续拉取消息);
- 若重连失败,容器会按照「重试间隔」继续重试,直到连接恢复或手动停止。
Spring AMQP
的重连机制默认是开启状态,且提供了合理的默认参数,大多数场景下无需修改即可满足需求。核心默认配置如下:
| 配置项 |
默认值 |
作用说明 |
| 重连开启状态 |
自动开启 |
无需手动配置,连接中断后自动触发重连 |
| 初始重连间隔 |
1000ms(1 秒) |
第一次重连失败后,等待 1 秒再尝试第二次重连 |
| 最大重连间隔 |
30000ms(30 秒) |
重连间隔会逐渐递增(避免频繁重试占用资源),最终稳定在 30
秒一次 |
| 重连重试次数 |
无限次 |
除非手动停止消费者或 MQ
永久不可用,否则会一直重试(保障最大程度的恢复能力) |
| 通道恢复机制 |
自动恢复 |
若仅通道(Channel)断开(连接未断),会自动重建通道,无需重新建立连接 |
配置文件配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
virtual-host: /
listener:
simple:
retry:
enabled: true
recovery-interval: 2000ms
container-type: simple
connection-timeout: 5000ms
connection-factory:
cache:
channel:
size: 5
connection:
size: 2
requested-heartbeat: 30s
|
失败处理策略
在消息发送本地测试达到最大重试次数后,消息会被丢弃。这在某些对于消息可靠性要求较高的业务场景下,显然不太合适了。
因此 Spring
允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- 重试次数用完后,该实现会返回
requeue=true
的指令,RabbitMQ
会将消息重新加入原队列尾部,等待下一次被消费者拉取处理。相当于无限重试
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
这是生产环境最常用的策略:重试耗尽后,将消息转发到死信队列(DLQ),而非直接丢弃。
它的原理比较复杂,消息重试耗尽后,DeadLetterPublishingRecoverer
会读取原队列的死信交换机(DLX),然后将失败消息封装为「死信消息」,并添加额外的死信属性(x-death),再通过
DLX 将死信消息路由到绑定的 DLQ 中。
这种情况下需要创建并且配置死信交换机、死信队列及各种绑定,然后配置DeadLetterPublishingRecoverer
示例的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| @Configuration
public class RabbitRecoveryConfig {
@Autowired
private AmqpTemplate amqpTemplate;
@Bean
public MessageRecovery messageRecovery() {
return new DeadLetterPublishingRecoverer(amqpTemplate,
(message, cause) -> {
return new DeadLetterPublishingRecoverer.Destination(
"dlx.exchange", "dlx.routing.key");
});
}
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setRetryTemplate(retryTemplate());
factory.setMessageRecovery(messageRecovery());
return factory;
}
private RetryTemplate retryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1000);
retryTemplate.setBackOffPolicy(backOffPolicy);
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(3);
retryTemplate.setRetryPolicy(retryPolicy);
return retryTemplate;
}
}
|
消息幂等性
什么是消息幂等性
在分布式系统中,消息的可靠传输是一项重要的任务,而 RabbitMQ
作为常用的消息中间件,消息幂等性是保证消息可靠处理的关键特性之一。
消息幂等性指的是,无论一条消息被重复处理多少次,最终的业务结果都应该是一致的,就好像这条消息只被处理了一次一样。对消息来说,就是“不管这条消息被消费多少次,业务结果都不会重复”。
比如,在电商系统中,支付消息如果不保证幂等性,当消息重复消费时,可能导致用户被重复扣款;而保证幂等性后,即使消息多次被消费,用户也只会被扣款一次。
在使用 RabbitMQ 过程中,消息重复的情况可能在以下场景中出现:
- 生产者消息确认机制问题:生产者发送消息后,由于网络波动等原因,没有及时收到
RabbitMQ 发送的确认应答,生产者会认为消息发送失败而进行重发,但实际上
RabbitMQ 可能已经接收到了消息,这就导致消息重复。
- 消费者消息确认机制问题:消费者从 RabbitMQ
获取消息并处理完成后,在发送确认消息给 RabbitMQ
的过程中,网络出现故障,RabbitMQ
没有收到确认,就会认为消息没有被成功消费,当消费者重新连接时,RabbitMQ
会再次推送该消息,造成消息重复消费。
- RabbitMQ 集群故障:在 RabbitMQ
集群环境下,当节点发生故障转移时,可能会导致部分消息的状态记录不准确,进而引发消息的重复发送或消费。
所以,消息幂等是分布式系统的“底线要求”,尤其是涉及写操作的场景。
RabbitMQ的ACK机制和持久化(durable)能保证消息“不丢失”,但无法直接解决重复消费。比如:
- 消费者处理消息时抛异常,RabbitMQ会把消息重新放回队列,下次消费者可能再次拉取到它;
- 生产者发送消息时因网络问题重试,导致Broker收到多条相同消息(虽然概率低,但必须防)。
四种幂等性解决方案
保证消息不被重复消费一定会有一定的决策。
利用重试机制
MQ 消费者的幂等性问题,主要在于 MQ
的重试机制,因为网络原因或客户端延迟消费导致重复消费。
因为可能会出现如下的情况,消费者在消费 MQ 中的消息时,MQ
已把消息发送给消费者,消费者在给 MQ 返回 ack 时网络中断,故 MQ
未收到确认信息,该条消息会重新发给其他的消费者,或者在网络重连后再次发送给该消费者,但实际上该消费者已成功消费了该条消息,造成消费者消费了重复的消息
在 RabbitMQ
消息处理中,重试机制用于应对临时故障(如网络波动、依赖服务短暂不可用),确保消息最终能被成功处理;
所以什么时候需要重试呢?
- 消费者获取到消息后,调用第三方接口,但接口暂时无法访问,是否需要重试?
需要重试
- 消费者获取到消息后,抛出数据转换异常,是否需要重试?
不需要,因为重试也没用
Spring AMQP 提供了成熟的重试机制,可通过 RetryTemplate
配置消费者重试(处理消费阶段的异常)和生产者重试(处理发送阶段的异常),一般重试都是消费者重试
首先,通过 application.yml 或 Java
配置类开启并定制重试策略:
1
2
3
4
5
6
7
8
9
10
11
| spring:
rabbitmq:
listener:
simple:
retry:
enabled: true
max-attempts: 3
initial-interval: 1000
multiplier: 2
max-interval: 5000
acknowledge-mode: AUTO
|
- 参数说明
max-attempts: 3:消息最多被处理 3 次(1 次正常消费 + 2
次重试)。initial-interval: 1000:首次失败后,1 秒后重试。multiplier: 2:第二次重试间隔为 1000*2=2000
毫秒,第三次为 4000 毫秒(不超过 max-interval)。
当重试达到最大次数后仍失败,需指定
“最终处理策略”(默认将消息丢弃,不推荐)。通常有两种方案:
- 方案
1:将消息转发到死信队列(DLQ),后续人工干预。
- 方案
2:记录日志并手动确认消息(避免消息无限重试)。
配置死信队列示例(重试耗尽后进入死信队列):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @Configuration
public class RetryDeadLetterConfig {
@Bean
public DirectExchange dlqExchange() {
return ExchangeBuilder.directExchange("retry.dlq.exchange").durable(true).build();
}
@Bean
public Queue dlqQueue() {
return QueueBuilder.durable("retry.dlq.queue").build();
}
@Bean
public Binding dlqBinding() {
return BindingBuilder.bind(dlqQueue()).to(dlqExchange()).with("retry.dlq.key");
}
@Bean
public Queue businessQueue() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "retry.dlq.exchange");
args.put("x-dead-letter-routing-key", "retry.dlq.key");
return QueueBuilder.durable("retry.business.queue")
.withArguments(args)
.build();
}
}
|
那么上述都是针对重试的操作,那么到底,如何保证消息幂等性,不被重复消费?
这个问题也算是 MQ 面试当中经常考察的一点,因为无论是什么 MQ
都会有这个问题。
这个就需要结合我们接下来提到的策略了。
利用全局唯一 ID
原理:为每条消息生成一个全局唯一的 ID,例如使用 UUID
或者业务系统中具有唯一性的业务单号(如订单号)。在消费者处理消息之前,先根据这个唯一
ID 去查询本地的处理记录(可以存储在数据库、缓存如 Redis
中),如果已经存在处理记录,说明该消息已经被处理过,直接跳过;如果不存在,则进行业务处理,并将处理记录保存到本地。
那么实现思路也很清晰了
- 生产者给每条消息打一个 “全局唯一
ID”(类似身份证),随消息一起发送;
- 消费者收到消息后,先查 “这个 ID 是否已处理过”(用 Redis
记录处理状态);
- 若已处理:直接跳过业务逻辑,避免重复执行;
- 若未处理:执行业务逻辑 → 成功后标记 “ID 已处理” →
失败则抛异常触发重试。
示例:
生产者,发送了带唯一ID的消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import org.springframework.amqp.core.MessagePostProcessor;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.UUID;
@Component
public class IdempotentProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage(String content) {
String messageId = UUID.randomUUID().toString();
MessagePostProcessor postProcessor = message -> {
message.getMessageProperties().setMessageId(messageId);
return message;
};
rabbitTemplate.convertAndSend(
"retry.business.exchange",
"retry.business.key",
content,
postProcessor
);
System.out.println("发送消息,ID:" + messageId + ",内容:" + content);
}
}
|
消费者:结合重试与幂等性处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
@Component
public class IdempotentConsumer {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@RabbitListener(queues = "retry.business.queue")
public void processMessage(Message message) {
String messageId = message.getMessageProperties().getMessageId();
String content = new String(message.getBody());
System.out.println("收到消息,ID:" + messageId + ",内容:" + content);
String redisKey = "processed:" + messageId;
Boolean isProcessed = redisTemplate.hasKey(redisKey);
if (Boolean.TRUE.equals(isProcessed)) {
System.out.println("消息已处理,ID:" + messageId);
return;
}
try {
doBusiness(content);
redisTemplate.opsForValue().set(redisKey, "1", 24, TimeUnit.HOURS);
System.out.println("消息处理成功,ID:" + messageId);
} catch (Exception e) {
System.err.println("消息处理失败,触发重试,ID:" + messageId + ",原因:" + e.getMessage());
throw e;
}
}
private void doBusiness(String content) throws Exception {
if (Math.random() < 0.5) {
throw new Exception("临时故障:依赖服务不可用");
}
System.out.println("执行业务逻辑:" + content);
}
}
|
为什么使用 Redis 呢?因为 Redis
是分布式缓存,支持高并发读写,且hasKey/set操作是单线程执行的(Redis
单线程模型),可避免
“并发重复处理”(如两个消费者同时处理同一条消息)。
数据库唯一约束
利用数据库的唯一索引,让重复消息的写操作直接报错,从而避免重复数据。
这种方案适合基于业务唯一标识(如订单号、支付流水号)的场景,无需额外维护版本号或状态标记。
- 唯一约束设计:在业务表中对 “业务唯一标识”(如订单号
order_no)创建唯一索引,确保同一标识的记录只能插入一次。
- 消息处理逻辑
- 消费者收到消息后,尝试向数据库插入或更新含该唯一标识的记录;
- 若成功:说明是首次处理,正常执行业务;
- 若触发唯一约束异常(如
DuplicateKeyException):说明是重复消息,直接忽略。
那么数据库表的设计如下
1
2
3
4
5
6
7
8
9
10
11
|
CREATE TABLE `t_payment` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',
`order_no` varchar(64) NOT NULL COMMENT '订单编号(唯一)',
`pay_amount` decimal(10,2) NOT NULL COMMENT '支付金额',
`pay_time` datetime NOT NULL COMMENT '支付时间',
`pay_status` tinyint NOT NULL COMMENT '支付状态(1:成功)',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`) COMMENT '订单编号唯一约束'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='支付记录表';
|
实体类忽略,生产者就是正常发送消息,也忽略了,消费者处理有一些不同,主要是尝试插入记录,通过捕获唯一约束异常判断是否为重复消息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| @Component
public class PaymentConsumer {
@Autowired
private PaymentMapper paymentMapper;
@RabbitListener(queues = "payment.success.queue")
public void handlePaymentSuccess(Message message) {
String orderNo = new String(message.getBody());
String messageId = message.getMessageProperties().getMessageId();
System.out.println("收到支付消息:消息ID=" + messageId + ",订单编号=" + orderNo);
Payment existing = paymentMapper.selectByOrderNo(orderNo);
if (existing != null) {
System.out.println("订单已支付(查询命中):" + orderNo);
return;
}
Payment payment = new Payment();
payment.setOrderNo(orderNo);
payment.setPayAmount(new BigDecimal("99.99"));
payment.setPayTime(LocalDateTime.now());
payment.setPayStatus(1);
try {
int rows = paymentMapper.insertPayment(payment);
if (rows > 0) {
System.out.println("支付记录插入成功:" + orderNo);
doAfterPaymentSuccess(orderNo);
}
} catch (DuplicateKeyException e) {
System.out.println("重复支付消息(唯一约束触发):" + orderNo);
} catch (Exception e) {
System.err.println("支付处理异常:" + e.getMessage());
throw e;
}
}
private void doAfterPaymentSuccess(String orderNo) {
System.out.println("执行后续业务:订单" + orderNo + "已支付,更新订单状态");
}
}
|
这种情况一般连重试都不用配置
状态机模式
状态机模式就是通过业务状态的流转控制和判断,确保同一消息在不同状态下只生效一次。
要想使用这种,你的业务就要有明确的业务状态流转规则,确保同一消息在不同状态下只能被处理一次,当重复消息到达时,若当前状态不符合预设的流转规则(如
“已支付” 状态无法再次执行 “支付”
操作),则直接拒绝处理,从而实现幂等。
在这种情况下,一般会有明确的流转规则,规定状态之间的合法转换路径(如
“待支付→已支付” 是合法的,“已支付→已支付” 是非法的)。
消息处理逻辑
- 消费者接收消息后,先查询业务实体的当前状态;
- 根据状态机规则判断当前状态是否允许执行消息对应的操作;
- 若允许:执行操作并更新状态;
- 若不允许:直接忽略消息(重复处理无意义)。
代码没什么特别的,定义状态和编写状态机就忽略了,消费者编写需要注意基于状态机处理消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
@Component
public class OrderConsumer {
@Autowired
private OrderMapper orderMapper;
@Autowired
private OrderStateMachine stateMachine;
@RabbitListener(queues = "order.pay.queue")
public void handlePaymentMessage(Message message) {
String orderNo = new String(message.getBody());
String messageId = message.getMessageProperties().getMessageId();
int targetStatusCode = (int) message.getMessageProperties().getHeader("targetStatus");
OrderStatus targetStatus = OrderStatus.getByCode(targetStatusCode);
System.out.println("收到支付消息:消息ID=" + messageId + ",订单编号=" + orderNo + ",目标状态=" + targetStatus);
Order order = orderMapper.selectByOrderNo(orderNo);
if (order == null) {
System.err.println("订单不存在:" + orderNo);
return;
}
OrderStatus currentStatus = order.getCurrentStatus();
if (!stateMachine.isTransitionValid(currentStatus, targetStatus)) {
System.out.println("状态转换非法(幂等拦截):当前状态=" + currentStatus + ",目标状态=" + targetStatus + ",订单编号=" + orderNo);
return;
}
try {
processPayment(order);
order.setStatus(targetStatus);
orderMapper.updateById(order);
System.out.println("订单状态更新成功:" + orderNo + ",从" + currentStatus + "到" + targetStatus);
} catch (Exception e) {
System.err.println("支付处理异常:" + e.getMessage());
throw e;
}
}
private void processPayment(Order order) {
System.out.println("执行支付逻辑:订单" + order.getOrderNo() + ",金额" + order.getAmount());
}
}
|
数据库乐观锁
原理:如果业务操作涉及到数据库,可以利用数据库的乐观锁机制。例如,在更新数据库记录时,为表添加一个版本号字段(version)。每次更新操作时,将版本号作为条件,只有当版本号与数据库中的版本号一致时,才进行更新操作,并且更新完成后将版本号加
1。如果版本号不一致,说明该数据已经被其他线程更新过,当前操作可以忽略,从而实现幂等性。
利用数据库乐观锁实现幂等性的核心逻辑:
- 业务表中添加
version 字段(版本号,初始值为 0);
- 消费者处理消息时,执行 SQL 更新操作,将
version
作为条件(where id = ? and version = ?);
- 若更新成功(影响行数 > 0):说明是首次处理,业务正常执行;
- 若更新失败(影响行数 =
0):说明消息已被处理(版本号已变更),直接忽略
那么就涉及到了数据库表的设计上的情况
1
2
3
4
5
6
7
8
9
10
11
|
CREATE TABLE `t_order` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`order_no` varchar(64) NOT NULL COMMENT '订单编号(唯一)',
`amount` decimal(10,2) NOT NULL COMMENT '订单金额',
`status` tinyint NOT NULL COMMENT '订单状态(0:待支付,1:已支付,2:已取消)',
`version` int NOT NULL DEFAULT 0 COMMENT '乐观锁版本号',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`) COMMENT '订单编号唯一索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表(含乐观锁)';
|
- 当第一次处理消息时,
version = 0
与数据库匹配,更新成功(rows = 1),version
变为 1;
- 若消息重复消费(如重试),再次执行时
version = 0
已不匹配(数据库中
version = 1),更新失败(rows = 0),避免重复处理。
乐观锁字段在实体类中也有体现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
@Data
public class Order {
private Long id;
private String orderNo;
private BigDecimal amount;
private Integer status;
private Integer version;
private LocalDateTime createTime;
}
|
生产者(发送带订单信息的消息)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import org.springframework.amqp.core.MessagePostProcessor;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.UUID;
@Component
public class OrderProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendPaymentMessage(String orderNo) {
String messageId = UUID.randomUUID().toString();
MessagePostProcessor postProcessor = message -> {
message.getMessageProperties().setMessageId(messageId);
return message;
};
rabbitTemplate.convertAndSend(
"order.exchange",
"order.pay",
orderNo,
postProcessor
);
System.out.println("发送支付消息:消息ID=" + messageId + ",订单编号=" + orderNo);
}
}
|
Repository 层对于乐观锁的处理也要有,这里省略了
消费者(基于乐观锁处理消息)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| import com.example.entity.Order;
import com.example.mapper.OrderMapper;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderConsumer {
@Autowired
private OrderMapper orderMapper;
@RabbitListener(queues = "order.pay.queue")
public void handlePaymentMessage(Message message) {
String orderNo = new String(message.getBody());
String messageId = message.getMessageProperties().getMessageId();
System.out.println("收到支付消息:消息ID=" + messageId + ",订单编号=" + orderNo);
Order order = orderMapper.selectByOrderNo(orderNo);
if (order == null) {
System.err.println("订单不存在:" + orderNo);
return;
}
if (order.getStatus() == 1) {
System.out.println("订单已支付,无需处理:" + orderNo);
return;
}
int rows = orderMapper.updateStatusWithVersion(
orderNo,
order.getVersion(),
1
);
if (rows > 0) {
System.out.println("订单支付成功:" + orderNo + ",版本号从" + order.getVersion() + "更新为" + (order.getVersion() + 1));
} else {
System.out.println("订单已被处理(乐观锁更新失败):" + orderNo + ",当前版本号=" + order.getVersion());
}
}
}
|
RabbitMQ配置优化
除了这种在业务逻辑上进行处理,通过配置,减少重复消息的发送其实也算是增强了幂等性
生产者配置优化,开启生产者确认机制,确保 RabbitMQ
成功接收消息后,生产者才认为发送成功,避免因 “不确定消息是否发送成功”
而盲目重试。
1
2
3
4
5
6
7
8
9
10
| spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
publisher-confirm-type: correlated
publisher-returns: true
|
代码层面上可以开启配置确认与回退回调,通过
RabbitTemplate
回调确认消息是否到达交换机和队列,避免重复发送:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitProducerConfig {
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (correlationData == null) return;
String messageId = correlationData.getId();
if (ack) {
System.out.println("消息[" + messageId + "]已到达交换机");
} else {
System.err.println("消息[" + messageId + "]未到达交换机,原因:" + cause);
}
});
rabbitTemplate.setReturnsCallback(returnedMessage -> {
String messageId = returnedMessage.getMessage().getMessageProperties().getMessageId();
System.err.println("消息[" + messageId + "]路由失败:交换机=" + returnedMessage.getExchange()
+ ",路由键=" + returnedMessage.getRoutingKey() + ",原因:" + returnedMessage.getReplyText());
});
return rabbitTemplate;
}
}
|
一般情况下,我们需要限制生产者重试次数与间隔,生产者发送失败时(如网络超时),需设置有限重试,避免因无限制重试导致消息重复。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import org.springframework.amqp.rabbit.retry.SimpleRetryPolicy;
import org.springframework.amqp.rabbit.retry.StatefulRetryOperationsInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.retry.interceptor.RetryOperationsInterceptor;
import org.springframework.retry.policy.TimeoutRetryPolicy;
import org.springframework.retry.support.RetryTemplate;
@Configuration
public class ProducerRetryConfig {
@Bean
public RetryOperationsInterceptor producerRetryInterceptor() {
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(3);
retryPolicy.setRetryableExceptions(java.net.SocketException.class, java.net.ConnectException.class);
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(1000);
backOffPolicy.setMultiplier(2);
backOffPolicy.setMaxInterval(4000);
RetryTemplate retryTemplate = new RetryTemplate();
retryTemplate.setRetryPolicy(retryPolicy);
retryTemplate.setBackOffPolicy(backOffPolicy);
return RetryInterceptorBuilder.stateless()
.retryOperations(retryTemplate)
.build();
}
}
|
- 仅对临时异常(如网络波动)重试,对永久异常(如路由键错误)不重试;
- 限制重试次数和间隔,避免短时间内大量重复消息冲击系统。
交换机与队列配置上就是主要减少消息丢失与重复路由,交换机和队列的稳定性直接影响消息的路由和存储,不合理的配置可能导致消息丢失,间接引发生产者重试和重复消息。
确保消息在 RabbitMQ 中持久化存储,避免 RabbitMQ
重启后消息丢失,进而引发生产者重新发送
1
2
3
4
5
| MessagePostProcessor postProcessor = message -> {
message.getMessageProperties().setDeliveryMode(MessageDeliveryMode.PERSISTENT);
return message;
};
|
需配合队列持久化使用(队列非持久化时,消息持久化无意义)。
然后,要避免交换机和队列过度绑定,过多的绑定关系可能导致消息被重复路由到多个队列,引发
“伪重复” 消息(同一消息被多个消费者处理)。
如果在消费者上进行配置就是减少重复处理,在需要的时候开启手动确认会好很多,然后配置合适的死信队列







