
MongoDB Shell
MongoDB Shell(简称简称 mongo 或
mongosh)是 MongoDB 官方提供的交互式命令行工具,用于连接
MongoDB 数据库并执行各种操作(如查询、插入、更新数据,管理数据库 /
集合等)。它是开发者与 MongoDB 交互的最直接方式之一,其使用的命令是
MongoDB 操作的 “原生语法”
它的本质实际上是一个基于 JavaScript 的交互式环境,支持 JavaScript
语法和 MongoDB 扩展命令。你可以在其中输入命令,实时执行并获取结果,类似
MySQL 的 mysql 命令行工具。
- 从 MongoDB 5.0 开始,官方推荐使用新一代 Shell 工具
mongosh(功能更完善,支持语法高亮、自动补全、更好的错误提示等),旧的mongo工具已逐步废弃。
也就是说,你可以使用 js 操作 MongoDB
1 | // 在 mongosh 中执行 JS 逻辑 |
而且,还可以通过 Node.js 环境,借助 MongoDB 官方提供的
Node.js 驱动(mongodb
包)来操作数据库。
1 | npm install mongodb |
1 | const { MongoClient } = require('mongodb'); |
MongoDB 的文档模型基于 BSON(类 JSON 格式),与 JavaScript 的对象语法高度契合,数据结构转换成本极低。
MongoDB的基本操作
MongoDB 是基于文档模型的 NoSQL 数据库,核心操作围绕数据库(Database)、集合(Collection)、文档(Document) 三层结构展开
数据库操作
数据库是集合的容器,一个 MongoDB
实例可包含多个数据库,若未指定数据库,MongoDB 会默认使用
test 数据库。
| 操作目的 | 命令 | 说明 |
|---|---|---|
| 查看所有数据库 | show dbs 或 show databases |
仅显示包含数据的数据库(空库不显示) |
| 切换 / 创建数据库 | use <数据库名> |
若数据库不存在,插入数据时会自动创建 |
| 查看当前所在数据库 | db |
无参数,直接返回当前数据库名称 |
| 删除当前数据库 | db.dropDatabase() |
谨慎操作,需先通过 db 确认当前库 |
数据库名可以是满足以下条件的任意 UTF-8 字符串:
- 不能是空字符串
- 不得含有
空格、.、$、/、\、\0等符号 - 全部小写
- 最多 64 字节
而且admin,local,config是保留的三个数据库,可以直接访问这些有特殊作用的数据库
在上一篇中我们也说了,MongoDB
的存储方式是每个数据库在磁盘上对应一个独立的文件夹(位于 MongoDB
数据目录,默认
data/db),文件夹名与数据库名一致,数据文件(如
.wt 格式)存放在其中。
选择数据库和创建数据库
use <数据库名>
是最常用的数据库操作命令,功能是切换到指定数据库;若该数据库不存在,则在首次插入数据时自动创建
但是,仅执行 use 不会实际创建空数据库
1 | // 切换到名为 "mydb" 的数据库(若不存在则准备创建) |
因为,空数据库(无任何集合和数据)不会显示在 show dbs
结果中,只有当插入数据后才会被持久化。
这也就是为什么,我们再 MongoDB Compass 中创建数据库的时候,需要让你插入一个集合
查看当前数据库
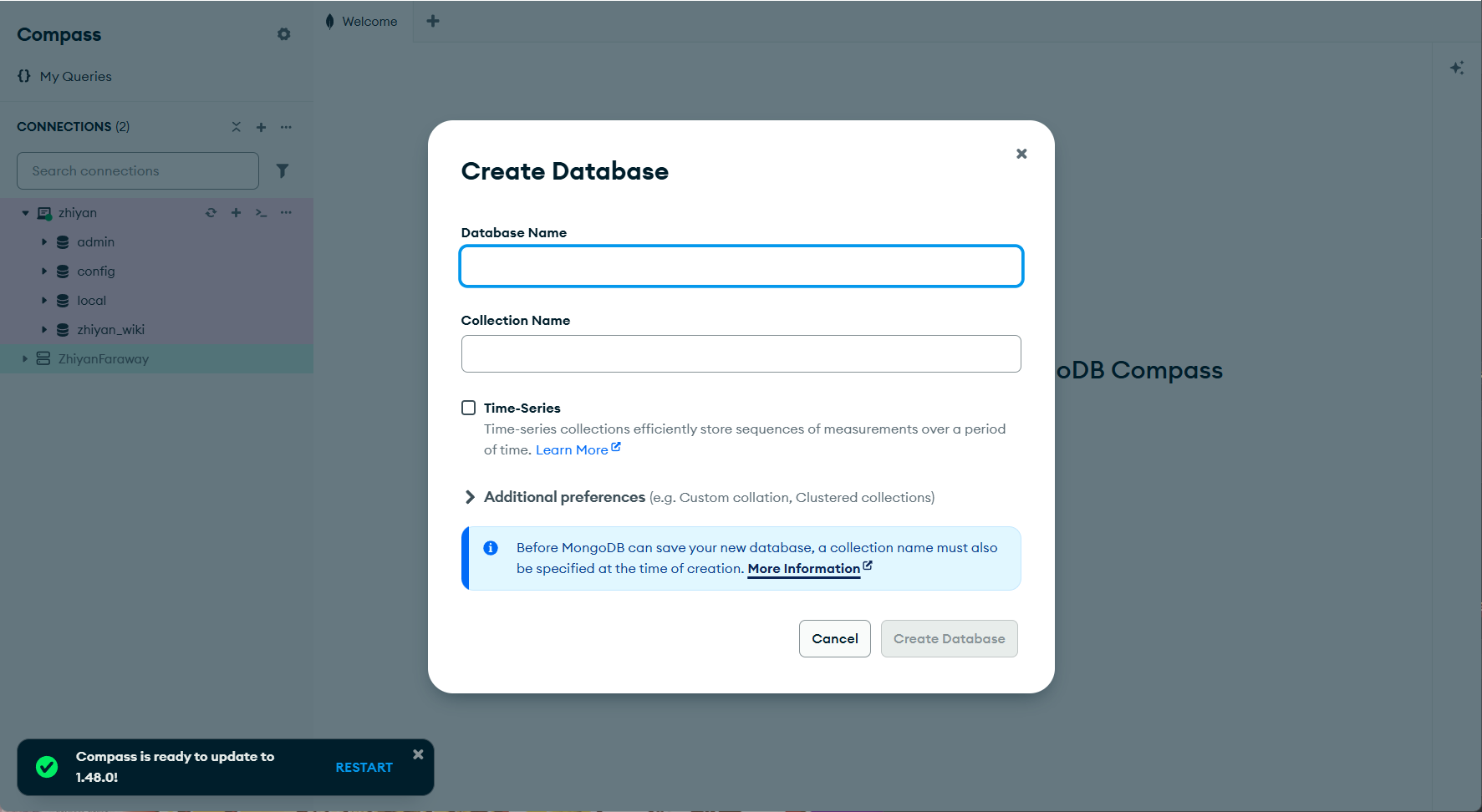
db 命令无需参数,直接返回当前所在的数据库名称。
1 | use mydb |
可以看到默认使用的是 test 库
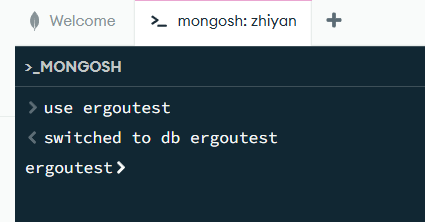
查看所有数据库
show dbs 或 show databases,用于列出
MongoDB
实例中所有非空数据库(包含至少一个集合和数据),并显示每个数据库的磁盘占用大小。
1 | show dbs |
删除当前数据库
删除当前所在的数据库,包括其中所有集合和数据,操作不可逆,需谨慎使用。
步骤:
- 先通过
db确认当前数据库,避免误删; - 执行
db.dropDatabase()命令。
1 | // 确认当前数据库 |
- 若删除的是
admin、local等系统数据库,可能导致 MongoDB 功能异常,禁止随意删除。 - 删除后,磁盘上对应的数据库文件夹会被移除(或标记为删除,后续由 MongoDB 清理)。
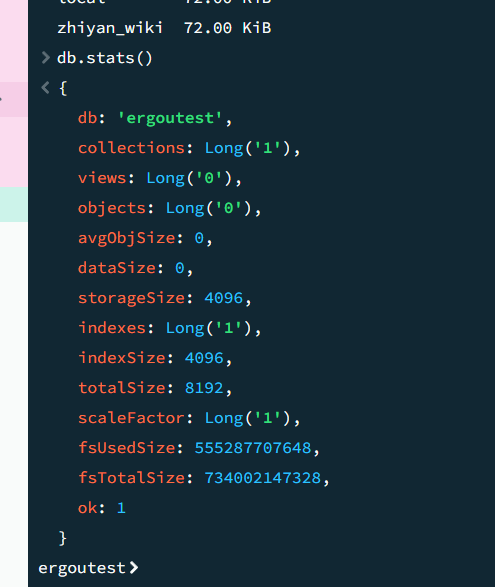
查看数据库状态(db.stats())
用于查看当前数据库的统计信息,包括数据量、集合数量、磁盘占用等。
1 | use mydb |
数据库权限与用户管理
数据库级别的权限控制通过创建用户实现,用户可被赋予对特定数据库的操作权限(如读、写、管理等)。
常用操作:
创建数据库用户:
1
2
3
4
5
6
7
8
9// 切换到目标数据库(用户权限仅作用于当前库)
use mydb
// 创建用户,赋予读写权限
db.createUser({
user: "myuser", // 用户名
pwd: "mypassword", // 密码
roles: [{ role: "readWrite", db: "mydb" }] // 角色(readWrite 表示读写权限)
})查看数据库用户:
1
2use mydb
show users // 列出当前数据库的所有用户删除数据库用户:
1
2use mydb
db.dropUser("myuser") // 删除指定用户
说明:admin
数据库是权限管理的根数据库,在 admin
中创建的用户可拥有跨库的超级权限(如 root 角色)。
数据库连接配置
在连接 MongoDB 时,可通过连接字符串指定目标数据库,无需手动执行
use 命令。
1 | # 连接到本地 MongoDB 实例的 "mydb" 数据库 |
数据库备份和恢复
备份与恢复可通过 mongodump 和
mongorestore 工具对单个数据库进行备份和恢复
1 | # 备份 "mydb" 数据库到指定目录 |
集合操作
集合是文档的容器(类似关系型数据库的 “表”),无需预先定义结构,插入文档时可自动创建。
| 操作目的 | 命令 | 说明 |
|---|---|---|
| 查看当前库的所有集合 | show collections 或 show tables |
显示当前数据库下所有非空集合 |
| 手动创建集合 | db.createCollection("<集合名>") |
可选参数(如 {capped: true, size: 1024}
表示固定大小集合) |
| 删除指定集合 | db.<集合名>.drop() |
谨慎操作,删除后数据不可恢复 |
集合也有命名规范
- 集合名不能是空字符串
- 集合名不能含有 \0 字符(空字符),这个字符表示集合名的结尾
- 集合名不能以 system.开头,这是为系统集合保留的前缀
- 不能以
system.开头(系统集合专用前缀,如system.indexes存储索引信息); - 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$
集合的显式创建
没啥好说
1 | db.createCollection('集合名称'); |
虽然集合可自动创建,但手动创建时可指定特殊属性(如固定大小、自动过期等)。
常用选项参数:
capped: <boolean>:是否为固定大小集合(默认false)。固定集合有最大容量限制,满后会覆盖最早的文档(类似环形缓冲区)。size: <number>:固定集合的最大存储空间(字节),需与capped: true配合使用。max: <number>:固定集合可存储的最大文档数(受size限制,若空间先满则优先按size覆盖)。autoIndexId: <boolean>:是否自动为_id字段创建索引(默认true)。validator: <document>:文档验证规则(限制插入 / 更新的文档必须满足的条件)。
1 | // 创建普通集合(无特殊属性,等价于插入文档时自动创建) |
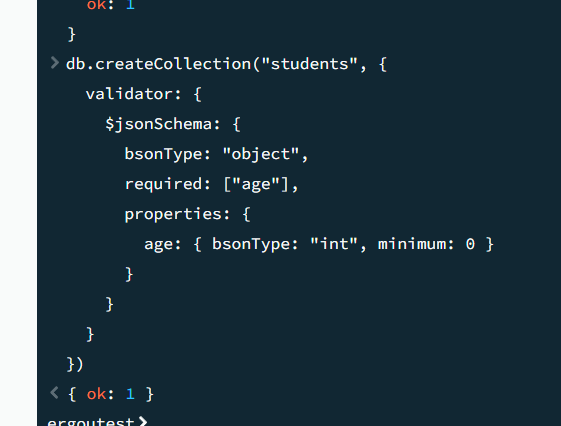
集合的隐式创建
当向不存在的集合插入文档时,MongoDB 会自动创建该集合
和上面提到的数据库类似
查看集合(show collections
或 show tables)
用于列出当前数据库中所有非空集合(包含数据的集合)。
示例:
1 | use mydb // 切换到目标数据库 |
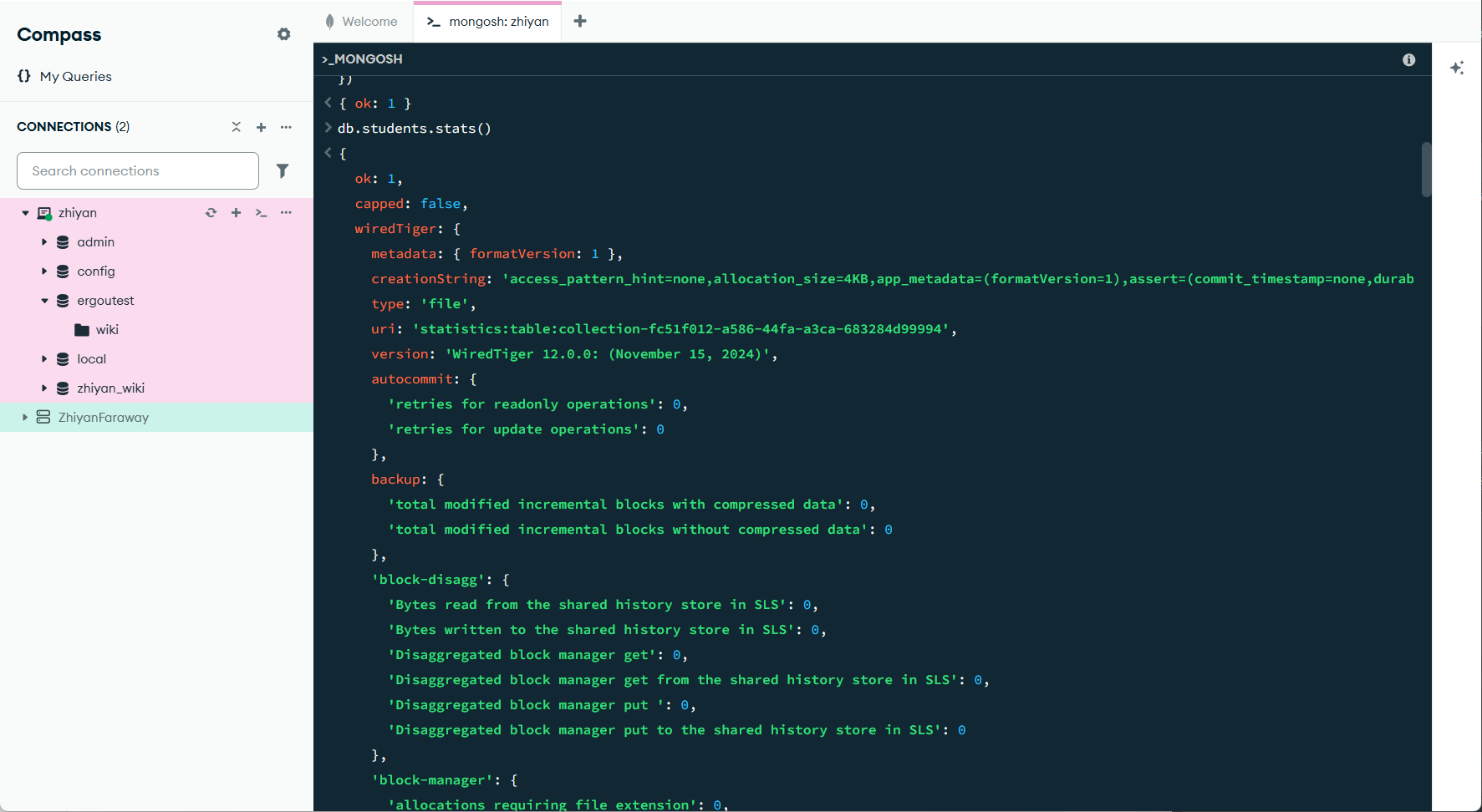
查看集合状态与信息
查看集合统计信息:
db.<集合名>.stats()包含文档数量、索引、存储空间等信息。
1
2
3
4
5
6
7
8
9
10db.users.stats()
// 输出示例(关键信息):
{
ns: "mydb.users", // 集合全名(数据库.集合)
count: 50, // 文档数量
size: 8192, // 数据总大小(字节)
storageSize: 32768, // 磁盘存储大小
indexes: 1, // 索引数量
indexDetails: { ... } // 索引详情
}
查看集合元数据:
db.getCollectionInfos()列出当前数据库所有集合的元数据(如名称、是否固定集合、验证规则等)。
1
db.getCollectionInfos({ name: "users" }) // 查看指定集合的元数据
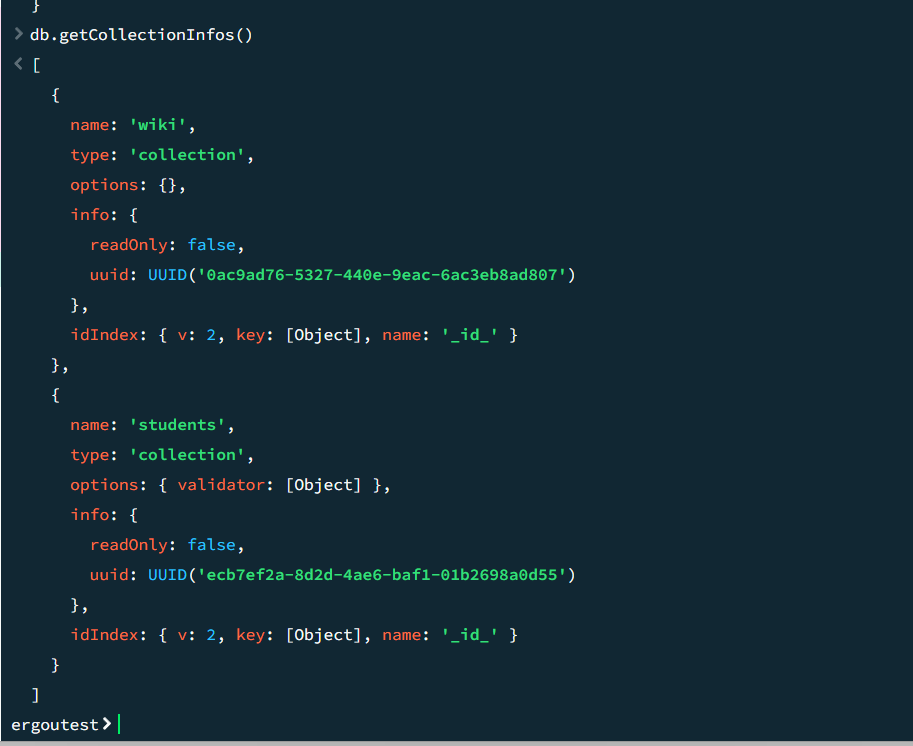
重命名集合(
db.<旧集合名>.renameCollection())用于修改集合名称,可跨数据库移动集合(需权限)。
1
db.<旧集合名>.renameCollection(<新集合名>, [选项])
示例:
1
2
3
4
5// 在当前数据库内重命名
db.users.renameCollection("user_profiles")
// 移动到其他数据库(需有目标库权限)
db.logs.renameCollection("archive.logs_2023") // 将 logs 移动到 archive 库,命名为 logs_2023注意:
- 若新集合名已存在,会抛出错误(可通过
{ dropTarget: true }选项强制删除目标集合后重命名,但需谨慎)。 - 固定集合(capped)重命名后仍保持固定属性。
- 若新集合名已存在,会抛出错误(可通过
删除集合(db.<集合名>.drop())
永久删除集合及其中所有文档和索引,操作不可逆,需谨慎。
1 | // 确认集合存在 |
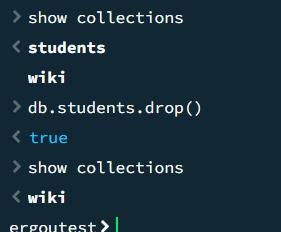
drop() 删除集合本身,而 deleteMany({})
仅删除集合内的文档(集合结构和索引保留)。
集合文档验证规则(validator)
手动创建集合时可指定验证规则,限制插入 / 更新的文档必须满足条件(默认仅在插入 / 更新时验证,不影响已有文档)。
1 | // 创建时指定验证规则(要求文档必须有 "score" 字段且≥0) |
其中有一类用到的比较多的特殊集合,TTL 集合(Time-To-Live):
可自动删除过期文档(通过在日期字段上创建 TTL 索引实现),无需手动清理。
1 | // 创建 TTL 索引(文档插入后 3600 秒自动删除) |
文档操作
文档(Document)是 MongoDB 中最小的数据单元(类似关系型数据库的 “行”),格式为 BSON(二进制 JSON),支持丰富的数据类型(如字符串、数字、数组、日期等)。对文档的操作是 MongoDB 的核心,涵盖插入(Create)、查询(Read)、更新(Update)、删除(Delete) 四大类(即 CRUD 操作)。
文档是键值对的集合,格式类似 JSON
1 | { |
注意,文档
_id字段:每个文档默认生成_id(ObjectId 类型),唯一标识文档,不可修改。操作原子性:单文档操作(如
insertOne、updateOne)是原子的,多文档操作需通过事务保证(MongoDB 4.0+ 支持多文档事务)。数据类型:BSON 支持丰富类型(如数组、日期、ObjectId),例如
{tags: ["a", "b"], createTime: new Date()}。
插入文档
用于向集合中添加新文档,支持单文档插入和多文档插入。
单文档插入(
insertOne())1
db.<集合名>.insertOne(<文档对象>)
其中,完整的语句如下
1
2
3
4
5
6
7db.collection.insertOne(
<document or array of documents>,
{
writeConcern: <document>,
ordered: <boolean>
}
);collection:插入文档的集合名称<document or array of documents>:要插入的一个文档或者文档数组writeConcern:可选参数,用于指定写入的安全级别ordered:可选参数,默认为true。如果设置为true,MongoDB会按照数组中的顺序插入文档,并在遇到错误时停止。如果设置为false,MongoDB会尝试插入所有文档,即使某些文档插入失败
例如
1
2
3
4
5
6
7
8
9
10
11
12
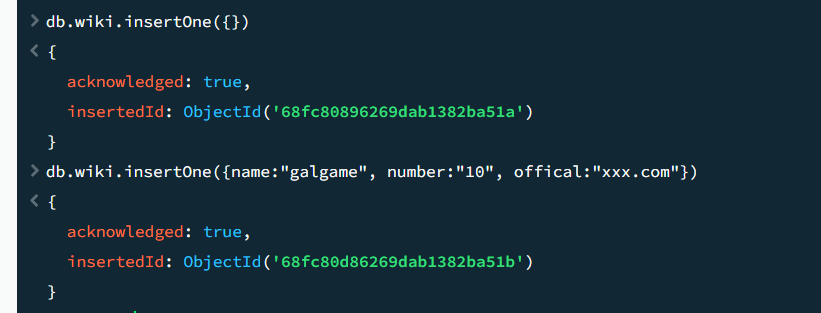
13// 向 users 集合插入一个文档(自动生成 _id)
const result = db.users.insertOne({
name: "Bob",
age: 30,
email: "bob@example.com"
});
// 输出结果(包含插入的文档 ID)
printjson(result);
// {
// acknowledged: true,
// insertedId: ObjectId("650aa1f39f1b2c3d4e5f6a7c")
// }
多文档插入(
insertMany())1
db.<集合名>.insertMany([<文档1>, <文档2>, ...])
ordered: <boolean>:默认true,表示按顺序插入,若某文档出错则终止后续插入;false表示并行插入,忽略错误继续执行。
1
2
3
4
5
6
7
8
9// 批量插入 3 个文档
const result = db.users.insertMany([
{ name: "Charlie", age: 28, email: "charlie@example.com" },
{ name: "Diana", age: 26, email: "diana@example.com" },
{ name: "Eve", age: 32, email: "eve@example.com" }
], { ordered: false }); // 允许并行插入,忽略错误
// 输出结果(包含所有插入的文档 ID)
printjson(result.insertedIds);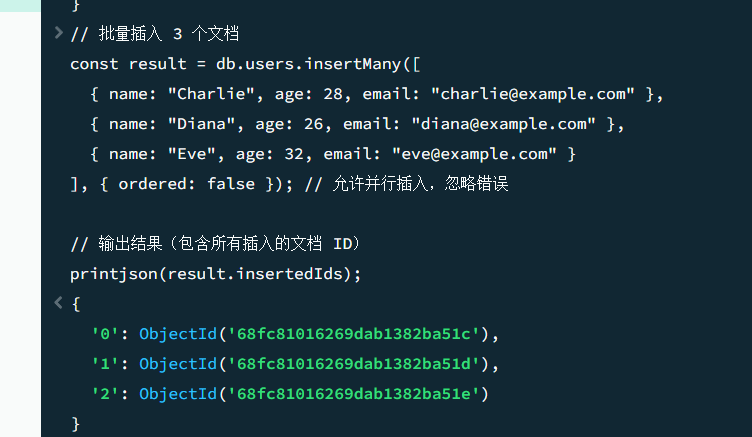
因为批量插入由于数据较多容易出现失败,可以使用 try catch 进行异常捕捉处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57try {
db.comment.insertMany([
{
_id: "1",
article_id: "100001",
content: "我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。",
user_id: "1002",
nickname: "相忘于江湖",
create_time: new Date("2019-08-05T22:08:15.522Z"),
like_number: NumberInt(1000),
state: "1"
},
{
_id: "2",
article_id: "100001",
content: "我夏天空腹喝凉开水,冬天喝温开水",
user_id: "1005",
nickname: "伊人憔悴",
create_time: new Date("2019-08-05T23:58:51.485Z"),
like_number: NumberInt(888),
state: "1"
},
{
_id: "3",
article_id: "100001",
content: "我一直喝凉开水,冬天夏天都喝。",
user_id: "1004",
nickname: "杰克船长",
create_time: new Date("2019-08-06T01:05:06.321Z"),
like_number: NumberInt(666),
state: "1"
},
{
_id: "4",
article_id: "100001",
content: "专家说不能空腹吃饭,影响健康。",
user_id: "1003",
nickname: "凯撒",
create_time: new Date("2019-08-06T08:18:35.288Z"),
like_number: NumberInt(2000),
state: "1"
},
{
_id: "5",
article_id: "100001",
content: "研究表明,刚烧开的水千万不能喝,因为烫嘴。",
user_id: "1003",
nickname: "凯撒",
create_time: new Date("2019-08-06T11:01:02.521Z"),
like_number: NumberInt(3000),
state: "1"
}
]);
} catch (e) {
print(e);
};若集合不存在,插入文档时会自动创建集合。
若文档中包含
_id字段,需确保其值在集合中唯一,否则会抛出重复键错误(E11000)。插入操作是原子的(单文档插入要么完全成功,要么失败)。
查询文档
用于从集合中检索文档,支持条件筛选、排序、分页、投影(只返回指定字段)等。
基础查询(find() 和 findOne())
find(<条件>):返回所有满足条件的文档(默认返回所有字段)。findOne(<条件>):返回满足条件的第一个文档(自动格式化输出,无需.pretty())。1
2
3
4
5
6
7
8// 查询 users 集合中所有文档(无筛选条件)
db.users.find().pretty(); // .pretty() 用于美化输出格式
// 查询 number=10 的文档
db.users.find({ number: 10 }).pretty();
// 查询第一个 age>30 的文档
db.users.findOne({ age: { $gt: 30 } });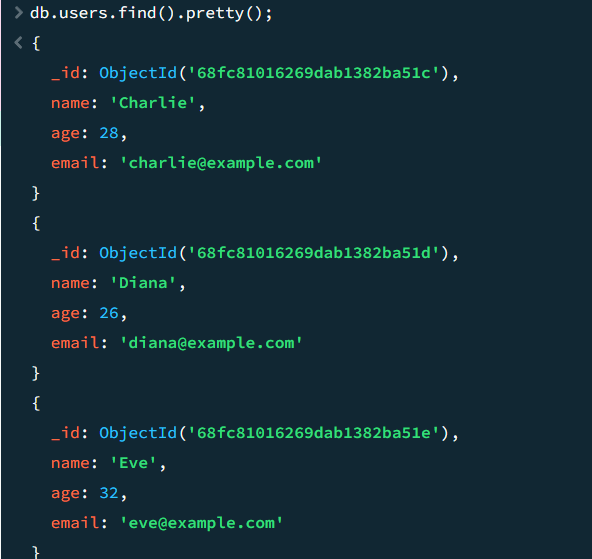
条件查询文档
MongoDB 提供丰富的查询操作符,用于复杂条件筛选:
| 操作符 | 说明 | 示例 |
|---|---|---|
$eq |
等于 | { age: { $eq: 25 } } |
$ne |
不等于 | { age: { $ne: 25 } } |
$gt |
大于 | { age: { $gt: 25 } } |
$gte |
大于等于 | { age: { $gte: 25 } } |
$lt |
小于 | { age: { $lt: 25 } } |
$lte |
小于等于 | { age: { $lte: 25 } } |
$in |
在指定数组内 | { age: { $in: [25, 30, 35] } } |
$nin |
不在指定数组内 | { age: { $nin: [25, 30] } } |
$and |
逻辑与 | { $and: [{ age: { $gt: 25 } }, { name: "Alice" }] } |
$or |
逻辑或 | { $or: [{ age: { $lt: 20 } }, { age: { $gt: 40 } }] } |
$not |
逻辑非 | { age: { $not: { $gt: 25 } } } |
$exists |
字段是否存在 | { email: { $exists: true } } |
$type |
字段类型匹配 | { age: { $type: "int" } } |
整体的查询规则是这样的:db.<集合名>.find(<查询条件>)
例如:
1 | // 查询年龄在 25~30 之间(含)的文档 |

如果条件查询之间需要连接,需要使用 $and 操作符将条件进行关联(相当于 SQL 的 and)
1 | $and:[ { },{ },{ } ] |
如果两个以上条件之间是或者的关系,我们使用 $or 操作符进行关联,与前面 $and 的使用方式相同
1 | $or:[ { },{ },{ } ] |
例如,查询评论集合中 like_number 大于等于 700 并且小于等于 2000 的文档
1 | db.comment.find({ |
数组查询
针对数组类型字段的查询,常用操作符:
| 操作符 | 说明 | 示例 |
|---|---|---|
$all |
数组包含所有指定元素 | { hobbies: { $all: ["reading", "hiking"] } } |
$elemMatch |
数组元素满足所有条件(嵌套) | { scores: { $elemMatch: { $gt: 80, $lt: 90 } } } |
$size |
数组长度等于指定值 | { hobbies: { $size: 2 } } |
示例:
1 | // 查询 hobbies 数组同时包含 "reading" 和 "hiking" 的文档 |
嵌套文档查询
查询嵌套在文档中的字段,需用 . 符号访问:
1 | // 文档结构:{ name: "Alice", address: { city: "Beijing", district: "Haidian" } } |
投影(只返回指定字段)
通过第二个参数指定返回的字段(1 表示返回,0
表示不返回,_id 默认返回,需显式设为 0
才不返回)。
1 | // 只返回 name 和 age 字段(不返回 _id) |
排序、分页与限制
- 排序(
sort()):1升序,-1降序。 - 限制返回条数(
limit(N)):最多返回N条。 - 跳过前 N 条(
skip(N)):用于分页(第page页:skip((page-1)*size).limit(size))。
skip()、limilt()、sort() 三个放在一起执行的时候,执行的顺序是先 sort()、skip()、limit(),和命令编写顺序无关
1 | // 按 age 降序排序,取前 3 条 |
模糊查询
也就是,在 find 中填入对应字段的正则表达式匹配
1 | db.集合.find({字段:/正则表达式/}) |
正则表达式是 js 的语法,直接量的写法
例如:查询评论内容包含 开水 的所有文档
1 | db.comment.find({content:/开水/}) |
更新文档
用于修改已存在的文档,支持单文档更新和多文档更新,需指定更新条件和更新操作。
而更新操作涉及到的操作符如下
| 操作符 | 说明 | 示例 |
|---|---|---|
$set |
设置字段值(新增或修改) | { $set: { age: 26, email: "new@example.com" } } |
$unset |
删除字段 | { $unset: { email: "" } } |
$inc |
数值字段自增 / 减 | { $inc: { age: 1 } }(age+1) |
$push |
向数组添加元素 | { $push: { hobbies: "swimming" } } |
$addToSet |
向数组添加元素(去重) | { $addToSet: { hobbies: "reading" } } |
$pull |
从数组移除满足条件的元素 | { $pull: { hobbies: "hiking" } } |
$rename |
重命名字段 | { $rename: { "oldField": "newField" } } |
单文档更新(updateOne())
只更新第一个满足条件的文档。
1 | db.<集合名>.updateOne( |
详细来说就是下面这样
1 | db.collection.updateOne( |

例如
1 | // 更新单文档:将 name=Alice 的文档 age 改为 26,添加 address 字段 |
多文档更新(updateMany())
更新所有满足条件的文档。
1 | db.<集合名>.updateMany( |
1 | // 更新多文档:将所有 age<25 的文档添加 status: "young" |
详细来说就是下面这样
1 | db.collection.updateMany( |

替换文档(replaceOne())
用新文档完全替换第一个满足条件的文档(保留
_id 字段)。
1 | db.<集合名>.replaceOne(<查询条件>, <新文档>) |
1 | // 替换文档:用新文档替换 name=Charlie 的文档 |
覆盖修改
值得注意的是,在高版本的 MongoDB 中,覆盖修改似乎已经被禁掉了,执行后会直接报错
如果我们想修改 _id 为 1 的记录,将该记录的点赞量修改为 1001,输入以下语句:
1 | db.comment.updateOne( |
执行后,我们会发现,这条文档除了 like_number 字段其它字段都不见了
局部修改
局部需要使用修改器 $set 来实现
例如,我们修改 _id 为 2 的记录,游戏名改成博德之门
1 | db.game.updateOne( |
删除文档
用于移除集合中的文档,支持单文档删除和多文档删除。
单文档删除(deleteOne())
删除第一个满足条件的文档。
1 | db.<集合名>.deleteOne(<查询条件>) |
例如:
1 | // 删除 name=Eve 的第一个文档 |
多文档删除(deleteMany())
删除所有满足条件的文档。
1 | db.<集合名>.deleteMany(<查询条件>) |
示例:
1 | // 删除所有 age>40 的文档 |
删除注意事项
- 删除操作不可逆,执行前需确认条件正确性。
deleteMany({})会删除集合中所有文档,但保留集合结构和索引;若需删除集合本身,用db.<集合名>.drop()。- 删除操作是原子的(单文档删除要么完全成功,要么失败)。
常用辅助操作
MongoDB 的常用辅助操作是指除了核心的数据库、集合、文档、索引操作之外,用于辅助管理、监控、调试数据库的实用功能。
统计文档数量(countDocuments()
和 estimatedDocumentCount())
评价为夯,能忍住不用的也是神人
countDocuments(<条件>):精确统计满足条件的文档数量(会扫描符合条件的文档)。
1 | // 统计 users 集合中 age>25 的文档数 |
estimatedDocumentCount():快速估算集合的总文档数(基于元数据,不扫描文档,适用于粗略统计,可能存在问题)。
1 | // 估算 users 集合的总文档数 |
countDocuments
支持条件筛选且精确,但性能略低;estimatedDocumentCount
无筛选,速度快但结果是估算值(适用于对精度要求不高的场景)。
查看数据库 /
集合状态(stats())
非分布式下用到的不多,分布式下有更好代替,基本不手搓,但是是基础,评价为一般
数据库状态:db.stats()
查看当前数据库的统计信息(如集合数量、总数据量、磁盘占用等)。
1 | use mydb; |
集合状态:db.<集合名>.stats()
查看指定集合的详细信息(如文档数、索引数、平均文档大小等)。
1 | db.users.stats(); // 输出:集合名、文档数、索引信息、存储空间等 |
查看集合元数据(getCollectionInfos())
拉
获取当前数据库中所有集合的元数据(如名称、是否为固定集合、验证规则等),支持按条件筛选。
1 | // 查看所有集合的元数据 |
数据导入与导出
速度很快,而且内部,人上人
MongoDB 提供命令行工具(非 mongosh
内部命令)用于数据的导入导出,方便数据迁移和备份。
导出数据(mongoexport)
将集合数据导出为 JSON 或 CSV 格式。
1 | # 导出为 JSON(默认) |
例如
1 | # 导出 mydb 库中 users 集合的数据到 users.json |
导入数据(mongoimport)
将 JSON 或 CSV 格式的数据导入集合。
1 | # 导入 JSON 文件 |
示例:
1 | # 将 users.json 导入到 mydb 库的 users 集合(若集合不存在则自动创建) |
数据库备份与恢复
人上人
通过 mongodump 和 mongorestore
工具进行数据库级别的备份和恢复,支持完整备份或指定库 / 集合。
备份数据库(mongodump)
创建数据库的二进制备份(包含数据和索引)。
1 | # 备份所有数据库(默认保存到 dump 目录) |
例如
1 | # 备份 mydb 数据库到 /backup/mydb_backup 目录 |
恢复数据库(mongorestore)
从 mongodump 生成的备份文件恢复数据。
1 | # 恢复所有数据库(从 dump 目录) |
例如
1 | # 将 /backup/mydb_backup/mydb 恢复到 mydb 数据库 |
查询优化与分析
查看查询执行计划(explain())
夯都感觉少了
分析查询的执行过程,判断是否使用索引、扫描文档数量等,用于优化查询性能。
语法:
1 | db.<集合名>.find(<查询条件>).explain(<模式>); |
常用模式:
queryPlanner(默认):返回查询计划的详细信息(如候选计划、最优计划)。executionStats:返回执行统计信息(如扫描文档数、耗时)。allPlansExecution:返回所有候选计划的执行信息(用于对比)。
示例:
1 | // 分析查询 { age: { $gt: 25 } } 的执行情况 |
关键指标:
executionStats.executionSuccess:查询是否成功。executionStats.totalDocsExamined:扫描的文档总数(越小越好)。executionStats.totalKeysExamined:扫描的索引键总数(使用索引时不为 0)。winningPlan.inputStage.stage:执行阶段(IXSCAN表示使用索引,COLLSCAN表示全表扫描,需优化)。
查看索引使用情况($indexStats)
夯
通过聚合管道的 $indexStats
阶段,查看集合中各索引的使用频率,识别冗余索引。
示例:
1 | // 查看 users 集合所有索引的使用情况 |
输出包含:
name:索引名称。accesses:包含ops(索引操作次数)和since(统计开始时间)。- 长期
ops=0的索引可考虑删除,减少写入开销。
查看当前连接信息(db.currentOp())
一般,可有可无
查看数据库当前执行的操作(如查询、更新、删除),用于诊断慢查询或阻塞问题。
1 | // 查看所有当前操作 |
终止操作(db.killOp())
绝对神存在,这个真不会卡
终止长时间运行的操作(需通过 db.currentOp() 获取操作
ID)。
1 | // 假设通过 currentOp() 得到操作 ID 为 12345 |
复制集合(copyTo())
工具底层,只能给个一般
将当前集合的数据复制到同一数据库的另一个集合(仅适用于小数据量,大数据量建议用
aggregate 或备份工具)。
1 | // 将 users 集合复制到 users_backup 集合 |
批量操作
批量操作允许在一个请求中执行多个插入、更新、删除操作,减少网络往返次数,提升处理大量数据的效率。MongoDB 提供两种批量操作模式:有序执行(Ordered) 和 无序执行(Unordered)。
批量写入
这是批量操作的核心方法:bulkWrite()
bulkWrite()
是集合级别的方法,接收一个操作数组作为参数,支持的操作类型包括:
insertOne:插入单文档updateOne:更新单文档updateMany:更新多文档replaceOne:替换单文档deleteOne:删除单文档deleteMany:删除多文档
一次性执行多个插入、更新、删除操作,减少网络交互,提高效率。
1 | db.<集合名>.bulkWrite([ |
ordered: boolean:默认true(有序执行)ordered: true:按顺序执行操作,若某步失败则终止后续操作。ordered: false:并行执行操作(无序),某步失败不影响其他操作(适合对顺序无要求的场景)。
假如对 users 集合执行以下的操作
- 插入两个新用户;
- 更新
name: "Alice"的年龄; - 删除
name: "Bob"的文档。
1 | const result = db.users.bulkWrite([ |
事务
与mysql一样,事务用于保证多个操作的原子性:当一组操作中任何一步失败,所有操作都会回滚(恢复到初始状态);只有所有操作成功,才会提交并持久化。
MongoDB 4.0+ 支持多文档事务,确保一组操作要么全部成功,要么全部失败(适用于复杂业务场景,如转账)。
基本流程也和 mysql 一样
- 创建会话(
startSession()); - 启动事务(
session.startTransaction()); - 在会话中执行一系列操作(所有操作需指定
{ session }参数); - 若所有操作成功,提交事务(
session.commitTransaction()); - 若发生错误,回滚事务(
session.abortTransaction()); - 结束会话(
session.endSession())。
以 “转账” 场景为例:用户 A 向用户 B 转账 100 元,需保证扣减 A 的余额和增加 B 的余额两个操作同时成功或失败。
1 | // 1. 创建会话 |
但是我一直感觉 MongoDB 不适合事务
注意,MongoDB 仅支持 WiredTiger 存储引擎(MongoDB
默认引擎)。事务中的操作可跨多个集合甚至多个数据库,但不能跨不同的
MongoDB 实例。
事务中的读操作默认使用 primary
读偏好(仅从主节点读取),确保读取到最新数据。这个和别的不太一样






