
关于Ollama
安装就不说了,直接快进到拉取模型这步骤
Ollama上拉取本地模型
Ollama上可以拉取的模型在官网就能看
https://ollama.com/search

我的笔记本是 4060 RAM是48G 的,所以我直接拉取 qwen3:4b 规模的模型就可以
下载略慢,耐心一些
byd 这个Ollama拉取模型貌似非要在 C盘 中
我改那个环境变量貌似没好使
位置在
n8n搭建工作流
我们搭建一个基于 Ollama 本地 qwen3 的工作流,目的是能够结合今日的实时天气,去发送对应的请求然后给出出行和穿衣的建议
高德地图的 api 自己去看吧,是需要自己申请 key 的,比和风好搞多了,我这边也不是很明白,我只知道一些比较简单的
https://console.amap.com/dev/index 高德开放平台
认识n8n的请求入口—Webhook
它的核心作用是作为 “触发器” 来接收外部系统的 HTTP 请求,从而启动你的自动化工作流。
简单来说,它就像一个 “监听端口”:你把它提供的 URL 配置给外部系统(比如其他应用、自定义脚本、甚至是手动发送的 HTTP 请求),当外部系统向这个 URL 发送请求时,Webhook 节点会捕获这个请求,并将请求中的数据传递给后续节点,进而触发整个工作流的执行。
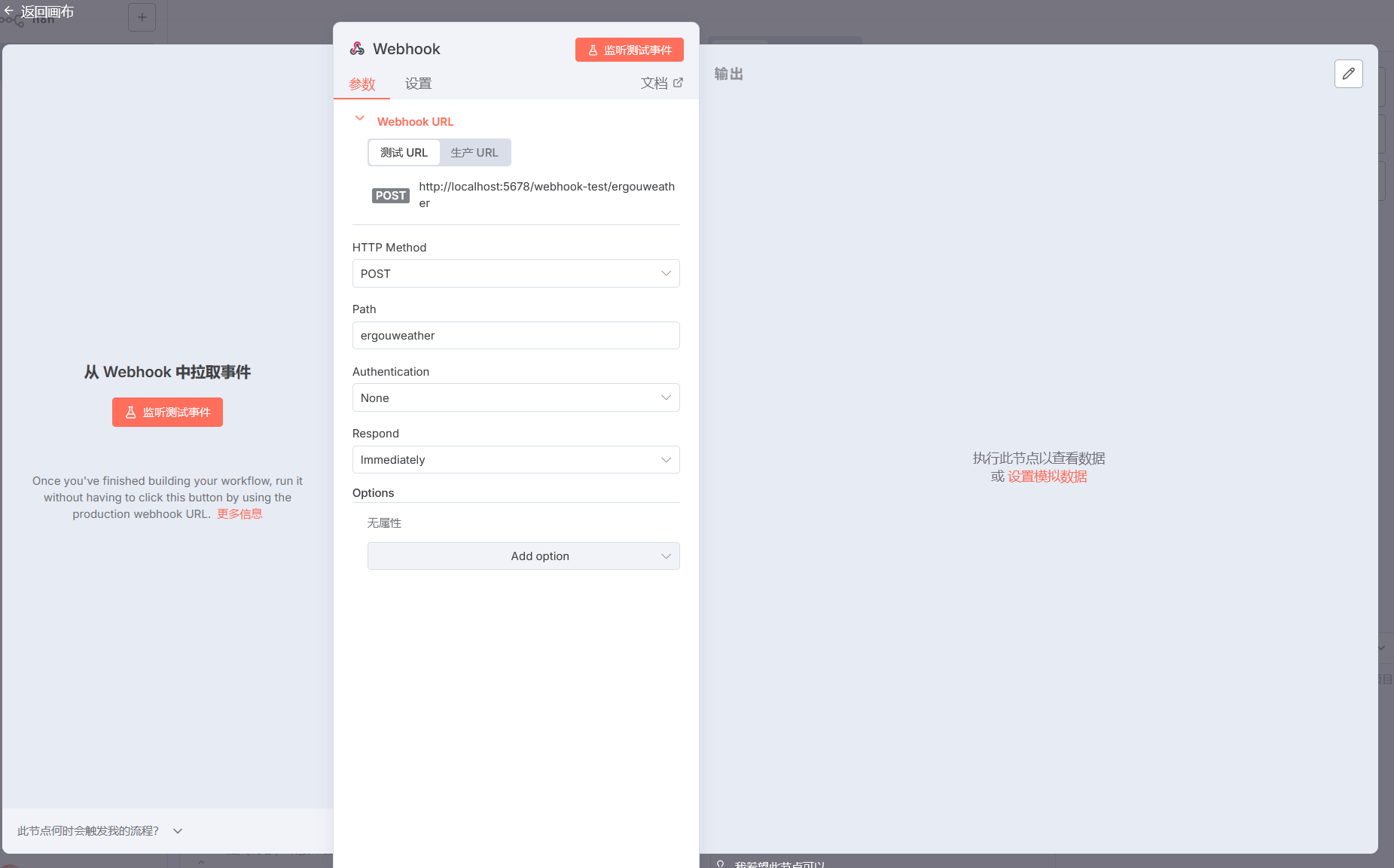
获取 Webhook URL
节点中显示的
http://localhost:5678/webhook-test/...就是用于测试的 Webhook 地址。如果要用于生产环境,可切换到 “生产 URL” 标签获取对外可访问的地址(需确保 n8n 服务可被外部访问)。配置请求方式
目前节点的
HTTP Method是GET,意味着它会监听GET 请求。你也可以根据需求改为POST、PUT等其他 HTTP 方法,以匹配外部系统的请求类型。触发工作流
- 测试阶段:点击 “监听测试事件” 按钮,然后用工具(如浏览器、Postman、curl 命令)向这个 Webhook URL 发送请求,即可触发工作流执行。
- 生产阶段:将 Webhook URL 配置到外部系统(比如让某个应用在特定事件发生时,自动向这个 URL 发送请求),当外部系统发送请求时,工作流就会自动启动。
处理请求数据
当 Webhook 接收到请求后,会将请求的参数、头信息、请求体等数据作为输出,传递给下一个节点(比如 HTTP Request 节点、数据处理节点等),你可以基于这些数据继续构建自动化逻辑(比如调用 API、处理数据、发送通知等)。
引入 Ollama 模型
如果出现这种情况
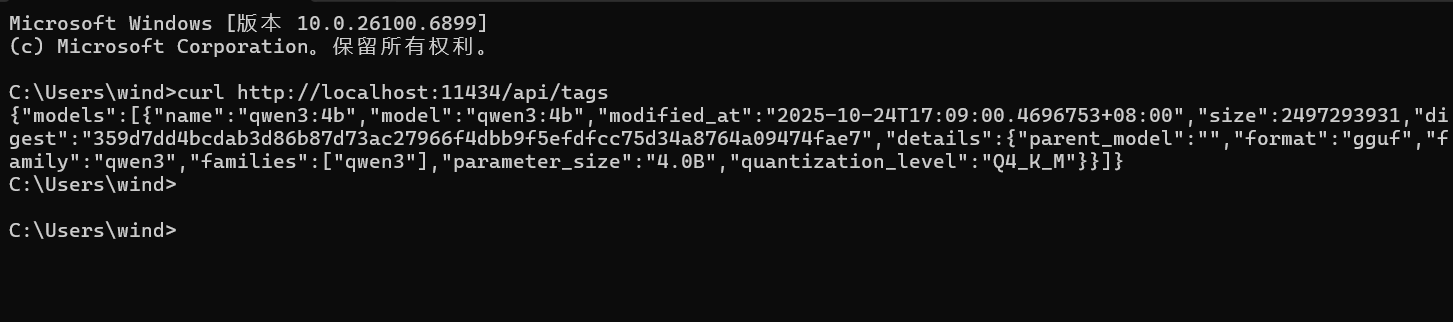
本地发送请求能获得 Ollama 的模型,说明本地 Ollama
是没有任何问题的,当然你也可以使用ollama run 模型名
来测试你的本地对话是否正常
但是 n8n 这边却检索不到模型,请求发不过去
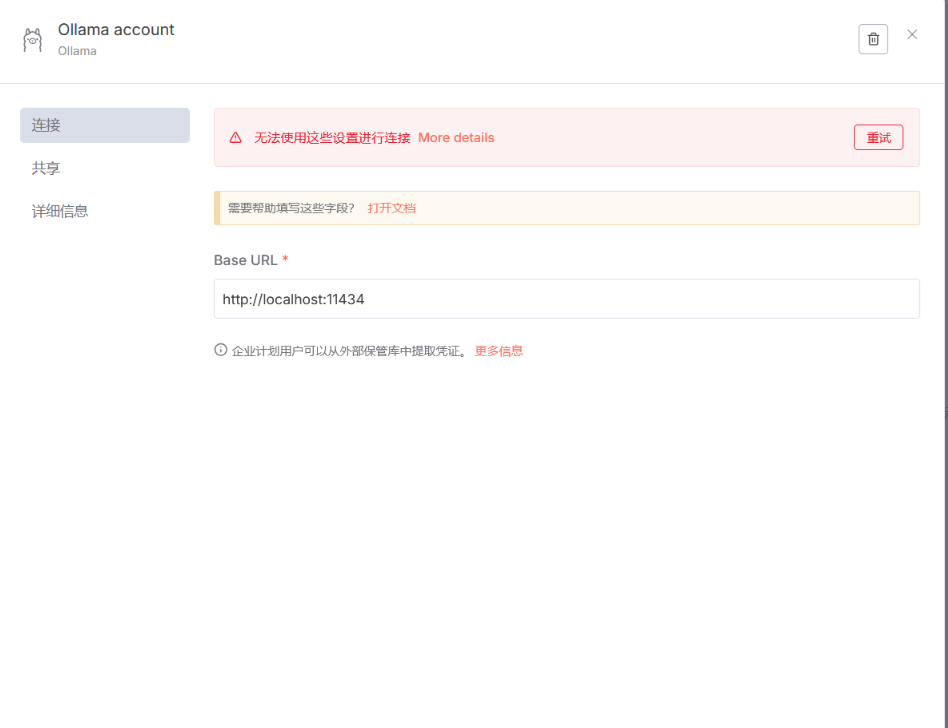
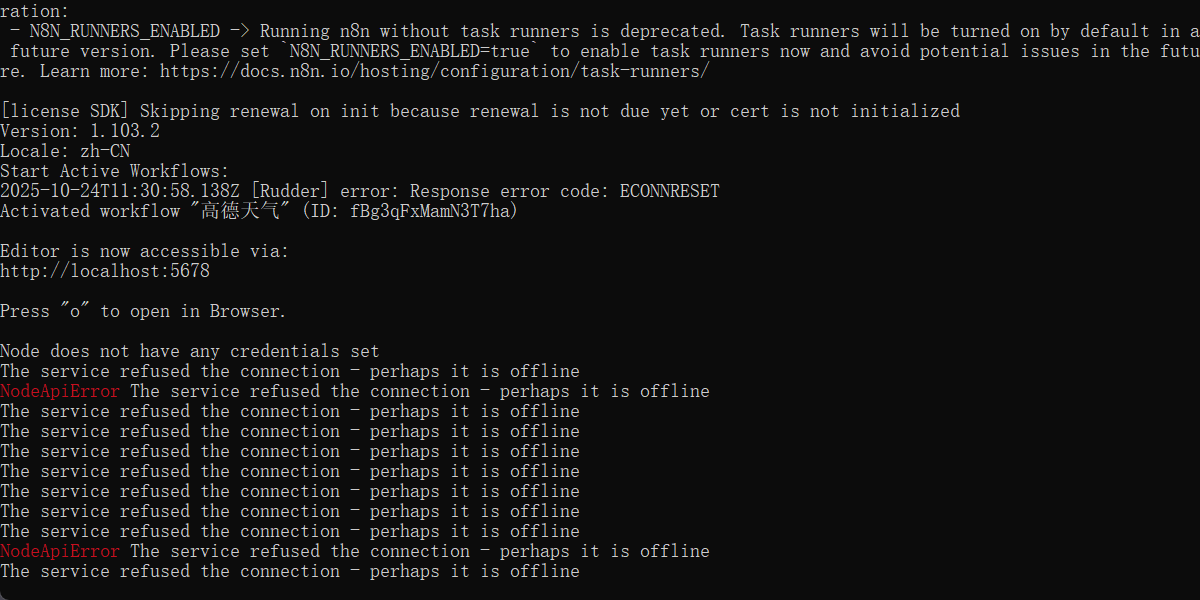
我猜测,你可能跟我一样,使用的是 nodejs 部署的 n8n,这种情况会出现n8n 以 “隔离模式” 运行,这样配置的 localhost” 解析就会出问题
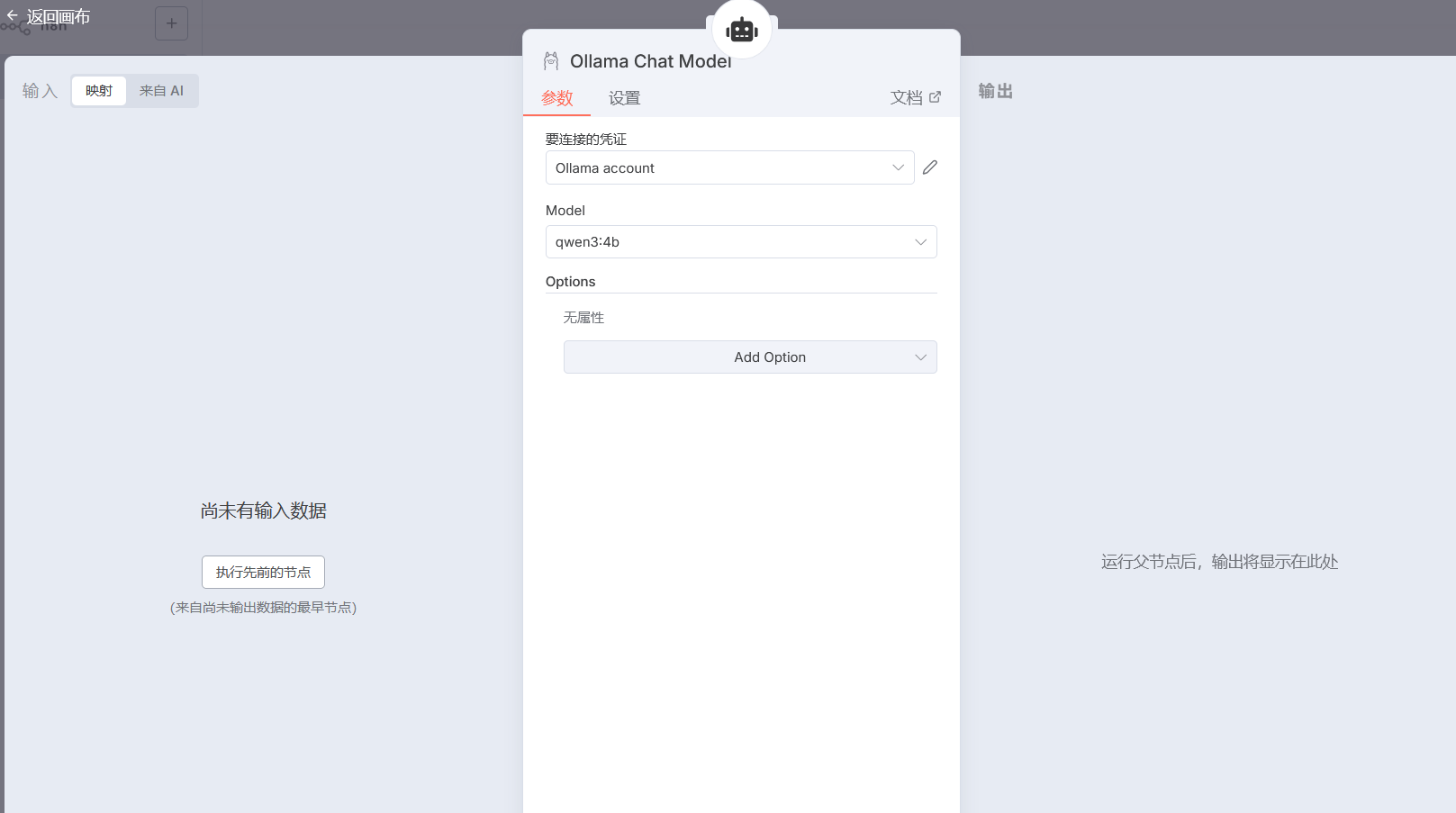
尝试将 n8n 中 Ollama 的 Base URL 从
http://localhost:11434 改为
http://127.0.0.1:11434(直接使用本地回环 IP)。
因为部分程序对 localhost 的解析可能存在延迟或异常,而
127.0.0.1 是更直接的本地地址。
我们可以看到 n8n 把我们本地的模型直接拉下来了
添加高德的天气请求
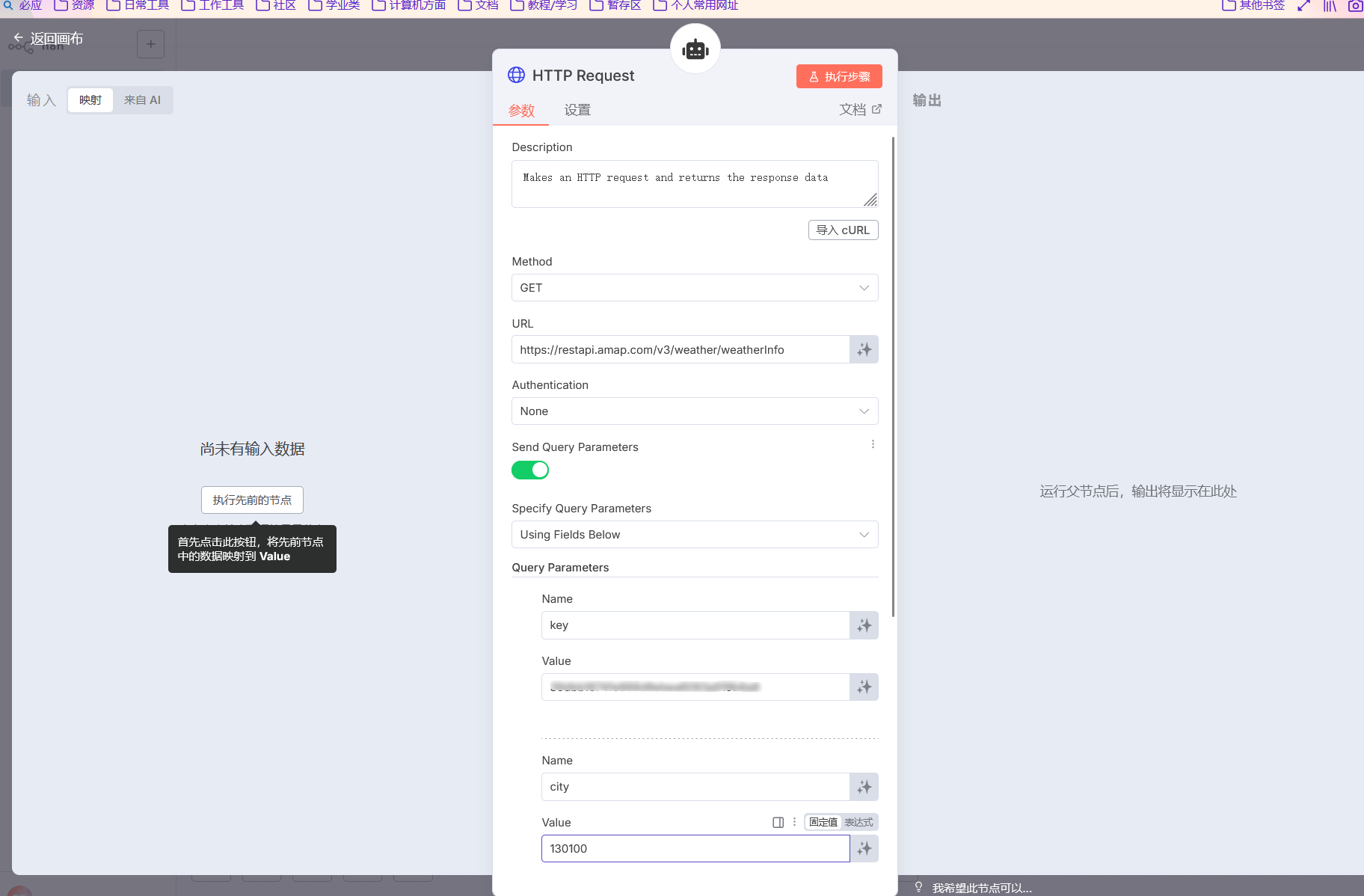
高德获取某个城市的今日天气情况的请求前缀就是这个
1 | https://restapi.amap.com/v3/weather/weatherInfo?key=你的API Key&city=城市编码&extensions=气象类型 |
key:必填,填写你申请的 API Key。city:必填,可填城市编码(如石家庄的编码是130100)或城市名称(如石家庄)。extensions:可选,base表示实况天气,all表示未来预报(默认base)
申请 API
- 访问 高德开放平台官网,注册并登录账号。
- 进入控制台 → 应用管理 → 创建新应用,填写应用名称和类型。
- 为应用添加 Key,服务平台选择 “Web 服务”(只有该类型支持天气 API 调用)。
- 复制生成的 API Key,这是调用接口的身份凭
你需要添加两个字段,一个 key,一个 city,这个 city 有对应的代码,直接打拼音也行
我也不太情况 AI 怎么结合实际情况为我能够不止查询出来我URL里面写死的地区信息,我这个后面寻思再修改一下,感觉这样确实有些死板了,但是别的我还不会
因为我们这里使用到了 AI Agent 的 Tool 工具中的 HTTP Request
你需要在提示词中向 AI 告诉它,你需要调用这个工具来返回真实的信息,这就涉及到提示词如何传入

上述是一个简单的测试你的高德天气请求情况的小工作流,js美化输出代码如下
1 | // 从 HTTP 请求节点获取天气数据(假设前一个节点是 HTTP Request1) |
为模型添加提示词
首先,为模型添加提示词,我们就需要知道前面 AI Agent 它是使用的什么变量来载入我们的信息
也就是说,要在 Set 节点中添加初始提示词,需通过手动映射字段来拼接 “提示词 + 用户输入”。
在 Set 节点的 “Fields to Set” 区域,点击
“添加字段”,输入字段名称(例如combinedPrompt,用于存储拼接后的提示词),前面那个{{ $json.chatInput }}是你可以设置用户输入的字段名,需确保与实际字段一致
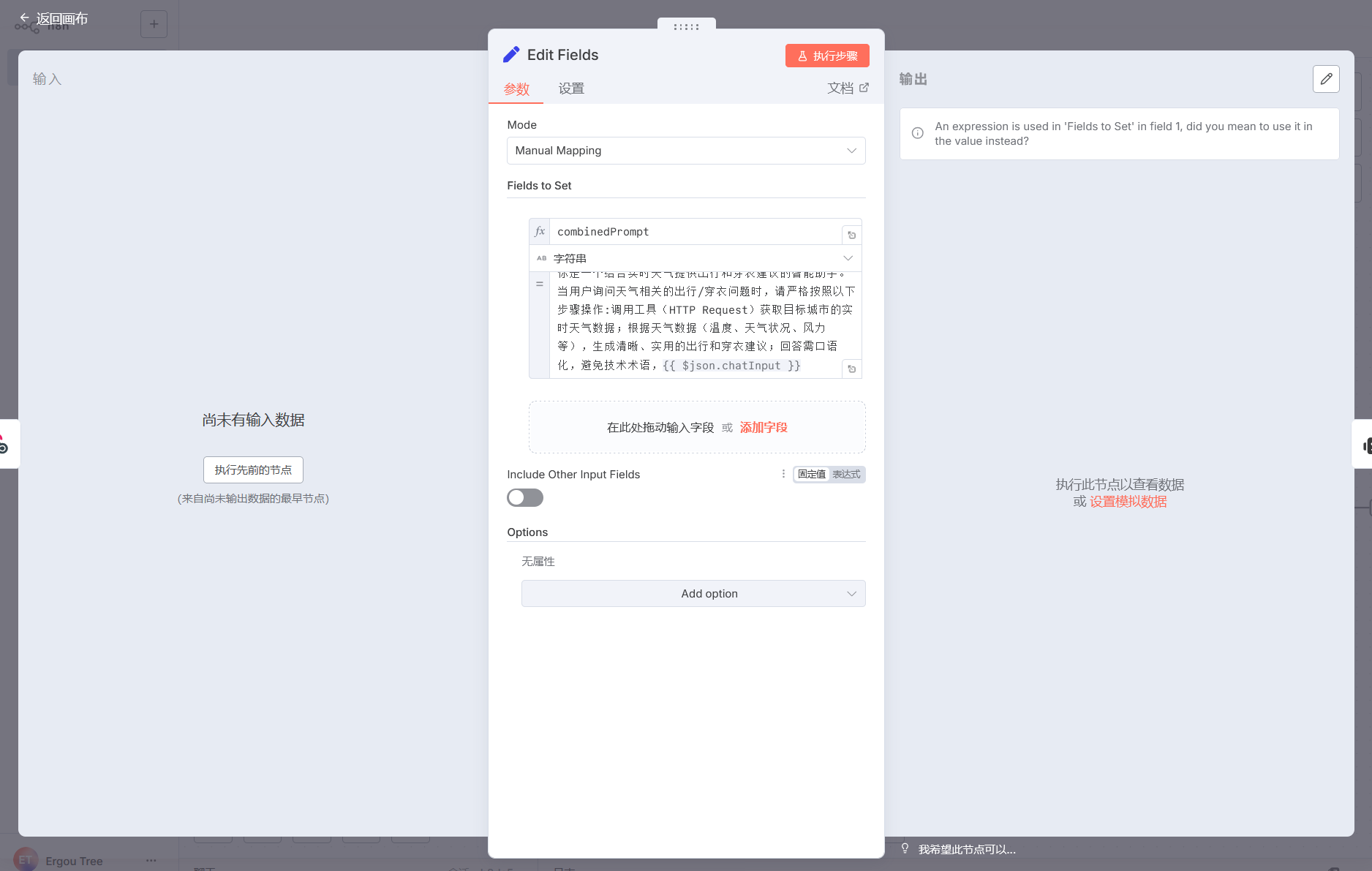
也就是说,如果你使用的是 Webhook,就需要在请求体中携带 chatInput 这个字段,如果你使用的是 Chat Message,就需要在对话中添加 chatInput 这个字段
这样变量才能够被识别,被继续传递下去,连接 Set 节点的输出到 AI Agent 节点的输入。

测试一下这一小段
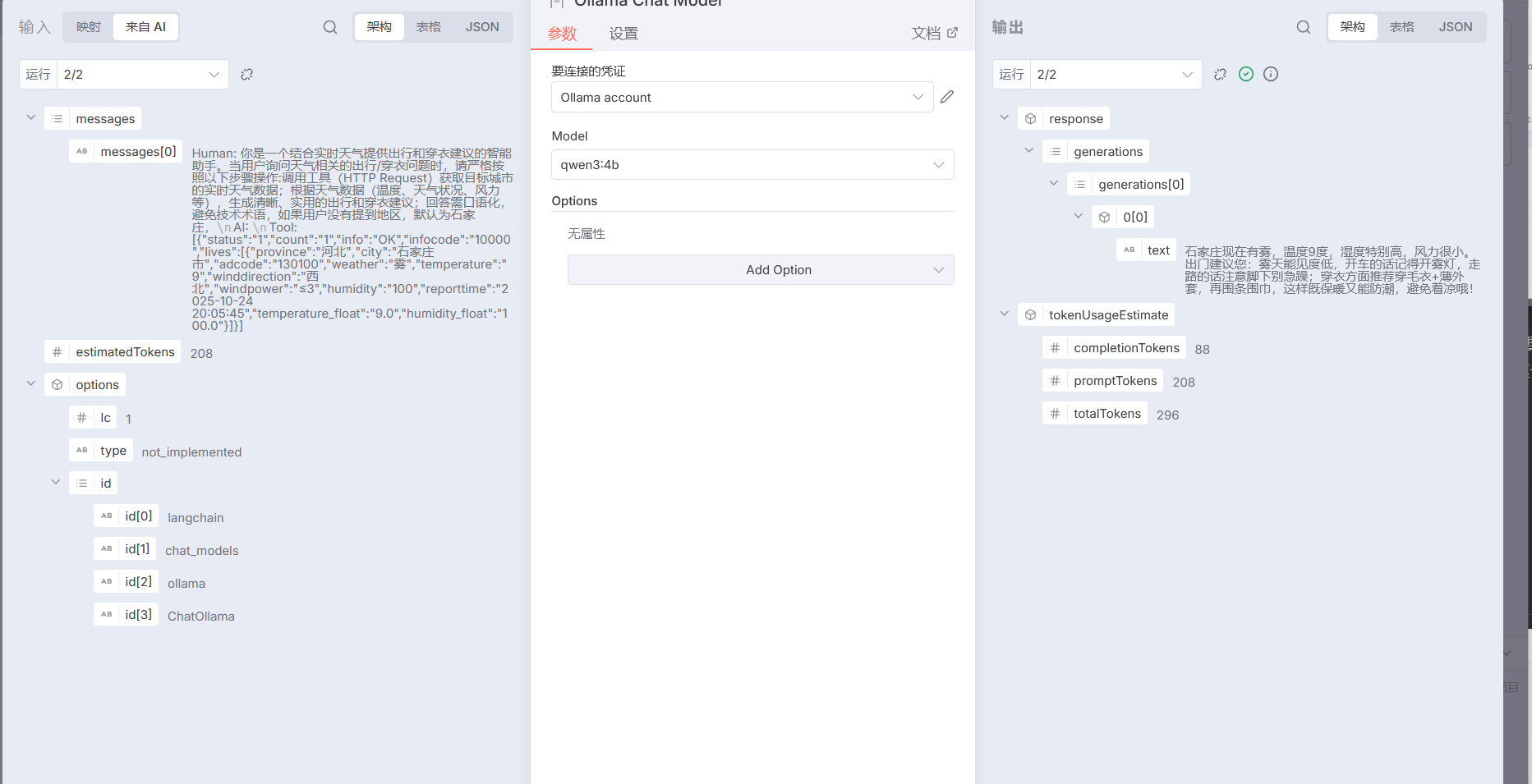
发送天气情况到我们的邮箱
看到上面的邮箱节点了吗,其实我们再编辑一下,我们可以让 AI 为我们发送今日天气的情况到我们邮箱
只需要拼接 AI 输出的内容,再配置邮箱的情况就可以了
邮箱节点是这样的
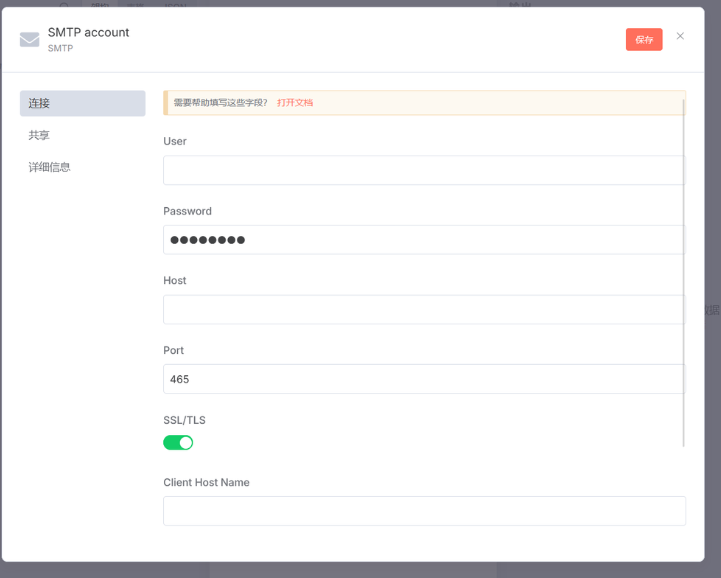
其中需填写你使用的邮箱服务商的 SMTP 服务器信息。
User(用户名)
- 填写你的邮箱地址(例如
your@email.com)。
- 填写你的邮箱地址(例如
Password(密码)
这里不是邮箱的登录密码,而是需要填写 SMTP 授权码(需在邮箱服务商处开启并生成):
QQ 邮箱:登录后进入「设置 → 账户 → 生成授权码」。
网易邮箱(163/126):登录后进入「设置 → POP3/SMTP/IMAP → 开启 SMTP 并生成授权码」。
Host(服务器地址)
根据邮箱服务商填写:
QQ 邮箱:
smtp.qq.com网易 163 邮箱:
smtp.163.com网易 126 邮箱:
smtp.126.comGmail(需科学上网):
smtp.gmail.com
Port(端口)
- 通常选择加密端口:
- 开启 SSL/TLS 时,端口填
465(如截图中已填,保持即可)。 - 若关闭 SSL/TLS,可填
587(但建议开启加密)。
- 开启 SSL/TLS 时,端口填
- 通常选择加密端口:
SSL/TLS
保持开启(绿色开关),确保传输加密。
Client Host Name(可选)
一般留空即可,部分服务商要求时可填邮箱域名(如
qq.com、163.com)。
配置好了我们就进入到编辑页面
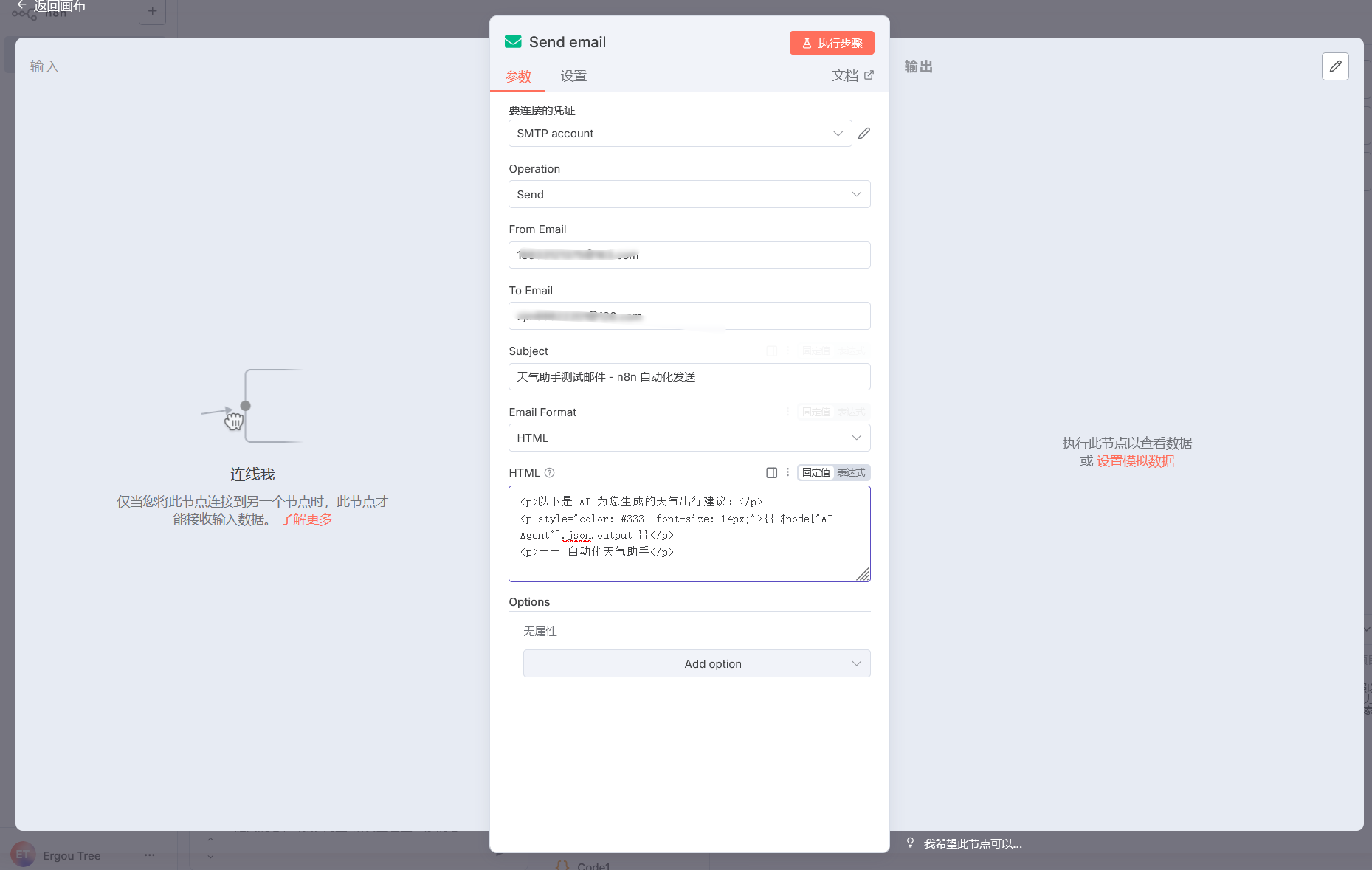
还记得我们之前传递的变量 chatInput 吗
我们使用这个,确保工作流中 AI Agent 节点的输出已连接到 Send email 节点(通过连线将 AI Agent 的输出端口与 Send email 的输入端口关联)。
在 Send email 节点的 HTML 输入框 中,使用 n8n 的变量引用语法,将 AI 的回复插入邮件内容。示例代码如下:
1 | <p>以下是 AI 为您生成的天气出行建议:</p> |
{{ $node["AI Agent"].json.output }}表示引用 AI Agent 节点 的输出字段output(即 AI 的回复内容)。- 可根据需要添加 HTML 样式(如颜色、字体大小),或补充其他文本说明。
通过这种方式,即可实现将 AI 的智能回复自动写入邮件并发送,完成从 “AI 生成建议” 到 “邮件通知” 的自动化流程。
我们进行测试
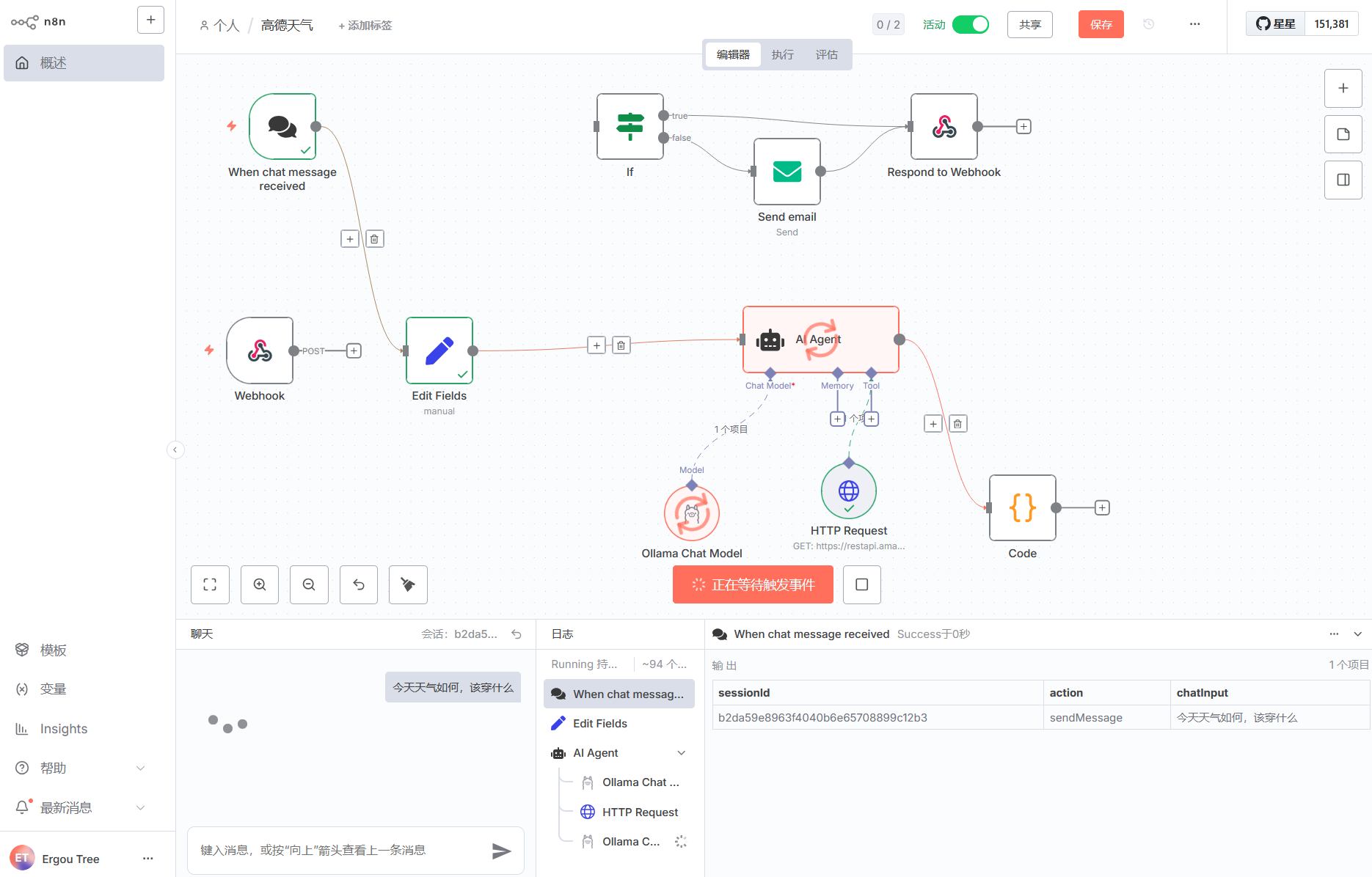
我草了我这边好慢,趁着这段时间,我修改了一下输出
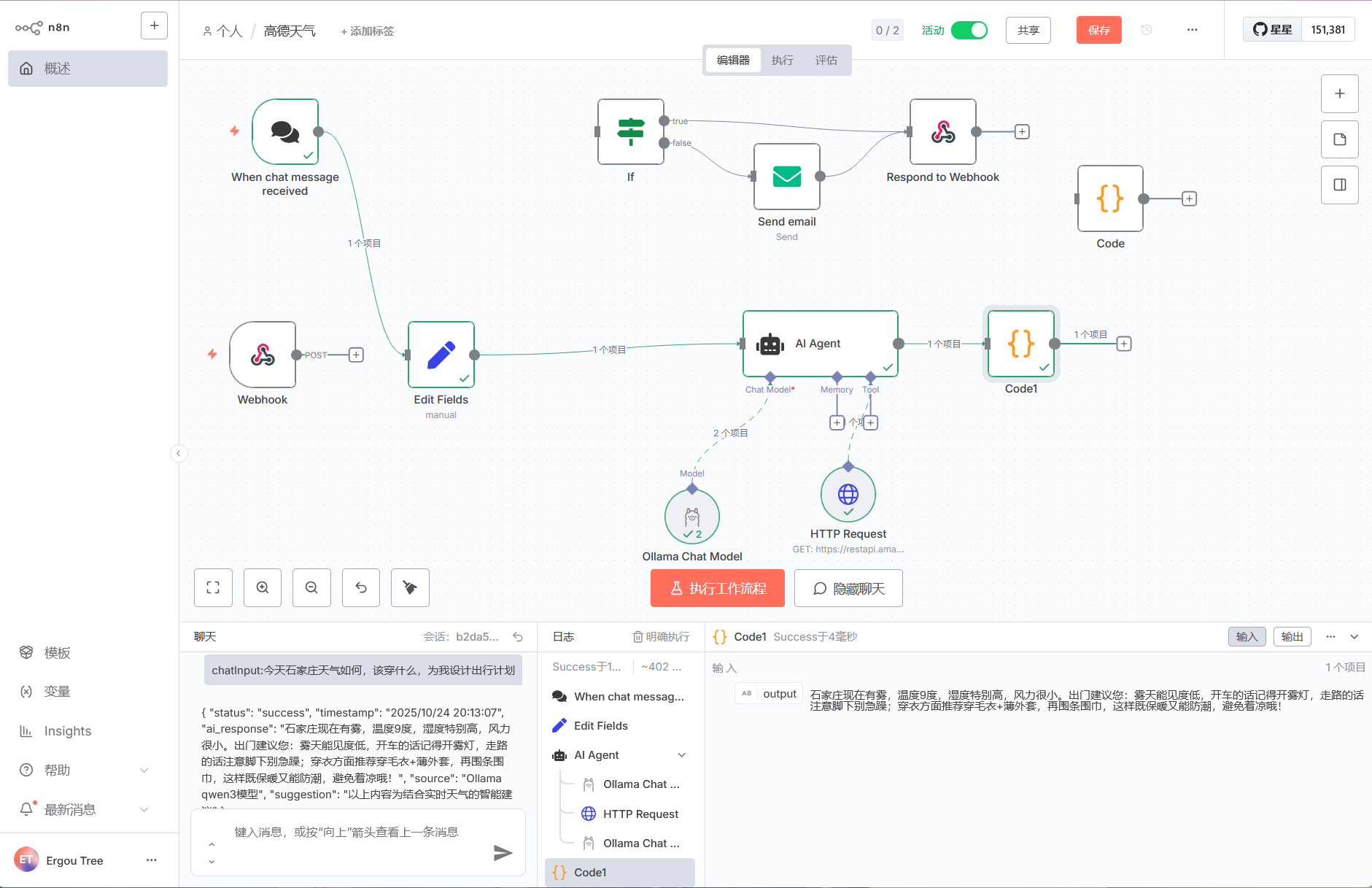
大功告成哩,我们接上邮箱试试看
好慢啊我超
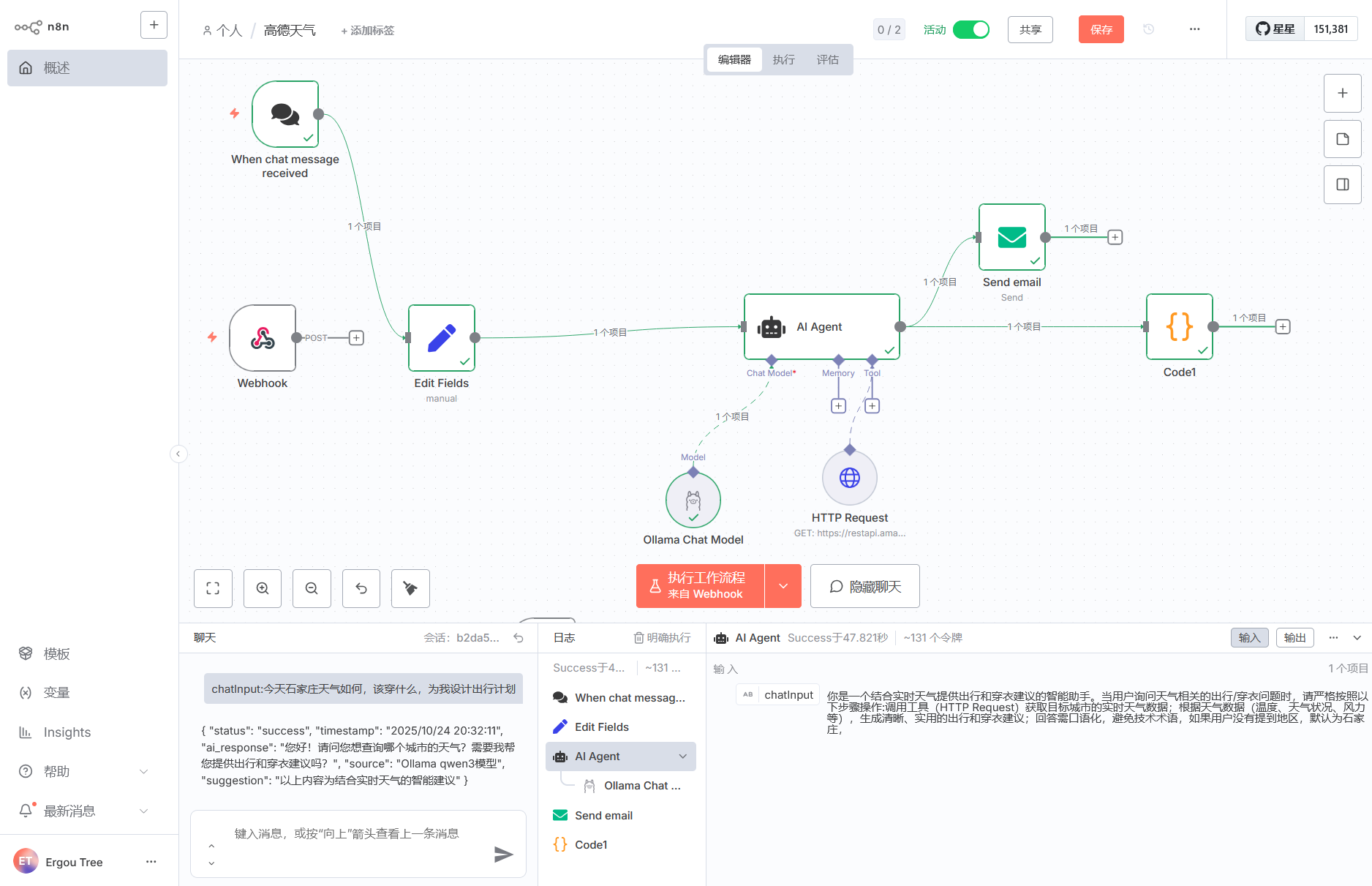
刚刚怎么没有成果调用 Request 工具,再试一下‘
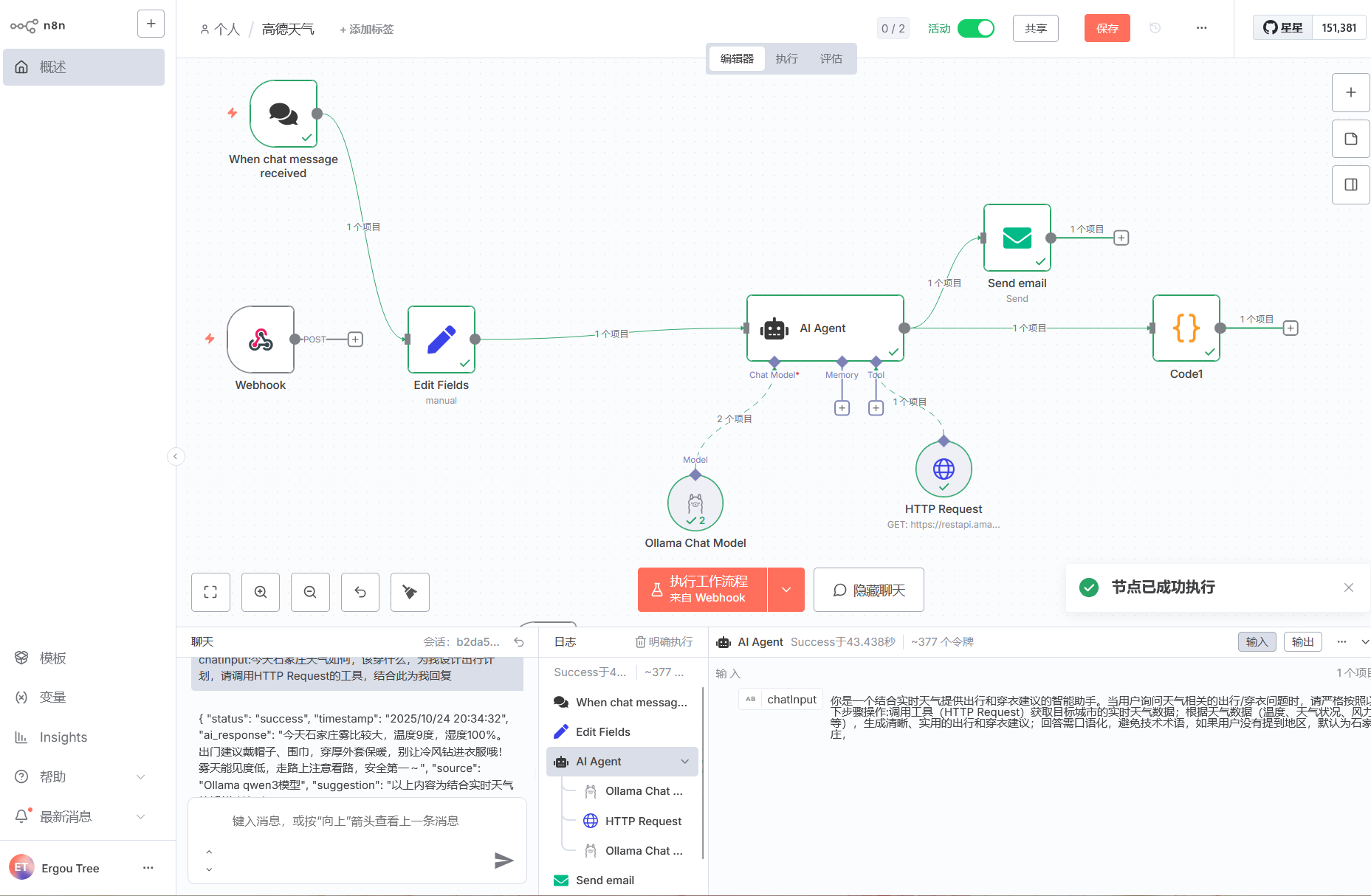
我去我去,n8n 给我来邮件了,接一下((
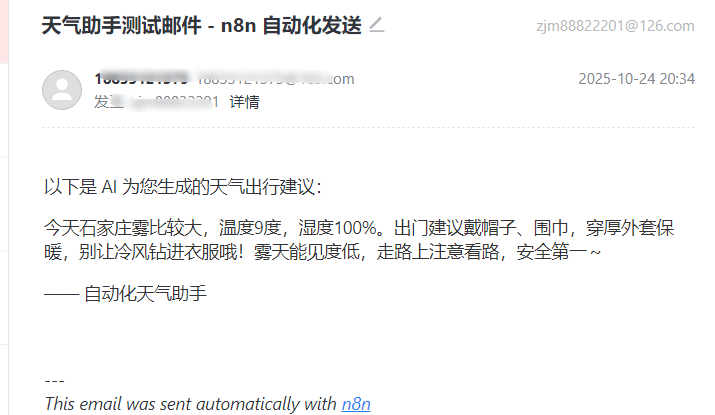
一个简单有趣的工作流就这样搭建好了






