
Elasticsearch介绍
前言
想象一下:
你拥有一个超大型的galgame数据库(你的数据),里面有数百个galgame游戏(你的文档)。Elasticsearch 就是这个数据库里一位强大的“老资历”。
- 传统查找(如数据库): 如果你想找一本名叫《XXX》的galgame,你得知道它在哪个区、哪个文件夹、哪一层(这相当于数据库的索引和主键)。如果你记不清全名,只记得游戏里提到了“人工智能”和“未来”,传统方式就几乎无能为力了。
- Elasticsearch 的方式: 这位老资历不同,他不仅记得每个galgame的游戏名、出场角色、cv,他甚至记得每个场景里每一句对话的每一个词。你只需要走过去对他说:“老资历,帮我找所有谈到‘人工智能’和‘未来’的galgame”,他几乎能瞬间给你一个精确的、按相关性排序的游戏——未来广播与人工鸽。
这个“超级老资历”就是 Elasticsearch。它是一个开源的、分布式的、RESTful 的搜索和分析引擎。
本质上,ES 也是一个数据库
核心功能是执行强大的全文搜索。它不仅仅是简单的字符串匹配,还能处理同义词、拼写错误、相关性评分等。近乎实时的搜索速度, 从你存入一条数据到它可以被搜索,通常只在 1 秒以内。这为需要快速响应的应用(如网站搜索、日志查询)提供了保障。
强大的全文搜索能力:
分词与倒排索引: 这是 ES 的核心魔法。它会将一段文本拆分成一个个词条(Tokenization),并建立一个“词条 -> 文档”的映射表(倒排索引)。这就像一本书末尾的索引页,告诉你“爱因斯坦”这个词出现在哪几页。搜索时直接查这个表,速度极快。
相关性评分: ES 使用 TF/IDF 或 BM25 等算法为每个搜索结果计算一个
_score,告诉你这个结果与你的搜索词有多匹配,并按分数高低排序。模糊查询: 能处理拼写错误。
同义词处理: 搜索“手机”也能找到包含“电话”的结果。
而且ES支持分布式,数据可以被分成多个部分(分片),并分布到多台服务器(节点)上。这使得它能够处理海量数据(PB级别),并提供高可用性(即使一台服务器宕机,数据也不会丢失,服务也不会停止)。
可扩展性和高可用性:
水平扩展: 当数据量增大或并发请求变多时,你只需要向集群中添加更多的服务器即可,非常简单。
容错性: 数据会有副本。即使某个节点失效,副本分片会立刻接管工作,确保服务不中断。
RESTful意味着你可以通过简单的 HTTP API(使用 JSON
格式)与它进行交互,比如使用
GET、POST、PUT、DELETE
等命令来操作数据。这使得任何编程语言都能轻松地与 ES 集成。
分析引擎就是 除了搜索,它还能对数据进行复杂的聚合分析。例如,“统计过去一个月内,哪个品牌的手机被讨论得最多,并按小时生成趋势图”。这在日志分析、商业智能等领域非常强大。
ES的查询语句非常丰富,使用基于 JSON 的、功能极其丰富的查询语言,你可以构建出任意复杂的查询和聚合逻辑。
而且ES 经常与 Logstash(数据采集和处理)和 Kibana(数据可视化)一起使用,构成著名的 ELK Stack。这是一个从数据摄入、存储到搜索、可视化的一站式解决方案,尤其在日志和指标分析领域是事实上的标准。
如何理解 ES
需要理解下面的核心概念
- 集群(Cluster)
- 一个集群就是由一个或多个节点组成的集合,它拥有整个集群的数据,并提供跨所有节点的联合索引和搜索能力。
- 每个集群都有一个唯一的名称标识,默认是
"elasticsearch"。
- 节点(Node)
- 一个节点是集群中的一个服务器,它存储数据,并参与集群的索引和搜索功能。
- 节点也通过集群名称来加入指定的集群。
- 索引(Index)
- 类比: 相当于关系型数据库中的 “Database”(数据库)。就是相同类型的文档的集合,例如所有用户文档,就可以组织在一起,称为用户的索引;
- 定义: 是具有某种相似特性的文档的集合。例如,你可以有一个“客户”索引,一个“产品”索引。
- 类型(Type) - 注意:在 7.x
及之后的版本中已逐渐被废弃,一个索引通常只建议有一个
_doc类型。 我们可以暂时忽略它,知道它曾经相当于“表”即可。 - 文档(Document)
- 类比: 相当于关系型数据库中的 “Row”(一行记录)。可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中
- 定义: 是可以被索引的基本信息单元。例如,你可以为一个客户创建一个文档。文档是用 JSON 格式表示的。
- 字段(Field)
- 类比: 相当于关系型数据库中的 “Column”(列)。
- 定义: 文档中包含的属性,比如客户的“姓名”、“年龄”、“地址”。
- 分片(Shards) 和 副本(Replicas)
- 分片: ES 允许你将一个索引划分成多个部分,每个部分就是一个分片。它允许你水平分割/扩展你的数据量,允许你在多个节点上并行操作,从而提高性能和吞吐量。
- 副本: 是分片的复制。它提供数据冗余,防止硬件故障导致数据丢失,并且所有的搜索请求都可以由主分片或副本分片来处理,所以副本也提升了搜索的吞吐量和性能。
关系梳理: 集群 包含多个
节点 -> 节点 上存储着 索引
-> 索引 被分成多个
分片(主分片和副本分片)-> 分片 里包含很多
文档 -> 文档 由多个 字段
组成。
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
Elasticsearch是数据库吗
Elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。
Elasticsearch 的核心本质是一个搜索引擎,但它具备了很多数据库的特性,因此常常被当作一种特殊的数据库来使用。
Elasticsearch 作为“搜索引擎”,这是它的出身和核心设计目标。
- 专为“搜索”而生: 它的底层数据结构(倒排索引)就是为了解决“如何从海量文本中快速找到包含特定词汇的信息”这一核心问题而设计的。
- 追求速度和相关性: 它的目标是:“快”(毫秒级响应)和 “准”(结果按相关性排序)。你输入一个模糊的关键词,它要能快速返回最可能符合你意图的结果,甚至能处理你的拼写错误。
- 类比: 就像 Google 或百度的核心引擎。你不会认为谷歌是一个“数据库”,对吧?你向它提问,它返回一个按重要性排序的网页列表。
搜索引擎的典型特征,ES 都具备:
- 全文检索: 对文本内容进行分词、索引,支持复杂的查询(匹配、短语匹配、模糊查询等)。
- 相关性评分: 内置复杂的算法(如 BM25)为每个结果计算匹配度分数。
- 理解用户意图: 支持同义词、拼写纠错、搜索建议等功能。
Elasticsearch 作为“数据库”是它功能上的延伸和扩展。
虽然核心是搜索,但 ES 具备了存储、查询和管理数据的能力,所以人们也把它当作一种 NoSQL 文档数据库 来用。
- 数据持久化: 它能把你的 JSON 文档可靠地存储在磁盘上。
- 基本的 CRUD 操作: 你可以执行创建、读取、更新、删除文档的操作,这和任何数据库一样。
- 简单的查询: 你可以通过文档 ID
来获取数据,或者进行一些精确匹配的查询(比如
where status = 'active')。 - 分布式和可扩展性: 它天生就是分布式的,能轻松处理海量数据,这比很多传统数据库更容易扩展。
那么,它是不是一个“完美的”数据库呢?并不是。 它在作为数据库使用时,有一些重要的权衡和短板:
| 特性 | Elasticsearch (作为数据库) | 传统数据库 (如 MySQL, PostgreSQL) |
|---|---|---|
| 事务性 (ACID) | 弱。不支持真正的跨文档 ACID 事务(虽然新版本有改进,但仍有局限)。复杂业务逻辑下的数据一致性是其短板。 | 强。完全支持 ACID 事务,是金融、订单等系统的基石。 |
| 查询模式 | 擅长复杂搜索和分析。例如:“找出所有标题包含‘手机’且评论中提到‘电池耐用’的商品,并按价格聚合”。 | 擅长精确查找和关联。例如:“根据用户ID查询他的所有订单和订单详情”(多表关联查询是强项)。 |
| 数据更新 | 文档级更新效率尚可,但频繁的、单字段更新成本较高。 | 行级、字段级更新效率非常高。 |
| ** schema 灵活性** | 动态映射,写入 JSON 后自动识别类型,非常灵活。但有时会导致 mapping 爆炸或类型不准确。 | 严格模式,需要预先定义好表结构,修改成本高。 |
核心区别就在于,倒排索引 和 B-Tree
这是理解它为何是“搜索引擎”的技术根源。
- 传统数据库(使用 B-Tree 索引):
- 思考方式是:“这条记录(第 100 行)的内容是什么?”
- 索引是为了快速定位到某一行。如果你想搜索内容,需要
LIKE '%keyword%',这种操作会进行全表扫描,效率极低。
- Elasticsearch(使用倒排索引):
- 思考方式是:“包含‘学习’这个词的文档有哪些?包含‘Elasticsearch’的词的有哪些?求交集。”
- 它提前建立了一个“词汇表”,记录了每个词出现在哪些文档中。搜索时直接查询这个词汇表,速度极快。
倒排索引表示例:
| 词条 (Term) | 文档 ID 列表 |
|---|---|
| 学习 | [Doc1, Doc2, Doc3] |
| Elasticsearch | [Doc1, Doc3] |
| 入门 | [Doc2] |
当你搜索 "学习 Elasticsearch" 时,ES
会立刻找到“学习”对应的列表 [1,2,3] 和 “Elasticsearch”
对应的列表 [1,3],然后取交集,得到最终结果
[Doc1, Doc3],并计算哪个文档更相关。
一般这样理解:
- 它首先是一个强大的、分布式的【搜索引擎】。 这是它的灵魂和最强项。
- 其次,它是一个功能特殊的【NoSQL 文档数据库】。 它用强大的搜索和分析能力,换取了传统数据库在事务和复杂关联查询上的优势。
- 它还是一个卓越的【分析引擎】。 它的聚合功能可以让你对数据进行类似 OLAP 的多维分析。
所以,在实际应用中:
- 当你需要构建网站搜索、应用内搜索、日志检索系统时,把它当作 搜索引擎 来用。
- 当你需要对日志、指标进行实时分析和可视化(例如:统计错误码分布、API 响应时间趋势)时,把它当作 分析引擎 来用。
- 当你需要存储的数据主要访问模式是搜索和分析,而不是频繁的事务性更新时,可以把它当作 主数据库 的补充或甚至直接作为 数据库 来用(但需谨慎评估事务需求)。
一个非常常见的架构是:数据首先写入传统数据库(如 MySQL)以保证事务安全,然后通过同步工具(如 Canal, Logstash)将数据导入 Elasticsearch,专门用于提供复杂的搜索和分析功能。 这样各自发挥其最强项。
Elasticsearch的安装
首先是 JDK 的准备
你需要配置 JAVA_HOME 路径,ES 读取的是你系统中的 JAVA_HOME 环境变量
一般来说 ES 要大于 JDK17,我这里安装的是 ES9.1.4
就是这里需要注意一件事
你的 JDK 最好是 OpenJDK 因为这种 JDK 不会缺少一种
访问官方下载页选择Windows ZIP包
解压到一个地方,然后配置环境变量

分别是 ES_HOME 也就是 ES 的安装位置和 ES 自带 JDK 的配置
进入bin目录运行:
1 | elasticsearch.bat |
浏览器访问:
启动后第一次会显示一些配置信息,包括默认的用户密码
1 | http://localhost:9200 |
输入后显示 JSON 信息就算成功
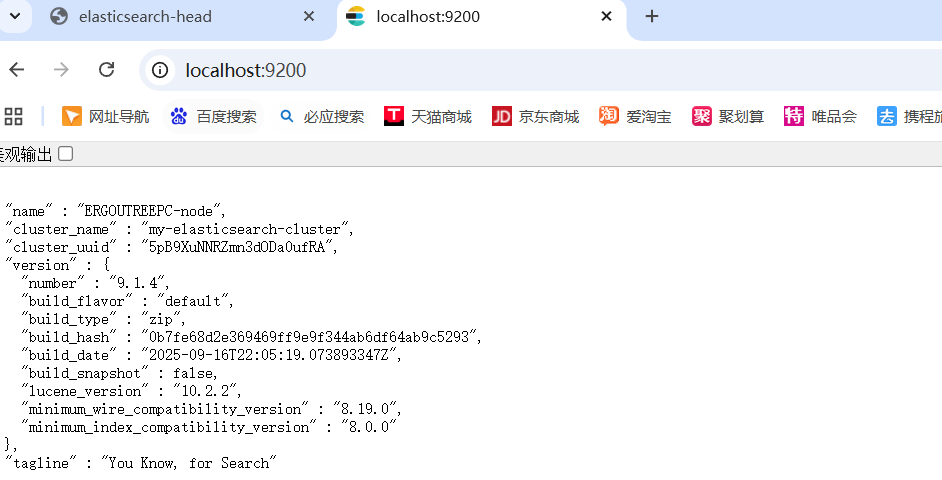
第一次启动时, 要注意此时的 ip 地址(注意下自己的虚拟机或者vpn, 它们的ip可能会产生干扰), 该 ip 地址会被绑定到 enrollment token 中, 在安装 Kibana 时有用
将 elasticsearch 以服务的方式安装,在添加上述环境变量后,cmd中执行
1 | elasticsearch-service.bat install |
启动和停止Elasticsearch服务:
1 | elasticsearch-service.bat start |
启动 Elasticsearch 属性gui:
1 | elasticsearch-service.bat manager |
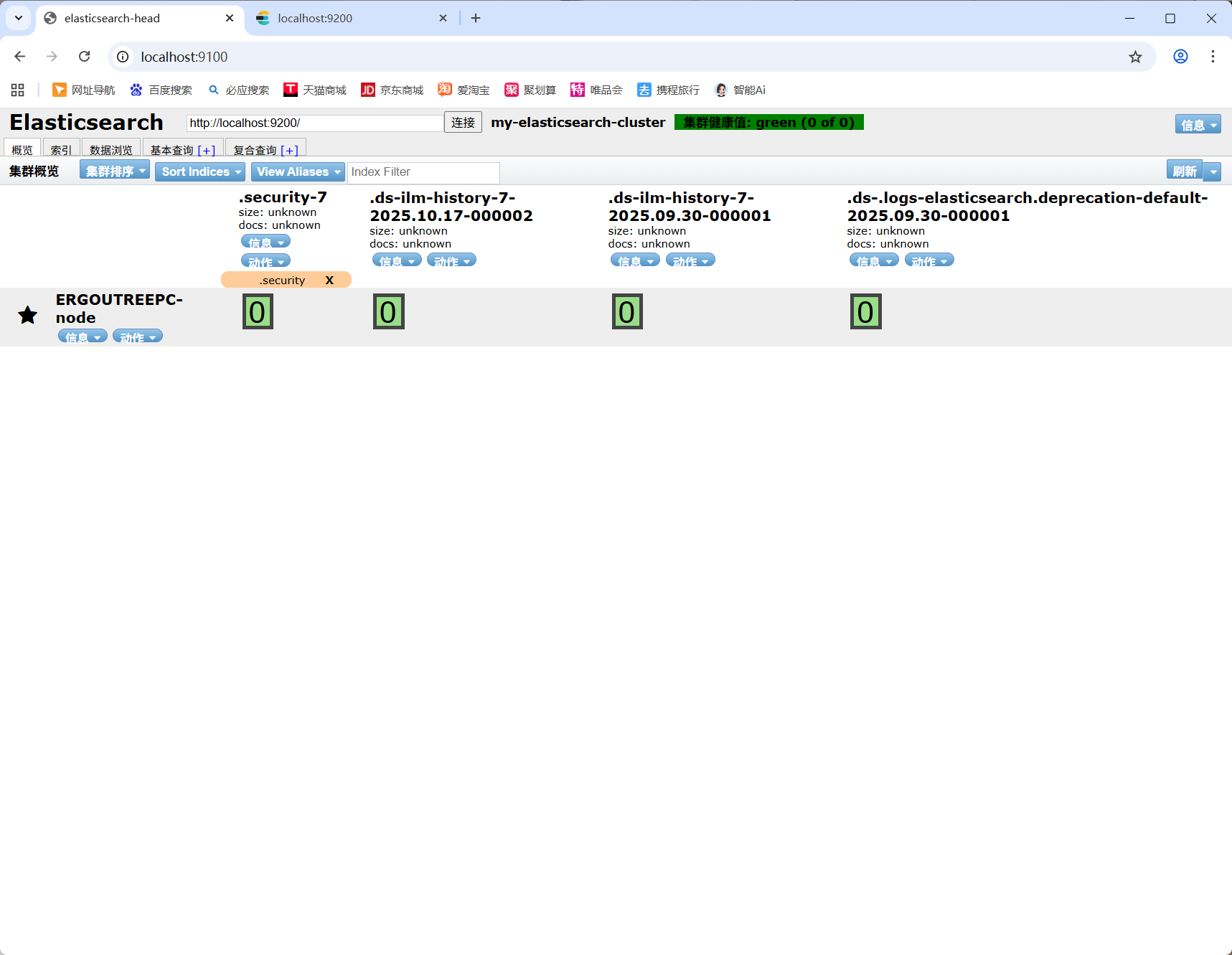
Elasticsearch-head的安装
Elasticsearch-head 是 ES 的 WebUI 管理页面
需要先安装 Grunt
1 | npm install -g grunt-cli |
从GitHub仓库下载ZIP包,解压到D:\elasticsearch-head
进入解压目录执行:
1 | npm install && npm start |
浏览器访问:
1 | http://localhost:9100 |
配置跨域,在elasticsearch.yml中添加:
1 | network.host: 0.0.0.0 |
Elasticsearch 9.x 版本默认启用了安全认证,而 elasticsearch-head 没有提供认证信息。你需要配置认证或者禁用安全功能。
禁用 Elasticsearch 安全功能的话就在 elasticsearch.yml
中添加以下配置:
1 | # 在文件末尾添加以下内容 |
然后重启 Elasticsearch。
如果你需要保持安全功能,可以在 elasticsearch-head 中配置认证:
获取初始密码:
1 | # 进入 Elasticsearch bin 目录 |
在 elasticsearch-head 中配置认证:
- 连接地址格式:
http://elastic:你的密码@localhost:9200
Kibana安装
Kibana 是一个为 Elasticsearch 设计的开源分析和可视化平台。你可以使用 Kibana 来搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互。你可以轻松地执行高级数据分析和可视化,并以各种图表、表格和地图的形式展示出来。
Elasticsearch、Logstash 和 Kibana 这三个技术就是我们常说的 ELK 技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash 担任控制层的角色,负责搜集和过滤数据。Elasticsearch 担任数据持久层的角色,负责储存数据。而我们这章的主题 Kibana 担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在 Elasticsearch 中的数据。
也就是 Kibana 是 Elasticsearch 的一种前端界面和客户端。
访问 Elastic 官方下载页面,选择与你的 Elasticsearch 版本完全一致的 Kibana 版本(那我的就是9.1.4)。
https://www.elastic.co/cn/downloads/past-releases#kibana
接下来演示的是 Windows 版本的
下载,解压
kibana.yml中修改如下配置
1 | server.port: 5601 |
进入 bin 目录下,执行 kibana.bat 文件。
但是貌似出现了Reason: Cannot find module ’../series_functions/undefined’的错误
上网发现 Kibana 的9.1.3也可以适配 ES 的9.1.4 并且没有这样的问题
启动成功
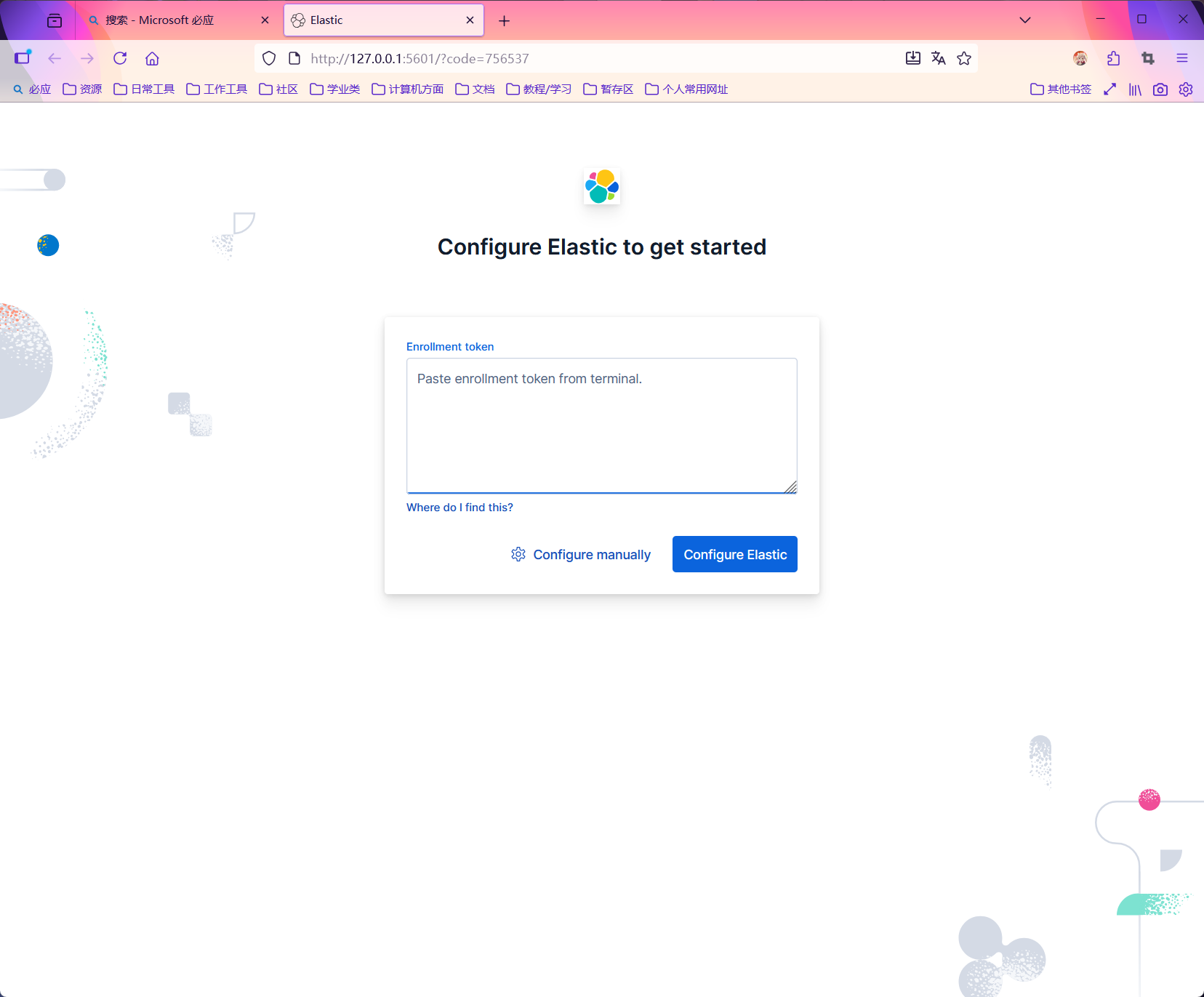
这里需要获得 Token,通过 Elasticsearch 命令行生成
1 | # 进入 Elasticsearch 的 bin 目录 |
这个页面是 Elastic 产品(通常是 Kibana,作为 Elastic Stack 的可视化界面)的欢迎页面。
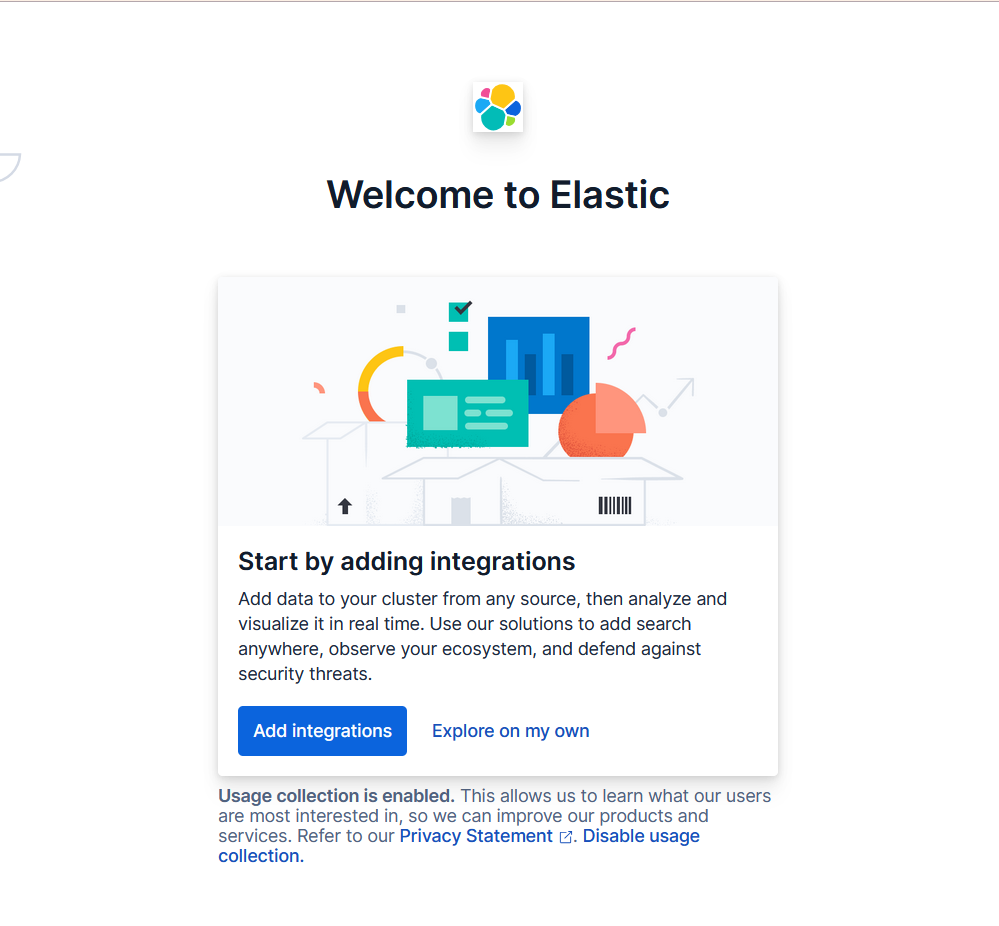
- “Add integrations”(添加集成):点击该按钮,你可以添加来自各种数据源的集成,将数据导入到 Elastic 集群中,之后能对这些数据进行实时分析和可视化。例如,可以集成日志数据、指标数据等,方便后续利用 Elastic 的搜索、观测和安全防御等功能。
- “Explore on my own”(自行探索):选择这个选项,你可以不立即添加集成,而是先自己探索 Kibana 的界面和功能,比如查看已有的数据(如果有)、熟悉仪表盘、可视化工具等。
配置完成
Linux 版本如下
选择 TAR.GZ
1 | # 进入你希望安装的目录,例如 /opt |
Kibana 的主要配置文件是 kibana.yml,位于
config 目录下。
1 | cd kibana-9.1.4/config |
改以下几个最关键的配置:
1 | # Kibana 服务端口,默认是 5601 |
elasticsearch.password的值需要替换为你实际在安装 Elasticsearch 时设置的kibana_system用户的密码。如果你忘记了,可以在 Elasticsearch 安装目录下使用bin/elasticsearch-reset-password -u kibana_system命令来重置。elasticsearch.ssl.verificationMode: none是为了方便测试。在生产环境中,这是一个安全风险,应配置正确的证书。
启动 Kibana
前台启动
1 | cd /opt/kibana-9.1.4 |
如果看到日志输出,最后有 http://0.0.0.0:5601
的信息,说明启动成功。按 Ctrl+C 可以停止。
后台启动(使用 nohup)
1 | cd /opt/kibana-9.1.4 |
创建系统服务文件(以 systemd 为例):
1 | sudo nano /etc/systemd/system/kibana.service |
将以下内容写入文件:
1 | [Unit] |
启用并启动 Kibana 服务:
1 | sudo systemctl daemon-reload |
访问 Kibana
- 打开你的浏览器。
- 访问
http://<your_server_ip>:5601。 - 第一次访问时,Kibana 可能会要求你输入一个 “Enrollment Token”。这个令牌是在 Elasticsearch 第一次启动时生成的。
获取 Enrollment Token:
在你的 Elasticsearch 服务器上运行:
1 | # 进入你的 Elasticsearch 安装目录 |
将输出的令牌复制到 Kibana 页面的输入框中。
之后,Kibana 会要求你输入一个 验证码。你需要在 Kibana 服务器的终端上查看它:
1 | # 在运行 Kibana 的服务器上执行 |
将输出的 6 位代码输入到浏览器中。
完成以上步骤后,你会被引导到登录页面。使用 Elasticsearch
的超级用户 elastic
和你为其设置的密码登录。






