
Elasticsearch 集群
ES的集群是啥样的
Elasticsearch(ES)集群是分布式搜索引擎的核心形态,通过多节点协同工作实现高可用、高扩展和负载均衡。
和其他分布式的其实差不多,ES的集群无非就是,由一个或多个节点(Node)组成的集合,共同管理整个数据集,并提供分布式查询能力。
集群通过唯一的 集群名称(默认
elasticsearch)标识,节点通过加入相同名称的集群实现协同。
节点是单个运行的 ES 实例,是集群的基本组成单元。每个节点有唯一名称(默认随机生成),可通过配置指定角色。
| 角色 | 功能说明 | 适用场景 |
|---|---|---|
| 主节点(Master) | 管理集群元数据(索引创建 / 删除、分片分配),不处理数据和查询(默认)。 | 集群控制节点,建议单独部署 |
| 数据节点(Data) | 存储数据(分片),处理 CRUD、搜索、聚合等操作。 | 承载数据和计算,需高 CPU / 内存 |
| 协调节点(Coordinating) | 接收客户端请求,分发到其他节点,聚合结果后返回(所有节点默认具备此能力)。 | 负载均衡,可单独部署 |
| ingest 节点 | 预处理写入的数据(如解析、转换),不存储数据。 | 数据清洗场景 |
| 机器学习节点 | 运行机器学习任务(如异常检测),需单独启用。 | 高级分析场景 |
而分片就是数据的最小存储单元,实现数据水平拆分。
- 主分片(Primary Shard):数据写入的原始分片,索引创建时指定数量(默认 5 个),创建后不可修改。
- 副本分片(Replica Shard):主分片的冗余副本,用于故障恢复和分担读压力,数量可动态调整(默认 1 个)。
那么这样,ES分布式的结构就很明显了,例如索引 order_index
配置 3 主分片 + 2 副本分片,则总分片数 = 3×(1+2) = 9
个,分布在不同节点上。
ES 通过 绿色、黄色、红色 标识集群可用性,可通过
GET /_cluster/health 查询:
- 绿色:所有主分片和副本分片均正常分配。
- 黄色:所有主分片正常,但部分副本分片未分配(数据安全但读性能受影响)。
- 红色:部分主分片未分配(数据丢失风险,相关索引不可用)。
高可用集群的搭建
以最小化集群部署(3 节点示例)作为演示,这适用于开发或小规模生产环境,节点同时承担主节点和数据节点角色:
| 节点名称 | IP 地址 | 角色 |
|---|---|---|
| es-node-1 | 192.168.1.1 | master: true, data: true |
| es-node-2 | 192.168.1.2 | master: true, data: true |
| es-node-3 | 192.168.1.3 | master: true, data: true |
核心配置(所有节点通用):
1 | cluster.name: my-es-cluster |
可以进行这样一个系统参数的优化
1 | # 修改系统参数 |
soft nofile 65536:表示软性限制下,一个进程最多能打开的文件描述符(或句柄)数量为65536。软性限制是一个警告阈值,当达到或超过这个限制时,系统会给出警告,但进程仍然可以继续运行(取决于系统配置和策略)。hard nofile 131072:表示硬性限制下,一个进程最多能打开的文件描述符数量为131072。硬性限制是一个严格的阈值,当达到或超过这个限制时,系统会拒绝进程打开更多的文件,并可能导致进程出错。soft nproc 2048:表示软性限制下,一个用户最多能创建的进程数量为2048。同样,这是一个警告阈值。hard nproc 4096:表示硬性限制下,一个用户最多能创建的进程数量为4096。这是一个严格的阈值,当达到或超过这个限制时,系统会拒绝用户创建更多的进程。
然后为每个节点安装 JDK,安装 ES,下载后将压缩包上传至服务器。
然后生成ES的证书(用于ES节点之间进行安全数据传输),注意是其中一个ES节点执行,生成证书后拷贝到其他服务器的ES节点上。
Elasticsearch 节点间通信(9300 端口)默认不加密,生产环境需通过
SSL/TLS 加密。我们使用 ES 自带的 elasticsearch-certutil
工具生成证书,步骤如下:
在其中一个节点(如 es-node-1)生成证书,登录 es-node-1
服务器,切换到 Elasticsearch 安装目录(假设安装路径为
/opt/elasticsearch-8.10.4),执行证书生成命令:
1 | # 进入ES安装目录的bin文件夹 |
cert:生成节点间通信的证书。-out:指定证书输出路径(需先创建certs文件夹)。-pass "":证书无密码(生产环境可设置密码,需记录)。
执行后会在 /opt/elasticsearch-8.10.4/config/certs/
目录生成 elastic-certificates.p12 文件(PKCS#12
格式证书)
将生成的证书拷贝到 es-node-2 和 es-node-3
的相同目录下,确保所有节点的证书一致:
1 | # 在es-node-1上执行,拷贝证书到es-node-2 |
拷贝后需修改证书文件的权限,确保 Elasticsearch 进程有权限访问(假设
ES 运行用户为 elasticsearch):
1 | # 在所有节点执行 |
在之前的基础配置上,添加 SSL 加密相关配置,确保节点间通信和 HTTP
访问均加密。修改所有节点的
elasticsearch.yml(路径:/opt/elasticsearch-8.10.4/config/elasticsearch.yml):
1 | # -------------- 原有配置 -------------- |
配置好了就可以启动了,建议按
es-node-1 → es-node-2 → es-node-3
的顺序启动,确保主节点选举顺利进行。
1 | # 在每个节点上,切换到elasticsearch用户(禁止root启动) |
ES 8.x 9.x 启用安全模块后,默认会生成随机密码,但我们可以手动设置固定密码(在任意一个节点执行):
1 | # 切换到ES的bin目录 |
按照提示为以下用户设置密码(至少记住 elastic
用户的密码,这是用于管理员操作的):
elastic:超级管理员用户。kibana:Kibana 连接 ES 专用用户。logstash_system:Logstash 连接 ES 专用用户。
之后就可以查看节点列表,查看配置的情况了
1 | curl -u elastic:Elastic@123 -k https://192.168.1.1:9200/_cat/nodes?v |
输出示例(3 个节点均为 master 和 data
角色):
1 | ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name |
为确保集群高可用,可模拟节点故障,验证集群是否自动恢复:
1 | # 查找ES进程ID并杀死,停止主节点(es-node-1),模拟节点故障 |
再检查集群的状态
1 | curl -u elastic:Elastic@123 -k https://192.168.1.2:9200/_cluster/health?pretty |
- 短暂时间后,集群状态应从
red恢复为yellow或green(新主节点会被选举,如es-node-2或es-node-3)。 - 查看节点列表,确认新主节点标记(
*)。
至此,一个 3 节点的 Elasticsearch 高可用集群已搭建完成,可以继续部署 Kibana 连接集群
Elasticsearch集群特性
主节点选举(Master Election)
据我所知 Nacos 也是这种选举式主节点
当集群启动或现有主节点故障时,由具备 node.master: true
的节点竞争成为主节点,确保集群元数据一致性。
- 关键参数:
discovery.seed_hosts(候选主节点列表)、cluster.initial_master_nodes(首次启动时的初始主节点)。 - 选举条件:获得超过半数候选主节点的投票(如 3 个候选节点需至少 2 票)。
配置示例:
1 | # 候选主节点的IP:端口列表 |
而且由主节点决定分片在节点上的分布,遵循以下原则:
- 主分片均匀分布在不同节点。
- 副本分片不会与对应的主分片在同一节点(避免单点故障)。
- 优先分配到磁盘空间充足、负载较低的节点。
当然你可以手动调整
1 | # 将索引order_index的副本数调整为2 |
同步机制:数据写入主分片后,异步同步到副本分片,确保最终一致性。
故障转移:若主节点故障,重新选举主节点;若数据节点故障,主分片丢失时,自动将其副本分片升级为主分片。
Elasticsearch 分片
什么是Elasticsearch 分片
Elasticsearch 分片通过将索引拆分为多个主分片和副本分片,实现了数据的分布式存储、并行处理和高可用。主分片负责数据写入和核心计算,副本分片提供冗余和查询扩展,两者结合是 Elasticsearch 应对大规模数据和高并发场景的核心能力。
在 Elasticsearch 中,分片(Shard) 是数据的最小存储和处理单元,用于实现数据的分布式存储与并行计算。
- 当索引(Index)的数据量过大时,单节点无法高效存储和处理,Elasticsearch 会将索引数据拆分到多个分片中,每个分片是一个独立的 Lucene 索引(Elasticsearch 基于 Lucene 实现),可分布在集群的不同节点上。
- 分片是 Elasticsearch 实现水平扩展(存储容量、查询性能)的核心机制。
Elasticsearch 将分片分为两种类型,两者配合实现高可用和数据安全:
- 主分片(Primary Shard)
- 索引数据的原始分片,负责处理索引和查询请求,是数据写入的唯一入口。
- 一个索引的主分片数量在创建时固定(默认 1 个),后续无法修改(除非重建索引),需提前根据数据量规划。
- 副本分片(Replica Shard)
- 主分片的冗余副本,用于故障转移和负载均衡(分担查询压力)。
- 副本分片的数据与主分片实时同步,本身不处理写入请求,但可处理查询请求。
- 副本分片的数量可动态调整(默认 1 个,即每个主分片对应 1 个副本),且不能与对应的主分片在同一节点(避免单点故障)。
也就是说,ES通过分片将大索引拆分到多个分片,分散在不同节点,突破单节点存储上限,实现了分布式存储,简单来讲就是在ES中所有数据的文件块,也是数据的最小单元块,整个ES集群的核心就是对所有分片的分布、索引、负载、路由等达到惊人的速度
- 假设 IndexA 有2个分片,我们向 IndexA 中插入10条数据 (10个文档),那么这10条数据会尽可能平均的分为5条存储在第一个分片,剩下的5条会存储在另一个分片中。
和主流关系型数据库的表分区的概念有点类似
而分片也和分布式的状态管理类似
- 主节点通过集群状态(Cluster State)
维护分片的分布和状态(如
STARTED、UNASSIGNED等)。 - 当节点故障时,主节点检测到分片不可用,会自动将该分片的副本升级为主分片(若有副本),并重新分配新的副本分片到其他节点。
这个状态管理和 Nacos 非常像
分片的实现
Elasticsearch 分片的实现依赖于 Lucene 和分布式协调机制,核心流程如下:
分片的创建与分配
索引创建时:用户指定主分片数量(
number_of_shards)和副本数量(number_of_replicas),例如1
2
3
4
5
6
7PUT /my_index
{
"settings": {
"number_of_shards": 3, // 3个主分片
"number_of_replicas": 1 // 每个主分片1个副本(共3个副本分片)
}
}分片分配:集群的主节点(Master Node)根据节点负载、可用空间等策略,将主分片和副本分片分配到不同节点(副本不会与主分片同节点)。
索引建立后,分片个数是不可以更改的
那么分片的个数应该如何确定,太多肯定不行,太少肯定也不太行
一般情况如下:
1 | SN(分片数) = IS(索引大小) / 30 |
每一个分片数据文件小于30GB
每一个索引中的一个分片对应一个节点
节点数大于等于分片数
分片创建了如何把文档进行分配呢?
当写入文档时,Elasticsearch 会通过哈希算法确定文档所归属的主分片,流程如下:
- 计算文档
_id的哈希值(若未指定_id,则自动生成)。 - 用哈希值对主分片数量取模:
shard = hash(_id) % number_of_primary_shards。 - 文档被路由到计算出的主分片,并同步到其所有副本分片。
所以主分片数量固定的原因是,若数量变化,取模结果会改变,导致所有文档的路由规则失效,数据无法正确查找。
而查询请求会被分发到索引的所有主分片或副本分片(通过负载均衡选择),流程如下:
- 协调节点(接收请求的节点)将查询分发到相关分片。
- 各分片执行查询并返回本地结果。
- 协调节点汇总所有分片结果,处理排序、聚合等,最终返回给用户。
副本分片数量对 Elasticsearch 性能的影响
副本分片(Replica Shard)的数量直接影响 Elasticsearch 的高可用性和查询性能,但也会带来存储和写入开销
ES 做不到既要又要
对查询性能的影响
- 正面影响:副本分片可分担查询压力。当查询请求量较大时,协调节点会将请求分发到主分片和副本分片(通过轮询等负载均衡策略),多个分片并行查询,能显著提升整体查询吞吐量。
- 负面影响:副本数量过多时,查询结果的聚合(协调节点汇总各分片结果)开销会略有增加,但通常远小于查询并行带来的收益。
对写入性能的影响
- 负面影响:每次写入主分片后,主分片需将数据同步到所有副本分片(并行同步)。副本数量越多,同步的耗时越长,写入性能越低(但 Elasticsearch 会通过异步 / 同步策略平衡,默认是等待主分片和至少一个副本写入成功后返回)。
对高可用性的影响
正面影响:副本数量越多,主分片故障时,可快速将副本升级为主分片的概率越高,服务恢复更迅速,高可用性越强。
无副本风险:若副本数为 0,主分片故障会导致数据丢失且服务中断,直到主分片所在节点恢复。
分片查询
首先要清楚一个关键规则:一个索引的分片数量在创建时固定(主分片不可修改,副本可动态调整),查询会覆盖该索引的所有主分片 + 所有可用副本分片。
ES 采用 “协调节点(Coordinating Node)” 主导的分布式查询模式,流程可分为 4 步,完全适配分布式场景下的性能与一致性需求,所以说
请求分发(协调节点)
用户发起查询请求(如
GET /index/_search),该请求会先到达任意一个协调节点(无需提前指定,ES 自动路由)。协调节点根据索引的分片配置(主分片数量、副本分布),计算出 “需要查询哪些分片”,并为每个分片选择一个 “执行节点”(优先选副本分片,避免主分片压力过大)。
示例:若索引
ergou_store有 3 个主分片(P0/P1/P2),每个主分片有 1 个副本(R0/R1/R2),协调节点可能会将查询分发到 R0(节点 A)、P1(节点 B)、R2(节点 C)。
并行执行(数据节点)
每个接收请求的 “数据节点”(存储分片的节点),会在本地分片上独立执行查询逻辑(如过滤、排序、聚合),并生成部分结果(而非全量数据)。
优势:并行计算大幅提升查询速度,尤其在亿级数据场景下,避免单节点算力瓶颈。
结果聚合(协调节点)
- 协调节点收集所有数据节点返回的 “部分结果”,进行全局合并处理:
- 排序:将各分片的 Top N 结果合并为全局 Top N。
- 聚合:将各分片的统计值(如求和、计数)汇总为全局统计值。
- 去重:若查询有
distinct需求,需合并各分片的唯一值并去重。
- 注意:聚合操作可能产生 “内存压力”,若聚合结果集过大,需调整
size或使用滚动查询(Scroll)。
- 协调节点收集所有数据节点返回的 “部分结果”,进行全局合并处理:
响应返回(协调节点)
- 协调节点将最终聚合后的结果封装成 JSON 格式,返回给用户或应用程序。
查看 es 分片信息如下
1 | curl -XGET http://localhost:9200/_cat/shards/test*?v |
- 这是模糊匹配,比如匹配test:
返回信息如下:
1 | index shard prirep state docs store ip node |
解析如下:
1 | index:所有名称 |
查看所有分片状态如下
1 | # 查看索引ergou_tree_galemj_store的所有分片信息 |
我 ES 没开,不演示了,信息类似上面的内容
在实际的业务中,写成java代码如下
1 | // 查询每个分片的文档数 |
分片级聚合查询在避免协调节点出现性能瓶颈的时候很有用
但是一般都是当数据量极大时,因为这时候全局聚合(协调节点合并所有分片结果)可能产生瓶颈,可通过 分片级聚合(Shard-level Aggregations) 先在分片本地计算中间结果,再聚合全局结果。
实际上在代码可以这么写
1 | // 分片级聚合:统计每个分类的商品数(先分片本地聚合,再全局合并) |
Elasticsearch读写原理
Elasticsearch读取数据过程
整体的读取流程比较清晰,和写入比较类似,两则可以关系着看
请求发送到协调节点
客户端发起读取数据的请求,并将该请求发送到 Elasticsearch 集群中的一个节点,这个节点被称为协调节点(coordinate node) 。协调节点负责协调整个读取操作,它并不存储实际的数据,而是起到类似于 “交通枢纽” 的作用,对请求进行转发和结果汇总。
广播请求到分片
协调节点接收到请求后,会根据轮询算法(round-robin 随机轮询算法)将查询请求广播到各个节点上不同的分片,包括主分片(primary shard)和副本分片(replica shard)。使用轮询算法的目的是为了实现负载均衡,确保各个分片能够均匀地分担查询压力,避免某些分片出现过载的情况。
查询阶段(query phase)
- 分片本地查询:每个接收到查询请求的分片会在本地执行查询操作。由于 ES 的数据存储在倒排索引中,这个过程会快速定位到符合查询条件的文档。不过,此时分片并不会直接返回完整的文档数据,而是返回一些轻量级的结果,例如文档 ID(doc id)、排序信息等 。这些轻量级结果的好处是数据量较小,能够快速在网络中传输,减少传输开销。
- 结果合并与处理:各个分片将本地查询得到的轻量级结果返回给协调节点。协调节点收到所有分片的结果后,会进行全局的合并、排序、分页等操作。比如,根据查询条件中的排序规则对所有分片返回的文档 ID 进行统一排序,以及按照分页参数确定最终需要返回给客户端的文档范围,从而产出最终的查询排序结果。
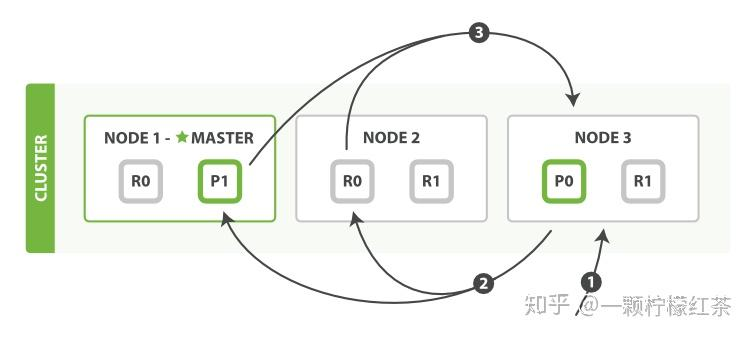
取回阶段(fetch phase)
- 获取实际文档数据:协调节点根据在查询阶段得到的最终查询排序结果,确定需要获取实际文档数据的文档 ID。然后,协调节点向包含这些对应文档 ID 的节点(主分片或副本分片所在节点)发送请求,拉取实际的 document 数据。
- 返回结果给客户端:相关节点将实际的文档数据返回给协调节点,协调节点再将这些数据最终返回给客户端,至此,客户端完成了数据读取操作。
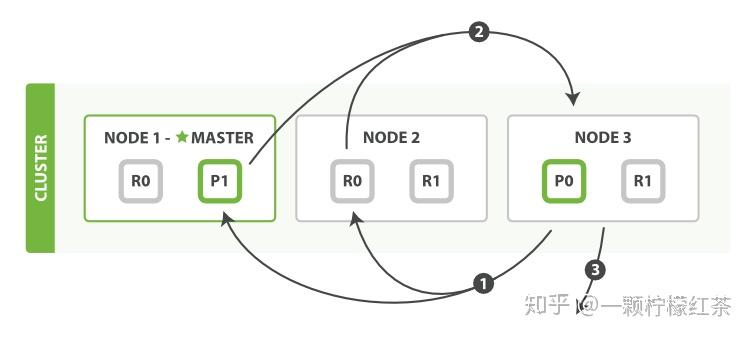
简单读取特定 doc id 文档的情况
如果只是简单地读取某个 doc id 对应的文档值,就不需要经过完整的查询阶段。因为可以直接根据 doc id 确定文档所在的分片,所以直接按照取回阶段(fetch phase) 的过程,由协调节点向包含该 doc id 的节点请求获取文档数据,并返回给客户端即可。
Elasticsearch写入数据过程
首先整理写入的流程是比较清晰的,但拆开每个环节都会比较那个
- 协调节点(Coordinating Node)选择:客户端会挑选一个 ES 节点发送写入请求,这个被选中的节点就成为协调节点。协调节点的作用是统筹整个写入操作,它需要确定新文档应该写入到哪个分片(shard)中。因为每个节点都存储着所有分片在各节点的分布信息,所以协调节点能精准地将请求转发到主分片(primary shard)所在的节点。
- 主分片写入与副本同步:主分片所在节点接收到请求后,完成新文档的写入操作。之后,主分片会并行地将请求发送给其所有的副本分片(replica shard),这样做是为了保证数据的高可用性,让副本分片也能拥有最新的数据。
- 结果反馈:协调节点会收集主分片和所有副本分片所在节点的响应信息,然后将最终的结果返回给客户端,告知客户端写入操作是否成功。
底层存储原理就涉及到了数据在分片内的处理
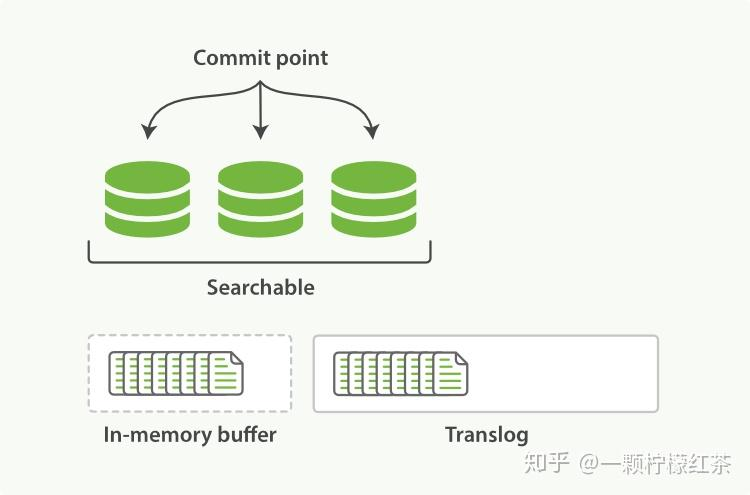
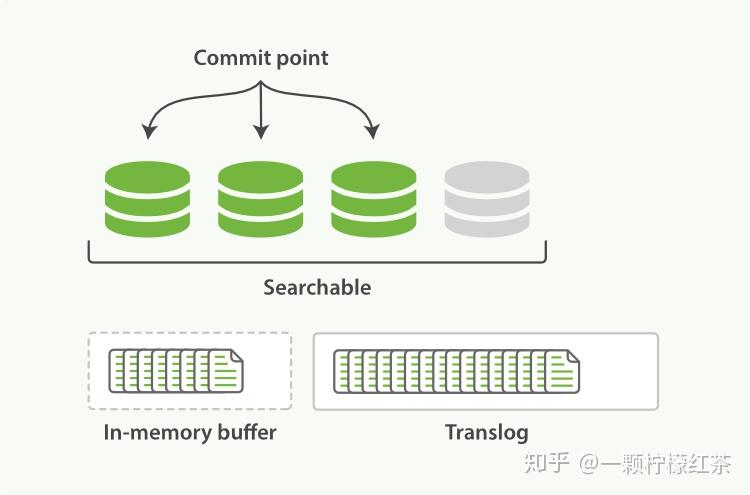
数据暂存与日志记录(Refresh 前)
当有新文档写入时,首先会被写入内存缓冲区(in - memory buffer),与此同时,这次写入操作会被记录到事务日志(translog)中。需要注意的是,在这个阶段,新文档还不能被搜索到,因为它还没有进入可搜索的存储结构。
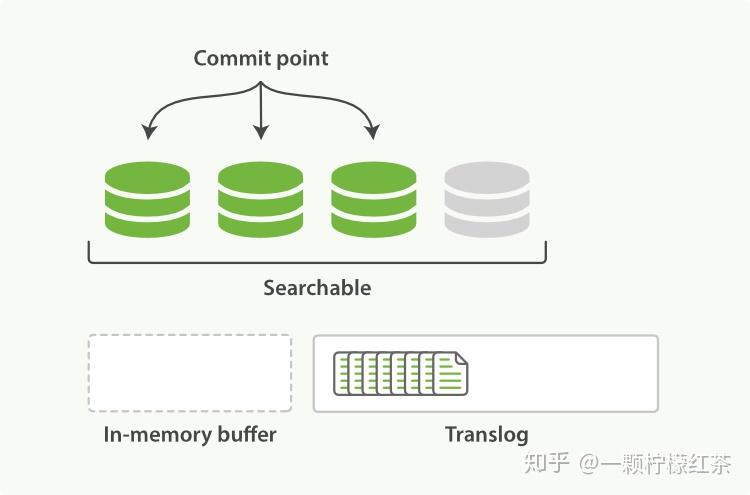
生成可搜索分段(Refresh 操作)
当 buffer 中有数据,ES 默认每隔 1 秒(这个时间可以配置修改)会执行一次 refresh 操作。在 refresh 过程中,内存缓冲区中在这 1 秒内写入的文档会被写入到文件系统缓存(filesystem cache)中,并且形成一个分段(segment),之后内存缓冲区会被清空。此时,这个 segment 里的文档就可以被搜索到了,但这些文档还没有被持久化到硬盘中,如果此时发生断电,这些文档就有可能丢失。
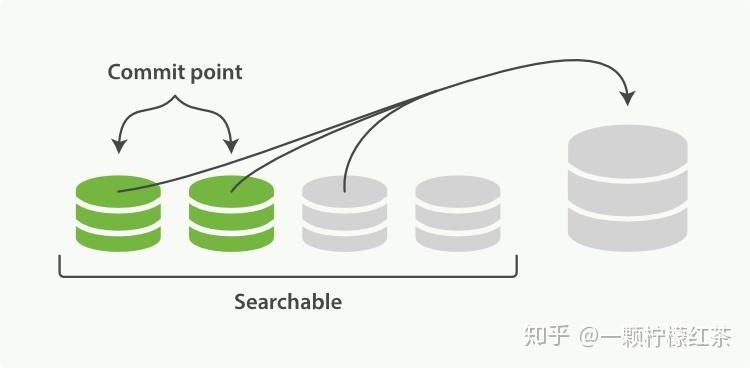
事务日志增长与 Flush 操作
随着新文档不断写入,refresh 操作会不断重复执行,每隔一秒就会生成一个新的 segment,而 translog 文件也会越来越大。
当每隔 30 分钟,或者 translog 文件大到一定程度时,就会执行一次 fsync 操作。
在 fsync 操作时,会先立刻执行一次 refresh 操作,然后将文件系统缓存中所有的 segment 写入到磁盘中,同时旧的 translog 会被删除,之后会生成新的 translog,这个过程被称为 flush。
flush 操作的目的是将数据持久化到磁盘,保障数据的安全性。
数据安全保障(Translog 的作用)
由上面的流程可以看出,在两次 fsync 操作之间,存储在内存和文件系统缓存中的文档是不安全的,一旦断电就可能丢失。
ES 引入 translog 来记录两次 fsync 之间的所有操作。这样,当机器从故障中恢复或者重新启动时,ES 就可以根据 translog 来还原数据。
不过,translog 本身也是存在于内存中的文件,断电也会丢失,但 ES 会每隔 5 秒或者在一次写入请求完成后,将 translog 写入磁盘。可以认为一个对文档的操作一旦写入磁盘便是安全的可以复原的。
只有当操作记录被写入磁盘后,ES 才会把操作成功的结果返回给客户端,以此确保数据操作的安全性。
搜索效率优化(Segment 合并)
由于每秒都会生成一个新的 segment,分片里很快就会有大量的 segment。当对一个分片进行查询请求时,需要轮流查询分片中的所有 segment,这会降低搜索效率。
所以 ES 会自动启动合并 segment 的工作,将一部分大小相似的 segment 合并成一个新的大 segment。
在合并过程中,会创建一个新的 segment,当新 segment 被写入磁盘后,所有被合并的旧 segment 就会被清除,从而提高搜索的效率。
Elasticsearch更新文档的机制
Elasticsearch(ES)更新和删除文档的底层机制都围绕不可变 Segment 特性展开,通过特殊标记和后台合并来实现
首先可以看这样的一段伪代码
1 | // 伪代码表示更新过程 |
这大概就是 ES 底层更新文档的机制,其中,还会涉及到乐观锁的控制版本
而更新本质上是 “删除旧版 + 插入新版”
标记旧文档为删除
ES 的 Segment 是不可变的(一旦写入磁盘,就无法修改)。当更新文档时,ES 不会直接修改原 Segment 中的文档,而是先在原文档所在的 Segment 中,将该文档标记为 “已删除”(类似数据库的逻辑删除)。
插入新文档版本:
然后,ES 会将更新后的新文档版本,按照 “新文档写入流程”(先写内存缓冲区、生成新 Segment 等)插入到新的 Segment 中。此时,搜索时会同时查询所有 Segment:旧 Segment 中被标记为删除的文档会被过滤,新 Segment 中的新文档版本会被返回。
后台合并清理:
随着时间推移,ES 会通过 “Segment 合并”(如
_forcemerge操作或自动合并),将多个小 Segment 合并为大 Segment。合并时,会自动清理被标记为删除的旧文档,只保留最新的文档版本,从而减少无效数据对存储和搜索的影响。
而每一个磁盘上的segment都会维护一个del文件,用来记录被删除的文件。每当用户提出一个删除请求,文档并没有被真正删除,索引也没有发生改变,而是在del文件中标记该文档已被删除。
因此,被删除的文档依然可以被检索到,只是在返回检索结果时被过滤掉了。每次在启动segment合并工作时,那些被标记为删除的文档才会被真正删除。
更新文档会首先查找原文档,得到该文档的版本号。然后将修改后的文档写入内存,此过程与写入一个新文档相同。同时,旧版本文档被标记为删除,同理,该文档可以被搜索到,只是最终被过滤掉。
Elasticsearch删除文档的机制
Elasticsearch 的删除是 逻辑删除,而不是物理立即删除。
每一个磁盘上的segment都会维护一个del文件,用来记录被删除的文件。每当用户提出一个删除请求,文档并没有被真正删除,索引也没有发生改变,而是在del文件中标记该文档已被删除。因此,被删除的文档依然可以被检索到,只是在返回检索结果时被过滤掉了。每次在启动segment合并工作时,那些被标记为删除的文档才会被真正删除。
删除操作的底层步骤相对清晰,我使用伪代码展示
标记删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 伪代码表示删除过程
public void deleteDocument(String index, String id) {
// 1. 在 .liv 文件中标记文档为删除状态
addToLiveDocsDeletions(id);
// 2. 在事务日志中记录删除操作
addToTranslog(DELETE, index, id);
// 3. 更新版本号
updateVersionInVersionMap(id, Version.DELETED);
// 4. 返回删除成功(此时物理数据还在)
return DeleteResult.SUCCESS;
}段合并时的物理删除
1
2
3
4
5
6
7
8
9
10
11
12
13// 段合并时的清理过程
public void performSegmentMerge(List<Segment> segments) {
for (Segment segment : segments) {
// 只复制未被删除的文档到新段
for (Document doc : segment.getDocuments()) {
if (!isDeleted(doc.getId())) {
newSegment.addDocument(doc);
}
}
}
// 删除旧的段文件
deleteOldSegments(segments);
}
物理删除存在四个时机
| 操作 | 触发条件 | 效果 |
|---|---|---|
| Refresh | 自动(1s) / 手动 | 新段不包含删除文档,但原段仍在 |
| Flush | translog 大小 / 手动 | 持久化删除状态,清理 translog |
| Merge | 段数量/大小阈值 | 物理删除数据,释放磁盘空间 |
| Expunge Deletes | 手动强制 | 立即物理删除所有标记的文档 |
而删除文档(本质是 “标记删除 + 合并清理”)
标记为删除:
当执行删除文档操作时,ES 同样不会直接从 Segment 中物理删除文档,而是在文档所在的 Segment 中,将该文档标记为 “已删除”。此时,该文档仍占用磁盘空间,但搜索时会被过滤掉,不会出现在结果中。
合并时清理:
只有当 Segment 参与合并时(如定期的自动合并,或手动触发
_forcemerge),ES 才会在合并过程中,物理删除那些被标记为 “已删除” 的文档,释放磁盘空间。
更新和删除操作的底层,都依赖 ES 写入流程中的内存缓冲区(In - memory Buffer)、事务日志(Translog)、Refresh、Flush 等机制:
- 标记删除 / 插入新文档的操作,会先写入内存缓冲区,并记录到 Translog。
- 之后通过 Refresh 生成可搜索的 Segment(更新的新文档版本会进入新 Segment)。
- 最终通过 Flush 将 Segment 持久化到磁盘,同时 Translog 确保操作的可恢复性。






